Create a Project Using QuickStart
Before you begin
You need:
- Java SE JDK 8 or later
- MarkLogic Server (See Version Compatibility.)
- Chrome or Firefox for QuickStart
About this task
QuickStart is the easiest way to use MarkLogic Data Hub.
In this task, you will download and run the QuickStart .war file to do the following:
- Set up the local directories and files required for your project.
- Deploy the required Data Hub components to your MarkLogic Server.
Important: QuickStart is not supported for production use.
Procedure
- Run the QuickStart .war.
- To use the default port number for the internal web server (port 8080):
java -jar marklogic-datahub-5.2.1.war - To use a custom port number; e.g., port 9000:
java -jar marklogic-datahub-5.2.1.war --server.port=9000
Note: If you are using Windows and a firewall alert appears, click Allow access.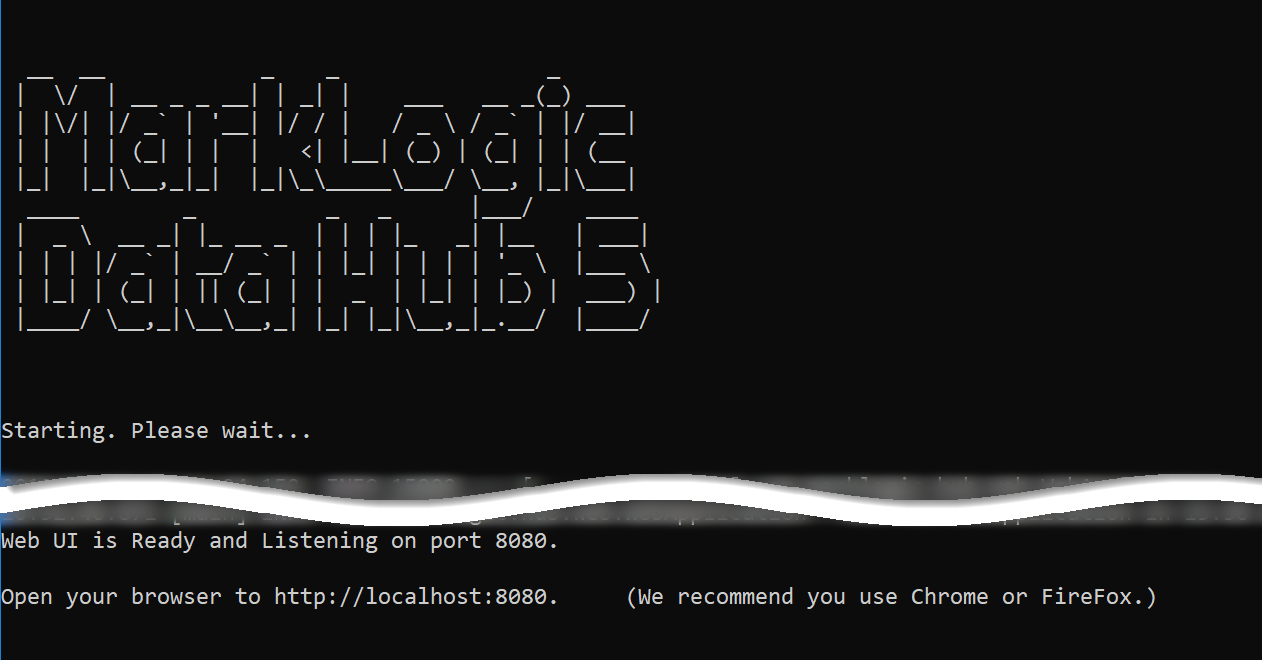
- To use the default port number for the internal web server (port 8080):
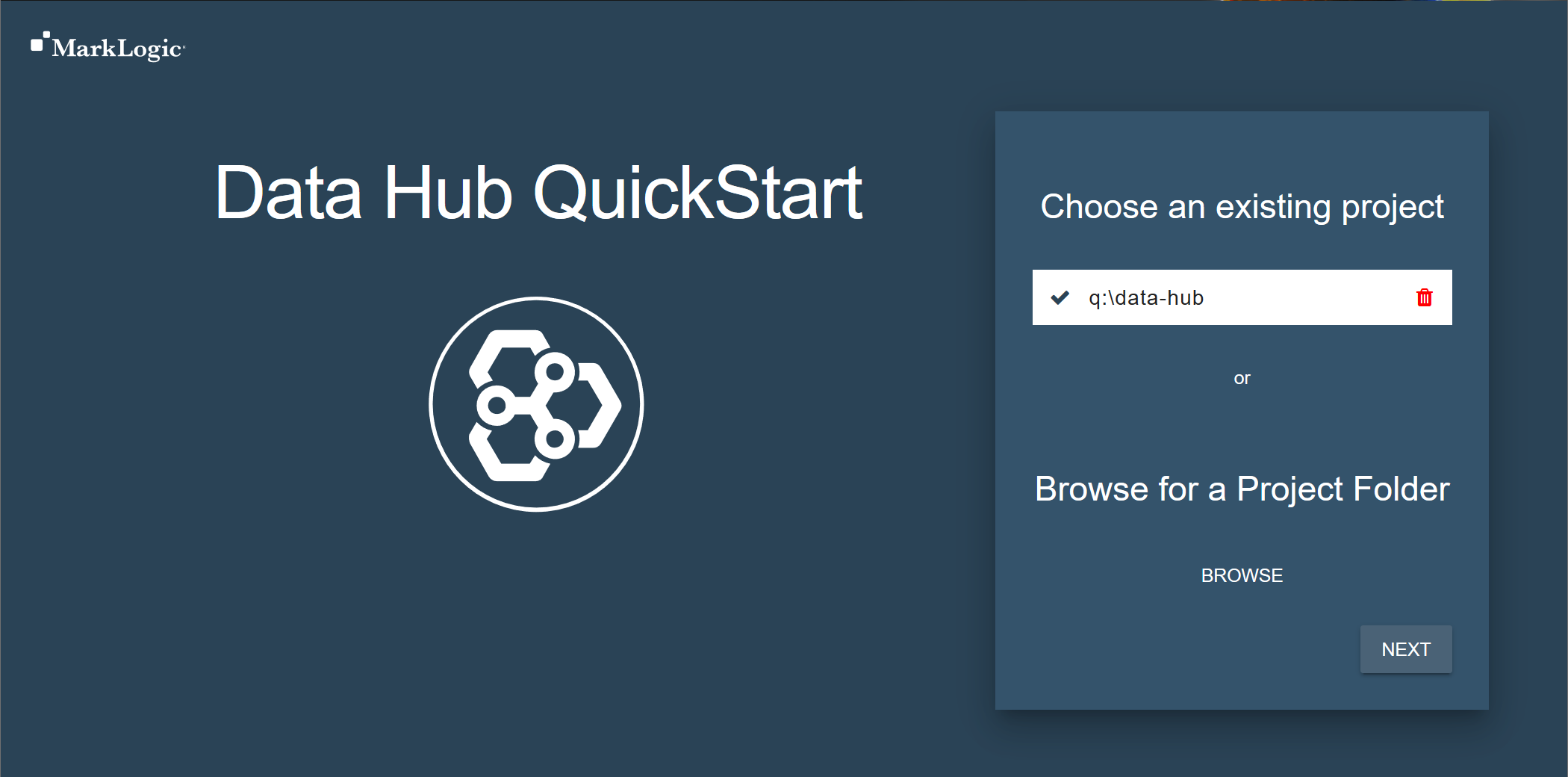
- Go through the wizard to initialize your project and install Data Hub to your MarkLogic Server.
- Browse to your project root directory. Then click .
- Click to initialize your project directory.
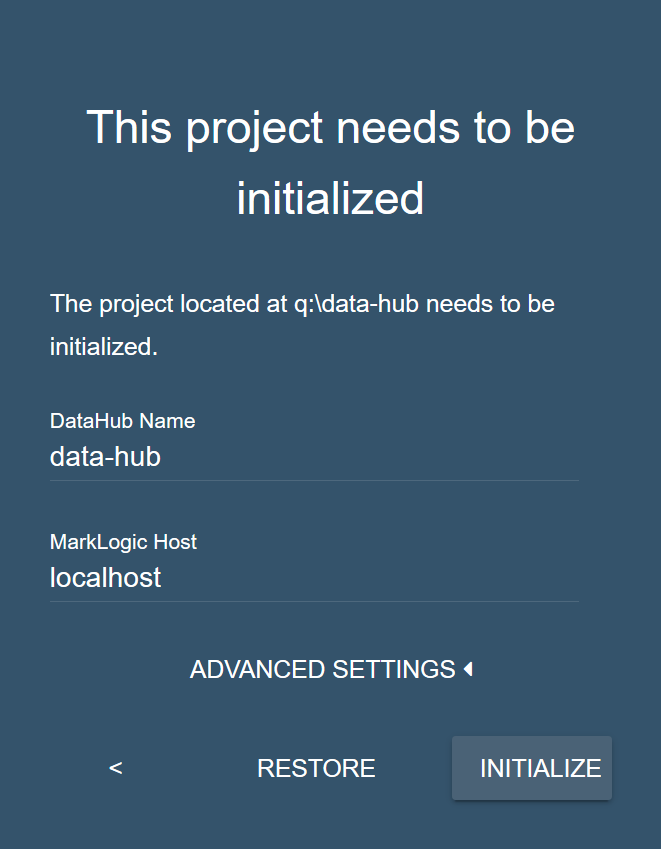
- After initializing your Data Hub Framework project, your project directory contains additional files and directories. Click .
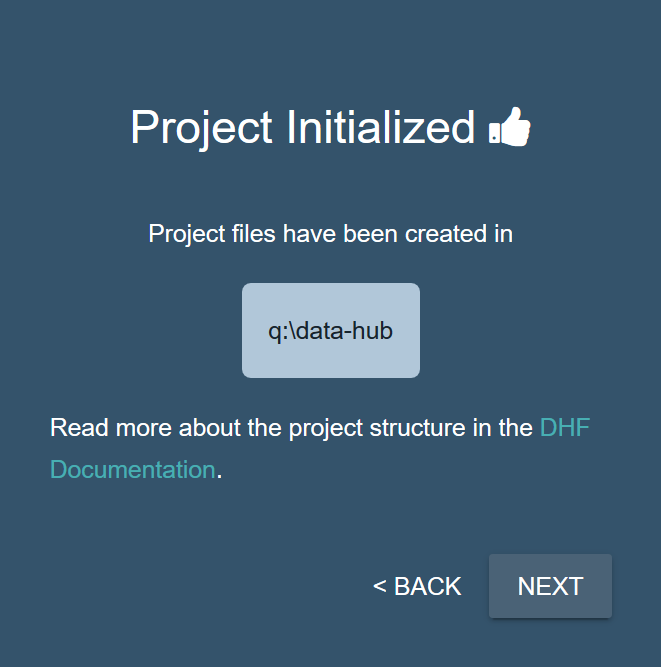
- Choose the local environment, then click .
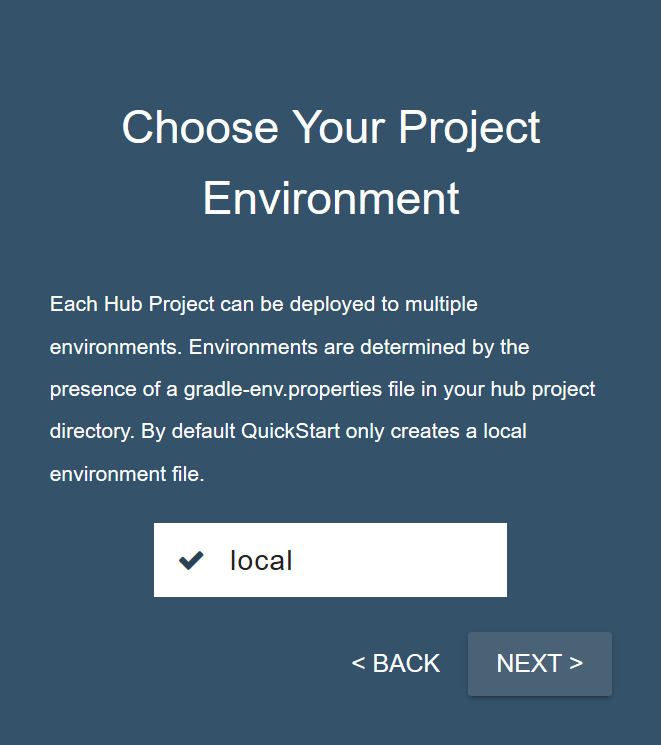
- Enter your MarkLogic Server credentials, then click .
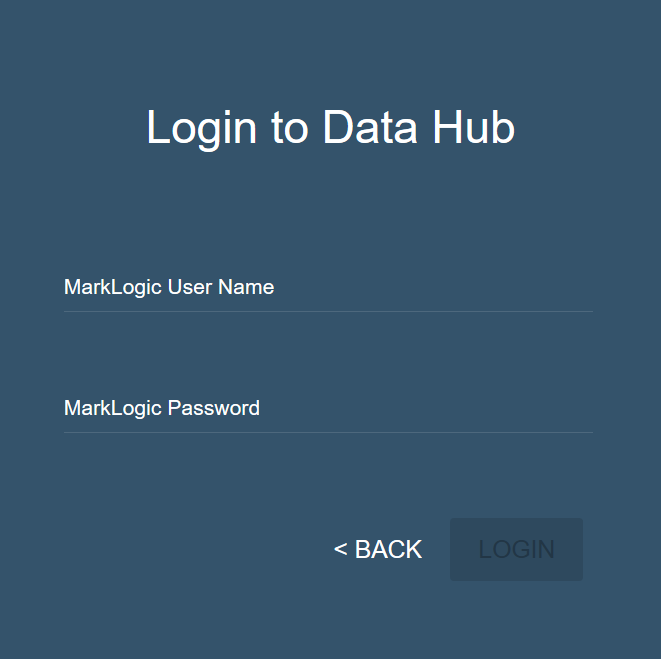
- Click to install the Data Hub into MarkLogic.

- Wait for the installation to complete.
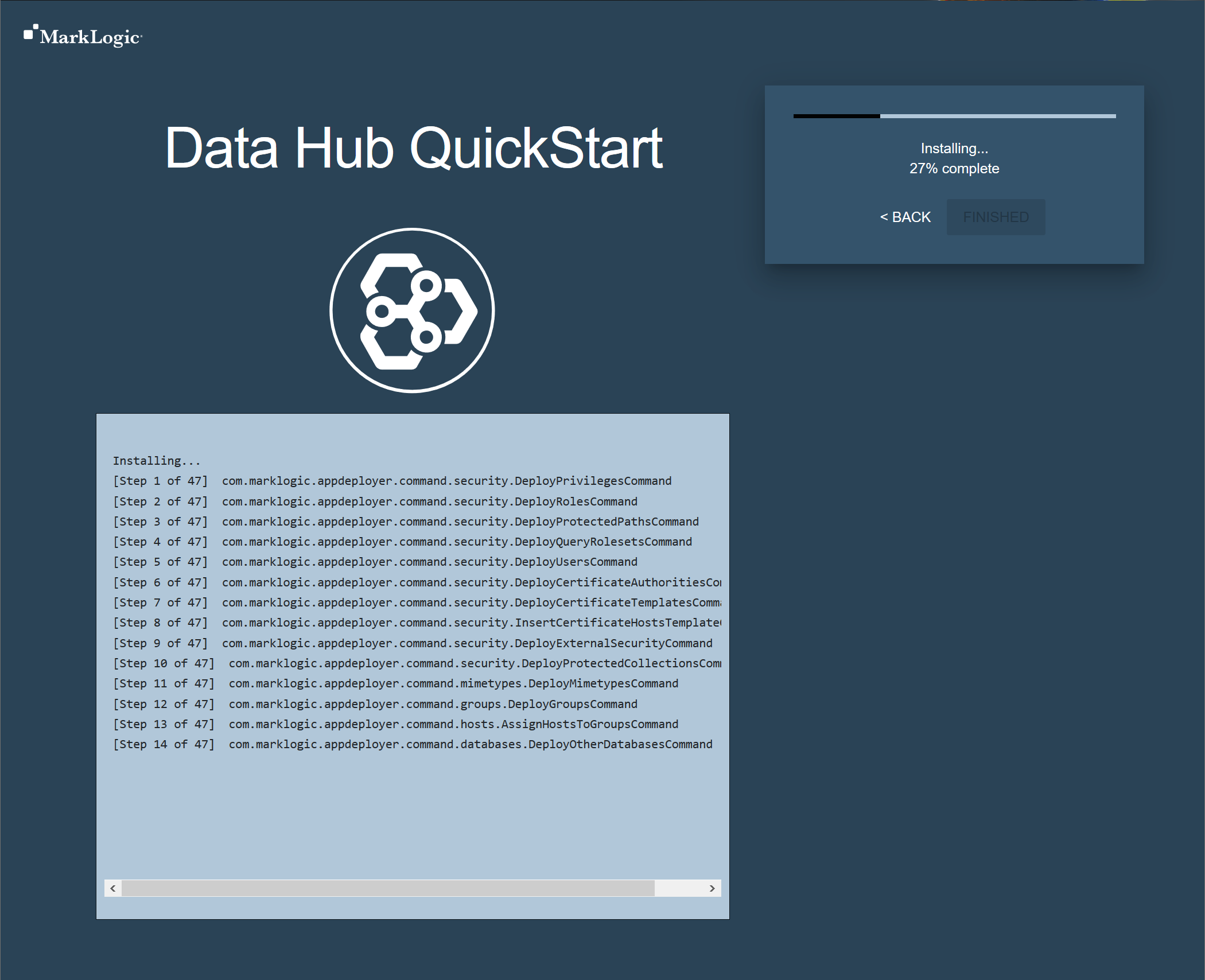
- When installation is complete, click .
- Browse to your project root directory. Then click .
Results
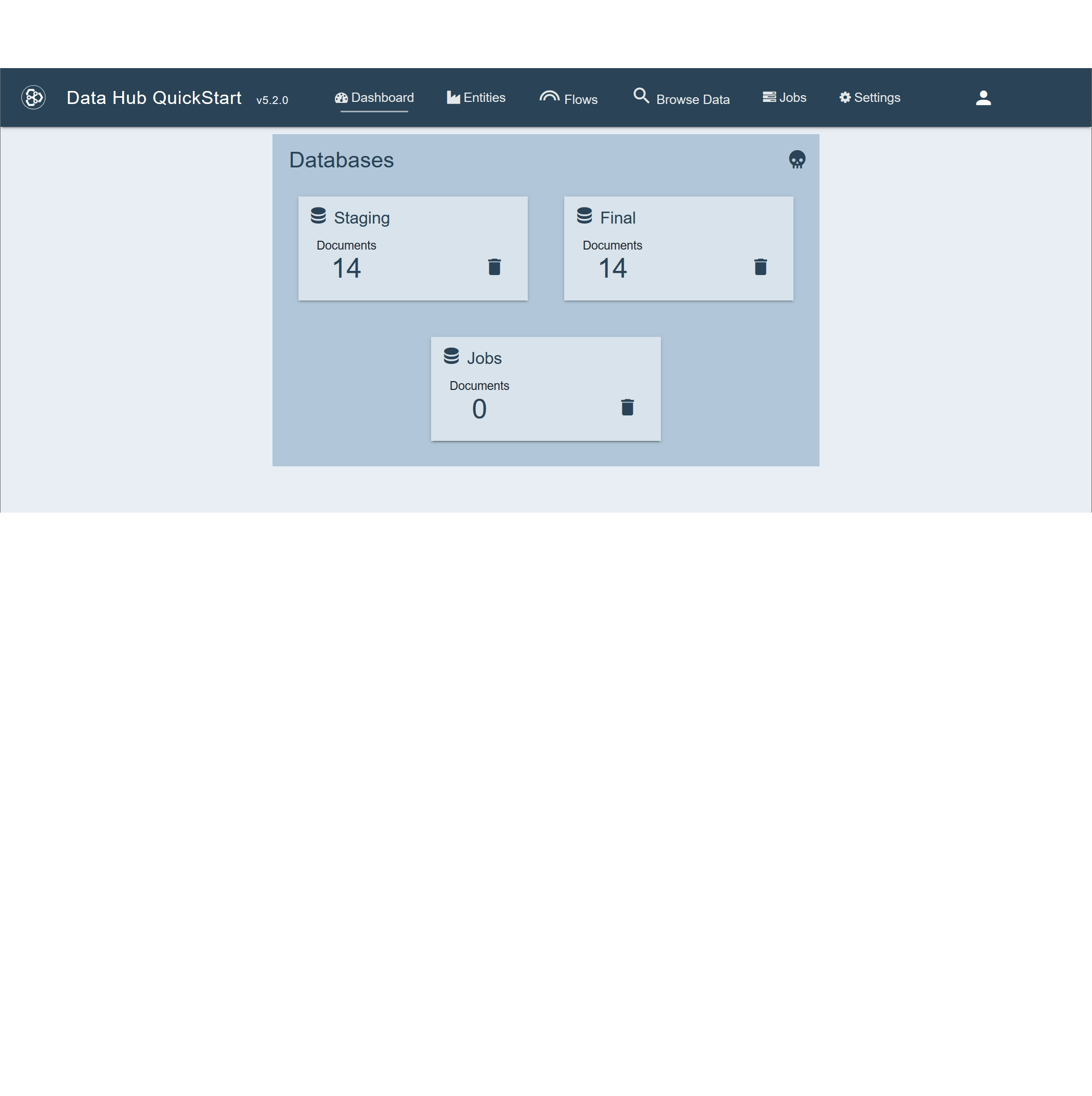
When installation is complete, the Dashboard page displays the three initial databases and the number of records in each.
- Staging holds ingested data.
- Final holds processed data.
- Jobs holds data about the jobs that are run and tracing data about each processed record.
The STAGING and FINAL databases are prepopulated with default steps and flows.