
MarkLogic 9 Product DocumentationApplication Developer's Guide — Chapter 21
Using Triggers to Spawn Actions
MarkLogic Server includes pre-commit and post-commit triggers. This chapter describes how triggers work in MarkLogic Server and includes the following sections:
- Overview of Triggers
- Triggers and the Content Processing Framework
- Pre-Commit Versus Post-Commit Triggers
- Trigger Events
- Trigger Scope
- Modules Invoked or Spawned by Triggers
- Creating and Managing Triggers With triggers.xqy
- Simple Trigger Example
- Avoiding Infinite Trigger Loops (Trigger Storms)
Overview of Triggers
Conceptually, a trigger listens for certain events (document create, delete, update, or the database coming online) to occur, and then invokes an XQuery module to run after the event occurs. The trigger definition determines whether the action module runs before or after committing the transaction which causes the trigger to fire.
Creating a robust trigger framework is complex, especially if your triggers need to maintain state or recover gracefully from service interruptions. Before creating your own custom triggers, consider using the Content Processing Framework. CPF provides a rich, reliable framework which abstracts most of the event management complexity from your application. For more information, see Triggers and the Content Processing Framework.
Triggers run as the user performing the update transaction that caused the trigger. The programmer is free to call amped library functions in triggers if the use case requires certain roles to work correctly. The only exception here is the database-online trigger, because in that case there is no triggering update transaction, and hence no user. For database-online trigger the user is specified by the trigger itself. Some customization of CPF installation scripts is required in order to insure that this event is run as an existing administrative user.
Trigger Components
A trigger definition is stored as an XML document in a database, and it contains information about the following:
A trigger definition is created and installed by calling trgr:create-trigger. To learn more about trigger event definitions, see Trigger Events.
Databases Used By Triggers
A complete trigger requires monitored content, a trigger definition, and an action module. These components involve 3 databases:
- The content database monitored by the trigger.
- The triggers database, where the trigger definition is stored by trgr:create-trigger. This must be the triggers database configured for the content database.
- The module database, where the trigger action module is stored. This need not be the modules database configured for your App Server.
The following diagram shows the relationships among these databases and the trigger components:
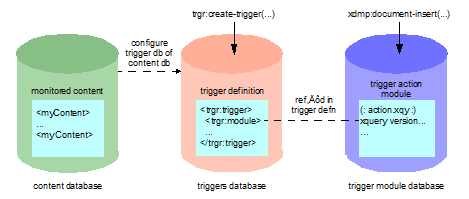
Usually, the content, triggers and module databases are different physical databases, but there is no requirement that they be separate. A database named Triggers is installed by MarkLogic Server for your convenience, but any database may serve as the content, trigger, or module database. The choice is dependent on the needs of your application.
For example, if you want your triggers backed up with the content to which they apply, you might store trigger definitions and their action modules in your content database. If you want to share a trigger action module across triggers that apply to multiple content databases, you would use a separate trigger modules database.
Most trigger API function calls must be evaluated in the context of the triggers database.
Triggers and the Content Processing Framework
The Content Processing Framework uses triggers to capture events and then set states in content processing pipelines. Since the framework creates and manages the triggers, you only need to configure the pipeline and supply the action modules.
In a pipeline used with the Content Processing Framework, a trigger fires after one stage is complete (from a document update, for example) and then the XQuery module specified in the trigger is executed. When it completes, the next trigger in the pipeline fires, and so on. In this way, you can create complex pipelines to process documents.
The Status Change Handling pipeline, installed when you install Content Processing in a database, creates and manages all of the triggers needed for your content processing applications, so it is not necessary to directly create or manage any triggers in your content applications.
When you use the Content Processing Framework instead of writing your own triggers:
- Actions may easily be chained together through pipelines.
- You only need to create and install your trigger action module.
- CPF handles recovery from interruptions for you.
- CPF automatically makes state available to your module and across stages of the pipeline.
Applications using the Content Processing Framework Status Change Handling pipeline do not need to explicitly create triggers, as the pipeline automatically creates and manages the triggers as part of the Content Processing installation for a database. For details, see the Content Processing Framework Guide manual.
Pre-Commit Versus Post-Commit Triggers
There are two ways to configure the transactional semantics of a trigger: pre-commit and post-commit. This section describes each type of trigger and includes the following parts:
Pre-Commit Triggers
The module invoked as the result of a pre-commit trigger is evaluated as part of the same transaction that produced the triggering event. It is evaluated by invoking the module on the same App Server in which the triggering transaction is run. It differs from invoking the module with xdmp:invoke in one way, however; the module invoked by the pre-commit trigger sees the updates made to the triggering document.
Therefore, pre-commit triggers and the modules from which the triggers are invoked execute in a single context; if the trigger fails to complete for some reason (if it throws an exception, for example), then the entire transaction, including the triggering transaction, is rolled back to the point before the transaction began its evaluation.
This transactional integrity is useful when you are doing something that does not make sense to break up into multiple asynchronous steps. For example, if you have an application that has a trigger that fires when a document is created, and the document needs to have an initial property set on it so that some subsequent processing can know what state the document is in, then it makes sense that the creation of the document and the setting of the initial property occur as a single transaction. As a single transaction (using a pre-commit trigger), if something failed while adding the property, the document creation would fail and the application could deal with that failure. If it were not a single transaction, then it is possible to get in a situation where the document is created, but the initial property was never created, leaving the content processing application in a state where it does not know what to do with the new document.
Post-Commit Triggers
The task spawned as the result of a post-commit trigger is evaluated as a separate transaction. The task is compiled before the original transaction commits and is queued on the task server and run some time after the original transaction commits. Static errors that occur compiling a post-commit trigger task cause the original transaction to roll back. Dynamic errors that occur running a post-commit trigger task do not cause the original transaction to roll back. There is no guarantee that the post-commit trigger task will complete.
When a post-commit trigger spawns an XQuery module, it is put in the queue on the task server. The task server maintains this queue of tasks, and initiates each task in the order it was received. The task server has multiple threads to service the queue. There is one task server per group, and you can set task server parameters in the Admin Interface under Groups > group_name > Task Server.
Because post-commit triggers are asynchronous, the code that calls them must not rely on something in the trigger module to maintain data consistency. For example, the state transitions in the Content Processing Framework code uses post-commit triggers. The code that initiates the triggering event updates the property state before calling the trigger, allowing a consistent state in case the trigger code does not complete for some reason. Asynchronous processing has many advantages for state processing, as each state might take some time to complete. Asynchronous processing (using post-commit triggers) allows you to build applications that will not lose all of the processing that has already occurred should something happen in the middle of processing your pipeline. When the system is available again, the Content Processing Framework will simply continue the processing where it left off.
Trigger Events
The trigger event definition describes the conditions under which a trigger fires and the content to which it applies. There are two kinds of trigger events: data events and database events. Triggers can listen for the following events:
- document create
- document update
- document delete
- any property change (does not include MarkLogic Server-controlled properties such as
last-modifiedanddirectory) - specific (named) property change
- database coming online
Database Events
The only database event is a database coming online event. The module for a database online event runs as soon as the watched database comes online. A database online event definition requires only the name of the user under which the action module runs.
Data Events
Data events apply to changes to documents and properties. A trigger data event has the following parts:
- The trigger scope defines the set of documents to which the event applies. Use
trgr:*-scopefunctions such astrgr:directory-scopeto create this piece. For more information, see Trigger Scope. - The content condition defines the triggering operation, such as document creation, update or deletion, or property modification. Use the
trgr:*-contentfunctions such as trgr:document-content to create this piece.To watch more than one operation, you must use multiple trigger events and define multiple triggers.
- The timing indicator defines when the trigger action occurs relative to the transaction that matches the event condition, either pre-commit or post-commit. Use
trgr:*-commitfunctions such as trgr:post-commit to create this piece. For more information, see Pre-Commit Versus Post-Commit Triggers.
The content database to which an event applies is not an explicit part of the event or the trigger definition. Instead, the association is made through the triggers database configured for the content database.
Whether the module that the trigger invokes commits before or after the module that produced the triggering event depends upon whether the trigger is a pre-commit or post-commit trigger. Pre-commit triggers in MarkLogic Server listen for the event and then invoke the trigger module before the transaction commits, making the entire process a single transaction that either all completes or all fails (although the module invoked from a pre-commit trigger sees the updates from the triggering event).
Post-commit triggers in MarkLogic Server initiate after the event is committed, and the module that the trigger spawns is run in a separate transaction from the one that updated the document. For example, a trigger on a document update event occurs after the transaction that updates the document commits to the database.
Because the post-commit trigger module runs in a separate transaction from the one that caused the trigger to spawn the module (for example, the create or update event), the trigger module transaction cannot, in the event of a transaction failure, automatically roll back to the original state of the document (that is, the state before the update that caused the trigger to fire). If this will leave your document in an inconsistent state, then the application must have logic to handle this state.
For more information on pre- and post-commit triggers, see Pre-Commit Versus Post-Commit Triggers.
Trigger Scope
The trigger scope is the scope with which to listen for create, update, delete, or property change events. The scope represents a portion of the database corresponding to one of the trigger scope values: document, directory, or collection.
A document trigger scope specifies a given document URI, and the trigger responds to the specified trigger events only on that document.
A collection trigger scope specifies a given collection URI, and the trigger responds to the specified trigger events for any document in the specified collection.
A directory scope represents documents that are in a specified directory, either in the immediate directory (depth of 1); or in the immediate or any recursive subdirectory of the specified directory. For example, if you have a directory scope of the URI / (a forward-slash character) with a depth of infinity, that means that any document in the database with a URI that begins with a forward-slash character ( / ) will fire a trigger with this scope upon the specified trigger event. Note that in this directory example, a document called hello.xml is not included in this trigger scope (because it is not in the / directory), while documents with the URIs /hello.xml or /mydir/hello.xml are included.
Modules Invoked or Spawned by Triggers
Trigger definitions specify the URI of a module. This module is evaluated when the trigger is fired (when the event completes). The way this works is different for pre-commit and post-commit triggers. This section describes what happens when the trigger modules are invoked and spawned and includes the following subsections:
- Difference in Module Behavior for Pre- and Post-Commit Triggers
- Module External Variables trgr:uri and trgr:trigger
Difference in Module Behavior for Pre- and Post-Commit Triggers
For pre-commit triggers, the module is invoked when the trigger is fired (when the event completes). The invoked module is evaluated in an analogous way to calling xdmp:invoke in an XQuery statement, and the module evaluates synchronously in the same App Server as the calling XQuery module. The difference is that, with a pre-commit trigger, the invoked module sees the result of the triggering event. For example, if there is a pre-commit trigger defined to fire upon a document being updated, and the module counts the number of paragraphs in the document, it will count the number of paragraphs after the update that fired the trigger. Furthermore, if the trigger module fails for some reason (a syntax error, for example), then the entire transaction, including the update that fired the trigger, is rolled back to the state before the update.
For post-commit triggers, the module is spawned onto the task server when the trigger is fired (when the event completes). The spawned module is evaluated in an analogous way to calling xdmp:spawn in an XQuery statement, and the module evaluates asynchronously on the task server. Once the post-commit trigger module is spawned, it waits in the task server queue until it is evaluated. When the spawned module evaluates, it is run as its own transaction. Under normal circumstances the modules in the task server queue will initiate in the order in which they were added to the queue. Because the task server queue does not persist in the event of a system shutdown, however, the modules in the task server queue are not guaranteed to run.
Module External Variables trgr:uri and trgr:trigger
There are two external variables that are available to trigger modules:
The trgr:uri external variable is the URI of the document which caused the trigger to fire (it is only available on triggers with data events, not on triggers with database online events). The trgr:trigger external variable is the trigger XML node, which is stored in the triggers database with the URI http://marklogic.com/xdmp/triggers/trigger_id, where trigger_id is the ID of the trigger. You can use these external variables in the trigger module by declaring them in the prolog as follows:
xquery version "1.0-ml"; import module namespace trgr='http://marklogic.com/xdmp/triggers' at '/MarkLogic/triggers.xqy'; declare variable $trgr:uri as xs:string external; declare variable $trgr:trigger as node() external;
Creating and Managing Triggers With triggers.xqy
The <install_dir>/Modules/MarkLogic/triggers.xqy XQuery module file contains functions to create, delete, and manage triggers. If you are using the Status Change Handling pipeline, the pipeline takes care of all of the trigger details; you do not need to create or manage any triggers. For details on the trigger functions, see the MarkLogic XQuery and XSLT Function Reference.
For real-world examples of XQuery code that creates triggers, see the <install_dir>/Modules/MarkLogic/cpf/domains.xqy XQuery module file. For a sample trigger example, see Simple Trigger Example. The functions in this module are used to create the needed triggers when you use the Admin Interface to create a domain.
Simple Trigger Example
The following example shows a simple trigger that fires when a document is created.
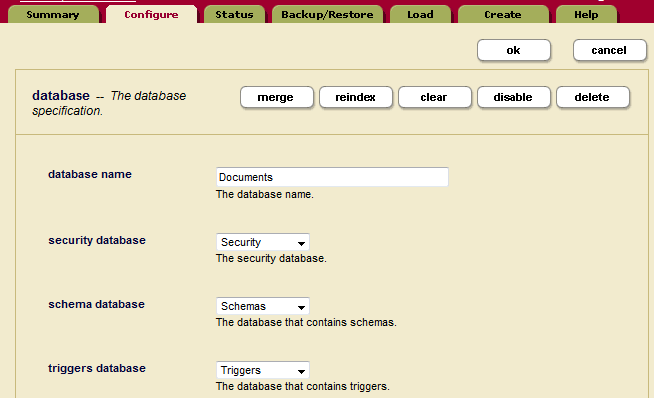
- Use the Admin Interface to set up the database to use a triggers database. You can specify any database as the triggers database. The following screenshot shows the database named
Documentsas the content database andTriggersas the triggers database. - Create a trigger that listens for documents that are created under the directory
/myDir/with the following XQuery code. Note that this code must be evaluated against the triggers database for the database in which your content is stored.xquery version "1.0-ml"; import module namespace trgr="http://marklogic.com/xdmp/triggers" at "/MarkLogic/triggers.xqy"; trgr:create-trigger("myTrigger", "Simple trigger example", trgr:trigger-data-event( trgr:directory-scope("/myDir/", "1"), trgr:document-content("create"), trgr:post-commit()), trgr:trigger-module(xdmp:database("Documents"), "/modules/", "log.xqy"), fn:true(), xdmp:default-permissions() )
This code returns the ID of the trigger. The trigger document you just created is stored in the document with the URI
http://marklogic.com/xdmp/triggers/trigger_id, where trigger_id is the ID of the trigger you just created. - Load a document whose contents is the XQuery module of the trigger action. This is the module that is spawned when the when the previously specified create trigger fires. For this example, the URI of the module must be
/modules/log.xqyin the database namedDocuments(from the trgr:trigger-module part of the trgr:create-trigger code above). Note that the document you load, because it is an XQuery document, must be loaded as a text document and it must have execute permissions. For example, create a trigger module in theDocumentsdatabase by evaluating the following XQuery against the modules database for the App Server in which the triggering actions will be evaluated:xquery version '1.0-ml'; (: evaluate this against the database specified in the trigger definition (
Documentsin this example) :) xdmp:document-insert("/modules/log.xqy", text{ " xquery version '1.0-ml'; import module namespace trgr='http://marklogic.com/xdmp/triggers' at '/MarkLogic/triggers.xqy'; declare variable $trgr:uri as xs:string external; xdmp:log(fn:concat('*****Document ', $trgr:uri, ' was created.*****'))" }, xdmp:permission('app-user', 'execute')) - The trigger should now fire when you create documents in the database named
Documentsin the/myDir/directory. For example, the following:xdmp:document-insert("/myDir/test.xml", <test/>)
will write a message to the
ErrorLog.txtfile similar to the following:2007-03-12 20:14:44.972 Info: TaskServer: *****Document /myDir/test.xml was created.*****
This example only fires the trigger when the document is created. If you want it to fire a trigger when the document is updated, you will need a separate trigger with a trgr:document-content of
"modify".
Avoiding Infinite Trigger Loops (Trigger Storms)
If you create a trigger for a document to update itself, the result is an infinite loop, which is also known as a trigger storm.
When a pre-commit trigger fires, its actions are part of the same transaction. Therefore, any updates performed in the trigger should not fire the same trigger again. To do so is to guarantee trigger storms, which generally result in an XDMP-MAXTRIGGERDEPTH error message.
In the following example, we create a trigger that calls a module when a document in the /storm/ directory is modified the database. The triggered module attempts to update the document with a new child node. This triggers another update of the document, which triggers another update, and so on, ad infinitum. The end result is an XDMP-MAXTRIGGERDEPTH error message and no updates to the document.
To create a trigger storm, do the following:
- In the
Modulesdatabase, create astorm.xqymodule to be called by the trigger:xquery version "1.0-ml"; import module namespace trgr="http://marklogic.com/xdmp/triggers" at "/MarkLogic/triggers.xqy"; if (xdmp:database() eq xdmp:database("Modules")) then () else error((), 'NOTMODULESDB', xdmp:database()) , xdmp:document-insert( '/triggers/storm.xqy', text { <code> xquery version "1.0-ml"; import module namespace trgr='http://marklogic.com/xdmp/triggers' at '/MarkLogic/triggers.xqy'; declare variable $trgr:uri as xs:string external; declare variable $trgr:trigger as node() external; xdmp:log(text {{ 'storm:', $trgr:uri, xdmp:describe($trgr:trigger) }}) , let $root := doc($trgr:uri)/* return xdmp:node-insert-child( $root, element storm {{ count($root/*) }}) </code> } ) - In the
Triggersdatabase, create the following trigger to call thestorm.xqymodule each time a document in the/storm/directory in the database is modified:xquery version "1.0-ml"; import module namespace trgr="http://marklogic.com/xdmp/triggers" at "/MarkLogic/triggers.xqy"; if (xdmp:database() eq xdmp:database("Triggers")) then () else error((), 'NOTTRIGGERSDB', xdmp:database()) , trgr:create-trigger( "storm", "storm", trgr:trigger-data-event(trgr:directory-scope("/storm/", "1"), trgr:document-content("modify"), trgr:pre-commit()), trgr:trigger-module( xdmp:database("Modules"), "/triggers/", "storm.xqy"), fn:true(), xdmp:default-permissions(), fn:true() ) - Now insert a document twice into any database that uses
Triggersas its triggers database:xquery version "1.0-ml"; xdmp:document-insert('/storm/test', <test/> )
- The second attempt to insert the document will fire the trigger, which should result in an
XDMP-MAXTRIGGERDEPTHerror message and repeated messages inErrorLog.txtthat look like the following:2010-08-12 15:04:42.176 Info: Docs: storm: /storm/test <trgr:trigger xmlns:trgr="http://marklogic.com/xdmp/triggers"> <trgr:trigger-id>1390446271155923614</trgr:trigger-id> <trgr:trig...</trgr:trigger>
If you encounter similar circumstances in your application and it's not possible to modify your application logic, you can avoid trigger storms by setting the $recursive parameter in the trgr:create-trigger function to fn:false(). So your new trigger would look like:
trgr:create-trigger( "storm", "storm", trgr:trigger-data-event(trgr:directory-scope("/storm/", "1"), trgr:document-content("modify"), trgr:pre-commit()), trgr:trigger-module( xdmp:database("Modules"), "/triggers/", "storm.xqy"), fn:true(), xdmp:default-permissions(), fn:false() )
The result will be a single update to the document and no further recursion.