
MarkLogic Server 11.0 Product DocumentationConcepts Guide — Chapter 10
High Availability and Disaster Recovery
This chapter describes the MarkLogic features that provide high availability and disaster recovery. The main topics are as follows:
Managing Backups
MarkLogic supports online backups and restores, so you can protect and restore your data without bringing the system offline or halting queries or updates. Backups are initiated via administration calls, either via the web console or an XQuery script. You specify a database to backup and a target location. Backing up a database backs up its configuration files, all the forests in the database, as well as the corresponding security and schemas databases. It's particularly important to backup the security database because MarkLogic tracks role identifiers as xs:long values and the backup forest data can't be read without the corresponding roles existing in the security database.
You can also choose to selectively backup an individual forest instead of an entire database. That's a convenient option if only the data in one forest is changing.
The topics in this section are as follows:
Typical Backup
Throughout most of the time when a backup is running all queries and updates proceed as usual. MarkLogic simply copies stand data from the source directory to the backup target directory, file by file. Stands are read-only except for the small Timestamps file, so this bulk copy can proceed without needing to interrupt any requests. Only at the very end of the backup does MarkLogic have to halt incoming requests for a brief moment in order to write out a fully consistent view for the backup, flushing everything from memory to disk.
If the target backup directory already has data from a previous backup (as is the case when old stands haven't yet been merged into new stands), MarkLogic skips copying any files that already exist and are identical in the target. This isn't quite an incremental backup, but it's similar, and it gives a nice performance boost.
For more detail on backup and restore, see Backing Up a Database and Restoring a Database without Journal Archiving in the Administrator's Guide. For backing and restoring a database with encryption, see Backup and Restore in the Security Guide.
Backup with Journal Archiving
The backup/restore operations with journal archiving enabled provide a point-in-time recovery option that enables you to restore database changes to a specific point in time between full backups with the input of a wall clock time. When journal archiving is enabled, journal frames are written to backup directories by near synchronously streaming frames from the current active journal of each forest.
When journal archiving is enabled, you will experience longer restore times and slightly increased system load as a result of the streaming of journal frames.
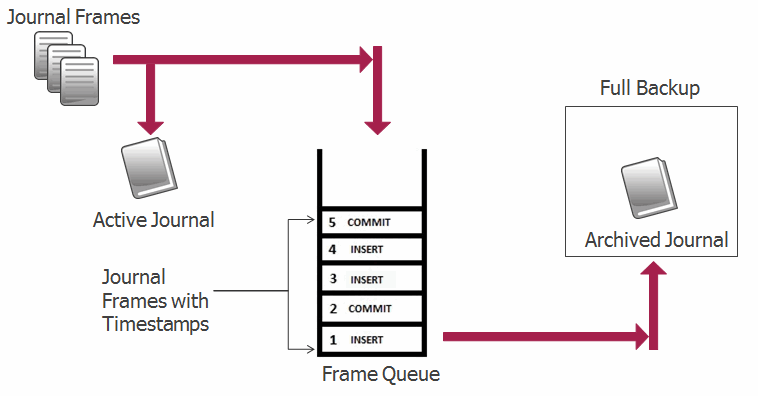
Journal archiving can only be enabled at the time of a full backup. If you restore a backup and want to reenable journal archiving, you must perform a full backup at that time.
When journal archiving is enabled, you can set a lag limit value that specifies the amount of time (in seconds) in which frames being written to the forest's journal can differ from the frames being streamed to the backup journal. For example, if the lag limit is set to 30 seconds, the archived journal can lag behind a maximum of 30 seconds worth of transactions compared to the active journal. If the lag limit is exceeded, transactions are halted until the backup journal has caught up.
The active and backup journal are synchronized at least every 30 seconds. If the lag limit is less than 30 seconds, synchronization will be performed at least once in that period. If the lag limit is greater than 30 seconds, synchronization will be performed at least once every 30 seconds. The default lag limit is 15 seconds.
The decision on setting a lag limit time is determined by your Recovery Point Objective (RPO), which is the amount of data you can afford to lose in the event of a disaster. A low RPO means that you will restore the most data at the cost of performance, whereas a higher RPO means that you will potentially restore less data with the benefit of less impact to performance. In general, the lag limit you chose depends on the following factors:
- Accurate synchronization between active and backup journals at the potential cost of system performance.
- Use when you have an archive location with high I/O bandwidth and your RPO objective is low.
- Delayed synchronization between active and backup journals, but lesser impact on system performance.
- Higher server memory utilization due to pending frames being held in memory.
- Use when you have an archive location with low I/O bandwidth and your RPO objective is high.
For more detail on backup and restore with journal archiving, see Backing Up Databases with Journal Archiving and Restoring Databases with Journal Archiving in the Administrator's Guide.
Incremental Backup
An incremental backup stores only the data that has changed since the previous full or incremental backup. Typically a series of incremental backups are done between full backups. Incremental backups are more compact than archived journals and are faster to restore. It is possible to schedule frequent incremental backups (for example, by the hour or the minute) because an incremental backup takes less time to do than a full backup.
Full and incremental backups need to be scheduled separately. An example configuration might be:
A full backup and a series of incremental backups can allow you to recover from a situation where a database has been lost. Incremental backup can be used with or without journal archiving. If you enable both incremental backup and journal archiving, you can replay the journal starting from the last incremental backup timestamp. See Backup with Journal Archiving for more about journal archiving.
When you restore from an incremental backup, you need to do a full backup before you can continue with incremental backups.
Incremental backup and journal archiving both provide disaster recovery. Incremental backup uses less disk space than journal archiving, and incremental backup is faster than using journal archiving.
For recovery you only need to specify the timestamp for the recovery to start and the server will figure out which full backup and which incremental backup(s) to use. You only need to schedule the incremental backup; the server will link together (or chain) the sequence the incremental backups automatically.
For more detail on incremental backup and restore, see Incremental Backup and Restoring from an Incremental Backup with Journal Archiving in the Administrator's Guide.
Failover and Database Replication
MarkLogic provides a variety of mechanisms to ensure high availability and disaster recovery. The general mechanisms and their uses are:
- Failover to ensure high availability within a cluster.
- Replication to facilitate disaster recovery between geographically distinct clusters.
Failover for MarkLogic Server provides high availability for data nodes in the event of a data node or forest-level failure. Data node failures can include operating system crashes, MarkLogic Server restarts, power failures, or persistent system failures (hardware failures, for example). A forest-level failure is any disk I/O or other failure that results in an error state on the forest. With failover enabled and configured, a forest can go down and the MarkLogic Server cluster automatically and gracefully recovers from the outage, continuing to process queries without any immediate action needed by an administrator.
Database Replication is used to ease disaster recovery, in the rare event of the complete failure of a production cluster or data center. Before configuring database replication, first provision a full DR cluster, separate from your production cluster, in an alternate geographic region.
Provision your DR cluster similarly to your production cluster, with the same number of forests, databases, and app servers.Then configure database replication from production cluster databases to DR cluster databases.
Database replication will continuously keep your DR cluster databases up-to-date with data from your production cluster databases.In the event of a complete production cluster failure, you can then manually reconfigure your application and DR cluster, making it the new production cluster.
The topics in this section are as follows:
Local- and Shared-Disk Failover
Databases in a MarkLogic cluster have forests that hold their content, and each forest is served by a single host in the cluster. To guard against a host going down and being disconnected from the cluster or forest-level failures, each forest allows you to set up one of two types of failover:
Both types of failover are controlled and configured at the forest level. Each type of failover has its pros and cons. Shared-Disk Failover is more efficient with disk. Local-Disk Failover is easier to configure, can use cheaper local disk, and doesn't require a clustered filesystem or fencing software.
Local-Disk Failover
Local-Disk Failover uses the intra-cluster forest replication capability introduced with MarkLogic 4.2. With forest replication you can have all writes to one forest be automatically replicated to another forest or set of forests, with each forest held on a different set of disks, generally cheap local disks, for redundancy.
Should the server managing the master copy of the forest data go offline, another server managing a different forest with a copy of the data can continue forward as the new master. When the first forest comes back online, any updated data in the replica forest can be re-synchronized back to the master to get them in sync again.
MarkLogic starts forest replication by performing fast bulk synchronization for initial "zero day" synchronization. It also does this if a forest has been offline for an extended period. It then performs an incremental journal replay once the forests are in sync, sending journal frames from the master forest to the replica forest(s) as part of each commit. The replay produces an equivalent result in each forest, but the forests may not be "bit for bit" identical. (Imagine for example that one forest has been told to merge while the other hasn't.) Commits across replicated forests are synchronous and transactional, so a commit to the master is a commit to the replica.
For more information about local-disk failover see Local-Disk Failover in the Scalability, Availability, and Failover Guide.
Shared-Disk Failover
Shared-Disk Failover uses a clustered filesystem, such as Veritas or GFS. (The full list of supported clustered filesystems can be found in the Scalability, Availability, and Failover Guide.) Every Data Manager stores its forest data on a SAN that's potentially accessible by other servers in the cluster. Should one D-node server fail, it will be removed from the cluster and another server in the cluster with access to the SAN will take over for each of its forests. The failover Data Managers can read the same bytes on disk as the failed server, including the journal up to the point of failure, with filesystem consistency between the servers guaranteed by the clustered filesystem. As part of configuring each forest, you configure its primary host as well as its failover hosts. It's perfectly legitimate to use an E-node as a backup for a D-node. Instances can switch roles on the fly.
For more information about shared-disk failover see Shared-Disk Failover in the Scalability, Availability, and Failover Guide.
Database Replication
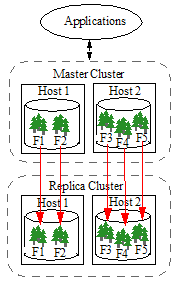
Database replication operates at the forest level by copying journal frames from a forest in the Master database and replaying them on a corresponding forest in the foreign Replica database.
As shown in the illustration below, each host in the Master cluster connects to the remote hosts that are necessary to manage the corresponding Replica forests. Replica databases can be queried but cannot be updated by applications.
Bulk Replication
Any content existing in the Master databases before Database Replication is configured is bulk replicated into the Replica databases. Bulk replication is also used after the Master and foreign Replica have been detached for a sufficiently long period of time that journal replay is no longer possible. Once bulk replication has completed, journal replication will proceed.
The bulk replication process is as follows:
- The indexing operation on the Master database maintains a catalog of the current state of each fragment. The Master sends this catalog to the Replica database.
- The Replica compares the Master's catalog to its own and updates its fragments using the following logic:
- If the Replica has the fragment, it updates the nascent/deleted timestamps, if they are wrong.
- If the Replica has a fragment the Master doesn't have, it marks that fragment as deleted (it likely existed on the Master at some point in the past, but has been merged out of existence).
- If the Replica does not have a fragment, it adds it to a list of missing fragments to be returned by the Master.
- The Master iterates over the list of missing fragments returned from the Replica and sends each of them, along with their nascent/deleted timestamps, to the Replica where they are inserted.
For more information on fragments, see the Fragments chapter in the Administrator's Guide.
Bootstrap Hosts
Each cluster in a Database Replication scheme contains one or more bootstrap hosts that are used to establish an initial connection to foreign clusters it replicates to/from and to retrieve more complete configuration information once a connection has been established. When a host initially starts up and needs to communicate with a foreign cluster, it will bootstrap communications by establishing a connection to one or more of the bootstrap hosts on the foreign cluster. Once a connection to the foreign cluster is established, cluster configuration information is exchanged between all of the local hosts and foreign hosts.
For details on selecting the bootstrap hosts for your cluster, see Coupling Clusters in the Administrator's Guide.
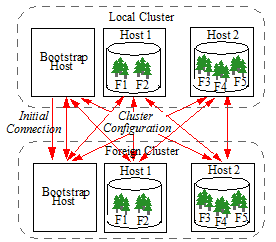
Inter-cluster Communication
Communication between clusters is done using the intra-cluster XDQP protocol on the foreign bind port. A host will only listen on the foreign bind port if it is a bootstrap host or if it hosts a forest that is involved in inter-cluster replication. By default, the foreign bind port is port 7998, but it can be configured for each host, as described in Changing the Foreign Bind Port in the Database Replication Guide. When secure XDQP is desired, a single certificate / private-key pair is shared by all hosts in the cluster when communicating with foreign hosts.
XDQP connections to foreign hosts are opened when needed and closed when no longer in use. While the connections are open, foreign heartbeat packets are sent once per second. The foreign heartbeat contains information used to determine when the foreign cluster's configuration has changed so updated information can be retrieved by the local bootstrap host from the foreign bootstrap host.
Replication Lag
Queries on a Replica database must run at a timestamp that lags the current cluster commit timestamp due to replication lag. Each forest in a Replica database maintains a special timestamp, called a Non-blocking Timestamp, that indicates the most current time at which it has complete state to answer a query. As the Replica forest receives journal frames from its Master, it acknowledges receipt of each frame and advances its nonblocking timestamp to ensure that queries on the local Replica run at an appropriate timestamp. Replication lag is the difference between the current time on the Master and the time at which the oldest unacknowledged journal frame was queued to be sent to the Replica.
You can set a lag limit in your configuration that specifies, if the Master does not receive an acknowledgement from the Replica within the time frame specified by the lag limit, transactions on the Master are stalled. For the procedure to set the lag limit, see Configuring Database Replication in the Database Replication Guide.
Master and Replica Database Index Settings
Starting with MarkLogic version 9.0-7, indexing information is replicated by the Master database to the Replica system. This is done to insure that the index data on the replica is always in sync with the master database. If you want the option to switch over to the Replica database after a disaster, you still need to insure that the index settings are identical on the Master and Replica clusters.
If you need to update index settings after configuring Database Replication, make sure they are updated on both the Master and Replica databases. Changes to the index settings on the Master database will trigger reindexing, after which the reindexed documents will be replicated to the Replica. When a Database Replication configuration is removed for the Replica database (such as after a disaster), the Replica database will reindex, if necessary.
Flexible Replication
Flexible Replication is an asynchronous (non-transactional), single-master, trigger-based, document-level, inter-cluster replication system built on top of the Content Processing Framework (CPF) described in Content Processing Framework (CPF). With the Flexible Replication system active, any time a document changes it causes a trigger to fire, and the trigger code makes note of the document's change in the document's property sheet. Documents marked in their property sheets as having changed will be transferred by a background process to the replica cluster using an HTTP-friendly protocol. Documents can be pushed (to the replica) or pulled (by the replica), depending on your configuration choice.
Flexible Replication supports an optional plug-in filter module. This is where the flexibility comes from. The filter can modify the content, URI, properties, collections, permissions, or anything else about the document as it's being replicated. For example, it can split a single document on the master into multiple documents on the replica. Or it can simply filter the documents, deciding which documents to replicate and which not to, and which documents should have only pieces replicated. The filter can even wholly transform the content as part of the replication, using something like an XSLT stylesheet to automatically adjust from one schema to another.
Flexible Replication has more overhead than journal-based intra-cluster replication. It supports sending approximately 250 documents per second. You can keep the speed up by increasing task server threads (so more CPF work can be done concurrently), spreading the load on the target with a load balancer (so more E nodes can participate), and buying a bigger network pipe between clusters (speeding the delivery).
For more information about Flexible Replication, see the Flexible Replication Guide and the flexrep Module API documentation.
Query-Based Flexible Replication
Query-Based Flexible Replication (QBFR) combines Flexible Replication with Alerting to enable customized information sharing between hosts communicating across disconnected, intermittent, and latent networks.
The purpose of Alerting is to notify a user when new content is available that matches a predefined query associated with that user. Combining Alerting with Flexible Replication allows you to replicate documents to select replica targets, only if those documents contain content that matches that target's predefined queries and users. When new content is inserted or updated in the Master database, it is replicated only to replica targets configured with the matching query/user Alerting criteria.
A user can have more than one alert, in which case they would receive documents that match any of their alerts. In addition to queries, the permissions for a user are taken into account. The user will only receive replicated content that they have permission to view in the database. If the permissions change, the replica will be updated accordingly. Most often QBFR is a pull configuration, but it can also be set up as a push configuration.
By setting up alerts, replication takes place any time content in the database matches that query. Any new or updated content within the domain scope will cause all matching rules or alerts to perform their corresponding action. QBFR can be used with filters to share specific documents or parts of documents. Filters can be set up in either a push or pull configuration.
For more information about Query-Based Flexible Replication, see Configuring Alerting With Flexible Replication in the Flexible Replication Guide.