
MarkLogic 9 Product DocumentationOps Director Guide — Chapter 5
MANAGE View
The MANAGE view shows details for a selected MarkLogic resource or resource category in the form of charts, tables, and other displays.
The default MANAGE view displays an inventory list of resources within an enterprise. It displays the list of clusters across an enterprise, along with their key properties, in a data grid.
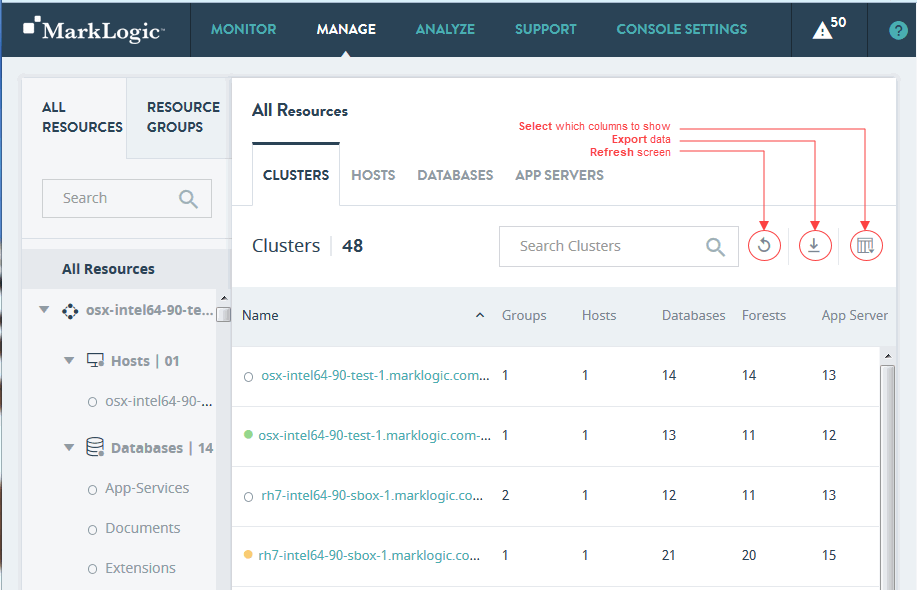
The panel on the left side is a navigation tree with scrolling lists of all resources displayed according to the object hierarchy. The title of the content area displays the object name selected in the navigation tree. For individual resources, this area displays the resource name and key information related to the resource.
The content area of this view presents content tabs in different categories for the selected object or resource. In the Enterprise case, there are four tabs, one for each resource type: CLUSTERS, HOSTS, DATABASES, and APP SERVERS. Each tab presents a table that lists the corresponding resources within the enterprise that has the resource name and status indicator in first column, followed by other properties.
This chapter covers the following topics:
Manage Clusters Tab
The CLUSTERS tab displays the list of clusters in your enterprise.

The columns displayed in the manage CLUSTERS tab are described in the following table.
You can export data from the Manage Clusters tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Manage Clusters table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
To drill down for a particular cluster, click on the cluster name in the table. You will see the following content tabs, each one representing an information category for the selected cluster:
- Cluster Metrics
- Cluster Information
- Cluster Tasks
- Cluster Logs
- Cluster Hosts
- Cluster Databases
- Cluster App Servers
- Cluster Forests
You can export all tables from the content tabs for a particular cluster. When you select a specific cluster (either in the left side resource navigation panel or in the content area of the view), Actions menu becomes available in the upper right corner.
From the Actions menu, select Download all tables to export all tables for this particular cluster.

A zip file with all exported tables for this cluster will be downloaded to your computer. Each table is represented by the corresponding CSV file. The zip file will contain the following CSV files for the cluster:
- Tasks CSV file (see the Cluster Tasks section for details on the contents)
- Hosts CVS file (see the Cluster Hosts section for details on the contents)
- Databases CVS file (see the Cluster Databases section for details on the contents)
- App Servers CVS file (see the Cluster App Servers section for details on the contents)
- Forests CVS file (see the Cluster Forests section for details on the contents)
For a cluster, exported tables will not include Logs table. This table can be exported from the Logs tab of that cluster, but not as part of the Download all tables operation.
Cluster Metrics
METRICS is the first tab displayed for any resource type. This tab displays key indicators enabling you to determine the health of the selected resource.
To filter the data used for rendering the graphs, select a pre-defined time period or specify a custom time period, as described in Date and Time Filters.

The metrics displayed by charts on the cluster METRICS tab are described in the following table.
| Chart | Definition of Displayed Metric |
|---|---|
| Disk I/O | Disk I/O in MB per second. For descriptions of the lines displayed on this graph, see Disk Performance Data. |
| App Server Request Rate | The total number of queries being processed per second, across all of the App Servers in the cluster. For descriptions of the lines displayed on this graph, see Server Performance Data. |
| App Server Latency | The average time (in seconds) it takes to process queries, across all of the App Servers in the cluster. For descriptions of the lines displayed on this graph, see Server Performance Data. |
| CPU | The aggregate I/O performance data for the CPUs in the cluster. For descriptions of the lines displayed on this graph, see CPU Performance Data. |
| Memory Footprint | The total amount (in MB) of memory consumed by all of the hosts in the cluster. |
| Memory Size | The amount of space (in MB) forest data files in this cluster use in memory. |
| Memory I/O | The number of pages per second moved between memory and disk.
For more information, see Memory Performance Data. |
| Network | Various XDQP (XML Data Query Protocol) performance metrics, such as the sum of XDQP activity across the cluster. XDQP is a MarkLogic internal protocol used for communication between nodes in a cluster. For more detail, see Network Performance Data. |
Cluster Information
Use the INFORMATION tab to access properties of the selected cluster.
The properties displayed in the cluster INFORMATION tab are described in the following table.
| Field | Description |
|---|---|
| Bootstrap Host | The connection attributes for the bootstrap host on this cluster.
For details, see Bootstrap Hosts in the Concepts Guide. |
| Cluster ID | The ID used to identify this cluster. |
| Cluster Name | The name used to identify this cluster. |
| Data Directory | The MarkLogic default data directory. For details, see Installing MarkLogic in the Installation Guide. |
| Effective Version | The effective version of MarkLogic Server that is installed on each host in this cluster. For details, see Effective version and software version in the Administrator's Guide. |
| Filesystem Directory | The MarkLogic installation directory. For details, see Installing MarkLogic in the Installation Guide. |
| Role | The role (local or foreign) of the cluster in the current environment. For details, see Coupling Clusters in the Administrator's Guide. |
| Security Version | The MarkLogic Server version number. |
| SSL Fips Enabled | Whether FIPS-capable OpenSSL is enabled (true) or disabled (false). For details, see OpenSSL FIPS 140-2 Mode in the Administrator's Guide. |
| Version | The software version of MarkLogic Server that is installed on each host in this cluster. For details, see Effective version and software version in the Administrator's Guide. |
| XDQP SSL Certificate | The SSL Certificate used for secure communication between the clusters. For details, see Ops Director Security and Inter-cluster Communication in the Concepts Guide. |
Cluster Tasks
Use the TASKS tab for an up-to-date report on tasks across the hosts within the selected cluster. The report shows tasks that are currently running, are scheduled to run, or have been delayed.

The columns displayed in the cluster TASKS tab are described in the following table.
You can export data from the cluster TASKS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the cluster TASKS table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Cluster Logs
Use the LOGS tab to access a tabular listing of log records that have been logged by various resources within the cluster.

The columns displayed in the cluster LOGS tab are described in the following table.
| Column | Description |
|---|---|
| Date & Time | Datetime of the logged event. |
| Level | The log level of the event. For a description of the log levels, see Understanding the Log Levels in the Administrator's Guide. |
| Cluster Name | The name of the cluster on which the logged event occurred. |
| Host Name | The name of the host on which the logged event occurred. |
| Message | The logged error message. |
| Log File | The full text of the logged event. |
You can export data from the cluster LOGS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Cluster Logs table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Cluster Hosts
Use the HOSTS tab to get the list of all hosts within the selected cluster. This tab shows host name as the first column, followed by other properties. Click the host name to navigate to the manage view of the selected host.

The columns displayed in the cluster HOSTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The hostname of each host. |
| Group | The name of the group that contains each host. |
| OS | The name and version of the operating system on which each host runs. |
| Server Version | The version of MarkLogic Server on each host. |
| Forests | The number of forests on each host. |
| Databases | The number of databases on each host. |
| App Servers | The number of App Servers on each host. |
| Disk Space (MB) | The amount of disk space (in MB) used on each host. |
| Uptime | The duration (Days Hrs:Min) each host has been available. |
| Maint. Mode | The host maintenance mode (normal or maintenance) for each host. For details, see Rolling Upgrades in the Administrator's Guide. |
| Zone | The Amazon Web Services (AWS) zone in which each host resides, if applicable. For details, see MarkLogic Server on Amazon Web Services (AWS) Guide. |
You can export data from the Cluster HOSTS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Cluster Hosts table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Cluster Databases
Use the DATABASES tab to get a list of all the databases within the cluster, with database name as the first column followed by other properties. Click on the database name to navigate to the manage view of the selected database.

The columns displayed in the cluster DATABASES tab are described in the following table.
| Column | Description |
|---|---|
| Name | Name of the database. |
| Forests | The number of forests used by the database. |
| Disk Size (MB) | The amount of disk space used by the database forests, in megabytes. |
| Documents | The number of documents in the database. |
| Last Backup | The date and time of the last backup of the database. No value, if the database has never been backed up. For details on backing up a database, see Backing Up and Restoring a Database in the Administrator's Guide. |
| Encryption | Specifies whether or not encryption at rest is enabled for the database. For details, see Encryption at Rest in the Security Guide. |
| HA | Specifies whether or not shared disk failover is enabled. For details, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled (On/Off). For details, see the Database Replication Guide. |
| Replication Status | Specifies whether or not database replication is configured for the database. |
| Security DB | The name of the security database used by the database. For details, see Administering Security in the Security Guide. |
| Schemas DB | The name of the schemas database used by the database. For details, see Understanding and Defining Schemas in the Administrator's Guide. |
| Triggers DB | The name of the schemas database used by the database. For details, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
You can export data from the cluster DATABASES tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Cluster Databases table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Cluster App Servers
Use the APP SERVERS tab to get a list of all the application servers within the cluster, with App Server name as the first column followed by other properties. Click on the App Server name to navigate to the manage view of the selected application server.

The columns displayed in the cluster APP SERVERS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the App Server. |
| Type | The App Server type (HTTP, WebDAV, XDBC, ODBC). |
| Database | The name of the App Server content database. |
| Port | The port number used to access the App Server. |
| SSL | Whether the App Server has SSL enabled (yes) or disabled (no). For details, see Configuring SSL on App Servers in the Security Guide. |
| Group | The name of the group to which the App Server belongs |
| Modules DB+Root | The name of the modules database, or if filesystem, the root directory. |
| Security | The type of security (internal or external). |
You can export data from the cluster APP SERVERS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Cluster App Servers table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Cluster Forests
Use the FORESTS tab to get a list of all the forests within the cluster, with forest name as the first column followed by other properties. Click on the forest name to navigate to the manage view of the selected forest.

The columns displayed in the cluster FORESTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the forest. |
| Host | The forest host. |
| Documents | The number of documents in the forest. |
| Status | The status of the forest. Enabled or Disabled. |
| Availability | The availability of the forest. Online or Offline. |
| Fragments | The number of active fragments (the fragments available to queries) in the forest. |
| Deleted Fragments | The number of deleted fragments (the fragments to be removed by the next merge operation) in the forest. |
| Stands | The number of stands in the forest. For more information on stands, see Databases, Forests, and Stands in the Concepts Guide. |
| Size (MB) | The size of the forest, in MB. |
| Encrypted Size (MB) | The amount of encrypted data in the forest. For details on data encryption, see Encryption at Rest in the Security Guide. |
| Free Space (MB) | The number of MB of free space on this forest. |
| Large Data Size (MB) | The amount of data in the large data directories of the forest. For more information on Large Data, see Working With Binary Documents in the Application Developer's Guide. |
| Fast Data Size (MB) | The amount of data in the fast data directories of the forest. For more information on Fast Data, see Fast Data Directory on Forests in the Query Performance and Tuning Guide. |
| Failover Enabled | Whether failover is enabled for the forest. For more information on stands, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled for this forest. For details, see the Database Replication Guide. |
You can export data from the cluster FORESTS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the cluster FORESTS table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Manage Hosts Tab
The HOSTS tab displays the list of hosts in your enterprise.
You can only see the hosts to which you have access. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the manage HOSTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The hostname of the host. |
| Cluster | The name of the cluster on which the host resides. |
| Group | The name of the group that contains the host. |
| OS | The name and version of the operating system on which the host runs. |
| Server Version | The version of MarkLogic Server on the host. |
| Forests | The number of forests on the host. |
| Databases | The number of databases on the host. |
| App Servers | The number of App Servers on the host. |
| Disk Space (MB) | The amount of disk space (in MB) used on the host. |
| Uptime | The duration (Days Hrs:Min) the host has been available. |
| Maint. Mode | The host maintenance mode (normal or maintenance). For details, see Rolling Upgrades in the Administrator's Guide. |
| Zone | The Amazon Web Services (AWS) zone in which the host resides, if applicable. For details, see MarkLogic Server on Amazon Web Services (AWS) Guide. |
You can export data from the manage HOSTS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Manage Hosts table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. In the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
To drill down for a particular host, click on the host name in the host table. You will see the following content tabs, each one representing an information category for the selected host:
You can export all tables from the content tabs for a particular host. When you select a specific host (either in the left side resource navigation panel or in the content area of the view), the Actions menu becomes available in the upper right corner.
From the Actions menu, select Download all tables to export all tables for this particular host.

A zip file with all exported tables for this host will be downloaded to your computer. Each table is represented by a corresponding CSV file. The zip file will contain the following CSV files for the host:
- Tasks CSV file (see the Host Tasks section for details on the contents)
- Databases CVS file (see the Host Databases section for details on the contents)
- App Servers CVS file (see the Host App Servers section for details on the contents)
- Forests CVS file (see the Host Forests section for details on the contents)
For a host, exported tables will not include Logs table. This table can be exported from the LOGS tab of that host, but not as part of the Download all tables operation.
Host Metrics
Select a single host from the navigation tree. The METRICS tab displays key indicators allowing administrators to determine the health of the selected resource.

To filter the data used for rendering the graphs, select a pre-defined time period or specify a custom time period, as described in Date and Time Filters.
The metrics displayed by charts on the host METRICS tab are described in the following table.
| Chart | Definition of Displayed Metric |
|---|---|
| Disk I/O | Disk I/O in MB/sec. For details, see Disk Performance Data. |
| CPU | The aggregate I/O performance data for the CPUs in the host. For details, see CPU Performance Data. |
| Memory Footprint | |
| Memory Size | The amount of space (in MB) forest data files for this host take up in memory. |
| Memory I/O | The number of pages per second moved between memory and disk.
|
| Network | Various XDQP performance metrics as the sum of XDQP activity for this host. For details, see Network Performance Data. |
Host Information
Use the INFORMATION tab to access properties of the selected host.

The properties displayed in the host INFORMATION tab are described in the following table.
| Field | Description |
|---|---|
| Bind Port | The port on which the host to handle inter-host communication within this cluster. For details, see Inter-cluster Communication in the Concepts Guide. |
| Bootstrap Host | Whether this host is a bootstrap host (true). If not, the value is false. For details, see Bootstrap Hosts in the Concepts Guide. |
| Foreign Bind Port | The port used by the host to handle XDQP communication with foreign clusters. For details, see Bootstrap Hosts in the Concepts Guide. |
| Group | The group to which this host belongs. For details on groups, see Groups in the Administrator's Guide. |
| Host Mode | The host maintenance mode (normal or maintenance). For details, see Rolling Upgrades in the Administrator's Guide. |
| Host Mode Description | Description of the host mode, if set. |
| Host Name | The name of the host. |
| Zone | The Amazon Web Services (AWS) zone in which the host resides, if applicable. For details, see MarkLogic Server on Amazon Web Services (AWS) Guide. |
Host Tasks
Use the TASKS tab for an up-to-date report on tasks that are currently running or scheduled to run on this host.
You can only see the tasks for the hosts to which you have access.For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the Host TASKS tab are described in the following table.
You can export data from the Host TASKS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Host Tasks table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Host Logs
Use the LOGS tab to access a tabular listing of log records of the host.
You can only see the logs from the hosts to which you have access. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the host LOGS tab are described in the following table.
| Column | Description |
|---|---|
| Date & Time | Datetime of the logged event. |
| Level | The log level of the event. For a description of the log levels, see Understanding the Log Levels in the Administrator's Guide. |
| Cluster Name | The name of the cluster on which the logged event occurred. |
| Host Name | The name of the host on which the logged event occurred. |
| Message | The logged error message. |
| Log File | The full text of the logged event. |
You can export data from the host LOGS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Host Logs table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Host Databases
Use the DATABASES tab to get a list of all the databases within the host, with database name as the first column followed by other properties. Click on the database name to navigate to the METRICS view of the selected database.
Access to databases of a host is implicit if you have access to that host. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the host DATABASES tab are described in the following table.
| Column | Description |
|---|---|
| Name | Name of the database. |
| Forests | The number of forests used by the database. |
| Disk Size (MB) | The amount of disk space used by the database forests, in megabytes. |
| Documents | The number of documents in the database. |
| Last Backup | The data-time of the last backup of the database. No value, if the database has never been backed up. For details on backing up a database, see Backing Up and Restoring a Database in the Administrator's Guide. |
| Encryption | Specifies whether or not encryption at rest is enabled for the database. For details, see Encryption at Rest in the Security Guide. |
| HA | Specifies whether or not shared disk failover is enabled. For details, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled. For details, see the Database Replication Guide. |
| Replication Status | Specifies whether or not database replication is configured for the database. |
| Security DB | The name of the security database used by the database. For details, see Administering Security in the Security Guide. |
| Schemas DB | The name of the schemas database used by the database. For details, see Understanding and Defining Schemas in the Administrator's Guide. |
| Triggers DB | The name of the schemas database used by the database. For details, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
You can export data from the host DATABASES tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Host Databases table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Host App Servers
Use the APP SERVERS tab to get the list of all the application servers within the host, with App Server name as the first column followed by other properties. Click on the App Server name to navigate to the manage view of the selected application server.
Access to App Servers is not implicit with host access. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the host APP SERVERS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the App Server. |
| Type | The App Server type (HTTP, WebDAV, XDBC, ODBC). |
| Database | The name of the App Server content database. |
| Port | The port number used to access the App Server. |
| SSL | Whether the App Server has SSL enabled (yes) or disabled (no). For details, see Configuring SSL on App Servers in the Security Guide. |
| Group | The name of the group to which the App Server belongs |
| Modules DB+Root | The name of the modules database, or if filesystem, the root directory. |
| Security | The type of security (internal or external). |
You can export data from the host APP SERVERS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Host App Servers table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Host Forests
Use the FORESTS tab to get a list of all the forests within the host, with forest name as the first column, followed by other properties. Click on the forest name to navigate to the manage view of the selected forest.

The columns displayed in the host FORESTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the forest. |
| Documents | The number of documents in the forest. |
| Status | The status of the forest. Enabled or Disabled. |
| Availability | The availability of the forest. Online or Offline. |
| Fragments | The number of active fragments (the fragments available to queries) in the forest. |
| Deleted Fragments | The number of deleted fragments (the fragments to be removed by the next merge operation) in the forest. |
| Stands | The number of stands in the forest. For more information on stands, see Databases, Forests, and Stands in the Concepts Guide. |
| Size (MB) | The size of the forest, in MB. |
| Encrypted Size (MB) | The amount of encrypted data in the forest. For details on data encryption, see Encryption at Rest in the Security Guide. |
| Free Space (MB) | The number of MB of free space on this forest. |
| Large Data Size (MB) | The amount of data in the large data directories of the forest. For more information on Large Data, see Working With Binary Documents in the Application Developer's Guide. |
| Fast Data Size (MB) | The amount of data in the fast data directories of the forest. For more information on Fast Data, see Fast Data Directory on Forests in the Query Performance and Tuning Guide. |
| Failover Enabled | Whether failover is enabled for the forest. For more information on stands, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled for this forest. For details, see the Database Replication Guide. |
You can export data from the host FORESTS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the host FORESTS table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Manage Databases Tab
The DATABASES tab displays a list of databases in your enterprise.

The columns displayed in the manage DATABASES tab are described in the following table.
| Column | Description |
|---|---|
| Name | Name of the database. |
| Cluster | Cluster on which the database resides. |
| Forests | The number of forests used by the database. |
| Disk Size (MB) | The amount of disk space used by the database forests, in megabytes. |
| Documents | The number of documents in the database. |
| Last Backup | The data-time of the last backup of the database. No value, if the database has never been backed up. For details on backing up a database, see Backing Up and Restoring a Database in the Administrator's Guide. |
| Encryption | Specifies whether or not encryption at rest is enabled for the database. For details, see Encryption at Rest in the Security Guide. |
| HA | Specifies whether or not shared disk failover is enabled. For details, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled. For details, see the Database Replication Guide. |
| Security DB | The name of the security database used by the database. For details, see Administering Security in the Security Guide. |
| Schemas DB | The name of the schemas database used by the database. For details, see Understanding and Defining Schemas in the Administrator's Guide. |
| Triggers DB | The name of the schemas database used by the database. For details, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
You can export data from the Manage Databases tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Manage Databases table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
To drill down for a particular database, click on the database name in the database table. You will see the following content choices, each one representing an information category for the selected database:
- Database Metrics
- Database Information
- Database Tasks
- Database Hosts
- Database App Servers
- Database Forests
You can export all tables from the database content tabs for a particular database. When you select a specific database (either in the left resource navigation panel or in the content area of the view), the Actions menu becomes available in the upper right corner.
From the Actions menu, select Download all tables to export all tables for this particular database.

A zip file with all exported tables for this database will be downloaded to your computer. Each table is represented by the corresponding CSV file. The zip file will contain the following CSV files for the database:
- Tasks CSV file (see the Database Tasks section for details on the contents)
- Hosts CVS file (see the Database Hosts section for details on the contents)
- App Servers CVS file (see the Database App Servers section for details on the contents)
- Forests CVS file (see the Database Forests section for details on the contents)
Database Metrics
Select a single database or all databases from the navigation tree. The METRICS tab displays key indicators enabling you to determine the health of the selected resource or resource group.

To filter the data used for rendering the graphs, select a pre-defined time period or specify a custom time period, as described in Date and Time Filters.
The metrics displayed by the charts on the database METRICS tab are described in the following table.
| Chart | Definition of Displayed Metric |
|---|---|
| Disk I/O | Disk I/O in MB/sec. The displayed metrics are described in Disk Performance Data. |
| Memory Footprint | The total amount (in MB) of memory consumed by the database. |
| Memory Size | The amount of space (in MB) forest data files for the database take up in memory. |
| Memory I/O | The number of pages per second moved between memory and disk.
|
| Lock Rate | The number of locks set per second across all of the databases in the cluster. |
| Lock Wait Load | The aggregate time (in seconds) transactions wait for locks. |
Database Information
Use the INFORMATION tab to access properties of the selected database.

The properties displayed in the database INFORMATION tab are described in the following table.
| Field | Description |
|---|---|
| Assignment Policy | Database rebalancer assignment policy. For details, see Rebalancer Document Assignment Policies in the Administrator's Guide. |
| Attribute Value Positions | Specifies whether index data is included which speeds up the performance of proximity queries that use the cts:field-value-query function. Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
| Collection Lexicon | Specifies whether to create a lexicon of all of the collection URIs in the database. The collection lexicon lets you tolist all of the collection URIs in the database and perform lexicon-based queries on the URIs. |
| Data Encryption | Specifies whether or not encryption at rest is enabled. For details, see Encryption at Rest in the Security Guide. |
| Database Name | The name of the database. |
| Database Replication | Specifies whether or not database replication is enabled. |
| Directory Creation | Specifies whether directories are automatically created in the database when documents are created. The default for a new database is manual. The settings are:
|
| Element Value Positions | Specifies whether index data is included for faster element-based phrase and cts:near-query searches that use cts:element-value-query. |
| Element Word Positions | Specifies whether index data is included in the database files to enable proximity searches (cts:near-query) within specific XML elements or JSON properties. You must also enable word positions to perform element position searches. When this setting is true, positional searches are possible within an XML element or JSON property, but document loading is slower and the database files are larger. |
| Element Word Query Through | The element markup to be searched through in searches that use the cts:element-word-query constructor. Words contained in text node children of a phrase through or Element Word Query Through element node match words in a cts:element-word-query for both the element and for the element's parent. If the parent is also a Phrase Through or Element Word Query Through element, the words also match words in a cts:element-word-query for the grandparent.
For details, see Element Word Query Throughs in the Administrator's Guide. |
| Enabled | Whether data encryption is enabled. For details, see Encryption at Rest in the Security Guide. |
| Encryption Key ID | Data encryption key ID. For details, see Encryption at Rest in the Security Guide. |
| Expunge Locks | Specifies if MarkLogic Server automatically expunges any lock fragments created using xdmp:lock-acquire with specified timeouts. The possible values are:
|
| Fast Case Sensitive Searches | Specifies whether index terms are included in the database files to support fast case-sensitive searches. When this setting is true, case-sensitive searches are faster, but document loading is slower and the database files are larger. |
| Fast Diacritic Sensitive Searches | Specifies whether index terms are included in the database files to support fast diacritic-sensitive searches. When this setting is true, diacritic-sensitive searches are faster, but document loading is slower and the database files are larger. |
| Fast Element Character Searches | Specifies whether wildcard searches are enabled to speed up element-based wildcard searches. For details about wildcard searches, see Understanding and Using Wildcard Searches in the Search Developer's Guide. |
| Fast Element Phrase Searches | Specifies whether index terms are included in the database files to enable fast element-phrase searches. When set to true, element-phrase searches are faster, but document loading is slower and the database files are larger. |
| Fast Element Trailing Wildcard Searches | Specifies whether index terms are included in the database files to enable element trailing wildcard searches and faster character-based XQuery predicates. When set to true, element-trailing-wildcard searches are faster, but document loading is slower and the database files are larger. |
| Fast Element Word Searches | Specifies whether index terms are included in the database files to support fast element-word searches. When set to true, element-word searches are faster, but document loading is slower and the database files are larger. |
| Fast Phrase Searches | Specifies whether index terms are included in the database files to support fast phrase searches. When set to true, phrase searches are faster, but document loading is slower and the database files are larger. |
| Fast Reverse Searches | Specifies whether index terms are included in the database files to support fast reverse searches. When set to true, cts:reverse-query searches are faster, but document loading is slower and the database files are larger. |
| Field | The configuration of any fields in the database. For details on fields, see Fields Database Settings in the Administrator's Guide. |
| Field Value Positions | Specifies whether index data is included which speeds up the performance of proximity queries that use the cts:field-value-query function. Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
| Field Value Searches | Specifies whether index data is included which speeds up the performance of field value queries that use the cts:field-value-query function. Turn this index off if you are not interested in field value queries and if you want to conserve disk space and decrease loading time. |
| Forest | The names of the forests used by the database. |
| Format Compatibility | The version compatibility that MarkLogic Server applies to the indexes for the database during request evaluation. A value other than automatic specifies that all forest data has the specified on-disk format, and it disables the automatic checking for index compatibility information. The automatic detection occurs during database startup and after any database configuration changes, and can take some time and system resources for very large forests and for very large clusters. The default value of automatic is recommended for most installations. |
| In-memory Geospatial Region Index Size | The amount of cache and buffer memory to be allocated for managing geospatial region index data for an in-memory stand. |
| In-memory Limit | The maximum number of fragments in an in-memory stand. An in-memory stand contains the latest version of any new or changed fragments. Periodically, in-memory stands are written to disk as a new stand in the forest. Also, if a stand accumulates a number of fragments beyond this limit, it is automatically saved to disk by a background thread. |
| In-memory List Size | The amount of cache and buffer memory allocated for managing termlist data for an in-memory stand. |
| In-memory Range Index Size | The amount of cache and buffer memory allocated for managing range index data for an in-memory stand. |
| In-memory Reverse Index Size | The amount of cache and buffer memory allocated for managing reverse index data for an in-memory stand. |
| In-memory Tree Size | The size, in megabytes, of the in-memory tree storage. The In-memory Tree Size must be at least one or two megabytes larger than the largest text or small binary document you plan on loading into the database. The largest small binary file size is always constrained by the Large Size Threshold database configuration setting. |
| In-memory Triple Index Size | The amount of cache and buffer memory allocated for managing triple index data for an in-memory stand. |
| Index Detection | Specifies whether to auto-detect index compatibility between the content and the current database settings. This detection occurs during database startup and after any database configuration changes, and can take some time and system resources for very large forests and for very large clusters. The possible values are: |
| Inherit Collections | When set to true, documents and directories automatically inherit collection settings from their parent directory (if collections are not set explicitly when creating the document or directory). If there are any default collections on the user who is creating the document or directory, those permissions are combined with any inherited collections. |
| Inherit Permissions | When set to true, documents and directories automatically inherit permissions from their parent directory (if permissions are not set explicitly when creating the document or directory). If there are any default permissions on the user who is creating the document or directory, those permissions are combined with any inherited permissions. |
| Inherit Quality | When set to true, documents and directories automatically inherit any quality settings from their parent directory (if quality is not set explicitly when creating the document or directory). |
| Journal Count | The number of journal files for the database. |
| Journal Size | The size, in megabytes, of each journal file. The system uses journal files for recovery operations if a transaction fails to complete successfully. The default value is sufficient for most systems; it is calculated at database configuration time based on the size of your system. If you change the other memory settings, however, the journal size must equal the sum of the In-memory List Size and the In-memory Tree Size. Additionally, you must add space to the journal size if you use range indexes (particularly if you use a lot of range indexes or have extremely large range indexes), as range index data can take up journal space. Also, if your transactions span multiple forests, you may also need to add journal size, as each journal must keep the lock information for all of the documents in the transaction, not just for the documents that reside in the forest in which the journal exists. When you change the journal size, the next time the system creates a new journal, it will use the new size limit; existing journals will continue to use the old size limit until they are replaced with new ones (for example, when a journal fills up, when a forest is cleared, or when the system is cleanly shutdown and restarted). |
| Journaling | Specifies how robust transaction journaling is. The possible values are:
|
| Language | The default language for content in the database. Any content without an xml:lang attribute is indexed in the language specified here. |
| Large Size Threshold | The size, in kilobytes, beyond which large binary documents are stored in the Large Data Directory instead of directly in a stand. Binaries smaller than or equal to the threshold are considered small binary files and stored in stands. Binaries larger the threshold are considered large binary files and stored in the Large Data Directory. |
| Locking | Specifies how robust transaction locking is. The possible values are:
|
| Maintain Directory Last Modified | Specifies whether to include a timestamp on the properties for each directory in the database. If set to true, update operations on documents in a directory also update the directory last-modified timestamp, which can cause some contention when multiple documents in the directory are being updated. If your application is experiencing contention during these type of updates (for example, if you see deadlock-detected messages in the error log), set this property to false. The default is false. |
| Maintain Last Modified | Specifies whether to include a timestamp on the properties document for each document in the database. The default is true. |
| Merge Max Size | The maximum size, in megabytes, of a stand that will result from a merge. If a stand grows beyond the specified size, it will not be merged. If two stands would be larger than the specified size if merged, they will not be merged together. If you set this to smaller sizes, large merges (which may require more disk and CPU resources) will be prevented. The default is 48 GB (49152 MB), which is recommended because it provides a good balance between keeping the number of stands low and preventing very large merges from using large amounts of disk space. Set this to 0 to allow any sized stand to merge. Use care when setting this to a non-zero value lower than the default value, as this can prevent merges which are ultimately required for the system to maintain performance levels and to allow optimized updates to the system. For details on controlling merges, see Understanding and Controlling Database Merges in the Administrator's Guide. |
| Merge Min Ratio | A positive integer indicating the minimum ratio between the number of fragments in a stand and the number of fragments in all of the other smaller stands (the stands with fewer fragments) in the forest. Stands with a fragment count below this ratio relative to all smaller stands are automatically merged with the smaller stands. For an example, see If You Want to Reduce the Number of 'Large' Merges in the Administrator's Guide. |
| Merge Min Size | The minimum number of fragments that a stand can contain. Two or more stands with fewer than this number of fragments are automatically merged. For details on controlling merges, see Understanding and Controlling Database Merges in the Administrator's Guide. |
| Merge Priority | Specifies the CPU scheduler priority at which merges run. The settings are:
Merges always run with normal priority on forests with more than 16 stands. For details on controlling merges, see Understanding and Controlling Database Merges in the Administrator's Guide. |
| Merge Timestamp | The timestamp stored on merged stands. This is used for point-in-time queries, and determines when space occupied by deleted fragments and old versions of fragments may be reclaimed by the database. If a fragment is deleted or updated at a time after the merge timestamp, the old version of the fragment is retained for use in point-in-time queries. Set this to 0 (the default) to let the system reclaim the maximum amount of disk space during merge activities. A setting of 0 removes all deleted and updated fragments when a merge occurs. Set this to 1 before loading or updating any content to create a complete archive of the changes to the database over time. Set this to the current timestamp to preserve all versions of content from this point on. Set this to a negative number to specify a window of timestamp values, relative to the last merge, at ten million ticks per second. The timestamp is a number maintained by MarkLogic Server that increments every time a change occurs in any of the databases in a system (including configuration changes from any host in a cluster). For details on point-in-time queries, see Point-In-Time Queries in the Application Developer's Guide. |
| One Character Searches | Specifies whether wildcard searches are enabled so that the search pattern contains a single non-wildcard characters (for example, a*). This index is not needed if you have Three Character Searches and a word lexicon. For details about wildcard searches, see Understanding and Using Wildcard Searches in the Search Developer's Guide. |
| Phrase Around | Specifies the element markup phrased around in searches. Searches for phrases can skip around element boundaries when a phrase-around is configured for that element. For example, if there is a Phrase Around configured on a <p>to <b>be</b> or not to be</p> The phrase indexer needs to know phrases may cross these markup boundaries at load time and reindex time so that it includes the right information in the indexes supporting phrase search. Each phrase-around has the following settings:
For more detail, see Phrasing and Element-Word-Query Boundary Control in the Administrator's Guide. |
| Phrase Through | Specifies the element markup to be phrased through in searches. Searches for phrases can cross element boundaries when a phrase-through is configured for that element. For example, if there is a phrase-through configured on a <p>to <b>be</b> or not to be</p> The phrase indexer needs to know phrases may cross these markup boundaries at load time and reindex time so that it includes the right information in the indexes supporting phrase search. Words contained in text node children of a phrase-through or Element Word Query Through element node match words in a cts:element-word-query for both the element and for the element's parent. If the parent is also a phrase-through or Element Word Query Through element, the words also match words in a cts:element-word-query for the grandparent. If you delete a phrase-through, the system will not automatically reindex away the indexed phrase-throughs, even if reindexing is enabled; to reindex deleted phrase-throughs, force a reindex (for example, by clicking the reindex button on the database configuration page). Each phrase-through has the following settings:
For more detail, see Phrasing and Element-Word-Query Boundary Control in the Administrator's Guide. |
| Positions List Max Size | The maximum size, in megabytes, of the position list portion of the index for a given term. If the position list size for a given term grows larger than the limit specified, the position information for that term is discarded. The default value is 256, the minimum value is 1, and the maximum value is 512. For example, position queries (cts:near-query) for frequently occurring words that have reached this limit (words like a, an, the, and so on) are resolved without using the indexes. Even though those types of words are resolved without using the indexes, this limit helps improve performance by making the indexes smaller and more efficient to the data actually loaded in the database. |
| Preallocate Journals | Has no effect as of MarkLogic, Version 8.0-4. |
| Preload Mapped Data | Specifies whether memory mapped data (for example, range indexes and word lexicons) is loaded into memory when a forest is mounted to the database. Preloading the memory mapped data improves query performance, but uses more memory, especially if you have a lot of range indexes and/or lexicons. Also, it will cause a lot of disk I/O at database startup time, slowing the system performance during the time the mapped data is read into memory. If you do not preload the mapped data, it will be paged into memory dynamically when a query requests data that needs it, slowing the query response time. |
| Preload Replica Mapped Data | Specifies whether memory mapped data (for example, range indexes and word lexicons) are loaded immediately into memory when a stand is opened. The setting of preload-replica-mapped-data is ignored if Preload Mapped Data is set to false. |
| Range Element Attribute Index | The range indexes on attributes in XML elements.
For details, see Defining Attribute Range Indexes in the Administrator's Guide. |
| Range Element Index | The range indexes on XML elements or JSON properties.
For details, see Defining Element Range Indexes in the Administrator's Guide. |
| Range Index Optimize | Specifies how range indexes are to be optimized. The values are defined as follows: |
| Rebalancer Enable | Specifies whether rebalancing are automatically performed in the background after configuration settings are changed. When set to true, the database rebalancer automatically redistributes the content across the database forests. When set to false, rebalancing is disabled. For details, see Configuring the Rebalancer on a Database in the Administrator's Guide. |
| Rebalancer Throttle | The priority of system resources devoted to rebalancing. Higher numbers give rebalancing a higher priority. For details, see How the Rebalancer Moves Documents in the Administrator's Guide. |
| Reindexer Enable | Specifies whether indexes are automatically rebuilt in the background after index configuration settings are changed. When set to true, index configuration changes automatically initiate a background reindexing operation on the entire database. When set to false, any new index settings take effect for future documents loaded into the database; existing documents retain the old settings until they are reloaded or until you set reindexer enable to true. For details, see Understanding the Reindexer Enable Settings in the Administrator's Guide. |
| Reindexer Throttle | The priority of system resources devoted to reindexing. Reindexing occurs in batches, where each batch is approximately 200 fragments. When set to 5 (the default), the reindexer works aggressively, starting the next batch of reindexing soon after finishing the previous batch. When set to 4, it waits longer between batches, when set to 3 it waits longer still, and so on until when it is set to 1, when it waits the longest. Therefore, higher numbers give reindexing a higher priority and use the most system resources. For details, see Understanding the Reindexer Enable Settings in the Administrator's Guide. |
| Reindexer Timestamp | The timestamp of fragments to force a reindex or refragment operation. If Reindex Enable is set to true, a reindex and refragment operation are done on all fragments in the database that have a timestamp equal to or less than the displayed timestamp. Note that when you restore a database that has a timestamp set, if there are fragments in the restored content that are older than the specified content, they will start to reindex as soon as they are restored. |
| Retain Until Backup | Specifies whether the deleted fragments are retained since the last full or incremental backup. When enabled, Retain Until Backup supersedes Merge Timestamp. Deleted fragments are not merged until backups are finished, regardless of the Merge Timestamp setting. Enabling Retain Until Backup is same to setting the Merge Timestamp to the timestamp of the last backup. For more information, see Incremental Backup with Journal Archiving in the Administrator's Guide. |
| Retired Forest Count | The number of forests used by the database to be retired. For more information, see Retiring a Forest from the Database in the Administrator's Guide. |
| Security Database | The security database used by the database. For more information, see Overview of the Security Database in the Security Guide. |
| Stemmed Searches | The level of stemming applied to word searches. Stemmed searches match not only the exact word in the search, but also words that come from the same stem and mean the same thing (for example, a search for be will also match the term is). For details on stemmed searches, see Understanding and Using Stemmed Searches in the Search Developer's Guide. |
| TF Normalization | Specifies the term-frequency normalization. The values are described as follows:
For more information, see Term Frequency Normalization in the Search Developer's Guide. |
| Three Character Searches | Specifies whether to enable wildcard searches where the search pattern contains three or more consecutive non-wildcard characters (for example, For details about wildcard searches, see Understanding and Using Wildcard Searches in the Search Developer's Guide. |
| Three Character Word Positions | Specifies whether index data is included in the database files to enable proximity searches (cts:near-query) within wildcard queries. You must also enable Three Character Searches to perform wildcard position searches. When set to For details about wildcard searches, see Understanding the Wildcard Indexes in the Search Developer's Guide. |
| Trailing Wildcard Searches | Specifies whether indexes are created to enable wildcard searches where the search pattern contains one or more consecutive non-wildcard characters at the beginning of the word, with the wildcard at the end of the word (for example, abc*). When this setting is true, character searches are faster, but document loading is slower and the database files are larger. For details about wildcard searches, see Understanding and Using Wildcard Searches in the Search Developer's Guide. |
| Trailing Wildcard Word Positions | Specifies whether index data is included in the database files to enable proximity searches (cts:near-query) within trailing wildcard queries. You must also enable trailing wildcard searches to perform trailing wildcard position searches. When this setting is true, positional searches are possible within a trailing wildcard query, but document loading is slower and the database files are larger. For details about wildcard searches, see Understanding the Wildcard Indexes in the Search Developer's Guide. |
| Triple Index | Specifies whether the RDF triple index is enabled to support SPARQL execution over RDF triples. When set to true, sem:sparql can be used, but document loading is slower and the database files are larger. This index must also be enabled to support Optic and SQL queries.This feature requires a valid semantics license key. For details, see Triple Index Overview in the Semantics Developer's Guide. |
| Triple Positions | Specifies whether index data is included which speeds up the performance of proximity queries that use the cts:triple-range-query function. Triple positions also improve the accuracy of the item-frequency option of cts:triples. For details, see Triple Positions in the Semantics Developer's Guide. |
| Two Character Searches | Specifies whether to enable wildcard searches where the search pattern contains two or more consecutive non-wildcard characters (for example, For details about wildcard searches, see Understanding and Using Wildcard Searches in the Search Developer's Guide. |
| URI Lexicon | Specifies whether to create a lexicon of all of the URIs used in a database. The URI lexicon speeds up queries that constrain on URIs. It is like a range index of all of the URIs in the database. To access values from the URI lexicon, use the cts:uris or cts:uri-match functions. For details, see URI and Collection Lexicons in the Search Developer's Guide. |
| Word Positions | Specifies whether index data is included in the database files to enable proximity searches (cts:near-query). When set to true, positional searches are possible, but document loading is slower and the database files are larger. For details, see Positions Indexes Can Help Speed Phrase Searches in the Query Performance and Tuning Guide. |
| Word Searches | Specifies whether index terms are included in the database files to support fast word searches. When this setting is For details, see the Search Developer's Guide. |
Database Tasks
Use the TASKS tab to get the list of the database tasks.
You can only see the tasks for the databases to which you have access.For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the database TASKS tab are described in the following table.
You can export data from the Database Tasks tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Database Tasks table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Database Hosts
Use the HOSTS tab to get the list of hosts on which the database is deployed. This tab shows host name as the first column, followed by other properties. Click on the host name to navigate to the manage view of the selected host.
Access to hosts is not implicit with database access. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the Database Hosts tab are described in the following table.
| Column | Description |
|---|---|
| Name | The hostname of the host. |
| Group | The name of the group that contains the host. |
| OS | The name and version of the operating system on which the host runs. |
| Server Version | The version of MarkLogic Server on each host. |
| Forests | The number of forests on the host. |
| Databases | The number of databases on the host. |
| App Servers | The number of App Servers on the host. |
| Disk Space (MB) | The amount of disk space (in MB) used on the host. |
| Uptime | The duration (Days Hrs:Min) the host has been available. |
| Maint. Mode | The host maintenance mode (normal or maintenance). For details, see Rolling Upgrades in the Administrator's Guide. |
| Zone | The Amazon Web Services (AWS) zone in which the host resides, if applicable. For details, see MarkLogic Server on Amazon Web Services (AWS) Guide. |
You can export data from the Database Hosts tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Database Hosts table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Database App Servers
Use the APP SERVERS tab to get the list of all the application servers that use the database, with App Server name as the first column followed by other properties. Click on the App Server name to navigate to the METRICS view of the selected application server.
Access to the APP SERVERS tab is not implicit with database access. For access rules, see Access Inheritance in Resource Groups.

The columns displayed in the database APP SERVERS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the App Server. |
| Type | The App Server type (HTTP, WebDAV, XDBC, ODBC). |
| Database | The name of the App Server content database. |
| Port | The port number used to access the App Server. |
| SSL | Whether the App Server has SSL enabled (yes) or disabled (no). For details, see Configuring SSL on App Servers in the Security Guide. |
| Group | The name of the group to which the App Server belongs |
| Modules DB+Root | The name of the modules database, or if filesystem, the root directory. |
| Security | The type of security (internal or external). |
You can export data from the database APP SERVERS tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Database App Servers table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Database Forests
Use the FORESTS tab to list all the forests within the database, with forest name as the first column, followed by other properties. Click on the forest name to navigate to the manage view of the selected forest.

The columns displayed in the database FORESTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the forest. |
| Host | The forest host. |
| Documents | The number of documents in the forest. |
| Status | The status of the forest. Enabled or Disabled. |
| Availability | The availability of the forest. Online or Offline. |
| Fragments | The number of active fragments (the fragments available to queries) in the forest. |
| Deleted Fragments | The number of deleted fragments (the fragments to be removed by the next merge operation) in the forest. |
| Stands | The number of stands in the forest. For more information on stands, see Databases, Forests, and Stands in the Concepts Guide. |
| Size (MB) | The size of the forest, in MB. |
| Encrypted Size (MB) | The amount of encrypted data in the forest. For details on data encryption, see Encryption at Rest in the Security Guide. |
| Free Space (MB) | The number of MB of free space on this forest. |
| Large Data Size (MB) | The amount of data in the large data directories of the forest. For more information on Large Data, see Working With Binary Documents in the Application Developer's Guide. |
| Fast Data Size (MB) | The amount of data in the fast data directories of the forest. For more information on Fast Data, see Fast Data Directory on Forests in the Query Performance and Tuning Guide. |
| Failover Enabled | Whether failover is enabled for the forest. For more information on stands, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled for this forest. For details, see the Database Replication Guide. |
You can export data from the Database Forests tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Database Forests table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
Manage App Servers Tab
The APP SERVERS tab displays a list of App Servers in your enterprise.

The columns displayed in the manage APP SERVERS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The name of the App Server. |
| Cluster | The name of the cluster that hosts the App Server. |
| Type | The App Server type (HTTP, WebDAV, XDBC, ODBC). |
| Database | The name of the App Server content database. |
| Port | The port number used to access the App Server. |
| SSL | Whether the App Server has SSL enabled (yes) or disabled (no). For details, see Configuring SSL on App Servers in the Security Guide. |
| Group | The name of the group to which the App Server belongs |
| Modules DB+Root | The name of the modules database, or if filesystem, the root directory. |
| Security | The type of security (internal or external). |
You can export data from the Manage App Servers tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the Manage App Servers table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values,
Yes/Noin the UI corresponds toTRUE/FALSEin the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
To drill down for a particular App Server, click on the App Server name in the App Servers table. The following content tabs each represent an information category for the selected App Server:
You can export all tables from the App Server content tabs for a particular App Server. When you select a specific App Server (either in the left side resource navigation panel or in the content area of the view), Actions menu becomes available in the upper right corner.
From the Actions menu, select Download all tables to export all tables for the selected App Server.

As the result, a zip file with all exported tables for this App Server will be downloaded to your computer. Each table is represented by the corresponding CSV file. The zip file will contain the following CSV files for the App Server:
- Hosts CVS file (see the App Server Hosts section for details on the contents)
- Databases CVS file (see the App Server Databases section for details on the contents)
App Server Metrics
Select a single App Server or all App Servers from the navigation tree. The METRICS tab displays key indicators allowing administrators to determine the selected resource or resource group's health.

To filter the data used for rendering the graphs, select a pre-defined time period or specify a custom time period, as described in Date and Time Filters.
The metrics displayed by charts on the App Server Metrics tab are described in the following table.
App Server Information
Use the Information tab to access properties of the selected application server.

The properties displayed in the App Server Information tab are described in the following table.
Most of these properties are described in detail in the HTTP Servers, XDBC Servers, WebDAV Servers, and ODBC Servers chapters in the Administrator's Guide.
| Field | Description |
|---|---|
| Address | The IP address for the App Server. |
| Authentication | The authentication scheme used by this App Server. The authentication scheme can be one of: digest, basic, digestbasic, certificate, kerberos-ticket, or application-level. For details, see Types of Authentication in the Security Guide. |
| Backlog | The maximum number of pending connections allowed on the App Server socket. |
| Collation | The default collation for queries run in this App Server. This is the collation used for string comparison and sorting if none is specified in the query. For details, see Encodings and Collations in the Search Developer's Guide. |
| Compute Content Length | Specifies whether to compute content length when using a webDAV server. A value of true indicates to compute content length; otherwise false. |
| Concurrent Request Limit | The maximum number of requests any user may have been running at a specific time. 0 indicates no maximum. For details, see Managing Concurrent User Sessions in the Administrator's Guide. |
| Content Database | The content database for this App Server. |
| Coordinate System | The default coordinate system for queries run in this App Server. This will be the coordinate system used for geospatial operations if none is specified in the query. For details, see Understanding Coordinate Systems in the Search Developer's Guide. |
| Debug Allow | Specifies whether to allow requests against this App Server to be stopped for debugging, using the MarkLogic Server debugging APIs. A value of true allows the App Server to be stopped; otherwise false. |
| Default Error Format | The default format for protocol errors for this server. The value can be:
For more information, see set-error-format in the Application Developer's Guide. |
| Default Inference Size | The amount of memory available to use for semantic inference queries. By default the amount of memory available for inference is 100mb (size=100). For details, see Memory Available for Inference in the Semantics Developer's Guide. |
| Default Time Limit | The default value for any request's time limit (in seconds), when otherwise unspecified. A request can change its time limit using the xdmp:set-request-time-limit function. The time limit, in turn, is the maximum number of seconds allowed for servicing a query request. The App Server gives up on queries that take longer, and returns an error. |
| Default User | The user used as the default user in application-level authentication. Setting the admin user as the default user is equivalent to turning security off. For details, see Application Level in the Security Guide. |
| Default Xquery Version | The default XQuery language for this App Server if an XQuery module does explicitly declare its language version. |
| Display Last Login | Specifies whether the xdmp:display-last-login API returns true or false in the display-last-login element. For details, see Storing and Monitoring the Last User Login Attempt in the Administrator's Guide. |
| Distribute Timestamps | Specifies how the latest timestamp is distributed after updates. This affects performance of updates and the timeliness of read-after-write query results from other hosts in the group. The possible values are:
|
| Enabled | Whether this App Server is enabled (true) or disabled (false). |
| Error Handler | The page to internally redirect to in case of any 400 or 500 errors. For details, see Controlling App Server Access, Output, and Errors in the Application Developer's Guide. |
| Execute | Specifies whether this App Server executes XQuery modules (for example, a WevDAV server does not). If true, the App Server executes XQuery modules; otherwise false. |
| File Log Level | The minimum log level for log messages sent to the MarkLogic Server log file (ErrorLog.txt). For a description of the log levels, see Understanding the Log Levels in the Administrator's Guide. |
| Group Name | The group to which this App Server belongs. For details on groups, see Groups in the Administrator's Guide. |
| Internal Security | Specifies whether the security database is used for authentication and authorization if the user is found in the security database. If true, use the security database; if false, external authentication/authorization is used. For details, see External Security in the Security Guide. |
| Keep Alive Timeout | The maximum number of seconds before a socket receives a timeout for subsequent requests over the same connection. |
| Log Errors | Specifies whether to log uncaught errors for this App Server to the ErrorLog.txt file. This is useful to log exceptions that might occur on an App Server for later debugging. If true, log errors; if false, do not log errors. |
| Max Inference Size | The maximum memory limit for semantic inference queries. For details, see Memory Available for Inference in the Semantics Developer's Guide. |
| Max Time Limit | The upper bound for any request's time limit. No request may set its time limit (for example with xdmp:set-request-time-limit) higher than this number. The time limit, in turn, is the maximum number of seconds allowed for servicing a query request. The App Server gives up on queries which take longer, and returns an error. |
| Multi Version Concurrency Control | Specifies how the latest timestamp is chosen for lock-free queries. This only affects query statements, not update statements. The following are the possible values:
For details about queries and transactions in MarkLogic Server, see Understanding Transactions in MarkLogic Server in the Application Developer's Guide. |
Output Cdata Section Localname Output Cdata Section Namespace URI Output Include Default Attributes |
The output options for the App Server. For details about controlling App Server output, see Controlling App Server Access, Output, and Errors in the Application Developer's Guide and Setting Output Options for an HTTP Server, Setting Output Options for an XDBC Server, Setting Output Options for an ODBC Server, and Setting Output Options for a WebDAV Server in the Administrator's Guide. For details on setting the serialization options in XQuery, see Declaring Options in the XQuery and XSLT Reference Guide. For XSLT output details, see the XSLT specification (http://www.w3.org/TR/xslt20#serialization). |
| Port | The port number applications use to access this App Server. |
| Pre Commit Trigger Depth | The maximum depth (how many triggers can cause other triggers to fire, which in turn cause others to fire, and so on) for pre-commit triggers that are executed against this App Server. For more information on triggers, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
| Pre Commit Trigger Limit | The maximum number of pre-commit triggers this App Server can invoke for a single statement. For more information on triggers, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
| Privilege | The execute privilege required to access this App Server. |
| Profile Allow | Specifies whether to allow requests against this App Server to be profiled, using the MarkLogic Server profiling APIs. For details, see Profiling Requests to Evaluate Performance in the Query Performance and Tuning guide. |
| Request Timeout | The maximum number of seconds before a socket receives a timeout for the first request. |
| Rewrite Resolves Globally | Specifies whether to allow rewritten URLs to be resolved from the global MarkLogic/Modules directory or App Server root. |
| Root | The directory in which programs executed against this App Server are stored. If the Modules field is set to a database, the root must be a directory URI in the specified modules database. If the Modules field is set to file system, the root directory is either a fully-qualified pathname or is relative to the directory in which MarkLogic Server is installed. For details on where the MarkLogic Server is installed by default on your platform, see Installing MarkLogic in the Installation Guide. |
| Server Name | The name of this App Server. |
| Server Type | The App Server type (http, odbc, xdbc, or WebDAV). |
| Session Timeout | The maximum number of seconds before an inactive session times out. |
| SSL Allow SSLv3 | Specifies whether to allow this App Server to communicate with applications by means of the SSLv3 security protocol. |
| SSL Allow TLS | Specifies whether to allow this App Server to communicate with applications by means of the TLSv1 security protocol. |
| SSL Ciphers | The SSL ciphers that may be used. For details, see Configuring SSL on App Servers in the Security Guide. |
| SSL Disable SSLv3 | Specifies whether to prevent this App Server from communicating with applications by means of the SSLv3 security protocol. |
| SSL Disable TLSv1 | Specifies whether to prevent this App Server from communicating with applications by means of the TLSv1 security protocol. |
| SSL Disable TLSv11 | Specifies whether to prevent this App Server from communicating with applications by means of the TLSv11 security protocol. |
| SSL Disable TLSv12 | Specifies whether to prevent this App Server from communicating with applications by means of the TLSv12 security protocol. |
| SSL Hostname | The hostname for the App Server SSL certificate. This is useful when many App Servers are running behind a load balancer. If not specified, each host will use a certificate for its own hostname. For details, see Configuring SSL on App Servers in the Security Guide. |
| SSL Require Client Certificate | Specifies whether to enable mutual authentication, where the client also holds a digital certificate that it sends to the server. Select which certificate authority is to be used to sign client certificates for the server. For details, see Configuring SSL on App Servers in the Security Guide. |
| Static Expires | The number of seconds before an expires HTTP header is added for static content. |
| Threads | The maximum number of App Server threads. |
| URL Rewriter | The path to the script to run to rewrite URLs. For details, see Setting Up URL Rewriting for an HTTP App Server in the Application Developer's Guide. |
| WebDAV | Specifies whether this App Server is a WebDAV App Server. |
App Server Hosts
Use the HOSTS tab to see the host that contains the selected App Server. This tab shows the host name as the first column, followed by other properties. Click on the host name to navigate to the manage view of the host.

The columns displayed in the App Server HOSTS tab are described in the following table.
| Column | Description |
|---|---|
| Name | The hostname of the host. |
| Group | The name of the group that contains the host. |
| OS | The name and version of the operating system on which the host runs. |
| Server Version | The version of MarkLogic Server on the host. |
| Forests | The number of forests on the host. |
| Databases | The number of databases on the host. |
| App Servers | The number of App Servers on the host. |
| Disk Space (MB) | The amount of disk space (in MB) used on the host. |
| Uptime | The duration (Days Hrs:Min) the host has been available. |
| Maint. Mode | The host maintenance mode (normal or maintenance). For details, see Rolling Upgrades in the Administrator's Guide. |
| Zone | The Amazon Web Services (AWS) zone in which the host resides, if applicable. For details, see MarkLogic Server on Amazon Web Services (AWS) Guide. |
You can export data from the App Server Hosts tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the App Server Hosts table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.
App Server Databases
Use the DATABASES tab to get a list of databases used by this App Server, with the database name as the first column, followed by other properties. Click on the database name to navigate to the manage view of the selected database.

The columns displayed in the App Server DATABASES tab are described in the following table.
| Column | Description |
|---|---|
| Name | Name of the database. |
| Forests | The number of forests used by the database. |
| Disk Size (MB) | The amount of disk space used by the database forests, in megabytes. |
| Documents | The number of documents in the database. |
| Last Backup | The data-time of the last backup of the database. No value, if the database has never been backed up. For details on backing up a database, see Backing Up and Restoring a Database in the Administrator's Guide. |
| Encryption | Specifies whether or not encryption at rest is enabled for the database. For details, see Encryption at Rest in the Security Guide. |
| HA | Specifies whether or not shared disk failover is enabled. For details, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. |
| Replication | Specifies whether or not database replication is enabled. For details, see the Database Replication Guide. |
| Replication Status | Specifies whether or not database replication is configured for the database. |
| Security DB | The name of the security database used by the database. For details, see Administering Security in the Security Guide. |
| Schemas DB | The name of the schemas database used by the database. For details, see Understanding and Defining Schemas in the Administrator's Guide. |
| Triggers DB | The name of the schemas database used by the database. For details, see Using Triggers to Spawn Actions in the Application Developer's Guide. |
You can export data from the App Server DATABASES tab as a CSV (Comma Separated Values) file by clicking the Export icon in the upper right corner. The following rules apply:
- The resulting CSV file will have the same columns as the App Server DATABASES table in the UI.
- All available columns are exported, regardless of whether they are visible or hidden in the UI.
- All records that satisfy the set filter parameters are exported.
- Data types of the fields in the CSV file correspond to those in the UI. in the case of boolean values, Yes/No in the UI corresponds to TRUE/FALSE in the CSV file.
You may then import the CSV file into other applications (such as Excel) for further processing or analysis.