Matches for cat:guide/ingestion have been highlighted.


MarkLogic Server 11.0 Product DocumentationLoading Content Into MarkLogic Server — Chapter 2
Controlling Document Format
Each document in a MarkLogic Server database has a format associated with it. The format is based on the root node of the document. Once a document has been loaded as a particular format, you cannot change the format unless you replace the root node of the document with one of a different format. You can replace the root node of a document to change its format in a number of ways, including reloading the document while specifying a different format, deleting the document and then loading it again with the same URI, or replacing the root node with one of a different format.
Documents loaded into a MarkLogic Server database in JSON, XML, or text format are always stored in UTF-8 encoding. Documents loaded in JSON, XML, or text format must either already be in UTF-8 encoding or the UTF-8 encoding must be explicitly specified during loading using options available in the load APIs. For example, you might use the encoding option of the xdmp:document-load function. For more details, see Encodings and Collations in the Search Developer's Guide.
The following topics are included:
- Supported Document Formats
- Choosing a Binary Format
- Implicitly Setting the Format Based on the MIME Type
- Explicitly Setting the Format
- Determining the Format of a Document
Terminology
The following terms are used in this topic.
| Term | Definition |
|---|---|
| document format | Refers to how documents are stored in MarkLogic databases: JSON, XML, binary, or text format. |
| QName | QName stands for qualified name and defines a valid identifier for elements and attributes. QNames are used to reference particular elements or attributes within XML documents. |
| small binary document | A binary document stored in a MarkLogic database whose size does not exceed the large size threshold. For details, see Choosing a Binary Format. |
| large binary document | A binary document stored in a MarkLogic database whose size exceeds the large size threshold. For details, see Choosing a Binary Format. |
| external binary document | A binary document that is not stored in a MarkLogic database and whose contents are not managed by the server. For details, see Choosing a Binary Format. |
| CLOB | Character large object documents, or text documents. |
| BLOB | Binary large object documents, binary data stored as a single entity. Typically images, audio, or other multimedia object. |
Supported Document Formats
MarkLogic supports the following document formats:
JSON Format
Documents that are in JSON format have special characteristics that enable you to do more with them. For example, you can use XPath expressions to search through to particular parts of the document and you can use the whole range of cts:query constructors to perform fine-grained search operations, including property-level search.
JSON documents are indexed when they are loaded. The indexing speeds up query response time. The type of indexing is controlled by the configuration options set on your document's destination database. JSON documents are a single fragment, and the maximum size of a fragment (and therefore of a JSON document) is 512 MB for 64-bit machines.
XML Format
Documents that are in XML format have special characteristics that enable you to do more with them. For example, you can use XPath expressions to search through to particular parts of the document and you can use the whole range of cts:query constructors to perform fine-grained search operations, including element-level search.
XML documents are indexed when they are loaded. The indexing speeds up query response time. The type of indexing is controlled by the configuration options set on your document's destination database. One technique for loading extremely large XML documents is to fragment the documents using various elements in the XML structure. The maximum size of a single XML fragment is 512 MB for 64-bit machines. For more details about fragmenting documents, see Fragments in the Administrator's Guide.
Binary Format
Binary documents are loaded into the database as binary nodes. Each binary document is a single node with no children. Binary documents are typically not textual in nature and require another application to read them. Some typical binary documents are image files (for example, .gif, .jpg), Microsoft Word files (.doc and .docx), executable program files, and so on.
Binary documents are not indexed when they are loaded.
MarkLogic Server supports three kinds of binary documents: small, large (BLOBs), and external. Applications use the same interfaces to read all three kinds of binary documents, but they are stored and loaded differently. These differences may lead to tradeoffs in access times, memory requirements, and disk consumption. For more details, see Choosing a Binary Format.
For a discussion of the sizing and configuration options to consider when working with binary content, see Configuring MarkLogic Server for Binary Content in the Application Developer's Guide.
Text (CLOB) Format
Character large object (CLOB) documents, or text documents, are loaded into the database as text nodes. Each text document is a single node with no children. Unlike binary documents, text documents are textual in nature, and you can therefore perform text searches on them. Because text documents only have a single node, however, you cannot navigate through the document structure using XPath expressions like you can with XML or JSON documents.
Some typical text documents are simple text files (.txt), source code files (.cpp, .java, and so on), non well-formed HTML files, or any non-XML or non-JSON text file.
For 64-bit machines, text documents have a 64 MB size limit. The in memory tree size limit database property (on the database configuration screen in the Admin Interface) should be at least 1 or 2 megabytes larger than the largest text document you plan on loading into the database.
The database text-indexing settings apply to text documents (as well as JSON and XML documents), and MarkLogic creates the indexes when the text document is loaded.
Choosing a Binary Format
Binary documents require special consideration because they are often much larger than text, JSON, or XML content. MarkLogic Server supports three types of binary documents: small, large, and external. Applications use the same interfaces to read all three types of binary document, but they are stored and loaded differently. A database may contain any combination of small, large, and external binaries. Choose the format that best matches the needs of your application and the capacity of your system. The size threshold that defines small and large binary objects is configurable. For details, see Selecting a Location For Binary Content in the Application Developer's Guide.
The following table summarizes attributes you should consider when organizing binary content:
Small and large binary documents are stored in a MarkLogic database and are fully managed by MarkLogic Server. These documents fully participate in transactions, backup, and replication. Small binaries are stored directly in the stands of a forest, which means they are cached in memory. Large binaries are stored in a special Large Data Directory, with only a small reference object in the stand. The data directory containing large binary documents is located inside the forest by default. The location is configurable during forest creation. For more details, see Selecting a Location For Binary Content.
MarkLogic stores small and large binaries differently in the database to optimize resource utilization. For example, if multiple stands contain the same large binary document, only the reference fragment is duplicated. Similarly, if a new large binary document is created from a segment of an existing binary document using xdmp:subbinary, a new reference fragment is created, but the binary content is not duplicated. For details about stands, see Understanding Forests in the Administrator's Guide.
MarkLogic Server does not fully manage external binary documents because the documents are not stored in the database. The MarkLogic database contains only a small reference fragment to each external file. MarkLogic Server manages the reference fragments as usual, but does not manage the external files. For example, MarkLogic Server does not replicate or back up the external files. You must provide security, integrity, and persistence of the external files using other means, such as the underlying operating system or file system.
Large and external binary documents require little additional disk space for merges. During a merge, MarkLogic copies fragments from the old stands to a new merged stand, as described in Understanding and Controlling Database Merges in the Administrator's Guide. The small reference fragments of large and external binaries contribute little overhead to the merge process. The referenced binary contents are not copied during a merge.
The following diagram shows the differences in small, large, and external binaries handling. Although multiple stands may contain references fragments for the same large or external binary document, only the reference fragment is duplicated:
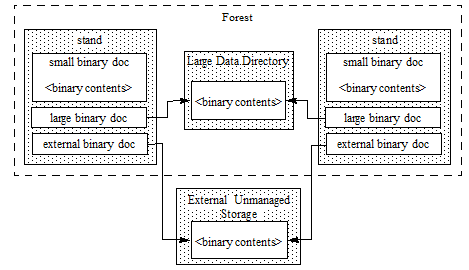
Loading Binary Documents
Loading small and large binary documents into a MarkLogic database does not require special handling, other than potentially explicitly setting the document format. Use the standard methods, such as XQuery functions or other interfaces.
External binaries require special handling at load time because they are not managed by MarkLogic. For details, see Creating External Binary References Using XQuery.
Configuring MarkLogic Server for Binary Documents
Before loading binary content, you should carefully consider the sizing and scalability implications of binary documents and configure the server appropriately. For details, see Configuring MarkLogic Server for Binary Content in the Application Developer's Guide.
Implicitly Setting the Format Based on the MIME Type
Unless the format is explicitly set when you load a document, the format of the document is determined based on the MIME type that corresponds to the URI extension of the new document. The URI extension MIME types, along with their default formats, are set in the Mimetypes section of the Admin Interface.
For example, with the default MIME type settings, documents loaded with the xml URI extension are loaded as XML files; therefore loading a document with a URI /path/doc.xml results in loading an XML document. The following table contains examples of applying the default MIME type mappings to output URIs with various file extensions. Many additional mappings are configured by default.
| URI | Document Type |
|---|---|
/path/doc.json |
JSON |
/path/doc.xml |
XML |
/path/doc.jpg |
binary |
/path/doc.txt |
text |
You can also use the Mimetypes configuration page of the Admin Interface to modify any of the default content setting, create new MIME types, or add new extensions and associate a format. For example, if you know that all of your HTML files are well-formed (or clean up nicely with content repair), you might want to change the default content loading type of URIs ending with .html and .htm to XML.
Explicitly Setting the Format
When you load a document, you can specify the format. In most cases, explicitly setting the format overrides the default settings specified on the Mimetypes configuration screen in the Admin Interface. However, this varies depending on the API you use for ingestion.
For example, HTML files have a default format of text, but you might have some HTML files that you know are well-formed, and can therefore be loaded as XML.
It is a good practice to explicitly set the format rather than relying on implicit format settings based on the MIME types because it gives you complete control over the format and eliminates surprises based on implicit MIME type mappings.
The following table summarizes the mechanisms available for explicitly setting the document format during loading for some commonly used MarkLogic interfaces and tools.
| Interface | Summary | For More Details |
|---|---|---|
| Content Pump (mlcp) | Set the -document_type import option |
Importing Content Into MarkLogic Server in the mlcp User Guide. |
| Java Client API | ContentDescriptor interface of the package com.marklog.client.document |
Single Document Operations in the Java Application Developer's Guide, and the Java Client API Documentation. |
| MarkLogic Connector for Hadoop | ContentOutputFormat class |
MarkLogic Connector for Hadoop Developer's Guide and javadoc. |
| REST Client API | Set the format parameter or Content-type header on a PUT or POST request to the /documents service. |
Loading Content into the Database and Controlling Input and Output Content Type in REST Application Developer's Guide. |
| XCC | Set the format in the ContentCreateOptions class. |
XCC Javadoc. |
| XQuery | Specify a value for the <format> element of the <options> node passed to xdmp:document-load. |
The API documentation for xdmp:document-load in the MarkLogic XQuery and XSLT Function Reference. |
The following XQuery example demonstrates explicitly setting the format to XML when using xdmp:document-load:
xdmp:document-load("c:\myFiles\file.html", <options xmlns="xdmp:document-load"> <uri>http://myCompany.com/file.html</uri> <permissions>{xdmp:default-permissions()}</permissions> <collections>{xdmp:default-collections()}</collections> <format>xml</format> </options>)
Determining the Format of a Document
After a document is loaded into a database, you cannot assume the URI accurately reflects the content format. For example, a document can be loaded as XML even if it has a URI that ends in .txt. To determine the format of a document in a database, perform a node test on the root node of the document.
XQuery includes node tests to determine if a node is text (text()) or if a node is an XML element (element()). MarkLogic Server has added a node test extension to XQuery to determine if a node is binary (binary()).
The following code sample shows how you can use a typeswitch to determine the format of a document.
(: Substitute in the URI of the document you want to test :)
let $x:= doc("/my/uri.xml")/node()
return
typeswitch ( $x )
case element() return "xml element node"
case text() return "text node"
case binary() return "binary node"
default return "don't know"