Create a Step Using QuickStart
Before you begin
You need:
- Java SE JDK 8 or later
- MarkLogic Server (See Version Compatibility.)
- Chrome or Firefox for QuickStart
About this task
Procedure
- Navigate to the flow definition of the flow you want.
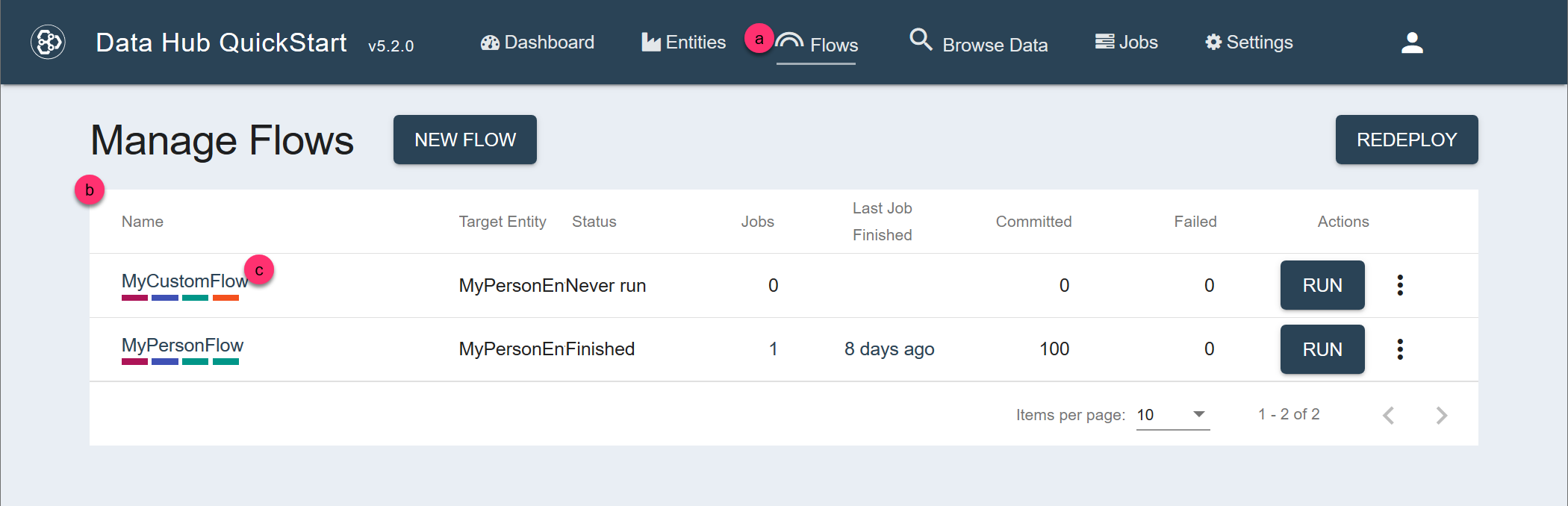
- In the flow definition page, click .
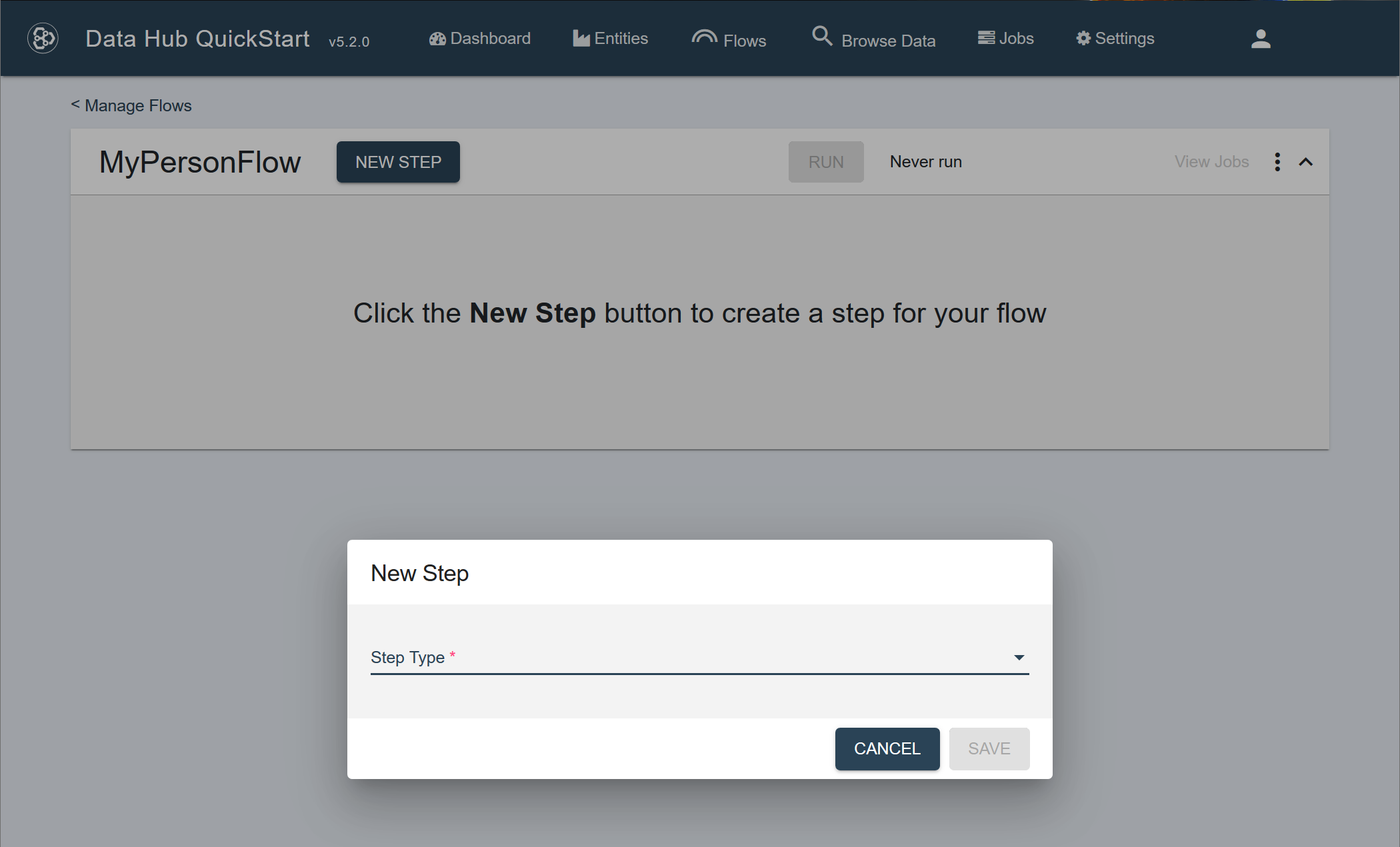
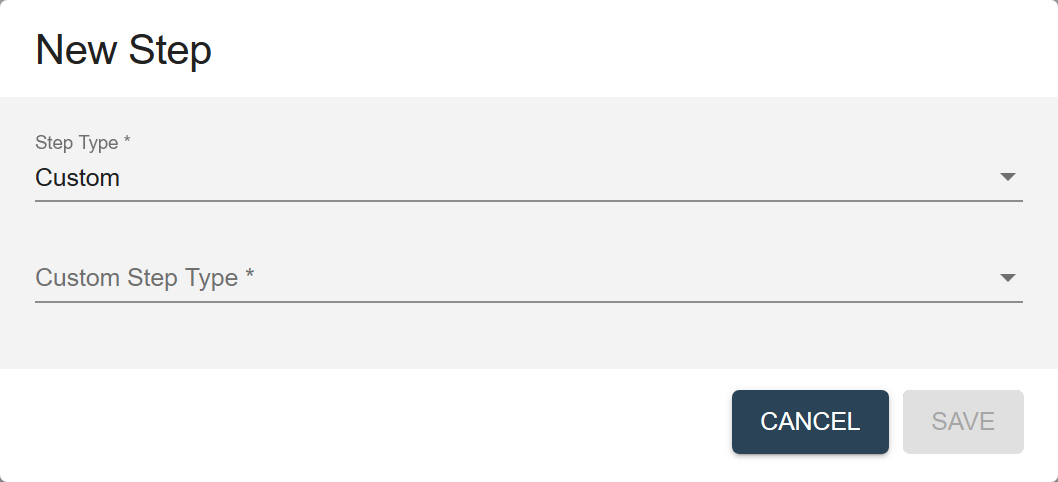
- If you select Custom, also choose the Custom Step Type.
The Custom Step Type can be Ingestion, Mapping, Mastering, or Other. The custom step type provides a more specific step definition with default settings.
- Configure the step settings.
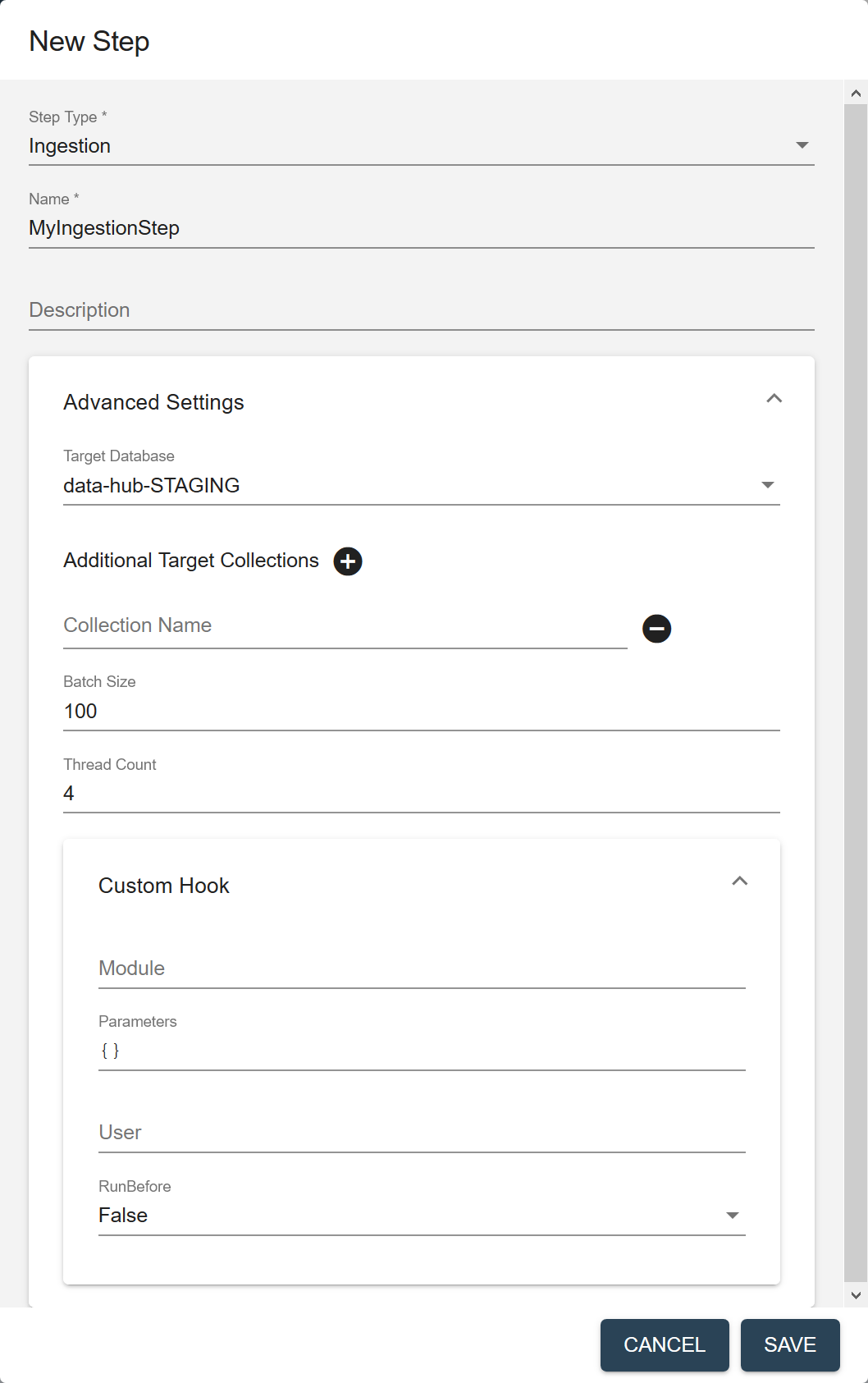
Field Description Name The name of the step instance. Description (Optional) A description of the step. Target Database The database where to store the processed data. Choose the STAGING database where you want to store the ingested data. Default is data-hub-STAGING.Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. 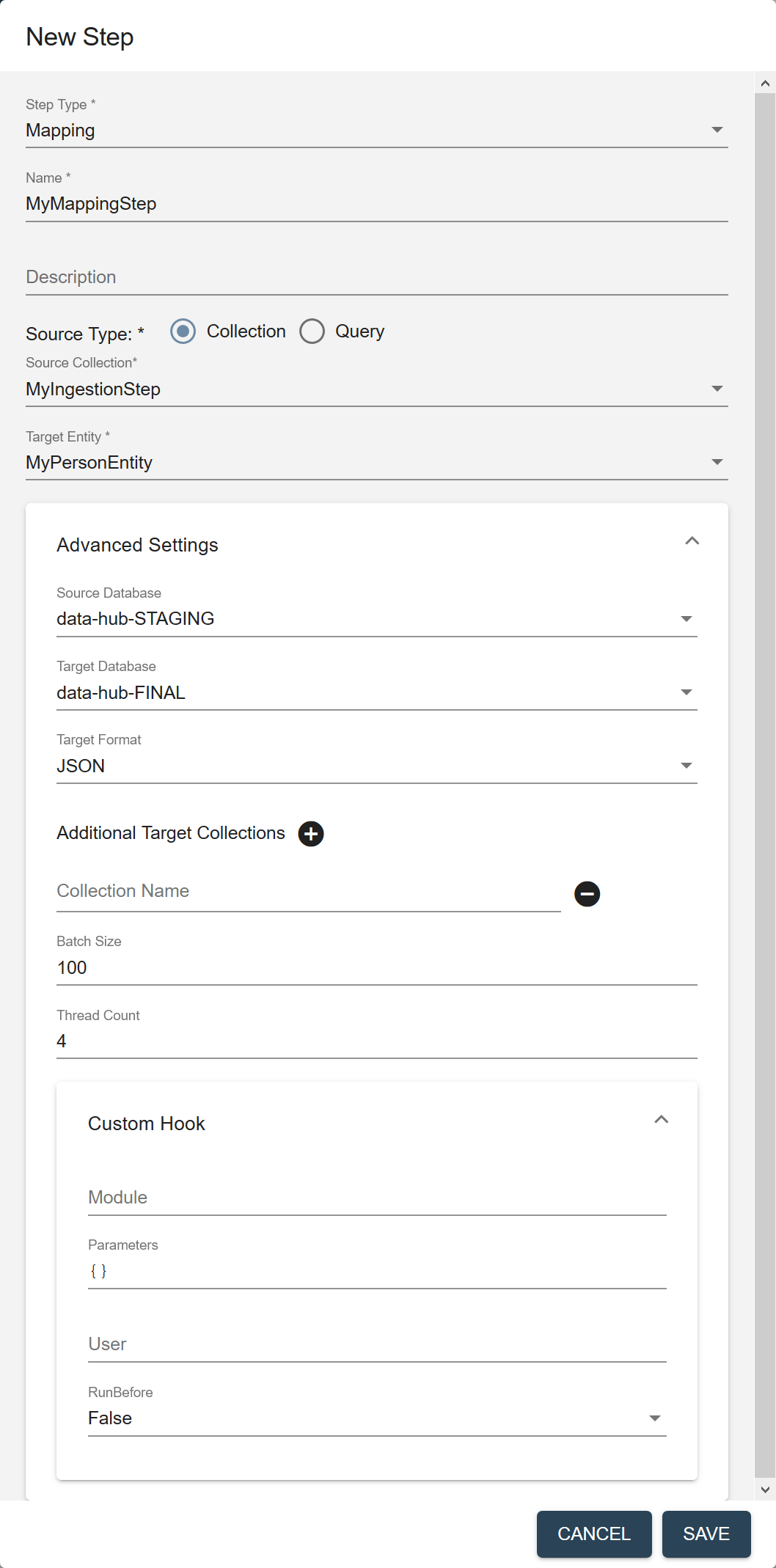
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. Choose the STAGING database where you stored ingested data. Default is data-hub-STAGING.Target Database The database where to store the processed data. Choose the FINAL database where you want to store mapped data. Default is data-hub-FINAL.Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. 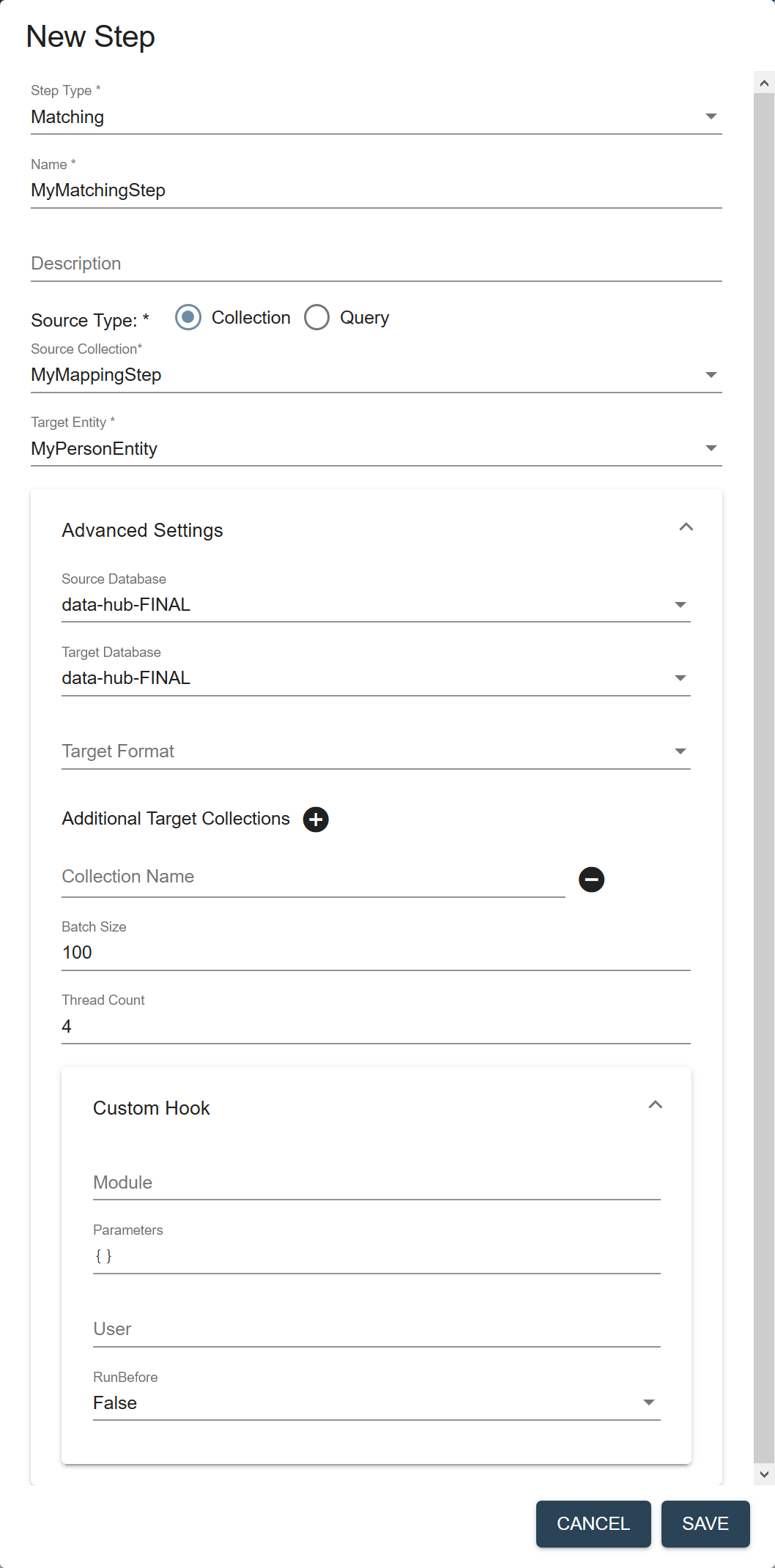
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. Choose the FINAL database where you stored mapped data. Default is data-hub-FINAL.Target Database The database where to store the processed data. Choose the same database you selected in Source Database. Default is
data-hub-FINAL.Important: For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. 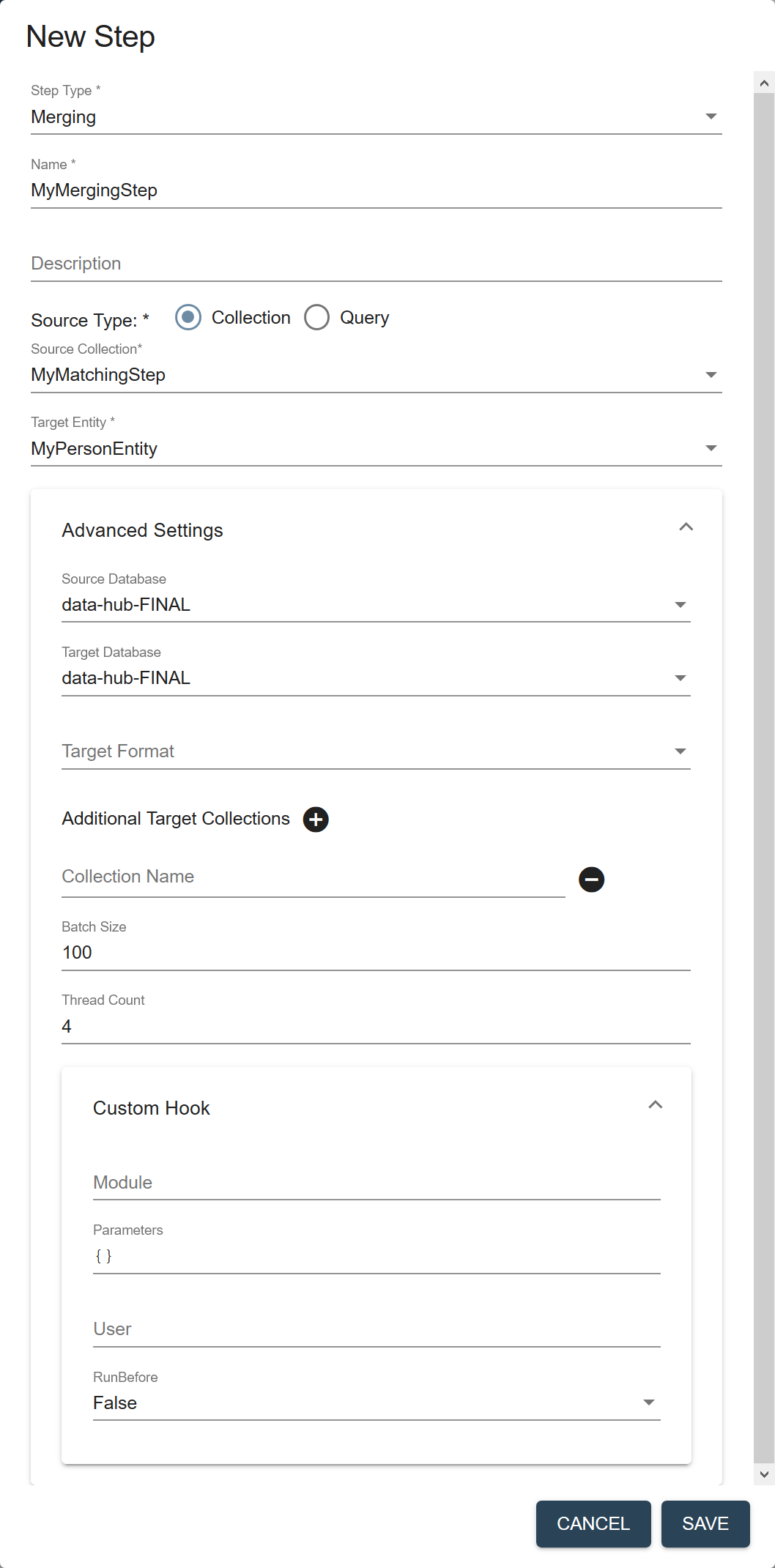
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. Choose the same source database that you selected in the matching step. Default is data-hub-FINAL.Target Database The database where to store the processed data. Choose the same database you selected in Source Database. Default is
data-hub-FINAL.Important: For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. 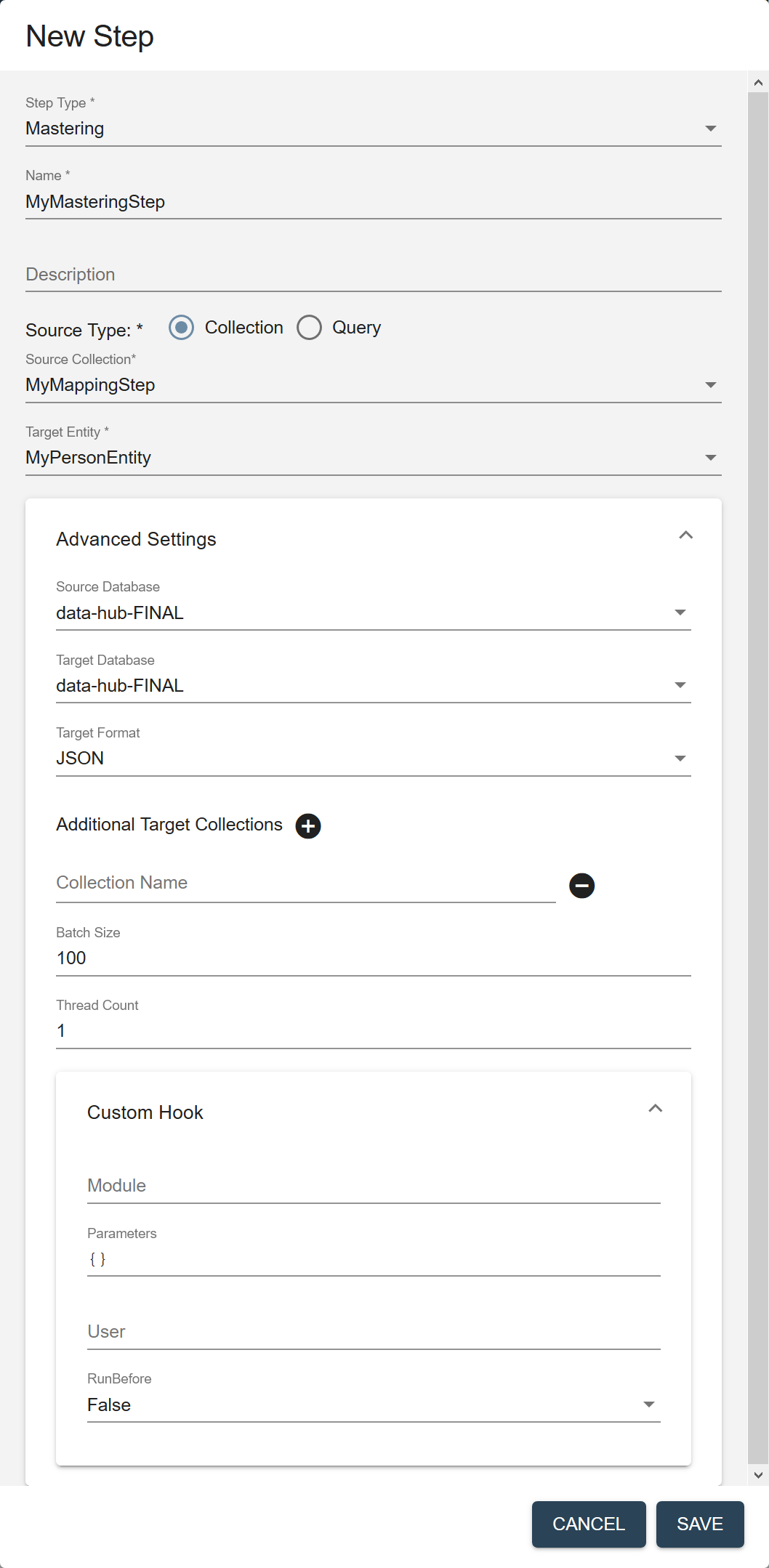
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. Choose the FINAL database where you stored mapped data. Default is data-hub-FINAL.Target Database The database where to store the processed data. Choose the FINAL database where you want to store mastered data. Default is
data-hub-FINAL.Important: For combined mastering (mastering step), the source database and the target database should be the same. If duplicates are found, the original records are archived and the merged version is added to the same database. If you want the target database to be different, you can create a custom step with a custom module to override the default behavior of the mastering step.Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. For a mastering step, this must be 1. To use more threads for improved performance, create a matching step and a merging step, instead of a mastering step. Default is 1.Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. 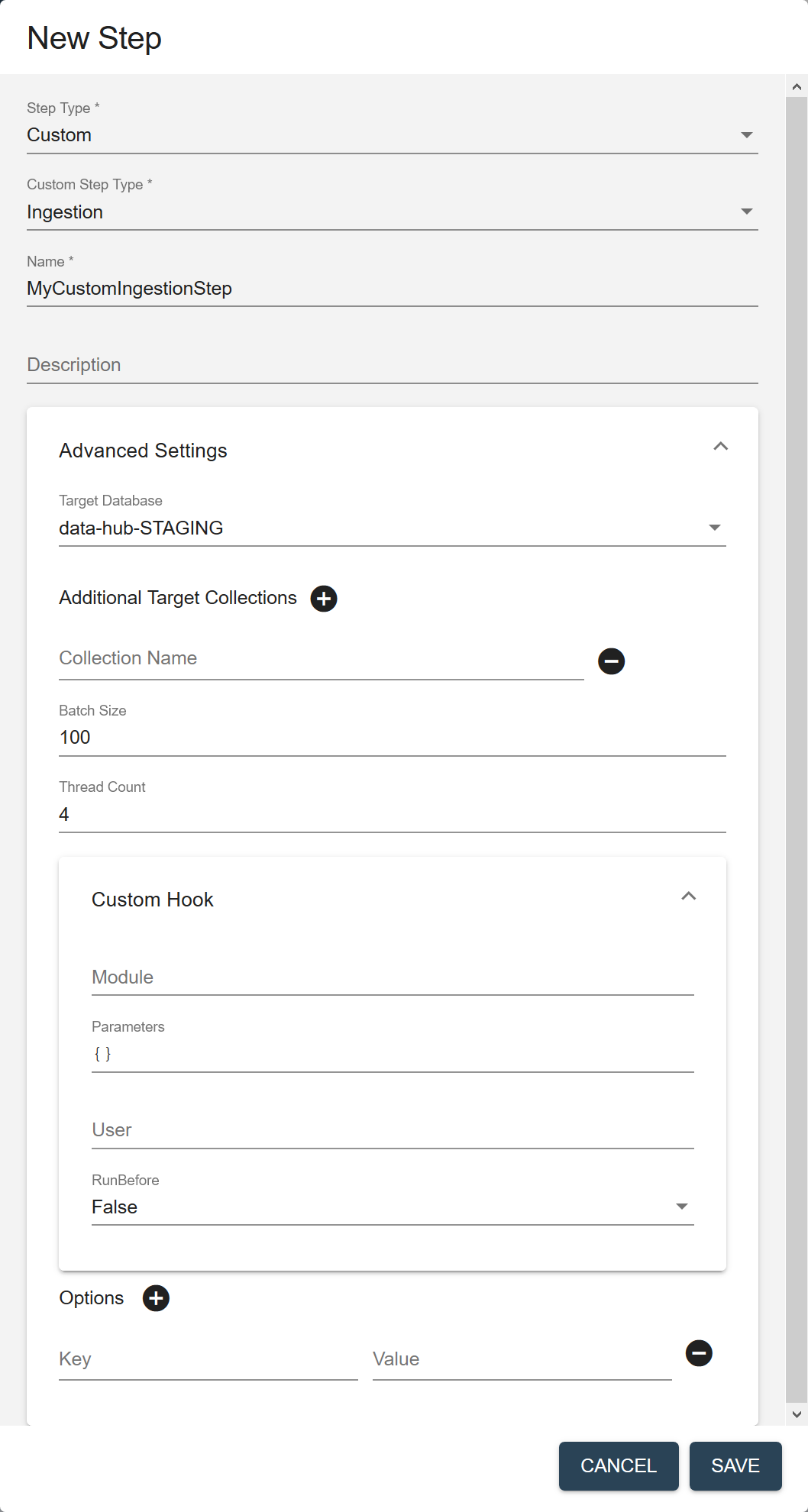
Field Description Name The name of the step instance. Description (Optional) A description of the step. Target Database The database where to store the processed data. - Choose the STAGING database where you want to store the ingested data. Default is
data-hub-STAGING. - Choose the FINAL database where you want to store mapped data. Default is
data-hub-FINAL. - Choose the FINAL database where you want to store mastered data. Default is
data-hub-FINAL.
Important:For combined mastering (mastering step), the source database and the target database should be the same. If duplicates are found, the original records are archived and the merged version is added to the same database. If you want the target database to be different, you can create a custom step with a custom module to override the default behavior of the mastering step.
For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.
Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. Options Key-value pairs to pass as parameters to custom modules in every step in the flow. 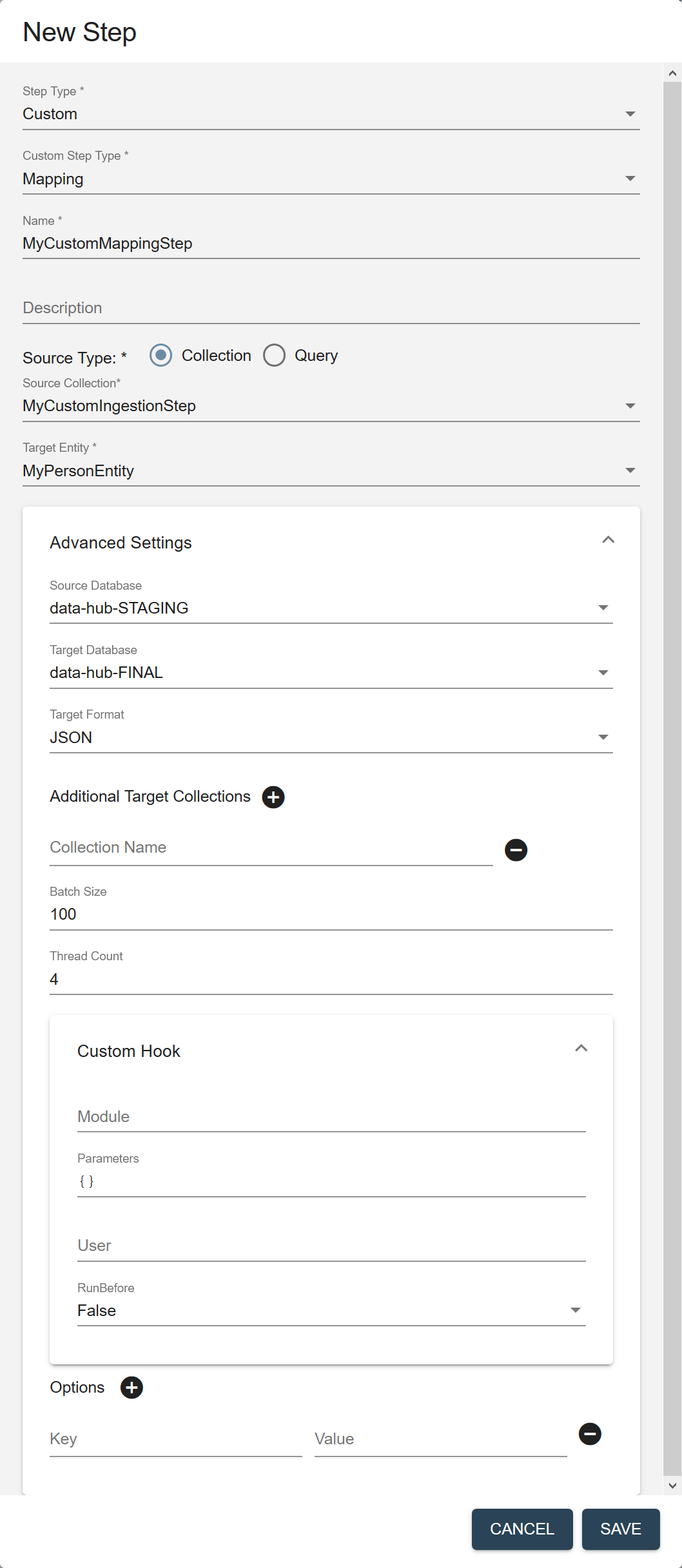
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. - Mapping: Choose the STAGING database where you stored ingested data. Default is
data-hub-STAGING. - Mastering: Choose the FINAL database where you stored mapped data. Default is
data-hub-FINAL.
Target Database The database where to store the processed data. - Choose the STAGING database where you want to store the ingested data. Default is
data-hub-STAGING. - Choose the FINAL database where you want to store mapped data. Default is
data-hub-FINAL. - Choose the FINAL database where you want to store mastered data. Default is
data-hub-FINAL.
Important:For combined mastering (mastering step), the source database and the target database should be the same. If duplicates are found, the original records are archived and the merged version is added to the same database. If you want the target database to be different, you can create a custom step with a custom module to override the default behavior of the mastering step.
For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.
Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. Options Key-value pairs to pass as parameters to custom modules in every step in the flow. 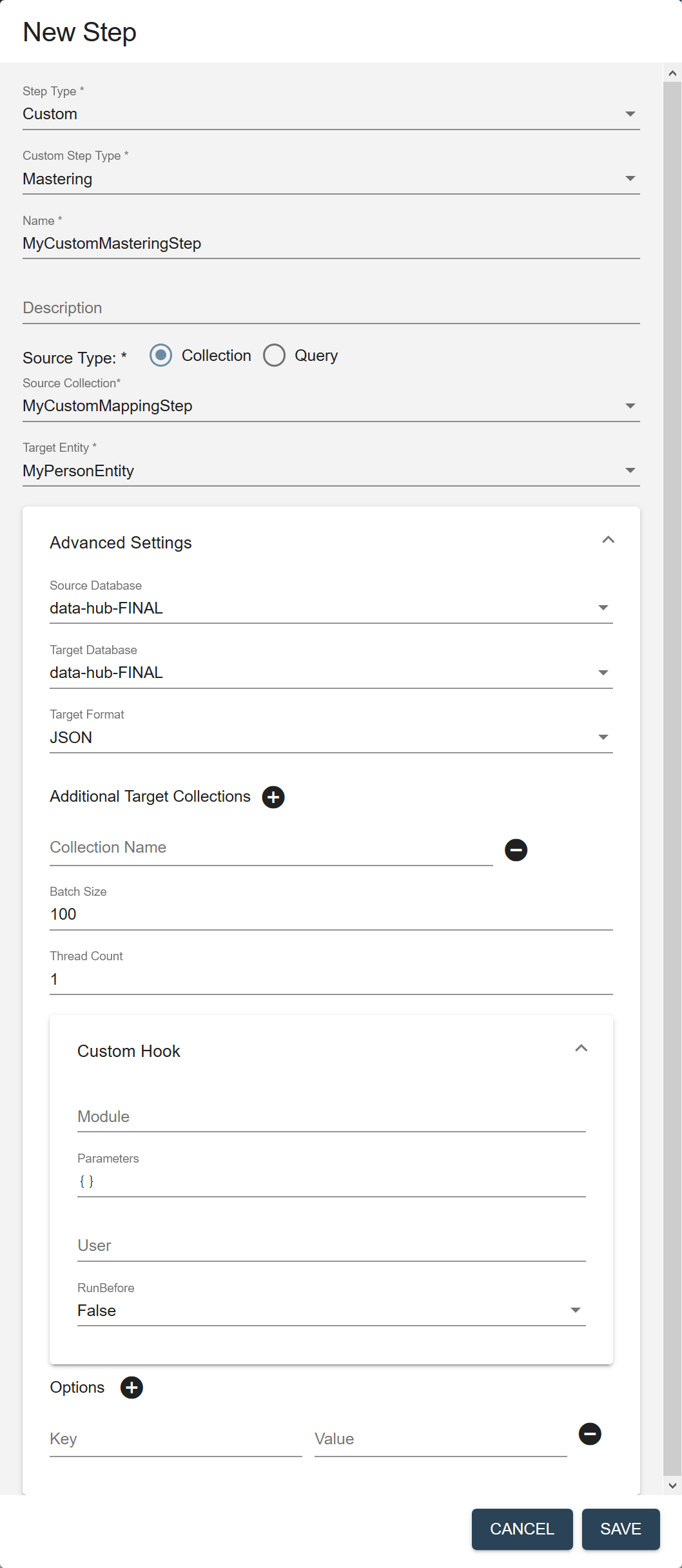
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. - Mapping: Choose the STAGING database where you stored ingested data. Default is
data-hub-STAGING. - Mastering: Choose the FINAL database where you stored mapped data. Default is
data-hub-FINAL.
Target Database The database where to store the processed data. - Choose the STAGING database where you want to store the ingested data. Default is
data-hub-STAGING. - Choose the FINAL database where you want to store mapped data. Default is
data-hub-FINAL. - Choose the FINAL database where you want to store mastered data. Default is
data-hub-FINAL.
Important:For combined mastering (mastering step), the source database and the target database should be the same. If duplicates are found, the original records are archived and the merged version is added to the same database. If you want the target database to be different, you can create a custom step with a custom module to override the default behavior of the mastering step.
For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.
Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. Options Key-value pairs to pass as parameters to custom modules in every step in the flow. 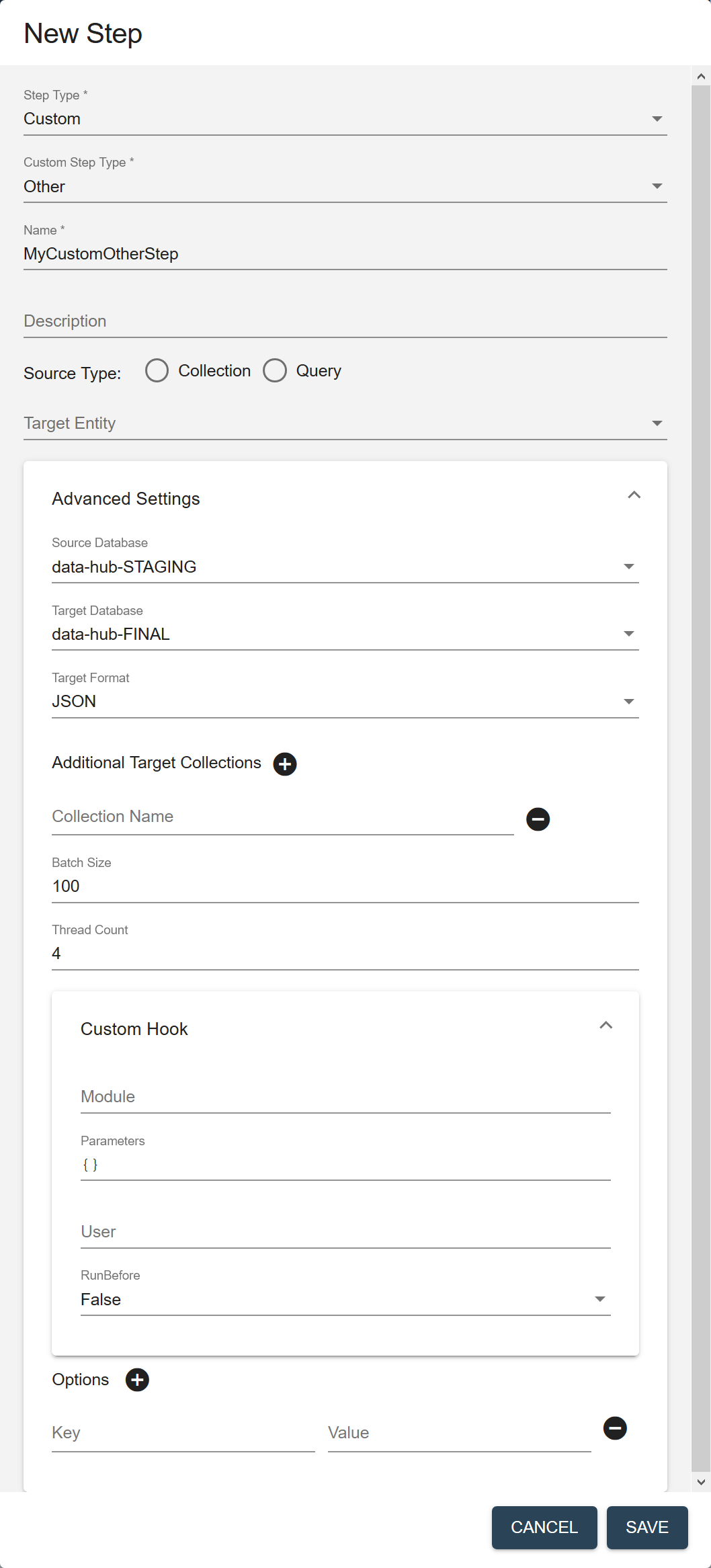
Field Description Name The name of the step instance. Description (Optional) A description of the step. Source Type The filter to use to select the source data to process in this flow. - Collection
- Query
Source Collection (Displayed if Source Type is Collection.) The collection tag to use to search for the records to process in this step. Source Query (Displayed if Source Type is Query.) The CTS query to use to select the source data to process. See CTS Query. Target Entity The entity to map against the source data. Required only if the flow includes a mapping step. Source Database The database from which to take the input data. - Mapping: Choose the STAGING database where you stored ingested data. Default is
data-hub-STAGING. - Mastering: Choose the FINAL database where you stored mapped data. Default is
data-hub-FINAL.
Target Database The database where to store the processed data. - Choose the STAGING database where you want to store the ingested data. Default is
data-hub-STAGING. - Choose the FINAL database where you want to store mapped data. Default is
data-hub-FINAL. - Choose the FINAL database where you want to store mastered data. Default is
data-hub-FINAL.
Important:For combined mastering (mastering step), the source database and the target database should be the same. If duplicates are found, the original records are archived and the merged version is added to the same database. If you want the target database to be different, you can create a custom step with a custom module to override the default behavior of the mastering step.
For split mastering (matching step and merging step), both the source database and the target database for both steps must be the same.
Target Format The format of the processed record: Text, JSON, XML, or Binary. Default is JSON. Additional Target Collections Collection tags to add to the processed records. By default, the processed records are added to the collection with the same name as the step. You can add the records to additional collections by specifying one or more collection tags. - Click to add more collection tags.
- Click next to a collection tag to delete it.
Batch Size The number of documents to process per batch. Each batch goes through all the steps in a flow before the next batch starts. A smaller batch size gives you flexibility to stop the processing and tweak your modules before continuing with the rest of your data. A smaller batch size also provides finer granularity in the jobs reporting. However, a smaller batch file also costs more because of the processing overhead. Must be 1 or more. Default is 100. Thread Count The number of threads to use when running a flow. Default is 4. Custom Hook: Module The path to your custom hook module. Custom Hook: Parameters Parameters, as key-value pairs, to pass to your custom hook module. Custom Hook: User The user account to use to run the module. Default is the user running the flow; e.g., flow-operator.Custom Hook: RunBefore For a pre-step hook, set to true. For a post-step hook, set to false. Options Key-value pairs to pass as parameters to custom modules in every step in the flow.
Results
The new step's summary box is added to the flow sequence in the flow panel at the top.
The step panels show the step details.
What to do next
Configure the step details: