
MarkLogic Server 11.0 Product DocumentationApplication Developer's Guide — Chapter 18
Template Driven Extraction (TDE)
Template Driven Extraction (TDE) enables you to define a relational lens over your document data, so you can query parts of your data using SQL or the Optic API. Templates let you specify which parts of documents make up rows in a view. You can also use templates to define a semantic lens, specifying which values from a document make up triples in the triple index.
TDE enables you to generate rows and triples from ingested documents based on predefined templates that describe the following:
- The input data to match
- The data transformations that apply to the matched data
- The final data projections that are translated into indexed data.
TDE enables you to access the data in your documents in several ways, without changing the documents themselves. A relational lens is useful when you want to let SQL-savvy users access your data and when users want to create reports and visualizations using tools that communicate using SQL. It is also useful when you want to join entities and perform aggregates across documents. A semantic lens is useful when your documents contain some data that is naturally represented and queried as triples, using SPARQL.
TDE is applied during indexing at ingestion time and serves the following purposes:
- SQL/Relation indexing. TDE allows the user to map parts of an XML or JSON document into SQL rows. With a TDE template instance, users can create different rows and describe how each column in a row is constructed using the extracted data from a document. For details, see Creating Template Views in the SQL Data Modeling Guide.
- Custom Embedded Triple Extraction. TDE enables users to ingest triples that do not follow the sem:triple schema. A user can define many triple projections in a single template, where each projection specifies the different parts of a document that are mapped to subjects, predicates or objects. For details, see Using a Template to Identify Triples in a Document in the Semantic Graph Developer's Guide.
- Entity Services Data Models. For details, see Creating and Managing Models in the Entity Services Developer's Guide.
TDE data is also used by the Optic API, as described in Optic API for Multi-Model Data Access.
The tde-admin role is required in order to insert a template into the schema database.
The main topics in this chapter are:
- Security on TDE Documents
- Template View Elements
- JSON Template Structure
- Template Dialect and Data Transformation Functions
- Validating and Inserting a Template
- Templates and Non-Conforming Documents
- Enabling and Disabling Templates
- Deleting Templates
Security on TDE Documents
Operations on template documents are controlled by:
The http://marklogic.com/xdmp/tde collection, which is a protected collection that contains TDE template documents.
The tde-admin role, which is required to access the TDE protected collection.
The tde-view role, which is required to view documents in the TDE protected collection. Access to views can be further restricted by setting additional permissions on the template documents that define the views. Since the same view can be declared in multiple templates loaded with different permissions, the access to views must be controlled at the column level as follows:
Column level read permissions are implicit by default and are derived from the read permissions set on the template documents. Permissions can also be explicitly set on a column using the permissions element. Permissions on a column are not required to be identical and are ORed together. A user with a role that has at least one of the read permissions set on a column will be able to see the column.
If a user does not have permissions on any of the view's columns, the view itself is not visible.
For example, as shown in the illustration below:
- Template document
TD1creates viewView 1with columnC1andC2. Template documentTD1was loaded with Read Permission 1. - Template document
TD2creates viewView 1with columnC1andC3. Template documentTD2was loaded with Read Permission 2. - Users with
Permission 1have access to columnsC1andC2at query time. - Users with
Permission 2have access to columnsC1andC3at query time. - Users without
Permission 1orPermission 2will not have access toView 1or any of its columns.
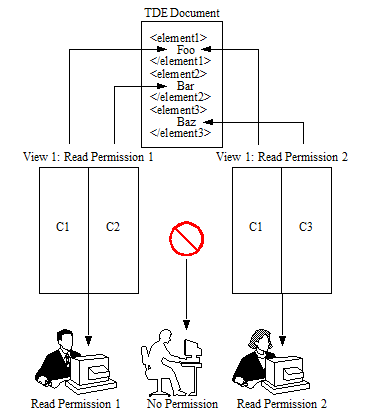
- Users can see columns referenced in templates they have access to.
- Users cannot see additional columns referenced in templates they do not have access to.
If a document in a TDE protected collection makes use of Element Level Security, both unprotected and protected elements will be extracted. For details on Element Level Security, see Element Level Security in the Security Guide.
Template View Elements
A template contains the elements and child elements shown in the table below.
When creating a JSON template, substitute the dash (-) with an upper-case character. For example, collections-and becomes collectionsAnd. For the complete structure of a JSON template, see JSON Template Structure
| Element | Description |
|---|---|
|
Optional description of the template. |
collections collection collections-and collection |
Optional collection scopes. Multiple collection scopes can be ORed or ANDed. See Collections. |
directories directory |
Optional directory scopes. Multiple directory scopes are ORed together. See Directories. |
vars var |
Optional intermediate variables extracted at the current context level. See Variables. |
rows row schema-name view-name view-layout sparse identical columns column name scalar-type val nullable permissions role-name default invalid-values ignore reject reindexing hidden visible collation |
These elements are used for template views, as described in Creating Template Views in the SQL Data Modeling Guide.
scalar-type is the type for the |
triples triple subject val invalid-values predicate val invalid-values object val invalid-values |
These elements are used for triple-extraction templates, as described in Using a Template to Identify Triples in a Document in the Semantic Graph Developer's Guide.
An extracted triple's graph cannot be specified through the template. The graph is implicitly defined by the document's collection similar to embedded triples. |
templates template |
Optional sequence of sub-templates. For details, see Creating Views from Multiple Templates and Creating Views from Nested Templates in the SQL Data Modeling Guide. |
path-namespaces path-namespace |
Optional sequence of namespace bindings. See path-namespaces. |
context invalid-values |
The lookup node that is used for template activation and data extraction. See Context. |
enabled |
A boolean that specifies whether the template is enabled (true) or disabled (false). Default value is true. |
The context, vars, and columns identify XQuery elements or JSON properties by means of path expressions. Path expressions are based on XPath, which is described in XPath Quick Reference in the XQuery and XSLT Reference Guide and Traversing JSON Documents Using XPath.
JSON Template Structure
Below is the structure of a view template in JSON.
{ "template":{ "description":"test template", "context":"context1", "pathNamespace":[ { "prefix":"sem", "namespaceUri":"http://semantics" }, { "prefix":"tde", "namespaceUri":"http://tde" } ], "collections":[ "colc1", "colc4", { "collectionsAnd":["colc2","colc3"]}, { "collectionsAnd":["colc5","colc6"]} ], "directories":["dir1","dir2"], "vars":[ { "name":"myvar1", "val":"someVal" } ], "rows":[ { "schemaName":"schemaA", "viewName":"viewA", "viewLayout":"sparse", "columns":[ { "name":"A", "scalarType":"int", "val":"someVal", "nullable":false, "default":"'1'", "invalidValues":"ignore" }, { "name":"B", "scalarType":"int", "val":"someVal", "nullable":true, "invalidValues":"ignore" } ] }, { "schemaName": ... ... } ], "triples":[ { "subject":{ "val":"someVal", "invalidValues":"ignore" }, "predicate":{ "val":"someVal" }, "object":{ "val":"someVal" } }, { "subject": ... ... } ], "templates":[ { "context":"context2", "vars":[ { "name":"myvar2", "val":"someval" } ], "rows":[ { "schemaName":"schemaA", "viewName":"viewC", "viewLayout":"sparse", "columns":[ { "name":"A", "scalarType":"string", "val":"someVal", "collation":"http://marklogic.com/collation/fr" }, { "name":"B", "scalarType":"int", "val":"someVal" } ] } ] } ] } }
Collections
A <collections> section defines the scope of the template to be confined only to documents in specific collections. The <collections> section is a top level OR of a sequence of:
<collection>that scope the template to a specific collection.<collections-and>that contains a sequence of<collection>that are ANDed together.
The following collection logical combinations are possible:
<collections> <collection>A</collection> <collection>B</collection> </collections>
<collections> <collections-and> <collection>A</collection> <collection>B</collection> </collections-and> </collections>
<collections> <collection>A</collection> <collection>B</collection> <collections-and> <collection>C</collection> <collection>D</collection> </collections-and> <collections-and> <collection>E</collection> <collection>F</collection> </collections-and> </collections>
Directories
A <directories> section defines the scope of the template to be confined only to documents in specific directories. The <directories> section is a top level OR of a sequence of <directory> elements that scope the template to a specific directory.
path-namespaces
A <path-namespaces> section is a top level of one or more <path-namespace> elements, which contain:
For example, a path namespace binding can be specified in the template as follows:
<path-namespaces> <path-namespace> <prefix>wb</prefix> <namespace-uri>http://marklogic.com/wb</namespace-uri> </path-namespace> </path-namespaces>
The namespace prefix definitions are stored in the template documents and not in the configuration of the target database. Otherwise, templates cannot be compiled into code without knowing the target database configuration that uses them.
Context
The context tag defines the lookup node that is used for template activation and data extraction. Path expressions occurring inside vars, rows, or triples are relative to the context element of their parent template. The context defines an anchor in the XML/JSON tree where data is collected by walking up and down the tree relative to the anchor. Any indexable path expression is valid in the context element, therefore predicates are allowed. The context element of a sub-template is relative to the context element of its parent template.
<context>/Employee</context> <context>/MedlineCitation/Article</context>
For performance and security reasons, your path expressions are limited to a subset of XPath. For more details, see Template Driven Extraction (TDE) in the XQuery and XSLT Reference Guide.
You can specify an invalid-values element to control the behavior when the context expression cannot be evaluated. The possible invalid-values settings are:
ignore-- The extraction will be skipped for the node that resulted in an exception thrown during the evaluation of thecontextexpression.reject-- The server will generate an error when the document is inserted and reject the document. This is the default setting.
It is important to understand that context defines the node from which to extract a single row. If you want to extract multiple rows from the document, the context must be set to the parent element of those rows. For example, you have order documents that are as structured as follows:
<order> <order-num>10663</order-num> <order-date>2017-01-15</order-date> <items> <item> <product>SpeedPro Ultimate</product> <price>999</price> <quantity>1</quantity> </item> <item> <product>Ladies Racer Helmet</product> <price>115</price> <quantity>1</quantity> </item> </items> </order>
Each order document contains one or more <item> nodes. You want to create a view template that extracts the <product>, <price>, and <quantity> values from each <item> node. A context of /order and column values, such as items/item/product, will trigger a single row extraction for the entire document, so the only way this will work is if the document has only one <item> node. To extract the content of all of the <item> nodes as multiple rows, the context must be /order/items/item. In this case, if you wanted to also extract <order-num>, the column value would be ../../order-num.
The context can be any path validated by cts:valid-tde-context. It may contain wildcards, such as '*', but, for performance reasons, do not use wildcards unless their value outweighs the performance costs. It is best to use collection or directory scoping when wildcards are used in the context.
Below is the complete grammar for the Restricted XPath, including all the supported constructs.
RestrictedPathExpr ::= "/" |(PathExpr)* (("/" | "//") LeafExpr Predicates) | SpecialFunctionExpr SpecialFunctionExpr::= ( "fn:doc(" ArgsExpr ")" ) | ( "xdmp:document-properties(" ArgsExpr ")" ) | ( "xdmp:document-locks(" ArgsExpr ")" ) LeafExpr ::= "(" UnionExpr ")" | LeafStep PathExpr ::= ("/" RelativePathExpr?) | ("//" RelativePathExpr) | RelativePathExpr RelativePathExpr ::= UnionExpr | "(" UnionExpr ")" UnionExpr ::= GeneralStepExpr ("|" GeneralStepExpr)* GeneralStepExpr ::= ("/" | "//")? StepExpr (("./" | ".//")? StepExpr)* StepExpr ::= ForwardStep Predicates ForwardStep ::= (ForwardAxis AbbreviatedForwardStep) | AbbreviatedForwardStep AbbreviatedForwardStep ::= "." | ("@" NameTest) | NameTest | KindTest LeafStep ::= ("@"QName) | QName NameTest ::= QName | Wildcard Wildcard ::= "*" | "<" NCName ":" "*" ">" | "<" "*" ":" NCName ">" QName ::= PrefixedName | UnprefixedName PrefixedName ::= Prefix ":" LocalPart UnprefixedName ::= LocalPart Prefix ::= NCName LocalPart ::= NCName NCName ::= Name - (Char* ":" Char*)/* An XML Name, minus the ":" */ Name ::= NameStartChar (NameChar)* Predicates ::= Predicate* Predicate ::= PredicateExpr | "[" Digit+ "]" Digit ::= [0-9] PredicateExpr ::= "[" PredicateExpr "and" PredicateExpr "]" | "[" PredicateExpr "or" PredicateExpr "]" | "[" ComparisonExpr "]" | "[" FunctionExpr "]" ComparisonExpr ::= RelativePathExpr GeneralComp SequenceExpr | RelativePathExpr ValueComp Literal | PathExpr FunctionExpr ::= FunctionCall GeneralComp SequenceExpr | FunctionCall ValueComp Literal | FunctionCall GeneralComp ::= "=" | "!=" | "<" | "<=" | ">" | ">=" ValueComp ::= "eq" | "ne" | "lt" | "le" | "gt" | "ge" SequenceExpr ::= Literal+ Literal ::= NumericLiteral | StringLiteral KindTest ::= ElementTest | AttributeTest | CommentTest | TextTest | ArrayNodeTest | ObjectNodeTest | BooleanNodeTest | NumberNodeTest | NullNodeTest | AnyKindTest | DocumentTest | SchemaElementTest | SchemaAttributeTest | PITest TextTest ::= "text" "(" ")" CommentTest ::= "comment" "(" ")" AttributeTest := "attribute" "(" (QNameOrWildcard ("," QName)?)? ")" ElementTest ::= "element" "(" (QNameOrWildcard ("," QName "?"?)?)? ")" ArrayNodeTest ::= "array-node" "(" NCName? ")" ObjectNodeTest ::= "object-node" "(" NCName? ")" BooleanNodeTest ::= "boolean-node" "(" ")" NumberNodeTest ::= "number-node" "(" ")" NullNodeTest ::= "null-node" "(" ")" AnyKindTest ::= "node" "(" ")" DocumentTest ::= "document-node" "(" (ElementTest | SchemaElementTest) ? ")" SchemaElementTest ::= "schema-element" "(" QName ")" SchemaAttributeTest::= "schema-attribute" "(" QName ")" PITest ::= "processing-instruction" "( "(NCName | StringLiteral) ? ")" QNameOrWildcard ::= QName | "*"
Variables
Variables are intermediate data projections needed for data transformation and are defined under var elements. Variables can reference other variables inside their transformation section val, for the cases where several intermediate projection/transformations are needed before the last projection into the column/triple. The expression inside the val code is relative to the context element of the current template in which the var is defined. See Template Dialect and Data Transformation Functions for the types of expressions allowed in a val.
<context>/northwind/Orders/Order</context> ....... <vars> <var> <name>OrderID</name> <val>./@OrderID</val> </var> </vars> ....... <column> <name>OrderID</name> <scalar-type>long</scalar-type> <val>$OrderID</val> </column>
You do not type variable values in the var description. Rather, the variable value is typed in the column description.
Template Dialect and Data Transformation Functions
Templates support a dialect using a subset of XQuery with limited functionalities where only a subset of functions are available.
The template dialect supports the following types of expressions described in the Expressions section of the An XML Query Language specification:
- Path Expressions
- Sequence Expressions
- Arithmetic Expressions
- Comparison Expressions
- Logical Expressions
- Conditional Expressions
- Expressions on SequenceTypes
More complex operations like looping, FLWOR statements, iterations, and XML construction are not supported within the dialect. The property axis property:: is also not supported.
The supported XQuery functions are listed in the following sections:
- Date and Time Functions
- Logical Functions and Data validation
- String Functions
- Type Casting
- Mathematical Functions
- Data Hub Mapping Functions
- Miscellaneous Functions
Templates only support XQuery functions. JavaScript functions are not supported.
Date and Time Functions
- fn:adjust-date-to-timezone
fn:adjust-dateTime-to-timezone- fn:adjust-time-to-timezone
- fn:current-date
- fn:month-from-date
fn:month-from-dateTime- fn:months-from-duration
fn:seconds-from-dateTime- fn:seconds-from-duration
- fn:seconds-from-time
fn:minutes-from-dateTime- fn:minutes-from-duration
- fn:minutes-from-time
- fn:timezone-from-date
fn:timezone-from-dateTime- fn:timezone-from-time
- fn:year-from-date
fn:year-from-dateTime- fn:years-from-duration
- fn:day-from-date
fn:day-from-dateTime- fn:days-from-duration
- fn:format-date
fn:format-dateTime- fn:format-time
fn:hours-from-dateTime- fn:hours-from-duration
- fn:hours-from-time
- xdmp:dayname-from-date
- xdmp:quarter-from-date
- xdmp:week-from-date
- xdmp:weekday-from-date
- xdmp:yearday-from-date
- sql:dateadd
- sql:datediff
- sql:datepart
- sql:day
- sql:seconds
- sql:dayname
- sql:timestampadd
- sql:hours
- sql:timestampdiff
- sql:minutes
- sql:week
- sql:month
sql:weekday- sql:monthname
- sql:year
- sql:quarter
- sql:yearday
xdmp:parse-dateTime- xdmp:parse-yymmdd
String Functions
- fn:codepoint-equal
- fn:codepoints-to-string
- fn:compare
- fn:concat
- fn:contains
- fn:encode-for-uri
- fn:ends-with
- fn:escape-html-uri
- fn:escape-uri
- fn:format-number
- fn:insert-before
- fn:iri-to-uri
- fn:last
- fn:lower-case
- fn:matches
- fn:normalize-space
- fn:normalize-unicode
- fn:position
- fn:remove
- fn:replace
- fn:reverse
- fn:starts-with
- fn:string-join
- fn:string-length
- fn:string-to-codepoints
- fn:subsequence
- fn:substring
- fn:substring-after
- fn:substring-before
- fn:tokenize
- fn:translate
- fn:upper-case
Type Casting
numberstringdecimalintegerlongintshortbytefloatdoublebooleandatetimedateTimegDaygMonthgYeargYearMonthgMonthDaydurationdayTimeDurationyearMonthDurationcastable-asanyURI- IRI (Internationalized Resource Identifier)
Mathematical Functions
And all the math (http://marklogic.com/xdmp/math namespace) built-in functions except aggregate functions like variance and stddev.
Data Hub Mapping Functions
- fn:abs
- fn:adjust-date-to-timezone
fn:adjust-dateTime-to-timezone- fn:adjust-time-to-timezone
- fn:avg
- fn:boolean
- fn:ceiling
- fn:codepoint-equal
- fn:codepoints-to-string
- fn:compare
- fn:concat
- fn:contains
- fn:count
- fn:current-date
fn:current-dateTime- fn:current-time
- fn:data
- fn:day-from-date
fn:day-from-dateTime- fn:days-from-duration
- fn:empty
- fn:encode-for-uri
- fn:ends-with
- fn:escape-html-uri
- fn:escape-uri
- fn:exists
- fn:false
- fn:floor
- fn:format-date
fn:format-dateTime- fn:format-number
- fn:format-time
- fn:generate-id
- fn:head
fn:hours-from-dateTime- fn:hours-from-duration
- fn:hours-from-time
- fn:implicit-timezone
- fn:insert-before
- fn:iri-to-uri
- fn:lang
- fn:last
- fn:local-name
- fn:lower-case
- fn:matches
- fn:max
- fn:min
fn:minutes-from-dateTime- fn:minutes-from-duration
- fn:minutes-from-time
- fn:month-from-date
fn:month-from-dateTime- fn:months-from-duration
- fn:name
- fn:namespace-uri
- fn:namespace-uri-for-prefix
- fn:node-name
- fn:normalize-space
- fn:normalize-unicode
- fn:not
- fn:number
- fn:position
- fn:remove
- fn:replace
fn:resolve-QName- fn:reverse
- fn:root
- fn:round
- fn:round-half-to-even
fn:seconds-from-dateTime- fn:seconds-from-duration
- fn:seconds-from-time
- fn:starts-with
- fn:string
- fn:string-join
- fn:string-length
- fn:string-to-codepoints
- fn:subsequence
- fn:substring
- fn:substring-after
- fn:substring-before
- fn:sum
- fn:tail
- fn:timezone-from-date
fn:timezone-from-dateTime- fn:timezone-from-time
- fn:tokenize
- fn:translate
- fn:true
- fn:upper-case
- fn:year-from-date
fn:year-from-dateTime- fn:years-from-duration
Miscellaneous Functions
- xdmp:node-uri
- xdmp:node-kind
- xdmp:path
- xdmp:type
- xdmp:node-metadata-value
- xdmp:node-metadata
- sem:uuid
- sem:uuid-string
- sem:bnode
- sem:datatype
sem:sameTerm- sem:lang
sem:iri-to-QNamesem:irisem:QName-to-iri- sem:unknown
- sem:unknown-datatype
- sem:invalid
- sem:invalid-datatype
- sem:typed-literal
- cts:point
- fn:head
- fn:tail
- fn:base-uri
- fn:document-uri
- fn:lang
- fn:local-name
- fn:name
- fn:namespace-uri
- fn:node-name
- fn:number
- fn:root
- fn:min
- fn:max
- fn:sum
- fn:count
- fn:avg
Validating and Inserting a Template
The tde-admin role is required in order to insert a template into the schema database.
The default collation for string values in a TDE template is codepoint. If you are having problems joining columns that use a different collation, you will need to change the TDE template to use a matching collation, or change the appropriate range indexes to use codepoint.
For best performance, it is recommended that you do not configure your content database to use the default Schemas database and instead create your own schemas database for your template documents. If you create multiple content databases to hold documents to be extracted by TDE, each content database must have its own schema database. Failure to do so may result in unexpected indexing behavior on the content databases.
Always validate your template before inserting your view into a schema database. To validate your view, use the tde:validate function as follows:
let $viewTemplate :=
<template xmlns="http://marklogic.com/xdmp/tde">
.....
</template>
return tde:validate($viewTemplate)A valid template will return the following:
<map:map xmlns:map="http://marklogic.com/xdmp/map" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <map:entry key="valid"> <map:value xsi:type="xs:boolean">true</map:value> </map:entry> </map:map>
Do not use xdmp:validate to validate your template, as this function may miss some validation steps.
After you have confirmed that the view template is valid, you can insert your view template into the schema database used by the content database holding the document data. You can use any method for inserting documents into the database to insert a view template, but you must insert the template document into the http://marklogic.com/xdmp/tde collection.
The tde:template-insert function is a convenience that validates the template, inserts the template document into the tde collection in the schema database (if executed on the content database) with the default permissions, and triggers a re-index of the database. The tde:template-batch-insert function is designed to insert multiple templates.
When a template is inserted, only those document fragments affected by the template are re-indexed.
For example, to define and insert a view template, you would enter the following:
xquery version "1.0-ml"; import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy"; let $ClinicalView := <template xmlns="http://marklogic.com/xdmp/tde"> <description>populates patients' data</description> <context>/Citation/Article</context> <rows> <row> <schema-name>Medical2</schema-name> <view-name>Publications</view-name> <columns> <column> <name>ID</name> <scalar-type>long</scalar-type> <val>../ID</val> </column> <column> <name>ISSN</name> <scalar-type>string</scalar-type> <val>Journal/ISSN</val> </column> </columns> </row> </rows> </template> return tde:template-insert("/Template.xml", $ClinicalView)
If you use an alternative insert operation, you must explicitly insert the template document into the http://marklogic.com/xdmp/tde collection of the schema database used by your content database. For example:
return xdmp:document-insert( "/Template.xml", $ClinicalView, (), "http://marklogic.com/xdmp/tde")
Templates and Non-Conforming Documents
Once you have inserted a TDE template for a content database, an attempt to insert a document that does not conform to the template may generate and error.
Doesn't conform might mean that the template says you must have a price element at some path and the column is not nullable, and there is no default value. But the inserted document has no price element at that path, or perhaps there is a price in the document but it can't be cast to the type of the column.
If the document is already in the database and you add the template, you may not want to delete the non-conforming document, but you do want to be aware of its existence. If you set the group file log level to debug, then in the case where you added a template and some existing documents are non-conforming, you'll get an error in the system error log for each document that doesn't get indexed. For details on setting the log level, see Understanding the Log Levels in the Administrator's Guide.
If the template is already in place and you try to insert the non-conforming document, there are two possible outcomes:
- The insert fails with an error
- The insert succeeds, but the row with the missing
pricecolumn is skipped (it doesn't get added to the index)
You can control the outcome by setting invalid-values in the template to reject (reject the non-conforming document and throw an error) or ignore (allow the document insert and ignore that row for indexing purposes).
Enabling and Disabling Templates
Templates can be enabled and disabled by modifying the <enabled> flag on the template. Set the <enabled> flag to true to enable the template or false to disable,
For example, to disable the template set the <enabled> flag to false, as follows:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/foo/bar</context> <enabled>false</enabled> ... </template>
Reindexing will start automatically every time a template is enabled or disabled.
Deleting Templates
Template documents can be safely deleted once they have been disabled and after enough time has elapsed to make sure that the reindexing related to the disabled template has completed.