
MarkLogic 9 Product DocumentationSemantics Developer's Guide — Chapter 8
SPARQL Update
The SPARQL1.1 Update language is used to delete, insert, and update (delete/insert) triples and graphs. An update is actually an INSERT/DELETE operation in the database.
SPARQL Update is a part of the SPARQL 1.1 suite of specifications at http://www.w3.org/TR/2013/REC-sparql11-update-20130321. It is a separate language from the SPARQL Query. SPARQL Update enables you to manipulate triples or sets of triples, while the SPARQL query language enables you to search and query your triple data.
You can manage security level using SPARQL Update. All SPARQL queries over managed triples are governed by the graph permissions. Triple documents will inherit those permissions at ingest.
Only triples managed by MarkLogic...Äìtriples whose document root is sem:triples...Äìare affected by SPARQL Update. Managed triples are triples that have been loaded into the database using:
- mlcp with
-input_file_type RDF - sem:rdf-load
- sem:rdf-insert
- sem:sparql-update
Embedded triples are part of an XML or JSON document . If you want to create, delete, or update embedded triples, use the appropriate document update functions. See Unmanaged Triples for more information about triples embedded in documents. Unmanaged triples can also be modified and updated with document management functions. See Inserting, Deleting, and Modifying Triples with XQuery and Server-Side JavaScript for details.
This section includes the following parts:
- Using SPARQL Update
- Graph Operations with SPARQL Update
- Graph-Level Security
- Data Operations with SPARQL Update
- Bindings for Variables
- Using SPARQL Update with Query Console
- Using SPARQL Update with XQuery or Server-Side JavaScript
- Using SPARQL Update with REST
Using SPARQL Update
You can use SPARQL Update to insert and delete managed triples in a Graph Store. There are two kinds of SPARQL Update operations: graph data operations, and graph management operations.
There are several ways to use SPARQL Update:
- From Query Console - Select SPARQL Update as the Query Type from the drop-down list. See Using SPARQL Update with Query Console.
- Using XQuery or JavaScript - Call SPARQL Update from XQuery (sem:sparql-update) or JavaScript (sem.sparqlUpdate). See Using SPARQL Update with XQuery or Server-Side JavaScript.
- Through the REST API (GET /v1/graphs/sparql or POST /v1/graphs/sparql). See Using SPARQL Update with REST.
SPARQL Update is used with managed triples. To modify embedded or unmanaged triples, use the appropriate document update functions with XQuery or JavaScript. See Inserting, Deleting, and Modifying Triples with XQuery and Server-Side JavaScript.
A new role has been added for SPARQL Update - sparql-update-user . Users must have sparql-update-user capabilities to INSERT, DELETE, or DELETE/INSERT triples into graphs. See Role-Based Security Model in the Security Guide for details.
Graph Operations with SPARQL Update
You can manipulate RDF graphs using SPARQL Update. Graph management operations include CREATE, DROP, COPY, MOVE, and ADD.
The SPARQL Update spec includes these commands and options for working with RDF graphs:
| Command | Options | Description |
|---|---|---|
| CREATE | SILENT, GRAPH IRIref | Creates a new graph. Use GRAPH to name the graph. SILENT creates the graph silently. This means if the graph already exists, do not return an error. |
| DROP | SILENT, GRAPH IRIref, DEFAULT, NAMED, ALL | Drops a graph and its contents. Use GRAPH to name a graph to remove, DEFAULT to remove the default graph |
| COPY | SILENT, GRAPH, IRIref_from, DEFAULT, TO, IRIref_to | Copies the source graph into the destination graph. Any content in the destination graph will be overwritten (deleted). |
| MOVE | SILENT, GRAPH, IRIref_from, DEFAULT, TO, IRIref_to | Moves the contents of the source graph into the destination graph, and removes that content from the source graph. Any content in the destination graph will be overwritten (deleted). |
| ADD | SILENT, GRAPH, IRIref_from, DEFAULT, TO, IRIref_to | Add the contents of the source graph to the destination graph. The ADD operation keeps the content of both the source graph and destination graph intact. |
Multiple statements separated by semicolons (;) in one SPARQL Update operation, run in the same transaction, and can be included in the same request. It is important to note that each statement can see the result of the previous statements.
For example, in this query, the COPY operation can see the graph <TEST> created in the first statement:
PREFIX dc: <http://purl.org/dc/elements/1.1/> INSERT DATA { <http://example/book0> dc:title "A default book" GRAPH <TEST> {<http://example/book1> dc:title "A new book" } GRAPH <TEST> {<http://example/book2> dc:title "A second book" } GRAPH <TEST> {<http://example/book3> dc:title "A third book" } }; COPY <TEST> TO <BOOKS1>
SPARQL Update operations return the empty sequence.
CREATE
This operation creates a graph. If the graph already exists, an error will be returned unless the SILENT option is used. The contents of already existing graphs remain unchanged. If you do not have permission to create the graph, an error is returned (unless the SILENT option is used).
The syntax for a CREATE operation is:
CREATE ( SILENT )? GRAPH IRIref
If the SILENT option is used, the operation will not return an error. The GRAPH IRIref option specifies the IRI for the new graph.
CREATE GRAPH <http://marklogic.com/semantics/tutorial/update> ;
If the specified destination graph does not exist, the graph will be created. The CREATE operation will create a graph with the permissions specified through sem:sparql-update, or with the user's default permission if no permissions are specified.
DROP
The DROP operation removes the specified graph or graphs from the Graph Store. The syntax for a DROP operation is:
DROP ( SILENT )? GRAPH IRIref | DEFAULT |NAMED | ALL )
The GRAPH keyword is used to remove a graph specified by IRIref . The DEFAULT keyword option is used to remove the default graph from the Graph Store. The NAMED keyword is used to remove all named graphs from the Graph Store. All graphs are removed from the Graph Store with the ALL keyword; this is the same as resetting the Graph store.
DROP SILENT GRAPH <http://marklogic.com/semantics/tutorial/intro> ;
After successful completion of this operation, the specified graphs are no longer available for further graph update operations. This operation returns an error if the specified named graph does not exist. If SILENT is present, the result of the operation will always be success.
If the default graph of the Graph Store is dropped, MarkLogic creates a new, empty default graph with the user's default permissions.
COPY
The COPY operation is used for inserting all of the triples from a source graph into a destination graph. Triples from the source graph are not affected, but triples in the destination graph, if any exist, are removed before the new triples are inserted.
The syntax for a COPY operation is:
COPY ( SILENT )? ( ( GRAPH )? IRIref_from | DEFAULT) TO ( ( GRAPH )?
IRIref_to | DEFAULT ) The COPY operation copies permissions from a source graph to the destination graph. Since source graph has the permission info, $perm parameter in sem:sparql-update does not apply in a COPY operation.
COPY <http://marklogic.com/semantics/tutorial/intro> TO <http://marklogic.com/semantics/tutorial/start> ;
If the destination graph does not exist, it will be created. The operation returns an error if the source graph does not exist. If the SILENT option is used, the result of the operation will always be success.
The COPY operation is similar to dropping a graph and then inserting a new graph:
DROP SILENT (GRAPH IRIref_to | DEFAULT); INSERT { ( GRAPH IRIref_to )? { ?s ?p ?o } } WHERE { ( GRAPH IRIref_from )? { ?s ?p ?o } }
If COPY is used to copy a graph onto itself, no operation is performed and the data is left as it was.
If you want the update to fail when the destination graph does not already exist, the existing-graph option in sem:sparql-update needs to be specified. If you copy into a new graph, that new graph takes the permissions of the graph that you copied from. If you copy into an existing graph, the permssions of that graph do not change.
MOVE
The MOVE operation is used for moving all triples from a source graph into a destination graph. The syntax for a MOVE operation is:
MOVE (SILENT)? ( ( GRAPH )? IRIref_from | DEFAULT) TO ( ( GRAPH )? IRIref_to | DEFAULT)
The source graph is removed after insertion. Triples in the destination graph, if any exist, are removed before destination triples are inserted.
MOVE <http://marklogic.com/semantics/tutorial/queries> TO <http://marklogic.com/semantics/tutorialSearches> ;
The graph <http://marklogic.com/semantics/queries> is removed after its triples have been inserted into <http://marklogic.com/semantics/searches>. Any triples in the graph <http://marklogic.com/semantics/searches> are deleted before the other triples are inserted.
If MOVE is used to move a graph onto itself, no operation will be performed and the data will be left as it was.
If the destination graph does not exist, it will be created. The MOVE operation returns an error if the source graph does not exist. If the SILENT option is used, the result of the operation will always be success.
The MOVE operation is similar to :
DROP SILENT (GRAPH IRIref_to | DEFAULT); INSERT { ( GRAPH IRIref_to )? { ?s ?p ?o } } WHERE { ( GRAPH IRIref_from )? { ?s ?p ?o } }; DROP ( GRAPH IRIref_from | DEFAULT)
The MOVE operation moves permissions from source graph to destination graph. Since source graph has the permission info, the $perm parameter in sem:sparql-update does not apply to the operation.
If you want the update to fail when the destination graph does not already exist, the existing-graph option in sem:sparql-update needs to be specified. If you copy into a new graph, that new graph takes the permissions of the graph that you copied from. If you copy into an existing graph, the permssions of that graph do not change.
ADD
The ADD operation is used for inserting all triples from a source graph into a destination graph. The triples from the source graph are not affected, and existing triples from the destination graph, if any exist, are kept intact.
The syntax for an ADD operation is:
ADD ( SILENT )? ( ( GRAPH )? IRIref_from | DEFAULT) TO ( ( GRAPH )? IRIref_to | DEFAULT)
ADD <http://marklogic.com/semantics/tutorial/queries> TO <http://marklogic.com/semantics/searches> ;
If ADD is used to add a graph onto itself, no operation will be performed and the data will be left as it was. If the destination graph does not exist, it will be created. The ADD operation returns an error if the source graph does not exist. If the SILENT option is used, the result of the operation will always be success.
If you are adding triples into a new graph, you can set the permissions of the new graph through sem:sparql-update. If no permissions are specified, your default graph permissions will be applied to the graph.
The ADD operation is equivalent to:
INSERT { ( GRAPH IRIref_to )? { ?s ?p ?o } } WHERE { ( GRAPH IRIref_from )? { ?s ?p ?o } }
If you want the update to fail when the destination graph does not already exist, the existing-graph option in sem:sparql-update needs to be specified. If you copy into a new graph, that new graph takes the permissions of the graph that you copied from. If you copy into an existing graph, the permssions of that graph do not change.
Graph-Level Security
You can manage security at the graph level using SPARQL Update. Graph-level security means that only users with a role corresponding to the permissions set on a graph can view a graph, change graph content, or create a new graph. As a user, you can only see the triples and graphs for which you have read permissions (via a role). See Role-Based Security Model in the Security Guide.
By default, graphs are created with the default permissions of the user creating the graph. If graph permissions are specified by passing in permissions as an argument to the sem:sparql-update call, graph operations and graph management operations that result in the creation of a new graph will use the specified permissions. This is true whether the graph is created explicitly using CREATE GRAPH, or implicitly by inserting or copying triples (INSERT or a graph operation to copy, move, or add) into a graph that does not already exist.
If you pass in permissions with sem:sparql-update on an operation that inserts triples into an existing graph, the permissions you passed in are ignored. If you're copying a graph from one graph to another, the permissions are ignored in favor of transferring the data and the permissions from one graph to another.
Graph-level security is enforced for all semantic operations using SPARQL or SPARQL Update, via XQuery or JavaScript, and includes semantic REST functions.
Your default user permissions are set by the MarkLogic admininstrator. These are the same default permissions for document creation that are discussed in Default Permissions in the Security Guide.
To see what permissions are currently on a graph, use sem:graph-get-permissions:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "MarkLogic/semantics.xqy"; sem:graph-get-permissions( sem:iri("MyGraph")) => <sec:permission xmlns:sec="http://marklogic.com/xdmp/security"> <sec:capability>read</sec:capability> <sec:role-id>5995163769635647336</sec:role-id> </sec:permission> <sec:permission xmlns:sec="http://marklogic.com/xdmp/security"> <sec:capability>update</sec:capability> <sec:role-id>5995163769635647336</sec:role-id> </sec:permission>
This returns the two capabilities set on in this graph: read and update. If you have the role with the ID 5995163769635647336, you will be able to read information in this graph, you will be able to see the graph and the triples in the graph. If you have the role with the ID 5995163769635647336, you will be able to update the graph. You must have read capability for the graph to use sem:graph-get-permissions.
In a new database, the graph document for the default graph does not exist yet. Once you insert triples into this database, the default graph is created.
To set permissions on a graph, use sem:graph-set-permissions:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "MarkLogic/semantics.xqy"; declare namespace sec = "http://marklogic.com/xdmp/security"; sem:graph-set-permissions(sem:iri("MyGraph"), (xdmp:permission("sparql-update-role", "update"))
This will set the permissions on the graph and the triples in the graph. If the specified IRI does not exist, the graph will be created. You must have update permissions for the graph to set the permissions.
To add permissions to a graph, use sem:graph-add-permissions
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "MarkLogic/semantics.xqy"; declare namespace sec = "http://marklogic.com/xdmp/security"; sem:graph-add-permissions(sem:iri("MyGraph"), (xdmp:permission("sparql-read-role", "read"),))
This will add read permissions for the sparql-read-role to the graph and to the triples in the graph. If the graph named by the IRI does not exist, the graph will be automatically created. You must have update permissions for the graph to add permissions to an existing graph.
A graph that is created by a non-admin user (that is, by any user who does not have the admin role) must have at least one update permission for the graph, otherwise the creation of the graph will return an XDMP-MUSTHAVEUPDATE exception.
To remove permissions, use sem:graph-remove-permissions:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "MarkLogic/semantics.xqy"; declare namespace sec = "http://marklogic.com/xdmp/security"; sem:graph-remove-permissions(sem:iri("MyGraph"), (xdmp:permission("sparql-read-role", "read"),))
This removes the read permission on MyGraph for sparql-read-role. You must have update permissions for the graph to remove permissions. If the graph does not exist, this will result in an error.
Data Operations with SPARQL Update
These data operations are part of SPARQL Update: INSERT DATA, DELETE DATA, DELETE/INSERT, LOAD, and CLEAR. Data operations involve triple data contained in graphs.
SPARQL Update includes these commands and options for working with data in RDF graphs:
| Command | Options | Description |
|---|---|---|
| INSERT DATA | QuadData, WITH, GRAPH | Inserts triples into a graph. If no graph is specified, the default graph will be used. |
| DELETE DATA | QuadData | Deletes triples from a graph, as specified by QuadData. If no graph is specified, deletes from all in-scope graphs. |
| DELETE..INSERT WHERE | WITH, IRIref, USING, NAMED, WHERE, DELETE, INSERT | Remove or add triples from/to the Graph Store based on bindings for a query pattern specified in a WHERE clause. |
| DELETE WHERE | WITH, IRIref, USING, NAMED, WHERE, DELETE, INSERT | Remove triples from the Graph Store based on bindings for a query pattern specified in a WHERE clause. DELETE WHERE is DELETE..INSERT WHERE with a missing INSERT (which is optional). |
| INSERT WHERE | WITH, IRIref, USING, NAMED, WHERE, DELETE, INSERT | Add triples to the Graph Store based on bindings for a query pattern specified in a WHERE clause. INSERT WHERE is DELETE..INSERT WHERE with a missing DELETE (which is optional). |
| CLEAR | SILENT, (GRAPH IRIref | DEFAULT | NAMED | ALL) | Removes all the triples in the specified graph. |
You can run multiple statements separated by semicolons (;) in one SPARQL Update operation in the same transaction, and you can include them in the same request. It is important to note that each statement can see the result of the previous statements.
SPARQL Update operations return the empty sequence.
Other ways to load triples into MarkLogic: mlcp, sem:rdf-load, or the HTTP REST endpoints. See Loading Triples with mlcp, sem:rdf-load, Addressing the Graph Store, and Loading Semantic Triples. For bulk loading, mlcp is the preferred method.
INSERT DATA
INSERT DATA adds triples specified in the request into a graph. The syntax for INSERT DATA is:
INSERT DATA QuadData (GRAPH VarOrIri) ? {TriplesTemplates}
The QuadData parameter is made up of sets of triple patterns (TriplesTemplates), which can optionally be wrapped in a GRAPH block.
All of the managed triples from a triples document will go into the default graph unless you specify the destination graph when inserting them using SPARQL Update.
If you are inserting triples into a new graph, create the graph with the permissions you want, specified through sem:sparql-update. If you do not specify permissions on the graph, the graph will be created with your default permissions. To manage the permissions of the graph, use sem:graph-add-permissions. See Graph-Level Security for more about permissions and security.
For example, this update uses sem:graph-add-permissions to add update permissions to the sparql-update-role to update for <My Graph>, and inserts three triples into that graph:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:graph-add-permissions(sem:iri("MyGraph"), xdmp:permission("sparql-update-role", "update")); sem:sparql-update(' PREFIX exp: <http://example.org/marklogic/people> PREFIX pre: <http://example.org/marklogic/predicate> INSERT DATA { GRAPH <MyGraph>{ exp:John_Smith pre:livesIn "London" . exp:Jane_Smith pre:livesIn "London" . exp:Jack_Smith pre:livesIn "Glasgow" . }} ')
If no graph is described in QuadData, the default graph is assumed (http://marklogic.com/semantics#default-graph). If data is inserted into a graph that does not exist in the Graph Store, a new graph is created for the data with the user's permissions.
This example uses INSERT DATA to insert a triple into a default graph and then insert three triples into a graph named BOOKS.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql-update(' PREFIX dc: <http://marklogic.com/dc/elements/1.1/> INSERT DATA { <http://example/book0> dc:title "A default book" GRAPH <BOOKS> {<http://example/book1> dc:title "A new book" } GRAPH <BOOKS> {<http://example/book2> dc:title "A second book" } GRAPH <BOOKS> {<http://example/book3> dc:title "A third book" } } ');
This example will delete any book titled A new bookin the graph BOOKS and insert the title Inside MarkLogic Server in its place:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql-update(' PREFIX dc: <http://marklogic.com/dc/elements/1.1/> WITH <BOOKS> DELETE {?b dc:title "A new book"} INSERT {?b dc:title "Inside MarkLogic Server" } WHERE { ?b dc:title "A new book". }')
The WITH keyword means to use this graph (<BOOKS>) in every clause.
DELETE DATA
The DELETE DATA operation removes some triples specified in the request, if the respective graphs in the Graph Store contain them. The syntax for DELETE DATA is:
DELETE DATA QuadData
The QuadData parameter specifies the triples to be removed. If no graph is described in QuadData, then the default graph is assumed.
Any MarkLogic-managed triple that matches subject, predicate, and object on any of the triples specified in QuadData will be deleted. If a graph is specified in QuadData, the scope of deletion is limited to the triples in that graph; otherwise, the scope of deletion is limited to the triples in default graph.
This example deletes triples that match true and Retail/Wholesale from the <http://marklogic.com/semantics/COMPANIES100A/> graph.
PREFIX demov: <http:demo/verb#> PREFIX demor: <http:demo/resource#> DELETE DATA { GRAPH <http://marklogic.com/semantics/COMPANIES100A/> { demor:COMPANY100 demor:listed "true" . demor:COMPANY100 demov:industry "Retail/Wholesale" . } }
An error will be thrown if a DELETE DATA operation includes variables or blank nodes. The deletion of non-existing triples has no effect. Any triples specified in QuadData that do not exist in the Graph Store are ignored.
DELETE..INSERT WHERE
The DELETE..INSERT WHERE operation is used to remove and/or add triples from/to the Graph Store based on bindings for a query pattern specified in a WHERE clause. You can use DELETE..INSERT WHERE to specify a pattern to match against and then delete and/or insert triples.
See http://www.w3.org/TR/sparql11-update/#updateLanguage for details.
To delete triples according to a specific pattern, use the DELETE..INSERT WHERE construct without the optional INSERT clause. If you do not specify a graph, you will insert into or delete triples from the default graph (http://marklogic.com/semantics#default-graph), also called the unnamed graph. The syntax for DELETE..INSERT WHERE is:
( WITH IRIref )? ( ( DeleteClause InsertClause? ) | InsertClause ) ( USING ( NAMED )? IRIref )* WHERE GroupGraphPattern DeleteClause ::= DELETE QuadPattern InsertClause ::= INSERT QuadPattern
This operation identifies data using the WHERE clause, which is used to determine matching sequences of bindings for a set of variables. The bindings for each solution are then substituted into the DELETE template to remove triples, and then in the INSERT template to create new triples.
If an operation tries to insert into a graph that does not exist, that graph will be created. DELETE and INSERT run in the same transaction, and obey MarkLogic security rules.
In this example each triple containing Healthcare/Life Sciences will be deleted and two triples and two triples will be inserted, one for Healthcare and a second one for Life Sciences.
PREFIX demov: <http:demo/verb#> WITH <http://marklogic.com/semantics/COMPANIES100A/> DELETE { ?company demov:industry "Healthcare/Life Sciences" . } INSERT { ?company demov:industry "Healthcare" . ?company demov:industry "Life Sciences" . } WHERE { ?company demov:industry "Healthcare/Life Sciences" .}
Note that the DELETE and INSERT are independent of each other.
DELETE WHERE
The DELETE WHERE operation is used to remove triples from the Graph Store based on bindings for a query pattern specified in a WHERE clause. DELETE WHERE is DELETE..INSERT WHERE with a missing INSERT, which is optional. You can use DELETE WHERE to specify a pattern to match against and then delete the matching triples.
To delete triples according to a specific pattern, use the DELETE WHERE construct without the optional INSERT clause. If you do not specify a graph, you will delete triples from the default graph (http://marklogic.com/semantics#default-graph), also called the unnamed graph.
The syntax for DELETE WHERE is:
( WITH IRIref )? ( ( DeleteClause InsertClause? ) | InsertClause ) ( USING ( NAMED )? IRIref )* WHERE GroupGraphPattern DeleteClause ::= DELETE QuadPattern InsertClause ::= INSERT QuadPattern
This example of DELETE WHERE deletes the sales data for any companies with less than 100 employees from the graph <http://marklogic.com/semantics/COMPANIES100A/>:
PREFIX demov: <http:demo/verb#> PREFIX vcard: <http:www.w3c.org/2006/vcard/ns#> WITH <http://marklogic.com/semantics/COMPANIES100A/> DELETE { ?company demov:sales ?sales . } WHERE { ?company a vcard:Organization . ?company demov:employees ?employees . } FILTER ( ?employees < 100 )
INSERT WHERE
The INSERT WHERE operation is used to add triples to the Graph Store based on bindings for a query pattern specified in a WHERE clause. INSERT WHERE is DELETE..INSERT WHERE with a missing DELETE, which is optional.You can use INSERT WHERE to specify a pattern to match against and then insert triples based on that match.
To insert triples according to a specific pattern, use the INSERT WHERE construct without the optional DELETE clause. If you do not specify a graph, you will insert triples into the default graph (http://marklogic.com/semantics#default-graph), also called the unnamed graph.
The syntax for INSERT WHERE is:
( WITH IRIref )? ( ( DeleteClause InsertClause? ) | InsertClause ) ( USING ( NAMED )? IRIref )* WHERE GroupGraphPattern DeleteClause ::= DELETE QuadPattern InsertClause ::= INSERT QuadPattern
This example of INSERT WHERE finds each company in New York, USA and adds State="NY" and deliveryRegion="East Coast".
PREFIX demov: <http:demo/verb#> PREFIX vcard: <http:www.w3c.org/2006/vcard/ns#> WITH <http://marklogic.com/semantics/sb/COMPANIES100A/> INSERT { ?company demov:State "NY" . ?company demov:deliveryRegion "East Coast" } WHERE { ?company a vcard:Organization . ?company vcard:hasAddress [ vcard:region "New York" ; vcard:country-name "USA"] }
CLEAR
The CLEAR operation removes all of the triples in the specified graph(s). The syntax for CLEAR is:
CLEAR (SILENT)? (GRAPH IRIref | DEFAULT | NAMED | ALL )
The GRAPH IRIref option is used to remove all triples from the graph specified by GRAPH IRIref. The DEFAULT option is used to remove all the triples from the default graph of the Graph Store. The NAMED option is used to remove all of the triples in all of the named graphs of the Graph Store, and the ALL option is used to remove all triples from all graphs of the Graph Store.
CLEAR GRAPH <http://marklogic.com/semantics/COMPANIES100A/> ;
This operation removes all of the triples from the graph. The graph and its metadata (such as permissions) will be kept after the graph is cleared. The CLEAR will fail if the specified graph does not exist. If the SILENT option is used, the operation will not return an error.
Bindings for Variables
Binding variables can be used as values in INSERT DATA, and DELETE DATA, and are passed in as arguments to sem:sparql-update.
To create bindings for variables to be used with SPARQL Update, you create an XQuery or JavaScript function to map the bindings and then pass in the bindings as part of a call to sem:sparql-update.
In this example we create a function, assign the variables, build a set of bindings, and then use the bindings to insert repetitive data into the triple store using INSERT DATA:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; declare function local:add-player-triples($id as xs:integer, $lastname as xs:string, $firstname as xs:string, $position as xs:string, $team as xs:string, $number as xs:integer ) { let $query := ' PREFIX bb: <http://marklogic.com/baseball/players/> PREFIX xs: <http://www.w3.org/2001/XMLSchema#> INSERT DATA { GRAPH <PlayerGraph> { ?playertoken bb:playerid ?id . ?playertoken bb:lastname ?lastname . ?playertoken bb:firstname ?firstname . ?playertoken bb:position ?position . ?playertoken bb:number ?number . ?playertoken bb:team ?team . } } ' let $playertoken := fn:concat("bb:", $id) let $player-map := map:entry("id", $id) let $put := map:put($player-map, "playertoken", $playertoken) let $put := map:put($player-map, "lastname", $lastname) let $put := map:put($player-map, "firstname", $firstname) let $put := map:put($player-map, "position", $position) let $put := map:put($player-map, "number", $number) let $put := map:put($player-map, "team", $team) return sem:sparql-update($update, $player-map) }; local:add-player-triples(417, "Doolittle", "Sean", "pitcher", 62, "Athletics"), local:add-player-triples(215, "Abad", "Fernando", "pitcher", 56, "Athletics"), local:add-player-triples(109, "Kazmir", "Scott", "pitcher", 26, "Athletics"),
The order of the variables does not matter because of the mapping.
This same pattern can be used with LIMIT and OFFSET clauses. Bindings for variables can be used with SPARQL Update (sem:sparql-update), SPARQL (sem:sparql), and SPARQL values (sem:sparql-values). See Using Bindings for Variables for an example using bindings for variables with SPARQL using LIMIT and OFFSET clauses.
Using SPARQL Update with Query Console
You can use SPARQL Update with Query Console. It is listed as a Query type in the Query Console drop-down menu.
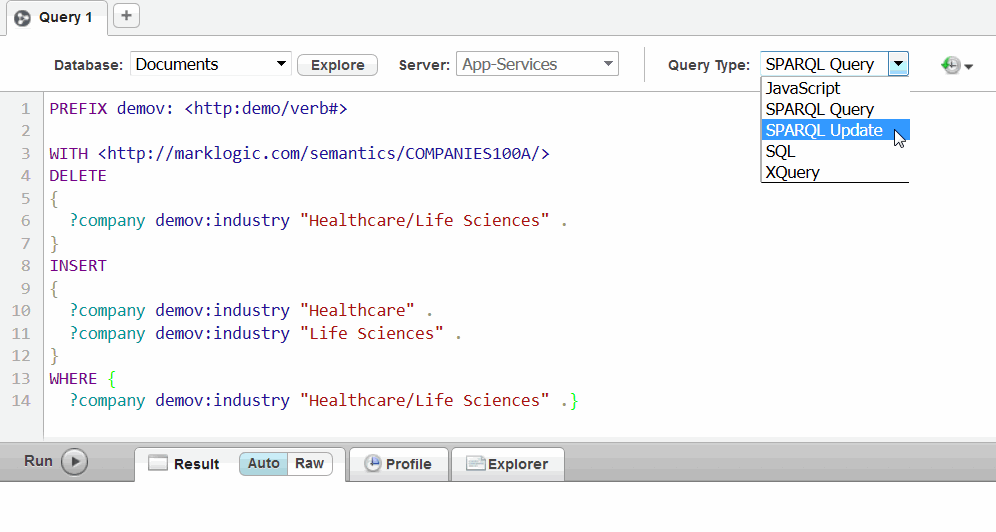
Query Console highlights SPARQL Update keywords as you create your query. You can run your SPARQL Update queries in the Query Console the same way you run SPARQL Queries.
Using SPARQL Update with XQuery or Server-Side JavaScript
You can execute SPARQL Updates with sem:sparql-update in XQuery and sem.sparqlUpdate in Javascript. For details about the function signatures and descriptions, see the Semantics documentation under XQuery Library Modules in the MarkLogic XQuery and XSLT Function Reference and in the MarkLogic Server-Side JavaScript Function Reference.
Although some of the semantics functions are built-in, others are not. We therefore recommend that you import the Semantics API library into every XQuery module or JavaScript module that uses the Semantics API.
Using XQuery, the import statement is:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy";
For Javascript, the import statement is:
var sem = require("/MarkLogic/semantics.xqy");
Here is a complex query using SPARQL Update with XQuery. The query selects a random player from the Athletics baseball team, formerly with the Twins, and deletes that player the Athletics:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $query := ' PREFIX bb: <http://marklogic.com/baseball/players#> PREFIX bbr: <http://marklogic.com/baseball/rules#> PREFIX xs: <http://www.w3.org/2001/XMLSchema#> WITH <Athletics> DELETE { ?s ?p ?o . } INSERT { ?s ?p bbr:Twins . } WHERE { ?s ?p ?o . { SELECT (max(?s1) as ?key) (count(?s1) as ?inner_numbers) WHERE { ?s1 bb:number ?o1 . } } FILTER (?s = ?key) FILTER (?p = bb:team) } return sem:sparql-update($query)
Using SPARQL Update with REST
SPARQL Update can be used with REST in client applications to manage graphs and triple data via the SPARQL endpoint. See SPARQL Update with the REST Client API for information about using SPARQL Update with REST.
For more information about using SPARQL with Node.js client applications, see Working With Semantic Data in the Node.js Application Developer's Guide. For semantic client applications using Java, you can find the Java Client API on GitHub at http://github.com/marklogic/java-client-api or get it from the central Maven repository.