
Concepts Guide — Chapter 5
Searching in MarkLogic Server
MarkLogic includes rich full-text search features. All of the search features are implemented as extension functions available in XQuery, and most of them are also available through the REST and Java interfaces. This section provides a brief overview some of the main search features in MarkLogic and includes the following parts:
- High Performance Full Text Search
- Search APIs
- Support for Multiple Query Styles
- Full XPath Search Support in XQuery
- Lexicon and Range Index-Based APIs
- Alerting API and Built-Ins
- Semantic Searches
- Template Driven Extraction (TDE)
- Where to Find Additional Search Information
High Performance Full Text Search
MarkLogic is designed to scale to extremely large databases (100s of terabytes or more). All search functionality operates directly against the database, no matter what the database size. As part of loading a document, full-text indexes are created making arbitrary searches fast. Searches automatically use the indexes. Features such as the xdmp:estimate XQuery function and the unfiltered search option allow you to return results directly out of the MarkLogic indexes.
Search APIs
MarkLogic provides search features through a set of layered APIs. The core text search foundations in MarkLogic are the XQuery cts:* and JavaScript cts.* APIs, which are built-in functions that perform full-text search. The XQuery search:*, JavaScript jsearch.*, and REST APIs above this foundation provide a higher level of abstraction that enable rapid development of search applications. For example, the XQuery search:* API is built using cts:* features such as cts:search, cts:word-query, and cts:element-value-query. On top of the REST API are the Java and Node.js Client APIs that enable users familiar with those interfaces access to the MarkLogic search features.
The following diagram illustrates the layering of the Java, Node.js, REST, XQuery (search and cts), and JavaScript APIs.

The XQuery search:*, JavaScript jsearch.*, REST, Java or Node.js APIs are sufficient for most applications. Use the cts APIs for advanced application features, such as using reverse queries to create alerting applications and creating content classifiers. The higher-level APIs offer benefits such as the following:
- Abstraction of queries from the constraints and indexes that support them.
- Built in support for search result snippeting, highlighting, and performance analysis.
- An extensible simple string query grammar.
- Easy-to-use syntax for query composition.
- Built in best practices that optimize performance.
You can use more than one of these APIs in an application. For example, a Java application can include an XQuery extension to perform custom search result transformations on the server. Similarly, an XQuery application can call both search:* and cts:* functions.
Support for Multiple Query Styles
Each of the APIs described in Search APIs supports one or more input query styles for searching content and metadata, from simple string queries (cat OR dog) to XML or JSON representations of complex queries. Search results are returned in either raw or report form. The supported query styles and result format vary by API.
For example, the primary search function for the cts:* API, cts:search, accepts input in the form of a cts:query, which is a composable query style that allows you to perform fine-grained searches. The cts:search function returns raw results as a sequence of matching nodes. The search:*, jsearch.*, REST, Java, and Node.js APIs accept more abstract query styles such as string and structured queries, and return results in report form, such as a search:response XML element. This customizable report can include details such as snippets with highlighting of matching terms and query metrics. The REST, Java, and Node.js APIs can also return the results report as a JSON map with keys that closely correspond to a search:response element.
The following diagram summarizes the query styles and results formats each API provides for searching content and metadata:
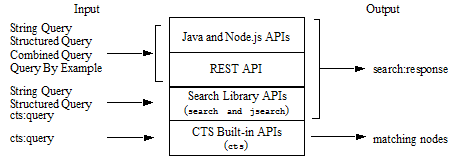
The following table provides a brief description of each query style. The level of complexity of query construction increases as you read down the table.
| Query Style | Supporting APIs | Description |
|---|---|---|
| String Query | Construct queries as text strings using a simple grammar of terms, phrases, and operators such as as AND, OR, and NEAR. String queries are easily composable by end users typing into a search text box. For details, see Searching Using String Queries in the Search Developer's Guide. | |
| Query By Example | Construct queries in XML or JSON using syntax that resembles your document structure. Conceptually, Query By Example enables developers to quickly search for documents that look like this. For details, see Searching Using Query By Example in the Search Developer's Guide. | |
| Structured Query | Construct queries in JSON or XML using an Abstract Syntax Tree (AST) representation, while still taking advantage of Search API based abstractions and options. Useful for tweaking or adding to a query originally expressed as a string query. For details, see Searching Using Structured Queries in the Search Developer's Guide. | |
| Combined Query | Search using XML or JSON structures that bundle a string and/or structured query with query options. This enables searching without pre-defining query options as is otherwise required by the REST and Java APIs. For details, see Specifying Dynamic Query Options with Combined Query in REST Application Developer's Guide or Apply Dynamic Query Options to Document Searches in Java Application Developer's Guide | |
Construct queries in XML from low level cts:query elements such as cts:and-query and cts:not-query. This representation is tree structured like Structured Query, but much more complicated to work with. For details, see Composing cts:query Expressions in the Search Developer's Guide. |
Full XPath Search Support in XQuery
MarkLogic Server implements the XQuery language, which includes XPath 2.0. XPath expressions are searches which can search across the entire database. For example, consider the following XPath expression:
/my-node/my-child[fn:contains(., "hello")]
This expression searches across the entire database returning my-child nodes that match the expression. XPath expressions take full advantage of the indexes in the database and are designed to be fast. XPath can search both XML and JSON documents.
Lexicon and Range Index-Based APIs
MarkLogic Server has range indexes which index XML and JSON structures such as elements, element attributes, XPath expressions, and JSON keys. There are also range indexes over geospatial values. Each of these range indexes has lexicon APIs associated with them. The lexicon APIs allow you to return values directly from the indexes. Lexicons are very useful in constructing facets and in finding fast counts of element or attribute values. The Search, Java, and REST APIs makes extensive use of the lexicon features. For details about lexicons, see Browsing With Lexicons in the Search Developer's Guide.
Alerting API and Built-Ins
You can create applications that notify users when new content is available that matches a predefined query. There is an API to help build these applications as well as a built-in cts:query constructor (cts:reverse-query) and indexing support to build large and scalable alerting applications. For details on alerting applications, see Creating Alerting Applications in the Search Developer's Guide.
Semantic Searches
MarkLogic allows you use SPARQL (SPARQL Protocol and RDF Query Language) to do semantic searches on the Triple Index, described in Triple Index. SPARQL is a query language specification for querying over RDF (Resource Description Framework) triples.
It is a formal W3C recommendation from the RDF Data Access Working Group, described in the SPARQL Query Language for RDF recommendation:
http://www.w3.org/TR/rdf-sparql-query/
MarkLogic supports SPARQL 1.1. SPARQL queries are executed natively in MarkLogic to query either in-memory triples or triples stored in a database. When querying triples stored in a database, SPARQL queries execute entirely against the triple index.
For details on MarkLogic support of SPARQL and RDF triples, see Semantic Queries in the Semantics Developer's Guide.
Template Driven Extraction (TDE)
Template Driven Extraction (TDE) enables you to define a relational lens over your document data, so you can query parts of your data using SQL or the Optic API. Templates let you specify which parts of documents make up rows in a view. You can also use templates to define a semantic lens, specifying which values from a document make up triples in the triple index.
TDE enables you to generate rows and triples from ingested documents based on predefined templates that describe the following:
- The input data to match
- The data transformations that apply to the matched data
- The final data projections that are translated into indexed data.
TDE enables you to access the data in your documents in several ways, without changing the documents themselves. A relational lens is useful when you want to let SQL-savvy users access your data and when users want to create reports and visualizations using tools that communicate using SQL. It is also useful when you want to join entities and perform aggregates across documents. A semantic lens is useful when your documents contain some data that is naturally represented and queried as triples, using SPARQL.
TDE is applied during indexing at ingestion time and serves the following purposes:
- SQL/Relation indexing. TDE allows the user to map parts of an XML or JSON document into SQL rows. With a TDE template instance, users can create different rows and describe how each column in a row is constructed using the extracted data from a document. For details, see Creating Template Views in the SQL Data Modeling Guide.
- Custom Embedded Triple Extraction. TDE enables users to ingest triples that do not follow the sem:triple schema. A user can define many triple projections in a single template, where each projection specifies the different parts of a document that are mapped to subjects, predicates or objects. For details, see Using a Template to Identify Triples in a Document in the Semantics Developer's Guide.
- Entity Services Data Models. For details, see Creating and Managing Models in the Entity Services Developer's Guide.
TDE data is also used by the Optic API, as described in Optic API.
For details on TDE, see Template Driven Extraction (TDE) in the Application Developer's Guide.
Where to Find Additional Search Information
The MarkLogic XQuery and XSLT Function Reference and Java Client API Documentation describe the XQuery and JavaScript function signatures and descriptions, as well as many code examples. The Search Developer's Guide contains descriptions and technical details about the search features in MarkLogic Server, including:
- Search API: Understanding and Using
- Composing cts:query Expressions
- Relevance Scores: Understanding and Customizing
- Browsing With Lexicons
- Using Range Queries in cts:query Expressions
- Highlighting Search Term Matches
- Geospatial Search Applications
- Entity Extraction and Enrichment
- Creating Alerting Applications
- Using fn:count vs. xdmp:estimate
- Understanding and Using Stemmed Searches
- Understanding and Using Wildcard Searches
- Collections
- Using the Thesaurus Functions
- Using the Spelling Correction Functions
- Language Support in MarkLogic Server
- Encodings and Collations
For information on search using the REST API, see the Using and Configuring Query Features chapter in the REST Application Developer's Guide.
For information on search using the Java API, see the Searching chapter in the Java Application Developer's Guide.
For information on search using Node.js, see the Querying Documents and Metadata chapter in the Node.js Application Developer's Guide
For other information about developing applications in MarkLogic Server, see the Application Developer's Guide.