
MarkLogic 9 Product DocumentationSemantics Developer's Guide — Chapter 7
Inference
In the context of MarkLogic Semantics, and semantic technology in general, the process of inference involves the automated discovery of new facts based on a combination of data and rules for understanding that data. Inference is the process of inferring or discovering new facts about your data based on a set of rules. Inference with semantic triples means that automatic procedures can generate new relationships (new facts) from existing triples.
An inference query is any SPARQL query that is affected by automatic inference. The W3C specification describing inference, with links to related standards, can be found here: http://www.w3.org/standards/semanticweb/inference
New facts may be added to the database (forward-chaining inference), or they may be inferred at query time (backward chaining inference), depending on the implementation. MarkLogic supports automatic backward-chaining inference.
This chapter includes the following sections:
- Automatic Inference
- Other Ways to Achieve Inference
- Performance Considerations
- Using Inference with the REST API
- Summary of APIs Used for Inference
Automatic Inference
Automatic inference is done using rulesets and ontologies. As the name implies, automatic inference is performed automatically and can also be centrally managed. MarkLogic semantics uses backward-chaining inference, meaning that the inference is performed at query time. This is very flexible; it means you can specify which ruleset(s) and ontology (or ontologies) to use per-query, with default rulesets per-database.
This section includes these topics:
Ontologies
An ontology is used to define the semantics of your data; it describes relationships in your data that can be used to infer new facts about your data. In Semantics, an ontology is a set of triples that provides a semantic model of a portion of the world, a model that enables knowledge to be represented for a particular domain (relationships between people, types of publications, or a taxonomy of medications). This knowledge model is a collection of triples used to describe the relationships in your data. Different vocabularies can supply sets of terms to define concepts and relationships to represent facts.
An ontology describes what types of things exist in the domain and how they are related. A vocabulary is composed of terms with clear definitions controlled by some internal or external authority. For example, the ontology triple ex:dog skos:broader ex:mammal states that dog is part of the broader concept mammal.
This SPARQL example inserts that ontology triple into a graph.
PREFIX skos: <http://www.w3.org/2004/02/skos/core#Concept/> PREFIX ex: <http://example.org/> INSERT DATA { GRAPH <http://marklogic.com/semantics/animals/vertebrates> { ex:dog skos:broader ex:mammal . }}
You may want to use an ontology you have created to model your business or your area of research, and use that along with one or more rulesets to discover additional information about your data.
The rulesets are applied across all of the triples in scope for the query, including onotology triples. Ontology triples have to be in scope for the query in order to be used. There are multiple ways to do this:
- Use
FROMorFROM NAMED/GRAPHin the query to specify what data is being accessed. Ontologies are organized by collection/named graph. - Use
default-graph=andnamed-graph=options to sem:sparql or sem:sparql-update. - Use a
cts:queryto exclude data to be queried. Ontologies can be organized by directory, or anything else that acts:querycan find. - Add the ontology to an in-memory store, and query across both the database and the in-memory store. In this case, the ontology is not stored in the database, and can be manipulated and changed for each query.
- Add the ontology to a ruleset as axiomatic triples. Axiomatic triples are triples that the ruleset says are always true - indicated by having an empty
WHEREclause in the rule. You can then choose to include the ontologies in certain ruleset files or not at query time.
Rulesets
A ruleset is a set of inference rules, or rules that can be used to infer additional facts from data. Rulesets are used by the inference engine in MarkLogic to infer new triples from existing triples at query time. A ruleset may be built up by importing other rulesets. Inference rules enable you to search over both asserted triples and inferred triples. The semantic inference engine uses rulesets to create new triples from existing triples at query time.

For example, if you know that John lives in London and London is in England, you (as a human) know that John lives in England. You inferred that fact. Similarly, if there are triples in the database that say that John lives in London and that London is in England, and there are also triples that express the meaning of lives in and is in as part of an ontology, MarkLogic can infer that John lives in England. When you query your data for all the people that live in England, John will be included in the results.
Here is a simple custom rule (ruleset) to express the concept of lives in:
# geographic rules for inference PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema/> PREFIX ex: <http://example.com/> PREFIX gn: <http://www.geonames.org/ontology/> RULE "livesIn" CONSTRUCT { ?person ex:livesIn ?place2 } { ?person ex:livesIn ?place1 . ?place1 gn:parentFeature ?place2 }
This rule states (reading from the bottom up): if place1 is in (has a parentFeature) place2, and a person lives in place1, then a person also lives in place2.
Inference that is done at query time using rulesets is referred to as backward chaining inference. Each SPARQL query looks at the specified ruleset(s) and creates new triples based on the results. This type of inferencing is faster during ingestion and indexing, but potentially a bit slower at query time. In general, inference becomes more expensive (slower) as you add more (and more complex) rules.
MarkLogic allows you to apply just the rulesets you need for each query. For convenience, you can specify the default ruleset or rulesets for a database, but you can also ignore those defaults for certain queries. It is possible to override the default ruleset association to allow querying without using inferencing and/or querying with alternative rulesets.
This section includes these topics:
- Pre-Defined Rulesets
- Specifying Rulesets for Queries
- Using the Admin UI to Specify a Default Ruleset for a Database
- Overriding the Default Ruleset
- Creating a New Ruleset
- Ruleset Grammar
- Example Rulesets
Pre-Defined Rulesets
Some pre-defined, standards-based rulesets (RDFS, RDFS-Plus, and OWL Horst) for inference are included with MarkLogic semantics. The rulesets are written in a language specific to MarkLogic that has the same syntax as the SPARQL CONSTRUCT query. Each ruleset has two versions; the full ruleset (xxx-full.rules) and the optimized version (xxx.rules).
The components of each of these rulesets are available separately so that you can do fine-grained inference with queries. You can also create your own rulesets by importing some of those rulesets and/or writing your own rules. See Creating a New Ruleset for more information.
To see these pre-defined rulesets (in Linux), go to the Config directory under your MarkLogic install directory (/MarkLogic_install_dir/Config/*.rules). For example:
/opt/MarkLogic/Config/*.rules
You will see a set of files with the .rules extension. Each of these .rules files is a ruleset. For a Windows installation, these files are usually located in C:\Program Files\MarkLogic\Config).
Here is an example of the rule domain.rules:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema/> tbox { ?p rdfs:domain ?c . } RULE "domain axioms" construct { rdfs:domain rdfs:domain rdf:Property . rdfs:domain rdfs:range rdfs:Class . } {} RULE "domain rdfs2" CONSTRUCT { ?x a ?c } { ?x ?p ?y . ?p rdfs:domain ?c }
In this example, a means type of (rdf:type or rdfs:type). The domain rdfs2 rule states that if all the things in the second set of braces are true (p has domain c; that is, for every triple that has the predicate p, the object must be in the domain c), then construct the triple in the first set of braces (if you see x p y, then x is a c).
If you open a rule in a text editor, you will see that some of the rulesets are componentized; they are defined in small component rulesets, then built up into larger rulesets. For example, rdfs.rules imports four other rules to create the optimized set of rdfs rules:
# RDFS 1.1 optimized rules prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> import "domain.rules" import "range.rules" import "subPropertyOf.rules" import "subClassOf.rules" RULE "rdf classes" construct { ... ...
By using a building block approach to using (and creating) rulesets, you can enable only the rules you really need, so that your query can be as efficient as possible. The syntax for rulesets is similar to the syntax for SPARQL CONSTRUCT.
Specifying Rulesets for Queries
You can choose which rulesets to use for your SPARQL query by using sem:ruleset-store. The ruleset is specified as part of the function. The sem:ruleset-store function returns a set of triples that result from the application of the ruleset to the triples defined by the sem:store function provided in $store (for example, all of the triples that can be inferred from this rule).
This statement specifies the rdfs.rules ruleset as part of sem:ruleset-store:
let $rdfs-store := sem:ruleset-store("rdfs.rules",sem:store() )
So this says, let $rdfs-store contain triples derived by inference using the rdfs.rules against the sem:store. If no value is provided for sem:store, the query uses the triples in the current database's triple index. The built-in functions sem:store and sem:ruleset-store are used to define the triples over which to query and the rulesets (if any) to use with the query. The $store definition includes a ruleset, as well as other ways of restricting a query's domain, such as a cts:query.
This example uses the pre-defined rdfs.rules ruleset:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $sup := 'PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> INSERT DATA { <someMedicalCondition> rdf:type <osteoarthritis> . <osteoarthritis> rdfs:subClassOf <bonedisease> . }' return sem:sparql-update($sup) ; (: transaction separator :) let $sq := 'PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX d: <http://diagnoses#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?diagnosis WHERE { ?diagnosis rdf:type <bonedisease>. } ' (: rdfs.rules is a predefined ruleset :) let $rs := sem:ruleset-store("rdfs.rules", sem:store()) return sem:sparql($sq, (), (), $rs) (: the rules specify that query for <bonedisease> will return the subclass <osteoarthritis> :)
If graph URIs are included as part of a SPARQL query that includes sem:store or sem:ruleset-store, the query will include triples that are in the store and also in these graphs.
This example is a SPARQL query against the data in $triples, using the rulesets rdfs:subClassOf and rdfs:subPropertyOf:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $triples := sem:store((), cts:word-query("henley")) return sem:sparql(" PREFIX skos: <http://www.w3.org/2004/02/skos/core#Concept/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT * { ?c a skos:Concept; rdfs:label ?l }",(),(), sem:ruleset-store(("subClassOf.rules","subPropertyOf.rules"), ($triples)) )
You can manage the default rulesets for a database using the Admin UI, the REST Mangement API, or XQuery Admin API. See Using the Admin UI to Specify a Default Ruleset for a Database for information about specifying rulesets with the Admin UI. See the default-ruleset property in PUT /manage/v2/databases/{id|name}/properties for REST Management API details. See admin:database-add-default-ruleset for Admin API details.
Using the Admin UI to Specify a Default Ruleset for a Database
You can use the Admin UI to set the default ruleset to be used for queries against a specific database (for example, when using this database, use this ruleset for queries).
To specify the ruleset or rulesets for a database:
- Click the Databases in left tree menu of the Admin UI.
- Click the database name to expand the list and scroll to Default Rulesets.
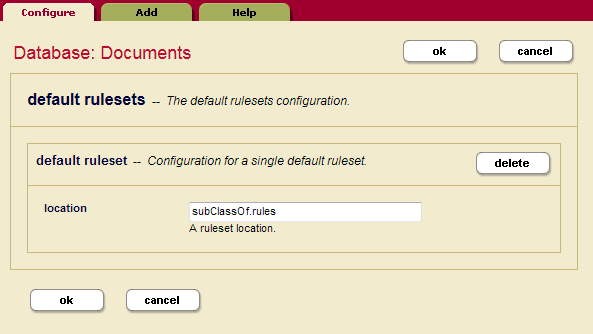
- Click Default Rulesets to see the rulesets currently associated with the Documents database.
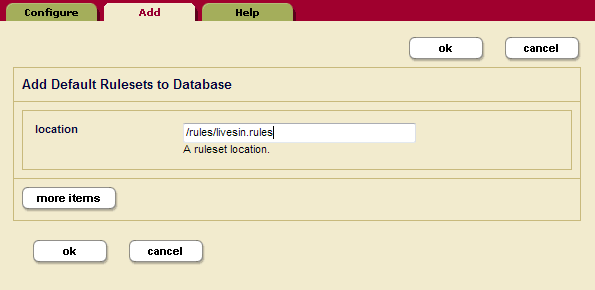
- To add your own ruleset, click Add to enter the name and location of the ruleset.
- Your custom rulesets will be located in the schemas database.
The rulesets supplied by MarkLogic are located in the Config directory under your MarkLogic installation directory (
/MarkLogic_install_dir/Config/*.rules). - Click more items to associate additional rulesets with this database.
Security for rulesets is managed the same way that security is handled for MarkLogic schemas.
You can use Query Console to find out what default rulesets are currently associated with a database using the admin:database-get-default-rulesets function.
This example will return the name and location of the default rulesets for the Documents database:
xquery version "1.0-ml"; import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $config := admin:get-configuration() let $dbid := admin:database-get-id($config, "Documents") return admin:database-get-default-rulesets($config, $dbid) => <default-ruleset xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://marklogic.com/xdmp/database"> <location>/rules/livesin.rules</location> </default-ruleset>
If you have a default ruleset associated with a database and you specify a ruleset as part of your query, both rulesets will be used. Rulesets are additive. Use the no-default-ruleset option in sem:store to ignore the default ruleset.
Overriding the Default Ruleset
You can turn off or ignore a ruleset set as the default on a database. In this example, a SPARQL query is executed against the database, ignoring the default rulesets and using the rdfs:subClassOf inference ruleset for the query:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql(" PREFIX skos: <http://www.w3.org/2004/02/skos/core#Concept/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT * { ?c a skos:Concept; rdfs:label ?l }",(),(), sem:ruleset-store("subClassOf.rules",sem:store("no-default-rulesets")) )
You can also turn off or ignore a ruleset as part of a query, through the Admin UI, or by using XQuery or JavaScript to specify the ruleset.
You can also change the default ruleset for a database in the Admin UI by deleting the default ruleset from that database. In the Admin UI, select the database name from the left navigation panel, click the database name. Click Default Rulesets.
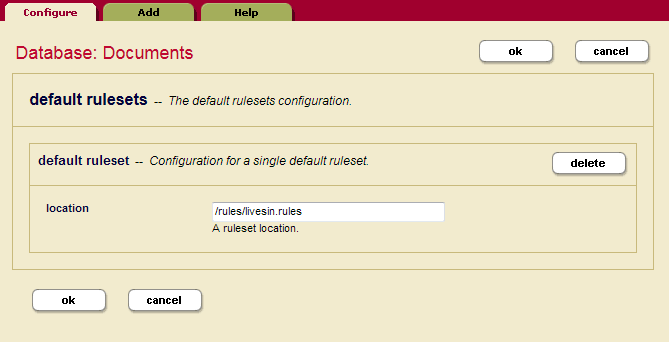
On the Database: Documents panel, select the default ruleset you want to remove, and click delete. Click ok when you are done. The ruleset is no longer the default ruleset for this database.
This action does not delete the ruleset, only removes it as the default ruleset.
You can also use admin:database-delete-default-ruleset with XQuery to change a database's default ruleset. This example removes subClassOf.rules as the default ruleset for the Documents database.
xquery version "1.0-ml"; import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $config := admin:get-configuration() let $dbid := admin:database-get-id($config, "Documents") let $rules := admin:database-ruleset("subClassOf.rules") let $c := admin:database-delete-default-ruleset($config, $dbid, $rules) return admin:save-configuration($c)
Creating a New Ruleset
You can create your own rulesets to use for inference in MarkLogic. MarkLogic rulesets are written in a language specific to MarkLogic, based on the SPARQL CONSTRUCT query.
One way to think of inference rules is as a way to construct some inferred triples, then search over the new data set (one that includes the portion of the database defined by the sem:store plus the inferred triples).
The MarkLogic-supplied rulesets are located in the install directory:
/MarkLogic_install_dir/Config/*.rules
When you create a custom ruleset, insert it into the schemas database and refer to it as a URI in the schemas database. A ruleset location is either a URI for the database you are using in the schemas database, or a filename in MarkLogic_Install_Directory/Config.
MarkLogic will search first for the MarkLogic-provided rulesets in /Config and then in the schemas database for any other rulesets.
Ruleset Grammar
MarkLogic rulesets are written in a language specific to MarkLogic. The language is based on the SPARQL 1.1 grammar. The syntax of an inference rule is similar to the grammar for SPARQL CONSTRUCT, with the WHERE clause restricted to a combination of only triple patterns, joins, and filters. The ruleset must have a unique name.
The following grammar specifies the MarkLogic Ruleset Language.
Rules ::= RulePrologue Rule* Rule ::= 'RULE' RuleName 'CONSTRUCT' ConstructTemplate 'WHERE'? RuleGroupGraphPattern RuleName ::= String RuleGroupGraphPattern ::= '{' TriplesBlock? ( ( Filter RuleGroupGraphPattern ) '.'? TriplesBlock? )* '}' RulePrologue ::= ( BaseDecl | PrefixDecl | RuleImportDecl )* RuleImportDecl ::= 'IMPORT' RuleImportLocation RuleImportLocation ::= String
The String for RuleImportLocation must be a URI for the location of the rule to be imported. Non-terminals that are not defined here (like BaseDecl) are references to productions in the SPARQL 1.1 grammar.
- The grammar restricts the contents of a rule's
WHEREclause, and it is further restricted during static analysis to a combination of only triple patterns, joins, and filters. - Comments are allowed using standard SPARQL comment syntax (comments in the form of
#, outside an IRI or string, and continuing to the end of line). - A MarkLogic ruleset uses the extension
.rulesand has a mimetype ofapplication/vnd.marklogic-ruleset. - Some kinds of property path operators (
/,^, for instance) can be used as part of ruleset. However, you cannot use these operators as part of a property path in a ruleset: |, ?, *, or +.
The import statement in the prolog includes all rules from the ruleset found at the location given, and all other rulesets imported transitively. If a ruleset at a given location is imported more than once, the effect of the import will be as if it had only been imported once. If a ruleset is imported more than once from different locations, MarkLogic will assume that they are different rulesets and raise an error because of the duplicate rule names they contain (XDMP-DUPRULE).
Example Rulesets
This ruleset (subClassOf.rules) from the /MarkLogic_Install/Config directory includes prefixes, and has rule names and a CONSTRUCT clause. The subClassOf rdfs9 rule is the one doing the work:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> tbox { ?c1 rdfs:subClassOf ?c2 . } RULE "subClassOf axioms" CONSTRUCT { rdfs:subClassOf rdfs:domain rdfs:Class . rdfs:subClassOf rdfs:range rdfs:Class . } {} RULE "subClassOf rdfs9" CONSTRUCT { ?x a ?c2 } { ?x a ?c1 . ?c1 rdfs:subClassOf ?c2 . FILTER(?c1!=?c2) }
Note that the subClassOf rdfs9 rule also includes a FILTER clause.
This ruleset from same directory (rdfs.rules) imports smaller rulesets to make a ruleset approximating the full RDFS ruleset:
# RDFS 1.1 optimized rules PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> import "domain.rules" import "range.rules" import "subPropertyOf.rules" import "subClassOf.rules" RULE "rdf classes" CONSTRUCT { rdf:type a rdf:Property . rdf:subject a rdf:Property . rdf:predicate a rdf:Property . rdf:object a rdf:Property . rdf:first a rdf:Property . rdf:rest a rdf:Property . rdf:value a rdf:Property . rdf:nil a rdf:List . } {} RULE "rdfs properties" CONSTRUCT { rdf:type rdfs:range rdfs:Class . rdf:subject rdfs:domain rdf:Statement . rdf:predicate rdfs:domain rdf:Statement . rdf:object rdfs:domain rdf:Statement . rdf:first rdfs:domain rdf:List . rdf:rest rdfs:domain rdf:List . rdf:rest rdfs:range rdf:List . rdfs:isDefinedBy rdfs:subPropertyOf rdfs:seeAlso . } {} RULE "rdfs classes" CONSTRUCT { rdf:Alt rdfs:subClassOf rdfs:Container . rdf:Bag rdfs:subClassOf rdfs:Container . rdf:Seq rdfs:subClassOf rdfs:Container . rdfs:ContainerMembershipProperty rdfs:subClassOf rdf:Property . } {} RULE "datatypes" CONSTRUCT { rdf:XMLLiteral a rdfs:Datatype . rdf:HTML a rdfs:Datatype . rdf:langString a rdfs:Datatype . } {} RULE "rdfs12" CONSTRUCT { ?p rdfs:subPropertyOf rdfs:member } { ?p a rdfs:ContainerMembershipProperty }
This is the custom rule shown earlier that you could create and use to infer information about geographic locations:
# geographic rules for inference PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema/> PREFIX ex: <http://example.com/> PREFIX gn: <http://www.geonames.org/ontology/> RULE "lives in" CONSTRUCT { ?person ex:livesIn ?place2 } { ?person ex:livesIn ?place1 . ?place1 gn:parentFeature ?place2 }
Add the livesIn rule to the schemas database using xdmp:document-insert and Query Console. Make sure the schemas database is selected as the Content Source before you run the code:
xquery version "1.0-ml"; xdmp:document-insert( '/rules/livesin.rules', text{' # geographic rules for inference PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema/> PREFIX ex: <http://example.com/> PREFIX gn: <http://www.geonames.org/ontology/> RULE "lives in" CONSTRUCT { ?person ex:livesIn ?place2 } { ?person ex:livesIn ?place1 . ?place1 gn:parentFeature ?place2 }' })
The example stores the livesin.rule in the schemas database, in the rules directory (/rules/livesin.rules). You can include your ruleset as part of inference in the same way you can include the supplied rulesets. MarkLogic will check the location for rules in the schemas database and then the location for the supplied rulesets.
Memory Available for Inference
The default, maximum, and minimum inference size values are all per-query, not per-system. The maximum inference size is the memory limit for inference. The appserver-max-inference-size function allows the administrator to set a memory limit for inference. You cannot exceed this amount.
The default inference size is the amount of memory available to use for inference. By default the amount of memory available for inference is 100mb (size=100). If you run out of memory and get an inference full error (INFFULL), you need to increase the default memory size using
admin:appserver-set-default-inference-size or by changing the default inference size on the HTTP Server Configuration page in the Admin UI.
You can also set the inference memory size in your query as part of sem:ruleset-store. This query sets the memory size for inference to 300mb (size=300):
Let $store := sem:ruleset-store(("baseball.rules", "rdfs-plus-full.rules"), sem:store(), ("size=300"))
If your query returns an INFFULL exception, you can to change the size in ruleset-store.
A More Complex Use Case
You can use inference in more complex queries. This is a JavaScript example of a SPARQL query where an ontology is added to an in-memory store. The in-memory store uses inference to discover recipes that use soft goat's cheese. The query then returns the list of possible recipe titles.
var sem = require("/MarkLogic/semantics.xqy"); var inmem = sem.inMemoryStore( sem.rdfParse(...Äò prefix ch: <http://marklogic.com/semantics/cheeses/> prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> prefix owl: <http://www.w3.org/2002/07/owl#> prefix dcterms: <http://purl.org/dc/terms/> ch:FreshGoatsCheese owl:intersectionOf ( ch:SoftFreshCheese [ owl:hasValue ch:goatsMilk ; owl:onProperty ch:milkSource ] ) ....Äò,"turtle")); var rules = sem.rulesetStore( ["intersectionOf.rules","hasValue.rules"], [inmem,sem.store()]) sem.sparql(...Äò prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> prefix dcterms: <http://purl.org/dc/terms/> prefix f: <http://linkedrecipes.org/schema/> prefix ch: <http://marklogic.com/semantics/cheeses/> select ?title ?ingredient WHERE { ?recipe dcterms:title ?title ; f:ingredient [ a ch:FreshGoatsCheese ; rdfs:label ?ingredient] }...Äò,[],[],rules)
To get results back from this query, you would need to have a triplestore of recipes, that also includes triples describing cheese made from goat's milk.
Other Ways to Achieve Inference
Before going down the path of automatic inference, consider other ways to achieve inference that may be more appropriate for your use case.
This section includes these topics:
Using Paths
In many cases, you can do inference by rewriting your query. For example, you can do some simple inference using unenumerated property paths. Property paths (as explained in Property Path Expressions) enable a simple kind of inference.
You can find all the possible types of a resource, including supertypes of a resources, using RDFS vocabulary and the / property path in a SPARQL query:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2001/01/rdf-schema#> SELECT ?type { <http://example/thing> rdf:type/rdfs:subClassOf* ?type }
The result will be all resources and their inferred types. The unenumerated property path expression with the asterisk (*) will look for triples where the subject and object are connected by rdf:type and followed by zero or more occurrences of rdfs:subClassOf.
For example, you could use this query to find the products that are subClasses of shirt, at any depth in the hierarchy:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX ex: <http://example.com> SELECT ?product WHERE { ?product rdf:type/rdfs:subClassOf* ex:Shirt ; }
Or you could use a property path to find people who live in England:
PREFIX gn: <http://www.geonames.org/ontology/> PREFIX ex: <http://www.example.org> SELECT ?p { ?p ex:livesIn/gn:parentFeature "England" }
For more about property paths and how to use them with semantics, see Property Path Expressions.
Materialization
A possible alternative to automatic inference at query time (backward-chaining inference) is materialization or forward-chaining inference, where you perform inference on parts of your data, not as part of a query, and then store those inferred triples to be queried later. Materialization worsk best for triple data that is fairly static; performing inference with rules and ontologies that do not change often.
This process of materialization at ingestion or update time may be time-consuming and will require a significant amount of disk space for storage. You will need to write code or scripts to handle transactions and security and to handle changes in data and ontologies.
These tasks are all handled for you if you choose automatic inference.
Materialization can be very useful if you need very fast queries and you are prepared to do the pre-processing work up front and use the extra disk space for the inferred triples. You may want to use this type of inference in situations where the data, rulesets, your ontologies, and some parts of your data do not change very much.
You can mix and match; materialize some inferred triples that do not change very much (such as ontology triples: for example, a customer is a person is a legal entity), while using automatic inference for triples that change or are added to more often. You can also use automatic inference where inference has a broader scope (new-order-111 contains line-item-222, which contains product-333, which is related to accessory-444).
Performance Considerations
The key to making your SPARQL queries run fast is partitioning the data (by writing a sufficiently rich query that the number of results returned is small). Backward-chaining inference will run faster in the available memory if it is querying over fewer triples. To achieve this, make your inference queries very selective by using a FILTER or constraining the scope of the query through cts:query (for example a collection-query).
Partial Materialization
You can do partial materialization of data, rulesets, and ontologies that you use frequently and that do not change often. You can perform inference on parts of your data to materialize the inferred triples and use these materialized triples in your inference queries.
To materialize these triples, construct SPARQL queries for the rules that you want to use for inference and run them on your data as part of your ingestion or update pipeline.
Using Inference with the REST API
When you execute a SPARQL query or update using the REST Client API methods POST /v1/graphs/sparql or GET /v1/graphs/sparql, you can specify rulesets through the request parameters default-rulesets and rulesets. If you omit both of these parameters, the default rulesets for the database are applied.
After you set rdfs.rules and equivalentProperties.rules as the default rulesets for the database, you can perform this SPARQL query using REST from the Query Console:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $uri := "http://localhost:8000/v1/graphs/sparql" return let $sparql :=' PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX prod: <http://example.com/products/> PREFIX ex: <http://example.com/> SELECT ?product FROM <http://marklogic.com/semantics/products/inf-1> WHERE { ?product rdf:type ex:Shirt ; ex:color "blue" } ' let $response := xdmp:http-post($uri, <options xmlns="xdmp:http"> <authentication method="digest"> <username>admin</username> <password>admin</password> </authentication> <headers> <content-type>application/sparql-query</content-type> <accept>application/sparql-results+xml</accept> </headers> </options> text {$sparql}) return ($response[1]/http:code, $response[2] /node()) => product <http://example.com/products/1001> <http://example.com/products/1002> <http://example.com/products/1003>
Using the REST endpoint and curl (with the same default rulesets for the database), the same query would look like this:
curl --anyauth --user Admin:janem-3 -i -X POST \ -H "Content-type:application/x-www-form-urlencoded" \ -H "Accept:application/sparql-results+xml" \ --data-urlencode query='PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> \ PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX prod: <http://example.com/products/> \ PREFIX ex: <http://example.com/> \ SELECT ?product FROM <http://marklogic.com/semantics/products/inf-1> \ WHERE {?product rdf:type ex:Shirt ; ex:color "blue"}' \ http://localhost:8000/v1/graphs/sparql
To run this curl example, remove the \ characters and make the command one line. See Using Semantics with the REST Client API and Querying Triples in the REST Application Developer's Guide for more information.
Summary of APIs Used for Inference
MarkLogic has APIs that can be used for semantic inference. Semantic APIs are available for use as part of the actual inference query (specifying which triples to query and which rules to apply). Database APIs can be used to choose rulesets to be used for inference by a particular database. Management APIs can control the memory used by inference by either an appserver or a taskserver.
Semantic APIs
MarkLogic Semantic APIs can be used for managing triples for inference and for specifying rulesets to be used with individual queries (or by default with databases). Stores are used to identify the subset of triples to be evaluted by the query.
| Semantic API | Description |
|---|---|
| sem:store | The query argument of sem:sparql accepts sem:store to indicate the source of the triples to be evaluated as part of the query. If multiple sem:store constructors are supplied, the triples from all the sources are merged and queried together. The sem:store can contain one or more options along with a |
| sem:in-memory-store | Returns a sem:store that represents the set of triples from the sem:triple values passed in as an argument. The default rulesets configured on the current database have no effect on a sem:store created with sem:in-memory-store. |
| sem:ruleset-store | Returns a new sem:store that represents the set of triples derived by applying the ruleset to the triples in sem:store in addition to the original triples. |
Use the sem:in-memory-store function with sem:sparql in preference to the deprecated sem:sparql-triples function (available in MarkLogic 7). The cts:query argument to sem:sparql has also been deprecated.
If you call sem:sparql-update with a store that is based on in-memory triples (that is, a store that was created by sem:in-memory-store) you will get an error because you cannot update triples that are in memory and not on disk. Similarly, if you pass in multiple stores to sem:sparql-update and any of them is based on in-memory triples you will get an error.
Database Ruleset APIs
These Database Ruleset APIs are used to manage the rulesets associated with databases.
| Ruleset API | Description |
|---|---|
| admin:database-ruleset | The ruleset element to be used for inference on a database. One or more rulesets can be used for inference. By default, no ruleset is configured. |
| admin:database-get-default-rulesets | Returns the default ruleset(s) for a database. |
| admin:database-add-default-ruleset | Adds a ruleset to be used for inference on a database. One or more rulesets can be used for inference. By default, no ruleset is configured. |
| admin:database-delete-default-ruleset | Deletes the default ruleset used by a database for inference. |
Management APIs
These Management APIs are used to manage memory sizing (default, minimum, and maximum) alloted for inference.
| Management API (admin:) | Description |
|---|---|
| admin:appserver-set-default-inference-size | Specifies the default value for any request's inference size on this application server. |
| admin:appserver-get-default-inference-size | Returns the default amount of memory (in megabytes) that can be used by sem:store for inference by an application server. |
| admin:taskserver-set-default-inference-size | Specifies the default value for any request's inference size on this task server. |
| admin:taskserver-get-default-inference-size | Returns the default amount of memory (in megabytes) that can be used by sem:store for inference by a task server. |
| admin:appserver-set-max-inference-size | Specifies the upper bound for any request's inference size. The inference size is the maximum amount of memory in megabytes allowed for sem:store performing inference on this application server. |
| admin:appserver-get-max-inference-size | Returns the maximum amount of memory (in megabytes) that can be used by sem:store for inference by an application server. |
| admin:taskserver-set-max-inference-size | Specifies the upper bound for any request's inference size. The inference size is the maximum amount of memory in megabytes allowed for sem:store performing inference on this task server. |
| admin:taskserver-get-max-inference-size | Returns the maximum amount of memory (in megabytes) that can be used by sem:store for inference by a task server. |