
Concepts Guide — Chapter 8
Application Development on MarkLogic Server
This chapter describes the various ways application developers can interact with MarkLogic Server. The main topics are as follows:
- Server-side XQuery and XSLT APIs
- Server-side JavaScript API
- REST API
- Java and Node.js Client APIs
- XML Contentbase Connector (XCC)
- SQL Support
- Optic API
- HTTP Functions to Access Internal and External Web Services
- Output Options
- Remote Filesystem Access
- Query Console for Remote Coding
- MarkLogic Connector for Hadoop
Server-side XQuery and XSLT APIs
MarkLogic includes support for XQuery 1.0 and XSLT 2.0. These are W3C-standard XML-centric languages designed for processing, querying, and transforming XML.
In addition to XQuery you have the option to use XSLT, and you have the option to use them both together. You can invoke XQuery from XSLT, and XSLT from XQuery. This means you can always use the best language for any particular task, and get maximum reuse out of supporting libraries.
XQuery includes the notion of main modules and library modules. Main modules are those you invoke directly (via either HTTP or XDBC). Library modules assist main modules by providing support functions and sometimes variables. With XSLT there is no formal separation. Every template file can be invoked directly, but templates often import one another.
XQuery and XSLT code files can reside either on the filesystem or inside a database. Putting code on a filesystem has the advantage of simplicity. You just place the code (as .xqy scripts or .xslt templates) under a filesystem directory. Putting code in a database, on the other hand, gives you some deployment conveniences: In a clustered environment it is easier to make sure every E-node is using the same codebase, because each file exists once in the database and doesn't have to be replicated across E-nodes or hosted on a network filesystem. You also have the ability to roll out a big multi-file change as an atomic update. With a filesystem deployment some requests might see the code update in a half-written state. Also, with a database you can use MarkLogic's security rules to determine who can make code updates, and you can expose (via WebDAV) remote secure access without a shell account.
There's never a need for the programmer to explicitly compile XQuery or XSLT code. MarkLogic does however maintain a "module cache" to optimize repeated execution of the same code.
You can find the full set of XQuery and XSLT API documentation at http://docs.marklogic.com. The documentation is built on MarkLogic.
Server-side JavaScript API
MarkLogic provides a native JavaScript API for core MarkLogic Server capabilities, such as search, lexicons, document management, App Servers, and so on.
For more information on JavaScript, see the JavaScript Reference Guide.
REST API
MarkLogic provides a REST Library. REST stands for Representational State Transfer, which is an architecture style that makes use of HTTP to make calls between applications and MarkLogic Server. The REST API consists of resource addresses that take the form of URLs. These URLs invoke XQuery endpoint modules in MarkLogic Server.
The REST Library provides a foundation to support other languages, such as Java and Node.js. The following diagram illustrates the layering of the Java, Node.js, REST, and XQuery and JavaScript APIs. The REST API is extensible, as described in Extending the REST API in the REST Application Developer's Guide, and works in a large number of applications.
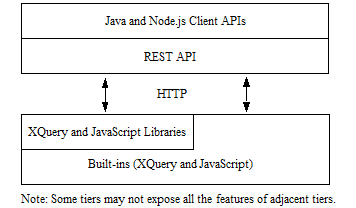
For more information on the REST API, see the REST Application Developer's Guide.
Java and Node.js Client APIs
MarkLogic's Java and Node.js Client APIs are built on top of the MarkLogic REST API described in REST API.
The Java API enables programmers to use MarkLogic without having to learn XQuery, and can easily take advantage of MarkLogic's advanced capabilities for persistence and search of unstructured documents.
In terms of performance, the Java API is very similar to MarkLogic's Java XCC, with only about a 5% difference at most on compatible queries. However, because the Java API is REST-based, to maximize performance, the network distance between the Java client and MarkLogic Server should be kept to a minimum.
When working with the Java API, you first create a manager for the type of document or operation you want to perform on the database (for instance, a JSONDocumentManager to write and read JSON documents or a QueryManager to search the database). To write or read the content for a database operation, you use standard Java APIs such as InputStream, DOM, StAX, JAXB, and Transformer as well as Open Source APIs such as JDOM and Jackson.
The Java API provides a handle (a kind of adapter) as a uniform interface for content representation. As a result, you can use APIs as different as InputStream and DOM to provide content for one read or write method. In addition, you can extend the Java API so you can use the existing read or write methods with new APIs that provide useful representations for your content.
To stream, you supply an InputStream or Reader for the data source not only when reading from the database but also when writing to the database. This approach allows for efficient write operations that do not buffer the data in memory. You can also use an OutputWriter to generate data as the API is writing the data to the database.
MarkLogic also supports JavaScript middleware in the form of a Node.js process for network programming and server-side request/response processing. Node.js is a low-level scripting environment that allows developers to build network and I/O services with JavaScript. Node.js is designed around non-blocking I/O and asynchronous events, using an event loop to manage concurrency. Node.js applications (and many of its core libraries) are written in JavaScript and run single-threaded, although Node.js uses multiple threads for file and network events.
For more information on Java, see the Java Application Developer's Guide. For more information on Node.js, see the Node.js Application Developer's Guide.
XML Contentbase Connector (XCC)
The XML Contentbase Connector (XCC) is an interface to communicate with MarkLogic Server from a Java middleware application layer.
XCC has a set of client libraries that you use to build applications that communicate with MarkLogic Server. XCC requires that an XDBC server is configured in MarkLogic Server.
An XDBC server responds to XDBC and XCC requests. XDBC and XCC use the same wire protocol to communicate with MarkLogic Server. You can write applications either as standalone applications or ones that run in an application server environment. Your XCC-enabled application connects to a specified port on a system that is running MarkLogic Server, and communicates with MarkLogic Server by submitting requests (for example, XQuery statements) and processing the results returned by those programs. These XQuery programs can incorporate calls to XQuery functions stored and accessible by MarkLogic Server, and accessible from any XDBC-enabled application. The XQuery programs can perform the full suite of XQuery functionality, including loading, querying, updating and deleting content.
For more information on XCC, see the XCC Developer's Guide.
SQL Support
The SQL supported by the core SQL engine is SQL92, with the addition of SET, SHOW, and DESCRIBE statements. MarkLogic SQL enables you to connect Business Intelligence (BI) tools, such as Tableau and Qlik, to analyze your data, as described in Connecting Tableau to MarkLogic Server and Connecting Qlik to MarkLogic Server in the SQL Data Modeling Guide.
For more information on MarkLogic SQL, see the SQL Data Modeling Guide.
Optic API
The MarkLogic Optic API makes it possible to perform relational operations on indexed values and documents. The Optic API is not a single API, but rather a set of APIs exposed within the XQuery, JavaScript, and Java languages.
The Optic API can read any indexed value, whether the value is in a range index, the triple index, or rows extracted by a template. The extraction templates, such as those used to create template views described in Creating Template Views in the SQL Data Modeling Guide, are a simple, powerful way to specify a relational lens over documents, making parts of your document data accessible via SQL. Optic gives you access to the same relational operations, such as joins and aggregates, over rows. The Optic API also enables document search to match rows projected from documents, joined documents as columns within rows, and dynamic document structures, all performed efficiently within the database and accessed programmatically from your application.
The Optic API allows you to use your data as-is and makes it possible to make use of MarkLogic document and search features using JavaScript or XQuery syntax, incorporating common SQL concepts, regardless of the structure of your data. Unlike SQL, Optic is well suited for building applications and accessing the full range of MarkLogic NoSQL capabilities. Because Optic is integrated into common application languages, it can perform queries within the context of broader applications that perform updates to data and process results for presentation to end users.
For more information on the Optic API, see Optic API for Multi-Model Data Access in the Application Developer's Guide.
HTTP Functions to Access Internal and External Web Services
You can access web services, both within an intranet and anywhere across the internet, with the XQuery-level HTTP functions built into MarkLogic Server. The HTTP functions allow you to perform HTTP operations such as GET, PUT, POST, and DELETE. You can access these functions directly through XQuery, thus allowing you to post or get content from any HTTP server, including the ability to communicate with web services. The web services that you communicate with can perform external processing on your content, such as entity extraction, language translation, or some other custom processing. Combined with the conversion and HTML Tidy functions, the HTTP functions make it very easy to process any content you can get to on the web within MarkLogic Server.
The XQuery-level HTTP functions can also be used directly with xdmp:document-load, xdmp:document-get, and all of the conversion functions. You can then, for example, directly process content extracted via HTTP from the web and process it with HTML Tidy (xdmp:tidy), load it into the database, or do anything you need to do with any content available via HTTP.
Output Options
With MarkLogic you can generate output in many different formats:
- XML, of course. You can output one node or a series of nodes.
- HTML. You can output HTML as the XML-centric xhtml or as traditional HTML.
- RSS and Atom. They're just XML formats.
- PDF. There's an XML format named XSL-FO designed for generating PDF.
- Microsoft Office. Office files use XML as a native format beginning with Microsoft Office 2007. You can read and write the XML files directly, but to make the complex formats more approachable we'd recommend you use MarkLogic's open source Office Toolkits.
- Adobe InDesign and QuarkXPress. Like Microsoft Office, these publishing formats use native XML formats.
- JSON, the JavaScript Object Notation format common in Ajax applications. It's easy to translate between XML and JSON. MarkLogic includes built-in translators.
Remote Filesystem Access
WebDAV provides a third option for interfacing with MarkLogic. WebDAV is a widely used wire protocol for file reading and writing. It's a bit like Microsoft's SMB (implemented by Samba) but it's an open standard. By opening a WebDAV port on MarkLogic and connecting to it with a WebDAV client, you can view and interact with a MarkLogic database like a filesystem, pulling and pushing files.
WebDAV works well for drag-and-drop document loading, or for bulk copying content out of MarkLogic. All the major operating systems include built-in WebDAV clients, though third-party clients are often more robust. WebDAV doesn't include a mechanism to execute XQuery or XSLT code. It's just for file transport.
Some developers use WebDAV for managing XQuery or XSLT code files deployed out of a database. Many code editors have the ability to speak WebDAV and by mounting the database holding the code it's easy to author code hosted on a remote system with a local editor.
Query Console for Remote Coding
Not actually a protocol into itself, but still widely used by programmers wanting raw access MarkLogic, is the Query Console web-based code execution environment. Query Console enables you to run ad hoc JavaScript, SPARQL, SQL, or XQuery code from a text area in your web browser. It's a great administration tool.
It includes multiple buffers, history tracking, beautified error messages, the ability to switch between any database on the server, and has output options for XML, HTML, or plain text. Query Console also allows you to list and open the files in any database. It also includes a profiler -- a web front-end on MarkLogic's profiler API -- that helps you identify slow spots in your code.
MarkLogic Connector for Hadoop
Hadoop MapReduce Connector provides an interface for using a MarkLogic Server instance as a MapReduce input source and/or a MapReduce output destination.
This section provides a high level overview of the features of The MarkLogic Connector for Hadoop. The MarkLogic Connector for Hadoop manages sessions with MarkLogic Server and builds and executes queries for fetching data from and storing data in MarkLogic Server. You only need to configure the job and provide map and reduce functions to perform the desired analysis.
The MarkLogic Connector for Hadoop API provides tools for building MapReduce jobs that use MarkLogic Server, such as the following:
InputFormatsubclasses for retrieving data from MarkLogic Server and supplying it to the map function as documents, nodes, and user-defined types.OutputFormatsubclasses for saving data to MarkLogic Server as documents, nodes and properties.- Classes supporting key and value types specific to MarkLogic Server content, such as nodes and documents.
- Job configuration properties specific to MarkLogic Server, including properties for selecting input content, controlling input splits, and specifying output destination and document quality.