
Concepts Guide — Chapter 4
Data Management
MarkLogic has the unique ability to bring multiple heterogenous data-sources (by structure and function) into a single platform architecture and allow for homogenous data access across disparate data-sources. Data sources do not have to be shredded or normalized to present a consistent view of the information. MarkLogic supports multiple mechanisms to present information to end-consumers in the language of their choice.
This chapter describes how MarkLogic manages data on disk and handles concurrent reads and writes. The main topics are:
- What's on Disk
- Ingesting Data
- Modifying Data
- Multi-Version Concurrency Control
- Point-in-time Queries
- Locking
- Updates
- Isolating an update
- Documents are Like Rows
- MarkLogic Data Loading Mechanisms
- Content Processing Framework (CPF)
- Organizing Documents
- Database Rebalancing
- Bitemporal Documents
- Managing Semantic Triples
What's on Disk
This section describes how data is managed on disks. The topics are:
- Databases, Forests, and Stands
- Tiered Storage
- Super Databases and Super Clusters
- Partitions, Partition Keys, and Partition Ranges
Databases, Forests, and Stands
A database consists of one or more forests. A forest is a collection of documents that is implemented as a physical directory on disk. Each forest holds a set of documents and all of their indexes. A single machine may manage several forests, or in a cluster (when acting as an E-node) it might manage none. Forests can be queried in parallel, so placing more forests on a multi-core server can help with concurrency. A rule of thumb is to have one forest for every 2 cores on a box, with each forest holding millions or tens of millions of documents. In a clustered environment, you can have a set of servers, each managing their own set of forests, all unified into a single database.
Each forest holds zero or more stands. A stand (like a stand of trees) holds a subset of the forest data and exists as a physical subdirectory under the forest directory. Each stand contains the actual compressed document data (in TreeData) and indexes (in IndexData).
A forest might contain a single stand, but it is more common to have multiple stands because stands help MarkLogic ingest data more efficiently and improve concurrency.
Tiered Storage
MarkLogic allows you to manage your data at different tiers of storage and computation environments, with the top-most tier providing the fastest access to your most critical data and the lowest tier providing the slowest access to your least critical data. Infrastructures, such as Hadoop and public clouds, make it economically feasible to scale storage to accommodate massive amounts of data in the lower tiers. Segregating data among different storage tiers allows you to optimize trade-offs among cost, performance, availability, and flexibility.
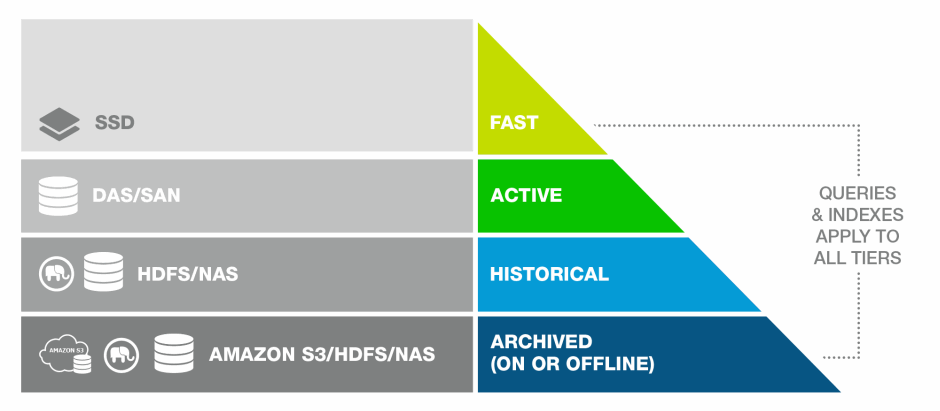
For more detail on tiered storage, see the Tiered Storage chapter in the Administrator's Guide.
Super Databases and Super Clusters
Multiple databases, even those that serve on different storage tiers, can be grouped into a super-database in order to allow a single query to be done across multiple tiers of data. Databases that belong to a super-database are referred to as sub-databases. A single sub-database can belong to multiple super-databases.
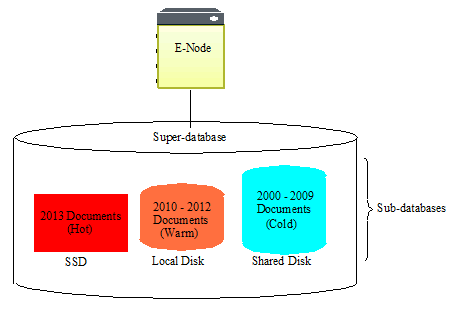
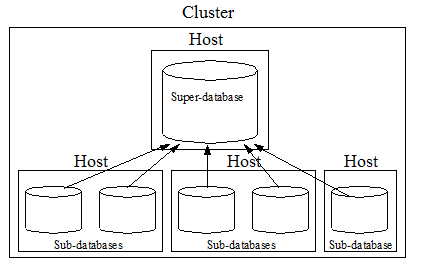
Sub-databases can be distributed on different storage tiers and on different clusters (called super-clusters). Updates are made on the sub-databases and they made visible for read in the super-database. Below is an illustration of a super-database and its sub-databases configured on a single cluster.
Below is a super-database configured with sub-databases on different foreign clusters. The cluster hosting the super-database must be coupled with the foreign clusters hosting the sub-databases.
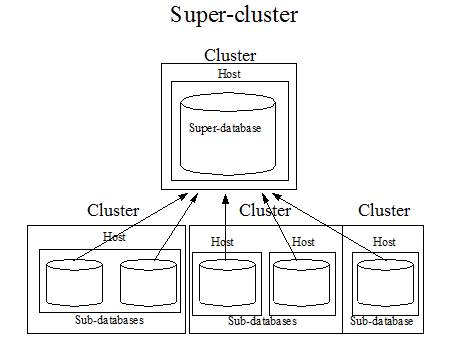
For more detail on super-databases and sub-databases, see the Super Databases and Clusters chapter in the Administrator's Guide.
Partitions, Partition Keys, and Partition Ranges
MarkLogic Server tiered storage manages data in partitions. Each partition consists of a group of database forests that share the same name prefix and the same partition range.
The range of a partition defines the scope of element or attribute values for the documents to be stored in the partition. This element or attribute is called the partition key. The partition key is based on a range index, collection lexicon, or field set on the database. The partition key is set on the database and the partition range is set on the partition, so you can have several partitions in a database with different ranges.
For example, you have a database, named WorkingVolumes, that contains nine forests that are grouped into three partitions. Among the range indexes in the WorkingVolumes database is an element range index for the update-date element with a type of date. The WorkingVolumes database has its partition key set on the update-date range index. Each forest in the WorkingVolumes database contains a lower bound and upper bound range value of type date that defines which documents are to be stored in which forests, as shown in the following table:
In this example, a document with an update-date element value of 2011-05-22 would be stored in one of the forests in the Vol2 partition. Should the update-date element value in the document get updated to 2012-01-02 or later, the document will be automatically moved to the Vol3 partition. How the documents are redistributed among the partitions is handled by the database rebalancer, as described in Range Assignment Policy.
Following is an illustration of the WorkingVolumes database, showing its range indexes, partition key, and its partitions and forests.
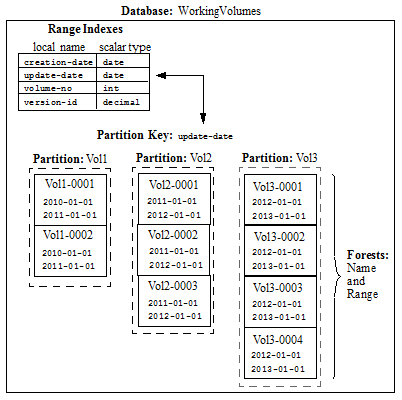
In a few months, the volumes of documents grow to 5 and there is no longer enough space on the fast SSD device to hold all of them. Instead, the oldest and least queried volumes (Vol1-Vol3) are migrated to a local disk drive, which represents a slower storage tier.
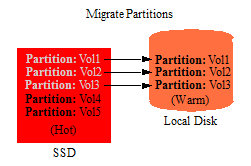
After years of data growth, the volumes of documents grow to 50. After migrating between storage tiers, the partitions are eventually distributed among the storage tiers, as shown below.
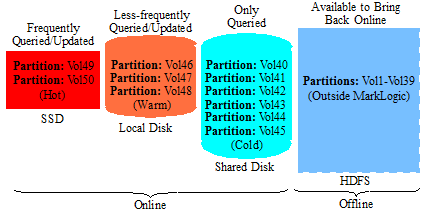
Ingesting Data
To see how MarkLogic ingests data, imagine an empty database having a single forest that (because it has no documents) has no stands. When a new document is loaded into MarkLogic, MarkLogic puts this document into an in-memory stand and writes the action to an on-disk journal to maintain transactional integrity in case of system failure.
As new documents are loaded, they are also placed in the in-memory stand. A query request at this point will see all of the data on disk (nothing yet), as well as everything in the in-memory stand (our small set of documents). The query request cannot tell where the data is located, but will see the full view of data loaded at this point in time.
After enough documents are loaded, the in-memory stand will fill up and be flushed to disk, written out as an on-disk stand. Each new stand gets its own subdirectory under the forest directory, with names that are monotonically-increasing hexadecimal numbers. The first stand is named 00000000. That on-disk stand contains all the data and indexes for the documents loaded so far. The stand data is written from memory out to disk as a sequential write for maximum efficiency. Once written to disk, the in-memory stand's allocated memory is freed.
As more documents are loaded, they go into a new in-memory stand. At some point this in-memory stand fills up as well, and the in-memory stand gets written as a new on-disk stand, probably named 00000001, and about the same size as the first on-disk stand. Sometimes under heavy load you may have two in-memory stands at once, when the first stand is still writing to disk as a new stand is created for additional documents. At all times an incoming query or update request can see all the data across the in-memory and on-disk stands.
As more documents are loaded, the process continues with in-memory stands filling up and writing to on-disk stands. As the total number of on-disk stands grows, an efficiency issue threatens to emerge. To read a single term list, MarkLogic must read the term list data from each individual stand and unify the results. To keep the number of stands to a manageable level where that unification is not a performance concern, MarkLogic merges some of the stands on disk into a new singular stand. The merge operation is done in the background, where the indexes and data are coalesced and optimized and previously deleted fragments are removed, as described below in Modifying Data. After the merge finishes and the new on-disk stand has been fully written, and after all the current requests using the old on-disk stands have completed, MarkLogic deletes the old on-disk stands.
MarkLogic uses an algorithm to determine when to merge, based on the size of each stand. In a normal server running under constant load you will usually see a few large stands, a few more mid-sized stands, and several more small stands. Over time, the smaller stands get merged with ever-larger stands. Merges tend to be CPU- and disk-intensive, so you have control over when merges can happen via system administration.
Each forest has its own in-memory stand and a set of on-disk stands. A new document gets assigned to a forest based on the rebalancer document assignment policy set on the database, as described in Rebalancer Document Assignment Policies in the Administrator's Guide. Loading and indexing content is a largely parallelizable activity, so splitting the loading effort across forests and potentially across machines in a cluster can help scale the ingestion work.
Modifying Data
If you delete a document, MarkLogic marks the document as deleted but does not immediately remove it from disk. The deleted document will be removed from query results based on its deletion markings, and the next merge of the stand holding the document will bypass the deleted document when writing the new stand.
If you change a document, MarkLogic marks the old version of the document as deleted in its current stand and creates a new version of the document in the in-memory stand. MarkLogic distinctly avoids modifying the document in place. Considering how many term lists a single document change might affect, updates in place would be inefficient. So, instead, MarkLogic treats any changed document like a new document, and treats the old version like a deleted document.
To keep the discussion simple, the delete and update operations have been described as being performed on documents. However, as described in Fragmentation of XML Documents, fragments (not documents) are the basic units of query, retrieval, and update. So if you have fragmentation rules enabled and make a change on a document that has fragments, MarkLogic will determine which fragments need to change and will mark them as deleted and create new fragments as necessary.
This approach is known as Multi-Version Concurrency Control (MVCC), which has several advantages, including the ability to run lock-free queries, as explained next in Multi-Version Concurrency Control.
Multi-Version Concurrency Control
In an MVCC system, changes are tracked with a timestamp number that increments for each transaction as the database changes. Each fragment gets its own creation-time (the timestamp at which it was created) and deletion-time (the timestamp at which it was marked as deleted, starting at infinity for fragments not yet deleted). On disk, you can see these timestamps in the Timestamps file, which is the only file in the stand directory that is not read-only.
For a request that does not modify data (called a query, as opposed to an update that might make changes), the system gets a performance boost by skipping the need for URI locking. The query is viewed as running at a certain timestamp, and throughout its life it sees a consistent view of the database at that timestamp, even as other (update) requests continue forward and change the data.
MarkLogic does this by adding to the normal term list constraints two extra constraints: first, that any fragments returned have to have been created at or before the request timestamp and second, that they have to have been deleted after the request timestamp. It is easy to create from these two primitives what is in essence a new implicit term list of documents in existence at a certain timestamp. This timestamp-based term list is implicitly added to every query as a high-performance substitute for locks.
Point-in-time Queries
Normally a query acquires its timestamp marker automatically based on the time the query started. However, it is also possible for a query to request data at a specific previous timestamp. MarkLogic calls this feature point-in-time queries. Point-in-time queries let you query the database as it used to be at any arbitrary point in the past, as efficiently as querying at present time. One popular use of point-in-time queries is to lock the public data at a certain timestamp while new data is loaded and tested. Only when the new data is approved does the public timestamp jump to be current. And, of course, if the data is not approved, you can undo all the changes back to a past timestamp (this is referred to as database rollback).
When doing point-in-time queries, you have to consider merging, which normally removes deleted documents. If you want to travel into the past to see deleted documents, you need to administratively adjust the merge setting to indicate a timestamp before which documents can be reclaimed and after which they can't. This timestamp becomes the point furthest in the past to which you can query a document.
Locking
An update request must use read/write locks to maintain system integrity while making changes. This lock behavior is implicit and not under the control of the user. Read-locks block for write-locks and write-locks block for both read- and write-locks. An update has to obtain a read-lock before reading a document and a write-lock before changing (adding, deleting, modifying) a document. Lock acquisition is ordered, first-come first-served, and locks are released automatically at the end of the update request.
In any lock-based system you have to worry about deadlocks, where two or more updates are stalled waiting on locks held by the other. In MarkLogic deadlocks are automatically detected with a background thread. When the deadlock happens on the same host in a cluster, the update farthest along (the one with the most locks) wins and the other update gets restarted. When it happens on different hosts, both updates start over.
MarkLogic differentiates queries from updates using static analysis. Before running a request, it looks at the code to determine if it includes any calls to update functions. If so, the request is an update. If not, the request is a query.
Updates
Locks are acquired during the update execution, yet the actual commit work only happens after the update has successfully finished. If the update exits with an error, all pending changes that were part of that update are discarded. Each statement is its own autocommit transaction.
During the update request, the executing code can't see the changes it is making. This is because an update function does not immediately change the data, but rather adds a work order to the queue of things to do should the update end successfully.
Code cannot see the changes it is making because XQuery is a functional language that allows different code blocks to be run in parallel if the blocks do not depend on each other. If the code blocks are to be run in parallel, one code block should not depend on updates from another code block to have already happened at any point.
Any batch of parallel updates has to be non-conflicting. The easiest definition of non-conflicting is that they could be run in any order with the same result. You can't, for example, add a child to a node in one code block and delete the node in another, because if the execution were the inverse it wouldn't make sense. You can however make numerous changes to the same document in the same update, as well as to many other documents, all as part of the same atomic commit.
Isolating an update
When a request potentially touches millions of documents (such as sorting a large data set to find the most recent items), a query request that runs lock-free will outperform an update request that needs to acquire read-locks and write-locks. In some cases you can speed up the query work by isolating the update work to its own transactional context.
This technique only works if the update does not have a dependency on the query, which is a common case. For example, you want to execute a content search and record the user's search string to the database for tracking purposes. The database update does not need to be in the same transactional context as the search itself, and would slow the transaction down if it were. In this case it is better to run the search in one context (read-only and lock-free) and the update in a different context.
See the documentation for the xdmp:eval and xdmp:invoke functions for details on how to invoke a request from within another request and manage the transactional contexts between the two.
Documents are Like Rows
When modeling data for MarkLogic, think of documents more like rows than tables. In other words, if you have a thousand items, model them as a thousand separate documents not as a single document holding a thousand child elements. This is for two reasons:
- Locks are managed at the document level. A separate document for each item avoids lock contention.
- All index, retrieval, and update actions happen at the fragment level. When finding an item, retrieving an item, or updating an item, it is best to have each item in its own fragment. The easiest way to accomplish that is to put them in separate documents.
Of course MarkLogic documents can be more complex than simple relational rows because XML and JSON are more expressive data formats. One document can often describe an entity (a manifest, a legal contract, an email) completely.
MarkLogic Data Loading Mechanisms
MarkLogic Server provides many ways to load content into a database. Choosing the appropriate method for a specific use case depends on many factors, including the characteristics of your content, the source of the content, the frequency of loading, and whether the content needs to be repaired or modified during loading. In addition, environmental and operational factors such as workflow integration, development resources, performance considerations, and developer expertise often need to be considered in choosing the best tools and mechanisms.
The following table summarizes content loading interfaces and their benefits.
For details on loading content into a MarkLogic database, see the Loading Content Into MarkLogic Server Guide.
Content Processing Framework (CPF)
The Content Processing Framework (CPF) is an automated system for transforming documents from one file format type to another, one schema to another, or breaking documents into pieces. CPF uses properties sheet entries to track document states and uses triggers and background processing to move documents through their states. CPF is highly customizable and you can plug in your own set of processing steps (called a pipeline) to control document processing.
MarkLogic includes a "Default Conversion Option" pipeline that takes Microsoft Office, Adobe PDF, and HTML documents and converts them into XHTML and simplified DocBook documents. There are many steps in the conversion process, and all of the steps are designed to execute automatically, based on the outcome of other steps in the process.
For more information on CPF, see the Content Processing Framework Guide.
Organizing Documents
There are a number of ways documents can be organized in a MarkLogic database. This section describes the following organization mechanisms:
Directories
Documents are located in directories in a MarkLogic database. Directories are hierarchical in structure (like a filesystem directory structure) and are described by a URI path. Because directories are hierarchical, a directory URI must contain any parent directories. For example, a directory named http://marklogic.com/a/b/c/d/e/ (where http://marklogic.com/ is the root) requires the existence of the parent directories d, c, b, and a.
Directories are required for WebDAV clients to see documents. In other words, to see a document with URI /a/b/hello/goodbye in a WebDAV server with /a/b/ as the root, directories with the following URIs must exist in the database:
/a/b/ /a/b/hello/
Collections
A collection is a named group of documents. The key differences in using collections to organize documents versus using directories are:
- Collections do not require member documents to conform to any URI patterns. They are not hierarchical; directories are. Any document can belong to any collection, and any document can also belong to multiple collections.
- You can delete all documents in a collection with the xdmp:collection-delete function. Similarly, you can delete all documents in a directory (as well as all recursive subdirectories and any documents in those directories) with the xdmp:directory-delete function.
- You cannot set properties on a collection; you can on a directory.
A document is assigned to a collection when it is inserted or updated. A document can also be assigned to a collection after it is loaded. A document can also be put into a collection implicitly when the document is loaded, based on the default collections assigned to the user's role(s). A document can belong to multiple collections.
Unprotected Collections
An unprotected collection is created implicitly when inserting or updating a document and specifying a collection URI that has not previously been used. An unprotected collection is not stored in the security database.
Any user with insert or update permissions on a document can add the document to or remove the document from an unprotected collection.
You can convert an unprotected collection to a protected collection, and vice versa.
Protected Collections
Protected collections enable you to control who can add documents to a collection. A protected collection does not affect access to documents in the collection. Use document permissions to control document access.
Only users with insert or update permissions on the collection can add documents to the collection. A user with update access to a document in a protected collection can update or delete the document whether or not they have any collection permissions. Such a user can also remove the document from the collection by re-inserting the document with a different set of collections. A user with read access to a document in a protected collection can read and search the document, whether or not they have any collection permissions.
A protected collection must be explicitly created using the Admin Interface, the Admin API, or the REST Management API. MarkLogic stores protected collection configuration information in the security database.
You can convert a protected collection to an unprotected collection, and vice versa.
Database Rebalancing
As your needs for data in a database expand and contract, the more evenly the content is distributed among the database forests, the better its performance and the more efficient its use of storage resources. MarkLogic includes a database rebalancing mechanism that enables it to evenly distribute content among the database forests.
A database rebalancer consists of two parts: an assignment policy for data insert and rebalancing and a rebalancer for data movement. The rebalancer can be configured with one of several assignment policies, which define what is considered balanced for a database. You choose the appropriate policy for a database. The rebalancer runs on each forest and consults the database's assignment policy to determine which documents do not belong to this forest and then pushes them to the correct forests. The assignment policies are described in Rebalancer Document Assignment Policies in the Administrator's Guide.
Document loads and inserts into the database follow the same document assignment policy used by the rebalancer, regardless of whether the rebalancer is enabled or disabled.
When you add a new forest to a database configured with a rebalancer, the database will automatically redistribute the documents among the new forest and existing forests. You can also retire a forest in a database to remove all of the documents from that forest and redistribute them among all of the remaining forests in the database.
In addition to enabling and disabling on the database level, the rebalancer can also be enabled or disabled at the forest level. For the rebalancer to run on a forest, it must be enabled on both the database and the forest.
For more information on database rebalancing, see the Database Rebalancing chapter in the Administrator's Guide.
Bitemporal Documents
Bitemporal data is data that is associated with two time values:
- Valid time - The actual time at which an event was known to occur.
- System time - The time at which the event is recorded in the database.
Bitemporal data is commonly used in financial applications to answer questions, such as:
- What were my customer's credit ratings last Monday as I knew it last Friday?
- What did we think our first quarter profit was when we gave guidance?
- What did we think the high day was when our trading strategy kicked in?
There are two aspects to bitemporal documents in MarkLogic Server:
Bitemporal Data Management
As bitemporal data management addresses audit and regulatory requirements, no record in bitemporal database can be deleted. This rule drives the semantics of insert, delete and update. Bitemporality is defined on a protected collection. The following describes the insert, update, and delete operations on bitemporal data:
- Insert: Each insert must set system begin and end times to the element that represent the system time period. On insert, the system end time is set to the farthest possible time. The document being inserted should already include one and only one occurrence of valid time.
- Delete: No document can be deleted from a bitemp oral collection without admin privilege. A logically deleted document remains in the database with system end time set to the time of deletion.
- Update: Update is a delete followed by one or more insert(s). The end time is marked as the time when update is performed and new version(s) of the document are inserted.
It is possible that documents will come in random order of system time, meaning later documents can either have bigger or smaller timestamp than earlier documents. The eventual state of the database will be the same as long as the exact same documents are ingested regardless of order.
For more detail on managing bitemporal documents in MarkLogic, see Managing Temporal Documents in the Temporal Developer's Guide.
Bitemporal Queries
Bitemporal queries are basically some interval operations on time period such as, period equalities, containment and overlaps. Allen's interval algebra provides the most comprehensive set of these operations to the best of our knowledge. SQL 2011 also provides similar operators. However all the SQL operators can be expressed using Allen's Algebra.
For more detail on querying bitemporal documents in MarkLogic, see Searching Temporal Documents in the Temporal Developer's Guide.
Managing Semantic Triples
You can use SPARQL Update with MarkLogic to manage both your managed RDF triple data and the RDF graphs containing the triples. With SPARQL Update you can delete, insert, and delete/insert (or "update") RDF triples and graphs. It uses a syntax derived from the SPARQL Query Language for RDF to perform update operations on a collection of graphs.
SPARQL Update is a formal W3C recommendation for managing triples described in the SPARQL Update 1.1 specification:
http://www.w3.org/TR/2013/REC-sparql11-update-20130321/
For details on MarkLogic support of SPARQL Update and RDF triples, see SPARQL Update in the Semantics Developer's Guide.