QuickStart Tutorial for Data Hub 5.x
Overview
- The Advantage dataset is comprised of JSON files.
- The Bedrock dataset is comprised of a single CSV file.
Most of the customer data fields are essentially the same; however, the field names are different. For example, Advantage has FirstName, whereas Bedrock has first_name. In addition, Advantage has a Phone field, but Bedrock does not have an equivalent field. You will define the entity model which will serve as the standard, and then map the source fields to the entity properties.
Finally, one or more records in the combined set might be duplicates. Therefore, you will set up a mastering step that defines the criteria for what is considered a duplicate and the actions to be taken if those criteria (thresholds) are met (exceeded).
Before you begin
You need:
- Java SE JDK 8
- MarkLogic Server (See Version Compatibility.)
- Gradle 4.6 or later
- Chrome or Firefox for QuickStart
About this task
Procedure
- In QuickStart, create an entity.
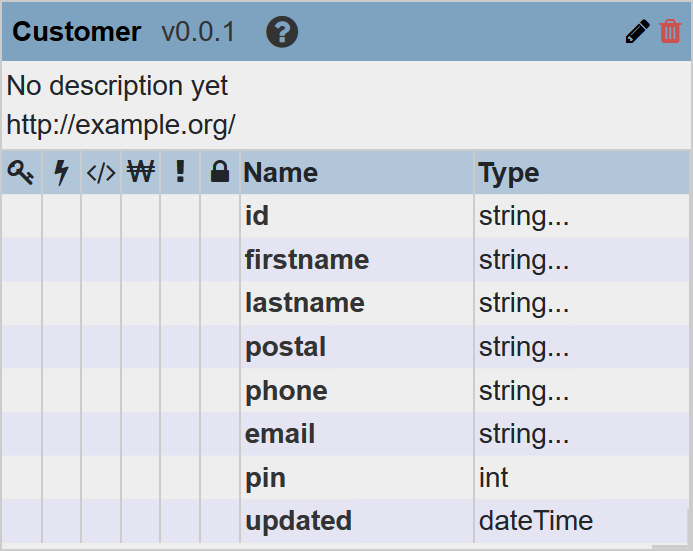
- Ingest and map the Advantage data.
-
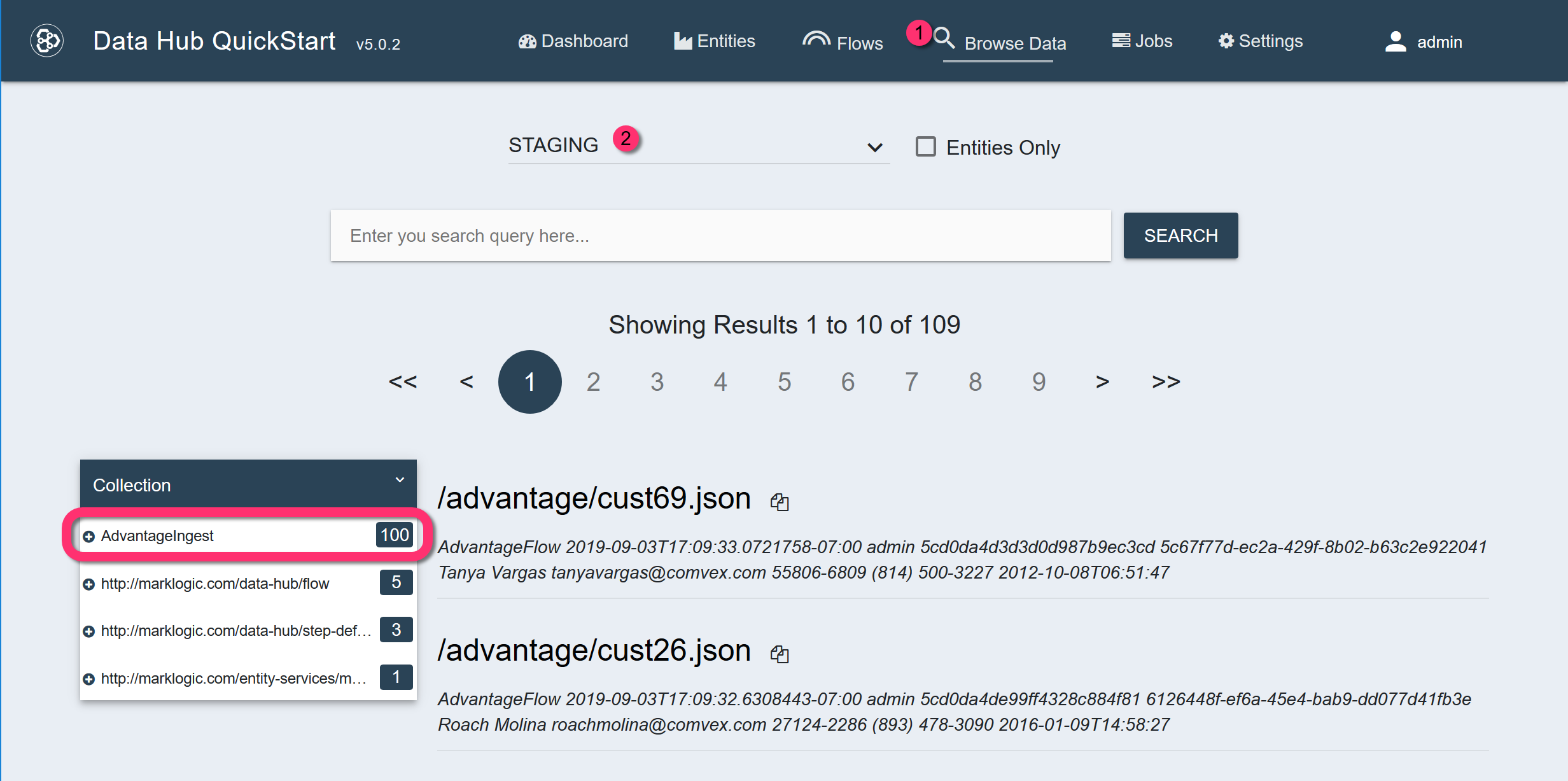
Run the flow to ingest the data.
The STAGING database will contain 100 JSON documents in the AdvantageIngest collection.
-
Map the source fields to the entity properties.
Source Fields Entity Properties CustomerID id FirstName firstname LastName lastname Postal postal Phone phone Email email PIN pin Updated updated View the mapping page.
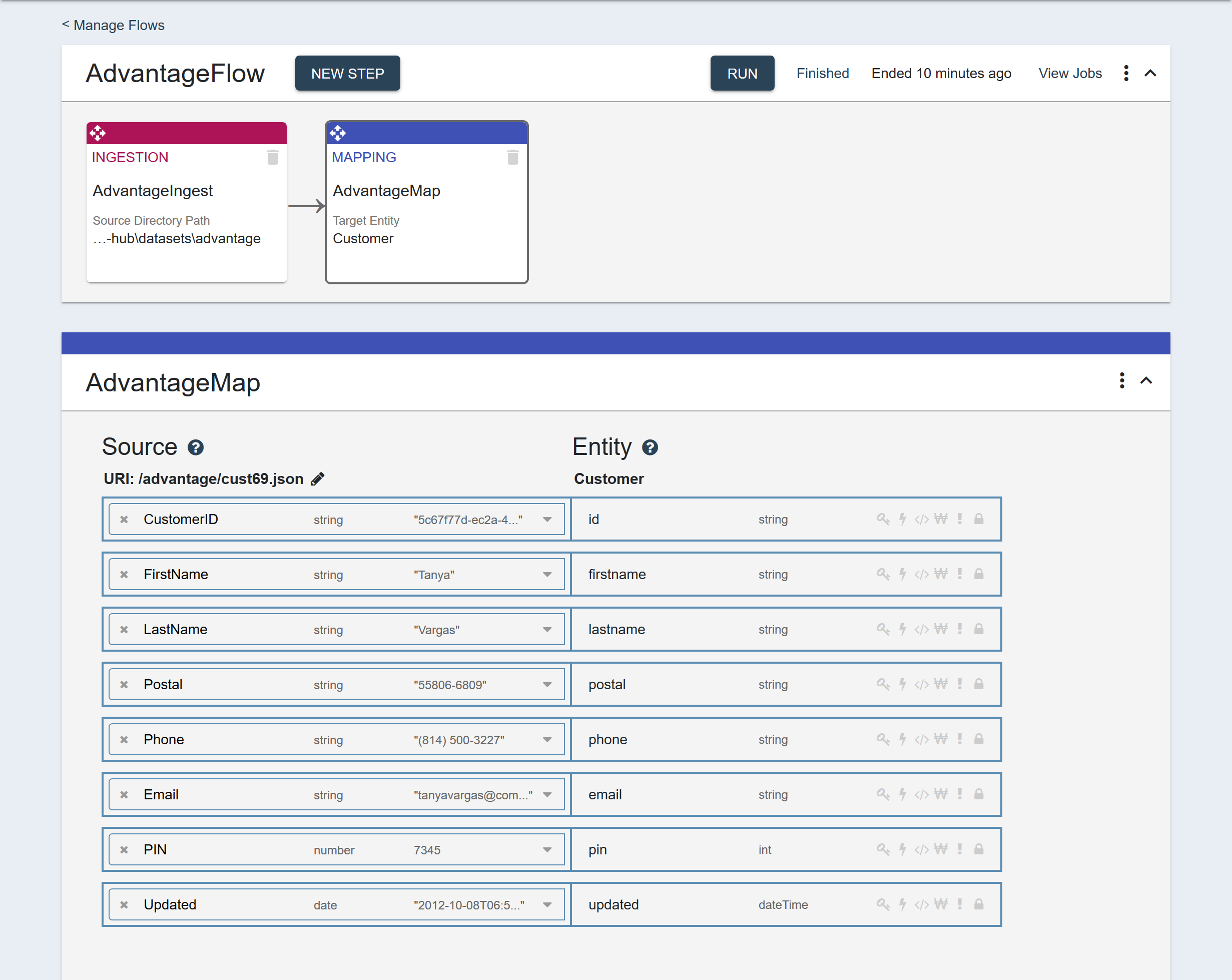
-
Run the flow, but select only the mapping step.
Because the flow includes both the ingestion step and the mapping step, running the complete flow will ingest the same documents again. If you have not made changes to any of the documents, then you can safely rerun the ingestion. The second run will simply overwrite the documents ingested in the first run.
The FINAL database will contain 100 mapped documents in the AdvantageMap collection. Each document or record will have an instance of the Customer entity.
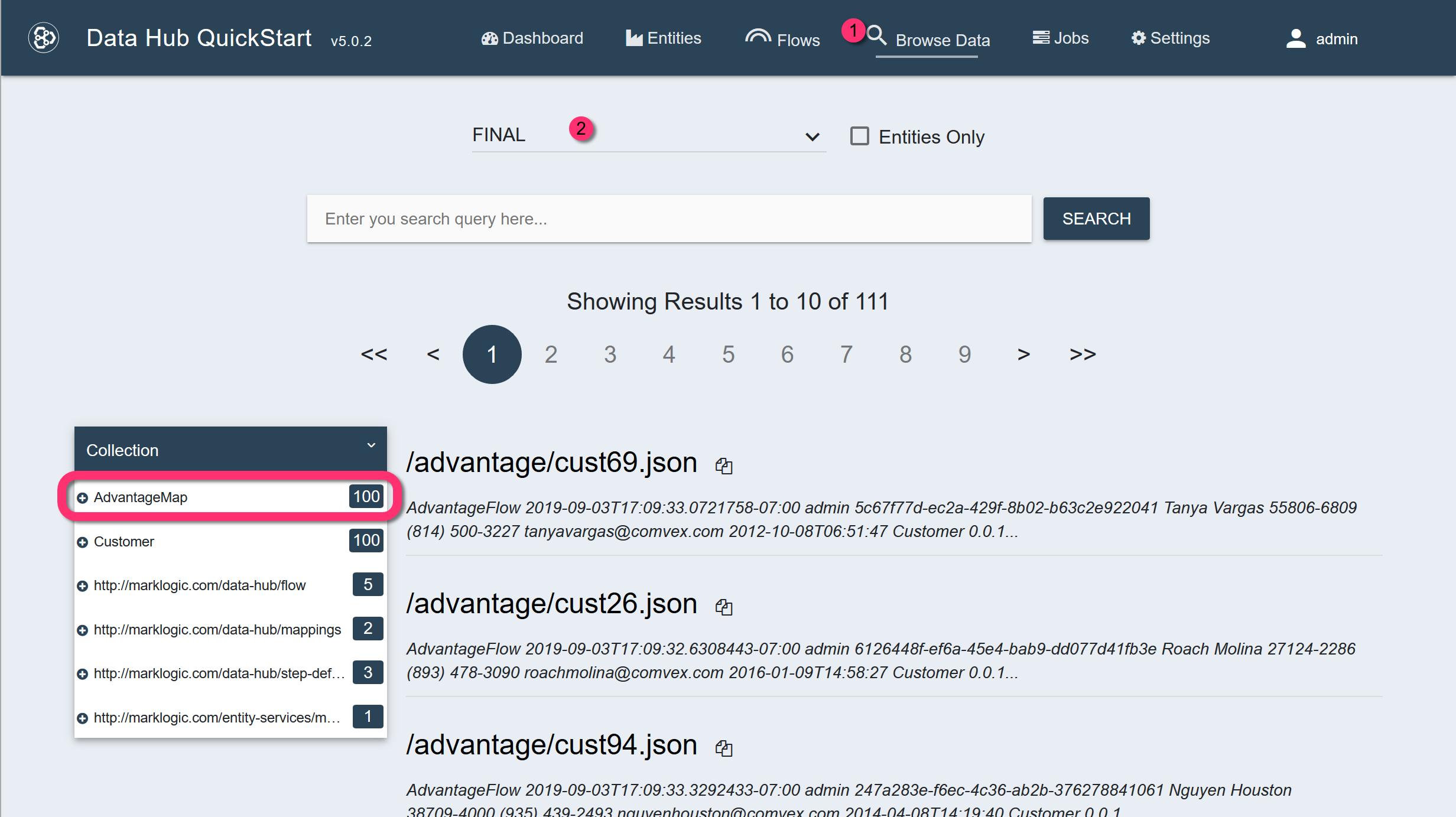
In the resulting record:$.envelope.instancecontains the mapped information, using the Customer entity's properties.$.envelope.attachments.envelope.instancecontains the original ingested data, using the source field names.
View the contents of an example mapped record.
{ "envelope": { "headers": {...}, "triples": [], "instance": { "Customer": { "id": "0881e206-a488-4f6d-a09b-ff18ed412998", "firstname": "Oneal", "lastname": "Banks", "postal": "43130-7986", "phone": "(913) 462-2899", "email": "onealbanks@comvex.com", "pin": 6880, "updated": "2018-02-10T19:54:20" }, "info": {...} }, "attachments": { "envelope": { "headers": {...}, "triples": [], "instance": { "ObjectID": { "$oid": "5cd0da4d857d8461bec88893" }, "CustomerID": "0881e206-a488-4f6d-a09b-ff18ed412998", "FirstName": "Oneal", "LastName": "Banks", "Email": "onealbanks@comvex.com", "Postal": "43130-7986", "Phone": "(913) 462-2899", "PIN": 6880, "Updated": "2018-02-10T19:54:20" }, "attachments": null } } } }
-
Run the flow to ingest the data.
- Ingest and map the Bedrock data.
-
Run the flow to ingest the data.
The STAGING database will contain 100 JSON documents in the BedrockIngest collection.
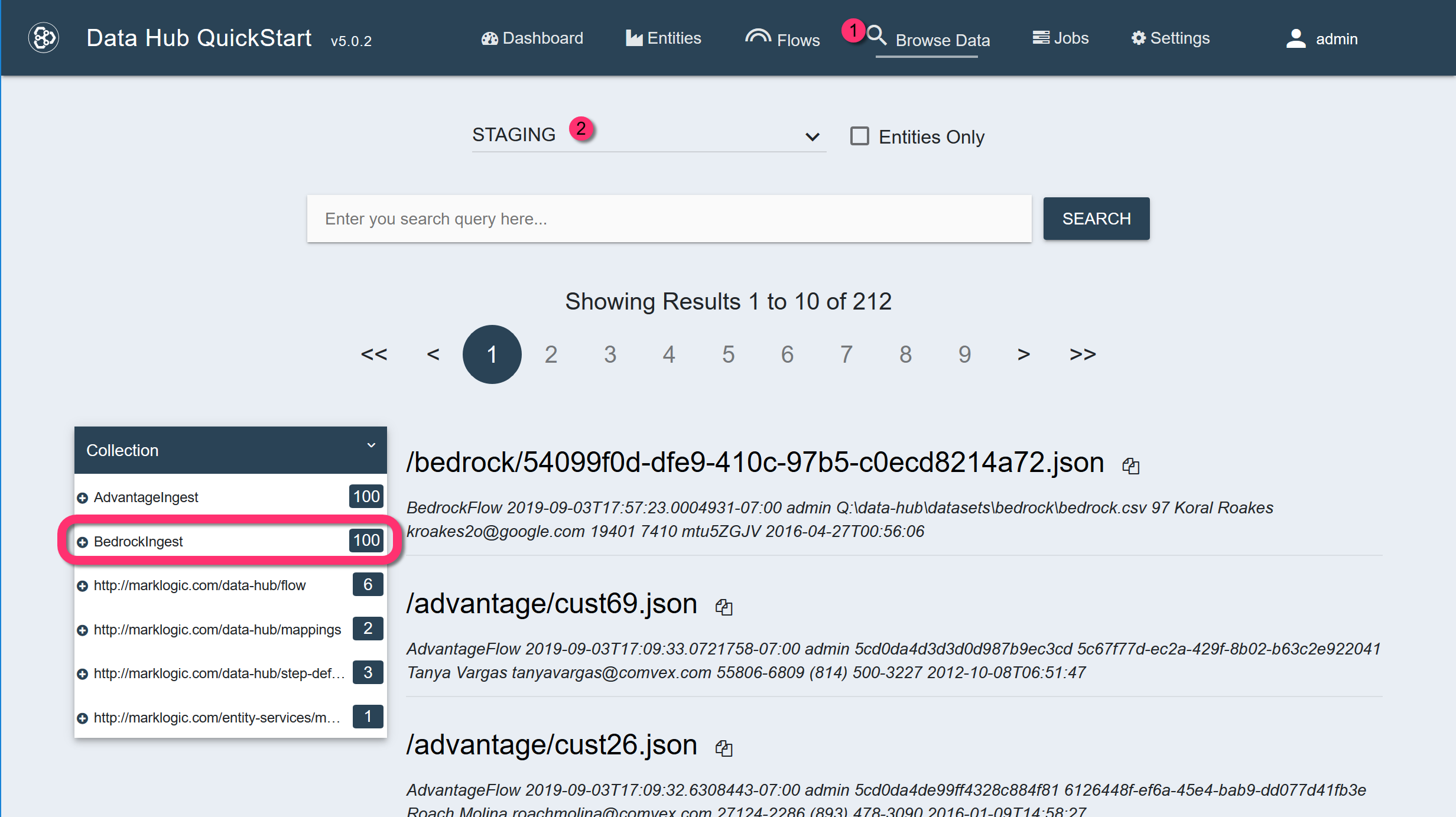
-
Run the flow, but select only the mapping step.
The FINAL database will contain 100 mapped documents in the BedrockMap collection. Each document or record will have an instance of the Customer entity.
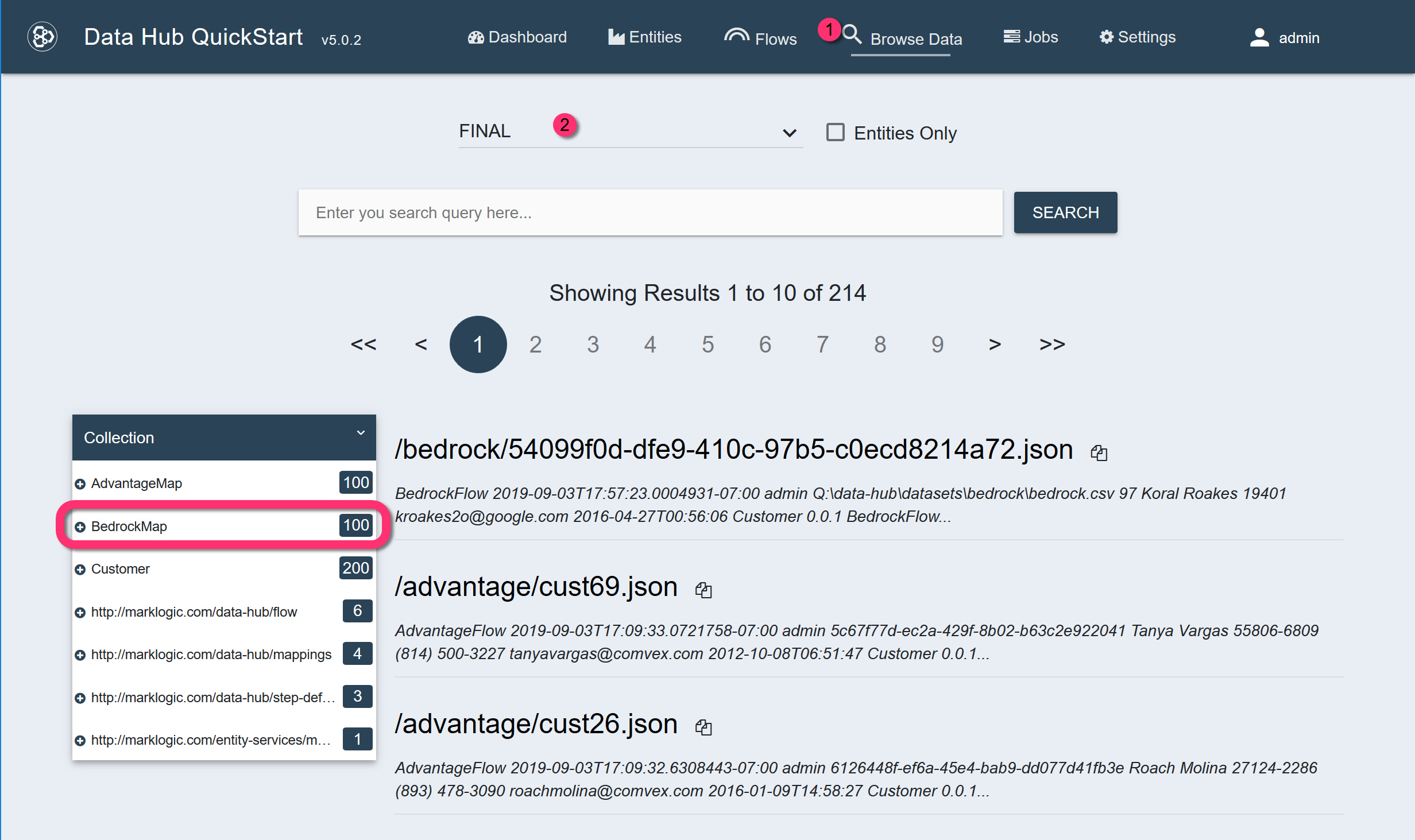
-
Run the flow to ingest the data.
- Find and merge duplicate records.
- Configure the mastering step.
The mastering step is comprised of two sets of options:
- The match options specify how to compare two records. Assigned weights indicate the degree of similarity between the records.
- The merge options specify how to combine two or more records when the sum of the weights exceed a threshold.
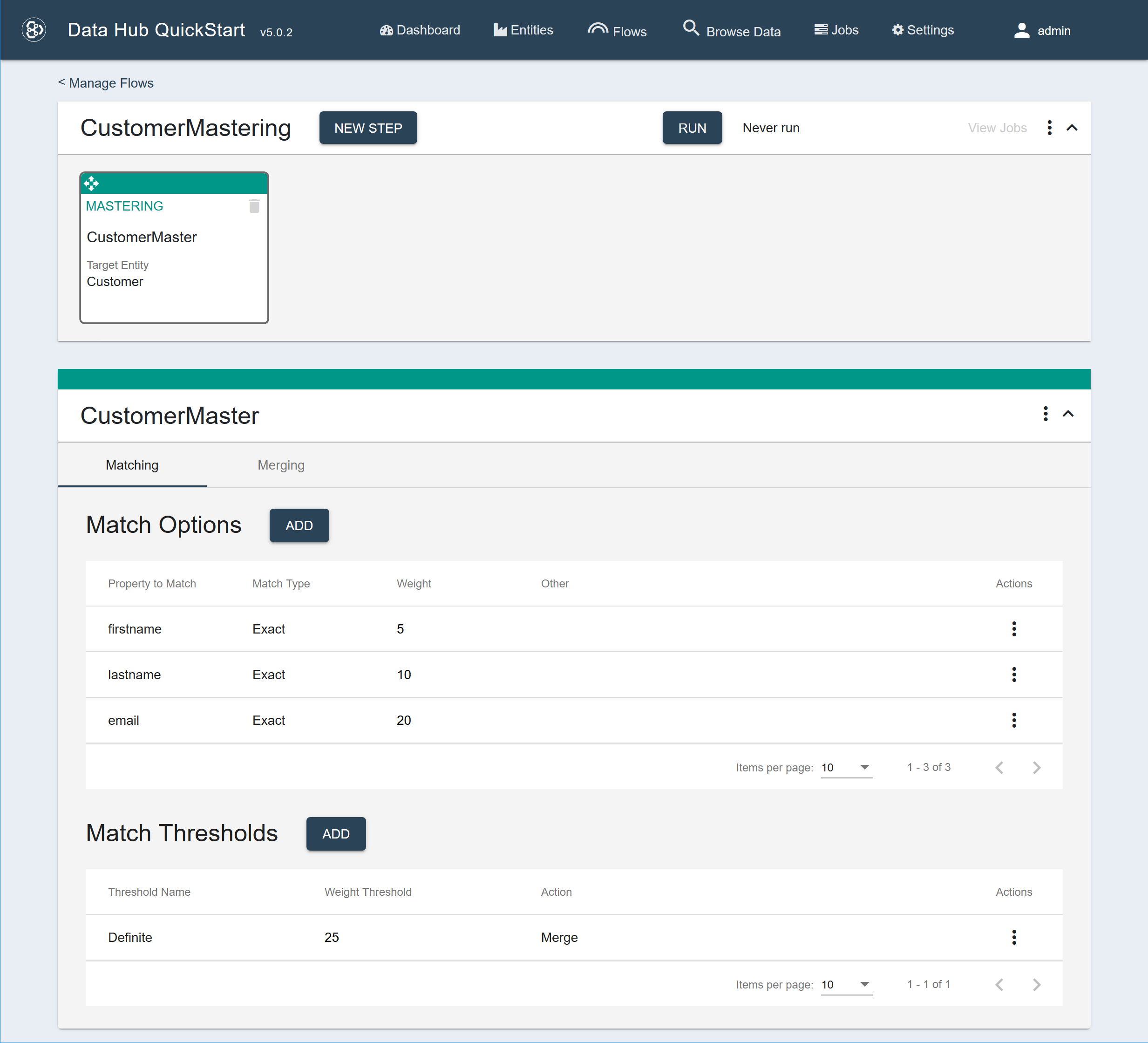
- Add the following match options:
Match Type Property to Match Weight Exact firstname 5 Exact lastname 10 Exact email 20 - Add the following match threshold:
Field Value Name Definite Weight Threshold 25 Action Merge The weights are used to produce a score that is compared with the match thresholds. In this example, if the comparison score meets or exceeds 25 (Weight Threshold), the matching records will be merged (Action). Based on the weights assigned to the match options, this threshold can be exceeded if:- the email matches and the firstname matches (weights: 20 + 5 = 25)
- the email matches and the lastname matches (weights: 20 + 10 = 30)
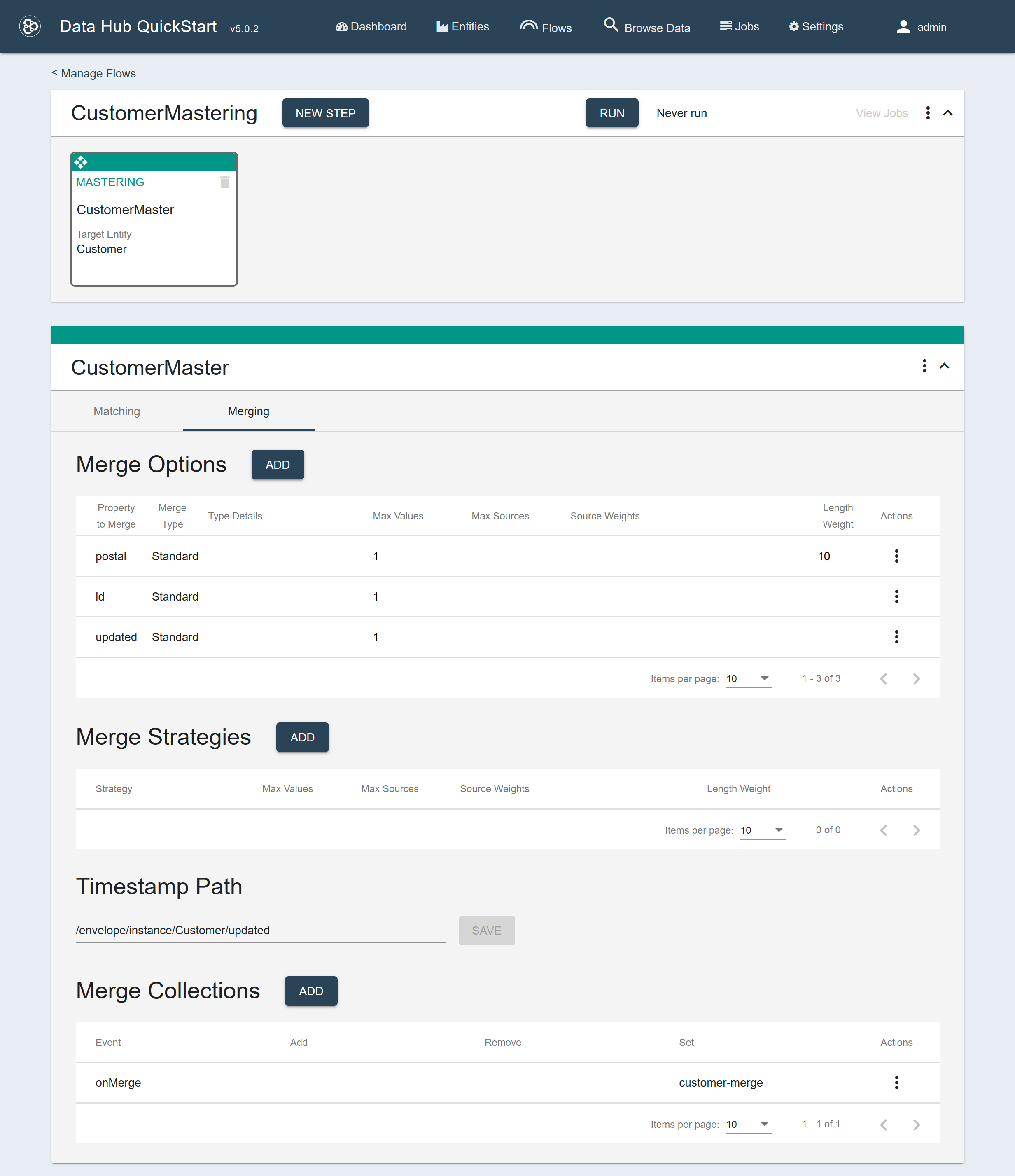
- Add the following merge options:
Merge Type Property Max Values Length Weight Standard postal 1 10 Standard id 1 Standard updated 1 These merge options ensure that a merged record would have only one value for each of the specified properties. The length weight for the postal property causes the longer 9-digit postal codes to be preferred over the 5-digit postal codes. - Set Timestamp to /envelope/instance/Customer/updated.
This sorts the matching records in reverse chronological order (newest first) based on the value of the property found at the given timestamp path.
- Add the following merge collection:
Event Collections to Set onMerge customer-merge
-
Run the flow to merge matching records.
Two pairs of customer entities will be merged together, and the merged records will be placed in the customer-merge collection.
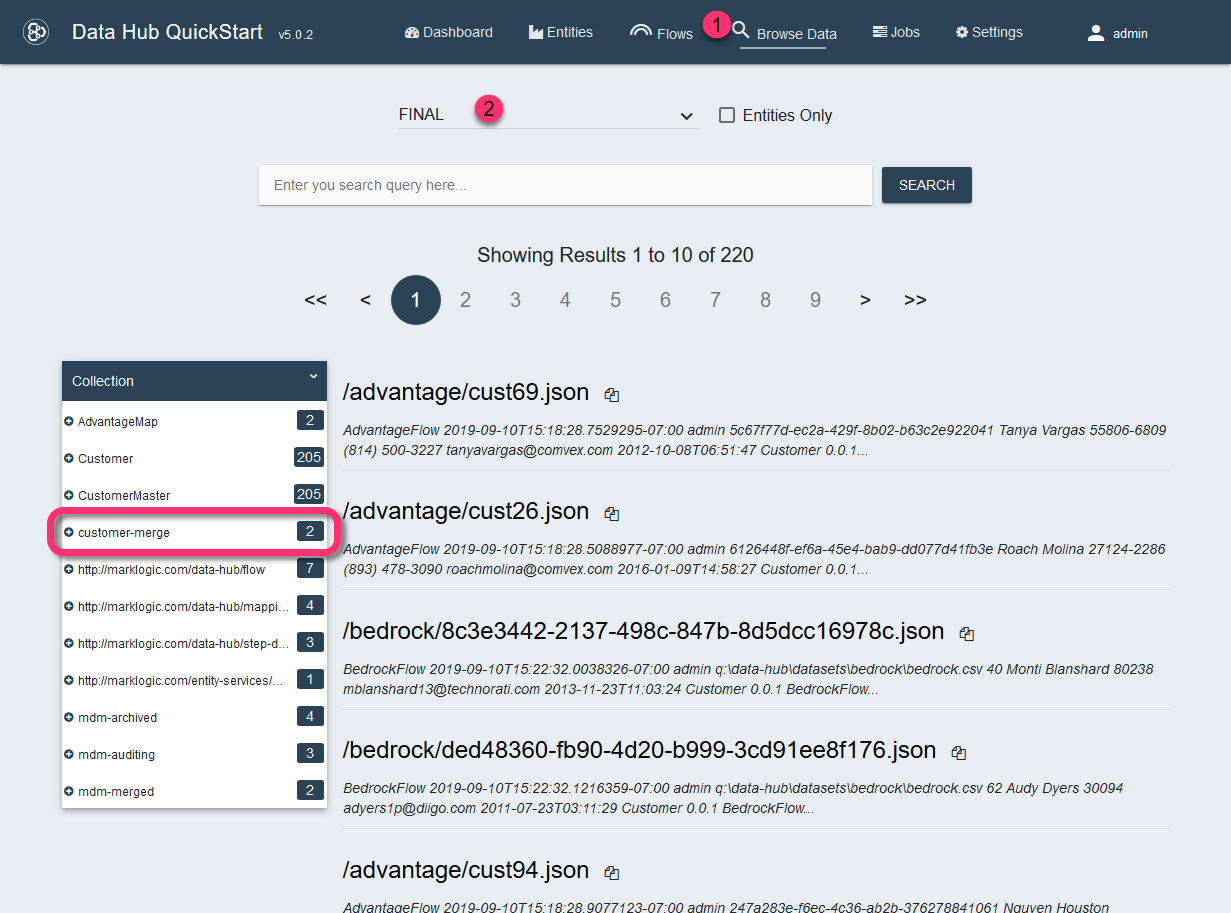
Each of the merged records would have a
$.envelope.headers.mergessection containing the URIs of the original matching records.Example merges section of a merged record
"merges": [ { "document-uri": "/advantage/cust14.json", "last-merge": "2019-09-10T15:42:03.2017696-07:00" }, { "document-uri": "/bedrock/c2288315-bb99-400d-afdb-554ef40117d3.json", "last-merge": "2019-09-10T15:42:03.2017696-07:00" } ],
- Configure the mastering step.