
SQL Data Modeling Guide — Chapter 2
SQL on MarkLogic Server Quick Start
This chapter describes how to set up your MarkLogic Server for SQL. This chapter describes how to set up a typical development environment in which the SQL client and MarkLogic Server are configured on the same machine. For a production environment, you would typically configure your SQL client and MarkLogic Server on separate machines.
You must have the admin role on MarkLogic Server to complete the procedures described in this chapter.
The main topics in this chapter are:
Setup MarkLogic Server
Install MarkLogic Server on the database server, as described in the Installation Guide. and follow these procedures:
Create a Schema Database and a SQL Database
How to create a database is described in detail in Creating a New Database in the Administrator's Guide. This section provides a quick-start procedure for creating the database used in this example.
Every SQL database must have its own separate schema database.
- Open your browser and navigate to the Admin Interface:
http://hostname:8001
Where hostname is the name of your MarkLogic Server host machine.
- Click the Forests icon in the left tree menu.
- Click the Create tab at the top right. The Create Forest page displays. Enter 'SQLschemas' as the name of your forest in the Forest Name textbox. Click OK.
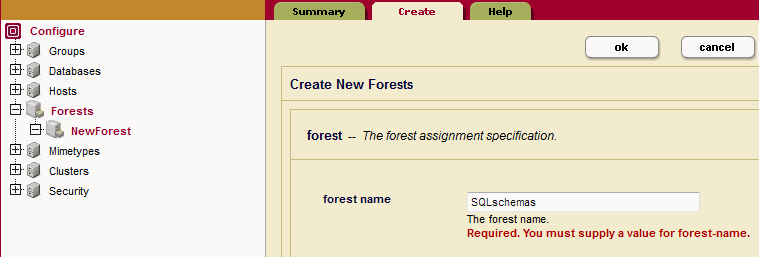
- Click the Create tab at the top right. The Create Forest page displays. Enter 'SQLdata' as the name of your forest in the Forest Name textbox. Click OK.

- Click the Databases icon in the left tree menu.
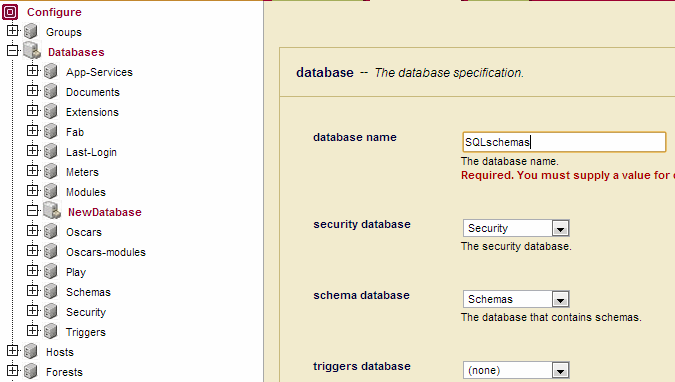
- Click the Create tab at the top right. The Create Database page displays. Enter 'SQLschemas' as the name of the new database and click Ok:
- At the top of the page click Database->Forests
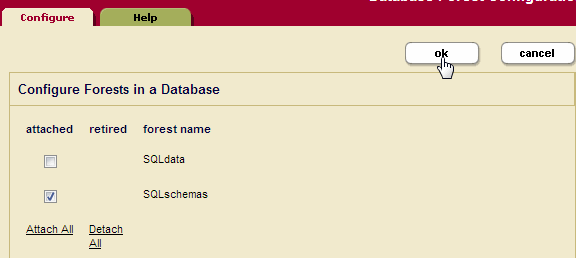
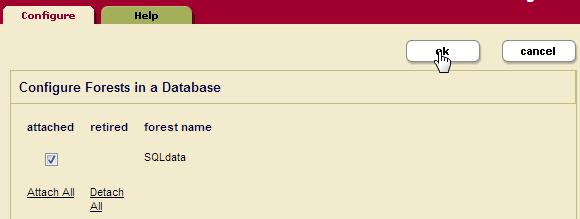
- Check the SQLschemas box to attach the SQLschemas forest. Click Ok:
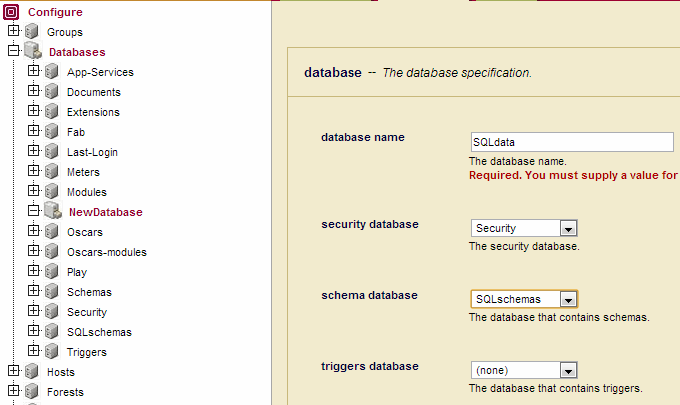
- Click the Create tab at the top right. The Create Database page displays. Enter 'SQLdata' as the name of the new database and select 'SQLschemas' as the Schema Database.
- Scroll down the Create Database page to the Triple Index setting and click 'true' to enable triple indexing. Click Ok:
- At the top of the page click Database->Forests
- Check the SQLdata box to attach the SQLdata forest. Click Ok:


Create an ODBC App Server
Schemas and views represent content stored in a MarkLogic Server database. Each content database used by a SQL client is managed by an ODBC App Server that accepts SQL queries from the SQL client and responds by returning MarkLogic Server data in tuple form. An ODBC App Server can manage only one content database. However, a single content database can be managed by multiple ODBC App Servers.
ODBC App Servers are described in detail in the ODBC Servers chapter in the Administrator's Guide.
To create a new server, complete the following steps:
- Click the Groups icon in the left tree menu.
- Click the group in which you want to define the ODBC server (for example, Default).
- Click the App Servers icon on the left tree menu.
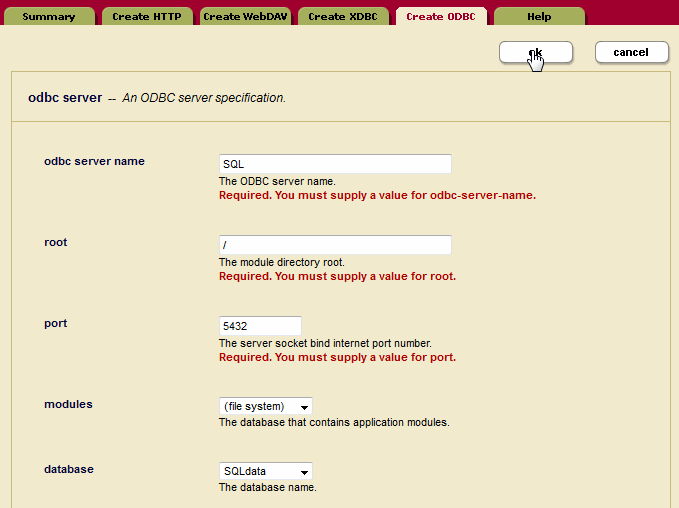
- Click the Create ODBC tab at the top right. The Create ODBC Server page will display:
- In the Server Name field, enter a shorthand name for this ODBC server. In this example, the name of the App Server is 'SQL.'
- In the Root directory field, enter /.
- In the Port field, enter the port number through which you want to make this ODBC server available. The default PostgreSQL listening socket port is 5432.
- Leave the Modules field as
(file system). - In the Database field, select the 'SQLdata' database you created in Create a Schema Database and a SQL Database.
Load the Data
This section describes the procedure for loading the sample documents.
- Go to the following URL to open Query Console:
http://hostname:8000/qconsole/
- Select the SQLdata database from the Content Source pulldown menu and JavaScript from the Query Type menu.

- Cut and paste the following JavaScript into Query Console:
declareUpdate(); xdmp.documentInsert( "/employee1.json", { "Employee": { "ID": 1, "FirstName": "John", "LastName": "Widget", "Position": "Manager of Human Resources" }}), xdmp.documentInsert( "/employee2.json", { "Employee": { "ID": 2, "FirstName": "Jane", "LastName": "Lead", "Position": "Manager of Widget Research" }}), xdmp.documentInsert( "/employee3.json", { "Employee": { "ID": 3, "FirstName": "Steve", "LastName": "Manager", "Position": "Senior Technical Lead" }}), xdmp.documentInsert( "/employee4.json", { "Employee": { "ID": 4, "FirstName": "Debbie", "LastName": "Goodall", "Position": "Senior Widget Researcher" }}), xdmp.documentInsert( "/employee5.json", { "Employee": { "ID": 14, "FirstName": "Lori", "LastName": "Baker", "Position": "Senior Wingnut" }}), xdmp.documentInsert( "/employee6.json", { "Employee": { "ID": 15, "FirstName": "Steve", "LastName": "Lostit", "Position": "Mad Scientist" }}), xdmp.documentInsert( "/employee7.json", { "Employee": { "ID": 16, "FirstName": "Donald", "LastName": "Putin", "Position": "Power Couple" }}), xdmp.documentInsert( "/expense1.json", { "Expenses": { "EmployeeID": 1, "Date": "2012-06-27", "Amount": 131.02, "Purchase": { "Category": "Lodging", "Vendor": "Hyatt Hotels", "Description": "Exec. King Room"}}}), xdmp.documentInsert( "/expense2.json", { "Expenses": { "EmployeeID": 2, "Date": "2012-06-27", "Amount": 155.22, "Purchase": { "Category": "Transportation", "Vendor": "Alaska", "Description": "SFO > SEA"}}}), xdmp.documentInsert( "/expense3.json", { "Expenses": { "EmployeeID": 1, "Date": "2012-08-03", "Amount": 59.95, "Purchase": { "Category": "Meals", "Vendor": "Doug's Dinner", "Description": "Dinner"}}}), xdmp.documentInsert( "/expense4.json", { "Expenses": { "EmployeeID": 3, "Date": "2012-05-07", "Amount": 162.95, "Purchase": { "Category": "Lodging", "Vendor": "Hilton Hotels", "Description": "Exec. Suite"}}}), xdmp.documentInsert( "/expense5.json", { "Expenses": { "EmployeeID": 3, "Date": "2012-05-30", "Amount": 120.00, "Purchase": { "Category": "Lodging", "Vendor": "Kingsman Motel", "Description": "Reg Room"}}}), xdmp.documentInsert( "/expense6.json", { "Expenses": { "EmployeeID": 4, "Date": "2012-03-23", "Amount": 155.55, "Purchase": { "Category": "Lodging", "Vendor": "Waterfront Hotel", "Description": "Queen Room"}}}), xdmp.documentInsert( "/expense7.json", { "Expenses": { "EmployeeID": 4, "Date": "2012-06-05", "Amount": 104.29, "Purchase": { "Category": "Meals", "Vendor": "Good Eats", "Description": "Client Lunch"}}}), xdmp.documentInsert( "/GoodEats.json", { "ApprovedVendor": { "Name": "Good Eats", "Address": { "Street": "707 Oxford Rd.", "City": "Ann Arbor", "Region": "MI", "PostalCode": "48104", "PostalCode": "USA", "Phone": "(313) 555-5735"}}}), xdmp.documentInsert( "/WaterfrontHotel.json", { "ApprovedVendor": { "Name": "Waterfront Hotel", "Address": { "Street": "1000 Coast Rd.", "City": "Santa Cruz", "Region": "CA", "PostalCode": "94330", "PostalCode": "USA", "Phone": "(831) 745-8913"}}}), xdmp.documentInsert( "/KingsmanMotel.json", { "ApprovedVendor": { "Name": "Kingsman Motel", "Address": { "Street": "4832 Frankster St.", "City": "Renor", "Region": "NV", "PostalCode": "88660", "PostalCode": "USA", "Phone": "(702) 436-3785"}}}), xdmp.documentInsert( "/Hilton.json", { "ApprovedVendor": { "Name": "Hilton Hotels", "Address": { "Street": "555 Market St.", "City": "San Francisco", "Region": "CA", "PostalCode": "94033", "PostalCode": "USA", "Phone": "(415) 540-8732"}}}), xdmp.documentInsert( "/Hyatt.json", { "ApprovedVendor": { "Name": "Hyatt Hotels", "Address": { "Street": "9023 Caterberry Ave.", "City": "Seattle", "Region": "WA", "PostalCode": "56445", "PostalCode": "USA", "Phone": "(206) 321-3152"}}}), xdmp.documentInsert( "/MealLimit.json", { "ExpenseLimit": { "Category": "Meals", "Limit": 100}}), xdmp.documentInsert( "/LodgingLimit.json", { "ExpenseLimit": { "Category": "Lodging", "Limit": 300}}), xdmp.documentInsert( "/TransLimit.json", { "ExpenseLimit": { "Category": "Transportation", "Limit": 200}})
- In the control bar below the query window, click Run:
Create Template Views
This section describes how to use the XQuery API to create the template views used by SQL queries.
- Create a template view in the
mainschema, namedemployees. Specify theEmployeeelement as the context and columns forEmployeeID,FirstName,LastName, andPosition. Use tde:template-insert to insert the template document into theSQLschemasdatabase as/employees.xml. Run the script withSQLdataselected in the Database menu.xquery version "1.0-ml"; import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy"; let $employees := <template xmlns="http://marklogic.com/xdmp/tde"> <context>/Employee</context> <rows> <row> <schema-name>main</schema-name> <view-name>employees</view-name> <columns> <column> <name>EmployeeID</name> <scalar-type>int</scalar-type> <val>ID</val> </column> <column> <name>FirstName</name> <scalar-type>string</scalar-type> <val>FirstName</val> </column> <column> <name>LastName</name> <scalar-type>string</scalar-type> <val>LastName</val> </column> <column> <name>Position</name> <scalar-type>string</scalar-type> <val>Position</val> </column> </columns> </row> </rows> </template> return tde:template-insert("/employees.xml", $employees)
- Create a second view in the
mainschema, namedexpenses, with a scope on theExpenseselement as the context and columns forEmployeeID,Date, andAmount. Use tde:template-insert to insert the template document into theSQLschemasdatabase as/expenses.xml.xquery version "1.0-ml"; import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy"; let $expenses := <template xmlns="http://marklogic.com/xdmp/tde"> <context>/Expenses</context> <rows> <row> <schema-name>main</schema-name> <view-name>expenses</view-name> <columns> <column> <name>EmployeeID</name> <scalar-type>int</scalar-type> <val>EmployeeID</val> </column> <column> <name>Date</name> <scalar-type>date</scalar-type> <val>Date</val> </column> <column> <name>Category</name> <scalar-type>string</scalar-type> <val>Purchase/Category</val> </column> <column> <name>Vendor</name> <scalar-type>string</scalar-type> <val>Purchase/Vendor</val> </column> <column> <name>Amount</name> <scalar-type>decimal</scalar-type> <val>Amount</val> </column> </columns> </row> </rows> </template> return tde:template-insert("/expenses.xml", $expenses)
- Create a two more views in the
mainschema, namedapprovedvendorandexpenselimitas follows.xquery version "1.0-ml"; import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy"; let $vendors := <template xmlns="http://marklogic.com/xdmp/tde"> <context>ApprovedVendor</context> <rows> <row> <schema-name>main</schema-name> <view-name>approvedvendor</view-name> <columns> <column> <name>Vendor</name> <scalar-type>string</scalar-type> <val>Name</val> </column> <column> <name>City</name> <scalar-type>string</scalar-type> <val>Address/City</val> </column> </columns> </row> </rows> </template> return tde:template-insert("/vendors.xml", $vendors); xquery version "1.0-ml"; import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy"; let $limits := <template xmlns="http://marklogic.com/xdmp/tde"> <context>ExpenseLimit</context> <rows> <row> <schema-name>main</schema-name> <view-name>expenselimit</view-name> <columns> <column> <name>Category</name> <scalar-type>string</scalar-type> <val>Category</val> </column> <column> <name>Limit</name> <scalar-type>decimal</scalar-type> <val>Limit</val> </column> </columns> </row> </rows> </template> return tde:template-insert("/limits.xml", $limits) - List the views that you just created.
tde:get-view("main","employees"), tde:get-view("main","expenses"), tde:get-view("main","approvedvendor"), tde:get-view("main","expenselimit")
If you change a template view, you must reindex your content database.
Enter SQL Queries to Test
- To test that everything is working correctly, click + to open another query window:
- In the new query window, make sure you have 'SQLdata' selected in the Content Source pull-down menu. Select a Query Type of SQL:
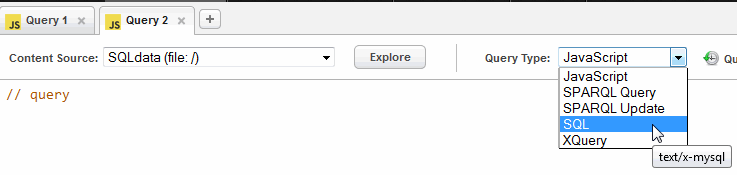
select * from employees
- In the control bar below the query window, select Run.
- You should see results that look like the following:
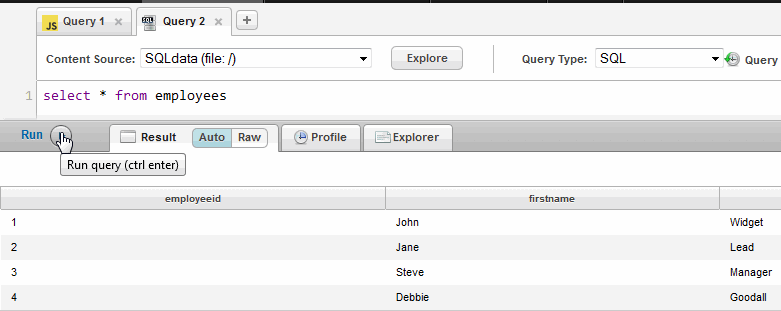
MarkLogic Server treats SQL as case insensitive. Uppercase and lowercase characters are treated the same.
Using MLSQL
The MLSQL tool is a command line interface for issuing SQL statements. The executable MLSQL file is located in the MarkLogic ODBC driver package, described in Installing and Configuring the MarkLogic Server ODBC Driver.
MLSQL is not supported on Mac OS.
You must be assigned the sql-execution role on MarkLogic Server to use MLSQL.
To use the MLSQL tool, open a shell window and enter:
mlsql -h hostname -p 5432 -U username
Enter your password when you see a prompt like:
username=>
Enter a few SQL queries, like the following:
username=> SELECT * FROM main.employees; username=> SELECT employees.FirstName, employees.LastName, SUM(expenses.Amount) AS ExpensesPerEmployee FROM employees, expenses WHERE employees.EmployeeID = expenses.EmployeeID GROUP BY employees.FirstName, employees.LastName; username=> SELECT employees.FirstName, employees.LastName, SUM(expenses.Amount) AS ExpensesPerEmployee FROM employees JOIN expenses ON employees.EmployeeID = expenses.EmployeeID GROUP BY employees.FirstName, employees.LastName ORDER BY ExpensesPerEmployee;
A semicolon (;) is used in MLSQL to designate the end of a SQL query.
To demonstrate the purpose of the Searchable Field in the view, try the following queries:
username=> SELECT * from employees WHERE employees MATCH "Manager"; username=> SELECT * from employees WHERE employees MATCH "position:Manager";
The first query searches for the word Manager in all of the document elements. The position:Manager specification in the second query narrows the search for Manager to the elements included in the position field, which in this case is the Position element.
If you get results from the SQL queries, you can proceed to connecting your BI tool to MarkLogic Server, as described in Connecting Tableau to MarkLogic Server.
If you add or change the contents of a view, database, or documents, you must exit and restart MLSQL.
The MLSQL session commands are:
| Command | Description |
|---|---|
| \copyright | Returns distribution terms. |
| \h | Returns list of available SQL commands. |
| \? | Returns list of available psql commands. |
| \g | Re-executes the last query. |
| \q | Exits MLSQL. |
The syntax of a MLSQL command is:
mlsql [OPTION]... [DBNAME [USERNAME]]