
MarkLogic Server 11.0 Product DocumentationSQL Data Modeling Guide — Chapter 1
SQL on MarkLogic Server
The views module is used to create and manage SQL schemas and views.
The main topics in this chapter are:
Terms Used in this Guide
The following are the definitions for the terms used in this guide:
- A view is a representation of a SQL view. A view is an XML document in the Schemas database and consists of a unique name (which must be unique in the context of a particular schema) and a sequence of column specifications. There are two types of views: template views and range views.
- A schema is a representation of a SQL schema. A schema is implemented as an XML document in the Schemas database and consists of a unique name (which must also be unique) and a collection of views. During SQL execution, the schema provides the naming context for its views, which enables you to have multiple views of the same name in different schemas. The default schema is called main. It is default in the sense that it is always implicitly available and first on the default schema search path for name resolution in SQL. Even though the main schema is a default, you must create this schema.
- A column in a view has a name, SQL datatype, and a value that identifies a particular document element or property.
- A view scope is used to constrain the subset of the database to which the view applies. A view scope can either limit rows in the view to documents with a specific element (local name + namespace), to documents in a particular directory, or to documents in a particular collection.
- Template Driven Extraction (TDE) is the method used to map documents in a MarkLogic database to SQL views.
You must have the
tde-adminandany-uriroles to create template views and theview-adminrole to create range views.
Schemas and Views
Schemas and views are the main SQL data-modeling components used to represent content stored in a MarkLogic Server database to SQL clients. A view is a virtual read-only table that represents data stored in a MarkLogic Server database. Each column in a view is based on an index in the content database, as described in Example Template View. User access to each view is controlled by a set of permissions, as described in Template View Security.
- template views: Views that are created by Template Driven Extraction (TDE templates). template views are inserted as documents into the schema database associated with the content database. When inserted into a schema database, template views automatically creates triple data in the content database for each column defined in the template and all of the documents are reindexed. Template views can also be created to extract existing triples in documents, rather than elements.
- range views: Views that are based on range indexes and fields. Each column in a view is based on a range index or field in the content database. You must create the range indexes and fields in the content database before creating a range view. Unlike template views, range views allow you to add and remove columns on the view.
In most situations, you will want to create a template view. Though a range view may be preferable to a template view in some situations, such as for a database already configured with range indexes, they are supported mostly for backwards compatibility with previous versions of MarkLogic. For this reason, most of the discussion in this guide will be on the use of template views. For details on range views, see Creating Range Views.
A schema is a naming context for a set of views and user access to each schema can be controlled with a different set of permissions. Each view in a schema must have a unique name. However, you can have multiple views of the same name in different schemas. For example, you can have three views, named 'Songs,' each in a different schema with different protection settings.
Each view has a scope that defines the documents from which it reads the column data. The view scope constrains the view to documents located in a particular directory (template views only), or to documents in a particular collection. The following figure shows a schema called 'main' that contains two views, each with a different view scope. The view Songs is constrained to documents that are in the http://view/songs collection and the view Names is constrained to documents that are located in the /my/directory/ directory.
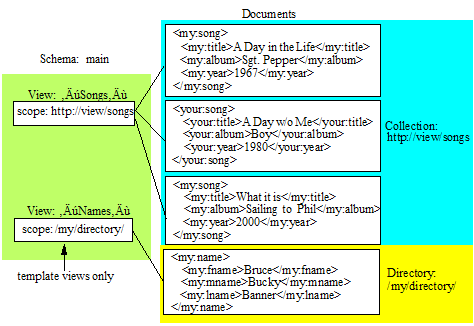
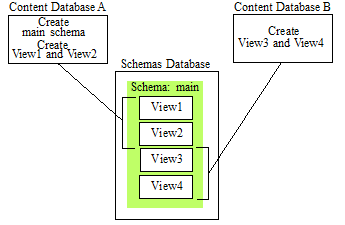
As described above, schemas and views are stored as documents in the schema database associated with the content database for which they are defined. The default schema database is named 'Schemas.' If multiple content databases share a single schema database, each content database will have access to all of the views in the schema database.
For example, in the following figure, you have two content databases, Database A and Database B, that both make use of the Schemas database. In this example, you create a single schema, named 'main,' that contains two views, View1 and View2, on Database A. You then create two views, View3 and View4, on Database B and place them into the 'main' schema. In this situation, both Database A and Database B will each have access to all four views in the 'main' schema.
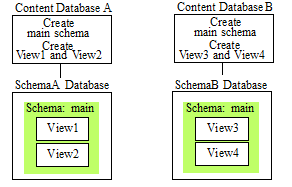
A more relational configuration is to assign a separate schema database to each content database. In the following figure, Database A and Database B each have a separate schema database, SchemaA and SchemaB, respectively. In this example, you create a 'main' schema for each content database, each of which contains the views to be used for its respective content database.
Template View Security
The tde-admin and any-uri roles are required in order to insert a template document into the schema database.
The tde-view role is required to access a template view. Access to views can be further restricted by setting additional permissions on the template document that defines the view. Since the same view can be declared in multiple templates loaded with different permissions, the access to views should be controlled at the column level.
Column level read permissions are implicit and are derived from the read permissions set on the template documents. Permissions on a column are not required to be identical and are ORed together. A user with a role that has at least one of the read permissions set on a column will be able to see the column.
If a user does not have permissions on any of the view's columns, the view itself is not visible.
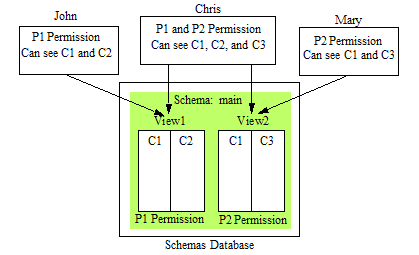
For example, there are two views:
- The View1 template document is configured for Columns C1 and C2 was loaded with P1 Permissions.
- The View2 template document is configured for Columns C1 and C3 was loaded with P2 Permissions.
John has P1 Permissions, so he can see Columns C1 and C2.
Chris has both P1 and P2 Permissions, so he can see Columns C1, C2, and C3.
Mary has P2 Permissions, so she can see Columns C1 and C3.
For details on how to set document permissions, see Protecting Documents in the Security Guide.
TDE extracts rows in the form of triples from documents during ingestion. TDE does not extract triples/rows from an element that is concealed for any role. TDE extracts data from unprotected parts of a document. For protected elements (for any role), TDE behavior is generally the same as if the element was missing in the document. There are exceptions, which are described in Template Driven Extraction (TDE) in the Application Developer's Guide.
Example Template View
This section provides an example document and a template view used to extract data from the document and present it in the form of a view.
Consider a document of the following form:
<book> <title subject="oceanography">Sea Creatures</title> <pubyear>2011</pubyear> <keyword>science</keyword> <author> <name>Jane Smith</name> <university>Wossamotta U</university> </author> <body> <name type="cephalopod">Squid</name> Fascinating squid facts... <name type="scombridae">Tuna</name> Fascinating tuna facts... <name type="echinoderm">Starfish</name> Fascinating starfish facts... </body> </book>
The following template extracts each element and presents it as a column in a view, named 'book' in the 'main' schema.
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/book</context> <rows> <row> <schema-name>main</schema-name> <view-name>book</view-name> <columns> <column> <name>title</name> <scalar-type>string</scalar-type> <val>title</val> </column> <column> <name>pubyear</name> <scalar-type>date</scalar-type> <val>pubyear</val> </column> <column> <name>keyword</name> <scalar-type>string</scalar-type> <val>keyword</val> </column> <column> <name>author</name> <scalar-type>string</scalar-type> <val>author/name</val> </column> <column> <name>university</name> <scalar-type>string</scalar-type> <val>author/university</val> </column> <column> <name>cephalopod</name> <scalar-type>string</scalar-type> <val>body/name[@type="cephalopod"]</val> </column> <column> <name>scombridae</name> <scalar-type>string</scalar-type> <val>body/name[@type="scombridae"]</val> </column> <column> <name>echinoderm</name> <scalar-type>string</scalar-type> <val>body/name[@type="echinoderm"]</val> </column> </columns> </row> </rows> </template>