
Administrator's Guide — Chapter 23
Forests
This section describes forests in the MarkLogic Server, and includes the following sections:
- Understanding Forests
- Creating a Forest
- Making a Forest Delete-Only
- Making a Forest Read-Only
- Attaching and Detaching Forests Using the Forest Summary Page
- Making Backups of a Forest
- Restoring a Forest
- Rolling Back a Forest to a Point In Time
- Merging a Forest
- Clearing a Forest
- Disabling a Forest
- Deleting a Forest from a Host
- Rolling Back a Prepared XA Transaction Branch
This chapter describes how to use the Admin Interface to manage forests. For details on how to manage forests programmatically, see Creating and Configuring Forests and Databases and Database Maintenance Operations in the Scripting Administrative Tasks Guide.
Understanding Forests
A forest is a collection of XML, JSON, text, or binary documents. Forests are created on hosts and attached to databases to appear as a contiguous set of content for query purposes. A forest can only be attached to one database at a time. You cannot load data into a forest that is not attached to a database.
A forest contains in-memory and on-disk structures called stands. Each stand is composed of XML, JSON, binary, and/or text fragments, plus index information associated with the fragments. When fragmentation rules are in place, XML documents may span multiple stands. MarkLogic Server periodically merges multiple stands into a single stand to optimize performance. See Understanding and Controlling Database Merges for details on merges.
A forest also contains a separate on-disk Large Data Directory for storing large objects such as large binary documents. MarkLogic Server stores large objects separately to optimize memory usage, disk usage, and merge time. A small object is stored directly in a stand as a fragment. A large object is stored in a stand as a small reference fragment, with the full content stored in the Large Data Directory. The size threshold for storing objects in the Large Object Store and the location of the Large Object Store are configurable through the Admin Interface and Admin API. For details, see Working With Binary Documents in the Application Developer's Guide.
By default, the operations allowed on a forest are: read, insert, update, and delete. You can control which operations are allowed on a forest by setting the following update types:
| Update Type | Description |
|---|---|
All |
Read, insert, update, and delete operations are allowed on the forest. |
delete-only |
Read and delete operations are allowed on the forest, but insert and update operations are not allowed unless a forest ID is specified, in which case it results in the document being moved to another forest. If you do not specify a forest ID when updating a document in a delete-only forest, the update throws an exception. This update type is useful when you want to eliminate the overhead imposed by the merge operation, but still allow transactions to delete data from the forest. See Making a Forest Delete-Only for details. |
| Read operations are allowed on the forest, but insert, update, and delete operations are not allowed. A transaction attempting to make changes to fragments in the forest will throw an exception. This update type is useful when you want to put your forests on read-only media and allow them to be queried. See Making a Forest Read-Only for details. | |
| This type puts the forest in read-only mode without throwing exceptions on insert, update, or delete transactions, allowing the transactions to retry. This update type is useful when you want to temporarily quiesce a forest or to disable changes to the forest data when doing a flash backup of the forest. See Making a Forest Read-Only for details. |
To make the entire database read-only, set all of the forests in the database to read-only.
Creating a Forest
To create a new forest, complete the following procedure:
- Click the Forests icon in the left tree menu.
- Click the Create tab at the top right. The Create Forest page displays:
- Enter the name of your forest in the Forest Name textbox. Each forest name must be unique.
- Select the host on which you want the forest to be created.
- Enter the path to the Data Directory, which specifies where the forest data is stored. This directory should specify a location on the host's file system with sufficient capacity to store your data.
The name of the forest is used by the system as a directory name. Therefore, the forest name must be a legal directory name and cannot contain any of the following 9 characters:
\ * ? / : < > | ". Additionally, the name cannot begin or end with a space or a dot (.). MarkLogic recommends that you use an absolute path if you specify a data directory. If you do not specify an absolute path for the data directory, your forest will be created in the default data directory.The directory you specified can be an operating system mounted directory path, it can be an HDFS path, or it can be an S3 path. For details on using HDFS and S3 storage in MarkLogic, see Disk Storage Considerations in the Query Performance and Tuning Guide.
The Forests directory is either a fully-qualified pathname or is relative to the Forests directory, set at installation time based on the directory in which MarkLogic Server is installed. The following table shows the default location Forest directory for each platform:
Platform Program Directory Microsoft Windows C:\Program Files\MarkLogic\Data\ForestsRed Hat Linux /var/opt/MarkLogic/ForestsMac OS X ~/Library/Application\ Support/MarkLogic/Data/Forests - If you want to specify a different directory to store large objects (such as large binary documents), specify a Large Data Directory. If you do not specify a large data directory, the Data Directory is used. For details on binary file support, see Working With Binary Documents in the Application Developer's Guide.
- If you want to specify a high-performance directory to store the journals and as much of the forest data that will fit in this high-performance directory, specify a Fast Data Directory. For further details on disks and the Fast Data Directory, see Disk Storage Considerations in the Query Performance and Tuning Guide.
- If you want to restrict the types of updates allowed on the field, select the types of updates you want to allow for this forest in the Updates Allowed field. See Making a Forest Delete-Only for details.
The Read-Only update types described in Making a Forest Read-Only can be set in the Configure page of an existing forest.
- In the Availability field, select online to make the forest data available to tiered-storage or offline to make the data unavailable. For details on tiered storage, see Tiered Storage.
- In the Rebalancer Enable field, specify whether or not you want this forest to participate in the rebalancer process for the database to which this forest is to be attached. For details on the database rebalancer, see Database Rebalancing.
- If you have enabled the database rebalancer with a document assignment policy of Range, specify the range for this forest in the Range field. For details on the range policy, see Range Assignment Policy.
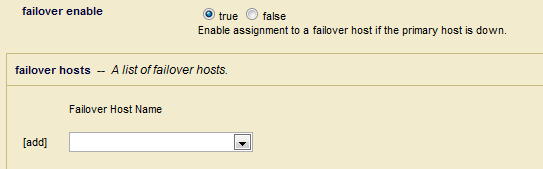
- In the Failover Enable field, specify whether or not to failover this forest to another host if the primary host goes down. For details on configuring failover on a forest, see Configuring Shared-Disk Failover for a Forest in the Scalability, Availability, and Failover Guide.
- Select the Failover Host from the Failover Host Name drop down menu:
- Click OK.


Creating a forest is a hot admin task; the changes take effect immediately. However, toggling between update types restarts the forest.
Making a Forest Delete-Only
You can configure a forest to only allow read and delete operations, disallowing inserts and updates to any documents stored in the forest. A delete-only forest is useful in cases where you have multiple forests in a database and you want to manage which forests change. To set a forest to only allow delete operations (and disallow inserts and updates), navigate to the configuration page for the forest you want specify as delete-only and set the updates allowed field to delete-only.
When a forest is set to delete-only, updates to documents in a delete-only forest that do not specify a forest ID will throw an exception. Updates to documents in a delete-only forest that specify one or more forest IDs of other forests in the database will result in the documents moving to one of those other forests. When a document moves forests, the old version of the document will be marked as deleted, and will be removed from the forest during the next merge.
To specify an update that will move a document in a delete-only forest to an updateable forest, you must specify the forest ID of at least one forest in which updates are allowed. One technique to accomplish this is to always specify all of the forest IDs, as in the following xdmp:document-insert example which lists all of the forests in the database for the $forest-ids parameter:
xdmp:document-insert($uri, $node, (), (), 0, xdmp:database-forests(xdmp:database()) )
You can only move a document from a delete-only forest to a forest that allows updates using an API that takes forest IDs, and then by explicitly setting the forest IDs to include one or more forests that allow updates. The node-level update built-in functions (xdmp:node-replace, xdmp:node-insert-child, and so on) do not have a forest IDs parameter and therefore do not support moving documents.
Under normal operating circumstances, you likely will not need to set a forest to be delete-only. Additionally, even if the reindexer is enabled at the database level, documents in a forest that is set to delete-only will not be reindexed.
There are cases where delete-only forests are useful, however. One of the use cases for delete-only forests is if you have multiple forests and you want to control when some forests are merging. The best way to control merges in a forest is to not insert any new content in the forest. In this scenario, you can set some of the forests to be delete-only, and then those forests will not merge during that time (unless you manually specify a merge, either with the xdmp:merge API or by clicking the Merge button in the Admin Interface). After a while, you can rotate which forests are delete-only. For example, if you have four forests, you can make two of them delete-only for one day, and then make the other two delete-only the next day, switching the first two forest back to allowing updates. This approach will only have two forests being updated (and periodically merging) at a time, thus needing less disk space for merging. For more details about merges, see Understanding and Controlling Database Merges.
Making a Forest Read-Only
You can configure an existing forest to only allow reads and to disallow inserts, updates and deletes to any documents stored in the forest.

MarkLogic Server supports two read-only forest settings:
read-only-- When this update type is set, update transactions on the forest are immediately aborted.flash-backup-- When this update type is set, update transactions on the forest are retried until either the update type is reset or the Default Time Limit set for the App Server is reached.Only existing forests can be set to
read-onlyorflash-backup. You cannot create a new forest with these settings.
A read-only forest is useful if you want to put your forests on read-only media and allow them to be queried. Another use of read-only is to control disk space. For example, in a multi-forest database, it might be useful to be able to mark one or more forests as read-only as they reach disk space limits.
One use for flash-backup is to prevent updates to the forest during a flash backup operation, which is a very fast backup that can be done on some file systems. You can set the flash-backup update type to temporarily put the forest in read-only mode for the duration of a flash backup and then reset the update type when the backup has completed. Transactions attempting to make changes to the forest during the backup period are retried.
Toggling between read-only or flash-backup and other forest update types triggers a forest restart. This activity is visible in the log file.
When the read-only or flash-backup update type is set, the forest will have the following characteristics:
- If a database has at least one updateable forest, and an insert, update or delete without a place key is requested, it will choose one of the updateable forests to perform the operation.
- No merges are allowed on the forest. Attempts to explicitly merge such forests do nothing.
- No re-indexing/re-fragmenting is allowed on the forest.
- You cannot upgrade from the forest. An attempt to upgrade will return an error.
- If a forest is set to read-only or flash-backup, an insert, update, or delete transaction will either generate an exception (in the case of
read-only) or retried later (in the case offlash-backup). - You cannot clear, restore, or fully delete the forest. However, you can delete the forest configuration, as described in Deleting a Forest from a Host.
- Backups are permitted on the forests. However, they will not modify the last backup time in the forest label. Consequently, the last backup time in the forest will denote the last time the forest was backed up when it wasn't read-only or flash-backup.
- If the database index settings are changed and index detection is set to 'automatic', then the forests will work, but the indexes won't be picked up. If index detection is set to 'none', you will get wrong results.
- You can enable failover on a read-only and flash-backup forest.
Attaching and Detaching Forests Using the Forest Summary Page
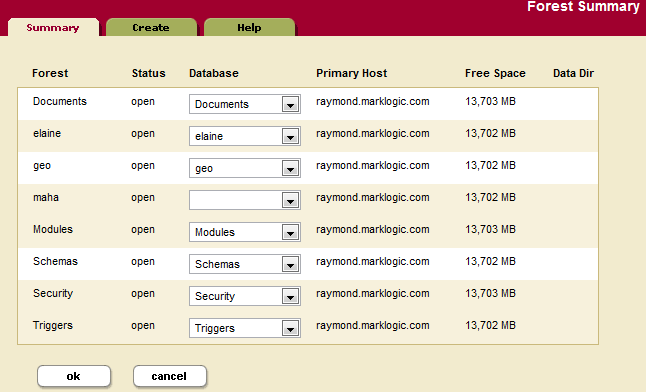
The Forest Summary page lists all of the forests in the cluster, along with various information about each forest such as its status, which host is the primary host, and amount of free space for each forest. It also lists which database each forest is attached to, and allows you to attach and/or detach forests from databases. Alternately, you can use the Database Forest Configuration page to attach and detach a forest, as described in Attaching and/or Detaching Forests to/from a Database.
Perform the following steps using the Admin Interface to attach or detach one or more forests to or from a database:
- Click the Forests icon on the left tree menu. The Forest Summary page appears.
- For each forest whose database assignment you want to change, select the name of the new database assignment.
If you change a database assignment from one database to another, it will detach the forest from the previous setting and attach it to the new setting. Be sure that is what you intend to do. Also, if you detach from one database and attach to another database with different index settings, the forest will begin reindexing if
reindexer enableis set totrue. - After you have made your selections, click OK to save the forest assignment changes.
The forests you attached or detached are now reflected in the database configuration. Attaching and detaching a forest to a database are hot admin tasks.
Making Backups of a Forest
MarkLogic Server backs up forest data by transactionally creating an image copy of a specified forest. You can back up data at the granularity of a forest or of a database. Use the Admin Interface to back up a forest.
Forest-level backups only back up the data in a forest, and are not guaranteed to have a consistent database state to restore. The data in the forest is consistent, but other parts of the database (other forests, the schema database, and so on) might be different when you restore the data. For a guaranteed consistent backup, perform a complete database backup For information on backing up a database, see Backing Up and Restoring a Database.
Forest backups do not provide a journal archive feature, as described for database backups in Backing Up and Restoring a Database. However, you can manually invoke the xdmp:start-journal-archiving function during a forest backup to make use of journal archiving with your forest backups.
This section describes the forest backup procedures, and includes the following parts:
Backing Up a Forest
To initiate a forest backup using the Admin Interface, complete the following procedure:
- Click the Forests icon on the left tree menu.
- Decide which forest to back up.
- Click the icon for this forest name.
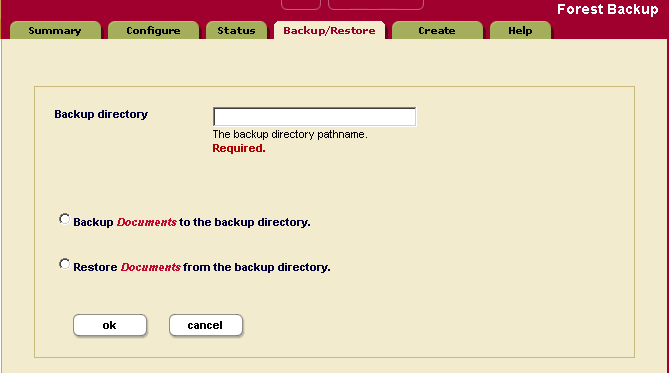
- Click the Backup/Restore tab at the top right. The Forest Backup screen appears.
- Enter the name of the directory in which you want the backup copy of the forest. You must provide an absolute path. Each directory must be unique for each forest.
The software deletes all the files in this directory before writing the new backup. To retain multiple generations of backup, specify a different backup directory for each backup.
- Select Backup.
- Click OK.
- A confirmation message appears. Click OK again to confirm the backup.
Your data in the selected forest is now backed up to the specified directory. Backing up your data is a hot admin task; the changes take effect immediately.
When performing backups on the Windows platform, ensure that no users have the Forests or Data directories (or any subdirectories within them) open while the backup is being made.
Scheduling a Forest Backup
You can schedule forest backups to periodically back up a forest. You can schedule backups to occur daily, weekly, monthly, or you can schedule a one-time backup. You can create as many scheduled backups as you want. To create a scheduled backup, perform the following steps using the Admin Interface:
- Click the Forests icon on the left tree menu.
- Select the forest for which you want to schedule a backup, either from the tree menu or from the Forest Summary page. The Forest Configuration page appears.
- Click the Scheduled Backup link in the tree menu for the forest. The Scheduled Backup Configuration page appears.
- On the Scheduled Backup Configuration page, you can delete any existing scheduled backups if you no longer need them.
- Click the Create tab. The Create Scheduled Backups page appears
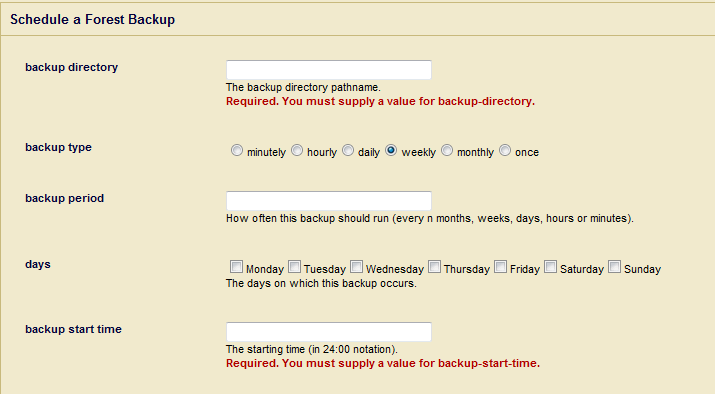
- Enter the absolute path to the backup directory. The backup directory must have permissions such that the MarkLogic Server process can read and write to it.
- Choose a scheduled or one-time for the backup type:
- For minutely, enter how many minutes between each backup.
- For hourly, enter how many hours between each backup. The Backup Minute setting specifies how many minutes after the hour the backup is to start. Note that the Backup Minute setting does not add to the interval.
- For daily, enter how many days between each backup and the time of day.
- For weekly, enter how many weeks between each backup, check one or more days of the week, and the time of day for the backup to start.
- For monthly, enter how many months between each backup, select one day of the month (1-31), and the time of day for the backup to start.
- For one-time, enter the backup start date in MM/DD/YYYY notation (for example, 07/29/2009 for July 29, 2009) and time in 24:00 notation.
- Enter the time of day to start the backup.
- Click OK to create the scheduled backup.
The backups will automatically start according to the specified schedule.
Restoring a Forest
You can restore a forest from a backup made earlier either using the Admin Interface. Backups are restored at the forest granularity only.
To restore a forest from a backup made previously, complete the following procedure:
- Click the Forests icon on the left tree menu.
- Decide which forest to restore.
- Click the icon for this forest name.
- Click the Backup/Restore tab on the top right.
- Enter the name of the directory that contains the backup copy of the forest.
- Select Restore.
- Click OK.
- Confirm that you want to restore data from this backup directory and click OK.
Restoring data from your backup is a hot admin task; the changes take effect immediately.
When performing restores on the Windows platform, ensure that no users have the Forests or Data directories (or any subdirectories within them) open while the restore process is executing.
Rolling Back a Forest to a Point In Time
You can use the xdmp:forest-rollback function to roll the state of one or more forests back to a specified system timestamp. To roll forest(s) back to an earlier timestamp, you must first set the merge timestamp to keep deleted fragments from that specified timestamp. For details on rolling back a forest, including the procedure to perform a rollback, see Rolling Back a Forest to a Particular Timestamp in the Application Developer's Guide and the xdmp:forest-rollback API documentation in the MarkLogic XQuery and XSLT Function Reference.
Merging a Forest
You can merge the forest data using the Admin Interface. As described in Understanding and Controlling Database Merges, merging a forest improves performance and is periodically done automatically in the background by MarkLogic Server. The Merge button allows you to explicitly merge the data for this forest.
To explicitly merge the forest, complete the following procedure:
- Click the Forests icon on the left tree menu.
- Decide which forest you want to merge.
- Click the forest name, either on the tree menu or the summary page.
- Click the Merge button on the Forest Configuration page.
- Confirm that you want to merge the forest data and click OK.
Merging data in a forest is a hot admin task; the changes take effect immediately.
Clearing a Forest
You can clear the document data from a forest using the Admin Interface. Clearing a forest removes all fragments from the forest, but does not remove its configuration information.
To clear all data from a forest, complete the following procedure:
- Click the Forests icon on the left tree menu.
- Decide which forest you want to clear.
- Click the forest name, either on the tree menu or the summary page.
- Click the Clear button on the Forest Configuration page.
- Confirm that you want to clear the document data from this forest and click OK.
Clearing data in a forest is a hot admin task; the changes take effect immediately.
Disabling a Forest
You can disable a forest using the Admin Interface. Disabling a forest unmounts the forest from the database and clears all memory caches for all the forests in the database. The database remains unavailable for any query operations while any of its forests are disabled.
Disabling a forest does not delete the configuration or document data. The forest can later be re-enabled by clicking Enable.
Deleting a Forest from a Host
You can use the Admin Interface to delete a forest. There are two levels of forest deletion:
- Delete configuration only, which removes the forest configuration information, but preserves the document data.
- Full Delete, which completely removes the document data and the configuration information for the forest.
The forest cannot be deleted if it is still attached to a database. Also, you can delete the configuration information on a Read-Only or Flash-Backup forest, but you cannot do a Full Delete on such forests.
To delete a forest, complete the following procedure:
- Click the Forests icon on the left tree menu.
- Decide which forest to delete.
- Click the forest name, either on the tree menu or the summary page.
- Click the Delete button on the Forest Configuration page.
- Select either Configuration Only to delete only the configuration information, or Full Delete to delete the configuration information and the document data.
- Click OK.
Deleting a forest is a hot task; the changes take effect immediately.
Rolling Back a Prepared XA Transaction Branch
MarkLogic Server transactions may participate in global, distributed XA transactions. The XA Transaction Manager usually manages the life cycle of transactions participating in an XA transaction, independent of MarkLogic Server. However, it may be necessary to manually rollback the MarkLogic Server portion of a global transaction (called a branch) if the Transaction Manager is unreachable for a long time. For details, see Heuristically Completing a Stalled Transaction in the XCC Developer's Guide.
Heuristic completion bypasses the Transaction Manager and the Two Phase Commit process, so it can lead to data integrity problems. Use heuristic completion only as a last resort.
Before the MarkLogic Server branch of an XA transaction is prepared, the transaction may be rolled back from the host status page of the host evaluating the transaction. See Rolling Back a Transaction.
Once the MarkLogic Server branch of an XA transaction enters the prepared state, the transaction appears only on the forest status page of the coordinating forest. To find the coordinating forest, examine the Forest Status page for each forest belonging to the participating database. The transaction will only appear on the status page for the coordinating forest.
To heuristically rollback the MarkLogic Server portion of an XA transaction using the Admin Interface, follow these steps:
- Open the Admin Interface in your browser by navigating to
http://yourhost:8001. - Click Forests on the left tree menu. The forest summary page appears.
- Click the name of the coordinating forest. The Forest Status page appears.
- Locate the target transaction in the transaction list. If you do not see a transaction list on the status page, then this forest is not the coordinating forest for any prepared transactions.
- Click
[rollback]on the right side of the target transaction status to initiate the rollback. The rollback confirmation dialog appears. For example: - Click OK to confirm the rollback. The rollback completion page appears.
- Click OK to return to the Forest Status page.

The rolled back transaction enters the remember abort state, indicating MarkLogic Server should remember that the local transaction was aborted until the Transaction Manager re-synchronizes the global transaction. Once re-synchronization occurs, the transaction no longer appears in the forest status. For details, see Heuristically Completing a MarkLogic Server Transaction in the XCC Developer's Guide.
You may use the Forest Status page to force MarkLogic Server to forget the rollback without waiting for the Transaction Manager. This is not recommended as it leads to errors and, potentially, a loss of data integrity when the Transaction Manager attempts to re-synchronize the global transaction. If forgetting the rollback is necessary, use the [forget] link in the transaction list on the Forest Status:
