
MarkLogic 10 Product DocumentationApplication Developer's Guide — Chapter 19
Optic API for Multi-Model Data Access
The MarkLogic Optic API makes it possible to perform relational operations on indexed values and documents. The Optic API is not a single API, but rather a set of APIs exposed within the XQuery, JavaScript, and Java languages.
The Optic API can read any indexed value, whether the value is in a range index, the triple index, or rows extracted by a template. The extraction templates, such as those used to create template views described in Creating Template Views in the SQL Data Modeling Guide, are a simple, powerful way to specify a relational lens over documents, making parts of your document data accessible via SQL. Optic gives you access to the same relational operations, such as joins and aggregates, over rows. The Optic API also enables document search to match rows projected from documents, joined documents as columns within rows, and dynamic document structures, all performed efficiently within the database and accessed programmatically from your application.
The Optic API allows you to use your data as-is and makes it possible to make use of MarkLogic document and search features using JavaScript or XQuery syntax, incorporating common SQL concepts, regardless of the structure of your data. Unlike SQL, Optic is well suited for building applications and accessing the full range of MarkLogic NoSQL capabilities. Because Optic is integrated into common application languages, it can perform queries within the context of broader applications that perform updates to data and process results for presentation to end users.
- Joins: Integrating documents that are frequently updated or that have many relations with a declarative query instead of with a denormalized write
- Grouping: Summarizing aggregate properties over many documents
- Exact matches over repeated structures in documents
- Joining Triples: Incorporating semantic triples to enrich row data or to link documents and rows
- Document Joins: Returning the entire source document to provide context to row data
- Document Query: Performing rich full text search to constrain rows in addition to relational filtering
As in the SQL and SPARQL interfaces, you can use the Optic API to build a query from standard operations such as where, groupBy, orderBy, union, and join by expressing the operations through calls to JavaScript and XQuery functions. The Optic API enables you to work in the environment of the programming language, taking advantage of variables and functions for benefits such as modularizing plan construction and avoiding the parse errors and injection attacks associated with assembling a query by concatenating strings.
Unlike in SQL, column order is indeterminate in Optic. Notable exceptions of the sort order keys in orderby and grouping keys in groupby, which specify priority.
There is also an Optic Java Client API, which is described in Optic Java API for Relational Operations in the Developing Applications With the Java Client API guide.
This chapter has the following main sections:
- Differences between the JavaScript and XQuery Optic APIs
- Objects in an Optic Pipeline
- Data Access Functions
- Kinds of Optic Queries
- Query DSL for Optic API
- Processing Optic Output
- Expression Functions For Processing Column Values
- Functions Equivalent to Boolean, Numeric, and String Operators
- Node Constructor Functions
- Best Practices and Performance Considerations
- Optic Execution Plan
- Parameterizing a Plan
- Exporting and Importing a Serialized Optic Query
- Sampling Data
- Query-Based Views
Differences between the JavaScript and XQuery Optic APIs
Libraries can be imported as JavaScript MJS modules. This is the preferred import method.
Resource service extensions, transforms, row mappers and reducers, and other hooks cannot be implemented as JavaScript MJS modules.
The XQuery Optic API and JavaScript Optic API are functionally equivalent. Each is adapted to the features and practices of their respective language conventions, but otherwise both are as consistent as possible and have the same performance profile. Use the language that best suits your skills and programming environment.
The following table highlights the differences between the JavaScript and XQuery versions of the Optic API.
| Characteristic | JavaScript | XQuery |
|---|---|---|
| Namespaces for proxy functions | Nested namespaces (such as op.fn.min) |
A module in a separate namespace conforming to the following template (for a prefix, such as
For details, see XQuery Libraries Required for Expression Functions. |
| Fluent object chaining | Methods that return objects | Functions take a state object as the first parameter and return a state object, enabling use of the XQuery => chaining operator. These black-box objects hold the state of the plan being built in the form of a map. Because these state objects might change in a future release, they must not be modified, serialized or persisted. Chained functions always create a new map instead of modifying the existing map. |
| Naming convention | camelCase | Hyphen-separated naming convention with the exception of proxy functions for a camelcase original function (such as the fn:current-dateTime function). |
| Unbounded parameters | Allowed | Supported as a single sequence parameter. The sole examples at present are the proxy functions for fn:concat and sem:coalesce. |
| Result types | Returns a sequence of objects, with the option to return a sequence of arrays | Returns a map of sql:rows, with the option to return an array consisting of a header and rows. |
Objects in an Optic Pipeline
The following graphic illustrates the objects that are used as input and output by the methods in an Optic pipeline.
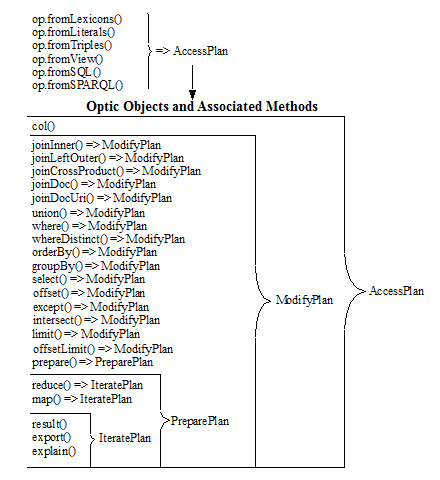
An Optic query creates a pipeline that applies a sequence of relational operations to a row set. The following are the basic characteristics of the functions and methods used in an Optic query:
- All data access functions (any
from*function) produce an output row set in the form of anAccessPlanobject. - All modifier operations, such as ModifyPlan.prototype.where, take an input row set and produce an output row set in the form of a
ModifyPlanobject. - All composer operations, such as ModifyPlan.prototype.joinInner, take two input row sets and produce one output row set in the form of a
ModifyPlanobject. - The last output row set is the result of the plan.
- The order of operations is constrained only in that the pipeline starts with an accessor operation. For example, you can specify:
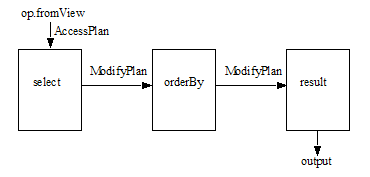
The following is simple example that selects specific columns from the rows in a view and outputs them in a particular order. The pipeline created by this query is illustrated below.
const op = require('/MarkLogic/optic'); op.fromView('main', 'employees') .select(['EmployeeID', 'FirstName', 'LastName']) .orderBy('EmployeeID') .result();
- The op.fromView function outputs an
AccessPlanobject that can be used by all of the API methods. - The AccessPlan.prototype.select method outputs a
ModifyPlanobject. - The ModifyPlan.prototype.orderBy method outputs another
ModifyPlanobject. - The ModifyPlan.prototype.result method consumes the
ModifyPlanobject and executes the plan.
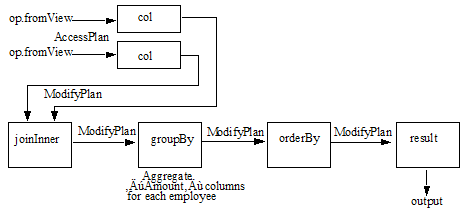
The following example calculates the total expenses for each employee and returns the results in order of employee number.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .groupBy(employees.col('EmployeeID'), ['FirstName','LastName', op.sum('totalexpenses', expenses.col('Amount'))]) .orderBy('EmployeeID') Plan.result();
The absence of .select is equivalent to a SELECT * in SQL, retrieving all columns in a view.
- The op.fromView functions outputs
AccessPlanobjects that are used by the op.on function and AccessPlan.prototype.col methods to direct the ModifyPlan.prototype.joinInner method to join the row sets from both views, which then ouputs them as a single row set in the form of aModifyPlanobject. - The ModifyPlan.prototype.groupBy method calculates the total expenses for each employee and collapes the results into single rows.
- The ModifyPlan.prototype.orderBy method sorts the results and outputs another
ModifyPlanobject. - The ModifyPlan.prototype.result method consumes the
ModifyPlanobject and executes the plan.
Data Access Functions
The following functions access data indexed as rows, triples, and lexicons, as well as literal row sets constructed in the program:
The op.fromView function accesses indexes created by a template view, as described in Creating Template Views in the SQL Data Modeling Guide.
The op.fromTriples function accesses semantic triple indexes and abstracts them as rows and columns. Note, however, that the columns of rows from an RDF graph may have varying data types, which could affect joins.
The op.fromLexiconsfunction dynamically constructs a view with columns on range-indexes, URI lexicons, and collection lexicons. Lexicons are often joined to enrich data indexed in views. Accessing lexicons from Optic may be useful if your application already has range indexes defined, or if URI or collection information is required for your query.
The op.fromLiterals function constructs a literal row set that is similar to the results from a SQL VALUES or SPARQL VALUES statement. This allows you to provide alternative columns to join with an existing view.
The op.fromSQL and op.fromSPARQL functions dynamically construct a row set based on a SELECT queries, template views, and triples, respectively.
The op.fromSearch accessor function exposes the plan:search function. It supports document matching and relevance by constructing rows with document fragment id and relevance columns.
The following sections provide examples of the different data access functions:
- fromView Examples
- fromTriples Example
- fromLexicons Examples
- fromLiterals Examples
- fromSQL Example
- fromSPARQL Example
- fromSearch Example
fromView Examples
Queries using fromView retrieve indexed rows exposed over documents. The examples in this section are based on documents and template views described in the SQL on MarkLogic Server Quick Start chapter in the SQL Data Modeling Guide.
List all of the employees in order of ID number.
const op = require('/MarkLogic/optic'); op.fromView('main', 'employees') .select(['EmployeeID', 'FirstName', 'LastName']) .orderBy('EmployeeID') .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-view("main", "employees") => op:select(("EmployeeID", "FirstName", "LastName")) => op:order-by("EmployeeID") => op:result()
You can use Optic to filter rows for specific data of interest. For example, the following query returns the ID and name for employee 3.
const op = require('/MarkLogic/optic'); op.fromView('main', 'employees') .where(op.eq(op.col('EmployeeID'), 3)) .select(['EmployeeID', 'FirstName', 'LastName']) .orderBy('EmployeeID') .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-view("main", "employees") => op:where(op:eq(op:col("EmployeeID"), 3)) => op:select(("EmployeeID", "FirstName", "LastName")) => op:order-by("EmployeeID") => op:result()
The following query returns all of the expenses and expense categories for each employee and return results in order of employee number. Because some information is contained only on the expense reports and some data is only in the employee record, a row join on EmployeeID is used to pull data from both sets of documents and produce a single, integrated row set.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .select([employees.col('EmployeeID'), 'FirstName', 'LastName', 'Category', 'Amount']) .orderBy(employees.col('EmployeeID')) Plan.result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
return $employees
=> op:join-inner($expenses, op:on(
op:view-col("employees", "EmployeeID"),
op:view-col("expenses", "EmployeeID")))
=> op:select((op:view-col("employees", "EmployeeID"),
"FirstName", "LastName", "Category", "Amount"))
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result()Locate employee expenses that exceed the allowed limit. The where operation in this example demonstrates the nature of the Optic chaining pipeline, as it applies to all of the preceding rows.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); const expenselimit = op.fromView('main', 'expenselimit'); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .joinInner(expenselimit, op.on(expenses.col('Category'), expenselimit.col('Category'))) .where(op.gt(expenses.col('Amount'), expenselimit.col('Limit'))) .select([employees.col('EmployeeID'), 'FirstName', 'LastName', expenses.col('Category'), expenses.col('Amount'), expenselimit.col('Limit') ]) .orderBy(employees.col('EmployeeID')) Plan.result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
let $expenselimit := op:from-view("main", "expenselimit")
return $employees
=> op:join-inner($expenses, op:on(
op:view-col("employees", "EmployeeID"),
op:view-col("expenses", "EmployeeID")))
=> op:join-inner($expenselimit, op:on(
op:view-col("expenses", "Category"),
op:view-col("expenselimit", "Category")))
=> op:where(op:gt(op:view-col("expenses", "Amount"),
op:view-col("expenselimit", "Limit")))
=> op:select((op:view-col("employees", "EmployeeID"),
"FirstName", "LastName",
op:view-col("expenses", "Category"),
op:view-col("expenses", "Amount"),
op:view-col("expenselimit", "Limit")))
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result()fromTriples Example
The following example returns a list of the people who were born in Brooklyn in the form of a table with two columns, person and name. This is executed against the example dataset described in Loading Triples in the Semantic Graph Developer's Guide.
const op = require('/MarkLogic/optic'); // prefixer is a factory for sem:iri() constructors in a namespace const resource = op.prefixer('http://dbpedia.org/resource/'); const foaf = op.prefixer('http://xmlns.com/foaf/0.1/'); const onto = op.prefixer('http://dbpedia.org/ontology/'); const person = op.col('person'); const Plan = op.fromTriples([ op.pattern(person, onto('birthPlace'), resource('Brooklyn')), op.pattern(person, foaf("name"), op.col("name")) ]) Plan.result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $resource := op:prefixer("http://dbpedia.org/resource/") let $foaf := op:prefixer("http://xmlns.com/foaf/0.1/") let $onto := op:prefixer("http://dbpedia.org/ontology/") let $person := op:col("person") return op:from-triples(( op:pattern($person, $onto("birthPlace"), $resource("Brooklyn")), op:pattern($person, $foaf("name"), op:col("name")))) => op:result()
fromLexicons Examples
The fromLexicons function may be useful if you already have range indexes defined for use elsewhere in your application. This data access function enables you to incorporate lexicons as another source of data for your query pipeline.
The examples in this section operate on the documents described in Load the Data in the SQL Data Modeling Guide.
The fromLexicons function queries on range index names, rather than column names in a view. For example, for the employee documents, rather than query on EmployeeID, you create a range index, named ID, and query on ID.
First, in the database holding your data, create element range indexes for the following elements: ID, Position, FirstName, and LastName. For details on how to create range indexes, see Defining Element Range Indexes in the Administrator's Guide.
The following example returns the EmployeeID for each employee. The text, myview, is prepended to each column name.
const op = require('/MarkLogic/optic'); const Plan = op.fromLexicons( {EmployeeID: cts.elementReference(xs.QName('ID'))}); Plan.result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-lexicons( map:entry( "EmployeeID", cts:element-reference(xs:QName("ID"))), "myview") => op:result()
The following example returns the EmployeeID, FirstName, LastName, and the URI of the document holding the data for each employee.
const op = require('/MarkLogic/optic'); const Plan = op.fromLexicons({ EmployeeID: cts.elementReference(xs.QName('ID')), FirstName: cts.elementReference(xs.QName('FirstName')), LastName: cts.elementReference(xs.QName('LastName')), URI: cts.uriReference()}); Plan.result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-lexicons( map:entry("EmployeeID", cts:element-reference(xs:QName("ID"))) => map:with("FirstName", cts:element-reference(xs:QName("FirstName"))) => map:with("LastName", cts:element-reference(xs:QName("LastName"))) => map:with("uri", cts:uri-reference())) => op:result()
Every view contains a fragment ID. The fragment ID generated from op.fromLexicons can be used to join with the fragment ID of a view. For example, the following returns the EmployeeID, FirstName, LastName, Position, and document URI for each employee.
const op = require('/MarkLogic/optic'); const empldocid = op.fragmentIdCol('empldocid'); const uridocid = op.fragmentIdCol('uridocid'); const employees = op.fromView('main', 'employees', null, empldocid); const DFrags = op.fromLexicons({'URI': cts.uriReference()}, null, uridocid) const Plan = employees.joinInner(DFrags, op.on(empldocid, uridocid)) .select(['URI', 'EmployeeID', 'FirstName', 'LastName', 'Position']); Plan.result() ;
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $empldocid := op:fragment-id-col("empldocid") let $uridocid := op:fragment-id-col("uridocid") let $employees := op:from-view("main", "employees", (), $empldocid) let $DFrags := op:from-lexicons(map:entry("URI", cts:uri-reference()), (), $uridocid) return $employees => op:join-inner($DFrags, op:on($empldocid, $uridocid)) => op:select((op:view-col("employees", "EmployeeID"), ("URI", "FirstName", "LastName", "Position"))) => op:result()
fromLiterals Examples
The fromLiterals function enables you to dynamically generate rows based on run-time input of arrays and objects of strings. This data access function is helpful for testing and debugging.
Build a table with two rows and return the row that matches the id column value of 1:
const op = require('/MarkLogic/optic'); op.fromLiterals([ {id:1, name:'Master 1', date:'2015-12-01'}, {id:2, name:'Master 2', date:'2015-12-02'} ]) .where(op.eq(op.col('id'),1)) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-literals( map:entry("columnNames", json:to-array(("id", "name", "date"))) => map:with("rowValues", ( json:to-array(( 1, "Master 1", "2015-12-01")), json:to-array(( 2, "Master 2", "2015-12-02"))))) => op:where(op:eq(op:col("id"), 1)) => op:result()
Build a table with five rows and return the average values for group 1 and group 2:
const op = require('/MarkLogic/optic'); op.fromLiterals([ {group:1, val:2}, {group:1, val:4}, {group:2, val:3}, {group:2, val:5}, {group:2, val:7} ]) .groupBy('group', op.avg('valAvg', 'val')) .orderBy('group') .result()
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-literals(( map:entry("group", 1) => map:with("val", 2), map:entry("group", 1) => map:with("val", 4), map:entry("group", 2) => map:with("val", 3), map:entry("group", 2) => map:with("val", 5), map:entry("group", 2) => map:with("val", 7) )) => op:group-by("group", op:avg("valAvg", "val")) => op:order-by("group") => op:result()
fromSQL Example
The fromSQL function enables you to dynamically generate rows based on a SQL SELECT query.
List all of the employees in the employees view:
const op = require('/MarkLogic/optic'); op.fromSQL('SELECT employees.FirstName, employees.LastName \ FROM employees') .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-sql('SELECT employees.FirstName, employees.LastName FROM employees') => op:result()
fromSPARQL Example
The fromSPARQL function enables you to dynamically generate rows based on a SPARQL SELECT query.
List all of the people born in Brooklyn:
'use strict';
const op = require('/MarkLogic/optic');
op.fromSPARQL(`PREFIX db: <http://dbpedia.org/resource/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX onto: <http://dbpedia.org/ontology/>
SELECT ?person ?name
WHERE {WHERE { ?person onto:birthPlace db:Brooklyn;
foaf:name ?name .}`)
.result()xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-sparql('PREFIX db: <http://dbpedia.org/resource/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX onto: <http://dbpedia.org/ontology/> SELECT ?person ?name WHERE { ?person onto:birthPlace db:Brooklyn; foaf:name ?name .}') => op:result()
fromSearch Example
The fromSearch accessor function exposes exposes the plan:search function. It supports document matching and relevance by constructing rows with document fragment id and relevance columns. The plan will typically join the rows on the document fragment id with the content of documents or with rows, triples, or lexicons indexed on the documents (where the lexicons include range indexes, the document URI lexicon, and the collection lexicon).
To get the document uris and content with the most relevance:
op.fromSearch('criteria') .joinDocUri('uri', op.fragmentIdCol('fragmentId')) .orderBy(op.desc('score')) .limit(100) .joinDoc('doc', op.fragmentIdCol('fragmentId')) ... operations to filter, project, aggregate, sort, or join on other data ...
To get the rows with the most relevance:
op.fromSearch('criteria') .joinInner( op.fromView(null, viewName, null, op.fragmentIdCol('viewDocId')), op.on('fragmentId', 'viewDocId') ) .orderBy(op.desc('score')) .limit(100) ... operations to filter, project, aggregate, sort, or join on other data ...
To get the triples with the most relevance:
op.fromSearch('criteria') .joinInner( op.fromTriples( op.pattern(op.col('s'), predicateIri, op.col('o'), op.fragmentIdCol('patternDocId')) ), op.on('fragmentId', 'patternDocId') ) .orderBy(op.desc('score')) .limit(100) ... operations to filter, project, aggregate, sort, or join on other data ...
To get the lexicon values with the most relevance:
op.fromSearch('criteria') .joinInner( op.fromLexicons({ uri: cts.uriReference(), collection: cts.collectionReference(), ... references to range indexes on the relevant documents ... }, null, op.fragmentIdCol('lexiconsDocId') ), op.on('fragmentId', 'lexiconsDocId') ) .orderBy(op.desc('score')) .limit(100) ... operations to filter, project, aggregate, sort, or join on other data ...
When there is no need to sort on score or other relevance factors, retrieving only the fragment id is an efficient way to access documents -- as in:
op.fromSearch(cts.wordQuery('criteria'), ['fragmentId']) .joinDoc('doc', op.fragmentIdCol('fragmentId'))
Kinds of Optic Queries
This section describes some of the kinds of Optic queries. The examples in this section are based on documents and template views described in the SQL on MarkLogic Server Quick Start chapter in the SQL Data Modeling Guide.
- Basic Queries
- Aggregates and Grouping
- Row Joins
- Document Joins
- Union, Intersect, and Except
- Grouping Sets
- Document Queries
Basic Queries
Begin using the Optic API by performing a basic query on a view over documents. Querying the view will return rows.
For example, the following lists all of the employee IDs and names in order of ID number.
const op = require('/MarkLogic/optic'); op.fromView('main', 'employees') .select(['EmployeeID', 'FirstName', 'LastName']) .orderBy('EmployeeID') .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-view("main", "employees") => op:select(("EmployeeID", "FirstName", "LastName")) => op:order-by("EmployeeID") => op:result()
Where select() can project a subset of existing columns and/or modify existing columns and/or add new columns, bind() can modify existing columns and/or add new columns but preserves unmodified existing columns.
const op = require('/MarkLogic/optic'); op.fromView('main', 'expenses') .bind([ op.as('Ceiling', op.multiply(op.col('Amount'), 1.1)), op.as('Floor', op.multiply(op.col('Amount'), 0.9)) ]) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:from-view("main", "expenses") => op:bind(( op:as("Ceiling", op:multiply(op:col("Amount"), 1.1)), op:as("Floor", op:multiply(op:col("Amount"), 0.9)) )) => op:result()
Aggregates and Grouping
Use the MarkLogic Optic API to conveniently perform aggregate functions on values across documents. The following examples perform several operations to get a sense of basic statistics about employee expenses. For information on the op.math.trunc and omath:trunc proxy functions used in these examples, see Expression Functions For Processing Column Values.
Grouping in Optic differs from SQL. In SQL, the grouping keys are in the GROUP BY statement and the aggregates are separately declared in the SELECT. In an Optic group-by operation, the grouping keys are the first parameter and the aggregates are an optional second parameter. In this way, Optic enables you to aggregate sequences and arrays in a group-by operation and then call expression functions that operate on these sequences and arrays. For example, many of the math:* functions, described in Expression Functions For Processing Column Values, take a sequence.
In Optic, instead of applying aggregate functions to the group, a simple column can be supplied. Optic will sample the value of the column for one arbitrary row within the group. This can be useful when the column has the same value in every row within the group; for example, when grouping on a department number but sampling on the department name.
const op = require('/MarkLogic/optic'); op.fromView('main', 'expenses') .groupBy(null, [ op.count('ExpenseReports', 'EmployeeID'), op.min('minCharge', 'Amount'), op.avg('average', 'Amount'), op.max('maxCharge', 'Amount') ]) .select(['ExpenseReports', 'minCharge', op.as('avgCharge', op.math.trunc(op.col('average'))), 'maxCharge']) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; import module namespace omath="http://marklogic.com/optic/expression/math" at "/MarkLogic/optic/optic-math.xqy"; let $expenses := op:from-view("main", "expenses") return $expenses => op:group-by((), ( op:count("ExpenseReports", "EmployeeID"), op:min("minCharge", "Amount"), op:avg("average", "Amount"), op:max("maxCharge", "Amount") )) => op:select(("ExpenseReports", "minCharge", op:as("avgCharge", omath:trunc(op:col("average"))), "maxCharge")) => op:result();
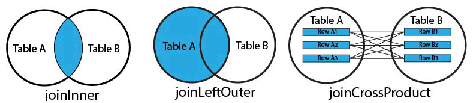
Row Joins
Optic supports the following types of row joins:
| Method | Description |
|---|---|
| joinInner | Creates one output row set that concatenates one left row and one right row for each match between the keys in the left and right row sets. |
| joinLeftOuter | Creates one output row set with all of the rows from the left row set with the matching rows in the right row set, or NULL when there is no match. |
| joinCrossProduct | Creates one output row set that concatenates every left row with every right row. |
The examples in this section join the employees and expenses views to return more information on employee expenses and their categories than what is available on individual documents.
joinInner
The following queries make use of the AccessPlan.prototype.joinInner and op:join-inner functions to return all of the expenses and expense categories for each employee in order of employee number. The join will supplement employee data with information stored in separate expenses documents. The inner join acts as a filter and will only include those employees with expenses.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .select([employees.col('EmployeeID'), 'FirstName', 'LastName', expenses.col('Category'), 'Amount']) .orderBy(employees.col('EmployeeID')) Plan.result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
return $employees
=> op:join-inner($expenses, op:on(
op:view-col("employees", "EmployeeID"),
op:view-col("expenses", "EmployeeID")))
=> op:select((op:view-col("employees", "EmployeeID"),
"FirstName", "LastName", "Category"))
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result()Use the AccessPlan.prototype.where and op:where functions to locate employee expenses that exceed the allowed limit. Join the employees, expenses, and category limits to get a 360 degree view of employee expenses.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); const expenselimit = op.fromView('main', 'expenselimit'); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .joinInner(expenselimit, op.on(expenses.col('Category'), expenselimit.col('Category'))) .where(op.gt(expenses.col('Amount'), expenselimit.col('Limit'))) .select([employees.col('EmployeeID'), 'FirstName', 'LastName', expenses.col('Category'), expenses.col('Amount'), expenselimit.col('Limit') ]) .orderBy(employees.col('EmployeeID')) Plan.result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
let $expenselimit := op:from-view("main", "expenselimit")
return $employees
=> op:join-inner($expenses, op:on(
op:view-col("employees", "EmployeeID"),
op:view-col("expenses", "EmployeeID")))
=> op:join-inner($expenselimit, op:on(
op:view-col("expenses", "Category"),
op:view-col("expenselimit", "Category")))
=> op:where(op:gt(op:view-col("expenses", "Amount"),
op:view-col("expenselimit", "Limit")))
=> op:select((op:view-col("employees", "EmployeeID"),
"FirstName", "LastName",
op:view-col("expenses", "Category"),
op:view-col("expenses", "Amount"),
op:view-col("expenselimit", "Limit")))
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result()joinLeftOuter
The following queries make use of the AccessPlan.prototype.joinLeftOuter and op:join-left-outer functions to return all of the expenses and expense categories for each employee in order of employee number, or null values for employees without matching expense records.
const op = require('/MarkLogic/optic');
const employees = op.fromView('main', 'employees');
const expenses = op.fromView('main', 'expenses');
const Plan =
employees.joinLeftOuter(expenses, op.on(employees.col('EmployeeID'),
expenses.col('EmployeeID')))
.orderBy(employees.col('EmployeeID'))
Plan.result();xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
return $employees
=> op:join-left-outer($expenses, op:on(
op:view-col("employees", "EmployeeID"),
op:view-col("expenses", "EmployeeID")))
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result()joinCrossProduct
The following queries make use of the AccessPlan.prototype.joinCrossProduct and op:join-cross-product functions to return all of the expenses and expense categories for each employee title (Position) in order of expense Category. If employees with a particular position do not have any expenses under a category, the reported expense is 0.
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); const expenses = op.fromView('main', 'expenses'); expenses.groupBy ('Category') .joinCrossProduct(employees.groupBy('Position')) .select(null, 'all') .joinLeftOuter( expenses.joinInner(employees, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID')) ) .groupBy(['Category', 'Position'], op.sum('rawExpense', expenses.col('Amount')) ) .select(null, 'expensed'), [op.on(op.viewCol('expensed', 'Category'), op.viewCol('all', 'Category')), op.on(op.viewCol('expensed', 'Position'), op.viewCol('all', 'Position'))] ) .select([op.viewCol('all', 'Category'), op.viewCol('all', 'Position'), op.as('expense', op.sem.coalesce(op.col('rawExpense'), 0)) ]) .orderBy(['Category', 'Position']) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; import module namespace osem="http://marklogic.com/optic/expression/sem" at "/MarkLogic/optic/optic-sem.xqy"; let $employees := op:from-view("main", "employees") let $expenses := op:from-view("main", "expenses") let $rawExpense := op:col("rawExpense") return $expenses => op:group-by('Category') => op:join-cross-product($employees => op:group-by("Position")) => op:select((), 'all') => op:join-left-outer( $expenses => op:join-inner($employees, op:on( op:col($employees, "EmployeeID"), op:col($expenses, "EmployeeID") )) => op:group-by(("Category", "Position"), op:sum("rawExpense", op:col($expenses, "Amount"))) => op:select((), "expensed"), (op:on(op:view-col("expensed", "Category"), op:view-col("all", "Category")), op:on(op:view-col("expensed", "Position"), op:view-col("all", "Position"))) ) => op:select((op:view-col("all", "Category"), op:view-col("all", "Position"), op:as("expense", osem:coalesce((op:col("rawExpense"), 0))))) => op:order-by(("Category", "Position")) => op:result();
Document Joins
The Optic API provides access not only to rows within views, but also to documents themselves.
Optic support the following types of document joins:
| Method | Description |
|---|---|
| joinDoc | Joins the source documents for rows (especially when the source documents have detail that's not projected into rows). In this case, name the fragment ID column and use it in the join |
| joinDocUri | Joins related documents based on document URIs. The AccessPlan.prototype.joinDocUri method provides a convenient way to join documents by their URIs. However, if you need more control (for example, left outer joins on related documents), you can use the explicit join with the cts.uriReference lexicon to get the fragment id and join the documents on the fragment id. After joining documents, you can use the op.xpath function to project or an xdmp:* function to add columns with the metadata for documents. |
Minimize the number of documents retrieved by filtering or limiting rows before joining documents.
joinDoc
In the examples below, the 'employee' and 'expense' source documents are returned by the AccessPlan.prototype.joinDoc or op:join-doc function after the row data. The join is done on the document fragment ids returned by op.fromView.
const op = require('/MarkLogic/optic'); const empldocid = op.fragmentIdCol('empldocid'); const expdocid = op.fragmentIdCol('expdocid'); const employees = op.fromView('main', 'employees', null, empldocid); const expenses = op.fromView('main', 'expenses', null, expdocid); const Plan = employees.joinInner(expenses, op.on(employees.col('EmployeeID'), expenses.col('EmployeeID'))) .joinDoc('Employee', empldocid) .joinDoc('Expenses', expdocid) .select([employees.col('EmployeeID'),'FirstName', 'LastName', expenses.col('Category'), 'Amount', 'Employee', 'Expenses']) .orderBy(employees.col('EmployeeID')) Plan.result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $empldocid := op:fragment-id-col("empldocid") let $expdocid := op:fragment-id-col("expdocid") let $employees := op:from-view("main", "employees", (), $empldocid) let $expenses := op:from-view("main", "expenses", (), $expdocid) return $employees => op:join-inner($expenses, op:on( op:view-col("employees", "EmployeeID"), op:view-col("expenses", "EmployeeID"))) => op:join-doc("Employee", $empldocid) => op:join-doc("Expenses", $expdocid) => op:select((op:view-col("employees", "EmployeeID"), "FirstName", "LastName", op:view-col("expenses", "Category"), op:view-col("expenses", "Amount"), "Employee", "Expenses")) => op:order-by(op:view-col("employees", "EmployeeID")) => op:result()
joinDocUri
The following examples show how the AccessPlan.prototype.joinDocUri or op:join-doc-uri function can be used to return the document URI along with the row data.
const op = require('/MarkLogic/optic'); const empldocid = op.fragmentIdCol('empldocid'); const employees = op.fromView('main', 'employees', null, empldocid); employees.joinDocUri(op.col('uri'), empldocid) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $empldocid := op:fragment-id-col("empldocid") return op:from-view("main", "employees", (), $empldocid) => op:join-doc-uri(op:col("uri"), $empldocid) => op:result()
Union, Intersect, and Except
Optic supports the following ways to combine data into new rows:
| Method | Description |
|---|---|
| union | Combines all of the rows from the input row sets. Columns that are present only in some input row sets effectively have a null value in the rows from the other row sets. |
| intersect | Creates one output row set from the rows that have the same columns and values in both the left and right row sets. |
| except | Creates one output row set from the rows that have the same columns in both the left and right row sets, but the column values in the left row set do not match the column values in the right row set. |
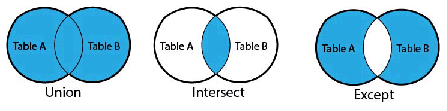
The examples in this section operate on the employees and expenses views to return more information on employee expenses and their categories than what is available on individual documents.
union
The following queries make use of the AccessPlan.prototype.union and op:union functions to return all of the expenses and expense categories for each employee in order of employee number.
const op = require('/MarkLogic/optic');
const employees = op.fromView('main', 'employees');
const expenses = op.fromView('main', 'expenses');
const Plan =
employees.union(expenses)
.whereDistinct()
.orderBy([employees.col('EmployeeID')])
Plan.result();xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $employees := op:from-view("main", "employees")
let $expenses := op:from-view("main", "expenses")
return $employees
=> op:union($expenses)
=> op:where-distinct()
=> op:order-by(op:view-col("employees", "EmployeeID"))
=> op:result() intersect
The following queries make use of the AccessPlan.prototype.intersect and op:intersect functions to return the matching columns and values in the tables, tab1 and tab2.
The op.fromLiterals function is used for this example because the data set does not contain redundant columns and values.
const op = require('/MarkLogic/optic'); const tab1 = op.fromLiterals([ {id:1, val:'a'}, {id:2, val:'b'}, {id:3, val:'c'} ]); const tab2 = op.fromLiterals([ {id:1, val:'x'}, {id:2, val:'b'}, {id:3, val:'c'} ]); tab1.intersect(tab2) .orderBy('id') .result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $tab1 := op:from-literals((
map:entry("id", 1) => map:with("val", "a"),
map:entry("id", 2) => map:with("val", "b"),
map:entry("id", 3) => map:with("val", "c")
))
let $tab2 := op:from-literals((
map:entry("id", 1) => map:with("val", "x"),
map:entry("id", 2) => map:with("val", "b"),
map:entry("id", 3) => map:with("val", "c")
))
return $tab1
=> op:intersect($tab2)
=> op:order-by("id")
=> op:result()except
The following queries make use of the AccessPlan.prototype.except and op:except functions to return the columns and values in tab1 that do not match those in tab2.
The op.fromLiterals function is used for this example because the data set does not contain redundant columns and values.
const op = require('/MarkLogic/optic'); const tab1 = op.fromLiterals([ {id:1, val:'a'}, {id:2, val:'b'}, {id:3, val:'c'} ]); const tab2 = op.fromLiterals([ {id:1, val:'x'}, {id:2, val:'b'}, {id:3, val:'c'} ]); tab1.except(tab2) .orderBy('id') .result();
xquery version "1.0-ml";
import module namespace op="http://marklogic.com/optic"
at "/MarkLogic/optic.xqy";
let $tab1 := op:from-literals((
map:entry("id", 1) => map:with("val", "a"),
map:entry("id", 2) => map:with("val", "b"),
map:entry("id", 3) => map:with("val", "c")
))
let $tab2 := op:from-literals((
map:entry("id", 1) => map:with("val", "x"),
map:entry("id", 2) => map:with("val", "b"),
map:entry("id", 3) => map:with("val", "c")
))
return $tab1
=> op:except($tab2)
=> op:order-by("id")
=> op:result()Grouping Sets
The Optic API for grouping sets include the AccessPlan.prototype.groupToArrays() and op:group-to-arrays convenience functions. While useful for row-oriented processing in the plan, grouping row sets can be inconvenient for processing in SJS or XQuery scripting on the enode or in an HTTP response on the client. The AccessPlan.prototype.groupToArrays()convenience function addresses those use cases with a facade over the groupByUnion function.
The AccessPlan.prototype.groupToArrays function has the following signature:
groupToArrays(namedGroup+, aggregateCol*)
Document Queries
The MarkLogic Optic API can be combined with other types of queries. Developers can restrict rows based on a document query, even if there are parts of the document that are not part of the row view. The following demonstrates the use of the AccessPlan.prototype.where and op:where functions to express a document query within the Optic API:
const op = require('/MarkLogic/optic'); op.fromView('main', 'employees') .where(cts.andQuery([cts.wordQuery('Senior'), cts.wordQuery('Researcher')])) .select(['FirstName', 'LastName', 'Position']) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $employees := op:from-view("main", "employees") return $employees => op:where(cts:and-query((cts:word-query("Senior"), cts:word-query("Researcher")))) => op:select(("FirstName", "LastName", "Position")) => op:result()
Query DSL for Optic API
Query DSL is a human-editable query language representation for the Optic API, added to the /v1/rows endpoint in MarkLogic 10.0-6. Query DSL creates a human readable textual representation of an Optic query without limiting the query capabilities. The human-oriented representation can be edited with text editors, displayed in diagnostic views, and so on.
If you need to write a query on the client, consider using a Query DSL.
This section contains the following topics:
Optic supports an AST (Abstract Syntax Tree) in JSON format that provides a machine-oriented representation of an Optic query. The DSL adds a human-oriented textual representation of an Optic query without limiting the query capabilities. The Optic API supports lossless conversion between the machine-oriented AST and human-oriented DSL representations of an Optic query.
Prior to MarkLogic 10.0-6, the /v1/rows endpoint was only available by using MarkLogic client APIs or previously exported ASTs. The REST API support for Optic queries was machine-oriented, but with the Query DSL enhancement it is now accessable via human-readable queries.
The Query DSL has the same syntax and vocabulary as the Optic builder in SJS. It looks like an eval but without raising the security concerns.
Here is an example of complete query:
const currentYear = fn.yearFromDate(fn.currentDate()) op.fromView(null, 'musician') .where($c.dob > xs.date(fn.concat(currentYear - 100, '-01-01'))) .select([op.as(...Äòage', currentYear - fn.yearFromDate($c.dob)), $c.lastName, $c.firstName]) .orderBy([$c.age, $c.lastName, $c.firstName])
For cut-and-paste compatibility with VSCode and Query Console, the Query DSL supports the representation of an Optic query built in SJS without changes.
The Query DSL also supports shortcuts to improve usability for the JavaScript user (including eliminating the difference between expressions executed at build time and expressions executed at query time based on the inputs to the expression).
Syntax
The complete syntax for Query DSL includes:
- primitive literals for string, numeric, boolean and null values - but not the undefined (void 0) literal value; use
op.isDefined()instead - object and array literals
- arithmetic, comparison, and boolean operators (including
==and!=equality) - but not===or!===identity or string concatenation (+); usefn.concat()instead - the ternary operator: testExpression ? consequentExpression : alternateExpression
- parenthetical grouping of expressions
- comma separation of expressions
- constant assignment and evaluation - for reuse of query fragments
- member evaluation - including namespaced functions
- functions calls - including functional composition and chained calls
A Query DSL can have any number of constant assignments followed by exactly one query builder expression.
Vocabulary
Here is the complete vocabulary for Query DSL:
- The cts, fn, geo, json, map, math, op, rdf, sem, spell, sql, xdmp, and xs namespaces
- The cts.query and sem.store constructors
- The side-effect-free expression functions in the cts, fn, geo, json, map, math, rdf, sem, spell, sql, xdmp, and xs namespaces supported by the Optic API see https://docs.marklogic.com/guide/app-dev/OpticAPI#id_69308 .
- The functions of the Optic query builder exclusive of the
result(),explain(),export(), andgenerateView()operations on the built query see https://docs.marklogic.com/js/op . - The $c.schemaName.viewName.colName, $c.viewName.colName, and $c.colName shortcut for specifying columns; use
op.schemaCol(),op.viewCol(), orop.col()if any name contains a period.
The operation on the Query DSL is specified by the request instead of as part of the query.
Server APIs
To avoid incurring the import of the JavaScript parser in the existing Optic library, a new MarkLogic/optic-dsl-js.mjs library provides one new function:
import()takes a Query DSL as a string and returns an Optic query ready for execution, explanation, or export.
The imported Optic query can be:
- executed with the existing Optic
results()method - analyzed with the existing Optic
explain()method - converted to the AST with the existing Optic
export()method - wrapped as a view by the existing Optic
generateView()method - serialized to Optic SJS source (and thus to the Query DSL without shortcuts) with the the existing Optic
toSource()functionBecause the
toSource()function doesn't apply any shortcuts in the serialization, editors that want to provide the original textual representation of a query should take a typical approach for such cases and save the original textual representation instead of relying on generating an equivalent textual representation.
The existing /v1/rows endpoint of the REST API, and (for completeness) the Java and Node.js Client APIs, can take the Optic DSL as an alternative to the AST representation of an Optic query. The content-type header for the request must specify a mime type of application/vnd.marklogic.querydsl+javascript
The operation on the query DSL is specified by the request instead of as part of the query.
Processing Optic Output
Optic JavaScript queries in Query Console output results in the form of serialized JSON objects. In most cases, you will want to have some code that consumes the Optic output. For example, the following query maps the Optic output to an HTML table.
const op = require('/MarkLogic/optic'); let keys = null; const rowItr = op.fromView('main', 'employees') .map(row => { if (keys === null) { keys = Object.keys(row); } return `<tr>${keys.map(key => `<td>${row[key]}</td>`)}</tr>`; }) .result(); const rows = Array.from(rowItr).join('\n'); const header = `<tr>${keys.map(key => `<th>${key}</th>`)}</tr>`; const report = `<table>\n${header}\n${rows}\n</table>`; report;
To view the output as a table in Query Console, select HTML from the String as menu.

Expression Functions For Processing Column Values
Optic supports expression functions that represent builtin functions to process column values returned by op.col and op:col. These include datatype constructors, datetime, duration, numeric, sequence, and string functions. Expression functions are both
- A proxy for a deferred call to a builtin function on the value of a column in each row.
- Nestable for powerful expressions that transform values.
For example, the math.trunc function is expressed by the op.math.trunc expression function in JavaScript and as omath:trunc in XQuery.
For example, the truncate to decimal portion of the returned 'average' value, do the following:
op.math.trunc(op.col('average')) // JavaScript
omath:trunc(op:col('average')) (: XQuery :)The list of JavaScript functions supported by expression functions is shown in the table below. Their XQuery equivalents are also supported, but you must import the respective module libraries listed in XQuery Libraries Required for Expression Functions.
Most every value processing built-in function you would want to use is listed below. In the unlikely event that you want to call a function that is not listed, the Optic API provides a general-purpose op.call constructor for deferred calls:
op.call(moduleUri, functionName, arg*) => expression op.call({uri:..., name:..., args:*}) => expression
Use the op.call function with care because some builtins could adversely affect performance or worse. You cannot call JavaScript or XQuery functions using this function. Instead, provide a map or reduce function to postprocess the results.
XQuery Libraries Required for Expression Functions
In XQuery, the following libraries must be imported to use the expression functions for the respective built-in functions.
import module namespace octs="http://marklogic.com/optic/expression/cts" at "/MarkLogic/optic/optic-cts.xqy";
import module namespace ofn="http://marklogic.com/optic/expression/fn" at "/MarkLogic/optic/optic-fn.xqy";
import module namespace ojson="http://marklogic.com/optic/expression/json" at "/MarkLogic/optic/optic-json.xqy";
import module namespace omap="http://marklogic.com/optic/expression/map" at "/MarkLogic/optic/optic-map.xqy";
import module namespace omath="http://marklogic.com/optic/expression/math" at "/MarkLogic/optic/optic-math.xqy";
import module namespace ordf="http://marklogic.com/optic/expression/rdf" at "/MarkLogic/optic/optic-rdf.xqy";
import module namespace osem="http://marklogic.com/optic/expression/sem" at "/MarkLogic/optic/optic-sem.xqy";
import module namespace ospell="http://marklogic.com/optic/expression/spell" at "/MarkLogic/optic/optic-spell.xqy";
import module namespace osql="http://marklogic.com/optic/expression/sql" at "/MarkLogic/optic/optic-sql.xqy";
import module namespace oxdmp="http://marklogic.com/optic/expression/xdmp" at "/MarkLogic/optic/optic-xdmp.xqy";
import module namespace oxs="http://marklogic.com/optic/expression/xs" at "/MarkLogic/optic/optic-xs.xqy";
Expression functions can be nested for powerful expressions that transform values. For example:
.select(['countUsers', 'minReputation', op.as('avgReputation', op.math.trunc(op.col('aRep'))), 'maxReputation', op.as('locationPercent', op.fn.formatNumber(op.xs.double( op.divide(op.col('locationCount'), op.col('countUsers'))),'##%')) ])
Functions Equivalent to Boolean, Numeric, and String Operators
| Function | SPARQL | SQL | Comments |
|---|---|---|---|
| = | In expressions, the call will pass a op.col value to identify a column. | ||
| > | > | ||
| >= | >= | ||
| < | < | ||
| <= | <= | ||
| != | != | ||
| && | AND | ||
| || | OR | ||
| ! | NOT | ||
| IF | CASE WHEN ELSE | ||
| WHEN | |||
| BOUND | IS NULL | ||
add(numericExpression, numericExpression) => numericExpression |
+ | + | A column must be named with an op.col value. |
divide(numericExpression, numericExpression) => numericExpression |
/ | / | |
modulo(numericExpression, numericExpression) => numericExpression |
% | ||
multiply(numericExpression, numericExpression) => numericExpression |
* | * | |
subtract(numericExpression, numericExpression) => numericExpression |
- | - | |
op:in($testValue as item(), $candidateValues as item()+) as xs:boolean op.in(testValue, [candidateValue1, candidateValue2, ... candidateValueN]) |
IN | IN | Returns true if the test value equals any of the candidate values. |
Expressions that use rows returned from a subplan (similar to SQL or SPARQL EXISTS) are not supported.
Node Constructor Functions
Optic provides node constructor functions that enable you to build tree structures. Node constructor functions can:
- Create JSON objects whose properties come from column values or XML elements whose content or attribute values come from column values.
- Insert documents or nodes extracted via op.xpath into constructed nodes.
- Create JSON arrays from aggregated arrays of nodes or XML elements from aggregated sequences of nodes.
The table below summarizes the Optic node constructor functions. For details on each function, see the Optic API reference documentation.
| Function | Description |
|---|---|
| op.jsonArray | Constructs a JSON array with the specified JSON nodes as items. |
| op.jsonBoolean | Constructs a JSON boolean node with a specified value. |
| op.jsonDocument | Constructs a JSON document with the root content, which must be exactly one JSON object or array node. |
| op.jsonNull | Constructs a JSON null node. |
| op.jsonNumber | Constructs a JSON number node with a specified value. |
| op.jsonObject | Constructs a JSON object with the specified properties. The properties argument is constructed with the prop() function. |
| op.jsonString | Constructs a JSON text node with the specified value. |
| op.prop | Specifies a key expression and value content for a JSON property of a JSON object. |
| op.xmlAttribute | Constructs an XML attribute with a name and atomic value. |
| op.xmlComment | Constructs an XML comment with an atomic value. |
| op.xmlDocument | Constructs an XML document with a root content. |
| op.xmlElement | Constructs an XML element with a name, zero or more attribute nodes, and child content. |
| op.xmlPI | Constructs an XML processing instruction with an atomic value. |
| op.xmlText | Constructs an XML text node. |
| op.xpath | Extracts a sequence of child nodes from a column with node values. |
For example, the following query constructs JSON documents, like the one shown below:
const op = require('/MarkLogic/optic'); const employees = op.fromView('main', 'employees'); employees.select(op.as('Employee', op.jsonDocument( op.jsonObject([op.prop('ID and Name', op.jsonArray([ op.jsonNumber(op.col('EmployeeID')), op.jsonString(op.col('FirstName')), op.jsonString(op.col('LastName')) ])), op.prop('Position', op.jsonString(op.col('Position'))) ]) ))) .result();
This query will produce output that looks like the following:
{ "Employee": { "ID and Name": [ 42, "Debbie", "Goodall" ], "Position": "Senior Widget Researcher" } }
Best Practices and Performance Considerations
Optic does not have a default/implicit limit for the rows or documents returned. Creating plans that return large result sets, such as tens of thousands of rows, may perform poorly. If you experience performance problems, it is a best practice to page the results using the AccessPlan.prototype.offsetLimit method or a combination of AccessPlan.prototype.offset and AccessPlan.prototype.limit methods.
Optic Execution Plan
An Optic Execution Plan expresses a logical dataflow with a sequence of atomic operations. You use the Optic API to build up a plan definition, creating and modifying objects in a pipeline and then executing the plan with the PreparePlan.prototype.result function.
You can use the PreparePlan.prototype.explain function to view or save an execution plan. The execution plan definition consists of operations on a row set. These operations fall into the following categories:
- data access - an execution plan can read a row set from a view, graph, or literals where a view can access the triple index or the cross-product of the co-occurrence of range index values in documents.
- row set modification - an execution plan can filter with
where,order by,group, project withselect, andlimita row set to yield a modified row set. - row set composition - an execution plan can combine multiple row sets with
join,union,intersect, orexceptto yield a single row set. - row result processing - an execution plan can specify operations to perform on the final row set including mapping or reducing.
When a view is opened as an execution plan, it has a special property that has an object with a property for each column in the view. The name of the property is the column name and the value of the property is a name object. To prevent ambiguity for columns with the same name in different views, the column name for a view column is prefixed with the view name and a separating period.
The execution plan result can be serialized to CSV, line-oriented XML or JSON, depending on the output mime type. For details on how to read an execution plan, see Execution Plan in the SQL Data Modeling Guide.
Parameterizing a Plan
You use the op.param function to create a placeholder that can be substituted for any value. You must specify the value of the parameter when executing the plan.
Because the plan engine caches plans, parameterizing a plan executed previously is more efficient than submitting a new plan.
For example, the following query uses a start and length parameter to set the offsetLimit and an increment parameter to increment the value of EmployeeID.
const op = require('/MarkLogic/optic');
const employees = op.fromView('main', 'employees');
employees.offsetLimit(op.param('start'), op.param('length'))
.select(['EmployeeID',
op.as('incremented', op.add(op.col('EmployeeID'),
op.param('increment')))])
.result(null, {start:1, length:2, increment:1});Exporting and Importing a Serialized Optic Query
You can use the IteratePlan.prototype.export method or op:export function to export a serialized form of an Optic query. This enables the plan to be stored as a file and later imported by the op.import or op:import function or to be used by the /v1/rows REST call as a payload. You can recreate the source code used to create an exported plan by means of the op.toSource or op:to-source function.
For example, to export an Optic query to a file, do the following:
const op = require('/MarkLogic/optic'); const EmployeePlan = op.fromView('main', 'employees') .select(['EmployeeID', 'FirstName', 'LastName']) .orderBy('EmployeeID') const planObj = EmployeePlan.export(); xdmp.documentInsert("plan.json", planObj)
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $plan := op:from-view("main", "employees") => op:select(("EmployeeID", "FirstName", "LastName")) => op:order-by("EmployeeID") => op:export() return xdmp:document-insert("plan.json", xdmp:to-json($plan))
To import an Optic query from a file and output the results, do the following:
const op = require('/MarkLogic/optic'); op.import(cts.doc('plan.json').toObject()) .result();
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:import(fn:doc("plan.json")/node()) => op:result()
To view the source code representation of a plan, do the following:
const op = require('/MarkLogic/optic'); op.toSource(cts.doc('plan.json'))
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; op:to-source(fn:doc("plan.json"))
Sampling Data
The Optic API provides a way to sample data.
The following example illustrates the technique for efficient sampling using the op.fromView() accessor where each row is produced from a single document:
const op = require('/MarkLogic/optic'); op.fromView(...).where(...column filters...).select([...projected columns..., op.as('randomNumberCol',op.sql.rand())]).orderBy('randomNumberCol').limit(10)... optional inner or left joins on other accessors ...... optional select expressions constructing column values from multiple accessors ...... optional grouping on rows from other accessors ....result();
The same technique works for the op.fromLexicons() accessor.
The technique also works for the op.fromSQL() accessor when each row is produced from a single document.
The technique also works for the op.fromTriples() or op.fromSPARQL() accessors when each result is produced from a single document.
Query-Based Views
A Query-based view is a view that has been created from an Optic query that can be referenced in subsequent calls to SQL or Optic. This feature is made available in MarkLogic 10.0-7.
The Query-based view (QBV) feature enables you to create SQL views that reference Template (TDE) views, lexicons, and SPARQL queries. SQL CREATE VIEW and a new Optic API (op.generateView) allow you to create custom views. The Query-based views you generate will be stored in the Schemas database and can be shared with privileged users.
Using SQL, you create a view with a statement like this:
CREATE VIEW customers.best_customers WITH ROLE optic_role CAN READ, UPDATE as SELECT name, address, sum(purchase) as total_spent FROM customer ORDER BY total_spent;
This creates a table with the information in columns (name, address, and total_spent) with rows for each entry that users with the optic_role can view.
SELECT * FROM best_customers,
You can supply N number of [WITH ROLE CAN] statements along with CREATE VIEW to grant N role privileges to the view.
READ privilege grants users the ability to query from the view, while UPDATE allows users to update or drop the view.
You must supply UPDATE permissions while creating a view, otherwise the XDMP-MUSTHAVEUPDATE error will be thrown.
You must have the role query-view-admin to create a view. Non-privileged users can use CREATE TEMP VIEW to create a view, but these views will not persist across SQL connections.
The CREATE VIEW statement inserts a document into the Schemas database as http://marklogic.com/qbv/schemaName/viewName.
To use the op.generateView function in the Optic API, you create an Optic query as usual, but instead of returning the result, you call op.generateView and supply a schema and view name for the QBV. Here is an example of creating a view using the Optic API and op.generateView:
const op = require('/MarkLogic/optic');
const trade = op.fromView('Trades','trade')
const customer = op.fromView('customers','customer')
const qbv = trade.joinInner(customer, op.on(op.viewCol('customer', 'customerid'),op.viewCol('trade','customerid')))
.select([op.viewCol('customer','customerid'), opcol('name')])
.orderBy(op.col('name'))
.limit(10)
.generateView('trades','customer_trade')
qbv;The generateView outputs an XML serializable version of the query plan.

You can insert this XML as a file in your Schemas database. The server will discover this new view, allowing you to query from it. Using query-based views, you can create a view from any Optic or SQL query, and that view will persist across SQL connections, enabling privileged users to query from it.
Query-based views have their own security model, allowing you to assign roles to the views, dictating which users can see a view. QBVs also inherit document-level, template-level, column-level, and element-level security from the data they are based on.
If you want to query the same columns from existing tables with certain filters applied repeatedly, you can create a QBV and query from that view with a simple SELECT * statement.
it is not recommended to manually edit the XML output from op.generateView(). This may cause errors and will break the view.
Query-based views can be shared. You can create a view that contains sensitive data for another user to query. The other user can query from the QBV you created, but only see the results that they have the privileges to see. Users can only see data for which they have the appropriate permissions, based on the policies of existing security features, ie. document-level, element-level, column-level security.
The Optic API also allows you to query from triples, which are usually queried from SPARQL. The QBV enables you to run SQL statements against SPARQL results, in turn providing the ability to visualize your triple data in Tableau, PowerBI, or your favorite BI tool.
'use strict'; const op = require('/MarkLogic/optic'); const query = ` PREFIX demov: http://demo/verb# PREFIX vcard: http://www.w3.org/2006/vcard/ns# SELECT ?country ( MAX (?sales) AS ?max_sales ) FROM http://marklogic.com/semantics/sb/COMPANIES100/ WHERE { ?company a vcard:Organization . ?company demov:sales ?sales . ?company vcard:hasAddress [ vcard:country-name ?country ] } GROUP BY ?country ORDER BY ASC( ?max_sales ) ?country ` var view = op.fromSPARQL(query) .limit(10) .generateView('sparql','qbv', [ { name:'country', type:'string', invalidValues:'reject', nullable:false, collation:'http://marklogic.com/collation/codepoint' }, { name:'max_sales', type:'int', invalidValues: 'skip', nullable:true } ]) xdmp.eval( `declareUpdate(); xdmp.documentInsert("sparql-qbv.xml", xmlView, { permissions: [xdmp.permission("optic-user", "read"), xdmp.permission("optic-user", "update")], collections: "http://marklogic.com/xdmp/qbv" })`, { xmlView : view}, { database: xdmp.database('custom-schemas') })
In this example code, the XML output from generateView is stored in the variable view and gets passed to xdmp.eval. This call executes xdmp.documentInsert against the custom-schemas database. This saves the XML serialization as a document under the name sparql-qbv.xml. In this example, we provided users with the optic-role the ability to read and update the view.
Users with read permissions on a view can query from it. Users with update permissions can edit or delete the view. The collection http://marklogic.com/xdmp/qbv is a protected collection. Only users with the built-in role query-view-admin can insert documents into this collection. In order for the view to be query-able, it must belong to this collection.
If creating a query-based view from a SPARQL query, it is necessary to define types for the columns. This is because SPARQL variables are largely untyped, while SQL columns are typed.
We provide the facility to do this, in order to assign the correct type to a QBV column while connecting via ODBC. BI tools use this type to show accurate analytics on your data.
The optional fourth argument to op.generateView() allows you to define types for columns that you see necessary. In the figure above, there is an example of providing a map to define column types for the QBV.
- name - the name of the column in the QBV (required)
- type - the type to define the column as. Any TDE column type is valid for this field. (required)
- nullable - true or false. If you expect null results in this column, set this field to true. (optional - default is true)
- collation - this is specifically for string types. Provide the collation you expect the result to be (optional - default is no collation)
- invalidValues - provide skip or reject to this field. If skip is provided, the engine skips rows that contain values whose type, nullability, or collation don't match your specification. If reject is provided, an error is thrown if a value that does not match the column criteria is found (optional - default is skip)
It is advisable to create a QBV with all invalidValues fields as reject while in development. This is so you can try out the QBV and see if you need to edit the query that generates the view (for example, add a filter).
If you are fine with the engine skipping rows that don't meet the column specification, set invalidValues to skip. This may produce unexpected empty results, so try reject first to see which column doesn't meet your criteria.
You can delete a view using a SQL query or a call to xdmp.documentDelete. Supply the name of the query-based view document in the Schemas database to this function in order to delete it. You can only query against,or drop query-based views for which you have the appropriate permissions.