
MarkLogic 9 Product DocumentationMonitoring MarkLogic Guide — Chapter 1
Monitoring MarkLogic Server
MarkLogic Server provides a rich set of monitoring features that include a pre-configured monitoring dashboard and a Management API that allows you to integrate MarkLogic Server with existing monitoring applications or create your own custom monitoring applications.
This chapter includes the following sections:
- Overview
- Selecting a Monitoring Tool
- Monitoring Architecture, a High-level View
- Monitoring Tools and Security
- Guidelines for Configuring your Monitoring Tools
- Monitoring Metrics of Interest to MarkLogic Server
Overview
In general, you will use a monitoring tool for the following:
- To keep track of the day-to-day operations of your MarkLogic Server environment.
- For initial capacity planning and fine-tuning your MarkLogic Server environment. For details on how to configure your MarkLogic Server cluster, see the Scalability, Availability, and Failover Guide.
- To troubleshoot application performance problems. For details on how to troubleshoot and resolve performance issues, see the Query Performance and Tuning Guide.
- To troubleshoot application errors and failures.
The monitoring metrics and thresholds of interest will vary depending on your specific hardware/software environment and configuration of your MarkLogic Server cluster. This chapter lists some of the metrics of interest when configuring and troubleshooting MarkLogic Server. However, MarkLogic Server is just one part of your overall environment. The health of your cluster depends on the health of the underlying infrastructure, such as network bandwidth, disk I/O, memory, and CPU.
Selecting a Monitoring Tool
Though this guide focuses on the tools available from MarkLogic that enable you to monitor MarkLogic Server, it is strongly recommended that you select an enterprise-class monitoring tool that monitors your entire computing environment to gather application, operating system, and network metrics alongside MarkLogic Server metrics.
There are many monitoring tools on the market that have key features such as alerting, trending, and log analysis to help you monitor your entire environment. MarkLogic Server includes the following monitoring tools:
- A Monitoring dashboard that monitors MarkLogic Server. This dashboard is pre-configured to monitor specific MarkLogic Server metrics. For details, see Using the MarkLogic Server Monitoring Dashboard.
- A Monitoring History dashboard to capture and make use of historical performance data for a MarkLogic cluster. For details, see MarkLogic Server Monitoring History.
- A RESTful Management API that you can use to integrate MarkLogic Server with existing monitoring application or create your own custom monitoring applications. For details, see Using the Management API.
Monitoring Architecture, a High-level View
All monitoring tools use a RESTful Management API to communicate with MarkLogic Server. The monitoring tool sends HTTP requests to a monitor host in a MarkLogic cluster. The MarkLogic monitor host gathers the requested information from the cluster and returns it in the form of an HTTP response to the monitoring tool. The Management API is described in Using the Management API.
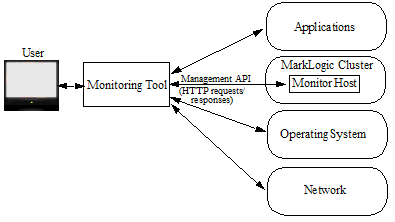
Monitoring Tools and Security
To gain access to the monitoring features described in this guide, a user must be assigned the manage-user role. Monitoring tools should authenticate as a user with that role. The manage-user role is assigned the http://marklogic.com/xdmp/privileges/manage execute privilege and provides access to the Management API, Manage App Server, and the UI for the Configuration Manager and Monitoring Dashboard. The manage-user role also provides read-only access to all of a cluster's configuration and status information, with the exception of the security settings. For details on assigning roles to users, see Users in the Administrator's Guide.
If you have enabled SSL on the Manage App Server, your URLs must start with HTTPS, rather than HTTP. Additionally, you must have a MarkLogic certificate on your browser, as described in Accessing an SSL-Enabled Server from a Browser or WebDAV Client in the Security Guide.
Guidelines for Configuring your Monitoring Tools
Monitoring tools enable you to set thresholds on specific metrics to alert you when a metric exceeds a pre-specified value.
The topics in this section are:
Establish a Performance Baseline
Many metrics that can help in alerting and troubleshooting are meaningful only if you understand normal patterns of performance. For example, monitoring an App Server for slow queries will require a different threshold on an application that spawns many long-running queries to the task server than on an HTTP App Server where queries are normally in the 100 ms range. Most enterprise-class monitoring tools support data storage to support this type of trend analysis. Developing a starting baseline and tuning it if your application profile changes will yield better results for developing your monitoring strategy.
Balance Completeness Against Performance
Collecting and storing monitoring metrics has a performance cost, so you need to balance completeness of desired performance metrics against their cost. The cost of collecting monitoring metrics can differ. In general, the more resources you monitor, the greater the cost. For example, if you have a lot of hosts, server status is going to be more expensive. If you have a lot of forests, database status is going to be more expensive. In most cases, you will use a subset of the available monitoring metrics. And there may be circumstances in which you temporarily monitor certain metrics and, once the issue have been targeted and resolved, you no longer monitor those metrics.
One balancing technique is to measure system performance on a staging environment under heavy load, then enable your monitoring tool and calculate the overhead. You can reduce overhead by reducing collection frequency, reducing the number of metrics collected, or writing a Management API plugin to produce a custom view that pinpoints the specific metrics of interest. Each response from the underlying Management API includes an elapsed time value to help you calculate the relative cost of each response. For details, see Using the Management API.
Monitoring Metrics of Interest to MarkLogic Server
Environments and workloads vary. Each environment will have a unique set of requirements based on variables including cluster configuration, hardware, operating system, patterns of queries and updates, feature sets, and other system components. For example, if replication is not configured in your environment, you can remove templates or policies that monitor that feature.
This section provides a set of guiding questions to help you understand and identify the relevant metrics. The topics in this section are:
- Does MarkLogic Have Adequate Resources?
- What is the State of the System Overall?
- What is Happening on the MarkLogic Server Cluster Now?
- Are There Signs of a Serious Problem?
Does MarkLogic Have Adequate Resources?
MarkLogic Server is designed to fully utilize system resources. Many settings, such as cache sizes, are auto-sized by MarkLogic Server at installation.
- Does MarkLogic Server have enough resources on the host machine? What processes other than MarkLogic Server are running on the host and what host resources do those processes require? When competing with other processes, MarkLogic Server cannot optimize resource utilization and consequently cannot optimize performance.
- Is there enough disk space for forest data and merges? Merges require at least one and one half times as much free disk space as used by the forest data (for details, see Memory, Disk Space, and Swap Space Requirements in the Installation Guide). If a merge runs out of disk space, it will fail.
- Is there enough disk space to log system activity? If there is no space left on the log file device, MarkLogic Server will abort. Also, if there is no disk space available to add messages to the log files, MarkLogic Server will fail to start.
- Is there enough memory for the range indexes? Range indexes improve performance at the cost of memory and increased load/reindex time. Running out of memory for range indexes may result in undesirable memory swapping that severely impacts performance.
- Is swap space configured correctly? At query time, MarkLogic Server makes use of both memory and swap space. If there is not enough of either, the query can fail with SVC-MEMALLOC messages. For details on configuring swap memory, see Tuning Query Performance in MarkLogic Server in the Query Performance and Tuning Guide.
- How many hosts are in the cluster? How are the hosts configured as evaluator and data nodes? How are the hosts organized into groups? For details on configuring MarkLogic Server clusters, see Clustering in MarkLogic Server in the Scalability, Availability, and Failover Guide.
- What applications use resource-intensive features, such as CPF, replication, and point-in-time recovery? Are the hardware, software, and network resources available and configured to most efficiently support such applications?
What is the State of the System Overall?
Many problems that impact MarkLogic Server originate outside of MarkLogic Server. Consider the health of your overall environment.
- How efficiently is CPU being used? How much CPU capacity exists at different time slices? What is the execution speed of the current read and write tasks? Can I optimize queries or choose a better time to batch load?
- How efficiently is I/O being used? What amount of data is currently being read from or written to disk? Are there any I/O bottlenecks?
- Is there enough free disk space for each file system?
- Are there any errors or warnings appearing in the logs for the operating system, MarkLogic Server, and applications?
- What is the current state of the network?
- Are there any serious errors in the system log files? Your monitor tool, or an auxiliary tool such as Splunk, should monitor your system logs and report on any detected errors.
What is Happening on the MarkLogic Server Cluster Now?
When you suspect an error or performance problem originates from MarkLogic Server, some questions to ask are:
- Are all of the hosts in the cluster online? Are all of the App Servers enabled? In what a states are the forests?
- What are the patterns of queries and updates? Do they appear to be evenly distributed across the hosts in the cluster?
- Are there any long-running queries? Longer than usual query execution times may indicate a bottleneck, such as a slow host or problems with XDQP communication between hosts. Other possible problems include increased loads following a failover or more than the usual number of total requests.
- Is there an increase in the number of outstanding requests? A consistent increase in the total number of outstanding requests may indicate the need to add more capacity and/or load balance. Decreases in total requests may indicate some upstream problem that needs to be addressed.
- What is the I/O rates and loads pattern? In this context, rates refers to amount of data applications are currently reading from or writing to MarkLogic Server databases (throughput) and loads refers to the execution time of the current read and write requests, which includes the time requests spend in the wait queue when maximum throughput is achieved.
Under normal circumstances you will see loads go up as rates go up. As the workload (number of queries and updates) increases, a steadily high rates value indicates the maximum database throughput has been achieved. When this occurs, you can expect to see increasing loads, which reflect the additional time requests are spending in the wait queue. As the workload decreases, you can expect to see decreasing loads, which reflect fewer requests in the wait queue.
If, while the workload is steady, rates decrease and loads increase, something is probably taking away I/O bandwidth from the database. This may indicate that MarkLogic Server has started a background task, such as a merge operation or some process outside of MarkLogic Server is taking away I/O bandwidth.
- What is the journal and save write rates and loads pattern? During a merge, you should see the rates for journal and save writes decrease and the loads increase. Once the merge is done, journal and save writes rates should increase and the loads should decrease. If no merge is taking place, then a process outside of MarkLogic Server may be taking away I/O bandwidth.
- What is the XDQP rates and loads pattern? In this context, rates refers to amount of data hosts are currently reading from or writing to other hosts and loads refers to the execution time of the current read and write requests, including those in the wait queue. A decrease in rates and an increase in loads may indicate that there is network problem.
- What are the cache hit/miss rates? Lots of cache hits means not having to read fragments off disk, so there is less I/O load. An increasing cache miss rate may indicate a need to increase the cache size, write queries that take advantage of indexes to reduce the frequency of disk reads, or adjust the fragment size to better match that of the queried data.
- How many concurrent updates and reads are in progress? An increase of both updates and reads may indicate that there are queries that are doing too many updates and reads concurrently. The potential problem is lock contention between the updates and reads on the same fragments, which degrades performance.
- How many database merges are in progress? Merges require both I/O and disk resources. If too many database merges are taking place at the same time, it may be necessary to coordinate merges by creating a merge policy or establishing merge blackout periods, as described in Understanding and Controlling Database Merges in the Administrator's Guide.
- How many reindexes are in progress? Database reindexing is periodically done automatically in the background by MarkLogic Server and requires both CPU and disk resources. If there are too many reindexing processes going on at the same time, you may need to adjust when reindexing is done for particular databases, as described in Text Indexing in the Administrator's Guide.
- How many backups and/or restores are in progress? Backup and restore processes can impact the performance of applications and other background tasks in MarkLogic Server, such as merges and indexing. Backups with point-in-time recovery enabled have an even greater impact on performance. If backup and/or restore processes are impacting system performance, it may be necessary to reschedule them, as described in Backing Up and Restoring a Database in the Administrator's Guide.
Are There Signs of a Serious Problem?
If you are encountering a serious problem in which MarkLogic Server is unable to effectively service your applications, some questions to ask are:
- Did MarkLogic Server abort or fail to start? This may indicate that there not enough disk space for the log files on the log file device. If this is the cause, you will need to either add more disk space or free up enough disk space for the log files.
- Is an application unable to update data in MarkLogic Server? This may indicate that you have exceeded the 64-stand limit for a forest. This could be the result of running out of merge space or that merges are suppressed.
- Are queries failing with SVC-MEMALLOC messages? This indicates that there is not enough memory or swap space. You may need to add memory or reconfigure your swap memory, as described in Tuning Query Performance in MarkLogic Server in the Query Performance and Tuning Guide
- Are there any forests in the async replicating state? This state indicates that a primary forest is asynchronously catching up to its replica forest after a failover or that a new replica forest was added to a primary forest that already contains content. If a forest has failed over, see Scenarios that Cause a Forest to Fail Over in the Scalability, Availability, and Failover Guide for possible causes.
- Are there any serious messages in the error logs? The various log levels are described in Understanding the Log Levels in the Administrator's Guide. All log messages at the error level and higher should be investigated, whereas lower-level messages, such as warnings and debug messages are mostly informational. Log messages that indicate a particularly serious problem include:
- Repeated server restart messages. Possible causes include a corrupted forest, segmentation faults, or some problem with the host's operating system.
- XDQP disconnect. Possible causes include an XDQP timeout or a network failure.
- Forest unmounted. Possible causes include the forest is disabled, it has run out of merge space, or the forest data is corrupted.
- SVC-* errors. These are system-level errors that result from timeouts, socket connect issues, lack of memory, and so on.
- XDMP-BAD errors. These indicate serious internal error conditions that shouldn't happen. Look at the error text for details and the logs for context. If you have an active maintenance contract, you can contact MarkLogic Technical Support for help.