Matches for cat:guide (cat:guide/concepts (cat:guide (cat:guide (cat:guide (cat:guide/concepts (xdmp:plan)))))) have been highlighted.


MarkLogic Server 11.0 Product DocumentationConcepts Guide — Chapter 3
Indexing in MarkLogic
MarkLogic makes use of multiple types of indexes to resolve queries. As described in Overview of MarkLogic Server, this combination of indexes is referred to as the Universal Index. This chapter describes the indexing model utilized by MarkLogic Server.
- The Universal Index
- Other Types of Indexes
- Index Size
- Fields
- Reindexing
- Relevance
- Indexing Document Metadata
- Fragmentation of XML Documents
The Universal Index
The universal index indexes the XML elements and JSON properties in the loaded documents. By default, MarkLogic Server builds a set of indexes that is designed to yield the fast query performance in general usage scenarios. You can configure MarkLogic to index additional data to speed up specific types of searches. In general, the cost of supporting additional indexes is increased disk space and document load times. As more and more indexes are maintained, search performance increases and document load speed decreases.
MarkLogic indexes the XML or JSON structure it sees during ingestion, whatever that structure might be. It does not have to be told what schema to expect, any more than a search engine has to be told what words exist in the dictionary. MarkLogic sees the challenge of querying for structure or for text as fundamentally the same. At the index level, matching the XPath expression /a/b/c can be performed similarly to matching the phrase "a b c".
The MarkLogic universal index captures multiple data elements, including full text, markup structure, and structured data. The universal index is optimized to allow text, structure and value searches to be combined into a single process for extremely high performance.
This section describes the types of indexes used by MarkLogic in the Universal Index:
Word Indexing
By default, a MarkLogic database is enabled for fast element word searches. This feature enables MarkLogic Server to resolve word queries by means of an inverted index, which is a list of all of the words in all the documents in the database and, for each word, a list of which documents have that word. An inverted index is called "inverted" because it inverts the relationship of words to documents.
For example, documents contain a series of words in a particular order. The document-words relationship can be described by the following picture:
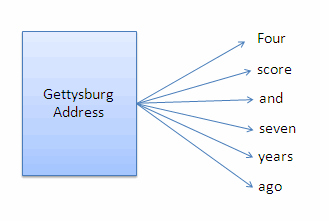
An inverted index inverts the document-words relationship described above into a word-documents relationship. For example, you can use an inverted index to identify which documents contain the word seven, as shown in the following picture:
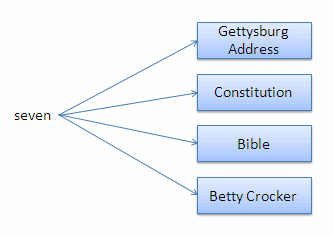
Each entry in the inverted index is called a term list. A term can be a word or a phrase consisting of multiple words. A database can be configured to index only the shortest stem of each term (run), all stems of each term (run, runs, ran, running), or all stems of each term and smaller component terms of large compound terms. Each successive level of stemming improves recall of word searches, but also causes slower document loads and larger database files.
No matter which word is used in a query, MarkLogic can quickly locate the associated documents by finding the right term in the term list. This is how MarkLogic resolves simple word queries.
For queries that ask for documents that contain two different words, MarkLogic simply searches the term list to find all document ids with the first word, then all document ids with the second, and then intersects the lists. By sorting the term lists in advance and storing them in a skip list, MarkLogic Server does this intersection efficiently and in logarithmic time. This is how MarkLogic resolves simple boolean queries.
For negative queries that ask for documents that contain one word but exclude those documents with another word, you can use the indexes to find all document ids with the first word, all document ids with the second word, and do a list subtraction.
Phrase Indexing
There are multiple ways MarkLogic Server can be configured to handle a query to locate all of the documents that contain two-word phrase:
- Use term lists to find documents that contain both words and then look inside the candidate documents to determine if the two words appear together in a phrase.
- Enable word positions to include position information for each term in the term list. That way you know at what location in the document each word appears. By looking for term hits with adjoining positions, you can find the answer using just indexes. This avoids having to look inside any documents.
Enable fast phrase searches to include two-word phrases as terms to the term list. When a user queries include a two-word phrase MarkLogic Server can find the term list for that two-word phrase and immediately know which documents contain that phrase without further processing. Because the fast phrase searches index doesn't expand the inverted index very much, it's a good choice when phrase searches are common.
For example, if a document contains the quick brown fox, the following terms will be stored in the term list:
- the quick
- quick brown
- brown fox
If a user queries for the quick brown fox, then the documents that include these three phrases will be returned. However, this does not necessarily mean these phrases appear in the specified order. For example, a document containing The clown spotted the quick brown monkey and the slow brown fox in the quick clown car would also be returned in the result set. However, if both word positions and fast phrase searches are enabled, only documents containing the quick brown fox would be returned.
The query results produced are the same regardless of whether fast phrase searches are enabled; it's just a matter of index choices and performance tradeoffs. After index resolution, MarkLogic optionally filters the candidate documents to check if they are actual matches.
Relationship Indexing
The indexing techniques described so far are typical of most standard search engines. This section describes how MarkLogic goes beyond simple search to index document structure.
In addition to creating a term list for each word, MarkLogic creates a term list for each XML element or JSON property in documents. For example, a query to locate all of the documents that have a <title> element within them can be return the correct list of documents very rapidly.
A more complex query might be to find documents matching the XPath /book/metadata/title and for each return the title node. That is, we want documents having a <book> root element, with a <metadata> child, and a <title> subchild. With the simple element term list from above you can find documents having <book>, <metadata>, and <title> elements. However, the hierarchical relationship between the elements is unknown.
MarkLogic automatically indexes element relationships to keep track of parent-child element hierarchies. Without configuring any index settings, MarkLogic, in this example, indexes the book/metadata and metadata/title relationships to produce a smaller set of candidate documents. Now you can see how the XPath /a/b/c can be resolved very much like the phrase "a b c". The parent-child index lets you search against an XPath even when you don't know the path in advance.
Note that, even with the parent-child index, there's still the potential for documents to be in the candidate set that aren't an actual match. Knowing that somewhere inside a document there's a <book> parent of <metadata> and a <metadata> parent of <title> doesn't mean it's the same <metadata> between them. That's where filtering comes in: MarkLogic confirms each of the results by looking inside the document before the programmer sees them. While the document is open MarkLogic also extracts any nodes that match the query.
Value Indexing
MarkLogic automatically creates an index that maintains a term list for each XML element or JSON property value. To understand how element and property values are indexed in MarkLogic, consider a query that starts with the same XPath but requires the title equal the phrase Good Will Hunting. This could be expressed with the following XPath:
/book/metadata/title[. = "Good Will Hunting"]Given the XPath shown above, MarkLogic Server searches the element-value index to locate a term list for documents having a <title> of Good Will Hunting and immediately resolves which documents have that element value.
Element-value indexing is made efficient by hashing. Instead of storing the full element name and text, MarkLogic hashes the element name and the text down to a succinct integer and uses that as the term list lookup key. No matter how long the element name and text string, it is only a small entry in the index. MarkLogic Server uses hashes to store all term list keys, element-value or otherwise, for sake of efficiency. The element-value index has proven to be so efficient that it's always and automatically enabled within MarkLogic.
Word and Phrase Indexing
MarkLogic allows you to enable a fast element word searches index that maintains a term list for tracking element names along with the individual words within the element. For example, consider a query for a title containing a word or phrase, like Good Will. The element-value index above isn't any use because it only matches full values, like Good Will Hunting. When enabled, the fast element word searches index maintains term lists for tracking element names along with the individual words within those elements. For example, the fast element word searches index adds a term list entry when it sees a <title> element with the word Good, another for <title> with the word Will, and another for <title> with the word Hunting. Using the fast element word searches index, MarkLogic Server can quickly locate which documents contain the words "Good" and "Will" under a <title> element to narrow the list of candidate documents.
The fast element word searches index alone does not know if the words Good Will are together in a phrase. To configure indexing to resolve at that level of granularity, MarkLogic allows you to enable the fast element phrase searches and element word positions index options. The fast element phrase searches option, when enabled, maintains a term list for every element and pair of words within the element. For example, it will have a term list for times when a <title> has the phrases "Good Will" and Will Hunting in its text. The element word positions maintains a term list for every element and its contained words, and tracks the positions of all the contained words. Either or both of these indexes can be used to ensure the words are together in a phrase under the <title> element. The fast element phrase searches and element word positions indexes are most beneficial should the phrase Good Will frequently appear in elements other than <title>.
Whatever indexing options you have enabled, MarkLogic will automatically make the most of them in resolving queries. If you're curious, you can use the xdmp:plan function to see the constraints for any particular XPath or cts:search expression.
Other Types of Indexes
MarkLogic Server makes use of other types of indexes that are not part of the Universal Index.
Range Indexing
The previously described indexes enable you to rapidly search the text, structure, and combinations of the text and structure within collections of XML and JSON documents. In some cases, however, documents can incorporate numeric, date or other typed information. Queries against these documents may include search conditions based on inequalities (for example, price < 100.00 or date ...â• 2007-01-01). Specifying range indexes for these elements and/or attributes will substantially accelerate the evaluation of these queries.
A range index enables you to do the following:
- Perform fast range queries. For example, you can provide a query constraint for documents having a date between two given endpoints.
- Quickly extract specific values from the entries in a result set. For example, you can get a distinct list of message senders from documents in a result set, as well as the frequency of how often each sender appears. These are often called facets and displayed with search results as an aid in search navigation.
- Perform optimized order by calculations. For example, you can sort a large set of product results by price.
- Perform efficient cross-document joins. For example, if you have a set of documents describing people and a set of documents describing works authored by those people, you can use range indexes to efficiently run queries looking for certain kinds of works authored by certain kinds of people.
- Quickly extract co-occurring values from the entries in a result set. For example, you can quickly get a report for which two entity values appear most often together in documents, without knowing either of the two entity values in advance.
- As described in Bitemporal Documents, bitemporal documents are associated with both a valid time that marks when a thing is known in the real world and a system time that marks when the thing is available for discovery in MarkLogic Server. The valid and system axis each make use of dateTime range indexes that define the start and end times. A temporal collection is a logical grouping of temporal documents that share the same axes with timestamps defined by the same range indexes.
- Create views on which SQL queries can be performed, as described in SQL Support.
To configure a range index, use the Admin Interface to provide the QName (the fully qualified XML or JSON name) for the element or attribute on which you want the range index to apply; a data type (int, date, string, etc); and (for strings) a collation, which is in essence a string sorting algorithm identified with a special URI. For each range index, MarkLogic creates data structures that make it easy to do two things: for any document get the document's range index value(s), or, for any range index value get the documents that have that value.
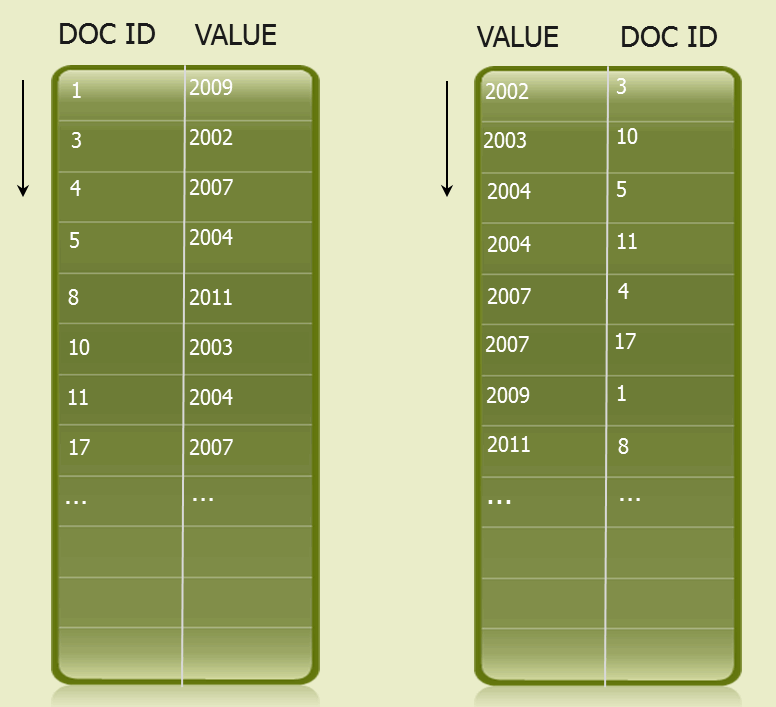
Conceptually, you can think of a range index as implemented by two data structures, both written to disk and then memory mapped for efficient access. One such data structure can be thought of as an array of document ids and values, sorted by document ids; the other as an array of values and document ids, sorted by values. It is not actually this simple or wasteful with memory and disk (in reality the values are only stored once), but it is a useful mental model.
A document id is really a fragment id and is used here to avoid introducing a new concept and keep the discussion focused on range indexing. Fragments are discussed later in Fragmentation of XML Documents.
The examples in this section conceptualize a range index as lists of people and their birthdays. The people represent documents and their birthdays represent their associated values. Imagine this range index as being a list of birthdays mapped to people, sorted by birthday, and a list of people mapped to birthdays, sorted by person, as illustrated below.

Range Queries
To perform a fast range query, MarkLogic uses the value to document id lookup array. Because the lookup array is sorted by value, there's a specific subsequence in the array that holds the values between the two user-defined endpoints. Each of those values in the range has a document id associated with it, and the set of those document ids can be quickly gathered and used like a synthetic term list to limit the search result to documents having a matching value within the user's specified range.
For example, to find people with a birthday between January 1, 1960, and May 16, 1980, you would find the point in the date-sorted range index for the start date, then the end date. Every date in the array between those two endpoints is a birthday for someone, and it's easy to get the people's names because every birthday date has the person listed right next to it. If multiple people have the same birthday, you'll have multiple entries in the array with the same value but a different corresponding name. In MarkLogic, instead of people's names, the system tracks document ids.
Range queries can be combined with any other types of queries in MarkLogic. Say you want to limit results to those within a date range as above but also having a certain metadata tag. MarkLogic uses the range index to get the set of document ids in the range, uses a term list to get the set of document ids with the metadata tag, and intersects the sets of ids to determine the set of results matching both constraints. All indexes in MarkLogic are fully composable with each other.
Extracting Values
To quickly extract specific values from the documents in a result set, MarkLogic uses the data structure that maps document ids to values. After first using inverted indexes to resolve the document ids that match a query, MarkLogic then uses the "document id to value" lookup array to find the values associated with each document id, quickly and without touching the disk. It can also count how often each value appears.
The counts can be bucketed as well. With bucketing, instead of returning counts per value, you return counts falling within a range of values. You can, for example, get the counts per day, week, or month against source data listing specific dates. You specify the buckets as part of the XQuery call. Then, when walking down the range index, MarkLogic keeps count of how many entries occur in each bucket.
For example, you want to find the birthdays of all of the people who live in Seattle, you first use your inverted index to find people who live in Seattle. Then you use your name-to-birthday lookup array to find the birthdays of those people. You can count how many people have each birthday. If you want to group the birthdays by month, you can do that with simple comparisons.
Optimized "Order By"
Optimized order by calculations allow MarkLogic to quickly sort a large set of results against an element for which there's a range index. The XQuery syntax has to be of a particular type, such as:
( for $result in cts:search(/some/path, "some terms") order by $result/element-with-range-index return $result )[1 to 10]
To perform optimized order by calculations, MarkLogic again uses the "document id to value" lookup array. For any given result set, MarkLogic takes the index-determined document ids and feeds them to the range index, which provides fast access to the values on which the results should be sorted. Millions of result items can be sorted in a fraction of a second because the values to be sorted come out of the range index.
For example, you want to sort the Seattle people by age, finding the ten oldest or youngest. You'd limit your list first to people from Seattle, extract their birthdays, then sort by birthday and finally return the list of people in ascending or descending order as you wish.
Performance of range index operations depends mostly on the size of the result set -- how many items have to be looked up. Performance varies a bit by data type but you can get roughly 10 million lookups per second per core. Integers are faster than floats, which are faster than strings, which are faster when using the simplistic Unicode Codepoint collation than when using a more advanced collation.
For more information on optimized order by expressions and the exact rules for applying them, see the Query Performance and Tuning Guide.
Using Range Indexes for Joins
Range indexes are also useful for cross-document joins. Here's the technique: In XQuery code, get a set of ids matching the first query, then feed that set into a second query as a constraint. The ability to use range indexes on both ends makes the work efficient.
Understanding this technique requires a code example. Imagine you have a set of tweets, and each tweet has a date, author id, text, etc. And you have a set of data about authors, with things like their author id, when they signed up, their real name, etc. You want to find authors who've been on Twitter for at least a year and who have mentioned a specific phrase, and return the tweets with that phrase. That requires joining between author data and the tweet data.
let $author-ids := cts:element-values( xs:QName("author-id"), "", (), cts:and-query(( cts:collection-query("authors"), cts:element-range-query( xs:QName("signup-date"), "<=", current-dateTime() - xdt:yearMonthDuration("P1Y") ) )) ) for $result in cts:search(/tweet, cts:and-query(( cts:collection-query("tweets"), "quick brown fox", cts:element-attribute-range-query( xs:QName("tweet"), xs:QName("author-id"), "=", $author-ids ) )) )[1 to 10] return string($result/body)
The first block of code finds all the author ids for people who've been on Twitter for at least a year. It uses the signup-date range index to resolve the cts:elementrange-query constraint and an author-id range index for the cts:elementvalues retrieval. This should quickly get us a long list of $author-ids.
The second block uses that set of $author-ids as a search constraint, combining it with the actual text constraint. Now, without the capabilities of a range index, MarkLogic would have to read a separate term list for every author id to find out the documents associated with that author, with a potential disk seek per author. With a range index, MarkLogic can map author ids to document ids using just in-memory lookups. This is often called a shotgun or or (for the more politically correct) a scatter query. For long lists it is vastly more efficient than looking up the individual term lists.
Word Lexicons
MarkLogic Server allows you to create lexicons, which are lists of unique words or values that enable you to quickly identify a word or value in the database and how many times it appears. You can also define lexicons that allow quick access to the document and collection URIs in the database, and you can create word lexicons on named fields.
Value lexicons are created by configuring the range indexes described in Range Indexing. Word lexicons can be created for the entire database or for specific elements or attributes. Lexicons containing strings (a word lexicon or a value lexicon of type string) have a collation that determines how the strings are ordered in the list.
For example, you might want to create a search-suggest application that can quickly match a partial string typed into the search box with similar strings in the documents stored in the database and produce them to the user for selection. In this case, you could enable word lexicons on the database to create a lexicon of all of the unique words across all of the documents in the database. Your application can quickly scan the collated list of words and locate those that partially contain the same string entered in the search box.
On large databases, the performance of using a word lexicon for suggestions will probably be slower than using a value lexicon (range index). This can be very application specific, and in some cases the performance might be good, but in general, range indexes will perform much better than word lexicons with the search:suggest function.
Reverse Indexing
All the indexing strategies described up to this point execute what you might call forward queries, where you start with a query and find the set of matching documents. A reverse query does the opposite: you start with a document and find all matching queries -- the set of stored queries that if executed would match this document.
Reverse Query Constructor
Programmatically, you start by storing serialized representations of queries within MarkLogic. You can store them as simple documents or as elements within larger documents. For convenience, any cts:query object automatically serializes as XML when placed in an XML context. This XQuery:
<query>{ cts:and-query(( cts:word-query("dog"), cts:element-word-query(xs:QName("name"), "Champ"), cts:element-value-query(xs:QName("gender"), "female") )) }</query>
<query> <cts:and-query xmlns:cts="http://marklogic.com/cts"> <cts:word-query> <cts:text xml:lang="en">dog</cts:text> </cts:word-query> <cts:element-word-query> <cts:element>name</cts:element> <cts:text xml:lang="en">Champ</cts:text> </cts:element-word-query> <cts:element-value-query> <cts:element>gender</cts:element> <cts:text xml:lang="en">female</cts:text> </cts:element-value-query> </cts:and-query> </query>
Assume you have a long list of documents like this, each with different internal XML that defines some cts:query constraints. For a given document $doc you could find the set of matching queries with this XQuery call:
cts:search(/query, cts:reverse-query($doc))
It returns all the <query> elements containing serialized queries which, if executed, would match the document $doc. The root element name can, of course, be anything.
MarkLogic executes reverse queries efficiently and at scale. Even with hundreds of millions of stored queries and thousands of documents loaded per second, you can run a reverse query on each incoming document without noticeable overhead. I'll explain how that works later, but first let me describe some situations where you'll find reverse queries helpful.
Reverse Query Use Cases
One common use case for reverse queries is alerting, where you want to notify an interested party whenever a new document appears that matches some specific criteria. For example, Congressional Quarterly uses MarkLogic reverse queries to support alerting. You can ask to be notified immediately anytime someone says a particular word or phrase in Congress. As fast as the transcripts can be added, the alerts can go out.
The alerting doesn't have to be only for simple queries of words or phrases. The match criteria can be any arbitrary cts:query construct -- complete with booleans, structure-aware queries, proximity queries, range queries, and even geospatial queries. Do you want to be notified immediately when a company's XBRL filing contains something of interest? Alerting gives you that.
Without reverse query indexing, for each new document or set of documents you'd have to loop over all your queries to see which match. As the number of queries increases, this simplistic approach becomes increasingly inefficient.
You can also use reverse queries for rule-based classification. MarkLogic includes an SVM (support vector machine) classifier. Details on the SVM classifier are beyond the scope of this paper, but suffice to say it's based on document training sets and finding similarity between document term vectors. Reverse queries provide a rule-based alternative to training-based classifiers. You define each classification group as a cts:query. That query must be satisfied for membership. With reverse query, each new or modified document can be placed quickly into the right classification group or groups.
Perhaps the most interesting and mind-bending use case for reverse queries is for matchmaking. You can match for carpools (driver/rider), employment (job/resume), medication (patient/drug), search security (document/user), love (man/woman or a mixed pool), or even in battle (target/shooter). For matchmaking you represent each entity as a document. Within that document you define the facts about the entity itself and that entity's preferences about other documents that should match it, serialized as a cts:query. With a reverse query and a forward query used in combination, you can do an efficient bi-directional match, finding pairs of entities that match each other's criteria.
A Reverse Query Carpool Match
Let's use the carpool example to make the idea concrete. You have a driver, a nonsmoking woman driving from San Ramon to San Carlos, leaving at 8AM, who listens to rock, pop, and hip-hop, and wants $10 for gas. She requires a female passenger within five miles of her start and end points. You have a passenger, a woman who will pay up to $20. Starting at "3001 Summit View Dr, San Ramon, CA 94582" and traveling to "400 Concourse Drive, Belmont, CA 94002". She requires a non-smoking car, and won't listen to country music. A matchmaking query can match these two women to each other, as well as any other matches across potentially millions of people, in sub-second time.
This XQuery code inserts the definition of the driver -- her attributes and her preferences:
let $from := cts:point(37.751658,-121.898387) (: San Ramon :) let $to := cts:point(37.507363, -122.247119) (: San Carlos :) return xdmp:document-insert( "/driver.xml", <driver> <from>{$from}</from> <to>{$to}</to> <when>2010-01-20T08:00:00-08:00</when> <gender>female</gender> <smoke>no</smoke> <music>rock, pop, hip-hop</music> <cost>10</cost> <preferences>{ cts:and-query(( cts:element-value-query(xs:QName("gender"), "female"), cts:element-geospatial-query(xs:QName("from"), cts:circle(5, $from)), cts:element-geospatial-query(xs:QName("to"), cts:circle(5, $to)) )) }</preferences> </driver>)
This insertion defines the passenger -- her attributes and her preferences:
xdmp:document-insert( "/passenger.xml", <passenger> <from>37.739976,-121.915821</from> <to>37.53244,-122.270969</to> <gender>female</gender> <preferences>{ cts:and-query(( cts:not-query(cts:element-word-query(xs:QName("music"), "country")), cts:element-range-query(xs:QName("cost"), "<=", 20), cts:element-value-query(xs:QName("smoke"), "no"), cts:element-value-query(xs:QName("gender"), "female") )) }</preferences> </passenger>)
If you're the driver, you can run this query to find matching passengers:
let $me := doc("/driver.xml")/driver for $match in cts:search(/passenger, cts:and-query(( cts:query($me/preferences/*), cts:reverse-query($me) )) ) return base-uri($match)
It searches across passengers requiring that your preferences match them, and also that their preferences match you. The combination of rules is defined by the cts:andquery. The first part constructs a live cts:query object from the serialized query held under your preferences element. The second part constructs the reverse query constraint. It passes $me as the source document, limiting the search to other documents having serialized queries that match $me.
If you're the passenger, this finds you drivers:
let $me := doc("/passenger.xml")/passenger for $match in cts:search(/driver, cts:and-query(( cts:query($me/preferences/element()), cts:reverse-query($me) )) ) return base-uri($match)
Again, the preferences on both parties must match each other. Within MarkLogic even a complex query such as this (notice the use of negative queries, range queries, and geospatial queries, in addition to regular term queries) runs efficiently and at scale.
The Reverse Index
To resolve a reverse query efficiently, MarkLogic uses custom indexes and a two-phased evaluation. The first phase starts with the source document (with alerting it'd be the newly loaded document) and finds the set of serialized query documents having at least one query term constraint match found within the source document. The second phase examines each of these serialized query documents in turn and determines which in fact fully match the source document, based on all the other constraints present.
To support the first phase, MarkLogic maintains a custom index. In that index MarkLogic gathers the distinct set of leaf node query terms (that is, the non-compound query terms) across all the serialized cts:query documents. For each leaf node, MarkLogic maintains a set of document ids to nominate as a potential reverse query match when that term is present in a document, and another set of ids to nominate when the term is explicitly not present.
When running a reverse query and presented with a source document, MarkLogic gathers the set of terms present in that document. It compares the terms in the document with this pre-built reverse index. This produces a set of serialized query document ids, each of which holds a query with at least one term match in the source document. For a simple one-word query this produces the final answer, but for anything more complex, MarkLogic needs the second phase to check if the source document is an actual match against the full constraints of the complex query.
For the second phase MarkLogic maintains a custom directed acyclic graph (DAG). It's a tree with potentially overlapping branches and numerous roots. It has one root for every query document id. MarkLogic takes the set of nominated query document ids, and runs them through this DAG starting at the root node for the document id, checking downward if all the required constraints are true, short-circuiting whenever possible. If all the constraints are satisfied, MarkLogic determines that the nominated query document id is in fact a reverse query match to the source document.
At this point, depending on the user's query, MarkLogic can return the results for processing as a final answer, or feed the document ids into a larger query context. In the matchmaker challenge, the cts:reverse-query() constraint represented just half of the cts:and-query(), and the results had to be intersected with the results of the forward query to find the bi-directional matches.
What if the serialized query contains position constraints, either through the use of a cts:near-query or a phrase that needs to use positions to be accurately resolved? MarkLogic takes positions into consideration while walking the DAG.
Range Queries in Reverse Indexes
What about range queries that happen to be used in reverse queries? They require special handling because with a range query there's no simple leaf node term. There's nothing to be found "present" or "absent" during the first phase of processing. What MarkLogic does is define subranges for lookup, based on the cutpoints used in the serialized range queries. Imagine you have three serialized queries, each with a different range constraint:
<four>{ cts:and-query(( cts:element-range-query(xs:QName("price"), ">=", 5), cts:element-range-query(xs:QName("price"), "<", 10) )) }</four>
<five>{ cts:and-query(( cts:element-range-query(xs:QName("price"), ">=", 7), cts:element-range-query(xs:QName("price"), "<", 20) )) }</five>
<six>{ cts:element-range-query(xs:QName("price"), ">=", 15) }</six>
For the above ranges you have cutpoints 5, 7, 10, 15, 20, and +Infinity. The range of values between neighboring cutpoints all have the same potential matching query document ids. Thus those ranges can be used like a leaf node for the first phase of processing:
| Range | Present |
|---|---|
| 5 to 7 | 4 |
| 7 to 10 | 4 5 |
| 10 to 15 | 5 |
| 15 to 20 | 5 6 |
| 20 to +Infinity | 6 |
When given a source document with a price of 8, MarkLogic will nominate query document ids 4 and 5, because 8 is in the 7 to 10 subrange. With a price of 2, MarkLogic will nominate no documents (at least based on the price constraint). During the second phase, range queries act just as special leaf nodes on the DAG, able to resolve directly and with no need for the cutpoints.
Lastly, what about geospatial queries? MarkLogic uses the same cutpoint approach as for range queries, but in two dimensions. To support the first phase, MarkLogic generates a set of geographic bounding boxes, each with its own set of query document ids to nominate should the source document contain a point within that box. For the second phase, like with range queries, the geographic constraint acts as a special leaf node on the DAG, complete with precise geospatial comparisons.
Overall, the first phase quickly limits the universe of serialized queries to just those that have at least one match against the source document. The second phase checks each of those nominated documents to see if they're in fact a match, using a specialized data structure to allow for fast determination with maximum short-circuiting and expression reuse. Reverse query performance tends to be constant no matter how many serialized queries are considered, and linear with the number of actual matches discovered.
Triple Index
The triple index is used to index schema-valid sem:triple elements found anywhere in a document. The indexing of triples is performed when documents containing triples are ingested into MarkLogic or during a database reindex.
This section covers the following topics:
- Triple Index Basics
- Triple Data and Value Caches
- Triple Values and Type Information
- Triple Positions
- Index Files
- Permutations
Triple Index Basics
A triple index consists of the following three identifiers:
- Subject -- Identifies a resource such as a person or an entity.
- Predicate -- Identifies a property or characteristics of the subject or of the relationship between the subject and the object.
- Object -- A node that identifies a property value, which in turn may be the subject in another triple.
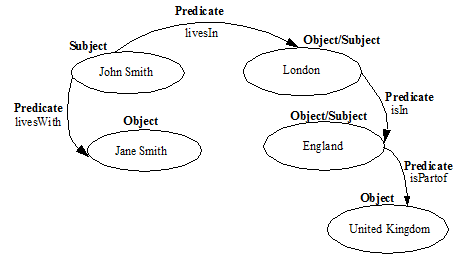
The validity of sem:triple elements is determined by checking elements and attributes in the documents against the sem:triple schema (/MarkLogic/Config/semantics.xsd). If the sem:triple element is valid, an entry is created in the triple index, otherwise the element is skipped.
Unlike range indexes, triple indexes do not have to fit in memory, so there is little up-front memory allocation. For more about triple indexes, see Triple Index Overview in the Semantics Developer's Guide.
Triple Data and Value Caches
Internally, MarkLogic stores triples in two ways: triple values and triple data. The triple values are the individual values from every triple, including all typed literal, IRIs, and blank nodes. The triple data holds the triples in different permutations, along with a document ID and position information. The triple data refer to the triple values by ID, making for very efficient lookup. Triple data is stored compressed on disk, and triple values are stored in a separate compressed value store. Both the triple index and the value store are stored in compressed four-kilobyte (4k) blocks.
When triple data is needed (for example during a lookup), the relevant block is cached in either the triple cache or the triple value cache. Unlike other MarkLogic caches, the triple cache and triple value cache shrinks and grows, only taking up memory when it needs to add to the caches.
You can configure the size of the triple cache and the triple value cache for the host of your triple store.
Triple Values and Type Information
Values are stored in a separate value store on disk in value equality sorted order, so that in a given stand, the value ID order is equivalent to value equality order.
Strings in the values are stored in the range index string storage. Anything that is not relevant to value equality is removed from the stored values, for example timezone and derived type information.
Since type information is stored separately, triples can be returned directly from the triple index. This information is also used for RDF-specific "sameTerm" comparison required by SPARQL simple entailment.
Triple Positions
The triple positions index is used to accurately resolve queries that use cts:triple-range-query and the item-frequency option of cts:triples. The triple positions index is also used to accurately resolve searches that use the cts:near-query and cts:element-query constructors. The triple positions index stores locations within a fragment of the relative positions of triples within that fragment (typically, a fragment is a document). Enabling the triple positions index makes index sizes larger and will make document loads a little slower, but increases the accuracy of queries that need those positions.
xquery version "1.0-ml"; cts:search(doc(), cts:near-query(( cts:triple-range-query(sem:iri("http://www.rdfabout.com/rdf/ usgov/sec/id/cik0001075285"), (), ()), cts:triple-range-query(sem:iri("http://www.rdfabout.com/rdf/ usgov/sec/id/cik0001317036"), (), ()) ),11), "unfiltered")
The cts:near-query returns a sequence of queries to match, where the matches occur within the specified distance from each other. The distance specified is in the number of words between any two matching queries.
The unfiltered search selects fragments from the indexes that are candidates to satisfy the specified cts:query and returns the document.
Index Files
To efficiently make use of memory, the index files for triple and value stores are directly mapped into memory. The type store is entirely mapped into memory.
Both the triple and value stores have index files consisting of 64-byte segments. The first segment in each is a header containing checksums, version number, and counts (of triples or values). This is followed by:
- Triples index - After the header segment, the triples index contains an index of the first two values and permutation of the first triple in each block, arranged into 64-byte segments. This is used to find the blocks needed to answer a given lookup based on values from the triple. Currently triples are not accessed by ordinal, so an ordinal index is not required.
- Values Index - After the header segment, the values index contains an index of the first value in each block, arranged into 64-byte segments. The values index is used to find the blocks needed to answer a given lookup based on value. This is followed by an index of the starting ordinal for each block, which is used to find the block needed to answer a given lookup based on a value ID.
The type store has an index file that stores the offset into the type data file for each stored type. This is also mapped into memory.
Permutations
The permutation enumeration details the role each value plays in the original triple. Three permutations are stored in order to provide access to different sort orders, and to be able to efficiently look up different parts of the triple. The permutations are acronyms made up from the initials of the three RDF elements (subject, predicate, and object), for example:{ SOP, PSO, OPS }.
Use the cts:triples function to specify one of these sort orders in the options:
Index Size
Many of the index options described in this chapter are either set automatically (with no option to disable) or are enabled by default. Out of the box, with the default set of indexes enabled, the on-disk size is often smaller than the size of the source XML. MarkLogic compresses the loaded XML and the indexes are often smaller than the space saved by the compression. With more indexes enabled, the index size can be two or three times the size of the XML source.
Fields
MarkLogic supports fields as a way to enable different indexing capabilities on different parts of the document. For example, a paper's title and abstract may need wildcard indexes, but the full text may not. For more information on fields, see Fields Database Settings in the Administrator's Guide.
Reindexing
Changes to the MarkLogic index settings require MarkLogic Server to reindex the database content. MarkLogic manages reindexing in the background while simultaneously handling queries and updates. If you change or add a new index setting, it will not be available to support requests until the reindexing has completely finished. If you remove an index setting, it stops being used right away.
You can manually initiate reindexing and monitor reindexing through the Admin Interface. You can also use the Admin Interface to set the "reindexer throttle" from 5 (most eager) to 1 (least eager), or set reindexer enable to disable to temporarily turn off reindexing when you don't want any background work happening.
Relevance
When performing a full text query it's not enough to just find documents matching the given constraint. The results have to be returned in relevance order. Relevance is a mathematical construct whose idea is simple. Documents with more matches are more relevant. Shorter documents that have matches are more relevant than longer documents having the same number of matches. If the search includes multiple words, some common and some rare, appearances of the rare terms are more relevant than appearances of the common terms. The math behind relevance can be very complex, but with MarkLogic you never have to do it yourself; it's done for you when you choose to order by relevance. You also get many control knobs to adjust relevance calculations when preparing and issuing a query.
Indexing Document Metadata
So far the discussions in this chapter have focused on how MarkLogic uses term lists for indexing text and structure. MarkLogic also makes use of term lists to index other things, such as collections, directories, and security rules. All of these indexes combined are referred to as the Universal Index.
This section covers the following topics:
Collection Indexes
Collections in MarkLogic are a way to tag documents as belonging to a named group (a taxonomic designation, publication year, origin, whether the document is draft or published, etc). Each document can be tagged as belonging to any number of collections. A query constraint can limit the scope of a search to a certain collection or a set of collections. Collection constraints like that are implemented internally as just another term list to be intersected. There's a term list for each collection listing the documents within that collection. If you limit a query to a collection, it intersects that collection's term list with the other constraints in the query. If you limit a query to two collections, the two term lists are unioned into one before being intersected.
Directory Indexes
MarkLogic includes the notion of database directories. They're similar to collections but are hierarchical and non-overlapping. Directories inside MarkLogic behave a lot like filesystem directories: each contains an arbitrary number of documents as well as subdirectories. Queries often impose directory constraints, limiting the query to a specific directory or its subdirectories.
MarkLogic indexes directories a lot like collections. There's a term list for each directory listing the documents in that directory. There's also a term list listing the documents held in that directory or lower. That makes it a simple matter of term list intersection to limit a view based on directory paths.
Security Indexes
MarkLogic's security model leverages the intersecting term list system. Each query you perform has an implicit constraint based on your user's security settings. MarkLogic uses a role-based security model where each user is assigned any number of roles, and these roles have permissions and privileges. One permission concerns document visibility, who can see what. As part of each query that's issued, MarkLogic combines the user's explicit constraints with the implicit visibility constraints of the invoking user. If the user account has three roles, MarkLogic gathers the term lists for each role, and unions those together to create that user's universe of documents. It intersects this list with any ad hoc query the user runs, to make sure the results only display documents in that user's visibility domain. Implicitly and highly efficiently, every user's worldview is shaped based on their security settings, all using term lists.
Properties Indexes
Each document within MarkLogic has optional XML-based properties that are stored alongside the document in the database. Properties are a convenient place for holding metadata about binary or text documents which otherwise wouldn't have a place for an XML description. They're also useful for adding XML metadata to an XML document whose schema can't be altered. MarkLogic out of the box uses properties for tracking each document's last modified time.
Properties are represented as regular XML documents, held under the same URI (Uniform Resource Identifier, like a document name) as the document they describe but only available via specific calls. Properties are indexed and can be queried just like regular XML documents. If a query declares constraints on both the main document and its properties (like finding documents matching a query that were updated within the last hour), MarkLogic uses indexes to independently find the matching properties and main document, and does a hash join (based on the URI they share) to determine the final set of matches.
Fragmentation of XML Documents
So far in this chapter, each unit of content in a MarkLogic database has been described as a document, which is a bit of a simplification. MarkLogic actually indexes, retrieves, and stores fragments. The default fragment size is the document, and that's how most people leave it. However it is also possible to break XML documents into sub-document fragments through configured fragment root or fragment parent database settings controlled using the Admin Interface. Though rarely necessary, breaking an XML document into fragments can be helpful when handling a large documents where the unit of indexing, retrieval, storage, and relevance scoring should be something smaller than a document. You specify a QName (a technical term for an XML element name) as a fragment root, and the system automatically splits the document internally at that breakpoint. Or you can specify a QName as a fragment parent to make each of its child elements into a fragment root.
The maximum size of a fragment is 512 MB for 64-bit machines. Fragmentation can only be done on XML documents. JSON documents are always stored as a single fragment.
For example, you might want to use fragmentation on a book, which may be too large to index, retrieve, and update as a single document (fragment). If you are doing chapter-based search and chapter-based display, it would be better to have <chapter> as the fragment root. With that change, each book document then becomes made up of a series of fragments, one fragment for the <book> root element holding the metadata about the book, and a series of distinct fragments for each <chapter>. The book still exists as a document, with a single URI, and it can be stored and retrieved as a single item, but internally it is broken into fragments.
Every fragment acts as its own self-contained unit. Each is the unit of indexing. A term list doesn't truly reference document ids; it references fragment ids. The filtering and retrieval process doesn't actually load documents; it loads fragments.
If no fragmentation is enabled, each fragment in the database is a document. The noticeable difference between a fragmented document and a document split into individual documents is that a query pulling data from two fragments residing in the same document can perform slightly more efficiently than a query pulling data from two documents. See the documentation for the cts:document-fragment-query function for more details. Even with this advantage, fragmentation is not something to enable unless you are sure you need it.