
MarkLogic Server 11.0 Product DocumentationApplication Developer's Guide — Chapter 26
Redacting Document Content
Redaction is the process of eliminating or obscuring portions of a document as you read it from the database. For example, you can use redaction to eliminate or mask sensitive personal information such as credit card numbers, phone numbers, or email addresses from documents. This chapter describes redaction features you can use when reading a document from the database.
Advanced Security License option is required when using redaction.
This chapter covers the following topics:
- Terms and Definitions
- Introduction to Redaction
- Example: Getting Started With Redaction
- Security Considerations
- Defining Redaction Rules
- Installing Redaction Rules
- Applying Redaction Rules
- Validating Redaction Rules
- Built-in Redaction Function Reference
- Example: Using the Built-In Redaction Functions
- User-Defined Redaction Functions
- Example: Using Custom Redaction Rules
- Using Dictionary-Based Masking
- Example: Dictionary-Based Masking
- Salting Masking Values for Added Security
- Preparing to Run the Examples
Terms and Definitions
The following terms are used in this chapter:
| Term | Definition |
|---|---|
| redaction | The process of modifying a document to obscure or conceal sensitive information. You can redact XML and JSON documents. |
| redaction rule | A specification of what portion of a document to redact and what function to use to make the modification. Rules can be defined in XML or JSON. For details, see Defining Redaction Rules. |
| rule document | A document containing exactly one redaction rule. Rule documents must be installed in the schema database and be part of a collection before you can use them to redact content. For details, see Installing Redaction Rules. |
| rule collection | A database collection that only includes rule documents. A rule must be part of a collection before you can use it to redact documents. |
| redaction function | A function used to modify content during redaction. A redaction rule must include a redaction function specification. MarkLogic provides several built-in redaction functions. You can also create user-defined redaction functions. For details, see Built-in Redaction Function Reference and User-Defined Redaction Functions. |
| source document | A database document to which you apply one or more redaction rules. Redacting a document creates an in-memory copy. The source document is unmodified. |
| masking | A form of redaction in which the original value is replaced by a new value. The new value may be deterministic or random. |
| deterministic masking | A form of redaction in which the original value is replaced by a new value, and the same input always yields the same output. For an example, see mask-deterministic. |
| random masking | A form of redaction in which the original value is replaced by a new, random value. The same input does not result in the same output every time. For an example, see mask-random. |
| dictionary-based masking | A form of random or deterministic masking in which the new value is drawn from a user-defined dictionary. For details, see Using Dictionary-Based Masking. |
| redaction dictionary | A specially formatted collection of values that can be used as a source for dictionary-based masking. Redaction dictionaries must be installed in the schemas database. You can define a dictionary using XML or JSON. For details, see Defining a Redaction Dictionary. |
| concealment | A form of redaction in which the original value is completely hidden. The XML element or JSON property containing the redacted value is usually hidden as well, depending on the semantics of the redaction operation. For an example, see conceal. |
Introduction to Redaction
This section provides a brief overview of the redaction feature. The following topics are covered:
- What is Redaction?
- Express Redaction Requirements Through Rules
- Apply Rules Using Multiple Interfaces
- Protection of Redaction Logic
What is Redaction?
The redaction feature covered in this chapter is a read transformation you can apply to XML and JSON documents. A redacted document usually has selected portions removed, replaced, or obscured when it is read from the database. For example, you might use redaction to eliminate email addresses or obscure all but the last 4 digits of credit card numbers when exporting a document from MarkLogic.
Using redaction requires the Advanced Security License option.
Redaction is best suited for granular data hiding when you're exporting content from the database. For granular, real-time, in-application information hiding use Element Level Security; for more details, see Element Level Security in the Security Guide. For document-level access control, use security features such as document permissions and URI privileges. For more details on these and other security features in MarkLogic, see the Security Guide.
Redaction does not secure your documents within the database. For example, even if you redact a document when it is read, applications can still search or modify the content unless you properly secure the content with features such as document permissions and Element Level Security.
The table below describes some of the techniques you can use to redact your content. The details of what to redact and what techniques to apply depend on the requirements of your application. For details, see Choosing a Redaction Strategy.
MarkLogic supports redaction through the mlcp command line tool and an XQuery library module in the rdt namespace. You can also use the library module with Server-Side JavaScript.
The redaction feature includes built-in redaction functions for common redaction tasks such as obscuring social security numbers and telephone numbers. You can also plug in your own redaction functions.
Express Redaction Requirements Through Rules
MarkLogic uses rule-based redaction. A redaction rule tells MarkLogic how to locate the content within a document that will be redacted and how to modify that portion. A rule expresses the business logic, independent of the documents to be redacted.
A key component of a redaction rule is a redaction function specification. This function is what modifies the input nodes selected by the rule. MarkLogic provides several built-in redaction functions that you can use in your rules. For example, there are built-in redaction functions for redacting Social Security numbers, telephone numbers, and email addresses. You can also define your own redaction functions.
For details, see Defining Redaction Rules.
Before you can apply a rule, you must install it in the Schemas database as part of a rule collection. For details, see Installing Redaction Rules.
Apply Rules Using Multiple Interfaces
You can apply redaction rules when reading documents from MarkLogic using the following tools and interfaces:
The rdt:redact and rdt.redact functions are primarily intended for testing redaction rules.
For details, see Applying Redaction Rules.
Protection of Redaction Logic
It is important that you design and implement security policies that properly protect your rules, as well as your content.
The redaction workflow enables you to protect the business logic captured in a redaction rule independent of the documents to be redacted. For example, the user who generates redacted documents need not have privileges to modify or create rules, and the user who creates and administers rules need not have privileges to read or modify the content to be redacted.
For more details, see Security Considerations.
Example: Getting Started With Redaction
This section walks you through a simple example of defining, installing, and applying a redaction rule. The example uses the built-in redaction functions redact-email and redact-us-phone.
In this example, rules are installed and applied using Query Console. For a similar example based on mlcp, see Example: Using mlcp for Redaction in the mlcp User Guide.
The walkthrough covers the following steps:
Installing the Source Documents
Use the procedure in this section to install the sample documents into the Documents database using XQuery and Query Console. Though this example uses XQuery, you do not need to be familiar with XQuery to successfully complete the exercise.
When you complete these steps, your Documents database will contain the following documents. The documents are also inserted in a collection named gs-samples for easy reference.
Follow these steps to insert the sample documents:
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console.
xquery version "1.0-ml"; xdmp:document-insert("/redact-gs/sample1.xml", <personal> <name>Little Bopeep</name> <summary>Seeking lost sheep. Please call 123-456-7890.</summary> <id>12-3456789</id> </personal>, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>gs-samples</collection> </collections> </options>); xquery version "1.0-ml"; xdmp:document-insert("/redact-gs/sample2.json", xdmp:unquote(' {"personal": { "name": "Jack Sprat", "summary": "Free nutrition advice! Call (234)567-8901 now!", "id": "45-6789123" }} '), <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>gs-samples</collection> </collections> </options> );
- Select Documents in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The sample documents are installed.
- Optionally, click the Explore (eyeglass) icon next to the Database dropdown to explore the database and confirm insertion of the sample documents.
Installing the Rules
Rules must be installed in the schemas database associated with your content database. Rules must also be part of a collection before you can use them. This section installs rules in the Schemas database, which is the default schemas database associated with the Documents database.
You can install rules using any document insert technique. This example uses XQuery and Query Console. You do not need to be familiar with XQuery to complete this exercise. For other rule installation options, see Installing Redaction Rules.
When you complete this exercise, your schemas database will contain one rule defined in XML one rule defined in JSON. The rules are inserted in a collection named gs-rules. The XML rule uses the redact-us-phone built-in redaction function. The JSON rule uses the conceal built-in redaction function.
Follow these steps to install the rules. For an explanation of what the rules do, see Understanding the Rules.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console.
(: Apply redact-us-phone to //summary :) xquery version "1.0-ml"; xdmp:document-insert("/rules/gs/redact-phone.xml", <rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <description>Obscure phone numbers.</description> <path>//summary</path> <method> <function>redact-us-phone</function> </method> <options> <level>partial</level> </options> </rule>, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>gs-rules</collection> </collections> </options> ); (: Apply conceal to //id :) xquery version "1.0-ml"; xdmp:document-insert("/rules/gs/conceal-id.json", xdmp:unquote(' { "rule": { "description": "Remove customer ids.", "path": "//id", "method": { "function": "conceal" } }} '), <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>gs-rules</collection> </collections> </options> );
- Select Schemas in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The rule documents are installed with the URIs /rules/gs/redact-phone.xml and /rules/gs/conceal-id.json. added to the custom-rules collection.
Understanding the Rules
The XML rule installed in Installing the Rules has the following form:
<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <description>Obscure phone numbers.</description> <path>//summary</path> <method> <function>redact-us-phone</function> </method> <options> <level>partial</level> </options> </rule>
The rule elements have the following effect:
description- Optional metadata for informational purposes.path- Apply the redaction function specified by the rule to nodes selected by the path expression //summary.method- Use the built-in redaction functionredact-us-phoneto redact the value in asummaryXML element or JSON property. By default, this function replaces all digits in a phone number by the character #. You can tell this is a built-in function becausemethodhas nomodulechild.options- Pass alevelparameter value of partial to redact-us-phone, causing the function to leave the last 4 digits of the value unchanged.
The expected result of applying this rule is that any text in the value of a node named summary that matches the pattern of a US phone number will be replaced. The replacement value uses the # number to replace all but the last 4 digits. For example, a value such as 123-456-7890 is redacted to ###-###-7890. For more details, see redact-us-phone.
The JSON rule installed in Installing the Rules has the following form:
{ "rule": { "description": "Remove customer ids.", "path": "//id", "method": { "function": "conceal" } }}
The rule properties have the following effect:
description- Optional metadata for informational purposes.path- Apply the redaction function specified by the rule to nodes selected by the path expression //id.method- Use the built-in redaction functionconcealto redact theidXML element or JSON property. This function will hide the nodes selected bypath. You can tell this is a built-in function becausemethodhas nomodulechild.
The expected result of applying this rule is to remove nodes named id. For example, if //id selects an XML element or JSON property, the element or property does not appear in the redacted output. Note that, if //id selects array items in JSON, the items are eliminated, but the id property might remain, depending on the structure of the document. For more details, see conceal.
Applying the Rules
Follow the steps in this section to apply the rules in the collection gs-rules to the sample documents. This example applies the rules using Query Console. You can also use the mlcp command line tool to apply rules; for more details, see Applying Redaction Rules.
The user who applies the rules must have read permission on the source documents, the rule documents, and the rule collection. For more details, see Security Considerations.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - If you want to use XQuery to apply the rules, perform the following steps:
- If you want to use Server-Side JavaScript to apply the rules, perform the following steps:
- Select Documents in the Databases dropdown.
- Click the Run button. The rules in the gs-rules collection are applied to the documents in the gs-samples collection.
The following table shows the result of redacting the XML sample document. Notice that the telephone number in the summary element has been partially redacted by the redact-us-phone function. Also, the id element has been completely hidden by the conceal function. The affected parts of the content are highlighted in the table.
The following table shows the result of redacting the JSON sample document. Notice that the telephone number in the summary property has been partially redacted by the redact-us-phone function. Also, the id property has been completely hidden by the conceal function.The affected parts of the content are highlighted in the table.
Security Considerations
Redaction is a kind of read transformation, intended for use when exporting documents from the database. Redaction does not secure your content within the database. For example, users with sufficient document permissions can still search, read, and update documents containing the information you wish to redact. Use security features such as Element Level Security, document permissions, and URI privileges for real-time security. For more details, see the Security Guide.
Rule documents and rule collections are potentially sensitive information. Carefully consider the access controls and security requirements applicable to your redaction rules and rule collections.
For example, implement security controls that limit exposures such as the following:
- An attacker who can read a rule has access to potentially sensitive business logic. Even if the attacker lacks read access to your content, read access to rule logic can reveal the structure of your content.
- An attacker who can modify a rule or change which rules are in a rule collection can affect the outcome of a redaction operation, exposing data that would otherwise be redacted.
Consider the following actors when designing your security architecture:
- Rule Administrators: Users who need to be able to create, modify, and delete rules; manage rule collections; and create and modify redaction dictionaries. You might have multiple such users, with rights to administer different rule collections.
- Rule Users: Users who need to be able to apply rules but not create, modify, or delete rules or manage rule collections. Different rule users might have access to different rules or rule collections.
- Other Users: Other users typically will not have access to or control over rule documents, rule collections, or redaction dictionaries.
The following diagram illustrates high level redaction flow and the separation of responsibilities between the rule administrator and the rule user:
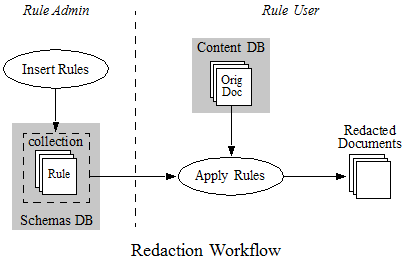
The following table lists some common tasks around administering and using redaction rules, the actor who usually performs this task, and the relevant security features available in MarkLogic. The security features are discussed in more detail below the table.
Document permissions enable you to control who can read, create, or update rule documents and redaction dictionaries. A rule administrator will usually have read and update permissions on such documents. Rule users will usually only have read permissions on rule documents and redaction dictionaries. To learn more about document permissions, see Protecting Documents in the Security Guide.
Placing rule documents in a protected collection enables you to control who can add documents to or remove documents from the collection. Rule administrators will usually have update permissions on a protected rule collection. Rule users will not have any special permissions on a protected rule collection. A protected collection must be explicitly created before you can add documents to it. To learn more about protected collections, see Collections and Security in the Search Developer's Guide.
A protected collection cannot be used to control who can read or modify the contents of documents in the collection; you must rely on document permissions for this control. Protected collections also cannot be used to control who can see which documents are in the collection.
MarkLogic predefines a redaction-user role. This role (or equivalent privileges) is required to validate rules and redact documents. That is, you must have this role to use the XQuery functions rdt:redact and rdt:rule-validate, the JavaScript functions rdt.redact and rdt.ruleValidate, or the -redaction option of mlcp.
To learn more about security features in MarkLogic, see the Security Guide.
Defining Redaction Rules
This section covers details related to authoring redaction rules. The following topics are covered:
- Rule Definition Basics
- Choosing a Redaction Strategy
- Choosing a Redaction Function
- Defining XML Namespace Prefix Bindings
- Limitations on XPath Expressions in Redaction Rules
- Defining Rules Usable on Multiple Document Formats
- XML Rule Syntax Reference
- JSON Rule Syntax Reference
Rule Definition Basics
You can define redaction rules in XML or JSON. The format of a rule (XML or JSON) has no effect on the type of document to which it can be applied.
A rule definition must include at least the following:
- An XPath expression defining the document components to which the rule applies. Some restrictions apply; for details, see Limitations on XPath Expressions in Redaction Rules.
- A descriptor specifying either a built-in or user-defined redaction function. The function performs the redaction on the node(s) selected by the path expression.
A rule definition can include additional data, such as a description or options. For details, see XML Rule Syntax Reference or JSON Rule Syntax Reference.
Designing a rule includes the following tasks:
- Choose a redaction strategy. For example, decide whether to mask or conceal redacted values. For details, see Choosing a Redaction Strategy.
- Determine whether to use a built-in or user-defined redaction function. For details, see Choosing a Redaction Function.
The following example rule specifies that the built-in redaction function redact-us-ssn will be applied to nodes matching the XPath expression //ssn. The redact-us-ssn function accepts a level parameter that specifies how much of the SSN to mask (full or partial). Use the options section of the rule definition to specify the level.
If you apply these rules to example documents from Preparing to Run the Examples, you will see the ssn XML element and JSON property values such as the following:
###-##-7890 ###-##-9012 ###-##-6789 ###-##-8901
You can also create your own XQuery or Server-Side JavaScript redaction functions and define rules that apply them. A user-defined function is identified in the method XML element or JSON property by function name, URI of the implementing module, and the module namespace URI (if your function is implemented in XQuery). For details, see User-Defined Redaction Functions.
The following example specifies that the user-defined redaction function redact-name will be applied to nodes matching the XPath expression //name. For more details and examples, see User-Defined Redaction Functions.
Choosing a Redaction Strategy
Redaction usually changes content in one of the following ways:
- Partial masking: Replace only a portion of the redacted value. For example, replace all but the last 4 digits in a credit card number with the character #.
- Full masking: Replace the entire redacted value with a new value. For example, replace all characters in an account number with a random string of characters.
- Concealment: Completely eliminate the redacted value or node.
When using masking, also consider the following points:
- Do I want the replacement value to always be the same for a given input (deterministic), or do I want it to be randomized?
Deterministic masking can preserve relationships between values and facilitate searches, which can be either beneficial or undesirable, depending on the application.
- Do I want the replacement value to be drawn from a known list of values (a dictionary)?
When you do not use a dictionary, the replacement value is either a randomly generated or repeating set of characters, depending on whether you choose random or deterministic masking. A redaction dictionary enables you to source replacement values from a pre-defined set of values instead.
- Is it important to preserve or obscure the shape of the input data?
For example, when you redact John Smith, must the resulting value be two words or one? Must the word length of the original input be preserved, or must it be normalized to something such as FIRSTNAME LASTNAME?
Once you determine the privacy requirements of your application, you can select an appropriate built-in redaction function or create one of your own.
Choosing a Redaction Function
A redaction function implements the logic of a given redaction rule, such as determining whether or not a node needs to be modified, generating a replacement value, or hiding a value or node. You can use one of the built-in redaction functions or create a user-defined redaction function.
The following built-in redaction functions are installed with MarkLogic. These functions meet the needs of most applications. These functions are discussed in detail in Built-in Redaction Function Reference. Examples are included with each function description.
mask-deterministicmask-randomconcealredact-numberredact-regexredact-us-ssnredact-us-phoneredact-emailredact-ipv4redact-datetime
If the built-in functions do not meet the needs of your application, you can create your own redaction function using XQuery or Server-Side JavaScript. For example, you might need a user-defined function to implement conditional redaction such as redact the name if the customer is a minor. For more details, see User-Defined Redaction Functions.
Defining XML Namespace Prefix Bindings
If you need to use namespace prefixes in the path XPath expression, define the namespace prefix binding by adding a namespaces component to your rule. For example, the following rule snippet uses an emp namespace prefix in its path value, and then defines a binding between the emp prefix and the namespace URI http://my/employees.
Limitations on XPath Expressions in Redaction Rules
Redaction rules applied to XML documents are restricted to the subset of XPath supported by XSLT. For example, you cannot use backward axes such as parent::*. The supported subset is defined in https://www.w3.org/TR/xslt#patterns.
Redaction rules applied to JSON documents have no such restrictions. However, if you apply rules to a mix of XML and JSON documents, limit your rules to the supported XPath subset.
Rule validation does not check the rule path for conformance to this limitation because it cannot know if the rule will ever be applied to an XML document. If you apply a rule to an XML document with an invalid path, the exception RDT-INVALIDRULEPATH is raised.
Defining Rules Usable on Multiple Document Formats
This section discusses important considerations when defining rules you expect to apply to both XML and JSON documents.
The XPath expression in the path XML element or JSON property of a rule is restricted to the subset of XPath supported by XSLT when the rule is applied to XML documents. Therefore, you must restrict your rule paths when redacting a mixture of XML and JSON context. For more details, see Limitations on XPath Expressions in Redaction Rules.
You must understand the interactions between XPath and the document model to ensure proper selection of nodes by a redaction rule. The XML and JSON document models differ in ways that can be surprising if you are not familiar with the models. For example, a simple path expression such as //id might match an element in an XML document, but all the items in an array value in JSON.
The built-in redaction functions compensate for differences in the JSON and XML document models in most cases, so they behave in a consistent way regardless of document type. If you write your own redaction functions, you might need to make similar adjustments.
You can write a single XPath expression that selects nodes in both XML and JSON documents, but if you do not understand the document models thoroughly, it might not select the nodes you expect. Keep the following tips in mind:
- XML and JSON contain different node types. Only XML documents contain element and attribute nodes; only JSON documents contain object, text, number, boolean, and null nodes. Thus, an expression such as //@color will never match nodes in a JSON document, even if the document contains a color property.
- There is no JSON property node. A JSON document such as
{"a": 42}is modeled as an unnamed root object node with a single number node child. The number node is named a and has the value 42. You can change the value of the number node, but you can only conceal the property by manipulating the parent object node. - Each item in a JSON array is a node with same name. For example, given
{"a": [1,2]}, the path expression //a selects two number nodes, not the containing array node. Selecting the array node requires a JSON specific path expression such as//array-node('a'). Thus, concealing an array-valued property requires a different strategy than concealing, say, a string-valued property. - A JSON property node whose name is not a valid XML element local name, such as one that contains whitespace, can only be selected using a node test operator such as
node(name). For example, given a document such as{"aa bb": "value"}, use the path expression/node('aa bb')to select the property named aa bb. - The
fn:data()function aggregates text children of XML elements, but does not do so for JSON properties. See the example in the table below.
For more details, see Working With JSON.
Any redaction function that can receive input from both XML and JSON must be prepared to handle multiple node types. For example, the same XPath expression might select an element node in XML, but an object node in JSON.
The rest of this section demonstrates some of the XML and JSON document model differences to be aware of. For a more detailed discussion of XPath over JSON, see Traversing JSON Documents Using XPath.
Suppose you are redacting the following example documents:
Then the following table summarizes the nodes selected by several XPath expressions.
XML Rule Syntax Reference
A redaction rule expressed in XML has the following form. All rule elements must be in the default namespace http://marklogic.com/xdmp/redaction and must not use namespace prefixes. For JSON syntax, see JSON Rule Syntax Reference.
<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <description>any text</description> <path>XPath expression</path> <namespaces> <namespace> <prefix>namespace prefix</prefix> <namespace-uri>uri</namespace-uri> </namespace> </namespaces> <method> <function>redaction function name</function> <module>user-defined module URI</module> <module-namespace>user-defined module namespace</module-namespace> </method> <options>params as elements</options> </rule>
Note the presence of rule/@xml:lang. The @lang value zxx is not a valid language. Rather, zxx is a special value that tells MarkLogic not to tokenize, stem, and index this element. Though you are not required to include this setting in your rules, it is strongly recommended that you do so because rules are configuration information and not meant to be searchable.
The following table provides more detail on the rule child elements.
| Element | Description |
|---|---|
description |
Optional. A description of this rule. |
path |
Required. An XPath expression identifying the content to redact. The expression must be an absolute path (begin with /) that selects an XML and/or JSON node, such as a element, attribute, object, array, text, boolean, number, or null node. It must not select a document node. Additional restrictions may apply; for details, see Limitations on XPath Expressions in Redaction Rules. |
namespaces |
Optional. If the XPath expression in path uses namespace prefixes, define the prefix-namespace URI bindings here. For details, see Defining XML Namespace Prefix Bindings. |
method |
Required. The specification of the redaction function to apply to content matching Use this form to apply a built-in redaction function. For details, see Built-in Redaction Function Reference. <method> <function>builtInFuncName</function> </method> Use this form to apply a user-defined function implemented in JavaScript: <method> <function>userDefinedFuncName</function> <module>javascriptModuleURI</module> </method> Use this form to apply a user-defined function implemented in XQuery: <method> <function>userDefinedFuncLocalName</function> <module>xqueryModuleURI</module> <module-namespace>moduleNSURI</module-namespace> </method> For details, see User-Defined Redaction Functions. |
options |
Optional. Specify data to pass to the redaction function. Each child element becomes a map entry (XQuery) or object property (JavaScript) in the options parameter passed to the redaction function. The element name is the map key or property name. |
JSON Rule Syntax Reference
A redaction rule expressed in JSON has the following form. For XML syntax, see XML Rule Syntax Reference.
{"rule": { "description": "any text", "path": "XPath expression", "method": { "function": "redaction function name", "module": "user-defined module URI", "moduleNamespace": "user-defined module namespace URI", }, "namespaces": [ {"namespace": { "prefix": "namespace prefix", "namespace-uri": "uri" }, ... ], "options": { "anyPropName": anyValue } } }
The following table provides more detail on each element.
| Element | Description |
|---|---|
description |
Optional. A description of this rule. |
path |
Required. An XPath expression identifying the content to redact. The expression must be an absolute path (begin with /) that selects an XML and/or JSON node, such as a element, attribute, object, array, text, boolean, number, or null node. The path must not select a document node. Additional restrictions may apply; for details, see Limitations on XPath Expressions in Redaction Rules. |
namespaces |
Optional. If the XPath expression in path uses namespace prefixes, define the prefix-namespace URI bindings here. For details, see Defining XML Namespace Prefix Bindings. |
method |
Required. The specification of the redaction function to apply to content matching Use this form to apply a built-in redaction function. For details, see Built-in Redaction Function Reference. "method": { "function": "builtInFuncName" } Use this form to apply a user-defined function implemented in JavaScript: "method": { "function": "userDefinedFuncName", "module": "javascriptModuleURI" } Use this form to apply a user-defined function implemented in XQuery: "method": { "function": "userDefinedFuncName", "module": "xqueryModuleURI", "moduleNamespace": "xqueryModuleNSURI" } For details, see User-Defined Redaction Functions. |
options |
Optional. Specify data to pass to the redaction function. This becomes the value of the options input parameter of the redaction function. For a redaction function implemented in XQuery, the options are passed to the function as a map:map, using the property names as map keys. |
Installing Redaction Rules
Before you can use a redaction rule, it must be installed as a document in the schema database associated with the database containing the documents to be redacted.
A rule document can only contain one rule and must not contain any non-rule data. A rule collection can contain multiple rule documents, but must not contain any non-rule documents. Every rule document must be associated with at least one collection because rules are specified by collection to redaction operations.
Use any MarkLogic document insertion APIs to insert rules into the schema database, such as the xdmp:document-insert XQuery function, the xdmp.documentInsert Server-Side JavaScript function, or the document creation features of the Node.js, Java, or REST Client APIs. You can assign rules to a collection at insertion time or as a separate operation.
If you run one of the following examples in Query Console using your schema database as the context database, a rule document is inserted into the database and assigned to two collections, pii-rules and security-rules.
Set permissions on your rule documents to constrain who can access or modify the rules. For more details, see Security Considerations.
Applying Redaction Rules
This section discusses applying redaction rules once rule collections have been installed on MarkLogic. The following topics are covered:
- Overview
- Applying Rules Using mlcp
- Applying Rules Using XQuery
- Applying Rules Using JavaScript
- No Guaranteed Ordering of Rules
The mlcp command line tool is the recommended interface because it can efficiently apply redaction to large numbers of documents when you export them from the database or copy them between databases. To learn more about mlcp, see the mlcp User Guide.
The rdt:redact and rdt.redact functions are suitable for debugging redaction rules or redacting small sets of documents.
Overview
Once you install one or more rule documents in the Schemas database and assign them to a collection, you can redact documents in the following ways:
- Exporting documents from a database using the mlcp command line tool.
- Copying documents between databases using the mlcp command line tool.
- Calling the XQuery function rdt:redact function.
- Calling the Server-Side JavaScript function rdt.redact.
The mlcp command line tool will provide the highest throughput, but you may find rdt:redact or rdt.redact convenient when developing and debugging rules.
Regardless of the redaction method you use, you select a set of documents to be redacted and one or more rule collections to apply to those documents.
Be aware of the following restrictions and guidelines when using redaction:
- You can redact both XML and JSON documents in the same operation.
- You can apply rules defined in XML to JSON documents and vice versa.
- You can only apply redaction rules to XML and JSON documents.
- You cannot redact document metadata such as document properties.
- You cannot rely on the order in which rules are applied. For details, see No Guaranteed Ordering of Rules.
- You must have read permissions for both the documents to be redacted and the redaction rules.
- If you apply a rule that uses a user-defined redaction function, you must have execute permissions for the module that contains the implementation. For details, see Security Considerations.
Your redaction operation will fail if any of the rule collections contain an invalid rule or no rules. You can use the rdt:rule-validate XQuery function or the rdt.ruleValidate JavaScript function to verify your rule collections before applying them. For details, see Validating Redaction Rules.
Applying Rules Using mlcp
You can apply redaction rules when using the mlcp export and copy commands. Use the -redaction option to specify one or more rule collections to apply to the documents as they are read from the source database. The redaction is performed by MarkLogic on the source host.
The following example command applies the rules in the collections with URIs pii-rules and hipaa-rules to documents in the database directory /employees/ on export.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh export -host localhost -port 8000 -username user \ -password password -mode local -output_file_path \ /example/exported/files -directory_filter /employees/ \ -redaction "pii-rules,hipaa-rules"
The following example applies the same rules during an mlcp copy operation:
$ mlcp.sh copy -mode local -input_host srchost -input_port 8000 \ -input_username user1 -input_password password1 \ -output_host desthost -output_port 8000 -output_username user2 \ -output_password password2 -directory_filter /employees/ \ -redaction "pii-rules,hipaa-rules"
For more details, see Redacting Content During Export or Copy Operations in the mlcp User Guide.
Applying Rules Using XQuery
Use the rdt:redact XQuery library function to create redacted in-memory copies of documents on MarkLogic Server. This function is best suited for testing and debugging your rules or for redacting a small number of documents. To extract large sets of redacted documents from MarkLogic, use the mlcp command line tool instead.
The following example applies the redaction rules in the collections with URIs pii-rules and hipaa-rules to the documents in the collection personnel:
xquery version "1.0-ml"; import module namespace rdt = "http://marklogic.com/xdmp/redaction" at "/MarkLogic/redaction.xqy"; rdt:redact(fn:collection("personnel"), ("pii-rules","hipaa-rules"))
The output is a sequence of document nodes, where each document is the result of applying the rules in the rule collections. The results includes both documents modified by the redaction rules and unmodified documents that did not match any rules or were not changed by the redaction functions.
If any of the rule collections passed to rdt:redact is empty, an RDT-NORULE exception is thrown. This protects you from accidentally failing to apply any rules, leading to unredacted content.
An exception is also thrown if any of the rule collections contain non-rule documents, if any of the rules are invalid, or if the path expression for a rule selects something other than a node. You can use rdt:rule-validate to test the validity of your rules before calling rdt:redact.
Applying Rules Using JavaScript
Use the rdt.redact JavaScript function to create redacted in-memory copies of documents on MarkLogic Server. This function is best suited for testing and debugging your rules or for redacting a small number of documents. To extract large sets of redacted documents from MarkLogic, use the mlcp command line tool instead.
You must use a require statement to bring the redaction functions into scope in your application. These functions are implemented by the XQuery library module /MarkLogic/redaction.xqy. For example:
const rdt = require('/MarkLogic/redaction');
The following example applies the redaction rules in the collections with URIs pii-rules and hipaa-rules to the documents in the collection personnel:
const rdt = require('/MarkLogic/redaction'); rdt.redact(fn.collection('personnel'), ['pii-rules','hipaa-rules'])
The output is a Sequence of document nodes, where each document is the result of applying the rules in the rule collections. A Sequence is an Iterable. For example, you can process your results with a for-of loop similar to the following:
const rdt = require('/MarkLogic/redaction'); const redacted = rdt.redact(fn.collection('personnel'), ['my-rules']); for (let doc of redacted) { // do something with the redacted document }
The results includes both documents modified by the redaction rules and unmodified documents that did not match any rules or were not changed by the redaction functions.
If any of the rule collections passed to rdt.redact is empty, an RDT-NORULE exception is thrown. This protects you from accidentally failing to apply any rules, leading to unredacted content. An exception is also thrown if any of the rule collections contain non-rule documents, if any of the rules are invalid, or if the path expression for a rule selects something other than a node.
You can use rdt.ruleValidate to test the validity of your rules before calling rdt.redact. For details, see Validating Redaction Rules.
No Guaranteed Ordering of Rules
The order in which rules are applied is undefined. You cannot rely on the order in which rules within a rule collection are run, nor on the ordering of rules across multiple rule collections used in the same redaction operation.
In addition, the final redacted result for a given reflects the result of at most one rule. If you have multiple rules that select the same node, they will all run, but the final document produced by redaction reflects the result of at most one of these rules.
Therefore, do not have multiple rules in the same redaction operation that redact or examine the same nodes.
For example, suppose you have two rule collections, A and B, with the following characteristics:
Collection A contains: ruleA1 using path //id ruleA2 using path //id Collection B contains: ruleB1 using path //id
If you apply both rule collections to a set of documents, you cannot know or rely on the order in which ruleA1, ruleA2, and ruleB1 are applied to any selected id node. In addition, the output only reflect the changes to //id made by one of ruleA1, ruleA2, and ruleB1.
Validating Redaction Rules
You can use the rdt:rule-validate XQuery function or the rdt.ruleValidate Server-Side JavaScript function to test your rule collections for validity before using them. Validate your rules before deploying them to production because an invalid rule or an empty rule collection will cause a redaction operation to fail.
Validation confirms that your rule(s) and rule collection(s) conforms to the expected structure and does not rely on any non-existent code, such as an undefined redaction function.
Note that a successfully validated rule can still cause runtime errors. For example, rule validation does not include dictionary validation if your rule uses dictionary-based masking. Similarly, validation does not verify that the XPath expression in a rule conforms to the limitations described in Limitations on XPath Expressions in Redaction Rules.
If all the rules in the input rule collections are valid, the validation function returns the URIs of all validated rules. Otherwise, an exception is thrown when the first validation error is encountered.
The following example validates the rules in two rule collections with URIs pii-rules and hipaa-rules.
Built-in Redaction Function Reference
MarkLogic provides several built-in redaction functions for use in your redaction rules. To use one of these functions, create a rule with a method child XML element or JSON property of the following form.
| XML | JSON |
|---|---|
<method> <function>builtInName</function> </method> |
"method": { "function": "builtInFuncName" } |
If the built-in accepts configuration parameters, specify them in the options child XML element or JSON property of the rule. For syntax, see Defining Redaction Rules. For parameter specifics and examples, see the reference section for each built-in.
The following table summarizes the built-in redaction functions and expected input parameters. Refer to the section on each function for more details and examples.
| Function Name | Description |
|---|---|
mask-deterministic |
Replace values with masking text that is deterministic. That is, a given input generates the same mask value every time it is applied. You can control features such as the length and type of the generated value. |
mask-random |
Replace values with random text. The masking value can vary across repeated application to the same input value. You can control the length of the generated value and type of replacement text (numbers or letters). |
conceal |
Remove the value to be masked. |
redact-number |
Replace values with random numbers. You can control the data type, range, and format of the masking values. |
redact-us-ssn |
Redact data that matches the pattern of a US Social Security Number (SSN). You can control whether or not to preserve the last 4 digits and what character to use as a masking character. |
redact-us-phone |
Redact data that matches the pattern of a US telephone number. You can control whether or not to preserve the last 4 digits and what character to use as a masking character. |
redact-email |
Redact data that matches the pattern of an email address. You can control whether to mask the entire address, only the username, or only the domain name. |
redact-ipv4 |
Redact data that matches the pattern of an IPv4 address. You can control what character to use as a masking character. |
redact-datetime |
Redact data that matches the pattern of a dateTime value. You can control the expected input format and the masking dateTime format. |
redact-regex |
Redact data that matches a given regular expression. You must specify the regular expression and the masking text. |
For a complete example of using all the built-in functions, see Example: Using the Built-In Redaction Functions.
mask-deterministic
Use this built-in to mask a value with a consistent masked value. That is, with deterministic masking, a given input always produces the same output. The original value is not derivable from the masked value.
Deterministic masking can be useful for preserving relationships across records. For example, you could mask the names in a social network, yet still be able to trace relationships between people (X knows Y, and Z knows Y).
Use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
length: The length, in characters, of the output value to generate. Optional. Default: 64. You cannot use this option with thedictionaryoption.character: The class of character(s) to use when constructing the masked value. Allowed values:any(default),alphanumeric,numeric,alphabetic. You cannot use this option with thedictionaryoption.dictionary: The URI of a redaction dictionary. Use the dictionary as the source of replacement values. You cannot use this option with any other options.salt: A salt to apply when generating masking values. MarkLogic applies the salt even when drawing replacement values from a dictionary. The default behavior is no salt.extend-salt: Whether/how to extend the salt with runtime information. You can extend the salt with the rule set collection name or the cluster id. Allowed values:none,collection,cluster-id(default).
When you use dictionary-based masking, a given input will always map to the same redaction dictionary entry. If you modify the dictionary, then the dictionary mapping will also change.
The salt and extend-salt options introduce rule and/or cluster-specific randomness to the generated masking values. Each masking value is still deterministic when salted: The same input produces the same output. However, the same input with different salts produces different output. For details, see Salting Masking Values for Added Security.
The following example rule applies deterministic masking to nodes selected by the XPath expression //name. The replacement value will be 10 characters long because of the length option.
The following table illustrates the effect of applying mask-deterministic to several different types of nodes. For an end-to-end example, see Example: Using the Built-In Redaction Functions.
In most cases, the entire value of the node is replaced by the redacted value, even if the original contents are complex, such as the //address example, above.
However, notice the //alias example above, which selects individual alias array items in the JSON example, rather than the entire array. If you want to redact the entire array value, you need a rule with a JSON-specific path selector. For example, a rule path such as //array-node('alias') selects the entire array in the JSON documents, resulting in a value such as the following for the alias property:
"alias": "6b162c290e"
For more details, see Defining Rules Usable on Multiple Document Formats.
To illustrate the effects of the various character option settings, assume a length option of 10 and the following input targeted for redaction:
<pii> <priv>redact me</priv> <priv>redact me</priv> <priv>redact me too</priv> </pii>
Then the following table shows the result of applying each possible value of the character option.
mask-random
Use this built-in to replace a value with a random masking value. A given input produces different output each time it is applied. The original value is not derivable from the masked value. Random masking can be useful for obscuring relationships across records.
Use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
length: The length, in characters, of the output value to generate. Optional. Default: 64. You cannot use thisoptionwith the dictionary option.character: The type of character(s) to use when constructing the masked value. Allowed values:any(default),alphanumeric,numeric,alphabetic. You cannot use this option with thedictionaryoption.dictionary: The URI of a redaction dictionary. Use the dictionary as the source of replacement values. You cannot use this option with any other options.
The following example rule applies random masking to nodes selected by the XPath expression //name. The replacement value will be 10 characters long because of the length option.
The following table illustrates the effect of applying mask-random to several different types of nodes. For an end-to-end example, see Example: Using the Built-In Redaction Functions.
In most cases, the entire value of the node is replaced by the redacted value, even if the original contents are complex, such as the //address example, above.
However, notice the //alias example above, which selects individual alias array items in the JSON example, rather than the entire array. If you want to redact the entire array value, you need a rule with a JSON-specific path selector. For example, a rule path such as //array-node('alias') selects the entire array in the JSON documents, resulting in a value such as the following for the alias property:
"alias": "6b162c290e"
For more details, see Defining Rules Usable on Multiple Document Formats.
To illustrate the effects of the various character option settings, assume a length option of 10 and the following input targeted for redaction:
<pii> <priv>redact me</priv> <priv>redact me</priv> <priv>redact me too</priv> </pii>
Then the following table shows the result of applying each possible value of the character option.
conceal
Use this built-in to entirely remove a selected value.
The following example rule applies concealment to values selected by the path expression //name.
The following table illustrates the effect of applying conceal to several different types of nodes. For an end-to-end example, see Example: Using the Built-In Redaction Functions.
In most cases, the entire selected node is concealed, even if the original contents are complex, such as the //address example, above.
However, note that a path such as //alias, above, conceals each array item in the JSON sample, rather than concealing the entire array. This is because the alias path step matches each array item individually; for details, see Defining Rules Usable on Multiple Document Formats and Traversing JSON Documents Using XPath.
If you want to redact the entire array value, you need a rule with a JSON-specific path selector, such as //array-node('alias'). For more details, see Defining Rules Usable on Multiple Document Formats.
redact-number
Use this built-in to mask values with a random number that conforms to a configurable range and format.
This function differs from the mask-random function in that it provides finer control over the masking value. Also, mask-random always generates a text node, while redact-number generates either a number node or a text node, depending on the configuration.
The redact-number function enables you to control the following aspects of the masking value:
- Constrain the value to a range by specifying a min and/or max value.
- Constrain the value to a specific numeric type (integer, decimal, or double).
- Specify a format for the value using a picture string. For example, limit the number of digits after the decimal point or include a currency symbol such as a dollar sign.
Use the following options to configure the behavior of this function:
min: The minimum acceptable masking value, inclusive. This function will not generate a masking value less than theminvalue. Optional. Default: 0.max: The maximum acceptable masking value, inclusive. This function will not generate a masking value greater than themaxvalue. Optional. Default: 18446744073709551615.format: Special formatting to apply to the replacement value. Optional. Default: No special formatting. The format string must conform to the syntax for an XSLT picture string, as described in the function reference for fn:format-number (XQuery) or fn.formatNumber ( JavaScript) and in https://www.w3.org/TR/xslt20/#function-format-number. If you specify a format, the replacement value is a text node in JSON documents instead of a number node. Note: If you specify a format, then the values in the range defined byminandmaxmust be convertible to decimal.type: The data type of the replacement value. Optional. Allowed values:integer,decimal,double. Default:integer. The values specified in theminandmaxoptions are subject to the specified type restriction.
The following example rule applies redact-number to values selected by the XPath expression //balance. The matched values will be replaced by decimal values in the range 0.0 to 100000.00, with two digits after the decimal point. The rule generates replacement values such as 3.55, 19.79, 82.96.
When applied to a JSON document, the node replaced by redaction can be either a text node or a number node, depending on whether or not you use the format option. With no explicit formatting, redaction produces a number node for JSON. With explicit formatting, redaction produces a text node. For example, redact-number might affect the value of a JSON property named key as follows:
no format option "key": 61.4121623617221 format option value "0.00" "key": "61.41"
The value range defined by a redact-number rule must be valid for the data type. For example, the following set of options is invalid because the specified range does not express a meaningful integer range from which to generate values:
min: 0.1 max: 0.9 type: integer
The values of min and max must be castable to the specified type.
The following table illustrates the effect of applying redact-number with various option combinations. For an end-to-end example, see Example: Using the Built-In Redaction Functions.
redact-us-ssn
Use this built-in to mask values that conform to one of the following patterns. These patterns correspond to typical representations for US Social Security Numbers (SSNs). The character N in these patterns represents a single digit in the range 0 - 9.
When a pattern match is found, every redacted digit is replaced with the same character. For example, a value such as 123-45-6789 might become XXX-XX-XXXX, depending on the rule configuration.
You can use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
level: How much to redact. Optional. This option can have the following values:full: Default. Replace all digits with the character specified by thecharacteroption.partial: Retain the last 4 digits; replace all other digits with thecharacterspecified by the character option.full-random: Replace all digits with random digits. Thecharacteroption is ignored. You will get a different value each time you redact a given value.
character: The character with which to replace each redacted digit whenlevelisfullorpartial. Optional. Default: #.
The following example redacts SSNs selected by the path expression //id. The parameters specify that last 4 digits of the SSN are preserved and the remaining digits are replaced with the character X.
The following table illustrates the effect of applying redact-us-ssn with various input values and configuration parameters. For a complete example, see Example: Using the Built-In Redaction Functions.
redact-us-phone
Use this built-in to mask values that conform to one of the following patterns. These patterns correspond to typical representations for US telephone numbers. The character N in these patterns represents a single digit in the range 0 - 9.
- NNN-NNN-NNNN (- separator)
- NNN.NNN.NNNN (. separator)
- (NNN)NNN-NNNN (no whitespace allowed)
- NNNNNNNNNN
When a pattern match is found, every redacted digit is replaced with the same character. For example, a value such as 123-456-7890 might become XXX-XXX-XXXX, depending on the configuration of the rule.
You can use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
level: How much to redact. Optional. This option can have the following values:full: Default. Replace all digits with the character specified by thecharacteroption.partial: Retain the last 4 digits; replace all other digits with thecharacterspecified by the character option.full-random: Replace all digits with random digits. Thecharacteroption is ignored. You will get a different random value each time you redact a given input.
character: The character with which to replace each redacted digit whenlevelisfullorpartial. Optional. Default: #.
The following example masks telephone numbers selected by the path expression //ph. The parameters specify that last 4 digits of the telephone number are preserved and the remaining digits are replaced with the character X.
The following table illustrates the effect of applying redact-us-phone with various input values and configuration parameters. For a complete example, see Example: Using the Built-In Redaction Functions.
redact-email
Use this built-in to mask values that conform to the pattern of an email address. The function assumes an email has the form name@domain.
Use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
level: How much of each email address to redact. Allowed values:full,name,domain. Optional. Default:full.
Redacting the username portion of an email address replaces the username with NAME. Redacting the domain portion of an email address replaces the domain name with DOMAIN. Thus, full redaction on the email address jsmith@example.com produces the replacement value NAME@DOMAIN.
The following example rule fully redacts email addresses selected by the path expression //email.
The following table illustrates the effect of applying redact-email with various levels of redaction. For a complete example, see Example: Using the Built-In Redaction Functions.
redact-ipv4
Use this built-in to mask values that conform to the pattern of an IP address. This function only redacts IPv4 addresses. That is, a value is redacted if it conforms to the following pattern, where N represents a decimal digit (0-9).
- Four blocks of 1-3 decimal digits, separated by period (.). The value of each block of digits must less than or equal to 255. For example:
123.201.098.112,123.45.678.0.
The redacted IP address is normalized to contain characters for the maximum number of digits. That is, an IP address such as 123.4.56.7 is masked as ###.###.###.###.
Use the following options to configure the behavior of this function. Set parameters in the options section of a rule.
The following example rule redacts IP addresses selected by the path expression //ip. The character parameter specifies the digits of the redacted IP address are replaced with X.
The following table illustrates the effect of applying redact-ipv4 with various configuration options. For a complete example, see Example: Using the Built-In Redaction Functions.
redact-datetime
Use this built-in to mask values that represent a dateTime value. You can use this function to mask dateTime value in one of two ways:
- Parse the input dateTime value and replace it with a masking value derived from applying a dateTime picture string to the input dateTime components. For example, redact the value 2012-05-23 by obscuring the month and date, producing a masking value such as 2012-MM-DD. You can only use this type of dateTime redaction to redact values that can be parsed by
fn:parse-dateTimeorfn.parseDateTime. - Replace any value with a random dateTime value, formatted according to a specified picture string. You can restrict the value to a particular year range.
You can use the following parameters to configure the behavior of this function. Set parameters in the options section of a rule.
level: The type of dateTime redaction. Required. Allowed values:parsed,random.format: A dateTime picture string describing how to format the masking value. Required.picture: A dateTime picture string describing the required input value format. This option is required whenlevelisparsedand ignored otherwise. Any input value that does not conform to the expected format is not redacted.range: A comma separated pair of years, used to constrain the masking value range whenlevelisrandom. Optional. This option is ignored iflevelis notrandom. For example, arangevalue of 1900,1999 will only generate masking values for the years 1900 through 1999, inclusive.When you apply
redact-datetimewith apictureoption, the content selected by your rule path must serialize to text whose leading characters conform to the picture string. If there are other leading characters in the serialized content, redaction fails with an error.
The following example rule redacts dateTime values using the parsed method. The picture option specifies that only input values of the form YYYY-MM-DD are redacted. The format option specifies that the masking value is of the form MM-DD-YYYY, with the day portion replaced by the literal value NN.
If you apply the above rules to a value such as 2012-11-09, the redacted value becomes NN-NN-2012.
The following example rule redacts values using the random method. The format option specifies that the masking value be of the form YYYY-MM-DD, and that the masking values be in the year range 1900 to 1999, inclusive. The format of the value to be redacted does not matter.
For a complete example, see Example: Using the Built-In Redaction Functions.
redact-regex
Use this built-in to mask values that match a regular expression. The regular expression and the replacement text are configurable.
Use the following options to configure the behavior of this function:
pattern: A regular expression identifying the values to be redacted. Required. Use the regular expression language syntax defined for XQuery and XPath. For details, see http://www.w3.org/TR/xpath-functions/%23regex-syntax.replacement: The text with which to replace values matchingpattern.
The pattern and replacement text are applied to the input values as if by calling the fn:replace XQuery function or the fn.replace Server-Side JavaScript function.
Note that the replacement pattern can contain back references to portions of the matched text. A back reference enables you to capture portions of the matched text and re-use them in the replacement value. See the example at the end of this section.
Regular expression patterns can contain characters that require escaping in your rule definitions. The following contains a few examples of problem characters. This is not an exhaustive list.
- Curly braces ({ }) in pattern in an XML rule installed with XQuery must be escaped as {{ and }} to prevent the XQuery interpreter from treating them as code block delimiters.
- A left angle bracket (<) in an XML rule must be replaced by the entity reference <.
- Backslashes (\) in a JSON rule definition must be escaped as \\ because \ is a special character in JSON strings.
The following example redacts text which has one of the following forms, where N represents a single digit in the range 0-9.
The following regular expression matches the supported forms:
\d{2}[-.\s]\d{7}
The following rule specifies that values in an id XML element or JSON property that match the pattern will be replaced with the text NN-NNNNNNN. Notice the escaped characters in the pattern.
The table below illustrates the result of applying the rule to documents matching the rule.
| Format | Original Document | Redacted Result |
|---|---|---|
XML |
<person> <id>12-3456789</id> </person> |
<person> <id>NN-NNNNNNN</id> </person> |
JSON |
{"id": "12-3456789"} |
{"id": "NN-NNNNNNN" } } |
The following rule uses a back reference in the pattern to leave the first 2 digits of the id intact. The pattern in the previous example has been modified to have parentheses around the sub-expression for the first block of digits ((\d{2}). The parentheses capture that block of text in a variable that is referenced in the replacement string as $1.
Applying this rule to the same documents as before results in the following redaction:
12-NNNNNNN
For more details, see the fn:replace XQuery function or the fn.replace Server-Side JavaScript function.
For a complete example, see Example: Using the Built-In Redaction Functions.
Example: Using the Built-In Redaction Functions
This example exercises all the built-in redaction functions using the sample documents from Preparing to Run the Examples. You can choose to work with either an XML rule set or a JSON rule set. The rules are equivalent in both rule sets.
This example has the following parts:
- Example Rule Summary
- Install the rules. Choose XML or JSON. Install one set or the other, not both.
- Apply the Rules
- Review the Results
Example Rule Summary
Each rule in this example exercises a different built-in redaction function. Each rule also operates on a different XML element or JSON property value of the sample documents to prevent overlap among the rules. Never apply collection of rules that act on the same document components.
The rules are inserted with a URI of the following form, where name is the XML element local name or JSON property name of the node selected by the rule. (The URI suffix depends on the rule format you install.)
/rules/redact-name.{xml|json}
For example, /rules/redact-alias.xml targets the alias XML element or JSON property of the sample documents.
Every rule is inserted into two collections, an all collection and a collection that identifies the built-in used by the rule. For example, /rules/redact-alias.json, which uses the mask-random built-in, is inserted in the collections all and random. This enables you to apply the rules together or selectively.
The table below summarizes the rules installed by this example:
Install the XML Rules
To install the XML rules, copy the following script into Query Console and run it against the Schemas database. For a detailed example of installing rules with Query Console, see Example: Getting Started With Redaction.
Follow these steps to install the example rules in XML format using XQuery. If you prefer to use JSON rules, see Install the JSON Rules. For a detailed example of installing rules with Query Console, see Example: Getting Started With Redaction.
- Copy the script below into Query Console.
- Set the Query Type to XQuery.
- Set the Database to Schemas.
- Click Run. The rules are installed in the Schemas database.
- Optionally, use the Query Console database explorer to review the rules.
Use the following script to install the rules. For a summary of what these rules do, see Example Rule Summary.
xquery version "1.0-ml"; import module namespace rdt = "http://marklogic.com/xdmp/redaction" at "/MarkLogic/redaction.xqy"; let $rules := ( <rules> <rule> <name>redact-name</name> <collection>deterministic</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//name</rdt:path> <rdt:method> <rdt:function>mask-deterministic</rdt:function> </rdt:method> <rdt:options> <length>10</length> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-alias</name> <collection>random</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//alias</rdt:path> <rdt:method> <rdt:function>mask-random</rdt:function> </rdt:method> <rdt:options> <length>10</length> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-address</name> <collection>conceal</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//address</rdt:path> <rdt:method> <rdt:function>conceal</rdt:function> </rdt:method> </rdt:rule> </rule> <rule> <name>redact-balance</name> <collection>balance</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//balance</rdt:path> <rdt:method> <rdt:function>redact-number</rdt:function> </rdt:method> <rdt:options> <min>0</min> <max>100000</max> <format>0.00</format> <type>decimal</type> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-anniversary</name> <collection>datetime</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//anniversary</rdt:path> <rdt:method> <rdt:function>redact-datetime</rdt:function> </rdt:method> <rdt:options> <level>random</level> <format>[Y0001]-[M01]-[D01]</format> <range>1900,1999</range> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-ssn</name> <collection>ssn</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//ssn</rdt:path> <rdt:method> <rdt:function>redact-us-ssn</rdt:function> </rdt:method> <rdt:options> <level>partial</level> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-phone</name> <collection>phone</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//phone</rdt:path> <rdt:method> <rdt:function>redact-us-phone</rdt:function> </rdt:method> <rdt:options> <level>full</level> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-email</name> <collection>email</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//email</rdt:path> <rdt:method> <rdt:function>redact-email</rdt:function> </rdt:method> <rdt:options> <level>name</level> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-ip</name> <collection>ip</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//ip</rdt:path> <rdt:method> <rdt:function>redact-ipv4</rdt:function> </rdt:method> <rdt:options> <character>X</character> </rdt:options> </rdt:rule> </rule> <rule> <name>redact-id</name> <collection>regex</collection> <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>//id</rdt:path> <rdt:method> <rdt:function>redact-regex</rdt:function> </rdt:method> <rdt:options> <pattern>\d{{2}}[-.\s]\d{{7}}</pattern> <replacement>NN-NNNNNNN</replacement> </rdt:options> </rdt:rule> </rule> </rules> ) return for $r in $rules/rule return let $collections := (<collection>all</collection>, $r/collection) let $options := <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>all</collection> <collection>{$r/*:collection/data()}</collection> </collections> </options> return xdmp:document-insert( fn:concat("/rules/", $r/name, ".xml"), $r/rdt:rule, $options )
Install the JSON Rules
Follow these steps to install the example rules in JSON format using Server-Side JavaScript. If you prefer to use XML rules, see Install the XML Rules. For a detailed example of installing rules with Query Console, see Example: Getting Started With Redaction.
- Copy the script below into Query Console.
- Set the Query Type to JavaScript.
- Set the Database to Schemas.
- Click Run. The rules are installed in the Schemas database.
- Optionally, use the Query Console database explorer to review the rules.
Use the following script to install the rules. For a summary of what these rules do, see Example Rule Summary.
declareUpdate(); const rules = [ { name: 'redact-name', content: {rule: { path: '//name', method: {function: 'mask-deterministic'}, options: {length: 10} }}, collection: 'deterministic' }, { name: 'redact-alias', content: {rule: { path: '//alias', method: {function: 'mask-random'}, options: {length: 10} }}, collection: 'random' }, { name: 'redact-address', content: {rule: { path: '//address', method: {function: 'conceal'}, }}, collection: 'conceal' }, { name: 'redact-balance', content: {rule: { path: '//balance', method: {function: 'redact-number'}, options: {min: 0, max: 100000, type: 'decimal', format: '0.00'} }}, collection: 'balance' }, { name: 'redact-anniversary', content: {rule: { path: '//anniversary', method: {function: 'redact-datetime'}, options: { level: 'random', format: '[Y0001]-[M01]-[D01]', range: '1900,1999' } }}, collection: 'datetime' }, { name: 'redact-ssn', content: {rule: { path: '//ssn', method: {function: 'redact-us-ssn'}, options: {level: 'partial'} }}, collection: 'ssn' }, { name: 'redact-phone', content: {rule: { path: '//phone', method: {function: 'redact-us-phone'}, options: {level: 'full'} }}, collection: 'phone' }, { name: 'redact-email', content: {rule: { path: '//email', method: {function: 'redact-email'}, options: {level: 'name'} }}, collection: 'email' }, { name: 'redact-ip', content: {rule: { path: '//ip', method: {function: 'redact-ipv4'}, options: {character: 'X'} }}, collection: 'ip' }, { name: 'redact-id', content: {rule: { path: '//id', method: {function: 'redact-regex'}, options: { pattern: '\\d{2}[-.\\s]\\d{7}', replacement: 'NN-NNNNNNN' } }}, collection: 'regex' } ]; rules.forEach(function (rule, i, a) { xdmp.documentInsert( '/rules/' + rule.name + '.json', rule.content, { permissions: xdmp.defaultPermissions(), collections: ['all', rule.collection] } ); })
Apply the Rules
Follow these steps to apply the complete set of example rules:
If you have not already done so, install the sample documents from Preparing to Run the Examples. This example assumes they are installed in the Documents database.
Choose one of the following methods to apply the rules:
Redact Using XQuery
Follow these steps to apply the example rules using XQuery and Query Console. All the rules will be applied to the sample documents.
- Copy the following script into Query Console:
xquery version "1.0-ml"; import module namespace rdt = "http://marklogic.com/xdmp/redaction" at "/MarkLogic/redaction.xqy"; rdt:redact(fn:collection("personnel"), "all")
- Set the Query Type to XQuery.
- Set the Database to Documents.
- Click Run.
The redacted documents will be displayed in Query Console. For a discussion of the expected results, see Review the Results.
Redact Using JavaScript
Follow these steps to apply the example rules using Server-Side JavaScript and Query Console. All the rules will be applied to the sample documents.
- Copy the following script into Query Console:
const rdt = require('/MarkLogic/redaction.xqy'); rdt.redact(fn.collection('personnel'), 'all');
- Set the Query Type to JavaScript.
- Set the Database to Documents.
- Click Run.
The redacted documents will be displayed in Query Console. For a discussion of the expected results, see Review the Results.
Redact Using mlcp
Use a command line similar to the following to export the redacted documents from the Documents database. All the rules will be applied to the sample documents.
Change the example command line as needed to match your environment. The output directory (./results) must not already exist.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh export -host localhost -port 8000 -username user \ -password password -mode local -output_file_path \ ./results -collection_filter personnel \ -redaction "all"
The redacted documents will be exported to ./results. For a discussion of the expected results, see Review the Results.
For more details on using mlcp with Redaction, see Redacting Content During Export or Copy Operations in the mlcp User Guide.
Review the Results
Applying all the example rules redacts most XML elements and JSON properties of the sample documents. Recall that the following rules are applied to each element or property:
The following table illustrates the effect on the sample documents /redact-ex/person1.xml. The redacted values you observe will differ from those shown if the rule generates a value, rather than masking an existing value.
The following table illustrates the effect on the sample document /redact-ex/person3.json.
You will observe similar changes to /redact-ex/person2.xml and /redact-ex/person3.json.
The results in Query Console will not necessarily be in the order person1, person2, person3, etc.
User-Defined Redaction Functions
If the built-in redaction functions do not address the needs of your application, you can implement a user-defined redaction function in XQuery or Server-Side JavaScript. Follow these steps to deploy and apply a user-defined function:
- Implement the function. For details, see Implementing a User-Defined Redaction Function.
- Install the function in the Modules database associated with your App Server. For details, see Installing a User-Defined Redaction Function.
- Define a rule that specifies your function. For syntax, see Defining Redaction Rules.
- Install and apply the rule.
This section covers the following topics:
For a complete example, see Example: Using Custom Redaction Rules.
Implementing a User-Defined Redaction Function
A user-defined function can be implemented in XQuery or Server-Side JavaScript. Your implementation must conform to one of the following interfaces:
The input node parameter is the node selected by the XPath expression in a rule using your function. The options parameter can be used to pass user-defined data from the rule into your function. Your function will return a node (redacted or not) or nothing.
Define your function in an XQuery or JavaScript library module. Install the module in the modules database associated with the App Server through which redaction will be applied. For details, see Installing a User-Defined Redaction Function.
The following table contains module templates suitable for defining your own conforming module. For a complete example, see Example: Custom Redaction Using JavaScript or Example: Custom Redaction Using XQuery.
Installing a User-Defined Redaction Function
Install your implementation in the modules database associated with your App Server using normal document insertion methods, such as the xdmp:document-insert XQuery function, the xdmp.documentInsert Server-Side JavaScript function, or any of the document insertion features of the Node.js, Java, or REST Client APIs.
For more details, see one of the following topics:
- Installing a Redaction Module Using XQuery
- Installing a Redaction Module Using JavaScript
- Installing a Redaction Module Using the Client APIs
Installing a Redaction Module Using XQuery
The procedure in this section demonstrates how to use Query Console and XQuery to install a module in the modules database. You can also use Server-Side JavaScript and the Java, Node.js, and REST Client APIs for this task.
The procedure outlined here makes the following assumptions. You will need to modify the procedure and example code to match your environment and application requirements.
- MarkLogic is installed on localhost.
- The modules database associated with your App Server is Modules.
- Your implementation is saved to a file on the file system with the path
/your/module/path/impl.xqy. - The default document permissions are suitable for the module permissions.
Use a procedure similar to the following to install your XQuery module in the Modules database.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into Query Console. Modify the module URI and the path in the
xdmp:document-get line to match your environment.(: MODIFY THE FILE SYSTEM PATH AND URI TO MATCH YOUR ENV :) xquery version "1.0-ml"; xdmp:document-insert( "/your/module/uri", xdmp:document-get("/your/module/path/impl.xqy"), <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> </options> )
- Select Modules in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The module is installed in the Modules database.
You can use the Explore feature of Query Console to browse the Modules database and confirm the installation.
Installing a Redaction Module Using JavaScript
The procedure in this section demonstrates how to use Query Console and Server-Side JavaScript to install a module in the modules database. You can also use XQuery or the Java, Node.js, and REST Client APIs for this task.
The procedure outlined here makes the following assumptions. You will need to modify the procedure and example code to match your environment and application requirements.
- MarkLogic is installed on localhost.
- The modules database associated with your App Server is Modules.
- Your implementation is saved to a file on the file system with the path
/your/module/path/impl.sjs. - The default document permissions are suitable for the module permissions.
Use a procedure similar to the following to install your XQuery module in the Modules database.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into Query Console. Modify the module URI and the path in the xdmp.documentGet line to match your environment.
// MODIFY THE FILE SYSTEM PATH and URI TO MATCH YOUR ENV declareUpdate(); xdmp.documentInsert( '/your/module/uri', xdmp.documentGet('/your/module/path/impl.sjs'));
- Select Modules in the Database dropdown.
- Select JavaScript in the Query Type dropdown.
- Click the Run button. The module is installed in the Modules database.
You can use the Explore feature of Query Console to browse the Modules database and confirm the installation.
Installing a Redaction Module Using the Client APIs
The Java Client API, Node.js Client API, and Node.js Client API include the capability to install modules in the modules database. See one of the following topics for details on how to install a module using one of the Client APIs.
Example: Using Custom Redaction Rules
This example walks you through installing and applying a custom redaction function. Two versions of the example are available, one that it JSON/JavaScript centric and another that is XML/XQuery centric. This artificial split is made to keep the example simple. You can mix XML and JSON freely with both XQuery and Server-Side JavaScript.
Choose one of the following examples to explore using custom redaction rules.
Example: Custom Redaction Using JavaScript
This example operates on JSON documents that include personal profile data such as name, address, and date of birth. A custom Server-Side JavaScript redaction function is used to redact the name if the person is less than 18 years old. A rule-specific option value controls the replacement text.
For simplicity, this example only uses JavaScript and JSON. You can also write a custom a function to handle both XML and JSON. For a similar XQuery/XML example, see Example: Custom Redaction Using JavaScript.
Before running the example, install the sample documents from Preparing to Run the Examples.
The example has the following parts:
- Input Data
- Installing the Redaction Function
- Installing the Redaction Rule
- Applying the Rule Using JavaScript
- Applying the Rule Using mlcp
Input Data
The input documents have the following structure. The birthdate property is used to determine whether or not to redact the name property.
{ "name": "any text", ... "birthdate": "YYYY-MM-DD" }
To install the sample documents, see Preparing to Run the Examples.
Installing the Redaction Function
Use the following procedure to install the custom function into the Modules database with the URI /redaction/redact-xml-name.sjs. These instructions use Server-Side JavaScript and Query Console, but you can use any document insertion interface. Discussion of the function follows the procedure.
- Save the following custom redaction function implementation to a file named redact-json-name.sjs. Choose a location readable by MarkLogic.
function redactName(node, options) { const parent = fn.head(node.xpath('./parent::node()')); // only redact if containing obj has the expected 'shape' if (parent.nodeKind == 'object' && parent.hasOwnProperty('birthdate')) { const birthday = xdmp.parseDateTime('[Y0001]-[M01]-[D01]', parent.birthdate); const age = Math.floor(fn.daysFromDuration( fn.currentDateTime().subtract(birthday)) / 365); if (age < 18) { // underage, so redact const builder = new NodeBuilder(); builder.addText(options.newName); return builder.toNode(); } } // not expected input, or not underage - do nothing return node; }; exports.redact = redactName;
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into Query Console. Modify the path in the
xdmp.documentGet line to match the file location from Step 1.// MODIFY THE FILE SYSTEM PATH TO MATCH YOUR ENV declareUpdate(); xdmp.documentLoad( '/your/path/redact-json-name.sjs', {uri: '/redaction/redact-json-name.sjs'});
- Select Modules in the Database dropdown.
- Select JavaScript in the Query Type dropdown.
- Click the Run button. The module is installed in the Modules databasew ith the URI /redaction/redact-xml-name.sjs.
You can use Query Console to explore the Modules database and confirm the installation.
The custom function expects to receive a JSON node corresponding to the node that is a candidate for redaction. This node must be a child of an object that also has a birthdate property. This code snippet implements this check:
const parent = fn.head(node.xpath('./parent::node()')); // only redact if containing obj has the expected 'shape' if (parent.nodeKind == 'object' && parent.hasOwnProperty('birthdate')) { ...
Note that you could theoretically write the function to expect the parent object as input and have the redaction rule use an XPath expression such as /name/parent::node(). However, such a rule path is invalid if the rule is ever applied to an XML document, so we traverse up to the parent node inside the redaction function instead of in the rule. For more details, see Limitations on XPath Expressions in Redaction Rules.
The redaction function uses the birthdate element to compute the age. If the age is less than 18, then the text in the name element is redacted. The value of the newName property in the options object is used as the replacement text.
const birthday = xdmp.parseDateTime('[Y0001]-[M01]-[D01]', parent.birthdate); const age = Math.floor(fn.daysFromDuration( fn.currentDateTime().subtract(birthday)) / 365); if (age < 18) { // underage, so redact const builder = new NodeBuilder(); builder.addText(options.newName); return builder.toNode(); }
Redaction functions must return a node, not a simple value. In this case, we need to return a JSON text node that will replace the original input node. You cannot construct a text node from a native JavaScript object, so the function uses a NodeBuilder to construct the return node.
These requirements are not specific to working with the root object node. Any time you have a node as input and want to modify it as a native JavaScript type, you need to use toObject. Similarly, you must always return a node, not a native JavaScript value.
Installing the Redaction Rule
Use the following procedure to install the rule in the schemas database associated with your content database. Some discussion of the rule follows the procedure.
These instructions assume you will use the pre-installed App Server on localhost:8000 and the Documents database, which is configured to use the Schemas database. This example uses Server-Side JavaScript and Query Console to install the rule, but you can use any document insertion interface.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console.
declareUpdate(); xdmp.documentInsert('/rules/redact-name.json', { rule: { path: '/name', method: { function: 'redact', module: '/redaction/redact-json-name.sjs' }, options: { newName: 'Jane Doe' } }}, { permissions: xdmp.defaultPermissions(), collections: ['custom-rules'] } );
- Select Schemas in the Database dropdown.
- Select JavaScript in the Query Type dropdown.
- Click the Run button. The rule document is installed with the URI /rules/redact-name.json and added to the custom-rules collection.
The path expression in the rule selects the name property for redaction. Since the custom function uses the birthdate sibling property of name to control the redaction, it would be more natural in some ways to apply the rule to the parent object. However, the parent object is anonymous, so it cannot be addressed by name in an XPath expression.
An XPath expression such as /name/parent::node() would select the anonymous parent object, but it will cause an error if the rule is ever applied to an XML document. Since we have a mixed XML and JSON document set, we choose write the rule and the custom function to use the name property as the redaction target.
The custom function is identified in the rule by exported function name and the URI of the implementation installed in the modules database:
method: { function: 'redact', module: '/redaction/redact-json-name.sjs' }
The options property contains a single child, newName. This value is used as the replacement value for any redacted name elements:
options: { newName: 'Jane Doe' }
For a similar XQuery/XML example of defining and installing a rule that uses a custom function, see Example: Custom Redaction Using XQuery.
Applying the Rule Using JavaScript
Follow this procedure to apply the example custom redaction function using Query Console and rdt.redact. Make sure you have already have installed the custom redaction module, rule, and sample documents.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console:
const jsearch = require('/MarkLogic/jsearch'); const rdt = require('/MarkLogic/redaction'); jsearch.collections('personnel').documents() .map(function (match) { match.document = fn.head( rdt.redact(fn.root(match.document), 'custom-rules') .root; return match; }).result();
- Select Documents in the Databases dropdown.
- Select JavaScript in the Query Type dropdown.
- Click the Run button. The rules in the custom-rules collection are applied to the documents in the personnel collection.
If you use the sample documents from Preparing to Run the Examples, running the script will have the following effect on the search result matches:
- /redact-ex/person1.xml: Unredacted because it doesn't match the rule path
- /redact-ex/person2.xml: Unredacted because it doesn't match the rule path
- /redact-ex/person3.json: Name changed to "Jane Doe"
- /redact-ex/person4.json: Unredacted because not under the age limit
(Note, if you installed both the XQuery/XML and JavaScript/JSON custom redaction examples, /personnel/person1.xml will also be redacted to displayJohn Doe.)
Note that the node passed to rdt.redact is obtained by applying fn.root to match.document.
rdt.redact(fn.root(match.document), 'custom-rules')
The rdt.redact function expects a document node as input, whereas match.document is the root node under the document node, such as a JSON object-node or XML element node. In the context of DocumentsSearch.map, the node in match.document is an in-database node, not an in-memory construct, so we can access the enclosing document node using fn.root, as shown above.
A similar technique is used, in reverse, to save the redaction result back into the search results:
match.document = fn.head(rdt.redact(...)).root;
This is necessary because rdt.redact function returns a Sequence of in-memory document nodes. To save the redacted content in the expected form, we access the first node in the Sequence with fn.head, and then dereference it using the .root property so that match.document again contains the root node under the document node.
Applying the Rule Using mlcp
You can apply the example custom redaction rule with mlcp by running a command similar to the one below. The command exports the redacted documents to ./mlcp-output. This directory must not already exist.
Modify the command line as needed to match your environment.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh export -host localhost -port 8000 -username user \ -password password -mode local -output_file_path \ ./mlcp-output -collection_filter personnel \ -redaction "custom-rules"
For more details, see Redacting Content During Export or Copy Operations in the mlcp User Guide.
If you use the sample documents from Preparing to Run the Examples, running the script will create 4 files in the directory ./mlcp-output.
These files will reflect the following effects relative to the input documents:
- /redact-ex/person1.xml: Unredacted because it doesn't match the rule path
- /redact-ex/person2.xml: Unredacted because it doesn't match the rule path
- /redact-ex/person3.json: Name changed to "Jane Doe"
- /redact-ex/person4.json: Unredacted because not under the age limit
(Note, if you installed both the XQuery/XML and JavaScript/JSON custom redaction examples, /personnel/person1.xml will also be redacted to displayJohn Doe.)
Example: Custom Redaction Using XQuery
This example operates on XML documents that include personal profile data such as name, address, and date of birth. A custom XQuery redaction function is used to redact the name if the person is less than 18 years old. A rule-specific option value controls the replacement text.
This example only uses XQuery and XML. You can write a custom a function to handle both XML and JSON, but you might find it more convenient to use XQuery for XML and Server-Side JavaScript for JSON. For an equivalent JavaScript/JSON example, see Example: Custom Redaction Using JavaScript.
Before running this example, you must install the sample documents from Preparing to Run the Examples.
The example has the following parts:
- Input Data
- Installing the Redaction Function
- Installing the Redaction Rule
- Applying the Rule Using XQuery
- Applying the Rule Using mlcp
Input Data
The input documents have the following structure. The birthdate element is used to determine whether or not to redact the name element.
<person> <name>any text</name> ... <birthdate>YYYY-MM-DD</birthdate> </person>
To install the sample documents, see Preparing to Run the Examples.
Installing the Redaction Function
Use the following procedure to install the custom function into the Modules database with the URI /redaction/redact-xml-name.xqy. These instructions use XQuery and Query Console, but you can use any document insertion interface.
- Save the following custom redaction function implementation to a file named redact-xml-name.xqy. Choose a location readable by MarkLogic.
xquery version "1.0-ml"; module namespace my = "http://marklogic.com/example/redaction"; declare function my:redact( $node as node(), $options as map:map ) as node()? { if (xdmp:node-kind($node) = "element" and fn:local-name-from-QName(fn:node-name($node)) = "person") then let $birthdate := xdmp:parse-dateTime('[Y0001]-[M01]-[D01]', $node//birthdate) let $age := math:floor(fn:days-from-duration( fn:current-dateTime() - $birthdate)) div 365 return if ($age < 18) then element { fn:node-name($node) } { $node/@*, for $n in ($node/node()) return if (fn:local-name-from-QName(fn:node-name($n)) = "name") then element {fn:node-name($n)} { $n/@*, text {map:get($options, "new-name")} } else $n } else $node else $node };
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into Query Console. Modify the path in the
xdmp:document-get line to match the file location from Step 1.(: MODIFY THE FILE SYSTEM PATH TO MATCH YOUR ENV :) xquery version "1.0-ml"; xdmp:document-load( "/your/path/redact-xml-name.xqy", <options xmlns="xdmp:document-load"> <uri>/redaction/redact-xml-name.xqy</uri> </options> )
- Select Modules in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The module is installed in the Modules database with the URI /redaction/redact-xml-name.xqy.
You can use Query Console to explore the Modules database and confirm the installation.
The custom function expects to receive a <person/> node as input and options that include a new-name key specifying the replacement name value.
The function uses the birthdate element to compute the age. If the age is less than 18, then the text in the name element is redacted.
If the input does not have the expected shape or the age is 18 or older, the input node is returned, unchanged.
For a similar JavaScript-based solution, see Example: Custom Redaction Using JavaScript.
Installing the Redaction Rule
Use the following procedure to install the rule in the schemas database associated with your content database. Some discussion of the rule follows the procedure.
These instructions assume you will use the pre-installed App Server on localhost:8000 and the Documents database, which is configured to use the Schemas database. This example uses XQuery and Query Console to install the rule, but you can use any document insertion interface.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console.
xquery version "1.0-ml"; xdmp:document-insert("/rules/redact-name.xml", <rdt:rule xml:lang="zxx" xmlns:rdt="http://marklogic.com/xdmp/redaction"> <rdt:path>/person</rdt:path> <rdt:method> <rdt:function>redact</rdt:function> <rdt:module>/redaction/redact-xml-name.xqy</rdt:module> <rdt:module-namespace>http://marklogic.com/example/redaction</rdt:module-namespace> </rdt:method> <rdt:options> <new-name>John Doe</new-name> </rdt:options> </rdt:rule> , <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>custom-rules</collection> </collections> </options>)
- Select Schemas in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The rule document is installed with URI /rules/redact-name.xml and added to the custom-rules collection.
Recall that the sample documents are rooted at a <person/> element, so the rule selects the entire contents by using /person as the path value. This enables the redaction function to easily examine /person/birthdate, as well as modify /person/name.
The custom function is identified in the rule by function name, module URI, and module namespace:
<rdt:method> <rdt:function>redact</rdt:function> <rdt:module>/redaction/redact-xml-name.xqy</rdt:module> <rdt:module-namespace> http://marklogic.com/example/redaction </rdt:module-namespace> </rdt:method>
The options element contains a single element, new-name, that is used as the replacement value for any redacted name elements:
<rdt:options> <new-name>John Doe</new-name> </rdt:options>
For a similar JavaScript/JSON example of defining and installing a rule that uses a custom function, see Example: Custom Redaction Using JavaScript.
Applying the Rule Using XQuery
Follow this procedure to apply the example custom redaction function using Query Console and rdt:redact. Make sure you have already installed the custom redaction module, rule, and sample documents.
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console:
xquery version "1.0-ml"; import module namespace rdt = "http://marklogic.com/xdmp/redaction" at "/MarkLogic/redaction.xqy"; rdt:redact( cts:search(fn:doc(), cts:collection-query("personnel")), "custom-rules")
- Select Documents in the Databases dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The rules in the custom-rules collection are applied to the documents in the personnel collection.
If you use the sample documents from Preparing to Run the Examples, running the script will return the following:
- /redact-ex/person1.xml: Name redacted by changing it to John Doe
- /redact-ex/person2.xml: Unredacted due to age > 18
- /redact-ex/person3.json: Unredacted because it doesn't match the rule path
- /redact-ex/person4.json: Unredacted because it doesn't match the rule path
(Note, if you installed both the XQuery/XML and JavaScript/JSON custom redaction examples, /personnel/person3.json will also be redacted to display Jane Doe.)
Applying the Rule Using mlcp
You can apply the example custom redaction rule with mlcp by running a command similar to the following. The command exports the redacted documents to ./mlcp-output. This directory must not already exist.
Modify the command line as needed to match your environment.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh export -host localhost -port 8000 -username user \ -password password -mode local -output_file_path \ ./mlcp-output -collection_filter personnel \ -redaction "custom-rules"
For more details, see in Redacting Content During Export or Copy Operations the mlcp User Guide.
If you use the sample documents from Preparing to Run the Examples, running the script will create 4 files in the directory ./mlcp-output. These files will reflect the following effects relative to the input documents:
- /redact-ex/person1.xml: Name redacted by changing it to John Doe
- /redact-ex/person2.xml: Unredacted due to age > 18
- /redact-ex/person3.json: Unredacted because it doesn't match the rule path
- /redact-ex/person4.json: Unredacted because it doesn't match the rule path
(Note, if you installed both the XQuery/XML and JavaScript/JSON custom redaction examples, person3.json will also be redacted to displayJane Doe.)
Using Dictionary-Based Masking
Some pre-defined redaction functions that mask content can extract the masking value from a redaction dictionary. This section covers the following topics related to using a dictionary for a masking source:
Defining a Redaction Dictionary
A redaction dictionary is an XML or JSON document with the form specified below.
| Format | Syntax |
|---|---|
| XML | <dictionary xmlns="http://marklogic.com/xdmp/redaction"> <entry>value</entry> ... </dictionary> |
| JSON | { "dictionary": { "entry":[ value, ... ] }} |
The following requirements apply. If these requirements are not met, you will get an RDT-INVALIDDICTIONARY error when you use the dictionary.
- A dictionary must contain at least one entry.
- The value in an entry cannot be empty or null.
- The value must be atomic. That is:
The following example is a trivial dictionary containing four entries of various types. For a complete example, see Example: Dictionary-Based Masking.
Installing a Redaction Dictionary
Before you can use a redaction dictionary, you must install it in the schemas database associated with the database that contains the content to be redacted. This must be the same database in which you install your redaction rules.
Install the using the same techniques discussed in Installing Redaction Rules.
For security purposes, use document permissions to carefully control who can read or modify your dictionary. For more details, see Security Considerations.
Using a Redaction Dictionary
The pre-defined redaction functions that support dictionary-based masking do so through a dictionary option that accepts a dictionary URI as its value.
For example, the mask-deterministic and mask-random built-in redaction functions support a dictionary option, so you can draw values from a dictionary with a rule similar to the following:
<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <path>//country</path> <method> <function>mask-random</function> </method> <options> <dictionary>/rules/dict/countries.xml</dictionary> </options> </rule>
For more details, see Built-in Redaction Function Reference. For a complete example, see Example: Dictionary-Based Masking.
Example: Dictionary-Based Masking
This section contain an example that demonstrates how to install a redaction dictionary and use it with built-in redaction functions. The examples rules perform the following redactions:
- The
mask-deterministicfunction and a JSON dictionary is applied to thecountryXML element or JSON property of the sample data. - The
mask-randomfunction and an XML dictionary is applied to the street XML element or JSON property of the sample data.
Before running this example, you must install the sample documents from Preparing to Run the Examples.
Use the following steps to exercise the example:
Install the Dictionaries
Use either of the following procedures to install example dictionaries. The procedure installs two dictionaries: A dictionary of country names, defined in XML, and a dictionary of street addresses, defined in JSON.
Install Dictionaries Using XQuery
The following procedure installs the two example dictionaries:
- Copy the script below into a new query in Query Console.
- Set the Query Type to XQuery.
- Set the Database to Schemas.
- Click Run. The dictionaries are installed in the Schemas database with the URIs
/rules/dict/countries.xmland/rules/dict/streets.json. - Optionally, use the Query Console database explorer to review the dictionaries.
Use the following script in Step 1, above.
(: NOTE: RUN AGAINST YOUR SCHEMAS DB :) (: Install example XML dictionary :) xquery version "1.0-ml"; let $dictURI := '/rules/dict/countries.xml' let $dict := <dictionary xmlns="http://marklogic.com/xdmp/redaction"> <entry>Brazil</entry> <entry>China</entry> <entry>France</entry> <entry>Germany</entry> <entry>United States</entry> <entry>United Kingdom</entry> </dictionary> return xdmp:document-insert($dictURI, $dict, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> </options>); (: Install example JSON dictionary :) xquery version "1.0-ml"; let $dictURI := '/rules/dict/steets.json' let $dict := xdmp:unquote( '{ "dictionary": { "entry": [ "10 Oak Ln", "2451 Elm St", "892 Veterans Blvd", "P.O. Box 1234", "250 Park Ln", "16 Highway 82, Suite 301" ] } }') return xdmp:document-insert( $dictURI, $dict, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> </options>);
Install Dictionaries Using JavaScript
The following procedure installs the two example dictionaries:
- Copy the script below into a new query in Query Console.
- Set the Query Type to JavaScript.
- Set the Database to Schemas.
- Click Run. The dictionaries are installed in the Schemas database with the URIs
/rules/dict/countries.xmland/rules/dict/streets.json. - Optionally, use the Query Console database explorer to review the dictionaries.
Use the following script in Step 1, above.
// NOTE: RUN AGAINST YOUR SCHEMAS DB declareUpdate(); // Install example XML dictionary const countryDict = fn.head(xdmp.unquote( '<dictionary xmlns="http://marklogic.com/xdmp/redaction">' + '<entry>Brazil</entry>' + '<entry>China</entry>' + '<entry>France</entry>' + '<entry>Germany</entry>' + '<entry>United States</entry>' + '<entry>United Kingdom</entry>' + '</dictionary>')); xdmp.documentInsert( '/rules/dict/countries.xml', countryDict, { permissions: xdmp.defaultPermissions() } ); // Install example JSON dictionary const streetDict = { dictionary: { entry: [ '10 Oak Ln', '2451 Elm St', '892 Veterans Blvd', 'P.O. Box 1234', '250 Park Ln', '16 Highway 82, Suite 301' ] } }; xdmp.documentInsert( '/rules/dict/streets.json', streetDict, { permissions: xdmp.defaultPermissions() } );
Install the Rules
Use either of the following procedures to install rules that exercise the dictionaries. One rule is defined using XML, and the other rule is defined using JSON.
Install Rules Using XQuery
The following procedure installs two rules, each of which uses one of the dictionaries installed in Install the Dictionaries:
- Copy the script below into a new query in Query Console.
- Set the Query Type to XQuery.
- Set the Database to Schemas.
- Click Run. The rules are installed in the Schemas database with the URIs
/rules/randomize-country.xmland/rules/redact-street.json. - Optionally, use the Query Console database explorer to review the rules.
Use the following script in Step 1, above.
(: NOTE: RUN AGAINST YOUR SCHEMAS DB :) (: Install rule using mask-random with a dictionary :) xquery version "1.0-ml"; let $ruleURI := '/rules/randomize-country.xml' let $rule := <rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <path>//country</path> <method> <function>mask-random</function> </method> <options> <dictionary>/rules/dict/countries.xml</dictionary> </options> </rule> return xdmp:document-insert( $ruleURI, $rule, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>dict</collection> <collection>dict-random</collection> </collection> </options>); (: Install rule using mask-deterministic with a dictionary :) xquery version "1.0-ml"; let $ruleURI := '/rules/redact-street.json' let $rule := xdmp:unquote( '{"rule": { "path": "//street", "method": {"function": "mask-deterministic"}, "options": {"dictionary": "/rules/dict/streets.json"} }}' ) return xdmp:document-insert( $ruleURI, $rule, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>dict</collection> <collection>dict-deter</collection> </collections> </options> );
Install Rules Using JavaScript
The following procedure installs two rules, each of which uses one of the dictionaries installed in Install the Dictionaries:
- Copy the script below into a new query in Query Console.
- Set the Query Type to JavaScript.
- Set the Database to Schemas.
- Click Run. The rules are installed in the Schemas database with the URIs
/rules/randomize-country.xmland/rules/redact-street.json. - Optionally, use the Query Console database explorer to review the rules.
Use the following script in Step 1, above.
// NOTE: RUN AGAINST YOUR SCHEMAS DB declareUpdate(); // Install rule using mask-random with dictionary xdmp.documentInsert( '/rules/randomize-country.xml', fn.head(xdmp.unquote( '<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction">' + '<path>//country</path>' + '<method>' + '<function>mask-random</function>' + '</method>' + '<options>' + '<dictionary>/rules/dict/countries.xml</dictionary>' + '</options>' + '</rule>')), { permissions: xdmp.defaultPermissions(), collections: ['dict','dict-random'] } ); // Install rule using mask-deterministic with dictionary xdmp.documentInsert( '/rules/redact-street.json', {rule: { path: '//street', method: {function: 'mask-deterministic'}, options: {dictionary: '/rules/dict/streets.json'} }}, { permissions: xdmp.defaultPermissions(), collections: ['dict','dict-deter'] } );
Apply the Rules
Choose one of the following methods for exercising the rules that use dictionary-based masking:
Apply the Rules Using XQuery
Follow these steps to apply the example rules using XQuery and Query Console. All the rules will be applied to the sample documents.
- Copy the following script into Query Console:
xquery version "1.0-ml"; import module namespace rdt = "http://marklogic.com/xdmp/redaction" at "/MarkLogic/redaction.xqy"; let $results := rdt:redact(fn:collection("personnel"), "dict") return ( "*** REDACTED STREETS ***", $results//street/data(), "*** REDACTED COUNTRIES ****", $results//country/data() )
- Set the Query Type to XQuery.
- Set the Database to Documents.
- Click Run. The redacted street and country names from each document are displayed.
You will see output similar to the following, though the values may vary.
*** REDACTED STREETS *** P.O. Box 1234 2451 Elm St 892 Veterans Blvd 250 Park Ln *** REDACTED COUNTRIES **** United States Brazil Germany France
If you run the script again, the values for the street names will not change because they are redacted using mask-deterministic. The values for the countries will change with each run since they are redacted using mask-random.
Apply the Rules Using JavaScript
Follow these steps to apply the example rules using XQuery and Query Console. All the rules will be applied to the sample documents.
- Copy the following script into Query Console:
const rdt = require('/MarkLogic/redaction.xqy'); const results = rdt.redact(fn.collection('personnel'), 'dict'); // Extract the redacted streed and country data for display purposes const displayAccumulator = ['*** STREETS ***']; for (let doc of results) { displayAccumulator.push(doc.xpath('//street/data()')); } displayAccumulator.push('*** COUNTRIES ***'); for (let doc of results) { displayAccumulator.push(doc.xpath('//country/data()')); } // Dump the redacted street and country values displayAccumulator
- Set the Query Type to JavaScript.
- Set the Database to Documents.
- Click Run. The redacted street and country names from each document are displayed.
You will see output similar to the following, though the values may vary.
*** REDACTED STREETS *** P.O. Box 1234 2451 Elm St 892 Veterans Blvd 250 Park Ln *** REDACTED COUNTRIES **** United States Brazil Germany France
If you run the script again, the values for the street names will not change because they are redacted using mask-deterministic. The values for the countries will change with each run since they are redacted using mask-random.
Salting Masking Values for Added Security
When you use the mask-deterministic built-in redaction function without a salt, two rules with equivalent options always produce the same output for the same input. You can use a salt to introduce masking value variance across rules, rule sets, or clusters. When you use a salt, each masking value is still deterministic in that the same input produces the same output. However, the same input with different salts produces different output.
The mask-deterministic function supports applying a salt to masking value generation via the following options. You can use them individually or together.
salt: A user-defined salt value. This option has no value by default.extend-salt: Include the cluster id or rule set collection name in the salt. This option defaults tocluster-id.
To completely disable the salt, set salt to an empty string (or leave it unspecified) and set extend-salt to none.
For example, consider the following rules that apply equivalent redaction logic to two different paths, using no salt:
<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <path>/data/pii1</path> <method> <function>mask-deterministic</function> </method> <options> <length>20</length> <salt/> <extend-salt>none</extend-salt> </options> </rule> <rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <path>/data/pii2</path> <method> <function>mask-deterministic</function> </method> <options> <length>20</length> <salt/> <extend-salt>none</extend-salt> </options> </rule>
If you apply these rules to the following documents, both produce the same masking value by default for the input John Smith:
An attacker could use a similar salt-less rule to generate a lookup table that indicates John Smith redacts to 6c50dad68163a7a079db. That knowledge can be used to reverse engineer redacted output.
However, if you modify the /data/pii1 rule to include a salt option:
<rule xml:lang="zxx" xmlns="http://marklogic.com/xdmp/redaction"> <path>/data/pii1</path> <method> <function>mask-deterministic</function> </method> <options> <length>20</length> <salt>anyoldthing</salt> </options> </rule>
Then the masking values generated by the two rules differ as shown below. An attacker cannot deduce the relationship between the redacted value (89d7499b154a8b81c17f) and the input value (John Smith) without also knowing the salt.
By default, extend-salt option is set to cluster-id and the salt option is empty. This means that equivalent rules applied on the same cluster will generate the same output, but the same values would not be generated on a different cluster.
Similarly, setting extend-salt to collection means that an attacker who has access to one rule set cannot generate a lookup table that can be used to reverse engineer redacted values generated by a different rule set.
The following table outlines the impact of various salt and extend-salt option combinations, assuming all other options are the same.
Apply the Rules Using mlcp
Use a command line similar to the following to export the redacted documents from the Documents database. Both dictionary-based rules will be applied to the sample documents.
Change the example command line as needed to match your environment. The output directory (./dict-results) must not already exist.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh export -host localhost -port 8000 -username user \ -password password -mode local -output_file_path \ ./dict-results -collection_filter personnel \ -redaction "dict"
The redacted documents will be exported to ./dict-results. The //street and //country values will reflect values from the street and country dictionaries, respectively.
The redacted streets values will be the same each time you export the documents because they are redacted using mask-deterministic. The redacted country values will change each time you export the documents because they are redacted using mask-random.
For more details on using mlcp with Redaction, see Redacting Content During Export or Copy Operations in the mlcp User Guide.
Preparing to Run the Examples
Unless otherwise noted, the examples in this chapter are based on the same set of source documents. The source document set consists of two XML documents and two JSON documents with similar structure. They include some complex element and property values, such as child XML elements or JSON objects, and JSON arrays.
The documents are inserted into collections so they can easily be selected for redaction. The personnel collection contains all the samples. The xml-people collection includes only the XML samples. The json-people collection includes only the JSON samples.
When you complete the steps in this section, your Documents database will contain the following documents. The collection names are shown in parentheses after the URI in the following list.
/redact-ex/person1.xml(personnel,xml-people)/redact-ex/person2.xml(personnel,xml-people)/redact-ex/person3.json(personnel,json-people)/redact-ex/person4.json(personnel,json-people)
Follow these steps to install the sample documents:
- Navigate to Query Console in your browser. For example, go to
http://localhost:8000/qconsole. - Paste the following script into a new query tab in Query Console:
xquery version "1.0-ml"; xdmp:document-insert("/redact-ex/person1.xml", <person> <name>Little Bopeep</name> <alias>Peepers</alias> <alias>Bo</alias> <address> <street>100 Nursery Lane</street> <city>Hometown</city> <country>Neverland</country> </address> <ssn>123-45-6789</ssn> <phone>123-456-7890</phone> <email>bopeep@mothergoose.com</email> <ip>111.222.33.4</ip> <id>12-3456789</id> <birthdate>2015-01-15</birthdate> <anniversary>2017-04-18</anniversary> <balance>12.34</balance> </person>, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>personnel</collection> <collection>xml-people</collection> </collections> </options> ); xquery version "1.0-ml"; xdmp:document-insert("/redact-ex/person2.xml", <person> <name>Humpty Dumpty</name> <alias>Dumpy</alias> <address> <street>200 Nursery Lane</street> <city>Hometown</city> <country>Neverland</country> </address> <ssn>234.56.7890</ssn> <phone>234.567.8901</phone> <email>hdumpty@mothergoose.com</email> <ip>222.3.44.5</ip> <id>23-4567891</id> <birthdate>1965-06-12</birthdate> <anniversary>2012-11-09</anniversary> <balance>567.89</balance> </person>, <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>personnel</collection> <collection>xml-people</collection> </collections> </options> ); xquery version "1.0-ml"; xdmp:document-insert("/redact-ex/person3.json", xdmp:unquote(' { "name": "Georgie Porgie", "alias": ["George", "G.P."], "address": { "street": "300 Nursery Lane", "city": "Hometown", "country": "Neverland" }, "ssn": "345678901", "phone": "(345)678-9012", "email": "gp@mothergoose.com", "ip": "33.44.5.66", "id": "34-5678912", "birthdate": "2012-07-12", "anniversary": "2014-10-15", "balance": 12345.67 }'), <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>personnel</collection> <collection>json-people</collection> </collections> </options> ); xquery version "1.0-ml"; xdmp:document-insert("/redact-ex/person4.json", xdmp:unquote(' { "name": "Jack Sprat", "alias": ["Jacko","Beanpole"], "address": { "street": "400 Nursery Lane", "city": "Hometown", "country": "Neverland" }, "ssn": "456-78-9012", "phone": "4567890123", "email": "jack.sprat@mothergoose.com", "ip": "4.55.6.77", "id": "45-6789123", "birthdate": "1995-10-04", "anniversary": "2010-05-23", "balance": "90.12" }'), <options xmlns="xdmp:document-insert"> <permissions>{xdmp:default-permissions()}</permissions> <collections> <collection>personnel</collection> <collection>json-people</collection> </collections> </options> );
- Select Documents in the Database dropdown.
- Select XQuery in the Query Type dropdown.
- Click the Run button. The sample documents are installed in the Documents database.
- Optionally, click Explore next to the Database dropdown to explore the database and confirm insertion of the sample documents.