
MarkLogic 9 Product DocumentationEntity Services Developer's Guide — Chapter 4
Generating Code and Other Artifacts
The Entity Services API includes tools for generating code templates and configuration artifacts that enable you to quickly bring up a model-based application.
For example, you can generate code for creating instances and instance envelope documents from raw source and converting instances between different versions of your model. You can also generate an instance schema, TDE template, query options, and database configuration based on a model.
This chapter covers the following topics:
- Code and Artifact Generation Overview
- Summary of Available Generators
- Creating an Instance Converter Module
- Creating a Model Version Translator Module
- Generating a TDE Template
- Generating an Entity Instance Schema
- Generating a Database Configuration Artifact
- Generating a PII Security Configuration Artifact
- Generating Query Options for Searching Instances
- Deploying Generated Code and Artifacts
Code and Artifact Generation Overview
The following steps outline the basic procedure for generating code and configuration artifacts using the Entity Services API. The specifics are described in detail in the rest of this chapter.
- Author a model descriptor and create a model, as described in Creating and Managing Models.
- Pass the model (in the form of a json:object or JSON
object-node) to one of thees:*-generateXQuery functions ores.*GenerateJavaScript functions to generate a code module or configuration artifact. - Customize the generated code or artifact to meet the needs of your application. All generated code and artifacs are usable as-is, but you will want to customize some of them.
- Deploy the (customized) code or artifact, as needed. Code modules must be deployed to the modules database. Artifacts such as the TDE template must be deployed to the schemas database. Artifacts such as query options do not require deployment.
The following diagram illustrates this process. The relevant part of the model is the portion represented by the model descriptor.
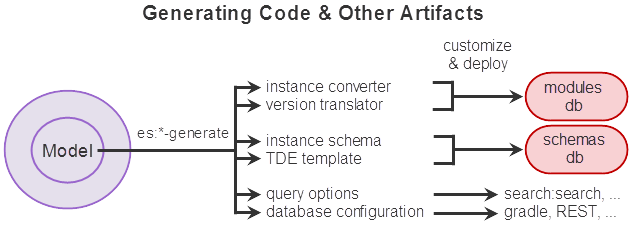
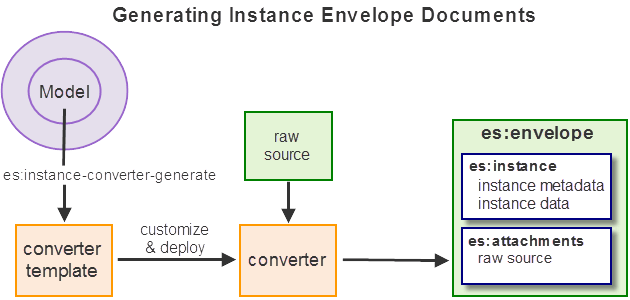
The following diagram illustrates the high level flow for creating, deploying and using an instance converter module. The instance converter module is discussed in more detail in Creating an Instance Converter Module.
Summary of Available Generators
The following table summarizes the code and artifact generation functions provided by Entity Services. Both the XQuery (es:*) and Server-Side JavaScript (es.*) name of each function is included. For more details, see the MarkLogic XQuery and XSLT Function Reference or MarkLogic Server-Side JavaScript Function Reference.
| Function | Description |
|---|---|
| Generate an XQuery library module containing functions useful for data conversion, such as converting raw source data into entity instances or an instance into its canonical representation. You can use this module from either XQuery or Server-Side JavaScript. For more details, see Creating an Instance Converter Module. | |
| Generate an XQuery library module containing functions useful for converting entity instances from one version to another. You can use this module from either XQuery or Server-Side JavaScript. For more details, see Creating a Model Version Translator Module. | |
| Generate an XSD schema for a model. The resulting schema is suitable for validating canonical entity instances. For details, see Generating an Entity Instance Schema. | |
| Generate a TDE template that facilitates searching entity instances as row or semantic data. For more deails, see Generating a TDE Template. | |
Generate a JSON database properties configuration object, suitable for use with the REST Management API or ml-gradle. This artifact includes range index and word lexicon configuration based on the model descriptor. For details, see Generating a Database Configuration Artifact. |
|
| Generates a set of query options helpful for searching entity instances with the XQuery Search API or the REST, Java, or Node.js Client APIs. For more details, see Generating Query Options for Searching Instances. | |
| Generate an Element Level Security configuration artifact that enables stricter control of entity properties that contain Personally Identifiable Information (PII). For more details, see Generating a PII Security Configuration Artifact. |
Creating an Instance Converter Module
An instance converter helps you create entity instance documents from raw source data. Generate a default instance converter using Entity Services, then customize the code for your application.
- Purpose of a Converter Module
- Generating a Converter Module Template
- Understanding the Default Converter Implementation
- Customizing a Converter Module
Purpose of a Converter Module
An instance converter is a key part of a model-driven application. The instance converter provides functions that facilitate the following tasks:
- Creating an entity instance from raw source data.
- Creating an entity envelope document that encapsulates an instance, metadata, and raw source data.
- Extracting a canonical instance or its attachments (such as the raw source) from an envelope document.
For more details on envelope documents, see What is an Envelope Document?.
You usually use the instance converter to create entity instance envelope documents and to extract canonical instances for use by downstream entity consumers.
You are expected to customize the generated converter module to meet the needs of your application.
Generating a Converter Module Template
Generate an instance converter from the JSON object-node or json:object representation of a model descriptor by calling the XQuery function es:instance-converter-generate or the JavaScript function es.instanceConverterGenerate. The result is an XQuery library module containing both model-specific and entity type specific code.
The input to the generator is a JSON descriptor. If you have an XML descriptor, you must first convert it to the expected format; for details, see Working With an XML Model Descriptor. The output of the generator function is an XQuery library module.
You can use the generated code as-is, but most applications will require customization of the converter implementation. For details, see Customizing a Converter Module.
The following example code generates a converter module from a previously persisted descriptor, and then saves the generated code as a file on the filesystem.
You could also insert the converter directly into the modules database, but the converter is an important project artifact that should be placed under source control. You will want to track changes to it as your application evolves.
Understanding the Default Converter Implementation
This section explores the default code generated for an instance converter module. The following topics are covered:
Module Namespace Declaration
The generated module begins with a module namespace declaration of the following form, derived from the info section of the model.
module namespace normalizedTitle = "baseUri/title-version";
For example, if your descriptor contains the following metadata:
"info": { "title": "Example", "version": "1.0.0", "baseUri": "http://marklogic.com/examples/" }
Then the converter module will contain the following module namespace declaration. Notice that the leading upper case letter in the title value (Example) is converted to lower case when used as a namespace prefix.
module namespace example = "http://marklogic.com/examples/Example-1.0.0";
If the model info section does not include a baseUri setting, then the namespace declaration uses the base URI http://example.org/.
If the baseUri does not end in a forward slash (/), then the module namespace URI is relative. For example, if baseUri in the previous example is set to http://marklogic.com/example, then the module namespace declaration is as follows:
module namespace example = "http://marklogic.com/examples#Example-1.0.0";
To learn more about the base URI, see Controlling the Model IRI and Module Namespaces.
Generated Functions
The converter module implements the following public functions, plus some private utility functions for internal use by these functions.
Each extract-instance-T function is a starting place for synthesizing an entity instance from raw source data. These functions are where you will apply most of your customizations to the generated code.
The input to an extract-instance-T function is a node containing the source data. The output is an entity instance represented as a json:object. By default, the instance encapsulates a canonicalized entity with the original source document. This is default envelope document repesentation.
In pseudo code, the generated implementation is as follows:
declare function ns:extract-instance-T( $source-node as node() ) as map:map { normalize the input source reference initialize variables for the values of each entity property initialize an empty instance of type T attach the source data to the instance assign values to the instance properties };
The portion of the function that sets up the entity property values is where you will apply most or all of your customizations. The default implementation assumes a one-to-one mapping between source and entity instance property values.
For example, suppose the model contains a Person entity type, with entity properties firstName, lastName, and fullName. Then the default extract-instance-Person implementation contains code similar to the following. The section following the begin customizations here comment is where you make most or all of your customizations.
declare function example:extract-instance-Name( $source-node as node() ) as map:map { let $source-node := es:init-source($source, 'Person') (: begin customizations here :) let $id := $source-node/id ! xs:string(.) let $firstName := $source-node/firstName ! xs:string(.) let $lastName := $source-node/lastName ! xs:string(.) let $fullName := $source-node/fullName ! xs:string(.) (: end customizations :) let $instance := es:init-instance($source-node, 'Person') (: Comment or remove the following line to suppress attachments :) =>es:add-attachments($source) return if (empty($source-node/*)) then $instance else $instance => map:with('id', $id) => map:with('firstName', $firstName) => map:with('lastName', $lastName) => map:with('fullName', $fullName) };
If the source XML elements or JSON objects have different names or require a more complex transformation than a simple type cast, customize the implementation. For more details, see Customizing a Converter Module.
Comments in the generated code describe the default implementation in more detail and provide suggestions for common customizations.
Customizing a Converter Module
Most customization involves changing the portion of each ns:extract-instance-T function that sets the values of the instance properties.
The default implementation of this portion of an extract function assumes that some property P in the entity instance gets its value from a node of the same name in the source data, and that a simple typecast is sufficient to convert the source value to the instance property type defined by the model.
For example, if an entity type named Person defines a string-valued property named firstName, then the generated code in firstName in example:extract-instance-Person related to intializing this property looks like the following:
let $firstName := $source-node/firstName ! xs:string(.) ... let $instance := es:init-instance($source-node, 'Person') .... if (empty($source-node/*)) then $instance else $instance ... => map:with('firstName', $firstName) ...
You might need to modify the code to perform a more complex transformation of the value, or extract the value from a different location in the source node. For example, if your source data uses the property name given to hold this information, then you would modify the generated code as follows:
let $firstName := $source-node/given ! xs:string(.)
The following list describes other common customization use cases:
- Synthesize a property value from other data. For example, aggregate an instance property from other values in your source data, or extract a value from other sources, based on information in the source node.
- Normalize data formats. For example, data such as dates, telephone numbers, and social security numbers often occur in multiple formats in raw data. You can normalize such data to a single format in your instances for easy search and comparison.
- Assign a default value for missing data. If you know that a required property in your entity instance is not always present in your source data, you can modify the code to ensure the entity instance contains a reasonable default value.
Once you finish customizing the code, you must deploy the module to your App Server before you can use the code. For details, see Deploying Generated Code and Artifacts.
For a more complete example, see Getting Started With Entity Services or the Entity Services examples on GitHub. For details on locating the GitHub examples, see Exploring the Entity Services Open-Source Examples.
Creating a Model Version Translator Module
You can use the Entity Services API to generate a template for transitioning entity instance data from one version of your model to another. This section covers the following topics:
- Purpose of a Version Translator
- Generating a Version Translator Module Template
- Understanding the Default Version Translator Implementation
For an end-to-end example of handling model version changes, see the Entity Services examples on GitHub. For more details, see Exploring the Entity Services Open-Source Examples.
Purpose of a Version Translator
A version translator is an XQuery library module that helps you convert instance data conforming to one model version into another.
The version translator only addresses instance conversion. Model changes can also require changes to other artifacts, such as the TDE template, schema, query options, instance converter, and database configuration. For more details, see Managing Model Changes.
Though you can run the generated translator code as-is, it is meant to serve as a starting point for your customizations. Depending on the ways in which your source and target models differ, you might be required to modify the code.
Generating a Version Translator Module Template
Generate a version translator using the XQuery function es:version-translator-generate or the JavaScript function es.versionTranslatorGenerate. The output is an XQuery library module that you can customize and install in your modules database.
The inputs to the generator are source and target model descriptors, as JSON. If you have an XML descriptor, you must first convert it to the expected format; for details, see Working With an XML Model Descriptor.
You can use the generated code as-is, but most applications will require customization of the converter implementation. For details, see Customizing a Version Translator Module.
You must install the translator module in your modules database before you can use it. For details, see Deploying Generated Code and Artifacts.
The following example code generates a translator module from previously persisted descriptors, and then saves the generated code as a file on the filesystem. The resulting module is designed to convert instances of version 1.0.0 to instances of version 2.0.0.
You could also insert the translator directly into the modules database, but the translator is an important project artifact that should be placed under source control. You will want to track changes to it as your application evolves.
Understanding the Default Version Translator Implementation
This section explores the default code generated for a version translator module. This information can help guide your customizations. This section covers the following topics:
Module Namespace Declaration
The generated module begins with a module namespace declaration of the following form, derived from the info section of the two models.
module namespace title2-from-title1 = "baseUri2/title2-version2-from-title1-version1";
Where title1 and version1 come from the info section of the source model, title2 and version2 come from the info section of the target model, and baseUri2 comes from the info section of the target model. (The base URI from the source model is unused.) The titles are normalized to all lower case.
For example, suppose the source and target models contain the following info sections, reflecting a change from version 1.0.0 to version 2.0.0 of a model with the title Person. The model title is unchanged between versions.
Then the version translator module will contain the following module namespace declaration.
module namespace person-from-person = "http://example.org/example-person/Person-2.0.0-from-Person-1.0.0";
If the info section of the target model does not include a baseUri setting, then the namespace declaration uses the base URI http://example.org/.
If the target baseUri does not end in a forward slash (/), then the module namespace URI is relative. For example, if baseUri in the previous example has no trailing slash, then the module namespace declaration is as follows:
module namespace person-from-person = "http://example.org/example-person#Person-2.0.0-from-Person-1.0.0";
Generated Functions
The version translator module contains a translation function named ns:convert-instance-T for each entity type T defined in the target model. The module can contain additional functions, but these for internal use by the translator module. The convert-instance-T functions are the public face of the converter.
For example, if the target model defines a Name entity type and a Person entity type and the title of the both the source and target model is Person, then the generated translation module will contain the following functions:
The input to a convert-instance-T function should be an entity instance or envelope document conforming to the source model version of type T. The output is an in-memory instance conforming to the target model version of type T, similar to the output from the extract-instance-T function of an instance converter module.
For each entity type property that is unchanged between the two versions, the default convert-instance-T code simply copies the value from source instance to target instance. Actual differences, such as a property that only exists in the target model, require customization of the translator. For details, see Customizing a Version Translator Module.
For an example, see example-version in the Entity Services examples on GitHub. To download a copy of the examples, see Exploring the Entity Services Open-Source Examples.
Customizing a Version Translator Module
This section describes some common model changes, how they are handled by the default translation code, and when customizations are likely to be required.
Most of your translator customizations go in the block of variable declarations near the beginning of the conversion function. For example, the block of code shown in bold, below. These declarations set up the values to be assigned to the properties of the new instance, later in the conversion function. The variable names and default initial values are model-dependent.
declare function person-from-person:convert-instance-Person( $source as node() ) as map:map { let $source-node := es:init-translation-source($source, 'Person') let $id := $source-node/id ! xs:string(.) let $firstName := $source-node/firstName ! xs:string(.) let $lastName := $source-node/lastName ! xs:string(.) let $fullName := $source-node/fullName ! xs:string(.) return...
The table below provides a brief overview of some common entity type definition changes and what customizations they might require. The context for the code snippets is the property value initialization block shown in the previous example. All the code snippets assume a required property; if the property under consideration is optional, then the call to map:with would be replaced by a call to es:optional.
| Use Case | Notes on the Generated Code |
|---|---|
| Unchanged Property | The default code copies the value of the source instance to the target instance. For array valued properties, the es:extract-array utility function performs the copy. For example, if both source and target contain a property named thing, the default translator function includes a line similar to one of the following: (: atomic type (string, in this case) :) let $thing := $source-node/thing ! xs:string(.) (: array type (item type string, in this case) :) let $thing := ex:extract-array($source-node/thing, xs:string#)) (: reference to a locally resolvable "Name" entity of type :) let $extract-reference-Name := es:init-instance(?, 'Name') let $thing := $soure-node/thing/* ! $extract-reference-Name(.) |
| Property Type Change From One Atomic Type to Another | The default code assumes a simple type cast to the target type is sufficient. Customization is required if the types are not meaninfully convertible this way. For example, if a property named rating has string type in the source but float type in the target, then the generated code includes the following: let $rating := $source-node/rating ! xs:float(.) |
| Property Type Change from Atomic to Array Type | The default code constructs an array containing a single item that is the value from the source property. This is done by For example, if the rating property is a simple string value in the source, but an array of float values in the target, then the generated code contains the following: let $rating := es:extract-array($source-node/rating, xs:float#1)) |
| Property Type Change From Array to Atomic Type | The default code populates the target instance with the value from the first item in the source array. A simple type cast is used to convert the value; customization is required if the source and target value types differ and are not meaninfully convertible this way. For example, if the rating property is an array of float values in the source and a single string value in the target, then you see: (: Warning: potential data loss, truncated array. :) let $rating := xs:string( fn:head($source-node/rating) ) |
| Property Type Change From Atomic to Local Reference Type | The default code creates a reference from the source value. Since the source value is not an entity, customization is required to construct a meaningful reference. For example, if a property named name is a string in the source but a locally resolvable reference to a let $name := $source-node/name ! es:init-instance(?, 'Name')(.) |
| Property in Target Only | The default code copies the value from the source instance to the target instance. However, the source instance probably doesn't contain this property, so customization is usually required. You might modify the code to assign a meaningful default value or extract the new value from the raw source in the attachments of the source envelope. For example, if only the target contains a float typed property named rating, then the generated code includes the following: (: The following property was missing from the source type. The XPath will not up-convert without intervention. :) let $rating := $source-node/rating ! xs:float(.) You could modify the code to give the rating property a default value of 0: let $rating := 0 ! xs:float(.) Alternatively, if an XML source envelope contains the desired value in its attachments, you could extract it as follows: let $rating := $source-node/rating ! xs:float(.)=> map:with('rating', xs:float( $source//es:attachments/Person/rating/fn:data())) |
| Property in Source Only | The default code contains only a commented out line you can use as a basic template for extraction, if appropriate. If this property has no analog in the target model, you can remove or ignore the commented out code. For example, if only the source contains a property named address, then the generated code includes the following: (: The following properties are in the source, but not the target => map:with('NO TARGET', xs:string($source-node/Person/address)) :) |
| Rename a Property | This appears as if the property in the source model was removed and a new property was added to the target model. Treat it like the Property in Target Only case, above, but use the original property as the source value. For example, if the source model contains a property named firstName that you change to first, then the default code contains the following: let $first := $source-node/first ! xs:string(.) Modify it to pull the value from the firstName property of the source: let $first := $source-node/firstName ! xs:string(.) |
| Entity Type Added to Target Model | A conversion function is generated that copies properties from the input source node to the output instance as if there are no differences. The code is equivalent to what es:instance-converter-generate produces. You should usually customize this function. For example, you could modify it to extract the new entity type property values from the raw source attachment of a source envelope. You could also use raw source as input to this function, rather than an envelope document. |
| Entity Type Removed from Source Model | A commented out conversion function is generated that copies properties from the input source node to the output instance as if there are no differences. You must uncomment and customize this function if you plan to store the values from instances of the defunct entity type somewhere in instances based on the target model. |
Generating a TDE Template
You can generate a Template Driven Extraction (TDE) template from your model using Entity Services. Once installed, the template enables the following capabilities for your model-based application:
- Query your entity instances as row data using SQL or the Optic API.
- Query facts about and infer connections between your entity instances using SPARQL or the Optic API.
You can only take advantage of these capabilities for entity types that define a primary key. Without a primary key, there is no way to uniquely identify entity instances. For details on defining a primary key, see Identifying the Primary Key Entity Property.
This section contains the following topics:
- Generating a TDE Template
- Characteristics of a Generated Template
- Deploying a TDE Template
- Example: TDE Template Generation and Deployment
To learn more about TDE, see Template Driven Extraction (TDE) in the Application Developer's Guide.
Generating a TDE Template
Use the es:extraction-template-generate XQuery function or the es.extractionTemplateGenerate JavaScript function to create a TDE template. The input to the template generation function is a JSON or json:object representation of a model descriptor. You can use the template as-is, or customize it for your application. You must install the template before your application can benefit from it. For details, see Deploying a TDE Template.
Any hyphens (-) in the model title, entity type names, or entity property names are converted to underscores (_) when used in the generated template, in order to avoid invalid SQL names.
For example, the following code snippet generates a template from a model previously persisted in the database. For a more complete example, see Example: TDE Template Generation and Deployment.
| Language | Example |
|---|---|
| XQuery | es:extraction-template-generate( fn:doc('/es-gs/models/person-1.0.0.json')) |
| JavaScript | es.extractionTemplateGenerate( cts.doc('/es-gs/models/person-1.0.0.json')); |
The template is an important project artifact that you should put under source contol.
If you customize the template, you should validate it. You can use the tde:validate XQuery function or the tde.validate JavaScript function for standalone validation, or combine validation with insertion, as described in Deploying a TDE Template.
Characteristics of a Generated Template
A TDE template generated by the Entity Services API is intended to apply to entity envelope documents with the structure produced by an instance converter module. If you use a different structure, you will have to customize the template. For more details, see What is an Envelope Document?.
The generated template has the following characteristics:
- The default root context for the template matches instance data in both XML and JSON envelopes, assuming the envelopes conform to the Entity Services envelope convention. The generated template includes comments on how to change the context path for better performance if you only use a single envelope format (only XML or only JSON).
- A triples sub-template is defined for each entity type in the model that defines a primary key. This enables Semantic queries and inferencing on entity instances. For details, see Triples Sub-Template Characteristics.
- A rows sub-template is defined for each entity type in the model that defines at least one required property. This enables querying instances as rows using SQL or the Optic API. For details, see Rows Sub-Template Characteristics and Rows Template Array Property View Characteristics.
- If you define a namespace prefix for an entity type as described in Defining a Namespace URI for an Entity Type, the prefix is used in XPath expressions in the template. Namespace prefixes are not used for references to entity types external to the model because such prefixes are unknown to the template generator.
Triples Sub-Template Characteristics
The triples sub-template for an entity type T has the following characteristics.
- A triples sub-template is only generated for entity types that define a primary key.
- The context for the sub-template is
./T. That is,//es:instance/T in an envelope document. For example,//es:instance/Personif the model defines aPersonentity type. - A subject identifier variable named
subject-iriis defined. The value of this variable is an IRI created by concatenating the entity type name with an instance's primary key value. This IRI identifies a particular instance of the entity type. - A
triplesspecification that will cause the following facts (triples) to be generated about each instance of type T:- This entity has type T, where the entity is identified by its primary key, and the type is identified by the
subject-iriof the entity type. In RDF terms, the triple expresses<subject-iri> a <entity-type-iri>. - This entity is defined by this model, where the entity is identified by its primary key, and the model is identified by the persisted descriptor URI. In RDF terms, the triple expresses
<subject-iri> rdfs:isDefinedBy <descriptor-document-uri>. This triple defines how to join instance/class membership to the instance document.
- This entity has type T, where the entity is identified by its primary key, and the type is identified by the
Rows Sub-Template Characteristics
The rows sub-template for an entity type T has the following characteristics.
- A rows sub-template is only generated for entity types that define at least one required property. (A primary key property is implicitly a required property.)
- The context for the sub-template is
./T. That is,//es:instance/T in an envelope document. - The schema name for the sub-template is the same as model title.
- For each entity property that does not have array type, a column with same name as the property is defined. (A property with array type is supported with a related view, so it is not present in the main view.)
- For each entity property with array type, a separate view named T
_propertyName is defined. For example,Person_friends, if thePersonentity type has an array typed property namedfriends. The characteristics of this view are described below. - An entity property with
irias its data type is indexed asIRI. - Any entity property that is not required is marked as nullable.
Rows Template Array Property View Characteristics
The T_propertyName view generated in the rows sub-template for an entity property with array type has the following characteristics:
- If the array item type is a scalar type, the view has two colums:
- If the array item type is a local reference and the referenced type defines a primary key, then view has two columns:
- If the array item type is a local reference and the referenced type does not define a primary key, then:
- If the array item type is an external reference, then the view has two columns:
Customizing a TDE Template
The following entity type characteristics result in a TDE template that requires customization:
- If no primary key is defined for an entity type that contains an array-typed property, you will like need to customize the template to define an appropriate type and value for the left column in the array view. This view is discussed in more detail in Rows Template Array Property View Characteristics.
- The template generator cannot determine the data type of an external entity type reference, so it defaults to string. You must manually set the type in the template.
- If you choose to embed entity instances inside one another, then the
contextelement of the embedded type must be changed to reflect its position in instance documents.
You can make other customizations required by your application. For example, you might want to generate additional facts about your instances, or remove some columns from a row sub-template.
The generated template should work for both XML and JSON envelope documents in most cases, but some entity type structures might require customization of XPath expressions in the template in order to accomodate both formats.
For more details on the structure and content of TDE templates, see Template Driven Extraction (TDE) in the Application Developer's Guide.
Deploying a TDE Template
You must install your TDE template in the schemas database associated with your content database. The template must be in the special collection http://marklogic.com/xdmp/tde for MarkLogic to recognize it as template document.
Choose one of the following template installation methods:
- Use the tde:template-insert XQuery function or the tde.templateInsert JavaScript function. This method combines validation and installation in one step, and automatically inserts the template into the required collection.
- Use any general-purpose document insertion interface, such as xdmp:document-insert (XQuery) or xdmp.documentInsert (JavaScript). You must explicitly insert the template document into the special collection
http://marklogic.com/xdmp/tde. No validation is performed.
For more details, see Validating and Inserting a Template in the Application Developer's Guide.
Once your template is installed, MarkLogic will update the row index and generate triples related to your instances whenever you ingest instances or reindexing occurs.
Example: TDE Template Generation and Deployment
The following example generates a TDE template from the model used in Getting Started With Entity Services, and then installs the template in the schemas database.
The following code generates a template from a previously persisted model, and then saves the template to a file on the filesystem as $ARTIFACT_DIR/person-templ.xml.
You are not required to save the template to the filesystem. However, the template is an important project artifact that you should place under source control. Saving the template to the filesystem makes it easier to do so.
If you apply the code above to the model from Getting Started With Entity Services, the resulting template defines two sub-templates. The first sub-template defines how to extract semantic triples from Person entity instances. The second sub-template defines how to extract a row-oriented projection of Person entity instances.
<template xmlns="http://marklogic.com/xdmp/tde"> ... <templates> <template xmlns:tde="http://marklogic.com/xdmp/tde"> <context>./Person</context> <vars> <var> <name>subject-iri</name> <val>sem:iri(...)</val> </var> ... </vars> <triples>...</triples> </template> <template xmlns:tde="http://marklogic.com/xdmp/tde"> <context>./Person</context> <rows>...</rows> ... </template> </templates> </template>
If the model includes additional entity types, then the template contains additional, similar sub-templates for these types.
The following code validates and installs a template using the convenience function provided by the TDE library module. Evaluate this code in the context of your content database.
If the query runs sucessfully, the document /es-gs/templates/person-1.0.0.xml is created in the schemas database. If you explore the schemas database in Query Console, you should see that the template is in the special collection http://marklogic.com/xdmp/tde.
Generating an Entity Instance Schema
Entity Services can generate an XSD schema that you can use to validate canonical (XML) entity instances. Instance validation can be especially useful if you have a client or middle tier application submitting instances.
This section contains the following topics:
- Schema Generation Overview
- Schema Characteristics
- Schema Customization
- Example: Generating and Installing an Instance Schema
- Example: Validating an Instance Against a Schema
Schema Generation Overview
To generate a schema, apply the es:schema-generate XQuery function or the es.schemaGenerate JavaScript function to the object-node or json:object representation of a model descriptor, as shown in the following table. For a more complete example, see Example: Generating and Installing an Instance Schema.
| Language | Example |
|---|---|
| XQuery | es:schema-generate(fn:doc('/es-gs/models/person-1.0.0.json')) |
| JavaScript | es.schemaGenerate(cts.doc('/es-gs/models/People-1.0.0.json')); |
The schema is an important project artifact, so you should place it under source control.
Before you can use the generated schema(s) for instance validation, you must deploy the schema to the schemas database associated with your content database. You can use any of the usual document insertion APIs for this operation.
If your model defines multiple entity types and the entity type definitions do not all use the same namespace, a schema is generated for each unique namespace. Install all of the generated schemas in the schemas database.
Use the xdmp:validate XQuery function or the xdmp.validate JavaScript function to validate instances against your schema. For an example, see Example: Validating an Instance Against a Schema.
Note that you can only validate entity instances expressed as XML. You can extract the XML representation of an instance from an envelope document using the es:instance-xml-from-document XQuery function or the es.instanceXmlFromDocument JavaScript function.
Schema Characteristics
The Entity Services API applies the following rules when generating a schema from a model:
- A scalar property type is translated into a simple, type-enforced
xs:element. - The schema includes an
xs:complexTypefor each entity type defined by the model. This type contains a sequence of elements representing the entity type properties. - For each external entity type reference, a type is generated that can hold a value for a reference of that type by using the string after the last slash (...Äò/') in the external reference URI.
- For each local entity type reference, an
es:complexTypeis generated. - Array typed entity properties are handled using
minOccursandmaxOccurson the property'sxs:element. - Any entity property that is not a primary key or required is set to
minOccurs=0. - A required property has cardinality 1.
- The automated schema generation cannot resolve multiple properties with same name, but different data type. If this occurs, an
xs:elementis generated for one property, and then thexs:elementdefinitions for the other properties will be commented out. You must customize the schema (or modify your model) to resolve this conflict. - A separate schema is generated for each namespace declared in the model. For more details on using namespaces in entity type definitions, see Defining a Namespace URI for an Entity Type.
Schema Customization
The following list describes some situations in which schema customization might be needed.
- If your model contains multiple entity type properties with the same name, only one of them will be reflected in the schema. The other(s) will be commented out. Change the schema (or your model) to resolve this conflict.
- Depending on how entity references are used in the model, parts of the schema might be superfluous and can be removed.
- You might have to choose between validating entity references or validating embedded entity instances, depending on the choices you make with respect to normalization and entity document structure.
Example: Generating and Installing an Instance Schema
The following example generates a schema from a previously persisted model, and then inserts it into the schemas database.
Since the model is in the content database and the schema must be inserted into the schemas database, xdmp:eval is used to switch database contexts for the schema insertion. If you generated the schema and saved it to the filesystem first, then you would only have to work with the schemas database, so the eval would be unnecessary.
The following code inserts a schema with the URI /es-gs/person-1.0.0.xsd into the schemas database associated with the content database that holds the source model. Assume the model was previously persisted as a document with URI /es-gs/models/person-1.0.0.json.
Example: Validating an Instance Against a Schema
The following example validates an instance against a schema generated using the es:schema-generate XQuery function or the es.schemaGenerate Server-Side JavaScript function. It is assumed that the schema is already installed in the schema database associated with the content database, as shown in Example: Generating and Installing an Instance Schema.
The following code validates an entity instance within a previously persisted envelope document. Assume this instance was created using the instance converter module for its entity type, and therefore is valid. Thus, the validation succeeds. The query returns an empty xdmp:validation-errors element in XQuery and an empty object in JavaScript.
The following example validates an in-memory instance against the schema. The schema is based on the model from Getting Started With Entity Services. The instance was intentionally created without a required property (id) so that it will fail validation.
Generating a PII Security Configuration Artifact
You identify PII entity properties using the pii property of an entity model, as described in Identifying Personally Identifiable Information (PII). Then, use the es:pii-generate XQuery function or the es.piiGenerate JavaScript function to generate a security configuration artifact that enables stricter access control for PII entity instance properties.
The generated configuration contains an Element Level Security (ELS) protected path definition for each PII property, and an ELS query roleset configuration. The protected path configuration limits read access to users with the pii-reader security role. The query roleset prevents users without the pii-reader role from seeing the protected content in response to a query or XPath expression. The pii-reader role is pre-defined by MarkLogic.
To learn more about Element Level Security, protected paths, and query rolesets, see Element Level Security in the Security Guide.
For example, the following model descriptors specify that the name and bio properties can contain PII:
Assuming the above model descriptor is persisted in the database as /es-ex/models/people-4.0.0.json, then the following code generates a database configuration artifact from the model:
The generated security configuration artifact should look similar to the following. If you deploy this configuration, then only users with the pii-reader security role can read the name and bio properties of a Person instance. The pii-reader role is pre-defined by MarkLogic.
{ "name": "People-4.0.0", "desc": "A policy that secures name,bio of type Person", "config": { "protected-path": [ { "path-expression": "/envelope//instance//Person/name", "path-namespace": [], "permission": { "role-name": "pii-reader", "capability": "read" } }, { "path-expression": "/envelope//instance//Person/bio", "path-namespace": [], "permission": { "role-name": "pii-reader", "capability": "read" } } ], "query-roleset": { "role-name": [ "pii-reader" ] } } }
Note that the configuration only includes protected paths for PII properties in the entity instance. Envelope documents also contain the original source document as an attachment by default. Any PII in the source attachment is not protected by the generated configuration. You might want to define additional protected paths or modify the extract-instance-T function of your instance converter module to exclude the source attachment.
Deploy the artifact using the Configuration Management API. For example, if the file pii-config.json contains the configuration generated by the previous example, then the following command adds the protected paths and query roleset to MarkLogic's security configuration:
curl --anyauth --user user:password -X PUT -i \ -d @./pii-config.json -H "Content-type: application/json" \ http://localhost:8002/manage/v3
You can add additional configuration settings to the generated artifact, or merge the generated settings into configuration settings created and maintained elsewhere. For example, you could configure additional protected paths to control access to the source data for the name and bio properties in the source attachment of your instance envelope documents.
Generating a Database Configuration Artifact
Use the es:database-properties-generate XQuery function or the es.databasePropertiesGenerate JavaScript function to create a database configuration artifact from the JSON object-node or json:object representation of a model descriptor. This artifact is helpful for configuring your content database. You are not required to use this artifact; it is a convenience feature.
The generated configuration information always has at least the following items, and may contain additional property definitions, depending on the model:
- Enable the triple index and the collection lexicon, both of which are required for querying a model as described in Search Basics for Models.
- Define the es namespace prefix globally so that it can be used in path queries.
If an entity type definition specifies entity properties for range index and word lexicon configuration, then the database configuration artifact includes corresponding index and/or lexicon configuration information.
For example, the following model descriptors specify a path range index for the id and rating properties and a word lexicon for the bio property of the Person entity type:
Assuming the above model descriptor is persisted in the database as /es-ex/models/people-3.0.0.json, then the following code generates a database configuration artifact from the model:
The generated configuration artifact should look similar to the following. Notice that range index information is included for id and rating and word lexicon information is included for bio.
{ "database-name": "%%DATABASE%%", "schema-database": "%%SCHEMAS_DATABASE%%", "path-namespace": [ { "prefix": "es", "namespace-uri": "http://marklogic.com/entity-services" } ], "element-word-lexicon": [ { "collation": "http://marklogic.com/collation/en", "localname": "bio", "namespace-uri": "" } ], "range-path-index": [ { "collation": "http://marklogic.com/collation/en", "invalid-values": "reject", "path-expression": "//es:instance/Person/id", "range-value-positions": false, "scalar-type": "int" }, { "collation": "http://marklogic.com/collation/en", "invalid-values": "reject", "path-expression": "//es:instance/Person/rating", "range-value-positions": false, "scalar-type": "float" } ], "triple-index": true, "collection-lexicon": true }
Note that the generated range index configuration disables range value positions and rejects invalid values by default. You might choose to change one or both of these settings, depending on your application.
You can add additional configuration settings to the generated artifact, or merge the generated settings into configuration settings created and maintained elsewhere.
You can use the generated configuration properties with your choice of configuration interface. For example, you can use the artifact with the REST Management API (after minor modification), or you can extract the configuration information to use with the XQuery Admin API.
To use the generated database configuration artifact with the REST Management API method PUT /manage/v2/databases/{id|name}/properties, make the following modifications:
- Replace
%%DATABASE%%with the name of your content database. - Replace
%%SCHEMAS_DATABASE%%with the name of the schemas database associated with your content database. - If you have configured other range indexes or word lexicons into your database, merge your existing index or lexicon configuration with the generated configuration so that no settings are lost.
For example, you can use a curl command similar to the following to change the properties of the database named es-ex. Assume the file db-props.json contains the previously shown config artifact above, with the database-name and schema-database property values modified to es-ex and Schemas, respectively.
curl --anyauth --user user:password -X PUT -i \ -d @./db-props.json -H "Content-type: application/json" \ http://localhost:8002/manage/v2/databases/es-ex/properties
If you then examine the configuration for the es-ex database using the Admin Interface or the REST Management API method GET /manage/v2/databases/{id|name}/properties, you should see the expected range indexes and word lexicon have been created.
For more information about database configuration, see the following:
Generating Query Options for Searching Instances
This section describes how to use the Entity Services API to generate a set of query options you can use to search entity instances using the XQuery Search API or the REST, Java, and Node.js Client APIs. This section covers the following topics:
- Options Generation Overview
- Characteristics of the Generated Options
- Example: Generating Query Options
For more details and examples, see Querying a Model or Entity Instances.
Options Generation Overview
Generate model-based query options using the es:search-options-generate XQuery function or the es.searchOptionsGenerate JavaScript function. Pass in the JSON object-node or json:object representation of a model descriptor.
For example, if the document /es-gs/models/person-1.0.0.json is a previously persisted descriptor, then you can generate query options from the model with one of the following calls.
| Language | Example |
|---|---|
| XQuery | es:search-options-generate( fn:doc('/es-gs/models/person-1.0.0.json')) |
| JavaScript | es.searchOptionsGenerate( cts.doc('/es-gs/models/person-1.0.0.json')); |
For a more complete example, see Example: Generating Query Options.
You can use the generated options in the following ways:
- Pass them as the second parameter of the search:search or search:resolve XQuery functions, or the search.search or search.resolve JavaScript functions.
- Embed them in a combined query used with the REST, Java, or Node.js APIs.
- Install them in the database and use them as persistent query options with the REST, Java, or Node.js APIs.
- Use them as a jumping off point for creating constraint bindings for use with the cts:parse XQuery function or the cts.parse JavaScript function. Then use the resulting cts:query object with cts:search or the JSearch API.
For an example and discussion of the options, see Example: Using the Search API for Instance Queries.
Characteristics of the Generated Options
The generated options include the following:
- A value constraint named entity-type for constraining searches to entities of a particular type. For example:
<search:constraint name="entity-type"> <search:value> <search:element ns="http://marklogic.com/entity-services" name="title"/> </search:value> </search:constraint>
- A URI value constraint named uris. For example:
<search:values name="uris"> <search:uri/> </search:values>
- An
extract-document-dataoption for returning just the canonical entity instance(s) from matched documents. For example, the following option extracts just thePersonentity instance from matched documents:<search:extract-document-data selected="include"> <search:extract-path xmlns:es="..."> //es:instance/(Person) </search:extract-path> </search:extract-document-data>
- An
additional-queryoption that constrains results to documents containinges:instanceelements. For example:<search:additional-query> <cts:element-query xmlns:cts="http://marklogic.com/cts"> <cts:element xmlns:es="...">es:instance</cts:element> <cts:true-query/> </cts:element-query> </search:additional-query>
- Options that disable faceting and snippeting (in favor of just extracting the instances). For example:
<search:return-facets>false</search:return-facets> <search:transform-results apply="empty-snippet"/>
- An option that enables unfiltered search. For example:
<search:search-option>unfiltered</search:search-option>
- If the model defines a primary key, a value constraint on the primary key property. For example:
<search:constraint name="id"> <search:value> <search:element ns="" name="id"/> </search:value> </search:constraint>
- For each property named in the
pathRangeIndexorrangeIndexproperty of an entity type definition, a path range index constraint with the same name as the entity property. For example:<search:constraint name="rating"> <search:range type="xs:float" facet="true"> <search:element ns="" name="rating" /> </search:range> </search:constraint>
- For each property named in the
elementRangeIndexproperty of an entity type definition, an element range index constraint with the same name as the entity property. For example:<search:constraint name="rating"> <search:range type="xs:float" facet="true"> <search:path-index xmlns:es="..."> //es:instance/Person/rating </search:path-index> </search:range> </search:constraint>
- For each property named in the
wordLexiconproperty of an entity type definition, a word constraint with the same name as the entity property. For example:<search:constraint name="bio"> <search:word> <search:element ns="" name="bio"/> </search:word> </search:constraint>
- If an entity type includes more than one property in the range index specification, a
tuplesoption with the same name as the entity type for finding co-occurrences of the indexed properties. For example:<search:tuples name="Item"> <search:range type="xs:int" facet="true"> <search:path-index xmlns:es="..."> //es:instance/Item/price </search:path-index> </search:range> <search:range type="xs:float" facet="true"> <search:path-index xmlns:es="..."> //es:instance/Item/rating </search:path-index> </search:range> </search:tuples>
The generated options include extensive comments to assist you with customization. The options are usable as-is, but optimal search configuration is highly application dependent, so it is likely that you will extend or modify the generated options.
If the primary key property is also listed in the range index specification, then both a value constraint and a range constraint would be generated with the same name. Since this is not allowed, one of these constraints will be commented out. You can change the name and uncomment it. For an example of this conflict, see Example: Generating Query Options.
Example: Generating Query Options
The following example generates a set of query options from a model and saves the results to a file on the filesystem so you can place it under source control or make modifications.
This example assumes the following descriptor has been inserted into the database with the URI /es-ex/models/people-1.0.0.json.
{ "info": { "title": "People", "description": "People Example", "version": "1.0.0" }, "definitions": { "Person": { "properties": { "id": { "datatype": "int" }, "name": { "datatype": "string" }, "bio": { "datatype": "string" }, "rating": { "datatype": "float" } }, "required": [ "name" ], "primaryKey": "id", "pathRangeIndex": [ "id", "rating" ], "wordLexicon": [ "bio" ] }}}
The following code generates a set of query options from the above model. The options are saved to the file ARTIFACT_DIR/people-options.xml.
The resulting options should be similar to the following.
<search:options xmlns:search="http://marklogic.com/appservices/search"> <search:constraint name="entity-type"> <search:value> <search:element ns="http://marklogic.com/entity-services" name="title"/> </search:value> </search:constraint> <search:constraint name="id"> <search:value> <search:element ns="" name="id"/> </search:value> </search:constraint> <!--This item is a duplicate and is commented out so as to create a valid artifact. <search:constraint name="id" xmlns:search="http://marklogic.com/appservices/search"> <search:range type="xs:int" facet="true"> <search:path-index xmlns:es="http://marklogic.com/entity-services"> //es:instance/Person/id </search:path-index> </search:range> </search:constraint> --> <search:constraint name="rating"> <search:range type="xs:float" facet="true"> <search:path-index xmlns:es="http://marklogic.com/entity-services"> //es:instance/Person/rating </search:path-index> </search:range> </search:constraint> <search:constraint name="bio"> <search:word> <search:element ns="" name="bio"/> </search:word> </search:constraint> <search:tuples name="Person"> <search:range type="xs:int" facet="true"> <search:path-index xmlns:es="http://marklogic.com/entity-services"> //es:instance/Person/id </search:path-index> </search:range> <search:range type="xs:float" facet="true"> <search:path-index xmlns:es="http://marklogic.com/entity-services"> //es:instance/Person/rating </search:path-index> </search:range> </search:tuples> <!--Uncomment to return no results for a blank search, rather than the default of all results <search:term xmlns:search="http://marklogic.com/appservices/search"> <search:empty apply="no-results"/> </search:term> --> <search:values name="uris"> <search:uri/> </search:values> <!--Change to 'filtered' to exclude false-positives in certain searches--> <search:search-option>unfiltered</search:search-option> <!--Modify document extraction to change results returned--> <search:extract-document-data selected="include"> <search:extract-path xmlns:es="http://marklogic.com/entity-services"> //es:instance/(Person) </search:extract-path> </search:extract-document-data> <!--Change or remove this additional-query to broaden search beyond entity instance documents--> <search:additional-query> <cts:element-query xmlns:cts="http://marklogic.com/cts"> <cts:element xmlns:es="http://marklogic.com/entity-services"> es:instance </cts:element> <cts:true-query/> </cts:element-query> </search:additional-query> <!--To return facets, change this option to 'true' and edit constraints--> <search:return-facets>false</search:return-facets> <!--To return snippets, comment out or remove this option--> <search:transform-results apply="empty-snippet"/> </search:options>
Notice that two constraints are generated for the id property. A value constraint is generated because id is the primary key for a Person entity. A path range constraint is generated because id is listed in the pathRangeIndex property of the Person entity type definition. Since it is not possible for two constraints to have the same name in a set of options, the second constraint is commented out:
<search:constraint name="id"> <search:value> <search:element ns="" name="id"/> </search:value> </search:constraint> <!--This item is a duplicate and is commented out so as to create a valid artifact. <search:constraint name="id" xmlns:search="http://marklogic.com/appservices/search"> <search:range type="xs:int" facet="true"> <search:path-index xmlns:es="http://marklogic.com/entity-services"> //es:instance/Person/id </search:path-index> </search:range> </search:constraint>
If you do not need both constraint types on id, you can remove one of them. Alternatively, you can change the name of at least one of these constraints and uncomment the path range constraint.
For an example of using the generated options, see Example: Using the Search API for Instance Queries.
Deploying Generated Code and Artifacts
Library modules and some configuration artifacts that you generate using the Entity Services API must be installed before you can use them.
- Code modules: Insert into the modules database associated with your App Server.
For example, if you're using the pre-configured App Server on port 8000, insert your instance converter module into the Modules database. For more details, see Importing XQuery Modules, XSLT Stylesheets, and Resolving Paths in the Application Developer's Guide.
- Schemas: Insert into the schemas database associated with your content database.
For example if your content database is the pre-configured Documents database, deploy schemas to the Schemas database.
- TDE templates: Insert into the schemas database associated with your content database.
For example if your content database is the pre-configured Documents database, deploy templates to the Schemas database. For details, see Deploying a TDE Template.
- Database configuration: This artifact does not require installation. Rather, you use it as input during configuration operations, as described in Generating a Database Configuration Artifact.
- Query Options: Installation on MarkLogic is optional. If you choose to use these as persistent options with the Java, Node.js, or REST Client APIs, see Pre-Installing Query Options. Otherwise, no installation is required.
Unless otherwise noted, you can install a module or configuration artifact using any document insertion interfaces, including the following MarkLogic APIs:
- The xdmp:document-insert XQuery function or the xdmp.documentInsert Server-Side JavaScript function.
- The Java, Node.js, and REST Client APIs. The Client APIs include interfaces specifically for managing documents in the modules database associated with a REST API instance, as well as normal document operations that can be performed against any database.
For an example of deploying a module using simple document insert, see Create and Deploy an Instance Converter (XQuery) or Create and Deploy an Instance Converter (JavaScript).
In addition, open source application deployment tools such as ml-gradle and roxy (both available on GitHub) support module deployment tasks. The Entity Services examples on GitHub use ml-gradle for this purpose; for more details, see Exploring the Entity Services Open-Source Examples.