
Administrator's Guide — Chapter 17
Database Rebalancing
As your needs for data in a database expand and contract, the more evenly the content is distributed among the database forests, the better its performance and the more efficient its use of storage resources. This chapter describes the database rebalancing mechanism that enables MarkLogic Server to evenly distribute content among the database forests.
This chapter includes the following topics:
- Overview of the Database Rebalancer
- Rebalancer Trigger Events
- Rebalancer Document Assignment Policies
- How the Rebalancer Moves Documents
- Configuring the Rebalancer on a Database
- Configuring the Rebalancer on a Forest
- Retiring a Forest from the Database
- Checking the Rebalancer Status
- How the Rebalancer Interacts with other Database and Forest Settings
- Rebalancer Settings after Upgrading from an Earlier Release
Overview of the Database Rebalancer
A database rebalancer consists of two parts: an assignment policy for data insert and rebalancing and a rebalancer for data movement. The rebalancer can be configured with one of several assignment policies, which define what is considered balanced for a database. You choose the appropriate policy for a database. The rebalancer runs on each forest and consults the database's assignment policy to determine which documents do not belong to this forest and then pushes them to the correct forests.
Document loads and inserts into the database follow the same document assignment policy used by the rebalancer, regardless of whether the rebalancer is enabled or disabled.
When you add a new forest to a database configured with a rebalancer, the database will automatically redistribute the documents among the new forest and existing forests. You can also retire a forest in a database to remove all of the documents from that forest and redistribute them among all of the remaining forests in the database.
In addition to enabling and disabling on the database level, the rebalancer can also be enabled or disabled at the forest level. For the rebalancer to run on a forest, it must be enabled on both the database and the forest.
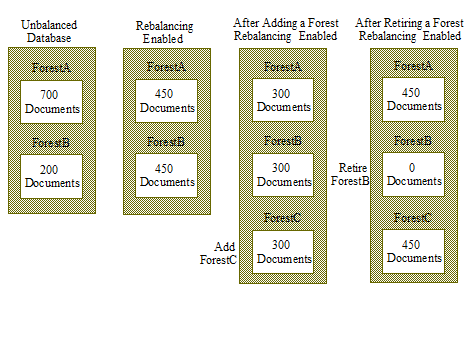
The following illustration shows how 900 documents might be distributed between database forests before rebalancing, after rebalancing, after adding a new forest to the database, and after retiring a forest from the database.
Rebalancer Trigger Events
In addition to the rebalancer periodically rebalancing the database, the following events trigger the rebalancer process:
Rebalancer Document Assignment Policies
A database is given an assignment policy that defines the logic used by the forests when reassigning documents to the other forests participating in the rebalancer process. Though they run in separate threads, both the rebalancer process and the document load/insert process follow the same assignment policy set on the database for the rebalancer.
The five commonly used assignment policies are as follows:
- Bucket Assignment Policy
- Segment Assignment Policy
- Statistical Assignment Policy
- Range Assignment Policy
- Query Assignment Policy
- Legacy Assignment Policy
Bucket Assignment Policy
The bucket policy uses the URI of a document to decide which forest the document should be assigned to. The URI is first "mapped" to a bucket then the bucket is "mapped" to a forest. The mapping from a bucket to a forest is kept in memory for fast access. The number of buckets is always 16K, regardless of the number of forests in the database.
How document URIs are mapped to buckets and buckets are mapped to forests are non-configurable implementation details.
Though there are 16K buckets used by the bucket assignment policy, for the purposes of the example illustrated below, assume there are eight buckets that distribute the 1200 documents across three forests: ForestA, ForestB, and ForestC and that the document URIs allow for even distribution of them among the buckets. ForestD is then added to the database and the rebalancer moves 1/3 of the documents from Forests A and B to ForestD by reassigning Bucket 3 from ForestA to ForestD and Bucket 6 from ForestB to ForestD.
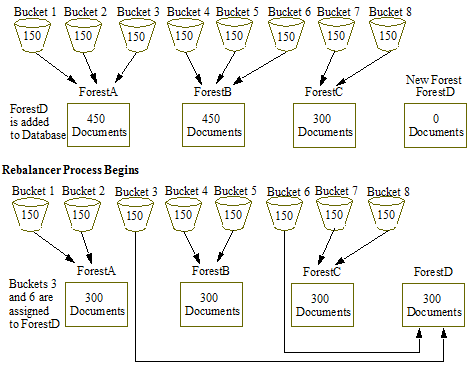
The bucket assignment policy is, in most situations, the most efficient document assignment policy because it is deterministic and it moves the least amount of data of the deterministic assignment policies.
Segment Assignment Policy
Unlike the legacy policy, described in Legacy Assignment Policy that ensures that documents are evenly distributed across forests in the database, the segment policy ensures that fragments are evenly distributed across the forests. The segment policy assigns fragments to forests based on their document URIs to allow for fast locking.
The segment policy is the most efficient rebalancing policy when you are adding or reducing the number of forests by 30% or more. For example, if the number of forests doubles, the half of the fragments in the existing forests are assigned to the newly added forests. Conversely, if the number of forests is reduced by half, all of the fragments in a retired forests are assigned to the remaining forests.
Statistical Assignment Policy
The statistical policy does not map a URI to a forest. Instead, each forest keeps track of how many documents it has and broadcasts that information to the other forests through heartbeats. The rebalancer then moves documents from the forests that have the most documents to the forests that have the least number of documents. When a new forest is added, the statistical policy moves the least number of documents to get to a balanced state. All forests don't have to have the exact same amount of documents for a database to be considered balanced.
For example, as shown in the figure below, a new forest, ForestD, is added to the database that already has three forests: ForestA, ForestB, and ForestC, each contains 400 documents. Each of the existing forests move 100 documents to the new forest, ForestD.
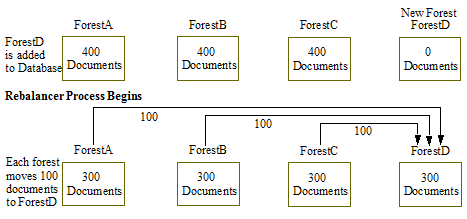
The number of documents in above example is used for the purposes of illustrating the behavior of the rebalancer when the statistical policy is set. In practice, it is inefficient to move such a small number of documents between forests. Typically, you will not see any significant rebalancing of documents between forests until the number of documents in the database exceeds 100,000.
If your database is balanced (the document count on each forest is roughly the same), setting the assignment policy to statistical will not trigger major data movement and any new inserts from then on will be automatically balanced across the forests.
Range Assignment Policy
The range policy is designed for use with Tiered Storage Range Partitions described in Range Partitions. It uses a range index value to decide which forest a document should be assigned to. When setting the range policy, you specify a range index for use as the partition key and configure each forest attached to the database with a range that defines a lower and upper end.
Avoid using the range policy to manage documents that might have more than one value for a range index, as the behavior in such a circumstance is undefined.
There may be multiple forests that cover the same range, but two forests cannot have partially overlapped ranges. For example, it is valid for both ForestA and ForestB to cover (1 to 10) but not valid for ForestA to cover (1 to 6) while ForestB covers (4 to 10). It is also not valid for ForestA to cover (1 to 10) while ForestB covers (4 to 9). Among those forests that cover the same range, documents are assigned to the forests based on their document count, following a similar mapping process as the statistical policy described in Statistical Assignment Policy.
In order to accommodate range gaps and documents that do not contain an element used as the partition key, you should always configure a default forest, as described below.
If a document has been processed by the Content Processing Framework (CPF), the property documents associated with the document may have a partition key value that is different from that in the document. When using the range policy, you may want to use the xdmp:document-add-properties or xdmp:document-set-properties function to put the same partition key value as specified in the document into the property documents to ensure that they are moved to the same forest as the original document. For example, the partition key is creation-date and the example.xml document has a creation-date of 2010-01-02, but its associated property documents contain no creation-date element. You could then use the xdmp:document-add-properties function as follows to add a matching creation-date element to the example.xml property documents.
xdmp:document-add-properties( "example.xml", (<creation-date>2010-01-02</creation-date>))
A forest with no range value behaves as the default forest, which means that documents that do not fit into any of the ranges set on the other forests are moved to the default forest. You cannot retire a forest unless there is another forest for the documents to move to, which means that there must either be another forest with the same range as the retired forest or that there is a default forest (no range set) attached to the database. If a database contains no default forest, an attempt to retire a forest containing documents with partition key values that do not match the ranges in the other forests will not be successful.
You should always define a default forest when configuring the range assignment policy.
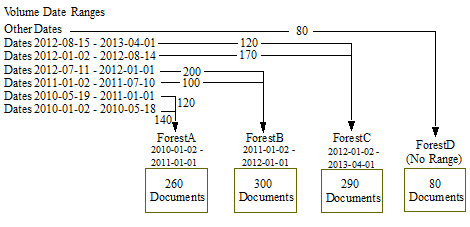
For example, as shown in the figure below, you have documents that are organized into 6 volumes and each document contains a <creation-date> element that indicates when that document was created. You can create an element range index, named creation-date, of type date and identify creation-date as the partition key for the range policy. If you have four forests, you can set the lower bound of the range on the ForestA to 2010-01-02 and the upper bound to 2011-01-01; on ForestB, the lower bound to 2011-01-02 and the upper bound to 2012-01-01, and on ForestC, the lower bound to 2012-01-02 and the upper bound to 2013-04-01. The fourth forest, ForestD, is designated as the default forest by not specifying a range. Any documents that have dates that fall outside of the date ranges set for the other forests and directed to the default forest.
Query Assignment Policy
The query assignment policy, like the range assignment policy, is designed for use with Tiered Storage Query Partitions described in Query Partitions. The query assignment policy works in a similar manner as the range assignment policy. However, rather than using lower and upper bound values to determine which documents are in a partition, the query assignment policy uses a query to determine which documents are in a partition. Users have the flexibility to use multiple keys and use different conditions for different types of documents.
With range assignment policy, the boundaries are fixed. However, you might want to rebalance the documents based on the difference between the entry time and the current time. When a range query compares a dateTime with duration, it becomes an age query.
For example, the following query will match documents where "LastModified" is within past year:
cts:element-range-query( xs:QName("LastModified"), ">=", xs:yearMonthDuration("P1Y"))
When creating a query partition, you assign it a partition number. Unlike range partitions, queries set for partitions using the query assignment policy can have overlaps, but, in the event of an overlap, the partition with lower number is selected before partitions with higher numbers.
As is the case with range assignment policy, you should always define a default partition when configuring the query assignment policy.
The following is an example of query assignment policy setup. MD and AD are elements in the documents.
There is only one cts:query per partition.
When the query assignment policy is used, the following rules are used for document insert:
- The partition number is used for priority. If there is more than one query that match the document, the partition with the lower partition number is used.
- If none of the queries matches the document, the default partition is used.
- If there is no default partition, the forests without a partition number are used.
- Otherwise, it is an error.
Among the forests in a partition, the documents are assigned to the forests using the statistical assignment policy.
The query requires the proper indexes to be configured in the database. The complexity of the query affects the performance of insert and rebalancing. Therefore slow queries such as those with wildcard matching are not recommended.
See Setting the Query Assignment Policy for the Query Partition for details on how to set the query assignment policy.
Legacy Assignment Policy
After upgrading to MarkLogic 7.0 or a later version, existing databases will be configured with the rebalancer disabled and the legacy assignment policy. This is to preserve the expected behavior when new documents are loaded into the database.
Under most circumstances you would not use the legacy policy when the database rebalancer is enabled. The segment policy, described in Segment Assignment Policy, is generally preferred over the legacy policy.
The legacy policy uses the URI of a document to decide which forest the document should be assigned to. The mapping from a URI to a forest uses the same algorithm as the one used on older releases of MarkLogic Server.
For example, as shown in the figure below, a new forest, ForestD, is added to the database that already has three forests: ForestA, ForestB, and ForestC, each contains 400 documents because the document URIs allow for even distribution of them among the forests. The data is rebalanced as follows:
- ForestA moves 100 documents to ForestB
- ForestB moves 200 documents to ForestC
- ForestC moves 300 documents to ForestD
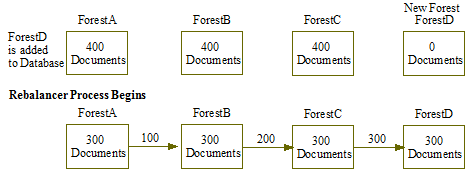
The legacy policy is the least efficient rebalancer policy, as it requires the greatest amount of document movement to rebalance the documents among the forests. For this reason, you should only use the legacy policy on legacy databases with the rebalancer disabled.
Summary of Assignment Policies
The following table summarizes the characteristics of the rebalancer assignment policies:
How the Rebalancer Moves Documents
There are many similarities between the rebalancing process and the reindexing process. Rebalancing is configured at the database level and individual rebalancing processes run separately on each forest.
The main task of the rebalancer is to consult the assignment policy associated with the database to get a list of documents (URIs) that do not belong to this forest and then push them out to the right forests. The deletion of documents from the rebalancing forest and the insertion of them into the right forests happens in the same transaction. All fragments with the same URI are handled by the same transaction. Each transaction moves a batch of documents.
When rebalancing is enabled, you can configure the rebalancer throttle for a database. The rebalancer throttle works the same as the reindexer throttle in that it establishes the priority of system resources devoted to rebalancing. When the rebalancer throttle is set to 5 (the default), the rebalancer works aggressively, starting the next batch of rebalancing soon after finishing the previous batch. When set to 4, it waits longer between batches, when set to 3 it waits even longer, and so on until when it is set to 1, it waits the longest. The higher numbers give rebalancing a higher priority and uses the most system resources.
The following sections describe how documents are moved when forests are reconfigured for the database:
- How Data is Moved when a Forest is Attached to the Database
- How Data is Moved when a Forest is Retired from the Database
How Data is Moved when a Forest is Attached to the Database
Attaching an empty forest to a database is the same as adding a new forest. If the forest contains existing documents, they will participate in the rebalancing with the documents that are in the other forests that are already attached to the database.
How Data is Moved when a Forest is Retired from the Database
If a rebalancer-enabled forest is retired, the rebalancer empties the forest by balancing out all of the documents to the other forests attached to the database. The rebalancers on other forests re-calculate document routing as if the retired forest no longer exists. For new inserts, the retired forest is excluded from consideration by the document assignment policy.
Retire is a separate operation from detach or delete. A read-only forest cannot be retired. To preserve all of the documents in the database, you must first retire a forest to rebalance the documents on the remaining forests in the database before detaching that forest.
Configuring the Rebalancer on a Database
You can configure and monitor the rebalancing process through the Admin Interface or the Admin APIs.
To configure the rebalancer on a database, complete the following procedure:
- Click the Databases icon on the left tree menu.
- Decide which database for which you want to configure the rebalancer.
- Click the database name, either on the tree menu or the summary page.
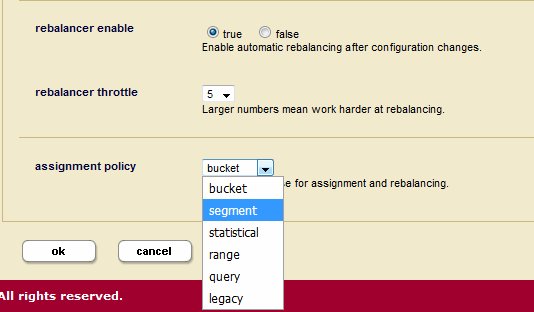
- Scroll down the Database Configuration page to the assignment policy and set the Rebalancer Enable to
true. - From the assignment policy pull-down menu, select the assignment policy. For details on the available rebalancer assignment policies, see Rebalancer Document Assignment Policies.
- From the rebalancer throttle pull-down menu, select the rebalancer throttle setting. For details on the rebalancer throttle, see How the Rebalancer Moves Documents.
- Click OK.
Configuring the Rebalancer on a Forest
In addition to enabling and disabling on the database level, as described in Configuring the Rebalancer on a Database, the rebalancer can also be enabled or disabled on each individual forest. For the rebalancer to run on a forest, it must be enabled on both the database and the forest.
The rebalancer is enabled on each new forest by default.
To configure the rebalancer on a forest, complete the following procedure:
- Click the Databases icon on the left-tree menu.
- Select the database for which you want to configure the forest.
- Click the database name, either on the tree menu or the summary page.
- In the left-tree menu under the database name, select Forests.
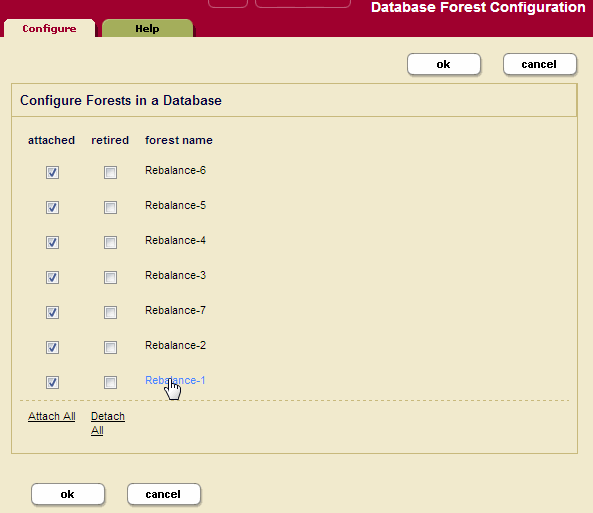
- In the Database Forest Configuration page, select the forest for which you want to enable or disable the rebalancer.
- In the Forest Configuration page, scroll down to Rebalancer Enable and set to
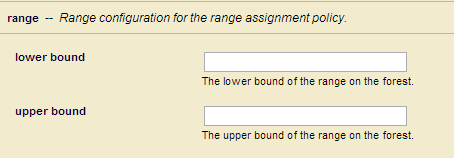
trueto enable the rebalancer orfalsedisable the rebalancer. - If you have configured the forest's database with the range assignment policy, you can set the range for this forest in the lower bound and upper bound fields. Do not set a range if this forest is to serve as a default forest.
- Click OK.

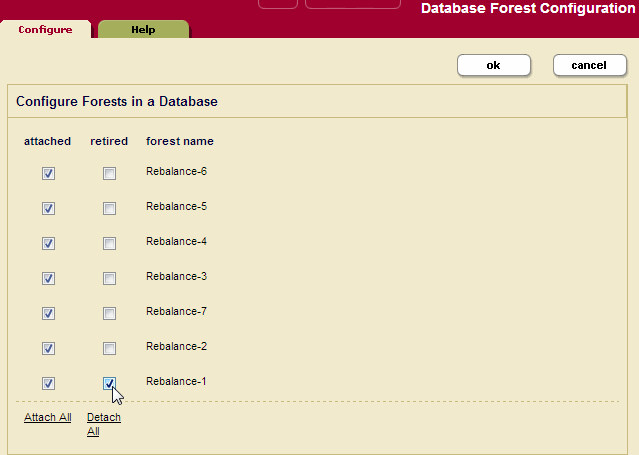
Retiring a Forest from the Database
You can retire a forest from a database in order to move all of its documents to the other forests and rebalance them among those forests, as described in How Data is Moved when a Forest is Retired from the Database. If you want to preserve forest documents in a database, you must first retire the forest before detaching it from the database.
To retire a forest from a database, complete the following procedure:
- Click the Databases icon on the left-tree menu.
- Decide which database for which you want to retire a forest.
- Click the database name, either on the tree menu or the summary page.
- In the left-tree menu under the database name, select Forests.
- In the Database Forest Configuration page, check the Retired box for the forest you want to retire from the database. If you want to preserve forest documents in a database, leave the forest Attached box checked.
- Click OK. The documents in the retired forest will be evenly redistributed to the other forests in the database.
- After the rebalancer has emptied the retired forest, if the forest is no longer needed, you can detach the forest from the database, as described in Attaching and/or Detaching Forests to/from a Database.
Checking the Rebalancer Status
When the rebalancer is enabled on the database, you can check the state of the rebalancer, along with an estimated completion time, on the Database Status page.
For example, if the database is rebalancing documents, you will see status similar to the following:

When the rebalancer is disabled on the database, you can click on the Show Rebalance button at the top of the Database Status page to view the number of fragments that are pending rebalancing.

This will display a table like the following toward the middle of the Database Status page:

How the Rebalancer Interacts with other Database and Forest Settings
This section describes how the database rebalancer interacts with other database and forest settings. The topics are:
- Database Replication
- Restoring a Database from a Backup
- Tiered Storage
- Fast Locking
- Delete-only and Read-only Forests
Database Replication
If you have configured a database for database replication and that database is enabled for rebalancing with the segment, legacy or bucket policy, the order of the forests in the database configuration is important, and it should be the same on the master and replica databases. If the order of the master and replica forests is different, you will see a message similar to the following in the log:
Warning: forest order mismatch: local forest XXX is at position A while foreign master forest YYY (cluster=ZZZ) is at position B.
Should you see this error, you can execute the admin:database-reorder-forests function on the replica database to reorder the forests to match the same order as on the master. If you do not reorder the forests so the master and replica match, then rebalancing will occur if replication is deconfigured.
Restoring a Database from a Backup
If you have a database enabled for database rebalancing with the segment, legacy or bucket policy, the order of forests on the database may differ from the order of forests when the database was backed up. You can execute xdmp:database-restore-validate function to return a backup-plan containing a database element that shows the order of the forests when the backup was done. If the order of the forests do not match, then you should execute the admin:database-reorder-forests function to reorder the forests on your database before restoring it from the backup.
When using the segment, legacy or bucket policy, if the order of forests on the database being restored differs from the order of forests when the database was backed up, the restore operation may trigger major data movement between the forests on the restored database.
Tiered Storage
The range assignment policy described in Range Assignment Policy is designed to support tiered storage. For details on tiered storage, see Tiered Storage.
Fast Locking
Fast locking works with the segment, legacy, and bucket policy. However, a database cannot use the statistical policy or the range policy with fast locking. With the statistical policy, two transactions that insert the same URI do not know which forest the other one will pick, so the server must use strict locking. With the range policy, there may be two transactions that insert the same URI but with different values for the range index, so the server must use strict locking.
Delete-only and Read-only Forests
Delete-only (DO) and read-only (RO) forests affect how documents are assigned. The following table summarizes the interaction between this feature and DO/RO forests.
Note that the second and the third columns cover what the rebalancers on RWs do when a forest is changed from RW to DO/RO or DO/RO to RW.
The rebalancer on a RO forest is always off. The rebalancer on a DO forest is off unless it is "retired".
A flash-backup forest is generally handled as a RO forest except that on new inserts, if the assignment logic cannot find a forest to insert the documents but there is at least one flash-backup forest, a Retry (instead of Exception) is thrown.
Rebalancer Settings after Upgrading from an Earlier Release
For a brand new database, the rebalancer is enabled by default and the assignment policy is bucket. The bucket policy moves less data than the legacy policy when adding or deleting a forest and it is still deterministic.
After upgrading from an earlier release of MarkLogic Server, the rebalancer is disabled on existing databases and the policy is set to legacy.
At the forest level, in both cases, the rebalancer is enabled by default.