Matches for cat:guide (cat:guide/search-dev) have been highlighted.


MarkLogic Server 11.0 Product DocumentationSearch Developer's Guide — Chapter 7
Creating JavaScript Search Applications
This chapter describes how to add search operations and lexicon analysis to your Server-Side JavaScript modules and extensions using the JSearch library module. This chapter includes the following sections:
- JSearch Introduction
- Searching Documents
- Scoping Operations by Collection
- Creating a cts.query
- Including Facets in Search Results
- Controlling the Ordering of Results
- Returning a Result Subset
- Including Snippets of Matching Content in Search Results
- Extracting Portions of Each Matched Document
- Using Options to Control a Query
- Transforming Results with Map and Reduce
- Querying Lexicons and Range Indexes
- Grouping Values and Facets Into Buckets
- Preparing to Run the Examples
This chapter provides background, design patterns, and examples of the JSearch library module. For the function signatures and descriptions, see the JSearch documentation under JavaScript Library Modules in the MarkLogic Server-Side JavaScript Function Reference.
You can also use the Node.js Client API to integrate search operations and lexicon analysis into your client-side code. For details, see the Node.js Application Developer's Guide.
JSearch Introduction
This section provides a high level overview of the features and design patterns of the JSearch library. This section covers the following topics:
- JSearch Feature Summary
- Top Level Function Summary
- Query Design Pattern
- How JSearch Relates to Other MarkLogic Search APIs
- Running the Examples in This Chapter
JSearch Feature Summary
You can use the JSearch library to perform most of the query operations available through the cts built-in functions and the Search API, including the following:
Top Level Function Summary
Libraries can be imported as JavaScript MJS modules. This is the preferred import method.
The following table provides an overview of the key top level JSearch methods. All these methods are effectively query builders. You can chain additional methods to them to refine and produce results. For details, see Query Design Pattern.
The API also includes helper functions, not listed here, for constructing complex inputs such as lexicon references, facet definitions, and heatmap definitions.
For a complete list of functions, see the MarkLogic Server-Side JavaScript Function Reference.
| JSearch Method | Description |
|---|---|
collections |
Creates a jsearch object that implicitly scopes all operations to one or more collections. For details, see Scoping Operations by Collection. |
documents |
Search documents and document properties. You can tailor the results to include data such as matching documents, document projections, and snippets, as well as search metadata such as relevance score. For details, see Document Search Basics. |
values |
Query the values in a lexicon or range index, optionally computing one or more aggregates over the values. For details, see Querying the Values in a Lexicon or Index. |
tuples |
Find n-way value co-occurrences in lexicons and range indexes, optionally computing one or more aggregates over the tuples. For details, see Finding Value Co-Occurrences in Lexicons and Indexes. |
words |
Query the values in a word lexicon. For details, see Querying Values in a Word Lexicon. |
facets |
Generate facets from a value lexicon. The results can optionally include documents as well as facets. For details, see Including Facets in Search Results. |
documentSelect |
Generate snippets, sparse document projections, and/or a set of similar documents from an arbitrary set of documents, such as the result of calling cts.search or fn.doc. |
Query Design Pattern
The top level JSearch operations, such as document search, lexicon value queries, and lexicon tuple queries use a pipeline pattern for defining the query and customizing results. The pipeline mirrors steps MarkLogic performs when evaluating a query. The pipeline stages vary by operation, but can include steps such as query criteria definition, result ordering, and result transformations.
Building and evaluating a query consists of the following steps:
- Select the resource you want to work with, such as documents, lexicon values, or tuples.
- Add the pipeline stages that define your query and desired result set, such as query criteria, sort order, and transformations. All pipeline stages are optional.
- Optionally, specify advanced options, such as a quality weight. The available options depend on the resource selected in Step 1.
- Perform the operation and get results.
If you omit all the pipeline stages in Step 2, then you retrieve the default slice from all selected resources. For example, all the documents in the database or all values or tuples in the selected lexicon(s).
Consider the case of a document search. The following example (1) selects documents as the resource; (2) defines the query and customizes the result using the where, orderBy, slice, and map pipeline stages; (3) specifies the returnQueryPlan option using the withOptions method; and then (4) evaluates the assembled query and gets results.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() // 1. resource selection .where(cts.parse('title:california', // 2. query defn pipeline {title: cts.jsonPropertyReference('title')})) .orderBy('price') // . .slice(0,5) // . .map({snippet: true}) // . .withOptions({returnQueryPlan: true}) // 3. additional options .result() // 4. query evaluation
The query definition pipeline in this example uses the following stages:
For comparsion, below is a JSearch values query. Observe that it follows the same pattern. In this case, the selected resource is the values in a range index on the price JSON property or XML element.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') // 1. resource selection .where(cts.parse('by:"mark twain"', // 2. query defn pipeline {by: cts.jsonPropertyReference('author')})) .orderBy('item','descending') // . .slice(0,20) // . .withOptions({qualityWeight: 2}) // 3. additional options .result() // 4. query evaluation
The query definition pipeline in this values query example uses the following stages:
The query definition pipeline is realized through a call chain, as shown in the examples. All pipeline stages are optional, but the order is fixed. The table below summarizes the pipeline stages available for querying each resource type. The stage names are also JSearch method names. Note that two pipelines are available for values and tuples queries: one for retrieving values or tuples from lexicons and another for computing aggregates over the values or tuples.
Results can be returned as values (typically, an array) or as an Iterable. The default is values. For example, the default output from a document search has the following form:
{ results: [resultItems], estimate: totalEstimatedMatches }
However, if you request an Iterable object by passing 'iterator' to the result method, then you get the following:
{ results: iterableOverResultItems, estimate: totalEstimatedMatches }
When you request iterable results by calling results('iterator') on the various JSearch APIs, you receive a Sequence in some contexts and a Generator in others. For more information on these constructs, see Sequence in the JavaScript Reference Guide and the definition of Generator in the JavaScript standard:
http://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Generator
How JSearch Relates to Other MarkLogic Search APIs
The JSearch library module is primarily designed for JavaScript developers writing MarkLogic applications that initiate document searches and lexicon queries on the server. The same capabilities are available through other server-side interfaces, such as the cts built-in functions and the Search API, but JSearch offers the following advantages for a JavaScript developer:
- All input and output is in the form of JavaScript objects.
- A fluent call chain pattern that is natural for JavaScript.
- Powerful convenience methods for operations such as snippet generation and faceting.
In addition, the design patterns, query styles, and configuration options are similar to those used by the Node.js Client API. Thus, developers creating multi-tier JavaScript applications will find it easy to move between client (or middle) and server tiers when using JSearch. To learn more about the Node.js Client API, see the Node.js Application Developer's Guide.
You can use the JSearch API in conjunction with the cts built-in functions, in many contexts. For example:
- You can use the
ctsquery constructors to create input queries usable with a JSearch-based document search. For details, see Using cts.query Constructors. - You can construct index references for a JSearch values query using the
cts.referenceconstructors. - You can use the jsearch.documentSelect method to generate snippets or sparse document projections from the results returned by cts.search.
- Many JSearch operations enable you to pass advanced options to the underlying cts layer through the
withOptionsmethod. For details, see Using Options to Control a Query.
Running the Examples in This Chapter
All the examples in this chapter can be run using Query Console. To configure the sample database and load the sample documents, see the instructions in Preparing to Run the Examples.
For more information about Query Console, see the Query Console User Guide or the Query Console help.
Scoping Operations by Collection
If your application primarily works with documents in one or more collections, you can use the collections method to create a top level jsearch object that implicitly limits operations by collection.
For example, suppose your application is operating on documents in a collection with the URI classics. Including a cts.collectionQuery('classics') in all your query operations can be inconvenient. Instead, use the collections method to create a scoped search object through which you can perform all JSearch operations, as shown below:
import jsearch from '/MarkLogic/jsearch.mjs'; const classics = jsearch.collections('classics'); // implicitly limit results to matches in the 'classics' collection classics.documents() .where(cts.parse('california')) .result()
You can use the resulting object everywhere you can use the object returned by the require that brings the JSearch library into scope.
You can scope to one or many collections. When you specify multiple collections, the implicit collection query matches documents in any of the collections. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; // Work with documents in either the "novels" or "poems" collection const books = jsearch.collections(['novels','poems']);
The collection scope is ignored on operations for which it makes no sense, such as when constructing a lexicon reference using a helper function like jsearch.elementLexicon. On operations where scope matters, such as documents, values, and words, the implicit cts.collectionQuery is added to a top-level cts.andQuery on every where clause.
For more details, see jsearch.collections .
Searching Documents
To perform a document search, use the jsearch.documents method and the design pattern described in Query Design Pattern.
Document Search Basics
This section outlines how to perform a document search. The search features touched on here are discussed in more detail in the remainder of this chapter.
Bring the JSearch library module functions into scope by including a import statement similar to the following in your code.
import jsearch from '/MarkLogic/jsearch.mjs';
A document search begins by selecting documents as the resource you want to work with by calling the top level documents method. You can invoke this method either on the object created by the require statement, or on a collection-scoped instantiation.
// Work with all documents jsearch.documents().where(cts.parse('cat')).result() ... // Work with documents in collections 'coll1' and 'coll2' const myColls = jsearch.collections([coll1,coll2]); myColls.documents().where(cts.parse('cat')).result() ...
To learn more about working with collections, see Scoping Operations by Collection
Build and execute your search following the pattern described in Query Design Pattern. The following table maps the applicable JSearch methods to the steps in the design pattern. Note that all the pipeline stages in Step 2 are optional, but you must use them in the order shown. For an example, see Example: Basic Document Search.
| Pattern Step | Method(s) | Notes | |
|---|---|---|---|
| 1 | Select resource | documents |
Required. Select documents as the resource to work with. For details, see jsearch.documents in the MarkLogic Server-Side JavaScript Function Reference. |
| 2 | Add a query definition and result set pipeline | where |
Optional. Define your query. Accepts one or more cts.query objects as input. If you pass in more than one cts.query object, the queries are implicitly AND'd together. You can create a cts.query from a QBE, query text, cts.query constructors, or any other technique that creates a cts.query. For details, see Creating a cts.query and DocumentsSearch.where in the MarkLogic Server-Side JavaScript Function Reference. |
orderBy |
Optional. Specify sort keys and/or sorting direction. For details, see Controlling the Ordering of Results and DocumentsSearch.orderBy in the MarkLogic Server-Side JavaScript Function Reference. | ||
filter |
Optional. Specify whether or not to filter the search. By default, the search is unfiltered. Filtered search is always accurate, but can take longer. For details, see DocumentsSearch.filter and Fast Pagination and Unfiltered Searches in the Query Performance and Tuning Guide. | ||
slice |
Optional. Select a subset of documents from the result set. The default slice is the first 10 documents. Retrieving results incrementally is best practice for most applications.For details, see Returning a Result Subset and DocumentsSearch.slice in the MarkLogic Server-Side JavaScript Function Reference. | ||
map | reduce |
Optional. Configure snippeting, extraction of specific pieces of matched documents, or custom transformations. You cannot use map and reduce together. For details, see Transforming Results with Map and Reduce, DocumentsSearch.map, and DocumentsSearch.reduce. |
||
| 3 | Add advanced options | withOptions |
Optional. Specify additional, advanced search options that customize the search behavior. For details, see Using Options to Control a Query and DocumentsSearch.withOptions in the MarkLogic Server-Side JavaScript Function Reference. |
| 4 | Evaluate the query and get results | result |
Required. Execute the search and receive your results, optionally specifying whether to receive the results as a value or an Iterable. The default is a value (typically an array). |
Example: Basic Document Search
The following is the most minimal JSearch document search, but it has the broadest scope in that it returns the default slice of all documents in the database.
jsearch.documents().result()
More typically, your search will include at least a where clause that defines the desired set of results. The where method accepts one or more cts.query objects as input and defines your search criteria. For example, the following query matches documents where the author property has the value Mark Twain:
jsearch.documents() .where(jsearch.byExample({author: 'Mark Twain'})) .result()
You can customize the results by adding orderBy, slice, map, and reduce stages to the operation. For example, you can suppress the search metadata, include snippets instead of (or in addition to) the full documents, extract just a portion of each matching document, or apply a custom content transformation. These and other features are covered elsewhere in this chapter.
The following example matches documents that contain an author JSON property with the value Mark Twain, price property with a value less than10, and that are in the /books/ directory. Notice that the search criteria are expressed in several ways; for details, see Creating a cts.query. The search results contain at most the first 3 matching documents (slice), ordered by the value of the title property (orderBy).
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where([ jsearch.byExample({author: 'Mark Twain'}), cts.parse('price LT 10', {price: cts.jsonPropertyReference('price')}), cts.directoryQuery('/books/')]) .orderBy('title') .slice(0,3) .result()
This query produces output similar to the following when run against the documents and database configuration described in Preparing to Run the Examples.
{ "results": [ { "index": 0, "uri": "/books/twain3.json", "score": 16384, "confidence": 0.43934014439583, "fitness": 0.69645345211029, "document": { "title": "Adventures of Huckleberry Finn", "author": "Mark Twain", "edition": { "format": "paperback", "price": 8 }, "synopsis": "The adventures of Huck, a boy ..." } }, { "index": 1, "uri": "/books/twain1.json", "score": 16384, "confidence": 0.43934014439583, "fitness": 0.69645345211029, "document": { "title": "Adventures of Tom Sawyer", "author": "Mark Twain", "edition": { "format": "paperback", "price": 9 }, "synopsis": "Tales of mischief and adventure ..." } } ], "estimate": 2 }
By default, the results include search metadata (uri, score, confidence, fitness, etc.) and the full content of each matched document.
You can also choose whether to work with the results embedded in the return value as a value or an Iterable. For example, by default the results are returned in an array:
import jsearch from '/MarkLogic/jsearch.mjs'; const response = jsearch.documents() .where(jsearch.byExample({author: 'Mark Twain'})) .result(); // or .result('value') response.results.forEach(function (result) { // work with the result object });
By passing iterator as the input to the result method, you can work with the results as an Iterable instead:
import jsearch from '/MarkLogic/jsearch.mjs'; const response = jsearch.documents() .where(jsearch.byExample({author: 'Mark Twain'})) .result('iterator'); for (const result of response.results) { // work with the result object }
Creating a cts.query
This section describes the most common ways of creating a cts.query for defining query criteria. Most JSearch operations include a where clause that accepts one or more cts.query objects as input. For example, the documents, values, and tuples methods all return an object with a where method for defining query criteria.
This section covers the following topics:
- Using byExample to Create a Query
- Using Query Text to Create a cts.query
- Using cts.query Constructors
Using byExample to Create a Query
The jsearch.byExample method enables you to build queries by modeling the structure of the content you want to match. It enables you to express your search in terms of documents that look like this.
This section covers the following topics:
- Introduction to byExample
- Example: Building a Query With byExample
- Differences Between byExample and QBE
Introduction to byExample
JSearch.byExample() and search:by-example() take a query represented as an XML element for XML or as a JSON node or map for JSON and return a cts:query that can be used in any API that takes a cts:query including cts:search(), cts:uris() and the Optic where clause:
jsearch.byExample({author: 'Mark Twain'})
Search criteria like the one immediately above are implicitly value queries with exact match semantics in QBE.
The XQuery equivalent to the preceding JavaScript call is:
import module namespace q = "http://marklogic.com/appservices/querybyexample" at "/MarkLogic/appservices/search/qbe.xqy"; q:by-example(<author>Mark Twain</author>)
cts:element-value-query(fn:QName("","author"), "Mark Twain", ...)
Search criteria like the jsearch.byExample() above are implicitly value queries with exact match semantics in QBE, so the query constructed with byExample above is equivalent to the following cts.query constructor call:
// equivalent cts.query constructor call: cts.jsonPropertyValueQuery( 'author', 'Mark Twain', ['case-sensitive','diacritic-sensitive', 'punctuation-sensitive','whitespace-sensitive', 'unstemmed','unwildcarded','lang=en'], 1)
QBE provides much of the expressive power of cts.query constructors. For example, you can use QBE keywords in your criteria to construct value, word, and range queries, as well as compose compound queries with logical operators. For a more complete example see Example: Building a Query With byExample. For details, see Searching Using Query By Example.
The JSearch byExample method does not use the $response portion of a QBE. This and other QBE features, such as result customization, are provided through other JSearch interfaces. For details, see Differences Between byExample and QBE.
The input to jsearch.byExample can be a JavaScript object, XML node, or JSON node. In all cases, the object or node can express either a complete QBE, as described in Searching Using Query By Example, or just the contents of the query portion of a QBE (the search criteria). For convenience, you can also pass in a document that encapsulates an XML or JSON node that meets the preceding requirements. You must use the complete QBE form of input if you need to specify the format or validate QBE flags.
For example, all the following are valid inputs to jsearch.byExample:
By default, a query expressed as JavaScript object or JSON node will match JSON documents and a query expressed as an XML node will match XML documents. You can use the format QBE flag to override this behavior; for details, see Scoping a Search by Document Type.
You must use the XML node (or a corresponding document node wrapper) form to search XML documents that use namespaces as there is no way to define namespaces in the JavaScript/JSON QBE format.
Example: Building a Query With byExample
This example assumes the database contains documents with the following structure:
{ "title": "Tom Sawyer", "author" : "Mark Twain", "edition": { "format": "paperback", "price" : 9.99 } }
To add similar data to your database, see Preparing to Run the Examples.
The following query uses most of the expressive power of QBE and matches the above document. The top level properties in the query object passed to byExample are implicitly AND'd together, so all these conditions must be met by matching documents. Since the query includes range queries on a price property, the database configuration must include an element range index with local name price and type float.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({ "title": { "$value": "adventures of tom sawyer", "$exact": false }, "$near": [ { "author": { "$word": "mark" } }, { "author": { "$word": "twain" } } ], "$distance": 2, "edition": { "$or" : [ { "format": "paperback" }, { "format": "hardback" } ] }, "$and": [ {"price": { "$lt": 10.00 }}, {"price": { "$ge": 8.00 }} ] })) .result()
If you run this query using the documents created by Preparing to Run the Examples, the above query should match one document.
The following table explains the requirements expressed by each component of the query. Each of the subquery types used in this example is explored in more detail in Understanding QBE Sub-Query Types.
If you examine the output from byExample, you can see that the generated cts.query is complicated and much more difficult to express than the QBE syntax.
For more details, see Searching Using Query By Example.
Differences Between byExample and QBE
The byExample method of JSearch does not use all parts of a QBE. A full QBE encapsulates search criteria, results refinement, and other options. However, JSearch supports some QBE features through other interfaces like filter and map. If you pass a full QBE to byExample, only the $query, $format, and $validate properties are used. Similarly, if you use an XML QBE, only the query, format, and validate elements are used.
When reviewing the QBE documentation or converting QBE queries from client-side code, keep the following differences and restrictions in mind:
- Use the JSearch
filtermethod instead of the QBE$filteredflag to enable filtered search. - Your database configuration must include a range index definition for any range queries. There is no equivalent to using
$filteredto avoid or defer index creation. - Use the JSearch
withOptionsmethod instead of the QBE$scoreflag to select a scoring algorithm. - You cannot use the QBE options
$constraintor$datatypein your queries. - Use the JSearch
mapmethod instead of the QBE$responseproperty to customize results.
The following table contains a QBE on the left that uses several features affected by the differences listed above, including $filtered, $score, and $response. The JSearch example on the right illustrates how to achieve the same result by combining byExample with other JSearch features.
Using Query Text to Create a cts.query
Use cts.parse to create a cts.query from query text such as cat AND dog that a user might enter in a search text box. The cts.parse grammar is similar to the Search API default string query grammar. For grammar details, see Creating a Query From Search Text With cts:parse.
For example, the following code matches documents that contain the word steinbeck and the word california, anywhere.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.parse('steinbeck AND california')) .result()
You can use the cts.parse grammar to generate complex queries. The following table illustrates some simple query text strings with their equivalent cts.query constructor calls.
| Query Text | Equivalent cts.query | Explanation |
|---|---|---|
(tom or huck)
NEAR becky |
cts.nearQuery( [ cts.orQuery([ cts.wordQuery("tom"), cts.wordQuery("huck")]), cts.wordQuery("becky") ]) |
at least one of the terms tom or huck within 10 terms (the default distance for cts.nearQuery) of the term becky |
tom NEAR/30 huck |
cts.nearQuery([ cts.wordQuery("tom"), cts.wordQuery("huck")], 30) |
the term tom within 30 terms of the term huck |
huck -tom |
cts.andQuery([ cts.wordQuery("huck"), cts.notQuery( cts.wordQuery("tom")) ]) |
the term huck where there is no occurrence of tom |
You can also bind a keyword to a query-generating function that the parser uses to generate a sub-query when the keyword appears in a query expression. This feature is similar to using pre-defined constraint names in Search API string queries. You can use a built-in function, such as cts.jsonPropertyReference, or supply a custom function that returns a cts.query.
For example, you can use a binding to cause the query text by:twain to generate a query that matches the word twain only when it appears in the value of the author JSON property. (In the cts.parse grammar, the colon (:) operator signifies a word query by default.)
import jsearch from '/MarkLogic/jsearch.mjs'; // bind 'by' to the JSON property 'author' const queryBinding = { by: cts.jsonPropertyReference('author') }; // Perform a search using the bound name in a word query expression jsearch.documents() .where(cts.parse('by:twain', queryBinding)) .result();
You can also define a custom binding function rather than using a pre-defined function such as cts.jsonPropertyReference. For more details and examples, see Creating a Query From Search Text With cts:parse.
Using cts.query Constructors
You can build a cts.query by calling one or more cts.query constructor built-in functions such as cts.andQuery or cts.jsonPropertyRangeQuery. The constructors enable you to compose complex and powerful queries.
For example, the following code uses a cts.query constructor built-in function to create a word query that matches documents containing the phrase mark twain in the value of the author JSON property.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where( cts.jsonPropertyWordQuery('author', 'mark twain')) .result();
Query constructor built-in functions can be either leaf constructors, such as the one in the above example, or composable constructors. A leaf constructor does not accept cts.query's as input, while a composable constructor does. You can use composable constructors to build up powerful, complex queries.
For example, the following call creates a query that matches documents in the database directory /books that contain the phrase huck or the phrase tom in the title property and either have a format property with the value paperback or a price property with a value that is less than 10.
cts.andQuery([ cts.directoryQuery('/books/', 'infinity'), cts.jsonPropertyWordQuery('title', ['huck','tom']), cts.orQuery([ cts.jsonPropertyValueQuery('format', 'paperback'), cts.jsonPropertyRangeQuery('price', '<', 10)]) ])
You can pass options to most cts.query constructor built-ins for fine-grained control of each portion of your search. For example, you can specify whether or not a particular word query should be case and diacritic insensitive. For details on available options, see the API reference documentation for each constructor.
For more details on constructing cts.query objects, see Composing cts:query Expressions.
Including Facets in Search Results
Search facets provide a summary of the values of a given characteristic across a set of search results. For example, you could query an inventory of appliances and facet on the manufacturer names. Facets can also include counts. The jsearch.facets method enables you to generate search result facets quickly and easily.
This section includes the following topics:
- Introduction to Facets
- Basic Steps for Generating Facets
- Example: Generating Facets From JSON Properties
- Creating a Facet Definition
- Understanding the Output of Facets
- Sorting Facet Values with OrderBy
- Retrieving Facets and Content in a Single Operation
- Multi-Facet Interactions Using othersWhere
- Example: Multi-Facet Interactions Using othersWhere
Introduction to Facets
Search facets can enable your application users to narrow a search by drilling down with search criteria presented by the application.
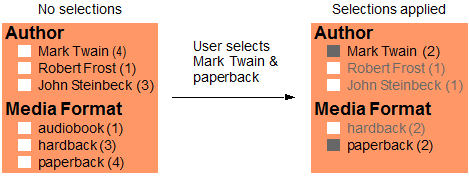
For example, suppose you have an application that enables users to search bibliographic data on books. If the user searches for American authors, the application displays the search results, plus filtering controls that enable the user to narrow the results by author and/or media format. The filtering controls may include both a list of values, such as author names, and the number of items matching each selection.
The following diagram depicts such an interaction. Search results are not shown; only the filtering controls are included due to space constraints. The greyed out items are just representative of how an application might choose to display unselected facet values.
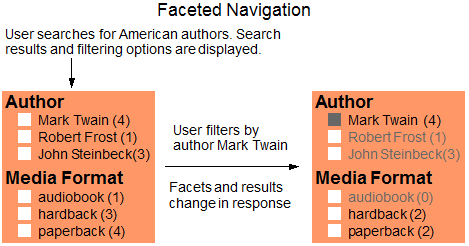
The filtering categories Author and Media Format represent facets. The author names and formats are values from the author and format facets, respectively. The numbers after each value represent the number of items containing that value.
MarkLogic generates facet values and counts from range indexes and lexicons. Therefore, your database configuration must include a lexicon or index for any content feature you want to use as a facet source, such as a JSON property or XML element.
Use the JSearch facet method to identify an index from which to source facet data; for details, see Creating a Facet Definition. Use the Jsearch facets method to generate facets from such definitions. Only facet data is returned by default, but you can optionally request matching documents as well; for details, see Retrieving Facets and Content in a Single Operation.
The remainder of this section describes how to generate and customize facets in more detail.
Basic Steps for Generating Facets
The primary interfaces for generating facets are the jsearch.facets and jsearch.facet methods. Use the facet method to create a FacetDefinition, then pass your facet definitions to the facets method to create a facet generation operation. As with other JSearch operations, facets are not generated until you call the result method.
The following procedure outlines the steps for building a faceting operation. For a complete example, see Example: Generating Facets From JSON Properties.
- Define one or more facets using the jsearch.facet method. For each, provide a label and an index, lexicon, or JSON property reference that identifies the facet source. The label becomes the property name for the facet data in the results.
For example, the following call defines a facet labeled Author derived from a range index on the JSON property named author. The database must include a range index on author.
jsearch.facet('Author', 'author')
A facet definition can include additional configuration. For details, see Creating a Facet Definition.
- Pass your facet definitions to the jsearch.facets method. For example:
jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')])
- Optionally, add a
documentsclause to return document search results and contents along with the facets. By default, only the facet data is returned. For example:jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')], jsearch.documents())
- Optionally, use FacetsSearch.where method to select the documents over which to facet. You can pass one or more
cts.queryobjects, just as for a document search. For example:jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')]) .where(jsearch.byExample({price: {$lt: 15}}))
- Optionally, use the FacetsSearch.withOptions method to specify advanced options. For example:
jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')]) .where(jsearch.byExample({price: {$lt: 15}})) .withOptions({maxThreads: 15})
- Generate facets (and documents, if requested in Step 3) by calling the
resultmethod. For example:jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')]) .where(jsearch.byExample({price: {$lt: 15}})) .result()
For a complete example, see Example: Generating Facets From JSON Properties.
For more details, see the following topics in the MarkLogic Server-Side JavaScript Function Reference:
Example: Generating Facets From JSON Properties
This example is a simple demonstration of generating facets. The example uses the sample documents and database configuration described in Preparing to Run the Examples.
The example generates facets for documents that contain a price property with value less than 15 (jsearch.byExample({price: {$lt: 15}})). Since the search criteria is a range query, the database configuration must include a range index on price.
Facets are generated for the matched documents from two content features:
- The author JSON property values. The database configuration must include a range index on this property.
- The format JSON property values. The database configuration must include a range index on this property.
If your database is configured according to the instructions in Preparing to Run the Examples, then it already includes the indexes needed to run this example.
The following query builds up and then evaluates a facet request. Facets are not generated until the result method is evaluated.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')]) .where(jsearch.byExample({price: {$lt: 15}})) .result()
Running this query in Query Console produces the following output:
{"facets":{ "Author": { "Mark Twain": 2, "John Steinbeck": 1 }, "MediaFormat": { "paperback": 3 }}}
Notice that the facets property of the results contains a child property corresponding to each facet definition created by jsearch.facet. In this case, the documents that met the price < 15 criteria include two documents with an author value of Mark Twain and one document with an author value of John Steinbeck. Similarly, based on the format property, a total of 3 paperbacks meet the price criteria.
If you add a documents query, you can retrieve facets and matched documents together. For details, see Retrieving Facets and Content in a Single Operation.
Creating a Facet Definition
The facets method accepts one or more facet definitions as input. Use the jsearch.facet method to create each facet definition.
The simplest form of facet definition just associates a facet name with a reference to a JSON property, XML element, field or other index or lexicon. For example, the following facet definition associates the name Author with a JSON property named author.
jsearch.facet('Author', 'author')
However, you can further customize the facet using a pipeline pattern similar to the one described in Query Design Pattern. The table below describes the pipeline stages availble for building a facet definition.All pipeline stages are optional, can appear at most once, and must be used in the order shown. Most stages behave as they do when used with a values query; for details, see ValuesSearch in the MarkLogic Server-Side JavaScript Function Reference.
| Method | Stage Description |
|---|---|
othersWhere |
Control how facets interact with each other and with any queries that are part of the facets call, such as a documents query. For details, see Multi-Facet Interactions Using othersWhere and FacetDefinition.othersWhere in the MarkLogic Server-Side JavaScript Function Reference. |
thisWhere |
Control how facets interact with each other and with any queries that are part of the facets call, such as a documents query. For details, see Multi-Facet Interactions Using othersWhere and FacetDefinition.thisWhere in the MarkLogic Server-Side JavaScript Function Reference. |
groupInto |
Group facet values into buckets based on a range of values. For example you can facet on price and group facet values into price range buckets such as Less than $10 and $10 or more, rather than simply retrieving a set of individual prices and counts. For details, see Grouping Values and Facets Into Buckets and FacetDefinition.groupInto in the MarkLogic Server-Side JavaScript Function Reference. |
orderBy |
Control whether the results from this facet are ordered by frequency or value and whether they're listed in ascending or descending order. For details, see Sorting Values or Tuples Query Results and FacetDefinition.orderBy in the MarkLogic Server-Side JavaScript Function Reference. |
slice |
Define a subset of the results to return. Slicing enables you to page through a large set of results. For details, see Returning a Result Subset and FacetDefinition.slice in the MarkLogic Server-Side JavaScript Function Reference. |
map | reduce |
Use map or reduce to apply transformations to the results. You can only use map or reduce, never both together. For details, see Transforming Results with Map and Reduce, FacetDefinition.map, and FacetDefinition.reduce. |
withOptions |
Specify advanced faceting options, such as an option accepted by cts.values or a quality weight. A facet definition accepts the same options configuration as a values query. For details, see FacetDefinition.withOptions in the MarkLogic Server-Side JavaScript Function Reference. |
Understanding the Output of Facets
By default, only facet data is returned from a facets request, and the data for each facet is an object containing facetValue:count properties. That is, the default output has the following form:
{"facets": { "facetName1": { "facetValue1": count, ... "facetValueN": count, }, "facetNameN": { ... }, }}
The facet names come from the facet definition. The facet values and counts come from the index or lexicon referenced in the facet definition. The following diagram shows the relationship between a facet definition and the facet data generated from it:

For example, the following output was produced by a facets request that included two facet definitions, name Author and MediaFormat. For details on the input facet definitions, see Example: Generating Facets From JSON Properties.
{"facets":{ "Author": { "Mark Twain": 2, "John Steinbeck": 1 }, "MediaFormat": { "paperback": 3 }}}
The built-in reducer generates the per facet objects, with counts. If you do not require counts, you can use the map method to bypass the reducer and configure the built-in mapper to omit the counts. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( jsearch.facet('Author', 'author').map({frequency: 'none'})) .where(cts.directoryQuery('/books/')) .result()
Running this query on a database configured according to the instructions in Preparing to Run the Examples produces the following output:
{"facets": { "Author": ["Mark Twain", "Robert Frost", "John Steinbeck"] }}
If you include a documents call in your facets operation, then the output includes both facet data and the results of the document search. The output has the following form:
{ "facets": { property for each facet }, "documents": [ descriptor for each matched document ] }
The documents array items are search result descriptors exactly as returned by a document search. They can include the document contents and search match snippets. For an example, see Example: Generating Facets From JSON Properties.
You can pass 'iterator' to your result call to return a Sequence as the value of each facet instead of an object. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; const results = jsearch.facets(jsearch.facet('Author', 'author')) .where(cts.directoryQuery('/books/')) .result('iterator') const authors = []; for (const author of results.facets.Author) { authors.push(author) } authors ==> [{"Mark Twain":4, "Robert Frost":1, "John Steinbeck":3}]
In this case, the returned Iterable contains only a single item: The object containing the value:count properties for the facet that is produced by the built-in reducer. However, if you use a mapper or a custom reducer, you can have more items to iterate over.
For example, the following call chain configures the built-in mapper to return only the facet values, without counts, so returning an iterator results in a Sequence over each facet value (author name, here):
import jsearch from '/MarkLogic/jsearch.mjs'; const results = jsearch.facets( jsearch.facet('Author', 'author').map({frequency: 'none'})) .where(cts.directoryQuery('/books/')) .result('iterator') const authors = []; for (const author of results.facets.Author) { authors.push(author) } authors ==> ["Mark Twain", "Robert Frost", "John Steinbeck"]
If you use groupInto to group the values for a facet into buckets representing value ranges, then the value of the facet is either an object or an Iterable over the bucket descriptors. For example, suppose you generate facets on a price property and get the following values:
{"facets":{ "Price": "8":1, "9":1, "10":1, "16":1, "18":2, "20":1, "30":1} }}
You could add a groupInto specification to group the facet values into 3 price range buckets instead, as shown in the following query:
jsearch.facets( jsearch.facet('Price','price') .groupInto([ jsearch.bucketName('under $10'), 10, jsearch.bucketName('$10 to $19.99'), 20, jsearch.bucketName('over $20') ])) .where(cts.directoryQuery('/books/')) .result();
Now, the generated facets are similar to the following:
{"facets": { "Price": { "under $10": { "value": { "minimum": 8, "maximum": 9, "upperBound": 10 }, "frequency": 2 }, "$10 to $19.99": { "value": { "minimum": 10, "maximum": 18, "lowerBound": 10, "upperBound": 20 }, "frequency": 4 }, "over $20": { "value": { "minimum": 20, "maximum": 30, "lowerBound": 20 }, "frequency": 2 } } } }
For details, see Grouping Values and Facets Into Buckets.
Sorting Facet Values with OrderBy
As mentioned in Introduction to Facets, facet results include a count (or frequency) by default. You can use FacetDefinition.orderBy to sort the results for a given facet by this frequency. Including an explicit sort order in your facet definition changes the structure of the results.
For example, the following query, which does not use orderBy, produces a set of facet values on author, in the form of a JSON object. This is the default behavior. Since the facet is an object with facetValue:count properties, the facet values are effectively unordered.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author')]) .where(jsearch.byExample({price: {$lt: 50}})) .result(); // Produces the following output: // {"facets":{ // "Author":{ // "John Steinbeck":3, // "Mark Twain":4, // "Robert Frost":1} // }}
If you add an orderBy clause to the facet definition, then the value of the facet is an array of arrays, where each inner array is of the form [ item_value, count ]. The array items are ordered by the frequency. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author').orderBy('frequency') ]) .where(jsearch.byExample({price: {$lt: 50}})) .result(); // Produces the following output: // {"facets":{ // "Author":[ // ["Mark Twain", 4], // ["John Steinbeck", 3], // ["Robert Frost", 1] // ] // }}
You can also sort by item (the value of author in our example), and choose whether to list the facet values in ascending or descending order. For example, if you use the orderBy clause orderBy('item', descending), the you get the following output:
{"facets":{ "Author":[ ["Robert Frost", 1], ["Mark Twain", 4], ["John Steinbeck", 3] ] }}
If the default structure does not meet the needs of your application, you can modify the output using a custom mapper. For more details, see Transforming Results with Map and Reduce.
Retrieving Facets and Content in a Single Operation
By default, the result of facet generation does not include content from the documents from which the facets are derived. Add snippets, complete documents, or document projections to the results by including a documents query in your facets call.
For example, the following query returns both facets and snippets for documents that contain a price property with a value less than 15:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')], jsearch.documents()) .where(jsearch.byExample({price: {$lt: 15}})) .result()
Running this query against the database created by Preparing to Run the Examples produces the following output. Notice the output includes facets on author and format, plus the document search results containing snippets (in the properties property).
{ "facets": { "Author": { "Mark Twain": 2, "John Steinbeck": 1 }, "MediaFormat": { "paperback": 3 } }, "documents": [ { "uri": "/books/twain1.json", "path": "fn:doc(\"/books/twain1.json\")", "index": 0, "matches": [ { "path": "fn:doc(\"/books/twain1.json\")/edition/number-node(\"price\")", "matchText": [ { "highlight": "9" } ] } ] }, ...additional documents... ], "estimate": 3 }
The matches property of each documents item contains the snippets. For example, if the above facets results are saved in a variable named results, then you can access the snippets for a given document through results.documents[n].matches.
To include the complete documents in your facet results instead of just snippets, configure the built-in mapper on the documents query to extract all. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')], jsearch.documents().map({extract:{select:'all'}})) .where(jsearch.byExample({price: {$lt: 15}})) .result()
In this case, you access the document contents through the extracted property of each document. For example, results.documents[n].extracted. The extracted property value is an array because you can potentially project multiple subsets of content out of the matched document using the map and reduce features. For details, see Extracting Portions of Each Matched Document.
The documents query can include where, orderBy, filter, slice, map/reduce, and withOptions qualifiers, just as with a standalone document search. For details, see Document Search Basics.
The document search combines the queries in the where qualifier of the facets query, the where qualifier of the documents query, and any othersWhere queries on facet definitions into a single AND query.
For example, the following facets query includes uses all three query sources.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat','format') .othersWhere(jsearch.byExample({format: 'paperback'}))], jsearch.documents() .where(jsearch.byExample({author: 'Mark Twain'}))) .where(jsearch.byExample({price: {$lt: 20}})) .result()
This query has the following effect on the returned results:
- Only generate facets from documents where price < 20. From this part of the query:
jsearch.facets(...).where(jsearch.byExample({price: {$lt: 20}})). - For facets other than
format, only return facet values for documents where format is paperback. From this part of the query:jsearch.facet('MediaFormat','format').othersWhere(jsearch.byExample({format: 'paperback'})) - Only return documents where author is Mark Twain. From this part of the query: jsearch.documents().where(
jsearch.byExample({author: 'Mark Twain'}))
Thus, the query only returns matches where all the following conditions are met: price < 20 and format is paperback and author is Mark Twain.
You can use the returnQueryPlan option to explore this relationship. For example, adding a withOptions call to the documents query as shown below returns the following information in the results:
... jsearch.documents() .where(jsearch.byExample({author: 'Mark Twain'})) .withOptions({returnQueryPlan: true}) ... ==> results.queryPlan includes the following information (reformatted for readability) Search query contributed 3 constraints: cts.andQuery([ cts.jsonPropertyRangeQuery("price", "<", xs.float("20"), [], 1), cts.jsonPropertyValueQuery("format", "paperback", ["case-sensitive","diacritic-sensitive","punctuation-sensitive", "whitespace-sensitive","unstemmed","unwildcarded","lang=en"], 1), cts.jsonPropertyValueQuery("author", "Mark Twain", ["case-sensitive","diacritic-sensitive","punctuation-sensitive", "whitespace-sensitive","unstemmed","unwildcarded","lang=en"], 1) ], [])
Multi-Facet Interactions Using othersWhere
Use the FacetDefinition.othersWhere method to efficiently vary facet values across user interactions and deliver a more intuitive faceted navigation user experience.
Imagine an application that enables users to filter a search using facet-based filtering controls. Each time a user interacts with the filtering controls, the application makes a request to MarkLogic to retrieve new search results and facet values that reflect the current search criteria.
A naive implementation might apply the selection criteria across all facets and document results. However, this causes values to drop out of the filtering choices, making it more difficult for users to be aware of other choice or change the filters.
The application could generate the values for each facet and for the matching documents independently, but this is inefficient because it requires multiple requests to MarkLogic. A better approach is to use the othersWhere method to apply criteria asymmetrically to the facets and collectively to the document search portion.
The following example uses othersWhere to generate facet values for two selection criteria, an author value of Mark Twain and a format value of paperback:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( [jsearch.facet('Author', 'author') .othersWhere(jsearch.byExample({author: 'Mark Twain'})), jsearch.facet('MediaFormat', 'format') .othersWhere(jsearch.byExample({format: 'paperback'}))], jsearch.documents()) .where(cts.directoryQuery('/books/')) .result()
When each facet applies othersWhere to selection criteria based on itself, you get multi-facet interactions. For example, the above query returns the following results. Thanks to the use of othersWhere on each facet definition, the author facet values are unaffected by the Mark Twain selection and the format facet values are unaffected by paperback selection. The document search is affected by both.
{"facets":{ "Author":{"John Steinbeck":1, "Mark Twain":2, "Robert Frost":1}, "MediaFormat":{"hardback":2, "paperback":2}}, "documents":[ ...snippets for docs matching both criteria... ] }
If you pass the criteria in through the where method instead, some facet values drop out, making it more difficult for users to see the available selections or to change selections. For example, the following query puts the author and format criteria in the where call, resulting in the facet values shown:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( [jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')], jsearch.documents()) .where([cts.directoryQuery('/books/'), jsearch.byExample({author: 'Mark Twain'}), jsearch.byExample({format: 'paperback'})]) .result() ==> {"facets":{ "Author":{"Mark Twain":2}, "MediaFormat":{"paperback":2}}, "documents":[ ...snippets for docs matching both criteria... ]
The differences in these two approaches are explored in more detail in Example: Multi-Facet Interactions Using othersWhere.
The JSearch API also includes a FacetDefinition.thisWhere modifier which has the opposite effect of othersWhere: The selection criteria is applied only to the subject facet, not to any other facets or to the document search. For details, see FacetDefinition.thisWhere in the MarkLogic Server-Side JavaScript Function Reference.
Example: Multi-Facet Interactions Using othersWhere
This example explores the use of othersWhere to enable search selection criteria to affect related facets asymmetrically, as described in Multi-Facet Interactions Using othersWhere.
This example assumes the database configuration and content described in Preparing to Run the Examples.
Suppose you have an application that enables users to search for books, and the application displays facets on author and format (hardback, paperback, etc.) that can be used to narrow a search.
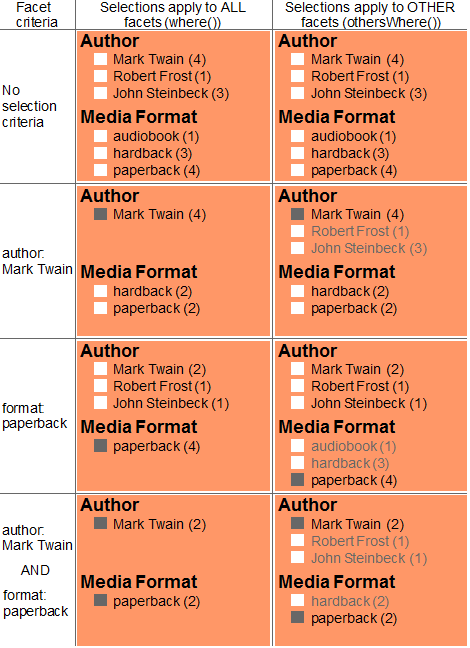
The following diagram contrasts two possible approaches to implementing such a faceted navigation control. The middle column represents a faceted navigation control when the user's selection criteria are applied symmetrically to all facets through the where method. The rightmost column represents the same control when the user's criteria are applied asymmetrically using othersWhere. Notice that, in the rightmost column, the user can always see and select alternative criteria.
The remainder of this example walks through the code that backs the results in both columns.
Before the user selects any criteria, the baseline facets are generated with the following request. Facet values are generated for the author and format JSON properties. The documents in the /books/ directory seed the initial search results that the user can drill down on. (Matched documents are not shown.)
// baseline - no selection criteria import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets([ jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format') ], jsearch.documents()) .where(cts.directoryQuery('/books/')) .result()
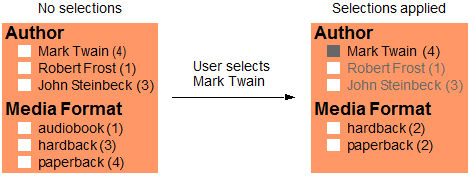
Consider the case where the user then selects an author, and the application applies the selection criteria unconditionally, resulting in the following filtering control changes:
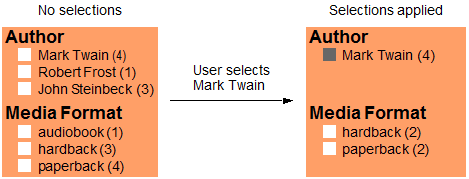
The user can no longer readily see the other available authors. These results were generated by the following query, where the cts.directoryQuery query represents the baseline search, and the jsearch.byExample query represents the user selection. Passing the author query to the where method applies it to all facets and the document search.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( [jsearch.facet('Author', 'author'), jsearch.facet('MediaFormat', 'format')], jsearch.documents()) .where([cts.directoryQuery('/books/'), jsearch.byExample({author: 'Mark Twain'})]) .result()
By moving the author query to an othersWhere modifier on the author facet, you can apply the selection to other facets, such as format, and to the document search, but leave the author facet unaffected by the selection criteria. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( [jsearch.facet('Author', 'author') .othersWhere(jsearch.byExample({author: 'Mark Twain'})), jsearch.facet('MediaFormat', 'format')], jsearch.documents()) .where(cts.directoryQuery('/books/')) .result()
Using using othersWhere instead of where to pass the criteria results in the following display. The user can clearly see the alternative author choices and the number of items that match each other. Yet, the user can still see how his author selection affects the available media formats and the matching documents. The diagram below illustrates how the application might display the returned facet values. Snippets are returned for all documents with Mark Twain as the author.
If the user chooses to further filter on the paperback media format, you can use othersWhere on the format facet to apply this criteria to the author facet values and the document search, but leave all the format facets values available. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( [jsearch.facet('Author', 'author') .othersWhere(jsearch.byExample({author: 'Mark Twain'})), jsearch.facet('MediaFormat', 'format') .othersWhere(jsearch.byExample({format: 'paperback'}))], jsearch.documents()) .where(cts.directoryQuery('/books/')) .result()
The above query results in the following display. The user can easily see and select a different author or format. The matched documents are not shown, but they consist of documents that match both the author and format selections.
Controlling the Ordering of Results
Use the orderBy function to control the order in which your query results are returned. You can apply an orderBy clause to a document search, word lexicon query, values query, or tuples query.
Though you can use orderBy with all these query types, the specifics vary. For example, you can only specify content-based sort keys in a document search, and you can only choose between item order and frequency order on a values or tuples query.
This section covers the following topics.
- Sorting Document Search Results
- Sorting Values or Tuples Query Results
- Sorting Word Lexicon Query Results
- Sorting Facet Values
Sorting Document Search Results
By default, search results are returned in relevance order, with most relevant results displayed first. That is, the sort key is the relevance score and the sort order is descending.
You can use the DocumentsSearch.orderBy method to change the sort key and ordering (ascending/descending). You can sort the results by features of your content, such as the value of a specified JSON property, and by attributes of the match, such as fitness, confidence, or document order. You must configure a range index for each JSON property, XML element, XML attribute, field, or path on which you sort.
For example, the following code sorts results by value of the JSON property named title. A range index for the title property must exist.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({'author': { '$word': 'twain' }})) .orderBy('title') .result();
The use of a simple name in the orderBy call implies a cts.jsonPropertyReference. You can also explicitly construct a cts.reference by calling an index reference constructor such as cts.jsonPropertyReference, cts.elementReference, cts.fieldReference, or cts.pathReference. For example, the following call specifies ordering on the JSON property price:
orderBy(cts.jsonPropertyReference('price'))
To sort results based on search metadata such as confidence, fitness, and quality, use the cts.order constructors. For example, the following orderBy specifies sorting by confidence rather than relevance score:
orderBy(cts.confidenceOrder())
You can also use the cts.order constructors to control whether results are sorted in ascending or descending order with respect to a sort key. For example, the following call sorts by the JSON property price, in ascending order:
orderBy( cts.indexOrder(cts.jsonPropertyReference('price'), 'ascending'))
You can specify more than one sort key. When there are multiple keys, they're applied in the order they appear in the array passed to orderBy. For example, the following call says to first order results by the price JSON property values, and then by the title values.
orderBy(['price', 'title'])
For details, see DocumentsSearch.orderBy in the MarkLogic Server-Side JavaScript Function Reference and Sorting Searches Using Range Indexes in the Query Performance and Tuning Guide.
Sorting Values or Tuples Query Results
By default, values and tuples query results are returned in ascending item order. You can use the ValuesSearch.orderBy and TuplesSearch.orderBy methods to specify whether to order the results by value (item order) or frequency, and whether to use ascending or descending order.
For example, the following query returns all the values of the price JSON property, in ascending order of the values:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price').result() ==> [8, 9, 10, 16, 18, 20, 30]
The following code modifies the query to return the results in frequency order. By default, frequency order returns results in descending order (most to least frequent). In this case, the database contained multiple documents with price 18, and only a single document containing each of the other price points, so the 18 value sorted to the front of the result array, and the remaining values that share the same frequency appear in document order.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price').orderBy('frequency').result() ==> [18, 8, 9, 10, 16, 20, 30]
To order the results by ascending frequency value, pass 'ascending' as the second parameter of orderBy. For example:
orderBy('frequency', 'ascending')
You can also include the frequency values in the results using the map or reduce methods. For details, see Querying the Values in a Lexicon or Index.
Sorting Word Lexicon Query Results
When you query a word lexicon using the jsearch.words resource selector method, results are returned in ascending order. Use the WordsSearch.orderBy method to control whether the results are returned in ascending or descending order.
For example, the following query returns the first 10 results in the default (ascending) order:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.words('title').result() ==> ["Adventures", "and", "Collected", "East", "Eden", "Finn", "Grapes", "Huckleberry", "Men", "Mice"]
You can use orderBy to change the order of results. For example, the following call returns the 10 results when the words in title are sorted in descending order:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.words('title').orderBy('descending').result() ==> ["Wrath", "Works", "Tom", "The", "Sawyer", "Of", "of", "Mice", "Men", "Huckleberry"]
Note that this example assumes the database configuration includes a word lexicon on the title JSON property. For more details on querying word lexicons, see Querying Values in a Word Lexicon.
Sorting Facet Values
When you generate facets with frequencies using jsearch.facets, the values of each facet are expressed as a JSON object, so they are effectively unordered. You can use FacetDefinition.orderBy to control the sort order and change the output to a structure that can be meaningfully ordered (an array of arrays).
For more details, see Sorting Facet Values with OrderBy.
Returning a Result Subset
You can use the slice method to return a subset of the results from a top level documents, values, tuples, or words query, or when generating facets.
A slice specification works like Array.slice and has the following form:
slice(firstPosToReturn, lastPosToReturn + 1)
The positions use a 0-based index. That is, the first item is position 0 in the result list. Thus, the following returns the first 3 documents in the classics collection:
import jsearch from '/MarkLogic/jsearch.mjs'; const classics = jsearch.collections('classics'); classics.documents() .slice(0,3) .result()
You cannot request items past the end of result set, so it is possible get fewer than the requested number of items back. When the search results are exhausted, the results property of the return value is null, just as for a search which matches nothing. For example:
{ results: null, estimate: 4 }
Applying slice iteratively to the same query enables you to return successive pages of results. For example, the following code iterates over search results in blocks of three results at a time:
import jsearch from '/MarkLogic/jsearch.mjs'; const sliceStep = 3; // max results per batch const sliceStart = 0; const sliceEnd = sliceStep; const response = {}; do { response = jsearch.documents().slice(sliceStart, sliceEnd).result(); if (response.results != null) { // do something with the results sliceStart += response.results.length; sliceEnd += sliceStep; } } while (response.results != null);
You can set the slice end position to zero to suppress returning results when you're only interested in query metadata, such as the estimate or when using returnQueryPlan:true. For example, the following returns the estimate without results:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('author', 'Mark Twain')) .slice(0,0) .result() ==> { results: null, estimate: 4 }
Including Snippets of Matching Content in Search Results
When you perform a document search using jsearch.documents, the result is an array or Iterable over descriptors of each match. Each descriptor includes the contents of the matching document by default. You can use snippeting to a include portion of the content around the match in each result, instead of (or in addition to) the complete document.
This section covers the following topics:
- Enabling Snippet Generation
- Configuring the Built-In Snippet Generator
- Returning Snippets and Documents Together
- Generating Custom Snippets
- Standalone Snippet Generation
Enabling Snippet Generation
You can include snippets in a document query by adding a map clause to your query that sets the built-in mapper configuration property snippet to true or setting snippet to a configuration object, as described in Configuring the Built-In Snippet Generator. (Snippets are generated by default when you include any document query in a jsearch.facets operation.)
For example, the following query matches occurrences of the word california and returns the default snippets instead of the matching document:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({synopsis: {$word: 'california'}})) .map({snippet: true}) .result() ==> {"results":[ {"score":28672, "fitness":0.681636929512024, "uri":"/books/steinbeck1.json", "path":"fn:doc(\"/books/steinbeck1.json\")", "confidence":0.529645204544067, "index":0, "matches":[{ "path":"fn:doc(\"/books/steinbeck1.json\")/text(\"synopsis\")", "matchText":[ "...from their homestead and forced to the promised land of ", {"highlight":"California"}, "." ] }] }, { ... }, ... ], "estimate":3 }
If this was a default search (no snippets), there would be a document property instead of the matches property, as shown in Example: Basic Document Search.
For more details, see DocumentsSearch.map.
Configuring the Built-In Snippet Generator
You can configure the built-in snippet generator by setting the built-in mapper snippet property to a configuration object instead of a simple boolean vaue.
You can set the following snippet configuration properties:
For example, the following configuration only returns snippets for matches occurring in the synopsis property and surrounds the highlighted matching text by at most 5 tokens.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.wordQuery('california')) .map({snippet: { preferredMatches: ['synopsis'], perMatchTokens: 5 }}) .result()
Thus, if the word query for occurrences of california matched text in both the title and synopsis for some documents, only the matches in synopsis are returned. Also, the snippet match text is shorter, as shown below.
// match text in snippet with default perMatchTokens "matchText":[ "...an unlikely pair of drifters who move from job to job as farm laborers in ", {"highlight":"California"}, ", until it all goes horribly awry." ] // match text in snippet with perMatchTokens set to 5 "matchText":[ "...farm laborers in ", {"highlight":"California"}, ", until it..." ]
When snippeting over XML documents and using preferredMatches, use a QName rather than a simple string to specify namespace-qualified elements. For example:
{snippet: { preferredMatches: [fn.QName('/my/namespace','synopsis')] }}
For more details, see DocumentsSearch.map.
Returning Snippets and Documents Together
To return snippets and complete documents or document projections together, set snippet to true and configure the extract property of the built-in mapper to select the desired document contents. For details about extract, see Extracting Portions of Each Matched Document.
The following example returns the entire matching document in an extracted property and the snippets in the matches property of the results:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({synopsis: {$word: 'California'}})) .map({snippet: true, extract: {selected: 'all'}}) .result() ==> {"results":[ {"score":28672, "fitness":0.681636929512024, "uri":"/books/steinbeck1.json", "path":"fn:doc(\"/books/steinbeck1.json\")", "extracted":[{ "title":"The Grapes of Wrath", "author":"John Steinbeck", "edition":{"format":"paperback", "price":9.99}, "synopsis":"Chronicles the 1930s Dust Bowl migration of one Oklahoma farm family, from their homestead and forced to the promised land of California." }] "confidence":0.529645204544067, "index":0, "matches":[{ "path":"fn:doc(\"/books/steinbeck1.json\")/text(\"synopsis\")", "matchText":[ "...from their homestead and forced to the promised land of ", {"highlight":"California"}, "." ] }] }, { ... }, ... ], "estimate":3 }
For more details, see DocumentsSearch.map.
Generating Custom Snippets
If the snippets and projections generated by the built-in mapper do not meet the needs of your application, you can use a custom mapper to generate customized results. For details, see Transforming Results with Map and Reduce.
Standalone Snippet Generation
You can use the jsearch.documentSelect method to generate snippets from an arbitrary set of documents, such as the output from cts.search or fn.doc. The output is a Sequence of results.
If the input is the result of a search that matches text, then the results include search result metadata such as score, along with your snippets. Search metadata is not included if the input is an arbitrary set of documents or the result of a search that doesn't match text, such as a collection or directory query.
You must include a query in the snippet configuration when using documentSelect so the snippeter has search matches against which to generate snippets. You can also include the other properties described in Configuring the Built-In Snippet Generator.
The following example uses documentSelect to generate snippets from the result of calling cts.search (instead of jsearch.documents).
import jsearch from '/MarkLogic/jsearch.mjs'; const myQuery = cts.andQuery([ cts.directoryQuery('/books/'), cts.jsonPropertyWordQuery('synopsis', 'california')]) jsearch.documentSelect( cts.search(myQuery), {snippet: {query: myQuery}})
Extracting Portions of Each Matched Document
You can use the built-in mapper of document search to return selected portions of each document that matches a search. You can use the extraction feature with jsearch.documents and jsearch.documentSelect.
This section includes the following topics:
Extraction Overview
By default, a document search returns the complete document for each search match. You can use extract feature of the built-in documents mapper to extract only selected parts of each matching document instead. Such a subset of the content in a document is sometimes called a sparse document projection. This feature is similar to the query option extract-document-data. available to the XQuery Search API and the Client APIs.
You use XPath expressions to identify the portions of the document to include or exclude. XPath is a standard expression language for addressing XML content. MarkLogic has extended XPath so you can also use it to address JSON. For details, see Traversing JSON Documents Using XPath in the Application Developer's Guide and XPath Quick Reference in the XQuery and XSLT Reference Guide.
To generate sparse projections, configure the extract property of the built-in mapper of a document search. The property has the following form:
extract: { paths: xPathExpr | [xPathExprs], selected: 'include' | 'include-with-ancestors' | 'exclude' | 'all' }
Specify one or more XPath expressions in the paths value; use an array for specifying multiple expressions. The selected property controls how the content selected by the paths affects the document projection. The selected property is optional and defaults to 'include' if not present; for details, see How selected Affects Extraction.
For example, the following code extracts just the title and author properties of documents containing the word California in the synopsis property.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({synopsis: {$word: 'California'}})) .map({extract: {paths: ['/title', '/author']}}) .result()
The table below displays the default output of the query (without a mapper) on the left and the result of using the example extraction on the right. Notice that the document property that contains the complete document contents has been replaced with an extracted property that contains just the requested subset of content.
When extracting XML content that uses namespaces, you can use namespace prefixes in your extract paths. Define the prefix bindings in the namespaces property of the mapper configuration object. For example, the following configuration binds the prefix my to the namespace URI /my/namespace, and then uses the my prefix in an extract path.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documentSelect(fn.doc('/books/some.xml'), { namespaces: {my: '/my/namespace'}, extract: {paths: ['/my:book/my:title']} })
Since the extraction feature is a capability of the built-in mapper for a document search, you cannot use it when using a custom mapper. If you want to return document subsets when using a custom mapper, you must construct the projections yourself.
For more details on using and configuring mappers, see Transforming Results with Map and Reduce.
How selected Affects Extraction
The selected property of the extract configuration for DocumentsSearch.map determines what to include in the extracted content. By default, the extracted content includes only the content selected by the path expressions. However, you can use the select property to configure these alternatives:
- include enclosing objects or elements (ancestors) in addition to the named nodes
- exclude the specified nodes rather than include them
- include all nodes, effectively ignoring the specified paths and including the whole document
For example, the documents loaded by Preparing to Run the Examples have the following form:
{ "title": string, "author": string, "edition": { "format": string, "price": number }, "synopsis": string}
The table below illustrates how various selected settings affect the extraction of the title and price properties. The first row ('include') also represents the default behavior when selected is not explicitly set.
If the combination of paths and select selects no content for a given document, then the results contain an extractedNone property instead of an extracted property. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({synopsis: {$word: 'California'}})) .map({extract: {paths: ['/no/matches'], selected: 'include'}}) .result() ==> {"results":[ { ..., "extractedNone":true, ... }]}
Combining Extraction With Snippeting
By default, snippets are not generated when you use extraction, but you can configure your search to return both snippets and extracted content by setting snippet to true in the mapper configuration. For example, the following search:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(jsearch.byExample({synopsis: {$word: 'California'}})) .map({snippet: true, extract: {paths: ['/title', '/author']}}) .result()
Produces output similar to the following, with the document projects in the extracted property and the snippets in the matches property:
{ "results": [ { "score": 18432, "fitness": 0.71398365497589, "uri": "/books/steinbeck1.json", "path": "fn:doc(\"/books/steinbeck1.json\")", "extracted": [ { "title": "The Grapes of Wrath" }, { "author": "John Steinbeck" } ], "confidence": 0.4903561770916, "index": 0, "matches": [{ "path": "fn:doc(\"/books/steinbeck1.json\")/text(\"synopsis\")", "matchText": [ "...from their homestead and forced to the promised land of ", { "highlight": "California" }, "." ] }] }, ...] }
Similarly, you can include both snippet and extract specifications in the configuration for jsearch.documentSelect. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documentSelect( cts.search(cts.jsonPropertyWordQuery('synopsis', 'California')), {snippet: { query: cts.jsonPropertyWordQuery('synopsis', 'California') } extract: {paths: ['/title', '/author'], selected: 'include'} } )
For more details on snippeting, see Including Snippets of Matching Content in Search Results.
Using Options to Control a Query
You can control a document search with options in two ways:
- Specify query-specific options during construction of a query.
- Specify search-wide options using the
DocumentsSearch.withOptionsmethod.
Other JSearch operations, such as lexicon searches, use a similar convention for passing options to a specific query or applying them to the entire operation.
For example, the following query uses the query-specific $exact option of QBE to disable exact match semantics on the value query constructed with jsearch.byExample. However, this setting has no effect on the query constructed by cts.jsonPropertyValueQuery or on the top level cts.orQuery.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.orQuery([ jsearch.byExample({author: {$value: 'mark twain', $exact: false}}), cts.jsonPropertyValueQuery('author', 'john steinbeck') ])) .result()
The available per-query options depend on the type of query. The mechanism for specifying per-query options depends on the construction method you choose. For details, consult the appropriate API reference.
For example, cts.jsonPropertyValueQuery accepts a set of options as a parameter. through these options you can control attributes such as whether or not to enable stemming:
cts.jsonPropertyValueQuery( 'author', 'mark twain', ['case-insensitive', 'lang=en'])
Options that can apply to the entire search are specified using the withOptions method. For example, you can use withOptions to pass options to the underlying cts.search operation of a documents search:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('author','mark twain')) .withOptions({search: ['format-xml','score-logtf']}) .result()
For more details, see the following methods:
- DocumentsSearch.withOptions
- ValuesSearch.withOptions
- TuplesSearch.withOptions
- WordsSearch.withOptions
- FacetsSearch.withOptions
- FacetDefinition.withOptions
Note that, specifically in the case of passing options through to cts.search, some commonly used options are surfaced directly through JSearch methods, such as the DocumentsSearch.filter method. You should use the JSearch mechanism when this overlap is present.
Transforming Results with Map and Reduce
The top level JSearch query options such as documents, values, tuples, and words include map and reduce methods you can use to tailor the final results in a variety of ways, such as including snippets in a document search or applying a content transformation.
This section includes the following topics:
- Map and Reduce Overview
- Configuring the Built-In Mapper
- Using a Custom Mapper
- Configuring the Built-In Reducer
- Using a Custom Reducer
- Example: Returning Only Documents
- Example: Using a Custom Mapper for Content Transformation
- Example: Custom Reducer For Document Search
- Example: Custom Reducer For Values Query
Map and Reduce Overview
The top level JSearch operations for document search (documents) and lexicon queries (values, tuples, and words) include map and reduce methods for customizing your query results. You can choose to use either map or reduce, but not both.
A mapper takes in a single value and produces zero results or one result. The mapper is invoked once for each item (search result, value, or tuple) processed by the query operation. The output from the mapper is pushed on to the results array. A mapper is well suited for applying transformations to results.
In broad strokes, a reducer takes in a previous result and a single value and returns either an item to pass to next invocation of the reducer, or a final result. The output from the final invocation becomes the result. Reducers are well suited for computing aggregates over a set of results.
You can supply a custom mapper or reducer by passing a function reference to the map or reduce method. Some operations also have a built-in mapper and/or reducer that you can invoke by passing a configuration object in to the map or reduce method. For example, the built-in mapper for document search can be used to generate snippets.
Thus, your map or reduce call can have one of the following forms:
// configure the built-in mapper, if supported .map({configProperties...}) // use a custom mapper .map(function (currentItem) {...}) // configure the built-in reducer, if supported .reduce({configProperties...}) // use a custom reducer .reduce(function (prevResult, currentItem, index, state) {...})
The available configuration properties and behavior of the built-in mapper and reducer depend on the operation you apply map or reduce to. For details, see Configuring the Built-In Mapper.
The following methods support map and reduce operations. For configuration details, see the MarkLogic Server-Side JavaScript Function Reference.
Configuring the Built-In Mapper
The capabilities of the built-in mapper vary, depending on the type of query operation (documents, values, or tuples). For example, the built-in mapper for a document search can be configured to generate snippets and document projections, while the built-in mapper on a values query can be configured to include frequency values in the results.
Configure the built-in mapper by passing a configuration object to the map method instead of a function reference. For example, the following call chain configures the built-in mapper for document search to return snippets:
jsearch.documents().map({snippet:true}).result()
The table below outlines the capabilities of the built-in mapper for each JSearch query operation.
| Operation | Built-In Mapper Capabilities |
|---|---|
|
Generation of snippets, document projections, and/or URIs for similar documents. For details, see Including Snippets of Matching Content in Search Results, Extracting Portions of Each Matched Document, and DocumentsSearch.map in the MarkLogic Server-Side JavaScript Function Reference. |
|
Control and generation of frequency data in the results. Optionally, add labels to returned values and frequencies. For details, see ValuesSearch.map in the MarkLogic Server-Side JavaScript Function Reference. |
|
Control and generation of frequency data in the results. Optionally, adds labels to returned tuples and frequencies. For details, TuplesSearch.map in the MarkLogic Server-Side JavaScript Function Reference. |
|
None. The words operation only supports a custom mapper. |
Using a Custom Mapper
You can supply a custom mapper to the map method of the documents, values, tuples, and words queries. To use a custom mapper, pass a function reference to the map method in your query call chain:
... .map(funcRef)
The mapper function must have the following signature and should produce either no result or a single result. If the function returns a value, it is pushed on to the final results array or iterator.
function (currentItem)
The currentItem parameter can be a search result, tuple, value, or word, depending on the calling context. For example, the mapper on a document search (the documents method) takes a single search result descriptor as input.
Any value returned by your mapper is pushed on to the results array.
The following example uses a custom mapper on a document search to add a property named iWasHere to each search result. The input in this case is the search result for one document.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('author','Mark Twain')) .map(function (value) {value.iWasHere = true; return value;}) .result() ==> {"results":[ {"index":0, "uri":"/books/twain4.json", "score":14336, "confidence":0.3745157122612, "fitness":0.7490314245224, "document":{...}, "iWasHere":true }, {"index":1, ...}, ... ], "estimate":4 }
Your mapper is not required to return a value. If you return nothing or explicitly return undefined, then the final results will contain no value corresonding to the current input item. For example, the following mapper eliminates every other search result:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .map(function (value) { if (value.index % 2 > 0) { return value; } }) .result().results.length
If your database contains only the documents from Preparing to Run the Examples, then the script should produce the answer 4 when run in Query Console.
For an additional example, see Example: Using a Custom Mapper for Content Transformation.
Configuring the Built-In Reducer
The capabilities of the built-in reducer vary, depending on the type of query operation. Currently, only values offers a built-in reducer.
Configure the built-in reducer by passing a configuration object to the reduce method instead of a function reference. For example, the following configures the built-in reducer for a values query to return item frequency data along with the values:
jsearch.values('price').reduce({frequency: 'item'}).result()
The table below outlines the capabilities of the built-in reducer for each JSearch query operation.
| Operation | Built-In Reducer Capabilities |
|---|---|
|
None. The documents operation only supports a custom reducer. |
|
Control and generation of frequency data in the results. Optionally, adds labels to returned values and frequencies. For details, see ValuesSearch.reduce in the MarkLogic Server-Side JavaScript Function Reference. |
|
None. The tuples operation only supports a custom reducer. |
|
None. The words operation only supports a custom reducer. |
Using a Custom Reducer
To use a custom reducer, pass a function reference and optional initial seed value to the reduce method of your query call chain:
... .reduce(funcRef, seedValue)
The reducer function must have the following signature:
function (prevResult, currentItem, index, state)
If you pass a seed value, it becomes the value of prevResult on the first invocation of your function. For example, the following reduce call seeds an accumulator object with initial values. On the first call to myFunc, prevResult contains {count: 0, value: 0, matches: []}.
... .reduce(myFunc, {count: 0, value: 0, matches: []}) ...
For example, the following call chain uses a custom mapper with an initial seed value as part of a document search.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('author','Mark Twain')) .reduce(function (prev, match, index, state) { // do something }, {count: 0, value: 0, matches: []}) .result()
The value returned by the last invocation of your reducer becomes the final result of the query. You can detect or signal the last invocation through state.isLast.
The following table describes the inputs to the reducer function:
Note that the map and reduce methods are exclusive of one another. If your query uses reduce, it cannot use map.
Example: Returning Only Documents
The following example uses a custom mapper to strip everything out of the results of a document search except the matched document. For more details, see Using a Custom Mapper and DocumentsSearch.map.
By default, a document search returns a structure that includes metadata about each match, such as uri and score, as well as the matched document. For example:
{ "results":[ { "index":0, "uri":"/books/frost1.json", "score":22528, "confidence":0.560400724411011, "fitness":0.698434412479401, "document": ...document node... }, ... ]}
The following code uses a custom mapper (expressed as a lambda function) to eliminate everything except the value of the document property. That is, it eliminates everything but the matched document node.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('format','paperback')) .slice(0,2) .map(match => match.document) .result()
The result is output similar to the following:
{ "results": [ { "title": "Collected Works", "author": "Robert Frost", "edition": { "format": "paperback", "price": 29.99 }, "synopsis": "The complete works of the American Poet Robert Frost." }, { "title": "The Grapes of Wrath", "author": "John Steinbeck", "edition": { "format": "paperback", "price": 9.99 }, "synopsis": "Chronicles the 1930s Dust Bowl migration of one Oklahoma farm family, from their homestead and forced to the promised land of California." }], "estimate": 4 }
The custom mapper lambda function (.map(match => match.document)) is equivalent to the following:
.map(function(match) { return match.document; })
Example: Using a Custom Mapper for Content Transformation
The following example demonstrates using a custom mapper to transform document content returned by a search. For more details, see Using a Custom Mapper and DocumentsSearch.map.
The following example code uses a custom mapper to redact the value of the JSON property author in each document matched by the search.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('format','paperback')) .slice(0,2) .map(function (match) { match.document = match.document.toObject(); match.document.author = 'READACTED'; return match; }) .result()
Each time the mapper is invoked, the author property value is changed to REDACTED in the document embedded in the search result. Notice the application of toObject to the document:
match.document = match.document.toObject();
This is necessary because match.document is initially a read-only document node. Applying toObject to the document node creates an in-memory, mutable copy of the contents.
If your database contains the documents created by Preparing to Run the Examples, then running the script produces output similar to the following. The part of each result affected by the mapper is shown in bold. Only two results are returned because of the slice(0,2) clause on the search.
{ "results": [ { "index": 0, "uri": "/books/frost1.json", "score": 14336, "confidence": 0.43245348334312, "fitness": 0.7490314245224, "document": { "title": "Collected Works", "author": "REDACTED", "edition": { "format": "paperback", "price": 29.99 }, "synopsis": "The complete works of the American Poet Robert Frost." } }, { "index": 1, "uri": "/books/steinbeck1.json", "score": 14336, "confidence": 0.43245348334312, "fitness": 0.7490314245224, "document": { "title": "The Grapes of Wrath", "author": "REDACTED", "edition": { "format": "paperback", "price": 9.99 }, "synopsis": "Chronicles the 1930s Dust Bowl migration of one Oklahoma farm family, from their homestead and forced to the promised land of California." } } ], "estimate": 4 }
Example: Custom Reducer For Document Search
The following example demonstrates using DocumentsSearch.reduce to apply a custom reducer as part of a document search.
The search selects a random sample of 1000 documents by setting the search scoring algorithm to score-random in withOptions. and the slice size to 1000 with slice. Notice that there is no where clause, so the search matches all documents in the database.
The following code snippet is the core search that drives the reduction:
jsearch.documents() .slice(0, 1000) .reduce(...) .withOptions({search: 'score-random'}) .result();
The reducer iterates over the node names (JSON property names or XML element names) in each document, adding each name to a map, along with a corresponding counter.
function nameExtractor(previous, match, index, state) { const nameCount = 0; for (const name of match.document.xpath('//*/fn:node-name(.)')) { nameCount = previous[name]; previous[name] = (nameCount > 0) ? nameCount + 1 : 1; } return previous; }
Each time the reducer is invoked, the match parameter contains the search result for a single document. That is, input of the following form. The precise properties in the input object can vary somewhat, depending on the search options.
{ index: 0, uri: '/my/document/uri', score: 14336, confidence: 0.3745157122612, fitness: 0.7490314245224, document: { documentContents } }
The following code puts all of the above together in a complete script. Notice that an empty object ( { } ) is passed to reduce as a seed value for the initial value of the previous input parameter.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .slice(0, 1000) .reduce(function nameExtractor(previous, match, index, state) { const nameCount = 0; for (const name of match.document.xpath('//*/fn:node-name(.)')) { nameCount = previous[name]; previous[name] = (nameCount > 0) ? nameCount + 1 : 1; } return previous; }, {}) .withOptions({search: 'score-random'}) .result();
Running this script with the documents created by Preparing to Run the Examples produces output similar to the following.
{"results":{ "title":8, "author":8, "edition":8, "format":8, "price":8, "synopsis":8 }, "estimate":8}
The property names are the JSON property names found in the sample documents. The property values are the number of occurrencesoccurrences of each name in the sampled documents. The values in this case are all the same because all the sample documents contain exactly the same properties. However, if you run the query on a less homogeneous set of documents you might get results such as the following:
{"results":{ "Placemark":52, "name":53, "Style":52, "ExtendedData":52, "SimpleData":208, "Polygon":574, "coordinates":610, "MultiGeometry":24, }, "estimate":58 }
If you want to retain the search results along with whatever computation is performed by your reducer, you must accumulate them yourself. For example, the reducer in the following script accumulates the results in an array in the result object:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.documents() .where(cts.jsonPropertyValueQuery('author','Mark Twain')) .reduce(function (prev, match, index, state) { prev.count++; prev.value += match.document.edition.price; prev.matches.push(match); if (state.isLast) { return {avgCost: prev.value / prev.count, matches: prev.matches}; } else { return prev; } }, {count: 0, value: 0, matches: []}) .result()
When run against the sample data from Preparing to Run the Examples, the output is similar to the following:
{"results":{ "avgCost": 13.25, "matches": [{"index":0, "uri": ...}, ...more matches...] }, estimate: 4 }
Example: Custom Reducer For Values Query
This example demonstrates using ValuesSearch.reduce to apply a custom reducer that computes an aggregate value from the results of a values query. The example relies on the sample data from Preparing to Run the Examples.
The query that produces the inputs to the reduction is a values query over the price JSON property. The database configuration should include a range index over price with scalar type float. The scalar type of the index determines the datatype of the value passed into the second parameter of the reducer.
The following code computes an average of the values of the price JSON property. Each call to the reducer accumulates the count and sum contributing to the final answer. When state.isLast becomes true, the final aggregate value is computed and returned. The reduction is seeded with an initial accumulator value of {count: 0, sum: 0}, through the second parameter passed to reduce.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') .where(cts.directoryQuery('/books/')) .reduce(function (accum, value, index, state) { const freq = cts.frequency(value); accum.count += freq; accum.sum += value * freq; return state.isLast ? (accum.sum / accum.count) : accum; }, {count: 0, sum: 0}) .result();
If you run the query in Query Console using the data from Preparing to Run the Examples, you should see output similar to the following:
16.125
Notice the use of cts.frequency in the example. The reducer is called once for each unique value in the index. If you're doing a reduction that depends on frequency, use cts.frequency on the input value to get this information.
Average and sum are only used here as a convenient simple example. In practice, if you needed to compute the average or sum, you would use built-in aggregate functions. For details, see Computing Aggregates Over Range Indexes.
Querying Lexicons and Range Indexes
- Querying the Values in a Lexicon or Index
- Finding Value Co-Occurrences in Lexicons and Indexes
- Querying Values in a Word Lexicon
- Computing Aggregates Over Range Indexes
- Constructing Lexicon and Range Index References
Querying the Values in a Lexicon or Index
Use jsearch.values to begin building a query over the values in a values lexicon or range index, and then use result to execute the query and return results. You can also use the values method to compute aggregates lexicon and index values; for details, see Computing Aggregates Over Range Indexes.
For example, the following code creates a values query over a range index on the title JSON property. The returned values are limited to those found in documents matching a directory query (where) and those that match the pattern *adventure* (match). The results are returned in frequency order (orderBy). Only the first 3 results are returned (slice).
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('title') .where(cts.directoryQuery('/books/')) .match('*adventure*') .orderBy('frequency') .slice(0,3) .result()
This query produces the following output when run against the sample data from Preparing to Run the Examples.
["Adventures of Huckleberry Finn", "Adventures of Tom Sawyer"]
Your database configuration must include an index or range index on each JSON property, XML element, XML element attribute, field, or path used in a values query.
For general information on lexicon queries, see Browsing With Lexicons.
Build and execute your values query following the pattern described in Query Design Pattern. The following table maps the applicable JSearch methods to the steps in the design pattern. Note that all the pipeline stages in Step 2 are optional, but you must use them in the order shown. For more details, see ValuesSearch in the MarkLogic Server-Side JavaScript Function Reference.
| Pattern Step | Method(s) | Notes | |
|---|---|---|---|
| 1 | Select resource | values |
Required. Select index and lexicon values as the resource to work with. Supply one or more lexicon or index references or JSON property names as input to values. |
| 2 | Add a query definition and result set pipeline | where |
Optional. Constrain the set of results (and frequency computation) to values from documents matching a query, as described in Constraining Lexicon Searches to a cts:query Expression. If you pass in multiple queries, they are implicitly AND'd together. You can create a cts.query from a QBE, query text, cts.query constructors, or any other technique that creates a cts.query. For details, see Creating a cts.query. |
match | groupInto |
Optional. You cannot use jsearch.values('title') .where(cts.directoryQuery('/books/')) .match('*adventure*') Use |
||
orderBy |
Optional. Specify the order of results. You can choose whether to order by frequency or item value, and ascending or descending order. For details, see Controlling the Ordering of Results | ||
slice |
Optional. Select a subset of values from the result set. The default slice is the first 10 values. For details, see Returning a Result Subset. | ||
map | reduce |
Optional. Apply a mapper or reducer function to the results. You cannot use map and reduce together. For details, see Transforming Results with Map and Reduce. |
||
| 3 | Add advanced options | withOptions |
Optional. Specify additional, advanced options that customize the query behavior. For details, see Using Options to Control a Query and ValuesSearch.withOptions. |
| 4 | Evaluate the query and get results | result |
Required. Execute the query and receive your results, optionally specifying whether to receive the results as a value or an Iterable. The default is a value (typically an array). |
Finding Value Co-Occurrences in Lexicons and Indexes
Use the jsearch.tuples method to find co-occurrences of values in lexicons and range indexes. Use tuples to begin building your query, and then use result to execute the query and return results. You can also use the tuples method to compute aggregates over tuples; for details, see Computing Aggregates Over Range Indexes.
For example, the following code creates a tuples query for 2-way co-occurences of the values in the author and format JSON properties. Only tuples in documents matching the directory query are considered (where). The results are returned in item order (orderBy).
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.tuples(['author','format']) .where(cts.directoryQuery('/books/')) .orderBy('item') .result()
This query produces the following output when applied to the data from Preparing to Run the Examples.
[["John Steinbeck", "audiobook"], ["John Steinbeck", "hardback"], ["John Steinbeck", "paperback"], ["Mark Twain", "hardback"], ["Mark Twain", "paperback"], ["Robert Frost", "paperback"]]
Your database configuration must include an index or range index on each JSON property, XML element, XML element attribute, field, or path used in a tuples query.
Build and execute your tuples query following the pattern described in Query Design Pattern. The following table maps the applicable JSearch methods to the steps in the design pattern. Note that all the pipeline stages in Step 2 are optional, but you must use them in the order shown. For more details, see TuplesSearch in the MarkLogic Server-Side JavaScript Function Reference.
| Pattern Step | Method(s) | Notes | |
|---|---|---|---|
| 1 | Select resource | tuples |
Required. Select index and lexicon value co-occurrences as the resource to work with. Supply one or more lexicon or index references or JSON property names as input to values. |
| 2 | Add a query definition and result set pipeline | where |
Optional. Constrain the set of tuples (and frequency computation) to values in documents matching a query, as described in Constraining Lexicon Searches to a cts:query Expression. If you pass in multiple queries, they are implicitly AND'd together. You can create a cts.query from a QBE, query text, cts.query constructors, or any other technique that creates a cts.query. For details, see Creating a cts.query. |
orderBy |
Optional. Specify the order of results. You can choose whether to order by frequency or item value, and ascending or descending order. For details, see Controlling the Ordering of Results | ||
slice |
Optional. Select a subset of tuples from the result set. The default slice is the first 10 tuples. For details, see Returning a Result Subset. | ||
map | reduce |
Optional. Apply a mapper or reducer function to the results. You cannot use map and reduce together. For details, see Transforming Results with Map and Reduce. |
||
| 3 | Add advanced options | withOptions |
Optional. Specify additional, advanced options that customize the query behavior. For details, see Using Options to Control a Query and TuplesSearch.withOptions. |
| 4 | Evaluate the query and get results | result |
Required. Execute the query and receive your results, optionally specifying whether to receive the results as a value or an Iterable. The default is a value (typically an array). |
Querying Values in a Word Lexicon
Use the jsearch.words method to create a word lexicon query, and then use result to execute the query and return results.
For example, the following code performs a word lexicon query for all words in the synopsis JSON property that begin with 'c' (match). Only occurrences in documents where the author property contains steinbeck (where) are returned. At most the first 5 words are returned (slice).
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.words('synopsis') .where(cts.jsonPropertyWordQuery('author', 'steinbeck')) .match('c*') .slice(0,5) .result();
When run against the data from Preparing to Run the Examples, this query produces the following output:
["Cain", "California", "Chronicles"]
Your database configuration must either enable the database-wide word lexicon or include a word lexicon on each JSON property, XML element, XML element attribute, or field used in a words query. For details on lexicon configuration, see Range Indexes and Lexicons in the Administrator's Guide.
For general information on lexicon queries, see Browsing With Lexicons.
Build and execute your word query following the pattern described in Query Design Pattern. The following table maps the applicable JSearch methods to the steps in the design pattern. Note that all the pipeline stages in Step 2 are optional, but you must use them in the order shown. For more details, see WordsSearch in the MarkLogic Server-Side JavaScript Function Reference.
| Pattern Step | Method(s) | Notes | |
|---|---|---|---|
| 1 | Select resource | words |
Required. Select index and word lexicons as the resource to work with. Supply one or more lexicon or index references or JSON property names as input to values. For example:// query word lexicon on a JSON property jsearch.words('synopsis'). ... // query the database wide word lexicon jsearch.words(jsearch.databaseLexicon()). ... // query the word lexicon on an XML element jsearch.words( jsearch.elementLexicon( fn.QName( 'http://marklogic.com/example', 'myElem'))) |
| 2 | Add a query definition and result set pipeline | where |
Optional. Constrain the set of tuples (and frequency computation) to words in documents matching a query, as described in Constraining Lexicon Searches to a cts:query Expression. If you pass in multiple queries, they are implicitly AND'd together. You can create a cts.query from a QBE, query text, cts.query constructors, or any other technique that creates a cts.query. For details, see Creating a cts.query. |
match |
Optional. Limit words to those matching a wildcard pattern. For example, the following match clause selects words beginning with 'c':import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.words('synopsis') .where(cts.directoryQuery('/books/')) .match('c*') |
||
orderBy |
Optional. Specify whether to list the results in ascending or descending order. For details, see Controlling the Ordering of Results | ||
slice |
Optional. Select a subset of tuples from the result set. The default slice is the first 10 results. For details, see Returning a Result Subset. | ||
map | reduce |
Optional. Apply a mapper or reducer function to the results. You cannot use map and reduce together. For details, see Transforming Results with Map and Reduce. |
||
| 3 | Add advanced options | withOptions |
Optional. Specify additional, advanced options that customize the query behavior. For details, see Using Options to Control a Query and WordsSearch.withOptions. |
| 4 | Evaluate the query and get results | result |
Required. Execute the query and receive your results, optionally specifying whether to receive the results as a value or an Iterable. The default is a value (typically an array). |
Computing Aggregates Over Range Indexes
You can compute aggregate values over range indexes and lexicons using built-in or user-defined aggregate functions using ValuesSearch.aggregate or TuplesSearch.aggregate. This section covers the following topics:
- Aggregate Function Overview
- Using Built-In Aggregate Functions
- Using Aggregate User-Defined Functions
Aggregate Function Overview
An aggregate function performs an operation over values or tuples in lexicons and range indexes. For example, you can use an aggregate function to compute the sum of values in a range index. You can apply an aggregate computation to the results of a values or tuples query using ValuesSearch.aggregate or TuplesSearch.aggregate.
MarkLogic Server provides built-in aggregate functions for many common analytical functions; for a list of functions, see Using Built-In Aggregate Functions. For a more detailed description of each built-in, see Using Builtin Aggregate Functions in the Search Developer's Guide.
You can also implement aggregate user-defined functions (UDFs) in C++ and deploy them as native plugins. Aggregate UDFs must be installed before you can use them. For details, see Implementing an Aggregate User-Defined Function in the Application Developer's Guide. You must install the native plugin that implements your UDF according to the instructions in Using Native Plugins in the Application Developer's Guide.
You cannot use the JSearch API to apply aggregate UDFs that require additional parameters.
Build and execute your aggregate computation following the pattern described in Query Design Pattern. The following table maps the applicable JSearch methods to the steps in the design pattern. Note that you must use the pipeline stages in Step 2 in the order shown. For more details, see ValuesSearch or TuplesSearch in the MarkLogic Server-Side JavaScript Function Reference.
| Pattern Step | Method(s) | Notes | |
|---|---|---|---|
| 1 | Select resource | values | tuples |
Required. Select index and lexicon values or tuples (co-occurrences) as the resource to work with. Supply one or more lexicon or index references or JSON property names as input. |
| 2 | Add a query definition and result set pipeline | where |
Optional. Constrain the values or tuples to values in documents matching a query, as described in Constraining Lexicon Searches to a cts:query Expression. If you pass in multiple queries, they are implicitly AND'd together. You can create a cts.query from a QBE, query text, cts.query constructors, or any other technique that creates a cts.query. For details, see Creating a cts.query. |
aggregate |
Required. Specify one or more built-in or user-defined aggregate functions. You can combine built-in and user-defined aggregates in the same query. For details, see Using Built-In Aggregate Functions and Using Aggregate User-Defined Functions. | ||
| 3 | Add advanced options | withOptions |
Optional. Specify additional, advanced options that customize the query behavior. For details, see Using Options to Control a Query and ValuesSearch.withOptions or TuplesSearch.withOptions. |
| 4 | Evaluate the query and get results | result |
Required. Execute the query and receive your results, optionally specifying whether to receive the results as a value or an Iterable. The default is a value (typically an array). |
Using Built-In Aggregate Functions
To use a builtin aggregate function, pass the name of the function to the aggregate method of a values or tuples query. The built-in aggregate functions only support tuples queries on 2-way co-occurrences. That is, you cannot use them on tuples queries involving more than 2 lexicons or indexes.
The following example uses built-in aggregate functions to compute the minimum, maximum, and average of the values in the price JSON property and produces the results shown. As with all values queries, the database must include a range index over the target property or XML element.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') .aggregate(['min','max','avg']) .result(); ==> {"min":8, "max":30, "avg":16.125}
The following built-in aggregate functions are supported on values queries:
| Values Aggregate Name | Description |
|---|---|
avg |
Compute the average of the values in a lexicon or range index. For details, see cts.avgAggregate. |
count |
Returns a count of the values in a lexicon or range index. For details, see cts.countAggregate. |
max |
Compute the maximum of the values in a lexicon or range index. For details, see cts.max. |
min |
Compute the minimum of the values in a lexicon or range index. For details, see cts.min. |
stddev |
Compute the frequency-weighted sample standard deviation of the values in a lexicon or range index. For details, see cts.stddev. |
stddev-population |
Compute the frequency-weighted sample standard deviation of the population from the values in a lexicon or range index. For details, see cts.stddevP. |
sum |
Compute the sum of the values in a lexicon or range index. For details, see cts.sumAggregate. |
variance |
Compute the frequency-weighted sample variance of the values in a lexicon or range index. For details, see cts.variance. |
variance-population |
Compute the frequency-weighted variance of population of the values in a lexicon or range index. For details, see cts.varianceP. |
The following built-in aggregate functions are supported on tuples queries:
| Tuples Aggregate Name | Description |
|---|---|
correlation |
Compute the frequency-weighted correlation of 2-way co-occurences. For details, see cts.correlation. |
covariance |
Compute the frequency-weighted correlation of 2-way co-occurrences. For details, see cts.covariance. |
covariance-population |
Compute the frequency-weighted correlation of the population of 2-way co-occurrences. For details, see cts.covarianceP. |
Using Aggregate User-Defined Functions
An aggregate UDF is identified by the function name and a relative path to the plugin that implements the aggregate, as described in Using Aggregate User-Defined Functions. You must install your UDF plugin on MarkLogic Server before you can use it in a query. For details on creating and installing aggregate UDFs, see Aggregate User-Defined Functions in the Application Developer's Guide.
Once you install your plugin, use jsearch.udf to create a reference to your UDF, and pass the reference to the aggregate clause of a values or tuples query. For example, the following script uses a native UDF called count provided by a plugin installed in the modules database under native/sampleplugin:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') .aggregate(jsearch.udf('native/sampleplugin', 'count')) .result();
For more details, see ValuesSearch.aggregate and TuplesSearch.aggregate.
Constructing Lexicon and Range Index References
This section provides a brief overview of the functions available for constructing the index and lexicon reference you may need for values queries, tuples queries, and facet generation.
Most JSearch interfaces that accept index or lexicon references also accept a simple JSON property name string. In most contexts, this is interpreted as a cts.jsonPropertyReference for a string property. If the referenced property (and associated index) have a type other than string, you can create a properly typed index reference as shown in these examples:
cts.jsonPropertyReference('price', ['type=float']) cts.jsonPropertyReference('start', ['type=date'])
Similar reference constructors are available for XML element indexes, XML element attribute index, path indexes, field indexes, and geospatial property, element, and path indexes. The following is a small sample of the available constructors:
Use the following reference constructors for the database-wide URI and collection lexicons. (These lexicons must be enabled on the database before you can use them.)
JSearch also provides the following word lexicon reference constructors for constructing references to word lexicons specifically for use with jsearch.words. Using these constructors ensures you only create word lexicons queries on lexicon types that support them.
- jsearch.databaseLexicon
- jsearch.jsonPropertyLexicon
- jsearch.elementLexicon
- jsearch.elementAttributeLexicon
- jsearch.fieldLexicon
For more details, see the MarkLogic Server-Side JavaScript Function Reference and Browsing With Lexicons.
Grouping Values and Facets Into Buckets
This section covers the following topics related to using the ValuesSearch.groupInto and FacetDefinition.groupInto to group values by range:
- Bucketing Overview
- Example: Generating Buckets With makeBuckets
- Example: Grouping Using Custom Buckets
Bucketing Overview
You can use the groupInto method to group values into ranges when performing a values query or generating facets. Such grouping is sometimes called bucketed search. The groupInto method of values and facets has the following form:
groupInto(bucketDefinition)
You can apply groupInto to a values query or a facet definition. For example:
// using groupInto with a values query jsearch.values(...).groupInto(bucketDefinition).result() // using groupInto for facet generation jsearch.facets( jsearch.facet(...).groupInto(bucketDefinition), ...more facet definitions... ).result()
A bucket definition can be an array of boundary values or an array of alternating bucket names and boundary value pairs. For geospatial buckets, a boundary value can be an object with lat and lon properties ({lat: latVal, lon: lonVal}). The JSearch API includes helper functions for creating bucket names (jsearch.bucketName), generating a set of buckets from a value range and step (jsearch.makeBuckets), and generating buckets corresponding to a geospatial heatmap (jsearch.makeHeatmap).
Buckets can be unnamed, use names generated from the boundary values, or use custom names. For example:
// Unnamed buckets with boundaries X < 10, 10 <= X < 20, and X > 20 groupInto([10,20]) // The same set of buckets with generated default bucket names groupInto([ jsearch.bucketName(),10, jsearch.bucketName(),20, jsearch.bucketName()]) // The same set of buckets with custom bucket names groupInto([ jsearch.bucketName('under $10'), 10, jsearch.bucketName('$10 to $19.99'), 20, jsearch.bucketName('over $20')]) // Explictly specify geospatial bucket boundaries groupInto([ jsearch.bucketName(),{lat: lat1, lon: lon1, jsearch.bucketName(),{lat: lat2, lon: lon2, jsearch.bucketName(),{lat: lat3, lon: lon3}])
You can create a bucket definition in the following ways:
- Define a set of unnamed buckets by creating an array of boundary values. For example,
[10,20]defines 3 buckets with boundariesX < 10,10 <= X < 20, andX > 20. - Define a set of named buckets by creating an array of (bucketName, upperBound) pairs. Use the
buckeNamehelper function to generate the name of each bucket. You can specify custom bucket names or groupInto generate bucket names from the boundary values. - Use the
makeBucketshelper function to create a set of buckets over a range of values (min and max) and a step or number of divisions. For example, create a series of buckets that each correspond to a decade over a 100 year time span. - Use the
makeHeatMaphelper function to generate buckets from a geospatial lexicon based on a heatmap box with latitude and longitude divisions.
The bounds for bucket for a scalar value or date/time range are determined by an explicit upper bound and the position of the bucket in a set of bucket definitions. For example, in the following custom bucket definition, each line represents one bucket as a name and upper bound.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') .groupInto([ jsearch.bucketName(), 10, jsearch.bucketName(), 20, jsearch.bucketName()]) .result()
The first bucket has no lower bound because it occurs first. The lower bound of the second bucket is the upper bound of the previous bucket (10), inclusive. The upper bound of the second bucket is 20, exclusive. The last bucket has no upper bound. When plugged into a values or facets query, the results are grouped into the following ranges:
x < 10 10 <= x < 20 20 <= x
For geospatial data, you can use makeHeatMap to sub-divide a region into boxes. For example, the following constraint includes a heat map that corresponds very roughly to the continental United States, and divides the region into a set of 20 boxes (5 latitude divisions and 4 longitude divisions).
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('incidents') .groupInto(makeHeatMap({ north: 49.0, east: -67.0, south: 24.0, west: -125.0, lonDivs: 4, latDivs: 5 })) .result()
When combined with a reducer that returns frequency, you can use the resulting set of boxes and frequencies to illustrate the concentration of points in each box, similar to a grid-based heat map.
You can create more customized geospatial buckets by specifying a series of latitude bounds and longitude bounds that define a grid in an object of the form {lat:[...], lon:[...]}. The points defined by the latitude bounds and longitude bounds are divided into box-shaped buckets. The lat and lon values must be ascending order. For example:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('incidents') .groupInto({lat: [15, 30, 45, 60, 75], lon: [0, 30, 60, 90, 120]}) .result()
For more details, see jsearch.makeHeatmap, cts:geospatial-boxes, and Creating Geospatial Facets.
Example: Generating Buckets With makeBuckets
The examples in this section demonstrate the following features:
- Using jsearch.makeBuckets to generate buckets for a values query.
- Using jsearch.makeBuckets to generate bucketed facets.
- Using a custom mapper to decorate your buckets.
The example uses makeBuckets to group date information by month, leveraging MarkLogic's built-in support for date, time and duration data..
The example assumes the following conditions exist in the database:
- The database contains documents of the following form describing events. Each document includes a
startproperty that represents the start date of the event.{ title: 'San Francisco Ocean Film Festival', venue: 'Fort Mason, San Francisco', start: '2015-02-27', end: '2015-03-01' }
- All the event documents of interest are in a collection with the URI 'events'.
- The database configuration includes an element range index of type 'date' on the
startproeprty.
The following query groups the values in the lexicon for the year 2015 by month, using jsearch.makeBuckets and ValuesSearch.groupInto. The results include frequency data in each bucket.
import jsearch from '/MarkLogic/jsearch.mjs'; const events = jsearch.collections('events'); events.values(cts.jsonPropertyReference('start', ['type=date'])) .groupInto( jsearch.makeBuckets({ min: xs.date('2015-01-01'), max: xs.date('2015-12-31'), step: xs.yearMonthDuration('P1M')})) .map({frequency: 'item', names: ['bucket', 'count']}) .result()
Notice the use of a 1 month duration (...ÄòP1M') for the step between buckets. You can use many MarkLogic date, dateTime, and duration operations from Server-side JavaScript. For details, see JavaScript Duration and Date Arithmetic and Comparison Methods in the JavaScript Reference Guide.
The query generates results similar to the following:
[ { "bucket": { "minimum": "2015-02-27", "maximum": "2015-02-27", "lowerBound": "2015-02-01", "upperBound": "2015-03-01" }, "count": 1 }, { "bucket": { "minimum": "2015-03-07", "maximum": "2015-03-14", "lowerBound": "2015-03-01", "upperBound": "2015-04-01" }, "count": 2 }, ... ]
You can use a custom mapper to name each bucket after the month it covers. Note that plugging in a custom mapper also eliminates the frequency data, so you must add it back in explicitly. The following example mapper adds a month name and count property to each bucket:
// For mapping month number to user-friendly bucket name const months = [ 'January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December' ]; // Add a name and count field to each bucket. Use month for name. function supplementBucket(bucket) { // get a mutable copy of the input const result = bucket.toObject(); // Compute index into month names. January == month 1 == index 0. const monthNum = fn.monthFromDate(xs.date(bucket.lowerBound)) - 1; result.name = months[monthNum]; result.count = cts.frequency(bucket); return result; }; // Generate buckets and counts import jsearch from '/MarkLogic/jsearch.mjs'; const events = jsearch.collections('events'); events.values(cts.jsonPropertyReference('start', ['type=date'])) .groupInto(jsearch.makeBuckets({ min: xs.date('2015-01-01'), max: xs.date('2015-12-31'), step: xs.yearMonthDuration('P1M')})) .map(supplementBucket) .result()
The output generated is similar to the following:
[ { "minimum": "2015-02-27", "maximum": "2015-02-27", "lowerBound": "2015-02-01", "upperBound": "2015-03-01", "name": "February", "count": 1 }, { "minimum": "2015-03-07", "maximum": "2015-03-14", "lowerBound": "2015-03-01", "upperBound": "2015-04-01", "name": "March", "count": 2 }, ... ]
Similarly, you can use the FacetDefinition.groupInto and FacetDefinition.map when generating facets for a document search with jsearch.facets. For example, the following query generates facets based on the same set of buckets:
import jsearch from '/MarkLogic/jsearch.mjs'; const events = jsearch.collections('events'); events.facets( events.facet('events', cts.jsonPropertyReference('start', ['type=date'])) .groupInto(jsearch.makeBuckets({ min: xs.date('2015-01-01'), max: xs.date('2015-12-31'), step: xs.yearMonthDuration('P1M')})) .map(supplementBucket), events.documents() ).result()
The output from this query is similar to the following:
{"facets": { "events": [ { "minimum": "2015-02-27", "maximum": "2015-02-27", "lowerBound": "2015-02-01", "upperBound": "2015-03-01", "name": "February", "count": 1 }, { "minimum": "2015-03-07", "maximum": "2015-03-14", "lowerBound": "2015-03-01", "upperBound": "2015-04-01", "name": "March", "count": 2 }, ... ]}, "documents": [ ...] }
For more details on faceting, see Including Facets in Search Results.
Example: Grouping Using Custom Buckets
This example demostrates how to use custom buckets for grouping. The example applies the grouping to facet generation, but you can use the same technique with a values query.
The following code defines custom buckets that group the values of the 'price' JSON property into 3 price range buckets.
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.facets( jsearch.facet('Price','price') .groupInto([ jsearch.bucketName('under $10'), 10, jsearch.bucketName('$10 to $19.99'), 20, jsearch.bucketName('over $20') ])) .where(cts.directoryQuery('/books/')) .result();
If the lexicon contains the values [8, 9, 10, 16, 18, 20, 30], then the query results in the following output. (Comments were added for clarity and are not part of the actual output.)
{"facets": { "price": { "under $10": { // bucket label (for display purposes) "value": { "minimum": 8, // min value found in bucket range "maximum": 9, // max value found in bucket range "upperBound": 10 // bucket upper bound }, "frequency": 2 }, "$10 to $19.99": { "value": { "minimum": 10, "maximum": 18, "lowerBound": 10, "upperBound": 20 }, "frequency": 4 }, "over $20": { "value": { "minimum": 20, "maximum": 30, "lowerBound": 20 }, "frequency": 2 } } } }
The results tell you, for example, that the price lexicon contains values under 10, with the maximum value in that range being 9 and the minimum being 8. Similarly, the lexicon contains values greater than or equal to 10, but less than 20. The minimum value found in that range is 10 and the maximum value is 18.
f you use the same grouping specification with ValuesSearch.groupInto, you get the same information, but it is arranged slightly differently. For example, the following output was produced using the values operation with the same groupInto clause.
[ { "minimum": 8, "maximum": 9, "upperBound": 10, "name": "under $10" }, { "minimum": 10, // min value found in bucket range "maximum": 18, // max value found in bucket range "lowerBound": 10, // bucket lower bound "upperBound": 20, // bucket upper bound "name": "$10 to $19.99" // bucket label (for display purposes) }, { "minimum": 20, "maximum": 30, "lowerBound": 20, "name": "over $20" } ]
If you specify an empty bucket name, a default name is generated from the bucket bounds. For example, the following code applies a similar set of buckets to a values query, using generated bucket names:
import jsearch from '/MarkLogic/jsearch.mjs'; jsearch.values('price') .where(cts.directoryQuery('/books/')) .groupInto([ jsearch.bucketName(), 10, jsearch.bucketName(), 20, jsearch.bucketName() ]) .result();
This code produces the following output. The bucket min, max, and bounds are the same as before, but the bucket names are the default generated ones:
[ { "minimum": 8, "maximum": 9, "upperBound": 10, "name": "x < 10" }, { "minimum": 10, "maximum": 19, "lowerBound": 10, "upperBound": 20, "name": "10 <= x < 20" }, { "minimum": 20, "maximum": 30, "lowerBound": 20, "name": "20 <= x" } ]
Preparing to Run the Examples
Use the instructions and scripts in this section to set up your MarkLogic environment to run the examples in this chapter. This includes loading the sample documents and configuring your database to have the required indexes and lexicons.
Configuring the Database
This section guides you through creation of a database configured to run the examples in this chapter. Many examples do not require the indexes, and only the word lexicon query examples require a word lexicon. However, this setup will ensure you have the configuration needed for all the examples.
Running the setup scripts below will do the following. The configuration details are summarized in a table at the end of the section.
- Create a database named jsearch-ex with one forest, named jsearch-ex-1, attached.
- Create element range indexes on the
title,author,format, andpriceJSON properties found in the sample documents. - Create an element word lexicon on the title JSON property found in the sample documents.
The instructions below use Query Console and XQuery to create and configure the database. You do not need to know XQuery to use these instructions. However, if you prefer to do the setup manually using the Admin Interface, see the table at the end of this section for configuration details.
Follow this procedure to create and configure the example database.
- In your browser, navigate to Query Console and authenticate as a user with Admin privileges. For example, navigate to the following URL is MarkLogic is installed on localhost:
http://localhost:8000/qconsole
- Use the + button to create a new, empty script.
- Select XQuery in the Query Type dropdown.
- Paste the following in Query Console as the text of the script just created.
xquery version "1.0-ml"; (: Create the database and forest :) import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $config := admin:get-configuration() let $config := admin:database-create( $config, "jsearch-ex", xdmp:database("Security"), xdmp:database("Schemas")) let $config := admin:forest-create( $config, "jsearch-ex-1", xdmp:host(), (), (), ()) return admin:save-configuration($config); (: Attach the forest to the database :) import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $config := admin:get-configuration() let $config := admin:database-attach-forest( $config, xdmp:database("jsearch-ex"), xdmp:forest("jsearch-ex-1")) return admin:save-configuration($config);
- Click the Run button to execute the script. The database and forest are created.
- Optionally, confirm creation of the database using the Admin Interface. For example, navigate to the following URL:
http://localhost:8001
- In Query Console, click + to create another new script. Confirm that the Query Type is still XQuery.
- Paste the following in Query Console as the text of the script just created. This script will create the indexes and lexicons needed by the examples.
xquery version "1.0-ml"; import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $title-index := admin:database-range-element-index( "string", "", "title", "http://marklogic.com/collation/", fn:false()) let $author-index := admin:database-range-element-index( "string", "", "author", "http://marklogic.com/collation/", fn:false()) let $format-index := admin:database-range-element-index( "string", "", "format", "http://marklogic.com/collation/", fn:false()) let $price-index := admin:database-range-element-index( "float", "", "price", "", fn:false()) let $config := admin:get-configuration() let $config := admin:database-add-range-element-index( $config, xdmp:database("jsearch-ex"), ($title-index, $author-index, $format-index, $price-index)) return admin:save-configuration($config); import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $title-lexicon := admin:database-element-word-lexicon( "", "title", "http://marklogic.com/collation/") let $config := admin:get-configuration() let $config := admin:database-add-element-word-lexicon( $config, xdmp:database("jsearch-ex"), ($title-lexicon)) return admin:save-configuration($config);
- Click the Run button. The range indexes and word lexicon are created.
You should now proceed to Loading the Sample Documents.
If you choose to create the example environment manually with the Admin Interface, use the configuration summary below.
Loading the Sample Documents
After you create and configure the sample database, follow the instructions in this section to load the sample documents.
- In your browser, navigate to Query Console and authenticate as a user with write privileges for the
jsearch-exdatabase. For example, navigate to the following URL is MarkLogic is installed on localhost:http://localhost:8000/qconsole
- Use the + button to create a new, empty script.
- Select
JavaScriptin the Query Type dropdown. - Select
jsearch-exin the Content Source dropdown.You will not see it if you have just finished creating and configuring the database and are still using the same Query Console session. If this happen, reload Query Console in your browser to refresh the Content Source list.
- Paste the following in Query Console as the text of the script just created.
const directory = '/books/'; const books = [ {uri: 'frost1.json', data: { title: 'Collected Works', author: 'Robert Frost', edition: {format: 'paperback', price: 30 }, synopsis: 'The complete works of the American Poet Robert Frost.' }}, {uri: 'twain1.json', data: { title: 'Adventures of Tom Sawyer', author: 'Mark Twain', edition: {format: 'paperback', price: 9 }, synopsis: 'Tales of mischief and adventure along the Mississippi River with Tom Sawyer, Huck Finn, and Becky Thatcher.' }}, {uri: 'twain2.json', data: { title: 'Adventures of Tom Sawyer', author: 'Mark Twain', edition: {format: 'hardback', price: 18 }, synopsis: 'Tales of mischief and adventure along the Mississippi River with Tom Sawyer, Huck Finn, and Becky Thatcher.' }}, {uri: 'twain3.json', data: { title: 'Adventures of Huckleberry Finn', author: 'Mark Twain', edition: {format: 'paperback', price: 8 }, synopsis: 'The adventures of Huck, a boy of 13, and Jim, an escaped slave, rafting down the Mississippi River in pre-Civil War America.' }}, {uri: 'twain4.json', data: { title: 'Adventures of Huckleberry Finn', author: 'Mark Twain', edition: {format: 'hardback', price: 18 }, synopsis: 'The adventures of Huck, a boy of 13, and Jim, an escaped slave, rafting down the Mississippi River in pre-Civil War America.' }}, {uri: 'steinbeck1.json', data: { title: 'The Grapes of Wrath', author: 'John Steinbeck', edition: {format: 'paperback', price: 10 }, synopsis: 'Chronicles the 1930s Dust Bowl migration of one Oklahoma farm family, from their homestead and forced to the promised land of California.' }}, {uri: 'steinbeck2.json', data: { title: 'Of Mice and Men', author: 'John Steinbeck', edition: {format: 'hardback', price: 20 }, synopsis: 'A tale of an unlikely pair of drifters who move from job to job as farm laborers in California, until it all goes horribly awry.' }}, {uri: 'steinbeck3.json', data: { title: 'East of Eden', author: 'John Steinbeck', edition: {format: 'audiobook', price: 16 }, synopsis: 'Follows the intertwined destinies of two California families whose generations reenact the fall of Adam and Eve and the rivalry of Cain and Abel.' }} ]; books.forEach( function(book) { xdmp.eval( 'declareUpdate(); xdmp.documentInsert(uri, data, xdmp.defaultPermissions(), ["classics"]);', {uri: directory + book.uri, data: book.data} ); });
- Click the Run button to execute script. The sample documents are inserted into the database.
- Optionally, click the Explore button to examine the database contents. You should see 8 JSON documents with URIs such as /books/frost1.json.
The jsearch-ex database is now fully configured to support all the samples in this chapter in Query Console. When running the examples, set the Content Source to jsearch-ex and the Query Type to JavaScript.