
MarkLogic 9 Product DocumentationAdministrator's Guide — Chapter 16
Understanding and Controlling Database Merges
This chapter describes database merges and how you can control them. It includes the following sections:
- Overview of Merges: Merges are Good
- Setting Merge Policy
- Blackout Periods for Merges
- Merges and Point-In-Time Queries
- Setting a Negative Merge Timestamp to Preserve Fragments For a Rolling Window of Time
- Monitoring a Merge
- Explicit Merge Commands
- Configuring Merge Policy Rules
Overview of Merges: Merges are Good
This section provides an overview of merges, and includes the following parts:
- Dynamic and Self-Tuning
- What Happens During a Merge
- Dangers of Disabling Merges
- Merges Will Change Scores
Dynamic and Self-Tuning
Merges are a way of self-tuning the performance of the system, and MarkLogic Server continuously assesses the state of each database to see if it would benefit from self-tuning through a merge. In most cases, the default merge settings and the dynamic nature of merges will keep the database tuned optimally at all times. Because merges can be resource intensive (both disk I/O and CPU), however, some DBAs might need to control when merges occur and/or when they do not occur. You can do that by setting your merge policy as appropriate for your environment, as described in Setting Merge Policy.
Dynamic and self-tuning, merges are a good thing; they not only reclaim disk space, but improve the query and search performance of the system. Databases are made up of one or more forests, and forests are made up of one or more stands. The more stands there are in a forest, the more time it takes to resolve a query. Merges reduce the number of stands in each forest in a database, thereby improving the time it takes to resolve queries.
What Happens During a Merge
A database consists of one or more forests, and each forest consists of one or more stands. Each stand consists of one or more fragments. When a document is updated, new versions of all of the fragments associated with the document update are created in a new stand. Any old versions of the fragment remain in the old stand with a system timestamp that lets MarkLogic Server know that they are old versions of the fragments. Similarly, when a document is deleted, its fragments remain in the old stand with a system timestamp that lets MarkLogic Server know that they are old versions of the fragments.
Merges occur to move any unchanged fragments from an old stand into a new stand, deleting any old versions of fragments (including deleted fragments), thereby freeing up disk space and compacting the usable fragments so they are all together on disk. Additionally, merges combine index data for all of the fragments in a stand, thereby optimizing the indexes. Merges are a normal part of database operation, and they ensure that the system continues to perform at its best as updates and deletes occur.
To summarize, as part of merging, the following occurs:
- Multiple stands are combined into one for improved performance.
- Disk space is reclaimed.
- Indexes and lexicons are combined and re-optimized based on their new size.
The result is a database that is smaller and can resolve queries much faster than before the merge.
Dangers of Disabling Merges
MarkLogic Server is designed to periodically merge. It is dangerous to leave merges disabled on a database when there are any updates occurring to the system. While disabling merges might eliminate some contention for resources during periods where merges and other requests are simultaneously occurring on the system, the performance of MarkLogic Server will degrade over time if merges are not allowed to proceed when changes (inserts, updates, deletes) are made to the database.
Furthermore, disabling or eliminating merging may eventually lead to a condition in which the server is unable to make changes to the database. For example, when an in-memory stands fills up, it is written to an on-disk stand. MarkLogic Server has a fixed limit for the maximum number of stands (64), and eventually, that limit will occur and you will no longer be able to update your system. Therefore, there is no control available to disable merges. If you feel you need to disable merges and you have an active maintenance contract, you can contact MarkLogic Technical Support for help.
In most cases where merges are causing disruptions to your system, you should be able to adjust the merge policy parameters to settings that will work in your environment. If you feel you need to disable merges and you have an active maintenance contract, you can contact MarkLogic Technical Support for help. Monitor the system and make sure the number of stands per forest does not grow too high. For details on setting merge controls, see Description of Merge Policy Parameters and Configuring Merge Policy Rules.
In some cases, especially in environments with many forests and constantly changing content across many of the forests, an alternative to disabling merges is to set one or more forests to be delete-only. For details, see Making a Forest Delete-Only.
Merges Will Change Scores
When a database merges, it deletes old fragments that exist in the database, therefore changing (making it smaller) the total number of fragments in the database. Because the number of fragments in the database is used in determining the score for a cts:search operation, merges will have an impact on search scores, which in turn might impact the order of search results (which are ordered by relevance score).
The amount of impact that merges have on scores is dependent on how many old versions of fragments there are waiting to be merged, the content of the old fragments, and the overall size of the database. For large databases with relatively little amount of change, the difference in the scores will be very small. For smaller databases with large amount of change, the differences in scores can be significant before and after a merge completes.
Setting Merge Policy
This section describes the tools you can use to control merges, and has the following parts:
In some cases, especially in environments with many forests and constantly changing content across many of the forests, another tool for setting merge policy is to set one or more forests to be delete-only (updates allowed set to false). For details, see Making a Forest Delete-Only.
Overview of the Merge Policy Controls
If you determine that you need to manage your merges, there are several types of controls to help you manage the conditions in which merges occur:
- The following controls determine the conditions under which MarkLogic Server deems a merge is desirable:
- The following controls determine the conditions under which a merge will be allowed:
- The following control determines if multiple versions of fragments are preserved when a merge is performed:
- The following controls explicitly initiate a merge (see Manually Initiating a Merge):
- The Admin Interface has controls for cancelling a merge (see Cancelling a Merge).
For more information on how set up your system to better control merges, see Configuring Merge Policy Rules.
Description of Merge Policy Parameters
The merge policy determines when automatic merges occur on a database, as well as other administrative functions. Perform the following to configure merge policy:
- In the Admin Interface tree menu, click the Databases > db_name link, where db_name is the name of the database in which you want to specify merge policy .
- Click
Merge Policyin the left hand menu. The Merge Policy Configuration page appears.
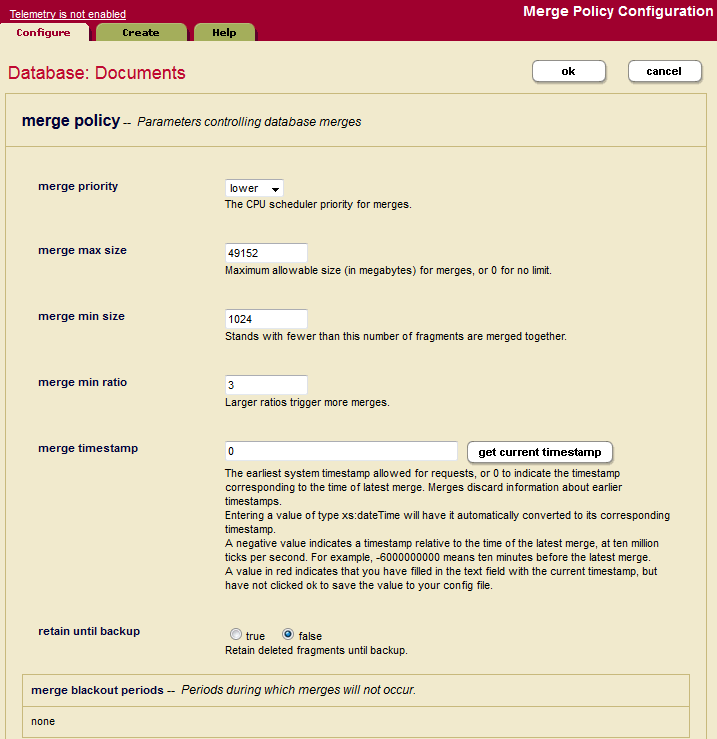
The following table describes the settings available on Merge Policy page.
| Database Setting | Description |
|---|---|
merge priority |
Specifies the CPU scheduler priority at which merges should run. The settings are:
Merges always run with normal priority on forests with more than 16 stands. |
merge max size |
The maximum size, in megabytes, of a stand that will result from a merge. If a stand grows beyond the specified size, it will not be merged. If two stands would be larger than the specified size if merged, they will not be merged together. If you set this to smaller sizes, large merges (which may require more disk and CPU resources) will be prevented. The default is 48 GB (49152 MB), which is recommended because it provides a good balance between keeping the number of stands low and preventing very large merges from using large amounts of disk space. Set this to 0 to allow any sized stand to merge. Use care when setting this to a non-zero value lower than the default value, as this can prevent merges which are ultimately required for the system to maintain performance levels and to allow optimized updates to the system. |
merge min size |
The minimum number of fragments that a stand can contain. Two or more stands with fewer than this number of fragments are automatically merged. |
merge min ratio |
A positive integer indicating the minimum ratio between the number of fragments in a stand and the number of fragments in all of the other smaller stands (that is stands with fewer fragments) in the forest. Stands with a fragment count below this ratio relative to all smaller stands are automatically merged with the smaller stands. For an example, see If You Want to Reduce the Number of 'Large' Merges. |
merge timestamp |
The timestamp stored on merged stands. This is used for point-in-time queries, and determines when space occupied by deleted fragments and old versions of fragments may be reclaimed by the database. If a fragment is deleted or updated at a time after the merge timestamp, then the old version of the fragment is retained for use in point-in-time queries. Set this to 0 (the default) to let the system reclaim the maximum amount of disk space during merge activities. A setting of 0 will remove all deleted and updated fragments when a merge occurs. Set this to 1 before loading or updating any content to create a complete archive of the changes to the database over time. Set this to the current timestamp to preserve all versions of content from this point on. Set this to a negative number to specify a window of timestamp values, relative to the last merge, at ten million ticks per second. The timestamp is a number maintained by MarkLogic Server that increments every time a change occurs in any of the databases in a system (including configuration changes from any host in a cluster). To set to the current timestamp, click the Click Get Current Timestamp to return the current merge timestamp. |
| retain until backup | Specify whether the deleted fragments are retained since the last full or incremental backup. When enabled, retain until backup supersedes merge timestamp. Deleted fragments are not merged until backups are finished, regardless of the merge timestamp setting. Enabling retain until backup is same to setting the merge timestamp to the timestamp of the last backup. For more information, see Incremental Backup with Journal Archiving. |
merge blackout periods |
Specify times when merges are disabled. To specify a merge blackout period, click the Create tab and specify when you want the blackout to occur. You can make it a recurring blackout period, or specify a one-time blackout period. Use caution when setting large blackout periods when there are significant updates occurring on the system; merges are a normal part of the self-tuning mechanism of the database, and disabling them completely or for long periods of time can cause performance degradation. |
Blackout Periods for Merges
Although merges are a normal part of system behavior, there are times when it is inconvenient for a merge to start. Merge blackout periods allow you to specify times when a merge should not begin. This section describes merge blackouts and includes the following parts:
Understanding Merge Blackouts
A merge blackout is a predetermined time period in which automatic merges are disabled. A Merge that starts before a merge blackout period will continue until either it completes or until it is canceled, even if the merge continues into a blackout period. If you want to stop any merges at the beginning of a blackout period, you must cancel them manually as described in Cancelling a Merge. Because merges that start just before a blackout period will continue into the blackout period, if you want to be sure no merges occur during a time period you should make the blackout period start earlier. This is especially true for merges that might run a long time.
If the system determines that a merge is required and it is during a blackout period, the merge will not begin until the blackout period is past.
Configuring Merge Blackout Periods
Perform the following to configure merge blackout periods:
- In the Admin Interface tree menu, click the Databases > db_name link, where db_name is the name of the database in which you want to specify merge blackout periods.
- Click the Merge Policy menu item under your database. The Merge Policy Configuration page appears.
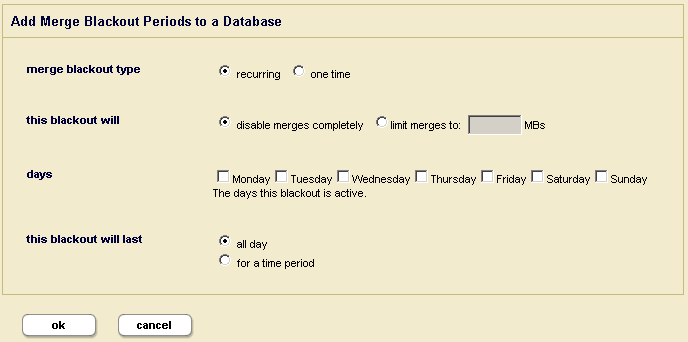
- Click the Create tab. The Add Merge Blackout page appears.
- Fill in the form as needed for the blackout period you want to create. Clicking the radio buttons will bring up more forms to complete.
- Click OK to create the blackout period.
Deleting Merge Blackout Periods
Perform the following to delete a merge blackout period:
- In the Admin Interface tree menu, click the Databases > db_name link, where db_name is the name of the database in which you want to delete a merge blackout period.
- Click the Merge Policy menu item under your database. The Merge Policy Configuration page appears.
- In the area corresponding to the blackout period you want to delete, click the Delete button.
- Click OK on the confirmation page to delete the blackout period.
Merges and Point-In-Time Queries
When a merge occurs, it deletes all fragments from the stands being merged that have a system timestamp older than the configured merge timestamp (unless the merge timestamp is set to 0, in which case it will delete all fragments older than the current timestamp). This can keep multiple versions of some fragments in the database. You can query the older fragments using point-in-time queries. For details, see the chapter on Point-In-Time Queries in the Application Developer's Guide.
Setting a Negative Merge Timestamp to Preserve Fragments For a Rolling Window of Time
If you are doing update operations and you want the ability to roll back to the point in time when you started, you can set the merge timestamp to a negative number to preserve fragments for the specified number of ticks. The ticks are calculated at 10,000,000 ticks per second.
For example, if you want to preserve deleted fragments for 24 hours (relative to the last merge), then you can set the merge timestamp to -864,000,000,000 (10,000,000 ticks/second times 60 seconds/minute times 60 minutes/hour times 24 hours/day). You can then use xdmp:forest-rollback on all of the forests in the database to roll back up to a day (or whatever time period you have set your negative merge timestamp).
If you do set a negative value for the merge timestamp parameter, keep in mind that you will keep deleted fragments for that period of time, so your database will be that much larger during that period. This could be significant, especially if you end up reloading several times during that period.
The following table shows the negative merge timestamp for specified periods of time.
| Time Period to Preserve Fragments | Calculation | merge timestamp Value |
|---|---|---|
| 5 minutes | 10000000 * 60 * 5 |
-3000000000 |
| 1 hour | 10000000 * 60 * 60 |
-36000000000 |
| 24 hours | 10000000 * 60 * 60 * 24 |
-864000000000 |
Monitoring a Merge
There are two main places to look for monitoring information about merges:
Messages in the ErrorLog.txt File
MarkLogic Server logs INFO level messages to the ErrorLog.txt file whenever a merge begins, completes, or is canceled. Additionally, there are other log messages that are logged at more detail logging levels during a merge. The following are some sample log messages for a typical merge:
2006-04-20 13:43:11.151 Info: Merging /var/opt/MarkLogic/Forests/bill/00000004 and /var/opt/MarkLogic/Forests/bill/00000005 to /var/opt/MarkLogic/Forests/bill/00000006 2006-04-20 13:43:15.726 Debug: OnDiskStand /var/opt/MarkLogic/Forests/bill/00000006, disk=47MB, memory=20MB 2006-04-20 13:43:15.726 Info: Merged 81 MB in 4 s at 20 MB/s to /var/opt/MarkLogic/Forests/bill/00000006 2006-04-20 13:43:15.806 Debug: ~OnDiskStand /var/opt/MarkLogic/Forests/bill/00000004 2006-04-20 13:43:15.806 Debug: ~OnDiskStand /var/opt/MarkLogic/Forests/bill/00000005 2006-04-20 13:43:15.859 Info: Deleted /var/opt/MarkLogic/Forests/bill/000000042006-04-20 13:43:15.894 Info: Deleted /var/opt/MarkLogic/Forests/bill/00000005
If you cancel a merge, you will see an message similar to the following in the ErrorLog.txt file:
2006-05-08 17:45:44.027 Error: PooledThread::run: XDMP-CANCELED: Canceled merge of stands: 13419435601900621379, 6182944041533805976 to: C:\Program Files\MarkLogic\Data\Forests\bill\0000009a
By examining the ErrorLog.txt file, you can determine when a merge started, when it completed, which stands where merged together, what stand they were merged into, the size of the merge, and other useful information.
There must be sufficient disk space on the file system in which the forest data is stored for a merge to complete successfully; if a merge runs out of disk space, it will fail with an error message. Also, there must be sufficient disk space on the file system in which the log files reside to log any activity on the system. If there is no space left on the log file device, MarkLogic Server will abort. Additionally, if there is no disk space available to add messages to the log files, MarkLogic Server will fail to start.
Database Status Page
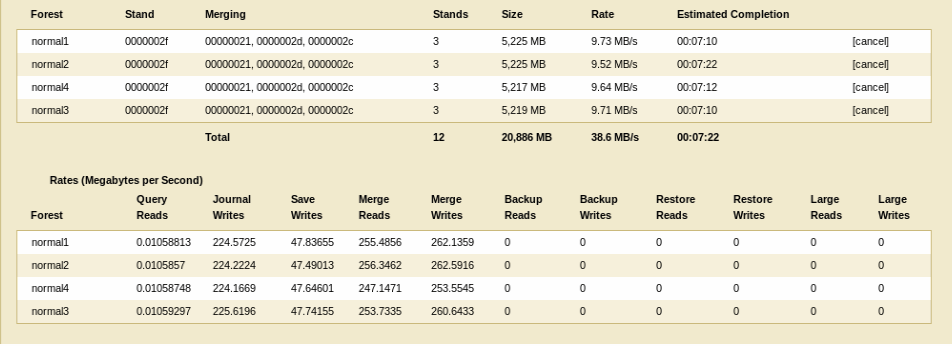
You can access the Database Status page by clicking the Databases > db_name link in the tree menu, then clicking the Status tab in the Admin Interface. The Database Status page lists the merge state, which indicates if a merge is going on, shows the size of the merge, and estimates how long it will take the merge to complete. Additionally, the Database Status page includes a link to cancel the current merge (for details, see Cancelling a Merge).
During a merge, the merge rates are reported, as shown below. The rate reported in the Merging status is the merge rate of all merges on the forest, averaged over the last few seconds. The Merge Reads and Writes reported in the Rates status are the merge rates for the current merge, averaged over the entire duration of that merge.
Explicit Merge Commands
This section describes how to manually perform the following operations:
Manually Initiating a Merge
You can manually initiate a merge, either by explicitly issuing the xdmp:merge command as described in Merging the Forests in a Database in the Scripting Administrative Tasks Guide, or by clicking the Merge button on the database configuration page of the Admin Interface. Either of these actions will immediately begin a merge on the database (if using xdmp:merge, on the database to which the App Server that responds to the request is connected, or if using the Admin Interface, the database being configured). Manually initiated merges continue even when merges are disabled for a database.
When you issue an xdmp:merge command or click the Merge button, it will begin a merge even if one would not occur automatically. If no options are specified to xdmp:merge, default values are used (not the configured values for the database).
If you have updates occurring on the system while a merge is in progress, the new fragments will not be merged during the active merge operation; they will be merged during a subsequent merge.
Manually initiating a merge is useful when you have your merge controls set such that very large merges do not occur (for example, merge min ratio set to 1), but you want to run the large merges during a period of low activity on your system. It can also be useful for expunging deleted fragments that have not yet reached the threshold for automatic merges. Note that if a merge timestamp is set on the database, even a forced merge will not merge out deleted fragments up to the merge timestamp. In normal situations, deleted fragments are retained for a short period of time. If you want to forcibly merge those, you need to explicitly set the merge-timestamp option to the current timestamp in your xdmp:merge call.
The xdmp:merge API also allows you to specify options to the merge to control the maximum merge size, the forests which are merged, whether to merge to a single stand, as well as other options. For details, see xdmp:merge in the MarkLogic XQuery and XSLT Function Reference.
Cancelling a Merge
You can cancel a merge in the Database Status page of the Admin Interface (Databases > db_name > Status tab). If you access the status page for a database during a merge, on the part of the status page for the stand(s) being merged, there is a cancel button (usually on the bottom right of the status page).

When you cancel a merge, the new stand that has not completed its merge is discarded, leaving the unmerged stands as they were before the merge began. Note that if you cancel an automatic merge, it might start up a new merge as soon as it is canceled (if the merge controls are set such that a merge is triggered). To avoid this situation, you can change some of the merge control parameters before you cancel an automatic merge.
- Click the Databases menu item in the Admin Interface.
- Click the name of the database, either from the tree menu or from the summary page.
- Click the Status tab.
- At the bottom right of the Database Status page, click the cancel button on the row for the stand being merged.
- Click OK on the Cancel Merge confirmation page.
The merge is canceled and the Database Status page appears again.
Configuring Merge Policy Rules
By changing some of the merge policy parameters, you can effectively control certain aspects of your merges. The descriptions in Description of Merge Policy Parameters describes what each parameter does. This section describes some scenarios with suggestions for how to tune the merge control parameters to satisfy the conditions. It includes the following parts:
- Determine the Baseline for Your Merges
- If You Want to Reduce the Number of 'Large' Merges
- Other Solutions
Determine the Baseline for Your Merges
The merge characteristics of your system depend on many factors, including the size of your forests, the amount of update activity on the system, and the way your data is fragmented. If you feel you need to change the configuration of your merges, the first step is to determine the merge characteristics for your database. This requires running your system under normal loads, then analyzing the log files to determine the following about your merges:
- average size of the merges
- average frequency of the merges
- average time it takes for the merges to complete
If it turns out that your merges are never taking more than a few minutes to complete, then there is probably no need to change any of your settings.
If You Want to Reduce the Number of 'Large' Merges
In most cases, MarkLogic Server will perform relatively small merges just often enough to keep the system properly optimized. Small merges are generally not very disruptive and reasonably fast. In some cases, however, you might find that your merges are too large and are taking too much time. Exactly how large constitutes a Large merge is difficult to measure, but if you determine that your merges are too large, then you might want to try and configure your settings to avoid a really large merge.
One way to avoid large merges is to set the merge max size value. If you do set this value, however, you should only set it to a value as a temporary way to control your maximum merge size, as it can lead to a state where the database really needs to perform a large merge but cannot. Such a situation can lead to a poorly optimized system. One way to think about large merges is to compare them to sleeping for people; a person can go without much sleep for relatively short periods of time (a day or two or maybe even three for some people), but eventually, the person needs sleep or else he begins to function extremely poorly. Similarly, if a database is growing, it will eventually need to perform a large merge. Also, be careful not to set merge max size to such a small value that you end up with a very large number of stands. Always use care when setting the merge max size value, as you might end up with a large number of stands in your database, which can cause it to perform poorly and, when it reaches the maximum number of stands (64), will cause it to go offline.
Another way to accomplish a goal of reducing the number of large merges is to lower the value for merge min ratio to 1. A value of 1 for merge min ratio will not stop large merges from happening, but will make large merges only occur when the number of fragments in your largest stand is equal to the number of fragments in all of the other stands combined. Therefore, the only time merges will be more than 1/2 the size of your forest is when the fragment count of the sum of all but the largest stand is equal to or greater than the fragment count of the largest stand. To illustrate this, consider a forest with the following scenario:

If the merge min ratio is set to 1, then a stand can merge if the following ratio is less than 1:
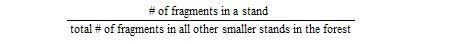
Substituting in the values from the example for stand 1 yields:
10000/(5000 + 1000 + 500) = 10000/6500 = 1.54
which is greater than 1. Therefore stand 1 is not merged. Next putting in the values for stand 2 yields:
5000/(1000 + 500) = 5000/1500 = 3.33
which is greater than 1. Therefore stand 2 is not merged. Next putting in the values for stand 3 yields:
1000/500 = 2.0
which is greater than 1. Therefore stand 3 is not merged. Therefore, if the forest remains in a steady state (that is, no new content is added), then a merge min ratio of 1 will cause this forest to not be merged.
Now, consider that a load is happening during this time and a stand that has 501 fragments is saved into the forest. The result is 5 stands as follows:

Now, substituting in the values for stand 3 yields:
1000/(500 + 501) = 1000/1001 = 0.99
which is less than 1. Therefore stand 3 is merged. Note that stands 4 and 5 are smaller than stand 3, so the sum of the fragments in those stands appear in the denominator of the merge min ratio. Therefore stands 3, 4, and 5 are merged. Therefore, a merge min ratio of 1 will cause this forest to be merged down to 3 stands, where stands 1 and 2 remain unmerged and stands 3, 4, and 5 are merged together into a new stand. The stands will now look as follows:

Note that, in a real world scenario with relatively large forests, this scenario (where the sum of the smaller stands fragment counts have as many fragments as the largest stand) will not happen very often, but will happen occasionally. For example, if another 3,000 fragments continued to accumulate in this forest, then stand 1 would merge with the other stands.
Other Solutions
In some cases, changing the merge parameters might not be the best solution for your system. For example, if your merges are taking a very long time due to slow disk drives or other system contention, addressing those issues might do more to help your merge times than any amount of tuning can do. Also, if your merges are extremely large, it could be that the forests are larger than optimal. There is no fixed maximum size for a forest, but experience in the field has shown that when forests grow over 512GB, query performance tends to start to decrease while merge times tend to start to increase. If your forests are larger than 512GB, consider breaking them into multiple forests.