
MarkLogic Server 11.0 Product DocumentationSearch Developer's Guide — Chapter 18
Understanding and Using Stemmed Searches
This chapter describes how to use the stemmed search functionality in MarkLogic Server. The following sections are included:
- Stemming in MarkLogic Server
- Enabling Stemming
- Stemmed Searches Versus Word Searches
- Using cts:highlight to Emphasize a Query Match
- Using cts:contains to Test for a Stemmed Match
- Interaction With Wildcard Searches
- Using a User-Defined Stemmer Plugin
The Role of Stemming and Tokenization in Search
Tokenization splits a run of text into individual tokens, such as words, whitespace, and punctuation. The rules used to split text into tokens is language-specific. For example, in a language like English, word tokens are usually separated by whitespace and punctuation tokens. Thus, a string such as ran, slept tokenizes to the following in English:
Tokenization is applied to documents when they are indexed, and to query text when you perform a search.
Stemming maps a word to its common lemma (stem). Thus, in the example above, ran stems to the verb run and slept stems to the verb sleep. Like tokenization, stemming rules are language-specific.
An unstemmed search matches only the word form you're searching for. For example, searching for ran will not match a document containing runs. When stemmed search is enabled, the search matches the exact term, plus words with the same stem. Thus, a search for ran will also match documents containing runs or running because they all share the stem run in English.
Stemming in MarkLogic Server
MarkLogic Server supports stemming in English and other languages. For a list of languages in which stemming is supported, see Supported Languages. You can also create a user-defined stemmer to add support for other languages; for details, see Using a User-Defined Stemmer Plugin.
The stem of a word is not based on spelling. For example, card and cardiac have different stems even though the spelling of cardiac begins with card. On the other hand, running and ran have the same stem (run) even though their spellings are quite different. If you want to search for a word based on partial pattern matching (like the card and cardiac example above), use wildcard searches as described in Understanding and Using Wildcard Searches.
The stemming supported in MarkLogic Server does not cross different parts of speech. For example, conserve (verb) and conservation (noun) are not considered to have the same stem because they have different parts of speech. Consequently, if you search for conserve with stemmed searches enabled, the results will include documents containing conserve and conserves, but not documents with conservation (unless conserve or conserves also appears).
Stemming is language-specific. Each word evaluated in the context of a specific language. A term in one language will not match a stemmed search for the same term in another language. The language can be specified with an xml:lang attribute or by several other methods. For details on how languages affect queries, see Querying Documents By Languages.
Enabling Stemming
To use stemming in your searches, stemming must be enabled in your database configuration. All new databases created in MarkLogic Server have stemmed searches disabled by default. You can enable stemmed searches after initial creation of your database.
Stemmed searches are supported by special indexes. If you enable stemmed searches in an existing database, you must either reload or reindex the database to ensure that you get stemmed results from searches. You should plan on allocating additional disk space of about twice the size of the source content if you enable stemmed searches.
There are three types of stemming available in MarkLogic Server: basic, advanced, and decompounding. The following table describes the stemming options available on the database configuration page of the Admin Interface.
When stemmed searches are enabled for a database, you can enable and disable the use of stemming on a per query basis through options. Query constructors such as cts:word-query, cts:element-word-query, and cts:element-value-query support stemmed and unstemmed options. For more details on these functions, see the MarkLogic XQuery and XSLT Function Reference.
Query terms that contain a wildcard will not be stemmed. If you leave the stemming option unspecified, the database configuration determines whether or not stemming is applied to words that do not contain a wildcard.
If stemming is turned off in the database, and stemming is explicitly specified in the query, the query will throw an error.
Stemmed Searches Versus Word Searches
The stemmed search indexes and word search (unstemmed) indexes have overlapping functionality, and there is a good chance you can get the results you want with only the stemmed search indexes enabled (that is, leaving the word search indexes turned off).
Stemmed searches return relevance-ranked results for the words you search for as well as for words with the same stem as the words you search for. Therefore, you will get the same results as with a word search plus the results for items containing words with the same stem. In most search applications, this is the desirable behavior.
The only time you need to also have word search indexes enabled is when your application requires an exact word search to only return the exact match results (that is, to not return results based on stemming).
Additionally, the stemmed search indexes take up less disk space than the word search (unstemmed) indexes. You can therefore save some disk space and decrease load time when you use the settings of stemmed search enabled and word search turned off in the database configuration. Every index has a cost in terms of disk space used and increased load times. You have to decide based on your application requirements if the cost of creating extra indexes is worthwhile for your application, and whether you can fulfill the same requirements without some of the indexes.
If you do need to perform word (unstemmed) searches when you only have stemmed search indexes enabled (that is, when word searches are turned off in the database configuration), you must do so by first doing a stemmed search and then filtering the results with an unstemmed cts:query, as described in Unstemmed Searches.
Using cts:highlight to Emphasize a Query Match
Because stemming enables query matches for terms that do not have the same spelling, it can sometimes be difficult to find the words that actually caused the query to match. You can use cts:highlight to test and/or highlight the words that actually matched the query. For details on cts:highlight, see the MarkLogic XQuery and XSLT Function Reference and Highlighting Search Term Matches.
Using cts:contains to Test for a Stemmed Match
You can use cts:contains to test if a word matches a query. The cts:contains function returns true if there is a match, false if there is no match. For example, you can use the following function to test if a word has the same stem as another word.
xquery version "1.0-ml"; declare function local:same-stem( $word1 as xs:string, $word2 as xs:string) as xs:boolean { cts:contains(text{$word1},$word2) }; (: The following returns true because running has the same stem as run :) local:same-stem("run", "running")
Interaction With Wildcard Searches
For information about how stemmed searches and Wildcard searches interact, see Interaction with Other Search Features.
Using a User-Defined Stemmer Plugin
You can use a user-defined stemmer plugin to affect how MarkLogic matches a word to its stems during search term resolution. You create a user-defined stemmer in C++ by implementing a subclass of the marklogic::StemmerUDF base class and deploying it to MarkLogic as a native plugin. The StemmerUDF class is a UDF (User Defined Function) interface.
MarkLogic also provides several built-in stemmer plugins that you can use to customize stemming instead of implementing your own. For details, see Customization Using a Built-In Lexer or Stemmer.
This section covers the following topics:
- When to Consider a User-Defined Stemmer
- StemmerUDF Interface Summary
- Understanding User-Defined Stemmer Control Flow
- Implementation Guidelines for User-Defined Stemmers
- Creating and Deploying a User-Defined Stemmer Plugin
- Registering a User-Defined Stemmer with MarkLogic
- Testing a User-Defined Stemmer
- Error Handling and Logging
When to Consider a User-Defined Stemmer
MarkLogic provides several built-in stemmers that you can configure for a language if you are not satisfied with the default stemmer. The following are some use cases in which you might consider implementing a your own stemmer:
- You need to stem a language that is not directly supported by MarkLogic.
- You want to use a specific 3rd party library for stemming for a given language.
- You need to use advanced stemming to obtain variants such as normalization and spelling variants not otherwise available.
- You require special format stemming in the context of specific data fields where the requirements are more complicated than simple reclassification.
In some cases, you might also need a custom lexer or custom dictionary. For example, if you're working with a language not supported by MarkLogic, you probably also need a custom lexer. For details, see Custom Tokenization and Custom Dictionaries for Tokenizing and Stemming.
StemmerUDF Interface Summary
You implement a user-defined stemmer as a subclass of the MarkLogic::StemmerUDF base class. StemmerUDF is defined in MARKLOGIC_INSTALL_DIR/include/MarkLogic.h. You can find detailed documentation about the class in the User-Defined Function API reference and in MarkLogic.h. You can find an example implementation in MARKLOGIC_INSTALL_DIR/Samples/NativePlugins.
The following table contains a brief summary of the key methods of StemmerUDF. For a discussions of how the methods are used by MarkLogic, see Understanding User-Defined Stemmer Control Flow.
| LexerUDF Method | Description |
|---|---|
initialize |
Initialize a StemmerUDF object after construction. This method is only called once per stemmer object. |
reset |
Prepare the stemmer to iterate over stems for a word. The first stem should be available through StemmerUDF::stem after calling this method. The preferred stem (if one exists) should be the first stem available. |
| start | Set the stemmer to the start of the list of stems. It should be possible to iterate over the stems repeatedly by successively calling start. |
next |
Advance the stemmer to the next stem. Returns false if there are no more stems. |
stem |
Return the current stem. Returns null if there is no current stem. |
| delegate | Returns true if stemming delegates to the default stemmer, instead of or in addition to this custom stemmer. For details, see Understanding Stemming Delegation. |
close |
Release the stemmer resources. This method is called when the stemmer is no longer needed. |
Understanding User-Defined Stemmer Control Flow
When stemmed searches are enabled, MarkLogic can use either the default stemming plugin for a language, a user-defined stemming plugin, or both (via delegation). This section describes how MarkLogic interacts with a user-defined stemmer. See the following topics:
- When MarkLogic Uses a User-Defined Stemmer
- StemmerUDF Object Creation and Management
- Interaction During Stemming
When MarkLogic Uses a User-Defined Stemmer
When stemmed searches are enabled, stemming is performed when indexing documents and when evaluating queries. For more details, see Tokenization and Stemming.
When a word is eligible for stemming:
- MarkLogic first checks for matching entries in any custom dictionary for the language. If an entry is found, the stems from the dictionary are used.
- If no custom dictionary entry is found, then MarkLogic consults any configured custom stemmer, which could be a built-in stemmer plugin or a user-defined stemmer plugin, as described in Stemming Customization.
- MarkLogic might also consult the default stemming plugin for the language, depending on the delegation configuration. For details, see Understanding Stemming Delegation.
Thus, a user-defined stemming plugin will only be invoked when all the following conditions are met:
- Stemmed search is enabled on the database. For details, see Understanding the Text Index Settings in the Administrator's Guide.
- Stemming is needed in a language configured to use a user-defined stemming plugin. For details, see Configuring Tokenization and Stemming Plugins.
- No custom stemming dictionary is configured for the current language, or the configured dictionary contains no entry for the word under consideration.
For more information on custom dictionaries, see Custom Dictionaries for Tokenizing and Stemming.
StemmerUDF Object Creation and Management
StemmerUDF objects are created on demand and kept in a pool for re-use.
Stemmers tend to be heavy-weight objects, so MarkLogic maintains a (per-language) pool of stemmer objects for re-use. When MarkLogic needs one of your StemmerUDF objects, it first checks to see if one is available from the pool. If not, MarkLogic creates one using the object factory obtained during plugin registration. MarkLogic then calls the object's initialize method.
When a stemming task completes, the stemmer is returned to the pool unless it is marked as stale. MarkLogic can choose to mark a stemmer stale, or a stemmer can flag itself as stale by returning true from its StemmerUDF::isStale method.
When a stemmer is no longer needed, MarkLogic calls its StemmerUDF::close method. This enables the stemmer to deallocate memory and release other resources, as needed.
Interaction During Stemming
The following diagram is a high level illustration of how MarkLogic interacts with a StemmerUDF object while finding stems. The actual stemming process is more complex and has parts not represented here.
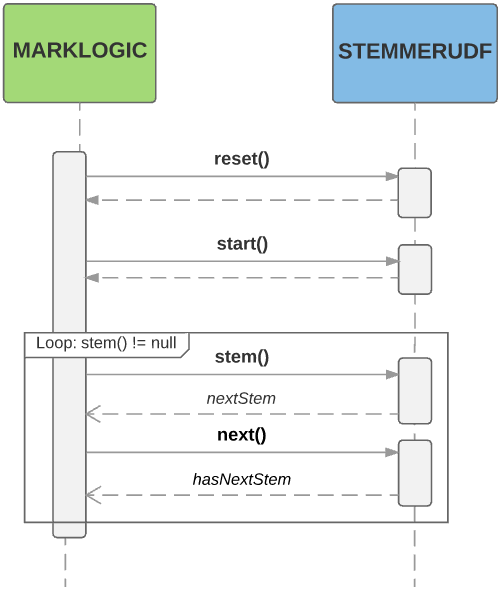
It is common to iterate over the stems for a word more than once. The StemmerUDF::start method is used to reset the iteration back to the first stem.
You can choose to have the default stemmer contribute stems instead of or in addition to your stemmer by returning true from the delegate method. For details, see Understanding Stemming Delegation.
Implementation Guidelines for User-Defined Stemmers
When implementing a StemmerUDF subclass, keep the following guidelines in mind.
Your implementation runs in the same memory and process space as MarkLogic Server, so errors in your implementation can crash MarkLogic Server. Before deploying a custom lexer, you should read and understand Using Native Plugins in the Application Developer's Guide. See also Testing a User-Defined Stemmer.
- You must implement a subclass of
marklogic::StemmerUDFfor each stemming algorithm you want to use. - Stemming is a low-level, inner-loop operation that MarkLogic performs during indexing (including document ingestion) and query evaluation. Your stemmer should introduce as little overhead as possible.
- If the input word has a preferred stem, it should be the first stem returned after calling
StemmerUDF::resetorStemmerUDF::start. The preferred stem is the only stem used when stemmed search is configured at the basic level. - Indicate contractions with the = character and compound words with the # character. For example, de=le for the French word du, or Kind#Platz for the German word Kinderplatz.
- The tokenizer can optionally pass along a Part of Speech (POS) for the word being stemmed. The POS is supplied to
StemmerUDF::reset. Stemming only makes use of this data for Japanese by default, but you can choose to use it in your stemmer. - The stemmer owns the memory allocated for the stem returned by the
stemmethod, and is responsible for releasing it when appropriate. Your stemmer can be called many times per word, so you should choose an efficient allocation strategy. - Your implementation does not have to be thread safe. MarkLogic will instantiate a new stemmer object in each thread in which it wants to perform stemming.
- Report errors using the
Reporterobject that is passed to mostStemmerUDFmethods, rather than by throwing exceptions. For details, see Error Handling and Logging. - You might also want to support your language with a custom lexer and/or a custom dictionary. To learn more about customization options, see Stemming and Tokenization Customization.
Creating and Deploying a User-Defined Stemmer Plugin
Follow the steps below to create and deploy a stemmer UDF in MarkLogic as a native plugin. A complete example is available in MARKLOGIC_DIR/Samples/NativePlugins.
- Implement a subclass of the C++ class
marklogic::StemmerUDF. See MARKLOGIC_DIR/include/MarkLogic.hfor interface details. - Implement an extern "C" function called
marklogicPluginto perform plugin registration. For details, see Registering a Native Plugin at Runtime in the Application Developer's Guide. - Build a dynamically linked library containing your UDF and registration function. You should use the Makefile in MARKLOGIC_DIR
/Samples/NativePluginsas the basis for building your plugin. For more details, see Building a Native Plugin Library in the Application Developer's Guide. - Following the directions in Using Native Plugins to package and install your plugin. See the note below about dependent libraries.
- Configure your stemmer as the stemmer plugin for at least one language. For details, see Configuring Tokenization and Stemming Plugins.
The native plugin interface includes support for bundling dependent libraries in the native plugin zip file. However, many 3rd party natural language processing tools are large, complex, and have strict installation directory requirements. If you are using such a packge, you should install the 3rd party package package independently on each host in the cluster, rather than trying to include it inside your native plugin package.
Registering a User-Defined Stemmer with MarkLogic
A native plugin becomes available for use once you install it, but it will not be loaded until there is a reason to use it. For example, a plugin containing only a stemmer UDF is only loaded if it is associated with at least one language and MarkLogic needs to stem a word in that language.
When MarkLogic loads a native plugin, it performs a registration handshake to obtain details about the plugin such as what capabilities the plugin provides. This handshake is performed through an extern "C" function named marklogicPlugin that must be part of every native plugin.
The following code is an example of a registration function for a plugin that registers only a single stemmer capability. Assume the plugin implements a StemmerUDF subclass named MyStemmerUDF. The stemmer is registered with the plugin id sample_stemmer.
extern "C" PLUGIN_DLL void marklogicPlugin(Registry& r) { r.version(); r.registerStemmer<MyStemmerUDF>("sample_stemmer"); }
The plugin id returned by the registerStemmer method, along with the relative path under which the plugin is installed, is used elsewhere to identify your user-defined stemming plugin.
For details, see Registering a Native Plugin at Runtime in the Application Developer's Guide. For a complete example, see the code in MARLOGIC_DIR/Samples/NativePlugins.
Testing a User-Defined Stemmer
You can test your stemmer implementation in the following ways:
- Create standalone test scaffolding.
- Use the cts:stem XQuery function or the cts.stem Server-Side JavaScript function to exercise your plugin after it is installed and configured for at least one language.
Testing your stemmer standalone during development is highly recommended. It is much easier to debug your code in this setup. Also, since it is possible for native plugin code to crash MarkLogic, it is best to test and stabilize your code outside the server environment.
You can find example test scaffolding in MARKLOGIC_DIR/Samples/NativePlugins/TestStemTok.cpp. See the main() function for a starting point.
Error Handling and Logging
Use marklogic::Reporter to log messages and notify MarkLogic Server of fatal errors. Your code should not report errors to MarkLogic Server by throwing exceptions.
Report non-fatal errors and other messages using marklogic::Reporter::log. This method logs a message to the MarkLogic Server error log and returns control to your code. Most methods of LexerUDF accept a marklogic::Reporter input parameter.
Report fatal errors using marklogic::Reporter::error. You should reserve calls to Reporter::error for serious errors from which no recovery is possible. Reporting an error via Reporter::error has the following effects:
- If you report a fatal stemming error during document insertion, the insertion transaction aborts.
- If you report a fatal stemming error during reindexing, reindexing of the document fails.
- Control does not return to your code. Stemming stops.
- MarkLogic Server returns
XDMP-UDFERRto the application. Your error message is included in theXDMP-UDFERRerror.
The following snippet reports an error and aborts tokenization:
#include "MarkLogic.h" using namespace marklogic; ... void ExampleUDF::next(Reporter& r) { ... r.log(Reporter::Error, "Bad codepoint."); }
For more details, see the marklogic::Reporter class in MARKLOGIC_DIR/include/MarkLogic.h.