
Administrator's Guide — Chapter 18
Tiered Storage
MarkLogic Server allows you to manage your data at different tiers of storage and computation environments, with the top-most tier providing the fastest access to your most critical data and the lowest tier providing the slowest access to your least critical data. Infrastructures, such as Hadoop and public clouds, make it economically feasible to scale storage to accommodate massive amounts of data in the lower tiers. Segregating data among different storage tiers allows you to optimize trade-offs among cost, performance, availability, and flexibility.
Tiered storage is supported by the XQuery, JavaScript, and REST APIs. This chapter describes the tiered storage operations using the REST API, which supports all of the operations you will want to integrate into your storage-management scripts.
To use Tiered Storage, a license that includes Tiered Storage is required.
This chapter contains the following topics:
- Terms Used in this Chapter
- Overview of Tiered Storage
- Range Partitions
- Query Partitions
- Partition Migration
- Configuring a Database with Range Partitions
- Configuring a Database with Query Partitions
- Overview of the Tiered Storage REST API
- Common Forest and Partition Operations
- Partitions with Forest-Level Failover
Terms Used in this Chapter
- A Partition is a set of forests sharing the same name prefix and same partition definition. Typically forests in a partition share the same type of storage and configuration such as updates allowed, availability, and enabled status. Partitions are based on forest naming conventions. A forest's partition name prefix and the rest of the forest name are separated by a dash (-). For example, a forest named
2011-0001belongs to the2011partition. - A Range Partition is a partition that is associated with a range of values. Documents with a partition key value that fall within the range specified for a partition are stored in that range partition.
- A Query Partition is a partition that is associated with a query. Documents that are returned by the query specified for a query partition are stored in that query partition.
- A Partition Key defines an element or attribute on which a range index, collection lexicon, or field is set and defines the context for the range set on the range partitions in the database. The partition key is a database-level setting.
- A Default Partition is a partition with no defined range or query. Documents that have no partition key or a partition key value that does not fall into any of the partition ranges or queries are stored in the default partition.
- A Super-database is a database containing other databases (sub-databases) so that they can be queried as if they were a single logical database.
- A Sub-database is a database contained in a super-database.
- Active Data is data that requires low-latency queries and updates. The activeness of a particular document is typically determined by its recency and thus changes over time.
- Historical Data is less critical for the lowest-latency queries than active data, but still requires online access for queries. Historical data is not typically updated.
- Archived Data is data that has aged beyond its useful life in the online storage tiers and is typically taken offline.
- An Online partition or forest is available for queries and updates.
- An Offline partition or forest is not available for queries, but is tracked by the cluster. The benefit of taking data offline is to spare the RAM, CPU, and network resources for the online data.
- The Availability of a partition or forest refers to its online/offline status.
Overview of Tiered Storage
The MarkLogic tiered storage APIs enable you to actively and easily move your data between different tiers of storage. For example, visualize how data might be tiered in different storage devices in a pyramid-like manner, as illustrated below.
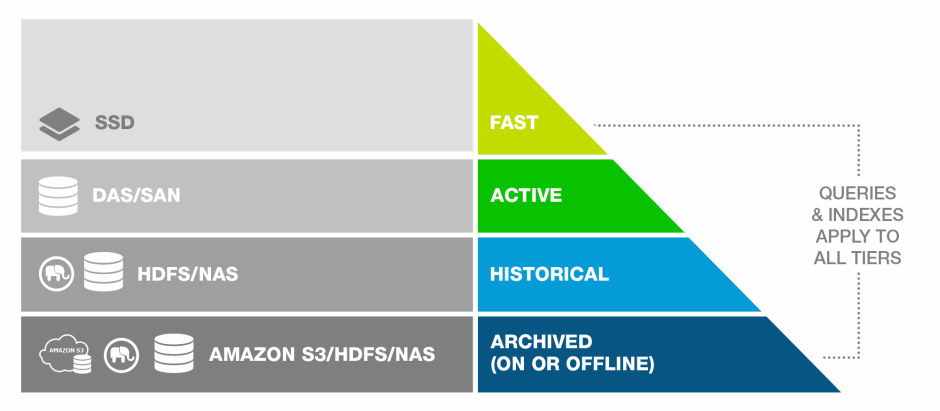
As data ages and becomes less updated and queried, it can be migrated to less expensive and more densely-packed storage devices to make room for newer, more frequently accessed and updated data, as illustrated in the graph below.
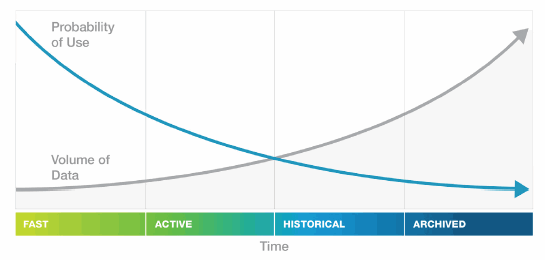
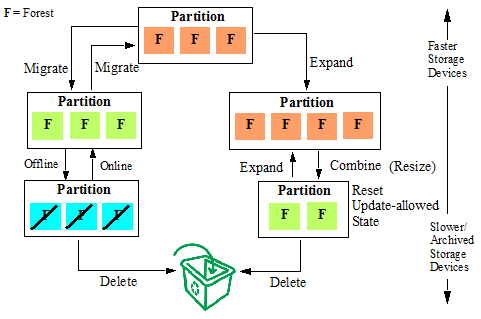
The illustration below shows the basic tiered storage operations:
- Migrate a partition to a different database, host, and/or directory, which may be mounted on another storage device.
- Resize the partition to expand or contract the number of forests it contains.
- Combine a number of forests into a single forest.
- Reset the update-allowed state of a partition. For example, make the partition read-only, so it can be stored more compactly on a device that is not required to reserve space for forest merges.
- Take a partition offline to archive the partition. The partition data is unavailable to query, update, backup, restore and replicate operations.
- Take a partition online to make the partition data available again.
- Delete a partition when its data has outlived its useful life.
Forest migrate, forest combine, partition migrate and partition resize may result in potential data loss when used during XA transactions.
Range Partitions
A range partition consists of a group of database forests that share the same name prefix and the same range assignment policy described in Range Assignment Policy.
When deploying forests in a cluster, you should align forests and forest replicas across hosts for parellelization and high availability, as described in the Scalability, Availability, and Failover Guide.
The range of a partition defines the scope of element or attribute values for the documents to be stored in the partition. This element or attribute is called the partition key. The partition key is based on a range index, collection lexicon, or field set on the database. The partition key is set on the database and the partition range is set on the partition, so you can have several partitions in a database with different ranges.
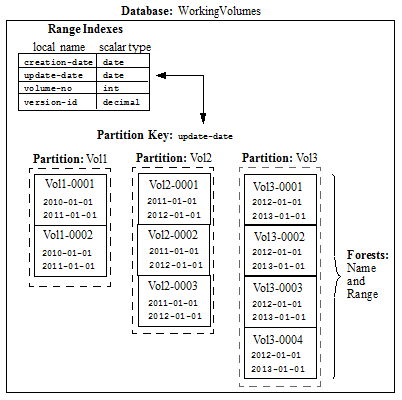
For example, you have a database, named WorkingVolumes, that contains nine forests that are grouped into three partitions. Among the range indexes in the WorkingVolumes database is an element range index for the update-date element with a type of date. The WorkingVolumes database has its partition key set on the update-date range index. Each forest in the WorkingVolumes database contains a lower bound and upper bound range value of type date that defines which documents are to be stored in which forests, as shown in the following table:
When Lower Bound Included is set to false on a database, the lower bound of the partition ranges are ignored. With this setting, documents with a partition key value that match the lower bound value are excluded from the partition and documents that match the upper bound value are included.
In this example, a document with an update-date element value of 2011-05-22 would be stored in one of the forests in the Vol2 partition. Should the update-date element value in the document get updated to 2012-01-02 or later, the document will be automatically moved to the Vol3 partition. How the documents are redistributed among the partitions is handled by the database rebalancer, as described in Range Assignment Policy.
Below is an illustration of the WorkingVolumes database, showing its range indexes, partition key, and its partitions and forests.
Query Partitions
A query partition consists of a group of database forests that share the same name prefix and the same query assignment policy described in Query Assignment Policy.
Query partitions query documents in an unfiltered manner. For details about unfiltered queries, see the Fast Pagination and Unfiltered Searches chapter in the Query Performance and Tuning Guide.
Each query partition is associated with a query that determines which documents are stored in that partition. When creating a query partition, you assign it a partition number. Unlike range partitions, queries set for partitions using the query assignment policy can have overlaps, so that a document may be matched by the query set for more than one partition. In the event of an overlap, the partition with lower number is selected over partitions with higher numbers.
As is the case with range assignment policy, you should define a default partition when configuring the query assignment policy. If you do not define a default partition, the database forests that are not associated with a query partition are used.
For example, you have three query partitions, a default partition and two partitions associated with the following types of queries:
Query Partition 1: (Default -- no query)
| Requirement | Query Type |
|---|---|
| the author includes twain | word |
| there is a paperback edition | value |
| the price of the paperback edition is less than 9.00 | range |
| Requirement | Query Type |
|---|---|
| the title includes Adventures | word |
| the characters include Huck | word |
| the class is fiction | word |
In this example, the document, Adventures of Huckleberry Finn matches both queries, but is stored in Query Partition 2 because it is the partition with the lower number. On the other hand, the document, Moby Dick doesn't match either query, so it is stored in Partition 1, the Default Query Partition.
Partition Migration
Both range and query partitions can be migrated between different types of storage. For example, you have the range partitions created in Range Partitions and, after a few months, the volumes of documents grow to 5 and there is no longer enough space on the fast SSD device to hold all of them. Instead, the oldest and least queried volumes (Vol1-Vol3) are migrated to a local disk drive, which represents a slower storage tier.
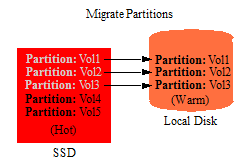
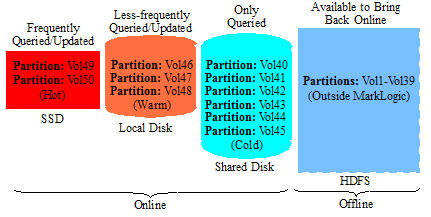
After years of data growth, the volumes of documents grow to 50. After migrating between storage tiers, the partitions are eventually distributed among the storage tiers, as shown below.
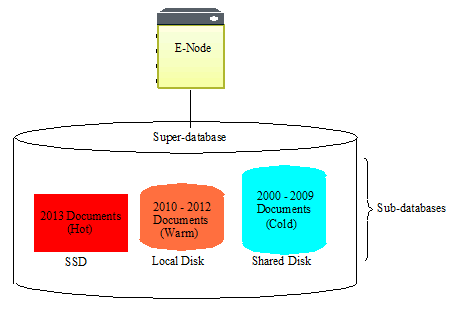
Multiple databases, even those that serve on different storage tiers, can be grouped into a super-database in order to allow a single query to be done across multiple tiers of data. Databases that belong to a super-database are referred to as sub-databases. A single sub-database can belong to multiple super-databases. For details on super-databases and sub-databases, see Super Databases and Clusters.
Configuring a Database with Range Partitions
If a database is to participate in a tiered storage scheme using range partitions, it must have the following set:
- Rebalancer enable set to
true - Rebalancer Assignment Policy set to
range - Locking set to
strict - A range index established for the partition key, as described in Range Indexes and Lexicons
- A partition key, as described in Defining a Range Partition Key
- Range partitions, as described in Creating Range Partitions
All of the forests in a database configured for tiered storage using range partitions must be part of a partition.
For details on how to configure the database rebalancer with the range assignment policy, see the sections Range Assignment Policy, Configuring the Rebalancer on a Database, and Configuring the Rebalancer on a Forest.
Defining a Range Partition Key
The partition key describes a common element or attribute in the stored documents. The value of this element or attribute in the document determines the partition in which the document is stored. A partition key is based on a range index, collection lexicon, or field of the same name set for the database. The range index, collection lexicon, or field used by the partition key must be created before the partition key is created.
For example, assume your documents all have an update-date element with a date value. The following procedure describes how to create a partition key for the update-date element:
- Create an element range index, named
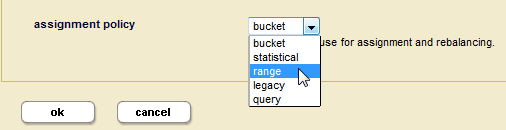
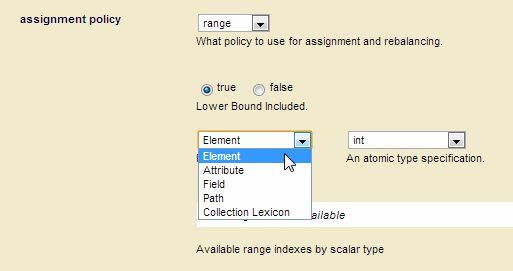
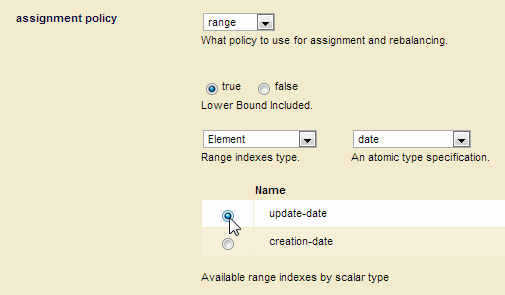
update-date, on the database of typedate. The details on how to create an element range index are described in Defining Element Range Indexes. - In the Admin UI, open the configuration page for the database, set the assignment policy to range. Additional settings appear under the assignment policy.
- Set the
Lower Bound Includedtotrueif you want to include documents with a partition key value that matches the lower bound value and exclude documents that match the upper bound value. Set theLower Bound Includedtofalse, if you want to exclude documents with a partition key value that matches the lower bound value and include documents that match the upper bound value. For example, if the range is2011-01-01(lower) to2012-01-01(upper) andLower Bound Includedis set tofalse, documents with anupdate-datevalue of2011-01-01will not be included in the partition, but documents with anupdate-datevalue of2011-01-02and2012-01-01will be included. - Note the type and scalar type of the range index, field, or collection lexicon you want to use as your partition key. In this example, we use an
Elementrange index with a scalar type ofdate. Set the index and scalar types in the drop down menus to list the matching range indexes, fields, or collection lexicons set for the database. - Select the range index, field, or collection lexicon you want to use as your partition key, which is
update-datein this example.
Creating Range Partitions
Range partitions are based on forest naming conventions. A forest's partition name prefix and the rest of the forest name are separated by a dash (-). For example, a forest named June-0001 belongs to the June partition.
It is a best practice to create a default partition (a partition without a range) before creating partitions with ranges. Doing this will allow you to load documents into the default partition before you have finished creating the other partitions. As new partitions with ranges are created, the documents will be automatically moved from the default partition to the partitions with matching ranges.
All of the forests in a database configured for tiered storage must be part of a partition.
There are two ways to create a range partition:
Creating a Range Partition with New Forests
You can use the POST /manage/v2/databases/{id|name}/partitions REST resource address to create a new range partition with empty forests. When creating a range partition, you specify the partition range and the number of forests to be created for the partition. You can also specify that the range partition be created for multiple hosts in a cluster, in which case the specified number of forests will be created on each host.
For example, the following creates a range partition, named 2011, in the Documents database on hosts, MyHost1 and MyHost2, with a range of 2011-01-01 - 2012-01-01 and four empty forests, named 2011-0001, 2011-0002, 2011-0003, and 2011-0004, on MyHost1 and four empty forests, named 2011-0005, 2011-0006, 2011-0007, and 2011-0008, on MyHost2:
$ cat create-partition.xml <partition xmlns="http://marklogic.com/manage"> <partition-name>2011</partition-name> <upper-bound>2012-01-01</upper-bound> <lower-bound>2011-01-01</lower-bound> <forests-per-host>4</forests-per-host> <hosts> <host>MyHost1</host> <host>MyHost2</host> </hosts> </partition> $ curl --anyauth --user user:password -X POST \ -d @create-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions
You can also include an options element to create replica forests for shared-disk or local-disk failover. For details, see Partitions with Forest-Level Failover.
Creating a Range Partition from Existing Forests
You can create a range partition from existing forests simply by renaming the forests so that they adhere to a range partition naming convention. For example, you have four forests, named 1-2011, 2-2011, 3-2011, and 4-2011. You can make these four forests into a range partition, named 2011, by renaming 1-2011 to 2011-1, and so on. You should also specify a common range for each renamed forest, or leave the range fields blank to identify the forests as belonging to a default range partition. Default range partitions store the documents that have partition key values that do not fit into any of the ranges set for the other range partitions.
For example, to rename the 1-2011 forest to 2011-1 and set the range to 2011-01-01 - 2012-01-01, do the following:
- Open the Forest Configuration page in the Admin UI, as described in Creating a Forest.
- In the forest name field, change the name from
1-2011to2011-1:
- In the range section of the Forest Configuration page, set the lower bound value to
2011-01-01and the upper bound value to2012-01-01:
- Click Ok.
You can also accomplish this operation using the XQuery, JavaScript, and REST APIs. For example, in XQuery using the admin:forest-rename and admin:forest-set-range-policy-range functions.
Configuring a Database with Query Partitions
If a database is to participate in a tiered storage scheme using query partitions, it must have the following set:
- Rebalancer enable set to
true - Rebalancer Assignment Policy set to
query - Locking set to
strict - Indexes established for the elements or properties to be queried
- Query partitions, as described in Creating Query Partitions
Unlike range partitions, it is not necessary for all of the forests in a database configured for tiered storage to be part of a query partition.
For details on the database rebalancer with the query assignment policy, see the sections Query Assignment Policy, Configuring the Rebalancer on a Database, and Configuring the Rebalancer on a Forest.
The following procedure describes how to configure a database to use the query assignment policy:
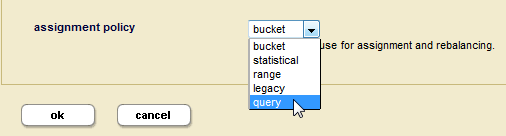
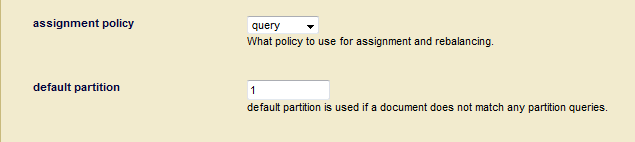
- In the Admin UI, open the configuration page for the database, set the assignment policy to query. The default partition setting then appears under the assignment policy.
- You can optionally enter the partition number for a default query partition in the Default Partition field. If you don't define a default query partition, then your database must have forests that are not part of a query partition. These forests will serve the same role as a default partition.
Creating Query Partitions
When creating a query partition, you specify the query partition name, number, and the number of forests to be created for the query partition. You can also specify that the query partition be created for multiple hosts in a cluster, in which case the specified number of forests will be created on each host.
Query partitions are based on forest naming conventions. A forest's partition name prefix and the rest of the forest name are separated by a dash (-). For example, a forest named tier1-0001 belongs to the tier1 partition. Unlike range partitions, it is not necessary for all of the forests in a database configured for tiered storage to be part of a query partition.
It is a best practice to create a default query partition (a partition without a query). Doing this will allow you to load documents into the default partition before you have finished creating the other partitions. As new partitions with queries are created, the documents will be automatically moved from the default partition to the query partitions with matching queries.
For details on how to configure the database rebalancer with the query assignment policy, see the sections Query Assignment Policy, Configuring the Rebalancer on a Database, and Configuring the Rebalancer on a Forest.
Query partitions do unfiltered searches, which means that the results are not filtered for validation. For details about unfiltered queries, see the Fast Pagination and Unfiltered Searches chapter in the Query Performance and Tuning Guide.
For example, the following creates query partition number 1, named tier1, with two forests in the Documents database on the host, MyHost1:
curl -X POST --anyauth --user admin:admin \ -H "Content-type: application/json" \ -d '{ "partition-name": "tier1", "partition-number": "1", "forests-per-host": 2, "host": [ "MyHost1" ], "option": [ "failover=none" ] }' \ http://MyHost1:8002/manage/v2/databases/Documents/partitions
Setting the Query Assignment Policy for the Query Partition
After creating a query partition, you can use the POST /manage/v2/databases/{id|name}/partition-queries REST resource address to assign to it a query assignment policy, as described in Query Assignment Policy.
Any indexes required for the query must be created before creating the query partition.
A query assignment policy in XML takes the form:
<partition-query-properties xmlns="http://marklogic.com/manage/partition-query/properties"> <partition-number>1</partition-number> <query> ....cts:query..... </query> </partition-query-properties>
A query assignment policy in JSON takes the form:
{ "partition-number": "1", "query": { ....cts.query..... } }
The search portion is a cts:query expression, as described in the Composing cts:query Expressions chapter in the Search Developer's Guide. There can be only one cts:query per partition.
The query requires the proper index to be configured in the database. The complexity of the query affects the performance of insert and rebalancing. Therefore slow query like wildcard matching is not recommended.
For example to direct all documents that have either the word Manager or Engineer in them to the tier1 query partition created above, you would do the following:
$ cat query1.xml
<partition-query-properties xmlns="http://marklogic.com/manage/partition-query/properties">
<partition-number>1</partition-number>
<query>
<cts:or-query xmlns:cts="http://marklogic.com/cts">
<cts:word-query>
<cts:text xml:lang="en">Manager</cts:text>
</cts:word-query>
<cts:word-query>
<cts:text xml:lang="en">Engineer</cts:text>
</cts:word-query>
</cts:or-query>
</query>
</partition-query-properties>
curl -X POST --anyauth -u admin:admin \
-H "Content-Type:application/xml" -d @query1.xml \
http://gordon-1:8002/manage/v2/databases/Schemas/partition-queriesThe following query assignment policy will match documents where "LastModified" is within past year:
<partition-query-properties> <partition-number>1</partition-number> <query> <element-range-query operator=">="> <element>LastModified</element> <value type="xs:yearMonthDuration">P1Y</value> </element-range-query> </query> </partition-query-properties>
The same query assignment policy in JSON:
{ "partition-number": 1, "query": { "element-range-query": { "operator": ">=", "element": "LastModified", "value": { "type": "xs:yearMonthDuration", "val": "P1Y" } } } }
For queries against a dateTime index, when $value is an xs:dayTimeDuration or xs:yearMonthDuration, the query is executed as an age query. $value is subtracted from fn:current-dateTime() to create a xs:dateTime used in the query. If there is more than one item in $value, they must all be the same type.
For example, given a dateTime index on element startDateTime, queries cts:element-range-query(xs:QName ("startDateTime"), ">", xs:dayTimeDuration("P1D")) and cts:element-range-query(xs:QName ("startDateTime"), ">", fn:current-dateTime() - xs:dayTimeDuration("P1D")) are the same; both match values within the last day.
Isolating a Query Partition
By default, when a search query is given to MarkLogic, all query partitions are searched, regardless of the query assignment policy set on the partition. To avoid this overhead, you can use the tieredstorage:partition-set-exclusion-enabled function to set safe-to-exclude on the query partition so that it will not be searched if the search query does not match the query assignment policy set for that partition.
When documents are distributed in query partitions based on time and date, you may want the option to always search a particular tier (typically the tier holding the most recent documents) because it may be the case that some of the documents in that tier are about to be migrated to a different tier but have not yet been moved. So if a search only matches the query set in a lower tier, the non-matching higher tier will also be searched to locate the matching documents that have not yet moved to the lower tier.
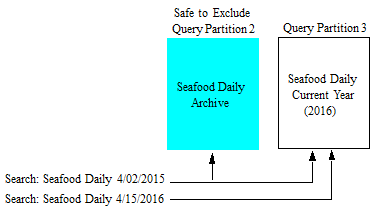
For example, you have two query partitions that hold the documents, Seafood Daily, as shown below. The query assignment policy for each compares the date of the document with the current date and sorts the documents so that one partition contains the issues from the current year and the other archives the issues from previous years. The query partition serving as the archive is set to safe-to-exclude and the query partition containing this year's issues is not set with this option.
The current year is 2016 and a search query is given that matches the query for Archive Partition will also result in a search on Current Year Partition. However, a search query that matches the Current Year Partition will exclude the Archive Partition.
Look Up Partitions Queries
To look up partitions queries:
- Use the management REST API via /manage/v2/databases/{id|name}/partition-queries
- Look in the associated schemas database for the partition queries with tieredstorage:partition-queries
Overview of the Tiered Storage REST API
Tiered storage is supported by the XQuery, JavaScript, and REST APIs. All of the operations you will want to integrate into your storage-management scripts to automate repetitive storage management operations are available through the REST API. However, some of the initial, one-time set-up operations, such as those related to setting the range policy and partition key on the database, are only supported by the Admin Interface and the XQuery API.
The Tiered Storage REST API supports both JSON and XML formats. The XML format is used for all of the examples in this chapter.
The topics in this section are:
- Asynchronous Operations
- Privileges
- /manage/v2/databases/{id|name}/partitions
- /manage/v2/databases/{id|name}/partitions/{name}
- /manage/v2/databases/{id|name}/partitions/{name}/properties
- /manage/v2/databases/{id|name}/partition-queries
- /manage/v2/databases/{id|name}/partition-queries/{partition-number}
- /manage/v2/databases/{id|name}/partition-queries/{partition-number}/properties
- /manage/v2/forests
- /manage/v2/forests/{id|name}
- /manage/v2/forests/{id|name}/properties
Asynchronous Operations
The partition resize and migrate, as well as the forest migrate and combine operations are processed asynchronously. This is because these operations may move a lot of data and take more time than generally considered reasonable for control to return to your script. Such asynchronous operations are tracked reusing ticket endpoints. This asynchronous process is initiated by GET /manage/v2/tickets/{tid}?view=process-status, as outlined in the following steps:
The generated ticket is returned in the form:
/manage/v2/tickets/{id}?view=process-status.You can view the status of the operation by visiting the URL. For example if the returned ticket is:
/manage/v2/tickets/8681809991198462214?view=process-status
and your host is MyHost, you can view the status of your operation using the following URL:
http://MyHost:8002/manage/v2/tickets/8681809991198462214?view=process-status
Historical ticket information can always be accessed by viewing the ticket default view.
Privileges
The following privileges are required for the resource addresses described in this section:
/manage/v2/databases/{id|name}/partitions
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets a list of partitions on the database | format? (json | xml) | tieredstorage:database-partitions |
| POST | Add a range or query partition to the database | format? (json | xml) |
/manage/v2/databases/{id|name}/partitions/{name}
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets a summary of the partition, including links to containing database, links to member forests, and link to configuration | format? (json | xml) | tieredstorage:partition-forests |
| DELETE | Deletes the partition | delete-data? (true|false) | tieredstorage:partition-delete |
| PUT | Invokes one of the following operations on the partition: | format? (json | xml) | tieredstorage:partition-resize |
/manage/v2/databases/{id|name}/partitions/{name}/properties
/manage/v2/databases/{id|name}/partition-queries
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets the query assignment policies for the query partitions set for the specified database. | format? (json | xml) | tieredstorage:partition-queries |
| POST | Sets the query assignment policy for a query partition. | tieredstorage:partition-set-query |
/manage/v2/databases/{id|name}/partition-queries/{partition-number}
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets the query assignment policy of the query partition with the specified number. | format? (json | xml) | tieredstorage:partition-get-query |
| DELETE | Deletes the query assignment policy for the query partition with the specified number. | tieredstorage:partition-delete-query |
/manage/v2/databases/{id|name}/partition-queries/{partition-number}/properties
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets the properties of the query for the query partition with the specified number. | format? (json | xml) | tieredstorage:partition-get-query |
| PUT | Update the query assignment policy in the query partition with the specified number. | format? (json | xml) | tieredstorage:partition-set-query |
/manage/v2/forests
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets a summary and list of forests. | format? (json | xml) view database-id group-id host-id fullrefs | |
| POST | Creates new forest(s) | format? (json | xml) | admin:forest-create |
| PUT | format? (json | xml) |
/manage/v2/forests/{id|name}
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets a summary of the forest. | format? (json | xml) view | admin:forest-get-* |
| POST | Initiates a state change on the forest. | state (clear | merge | restart | attach | detach | retire | employ) | |
| DELETE | Deletes the forest. | level (config-only | full) | admin:forest-delete |
/manage/v2/forests/{id|name}/properties
| Method | Description | Parameters | XQuery Equivalent |
|---|---|---|---|
| GET | Gets the properties on the forest | format? (json | xml) | admin:forest-get-rebalancer-enable admin:forest-get-updates-allowed admin:database-get-attached-forests |
| PUT | Initiates a properties change on the forest. The properties are: |
format? (json | xml) | admin:forest-set-rebalancer-enable admin:forest-set-updates-allowed |
Common Forest and Partition Operations
This section describes the following partition operations:
- Viewing Partitions
- Migrating Forests and Partitions
- Resizing Partitions
- Transferring Partitions between Databases
- Combining Forests
- Retiring Forests
- Taking Forests and Partitions Online and Offline
- Setting the Updates-allowed State on Partitions
- Deleting Partitions
Some of these operations operate asynchronously and immediately return a ticket number that you can use to check the status of the operation. For example, if the following is returned:
<link><kindref>process-status</kindref><uriref>/manage/v2/tickets/4678516920057381194?view=process-status</uriref></link>
You can check the status of the operation by entering a resource address like the following:
http://MyHost:8002/manage/v2/tickets/4678516920057381194?view=process-status
For details on asynchronous processes, see Asynchronous Operations.
Viewing Partitions
You can return all of the information on a partition.
For example, to return the details of the 2011 range partition on the Documents database, do the following:
curl -X GET --anyauth --user admin:admin --header \ "Content-Type:application/xml" \ http://MyHost:8002/manage/v2/databases/Documents/partitions/2011
Migrating Forests and Partitions
Forests and partitions can be migrated from one storage device to another. For example, a range partition on an SSD has aged to the point where is it less frequently queried and can be moved to a slower, less expensive, storage device to make room for a more frequently queried range partition.
For example, the 2011 range partition on the Documents database is mounted on a local disk on the host, MyHost. To migrate the 2011 range partition to the /warm-storage data directory mounted on a shared disk on the host, OurHost, do the following:
$ cat migrate-partition.xml <migrate xmlns="http://marklogic.com/manage"> <hosts> <host>OurHost</host> </hosts> <data-directory>/warm-storage</data-directory> <options> <option>failover=none</option> <option>local-to-shared</option> </options> </migrate> $ curl --anyauth --user user:password -X PUT \ -d @migrate-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions/2011
If you do not specify a data-directory, the default data directory is used.
The tiered storage migration operations allow you to migrate a forest or partition between different types of storage. The following table lists the four migration options. The migration option you select determines the sequence of steps taken by tiered storage during the migration operation.
You can use the PUT /manage/v2/forests resource address to migrate individual forests. For example, the forests 2011-0001 and 2011-0002, are mounted on a local disk on the host, MyHost. To migrate these forests to the /warm-storage data directory mounted on a shared disk on the host, OurHost, do the following:
$ cat migrate-forests.xml <forest-migrate xmlns="http://marklogic.com/manage"> <forests> <forest>2011-0001</forest> <forest>2011-0002</forest> </forests> <host>MyHost</host> <data-directory>/warm-storage</data-directory> <options> <option>local-to-shared</option> </options> </forest-migrate> $ curl --anyauth --user user:password -X PUT \ -d @migrate-forests.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/forests
If failover is configured on your forests, do a full backup of database after a forest or partition migrate operation to ensure that you can recover your data should something go wrong. You may also need to increase the timeout setting on the migrate operation, as it will take longer when failover is configured.
Resizing Partitions
You can increase or decrease the number of forests in a partition. Once the resize operation has completed, the documents in the partition forests will be rebalanced for even distribution.
For example, to resize the 2011 range partition up to five forests, do the following:
$ cat resize-partition.xml <resize xmlns="http://marklogic.com/manage"> <forests-per-host>5</forests-per-host> <hosts> <host>MyHost</host> </hosts> </resize> $ curl --anyauth --user user:password -X PUT \ -d @resize-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions/2011
In addition to resizing your partition, you can migrate your partition to another host by specifying a different host in the payload. Additionally, you can move the partition to a different storage tier (such as local-to-shared) by specifying one of the migration options described in Migrating Forests and Partitions.
If you resize partitions for databases configured for database replication, first resize the replica partitions before resizing the master partitions.
Transferring Partitions between Databases
You can move a partition from one database to another. For example, to transfer the 2011 range partition from the DB1 database to the DB2 database, do the following:
$ cat transfer-partition.xml <transfer xmlns="http://marklogic.com/manage"> <destination-database>DB2</destination-database> </transfer> $ curl --anyauth --user user:password -X PUT \ -d @transfer-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/DB1/partitions/2011
Combining Forests
You can use the PUT /manage/v2/forests resource address to combine multiple forests into a single forest. For example, to combine the forests, 2011-0001 and 2011-0002, into a single forest, named 2011, do the following:
$ cat combine-forests.xml <forest-combine xmlns="http://marklogic.com/manage"> <forests> <forest>2011-0001</forest> <forest>2011-0002</forest> </forests> <forest-name>2011</forest-name> <hosts> <host>MyHost</host> </hosts> </forest-combine> $ curl --anyauth --user user:password -X PUT \ -d @combine-forests.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/forests
You can both combine forests and migrate the combined forest to another host in a single operation by specifying a different host value. You can also move the forests to a different storage tier (such as local-to-shared) by specifying one of the migration options described in Migrating Forests and Partitions.
If you want to combine forests that are attached to databases configured for database replication, first combine the foreign replica forests with the snapshot option before combining the master forests.
If failover is configured on your forests, do a full backup of database after a forest combine operation to ensure that you can recover your data should something go wrong. You may also need to increase the timeout setting on the combine operation, as it will take longer when failover is configured.
Retiring Forests
You can retire a forest from a database in order to move all of its documents to the other forests and rebalance them among those forests, as described in How Data is Moved when a Forest is Retired from the Database.
For example, to retire the forest, 2011, from the Documents database, do the following:
curl -i -X POST --digest --user user:password -H \ "Content-Type:application/x-www-form-urlencoded" \ --data "state=retire&database=Documents" \ http://MyHost:8002/manage/v2/forests/2011
Taking Forests and Partitions Online and Offline
You can take a forest or partition offline and store it in an archive, so that it is available to later bring back online, if necessary. The benefit of taking data offline is to spare the RAM, CPU, and network resources for the online data.
An offline forest or partition is excluded from query, update, backup, restore and replicate operations performed by the database to which it is attached. An offline forest or partition can be attached, detached, or deleted. Operations, such as rename, forest-level backup and restore, migrate, and combine are not supported on an offline forest or partition. If a forest is configured with failover, the replica forest inherits the online/offline setting of its master forest, so disabling an offline master forest does not trigger a failover.
For example, to take the 2011 range partition in the DB2 database offline, do the following:
$ cat partition-offline.xml <partition-properties xmlns="http://marklogic.com/manage"> <availability>offline</availability> </partition-properties>
$ curl --anyauth --user user:password -X PUT \ -d @partition-offline.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/DB2/partitions/2011/properties
Setting the Updates-allowed State on Partitions
You can change the updates-allowed state of a partition to make its forests. The possible states are shown in the table below.
For example, to set the updates-allowed state in the 2011 range partition in the Documents database to read-only, do the following:
$ cat read-only-partition.xml <partition-properties xmlns="http://marklogic.com/manage"> <updates-allowed>read-only</updates-allowed> </partition-properties> $ curl --anyauth --user user:password -X PUT \ -d @read-only-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions/2011/properties
Deleting Partitions
You can delete a partition, along with all its forests. For example, to delete the 2011 range partition from the Documents database, do the following:
$ curl --anyauth --user user:password -X DELETE \ -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions/2011
Partitions with Forest-Level Failover
The partition create, migrate and resize operations allow you to specify an options element to create replica forests for shared-disk or local-disk failover, as described in the Configuring Local-Disk Failover for a Forest and Configuring Shared-Disk Failover for a Forest chapters in the Scalability, Availability, and Failover Guide.
To create replica forests for forest-level failover, you must create the partition on at least two hosts. For each master forest created on one host a replica forest will be created on another host. For example, to create a single replica forest for each forest in the 2011 range partition and configure the forests for local-disk failover between MyHost1, MyHost2, and MyHost3, do the following.
$ cat create-partition.xml <partition xmlns="http://marklogic.com/manage"> <partition-name>2011</partition-name> <upper-bound>2012-01-01</upper-bound> <lower-bound>2011-01-01</lower-bound> <forests-per-host>4</forests-per-host> <data-directory>/forests</data-directory> <hosts> <host>MyHost1</host> <host>MyHost2</host> <host>MyHost3</host> </hosts> <data-directory></data-directory> <large-data-directory></large-data-directory> <fast-data-directory></fast-data-directory> <options> <option>replicas=1</option> <option>failover=local</option> </options> </partition> $ curl --anyauth --user user:password -X POST \ -d @create-partition.xml -H 'Content-type: application/xml' \ http://MyHost:8002/manage/v2/databases/Documents/partitions
Keep in mind the following when configuring partitions or forests with forest-level failover:
- If failover is configured on your forests, do a full backup of database after doing a partition or forest migrate or a forest combine to ensure that you can recover your data should something go wrong. You may also need to increase the timeout setting on the migrate or combine operation, as these operations will take longer when failover is configured.
- It is not recommended to configure local-disk failover for forests attached to a database with journaling set to
off. - You cannot configure a partition with shared-disk or local-disk failover on Amazon Simple Storage Service (S3), unless its fast data directory, as designated by
<fast-data-directory>, is not on S3. - If your deployment of MarkLogic is on Amazon Elastic Compute Cloud (EC2) or is distributed across multiple data centers, be sure to specify an equal number of hosts on different zones when creating, migrating, or resizing your partition with forest-level failover. For example, two hosts on
us-east-1a, two hosts onus-east-1b, and two hosts onus-east-1c. In this example, tiered storage will ensure that master and their replica forests are created on hosts in different zones. This ensures that the partition will remain accessible should a forest, host, or entire zone go down.