
MarkLogic 9 Product DocumentationApplication Developer's Guide — Chapter 10
Point-In-Time Queries
You can configure MarkLogic Server to retain old versions of documents, allowing you to evaluate a query statement as if you had travelled back to a point-in-time in the past. When you specify a timestamp at which a query statement should evaluate, that statement will evaluate against the newest version of the database up to (but not beyond) the specified timestamp.
This chapter describes point-in-time queries and forest rollbacks to a point-in-time, and includes the following sections:
- Understanding Point-In-Time Queries
- Using Timestamps in Queries
- Specifying Point-In-Time Queries in xdmp:eval, xdmp:invoke, xdmp:spawn, and XCC
- Keeping Track of System Timestamps
- Rolling Back a Forest to a Particular Timestamp
Understanding Point-In-Time Queries
To best understand point-in-time queries, you need to understand a little about how different versions of fragments are stored and merged out of MarkLogic Server. This section describes some details of how fragments are stored and how that enables point-in-time queries, as well as lists some other details important to understanding what you can and cannot do with point-in-time queries:
- Fragments Stored in Log-Structured Database
- System Timestamps and Merge Timestamps
- How the Fragments for Point-In-Time Queries are Stored
- Only Available on Query Statements, Not on Update Statements
- All Auxiliary Databases Use Latest Version
- Database Configuration Changes Do Not Apply to Point-In-Time Fragments
For more information on how merges work, see the Understanding and Controlling Database Merges chapter of the Administrator's Guide. For background material for this chapter, see Understanding Transactions in MarkLogic Server.
Fragments Stored in Log-Structured Database
A MarkLogic Server database consists of one or more forests. Each forest is made up of one or more stands. Each stand contains one or more fragments. The number of fragments are determined by several factors, including the number of documents and the fragment roots defined in the database configuration.
To maximize efficiency and improve performance, the fragments are maintained using a method analagous to a log-structured filesystem. A log-structured filesystem is a very efficient way of adding, deleting, and modifying files, with a garbage collection process that periodically removes obsolete versions of the files. In MarkLogic Server, fragments are stored in a log-structured database. MarkLogic Server periodically merges two or more stands together to form a single stand. This merge process is equivalent to the garbage collection of log-structured filesystems.
When you modify or delete an existing document or node, it affects one or more fragments. In the case of modifying a document (for example, an xdmp:node-replace operation), MarkLogic Server creates new versions of the fragments involved in the operation. The old versions of the fragments are marked as obsolete, but they are not yet deleted. Similarly, if a fragment is deleted, it is simply marked as obsolete, but it is not immediately deleted from disk (although you will no longer be able to query it without a point-in-time query).
System Timestamps and Merge Timestamps
When a merge occurs, it recovers disk space occupied by obsolete fragments. The system maintains a system timestamp, which is a number that increases everytime anything maintained by MarkLogic Server is changed. In the default case, the new stand is marked with the current timestamp at the time in which the merge completes (the merge timestamp). Any fragments that became obsolete prior to the merge timestamp (that is, any old versions of fragments or deleted fragments) are eliminated during the merge operation.
There is a control at the database level called the merge timestamp, set via the Admin Interface. By default, the merge timestamp is set to 0, which sets the timestamp of a merge to the timestamp corresponding to when the merge completes. To use point-in-time queries, you can set the merge timestamp to a static value corresponding to a particular time. Then, any merges that occur after that time will preserve all fragments, including obsolete fragments, whose timestamps are equal to or later than the specified merge timestamp.
The effect of preserving obsolete fragments is that you can perform queries that look at an older view of the database, as if you are querying the database from a point-in-time in the past. For details on setting the merge timestamp, see Enabling Point-In-Time Queries in the Admin Interface.
How the Fragments for Point-In-Time Queries are Stored
Just like any fragments, fragments with an older timestamp are stored in stands, which in turn are stored in forests. The only difference is that they have an older timestamp associated with them. Different versions of fragments can be stored in different stands or in the same stand, depending on if they have been merged into the same stand.
The following figure shows a stand with a merge timestamp of 100. Fragment 1 is a version that was changed at timestamp 110, and fragment 2 is a version of the same fragment that was changed at timestamp 120.
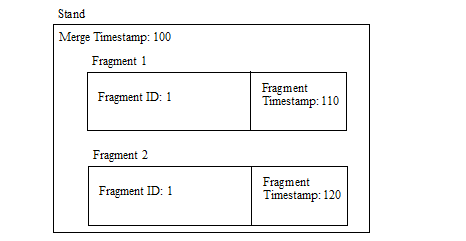
In this scenario, if you assume that the current time is timestamp 200, then a query at the current time will see Fragment 2, but not Fragment 1. If you perform a point-in-time query at timestamp 115, you will see Fragment 1, but not Fragment 2 (because Fragment 2 did not yet exist at timestamp 115).
There is no limit to the number of different versions that you can keep around. If the merge timestamp is set to the current time or a time in the past, then all subsequently modified fragments will remain in the database, available for point-in-time queries.
Only Available on Query Statements, Not on Update Statements
You can only specify a point-in-time query statement; attempts to specify a point-in-time query for an update statement will throw an exception. An update statement is any XQuery issued against MarkLogic Server that includes an update function (xdmp:document-load, xdmp:node-replace, and so on). For more information on what constitutes query statements and update statements, see Understanding Transactions in MarkLogic Server.
All Auxiliary Databases Use Latest Version
The auxiliary databases associated with a database request (that is, the Security, Schemas, Modules, and Triggers databases) all operate at the latest timestamp, even during a point-in-time query. Therefore, any changes made to security objects, schemas, and so on since the time specified in the point-in-time query are reflected in the query. For example, if the user you are running as was deleted between the time specified in the point-in-time query and the latest timestamp, then that query would fail to authenticate (because the user no longer exists).
Database Configuration Changes Do Not Apply to Point-In-Time Fragments
If you make configuration changes to a database (for example, changing database index settings), those changes only apply to the latest versions of fragments. For example, if you make index option changes and reindex a database that has old versions of fragments retained, only the latest versions of the fragments are reindexed. The older versions of fragments, used for point-in-time queries, retain the indexing properties they had at the timestamp in which they became invalid (that is, from the timestamp when an update or delete occured on the fragments). MarkLogic recommends that you do not change database settings and reindex a database that has the merge timestamp database parameter set to anything but 0.
Using Timestamps in Queries
By default, query statements are run at the system timestamp in effect when the statement initiates. To run a query statement at a different system timestamp, you must set up your system to store older versions of documents and then specify the timestamp when you issue a point-in-time query statement. This section describes this general process and includes the following parts:
- Enabling Point-In-Time Queries in the Admin Interface
- The xdmp:request-timestamp Function
- Requires the xdmp:timestamp Execute Privilege
- The Timestamp Parameter to xdmp:eval, xdmp:invoke, xdmp:spawn
- Timestamps on Requests in XCC
- Scoring Considerations
Enabling Point-In-Time Queries in the Admin Interface
In order to use point-in-time queries in a database, you must set up merges to preserve old versions of fragments. By default, old versions of fragments are deleted from the database after a merge. For more information on how merges work, see the Understanding and Controlling Database Merges chapter of the Administrator's Guide.
In the Merge Policy Configuration page of the Admin Interface, there is a merge timestamp parameter. When this parameter is set to 0 (the default) and merges are enabled, point-in-time queries are effectively disabled. To access the Merge Policy Configuration page, click the Databases > db_name > Merge Policy link from the tree menu of the Admin Interface.
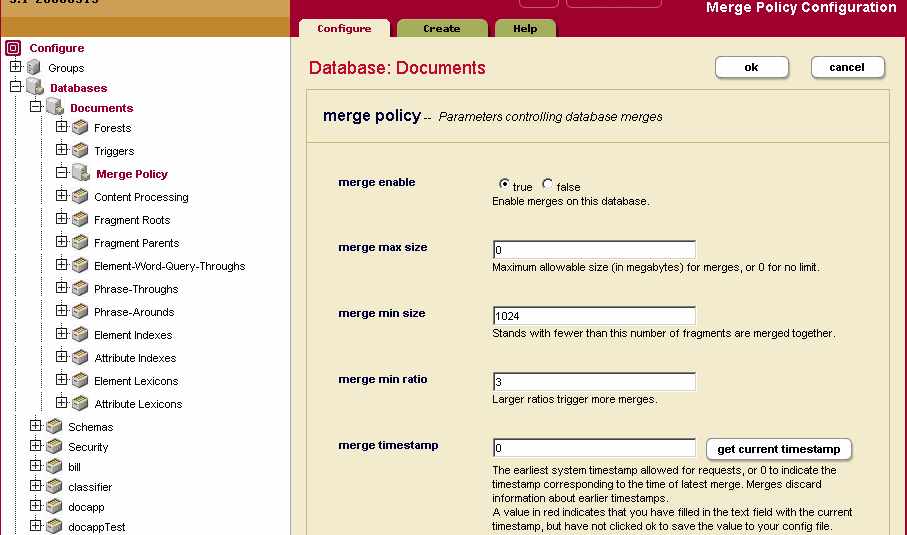
When deciding the value at which to set the merge timestamp parameter, the most likely value to set it to is the current system timestamp. Setting the value to the current system timestamp will preserve any versions of fragments from the current time going forward. To set the merge timestamp parameter to the current timestamp, click the get current timestamp button on the Merge Control Configuration page and then Click OK.
If you set a value for the merge timestamp parameter higher than the current timestamp, MarkLogic Server will use the current timestamp when it merges (the same behavior as when set to the default of 0). When the system timestamp grows past the specified merge timestamp number, it will then start using the merge timestamp specified. Similarly, if you set a merge timestamp lower than the lowest timestamp preserved in a database, MarkLogic Server will use the lowest timestamp of any preserved fragments in the database, or the current timestamp, whichever is lower.
You might want to keep track of your system timestamps over time, so that when you go to run point-in-time queries, you can map actual time with system timestamps. For an example of how to create such a timestamp record, see Keeping Track of System Timestamps.
After the system merges when the merge timestamp is set to 0, all obsolete versions of fragments will be deleted; that is, only the latest versions of fragments will remain in the database. If you set the merge timestamp to a value lower than the current timestamp, any obsolete versions of fragments will not be available (because they no longer exist in the database). Therefore, if you want to preserve versions of fragments, you must configure the system to do so before you update the content.
The xdmp:request-timestamp Function
MarkLogic Server has an XQuery built-in function, xdmp:request-timestamp, which returns the system timestamp for the current request. MarkLogic Server uses the system timestamp values to keep track of versions of fragments, and you use the system timestamp in the merge timestamp parameter (described in Enabling Point-In-Time Queries in the Admin Interface) to specify which versions of fragments remain in the database after a merge. For more details on the xdmp:request-timestamp function, see the MarkLogic XQuery and XSLT Function Reference.
Requires the xdmp:timestamp Execute Privilege
In order to run a query at a timestamp other than the current timestamp, the user who runs the query must belong to a group that has the xdmp:timestamp execute privilege. For details on security and execute privileges, see Security Guide.
The Timestamp Parameter to xdmp:eval, xdmp:invoke, xdmp:spawn
The xdmp:eval, xdmp:invoke, and xdmp:spawn functions all take an options node as the optional third parameter. The options node must be in the xdmp:eval namespace. The options node has a timestamp element which allows you to specify a system timestamp at which the query should run. When you specify a timestamp value earlier than the current timestamp, you are specifying a point-in-time query.
The timestamp you specify must be valid for the database. If you specify a system timestamp that is less than the oldest timestamp preserved in the database, the statement will throw an XDMP-OLDSTAMP exception. If you specify a timestamp that is newer than the current timestamp, the statement will throw an XDMP-NEWSTAMP exception.
If the merge timestamp is set to the default of 0, and if the database has completed all merges since the last updates or deletes, query statements that specify any timestamp older than the current system timestamp will throw the XDMP-OLDSTAMP exception. This is because the merge timestamp value of 0 specifies that no obsolete fragments are to be retained.
The following example shows an xdmp:eval statement with a timestamp parameter:
xdmp:eval("doc('/docs/mydocument.xml')", (), <options xmlns="xdmp:eval"> <timestamp>99225</timestamp> </options>)
This statement will return the version of the /docs/mydocument.xml document that existed at system timestamp 99225.
Timestamps on Requests in XCC
The xdmp:eval, xdmp:invoke, and xdmp:spawn functions allow you to specify timestamps for a query statement at the XQuery level. If you are using the XML Content Connector (XCC) libraries to communicate with MarkLogic Server, you can also specify timestamps at the Java.
In XCC for Java, you can set options to requests with the RequestOptions class, which allows you to modify the environment in which a request runs. The setEffectivePointInTime method sets the timestamp in which the request runs. The core design pattern is to set up options for your requests and then use those options when the requests are submitted to MarkLogic Server for evaluation. You can also set request options on the Session object. The following Java code snippet shows the basic design pattern:
// create a class and methods that use code similar to // the following to set the system timestamp for requests Session session = getSession(); BigInteger timestamp = session.getCurrentServerPointInTime(); RequestOptions options = new RequestOptions(); options.setEffectivePointInTime (timestamp); session.setDefaultRequestOptions (options);
For an example of how you might use a Java environment to run point-in-time queries, see Example: Query Old Versions of Documents Using XCC.
Scoring Considerations
When you store multiple versions of fragments in a database, it will subtly effect the scores returned with cts:search results. The scores are calculated using document frequency as a variable in the scoring formula (for the default score-logtfidf scoring method). The amount of effect preserving older versions of fragments has depends on two factors:
If the number of fragments with multiple versions is small compared with the total number of fragments in the database, then the effect will be relatively small. If that ratio is large, then the effect on scores will be higher.
For more details on scores and the scoring methods, see Relevance Scores: Understanding and Customizing in the Search Developer's Guide.
Specifying Point-In-Time Queries in xdmp:eval, xdmp:invoke, xdmp:spawn, and XCC
As desribed earlier, specifying a valid timestamp element in the options node of the xdmp:eval, xdmp:invoke, or xdmp:spawn functions initiates a point-in-time query. Also, you can use XCC to specify entire XCC requests as point-in-time queries. The query runs at the specified timestamp, seeing a version of the database that existed at the point in time corresponding to the specified timestamp. This section shows some example scenarios for point-in-time queries, and includes the following parts:
Example: Query Old Versions of Documents Using XCC
When making updates to content in your system, you might want to add and test new versions of the content before exposing the new content to your users. During this testing time, the users will still see the old version of the content. Then, when the new content has been sufficiently tested, you can switch the users over to the new content.
Point-in-time queries allow you to do this all within the same database. The only thing that you need to change in the application is the timestamps at which the query statements run. XCC provides a convenient mechanism for accomplishing this goal.
Example: Querying Deleted Documents
When you delete a document, the fragments for that document are marked as obsolete. The fragments are not actually deleted from disk until a merge completes. Also, if the merge timestamp is set to a timestamp earlier than the timestamp corresponding to when the document was deleted, the merge will preserve the obsolete fragments.
This example demonstrates how you can query deleted documents with point-in-time queries. For simplicity, assume that no other query or update activity is happening on the system for the duration of the example. To follow along in the example, run the following code samples in the order shown below.
- First, create a document:
xdmp:document-insert("/docs/test.xml", <a>hello</a>))
- When you query the document, it returns the node you inserted:
doc("/docs/test.xml") (: returns the node <a>hello</a> :)
- Delete the document:
xdmp:document-delete("/docs/test.xml")
- Query the document again. It returns the empty sequence because it was just deleted.
- Run a point-in-time query, specifying the current timestamp (this is semantically the same as querying the document without specifying a timestamp):
xdmp:eval("doc('/docs/test.xml')", (), <options xmlns="xdmp:eval"> <timestamp>{xdmp:request-timestamp()}</timestamp> </options>) (: returns the empty sequence because the document has been deleted :)
- Run the point-in-time query at one less than the current timestamp, which is the old timestamp in this case because only one change has happened to the database. The following query statement returns the old document.
xdmp:eval("doc('/docs/test.xml')", (), <options xmlns="xdmp:eval"> <timestamp>{xdmp:request-timestamp()-1}</timestamp> </options>) (: returns the deleted version of the document :)
Keeping Track of System Timestamps
The system timestamp does not record the actual time in which updates occur; it is simply a number that is increased each time an update or configuration change occurs in the system. If you want to map system timestamps with actual time, you need to either store that information somewhere or use the xdmp:timestamp-to-wallclock and xdmp:wallclock-to-timestamp XQuery functions. This section shows a design pattern, including some sample code, of the basic principals for creating an application that archives the system timestamp at actual time intervals.
It might not be important to your application to map system timestamps to actual time. For example, you might simply set up your merge timestamp to the current timestamp, and know that all versions from then on will be preserved. If you do not need to keep track of the system timestamp, you do not need to create this application.
The first step is to create a document in which the timestamps are stored, with an initial entry of the current timestamp. To avoid possible confusion of future point-in-time queries, create this document in a different database than the one in which you are running point-in-time queries. You can create the document as follows:
xdmp:document-insert("/system/history.xml", <timestamp-history> <entry> <datetime>{fn:current-dateTime()}</datetime> <system-timestamp>{ (: use eval because this is an update statement :) xdmp:eval("xdmp:request-timestamp()")} </system-timestamp> </entry> </timestamp-history>)
This results in a document similar to the following:
<timestamp-history> <entry> <datetime>2006-04-26T19:35:51.325-07:00</datetime> <system-timestamp>92883</system-timestamp> </entry> </timestamp-history>
Note that the code uses xdmp:eval to get the current timestamp. It must use xdmp:eval because the statement is an update statement, and update statements always return the empty sequence for calls to xdmp:request-timestamp. For details, see Understanding Transactions in MarkLogic Server.
Next, set up a process to run code similar to the following at periodic intervals. For example, you might run the following every 15 minutes:
xdmp:node-insert-child(doc("/system/history.xml")/timestamp-history, <entry> <datetime>{fn:current-dateTime()}</datetime> <system-timestamp>{ (: use eval because this is an update statement :) xdmp:eval("xdmp:request-timestamp()")} </system-timestamp> </entry>)
This results in a document similar to the following:
<timestamp-history> <entry> <datetime>2006-04-26T19:35:51.325-07:00</datetime> <system-timestamp>92883</system-timestamp> </entry> <entry> <datetime>2006-04-26T19:46:13.225-07:00</datetime> <system-timestamp>92884</system-timestamp> </entry> </timestamp-history>
To call this code at periodic intervals, you can set up a cron job, write a shell script, write a Java or dotnet program, or use any method that works in your environment. Once you have the document with the timestamp history, you can easily query it to find out what the system timestamp was at a given time.
Rolling Back a Forest to a Particular Timestamp
In addition to allowing you to query the state of the database at a given point in time, setting a merge timestamp and preserving deleted fragments also allows you to roll back the state of one or more forests to a timestamp that is preserved. To roll back one or more forests to a given timestamp, use the xdmp:forest-rollback function. This section covers the following topics about using xdmp:forest-rollback to roll back the state of one or more forests:
- Tradeoffs and Scenarios to Consider For Rolling Back Forests
- Setting the Merge Timestamp
- Notes About Performing an xdmp:forest-rollback Operation
- General Steps for Rolling Back One or More Forests
Tradeoffs and Scenarios to Consider For Rolling Back Forests
In order to roll a forest back to a previous timestamp, you need to have previously set a merge timestamp that preserved older versions of fragments in your database. Keeping deleted fragments around will make your database grow in size faster, using more disk space and other system resources. The advantage of keeping old fragments around is that you can query the older fragments (using point-in-time queries as described in the previous sections) and also that you can roll back the database to a previous timestamp. You should consider the advantages (the convenience and speed of bringing the state of your forests to a previous time) and the costs (disk space and system resources, keeping track of your system timestamps, and so on) when deciding if it makes sense for your system.
A typical use case for forest rollbacks is to guard against some sort of data-destroying event, providing the ability to get back to the point in time before that event without doing a full database restore. If you wanted to allow your application to go back to some state within the last week, for example, you can create a process whereby you update the merge timestamp every day to the system timestamp from 7 days ago. This would allow you to go back any point in time in the last 7 days. To set up this process, you would need to do the following:
- Maintain a mapping between the system timestamp and the actual time, as described in Keeping Track of System Timestamps.
- Create a script (either a manual process or an XQuery script using the Admin API) to update the merge timestamp for your database once every 7 days. The script would update the merge timestamp to the system timestamp that was active 7 days earlier.
- If a rollback was needed, roll back all of the forests in the database to a time between the current timestamp and the merge timestamp. For example:
xdmp:forest-rollback( xdmp:database-forests(xdmp:database("my-db")), 3248432) (: where 3248432 is the timestamp to which you want to roll back :)
Another use case to set up an environment for using forest rollback operations is if you are pushing a new set of code and/or content out to your application, and you want to be able to roll it back to the previous state. To set up this scenario, you would need to do the following:
Setting the Merge Timestamp
As described above, you cannot roll back forests in which the database merge timestamp has not been set. By default, the merge timestamp is set to 0, which will delete old versions of fragments during merge operations. For details, see System Timestamps and Merge Timestamps.
Notes About Performing an xdmp:forest-rollback Operation
This section describes some of the behavior of xdmp:forest-rollback that you should understand before setting up an environment in which you can roll back your forests. Note the following about xdmp:forest-rollback operations:
- An xdmp:forest-rollback will restart the specified forest(s). As a consequence, any failed over forests will attempt to mount their primary host; that is, it will result in an un-failover operation if the forest is failed over. For details on failover, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide guide.
- Use caution when rolling back one or more forests that are in the context database (that is, forests that belong to the database against which your query is evaluating against). When in a forest in the context database, the xdmp:forest-rollback operation is run asyncronously. The new state of the forest is not seen until the forest restart occurs, Before the forest is unmounted, the old state will still be reflected. Additionally, any errors that might occur as part of the rollback operation are not reported back to the query that performs the operation (although, if possible, they are logged to the
ErrorLog.txtfile). As a best practice, MarkLogic recommends running xdmp:forest-rollback operations against forests not attached to the context database. - If you do not specify all of the forests in a database to roll back, you might end up in a state where the rolled back forest is not in a consistent state with the other forests. In most cases, it is a good idea to roll back all of the forests in a database, unless you are sure that the content of the forest being rolled back will not become inconsistent if other forests are not rolled back to the same state (for example, if you know that all of content you are rolling back is only in one forest).
- If your database indexing configuration has changed since the point in time to which you are rolling back, and if you have reindexing enabled, a rollback operation will begin reindexing as soon as the rollback operation completes. If reindexing is not enabled, then the rolled backed fragments will remain indexed as they were at the time they were last updated, which might be inconsistent with the current database configuration.
- As a best practice, MarkLogic recommends running a rollback operation only on forests that have no update activitiy at the time of the operation (that is, the forests should be quiesced).
General Steps for Rolling Back One or More Forests
To roll back the state of one or more forests, perform the following general steps:
- At the state of the database to which you want to be able to roll back, set the merge timestamp to the current timestamp.
- Keep track of your system timestamps, as desribed in System Timestamps and Merge Timestamps.
- Perform updates to your application as usual. Old version of document will remain in the database.
- If you know you will not need to roll back to a time earlier, than the present, go back to step 1.
- If you want to roll back, you can roll back to any time between the merge timestamp and the current timestamp. When you perform the rollback, it is a good idea to do so from the context of a different database. For example, to roll back all of the forests in the
my-dbdatabase, perform an operation similar to the following, which sets the database context to a different one than the forests that are being rolled back:xdmp:eval( 'xdmp:forest-rollback( xdmp:database-forests(xdmp:database("my-db")), 3248432) (: where 3248432 is the timestamp to which you want to roll back :)', (), <options xmlns="xdmp:eval"> <database>{xdmp:database("Documents")}</database> </options>)