
MarkLogic Server on Amazon Web Services (AWS) Guide — Chapter 4
Managing MarkLogic Server on EC2
This chapter describes how to launch a MarkLogic Server AMI and access the MarkLogic Server Admin interface. This chapter includes the following sections:
- Accessing a MarkLogic Server Instance
- Accessing an EC2 Instance
- Detecting EC2 Errors
- Using the mlcmd Script
- Configuring MarkLogic for Amazon Simple Storage Service (S3)
- Configuring a VPC for MarkLogic Telemetry
- Configuring a VPC for MarkLogic Clients
- Scaling Cluster Resources on EC2
- Upgrading MarkLogic on AWS
- Monitoring (CloudWatch)
- Migrating from Enterprise Data Center to EC2
- Creating an EBS Volume and Attaching it to an Instance
- Hibernating a MarkLogic Cluster
- Resizing a MarkLogic Cluster
- Terminating a MarkLogic Cluster
Accessing a MarkLogic Server Instance
This section describes how to use the Elastic Load Balancer (ELB) URL to access an instance of MarkLogic Server in EC2. The ELB URL will direct you to any available instance of MarkLogic Server in your cluster. If you want to access a specific instance, as you would when running the mlcmd script described in Using the mlcmd Script, then use the Public DNS for that instance.
You can access the MarkLogic Admin Interface through the ELB by clicking on the URL in the Outputs portion of the Cloud Formation Console, as described in 13 in Creating a CloudFormation Stack using the AWS Console.
This section describes how to access MarkLogic Server through the ELB from the EC2 Dashboard.
- In the EC2 Dashboard, click on Load Balancers in the left-hand navigation menu.
- Select a Load Balancer from the list and copy URL from the DNS name.
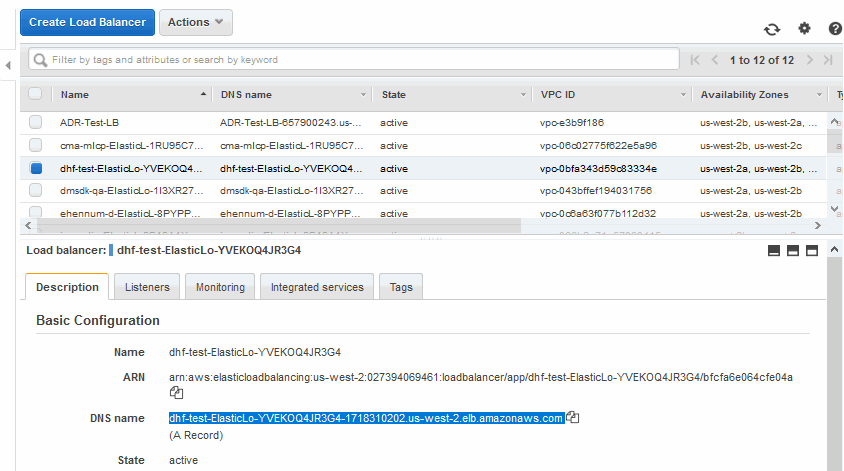
You use the URL to access the MarkLogic Server. You can access any of the ports you have defined as an ELB port. For example, if the URL is DLEE-CF-L-ElasticL-OCCR192PW0OO-925510329.us-east-1.elb.amazonaws.com, then, to access MarkLogic port 8000, the URL you enter into the browser would be:
http://DLEE-CF-L-ElasticL-OCCR192PW0OO-925510329.us-east-1.elb.amazonaws.com:8000
Accessing an EC2 Instance
You may need to SSH into an EC2 instance for certain task, such as checking the log files for that instance, as described in Detecting EC2 Errors.
You cannot SSH to the load balancer, you must SSH to a specific EC2 instance. To SSH into an EC2 instance, you must have the key pair used by the instance downloaded to your local host.
To SSH into an instance, do the following:
- Open the EC2 Dashboard.
- Select Instances from the left-hand navigation section.
- Select the instance to which you want to connect.
- Click on the Connect button, or select Connect from the Actions pull-down menu.
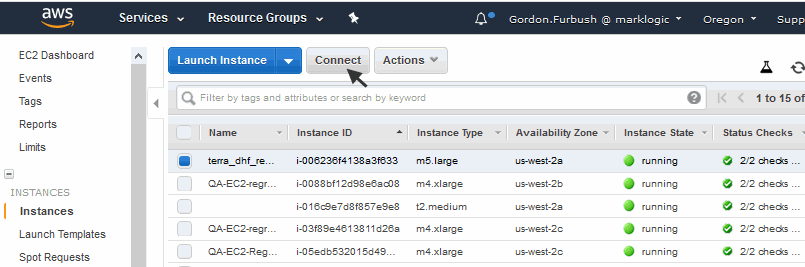
- Select A Java SSH Client directly from my browser (Java required). Specify
ec2-useras the User Name, and provide the path to your copy of the key pair you downloaded to your local host. Click Launch SSH Client. - This will open up a shell window to the EC2 instance. When you first connect in this manner, you may be prompted to create various directories. Respond by clicking
Yesfor each prompt.
Alternatively you can open a shell window and SSH into an instance using the following command:
ssh -i /path/to/keypair.pem ec2-user@<Public DNS>
For example, if your keypair, named newkey.pem, is stored in your c:/stuff/ directory, you can access the instance with a public DNS of ec2-54-242-94-98.compute-1.amazonaws.com as follows:
ssh -i c:/stuff/newkey.pem ec2-user@ec2-54-242-94-98.compute-1.amazonaws.com
Detecting EC2 Errors
Start up errors are stored in the /var/log/messages file in each instance. To view the messages file, SSH into an instance as described in Accessing an EC2 Instance.
To access the messages file, you must be super user. For example, if you want to tail the messages file, enter:
sudo tail -f /var/log/messages
You can also capture errors related to Cloud Formation stack by means of the SNS Topic, as described in Creating a Simple Notification Service (SNS) Topic.
Using the mlcmd Script
The mlcmd script supports startup operations and advanced use of the Managed Cluster features. The mlcmd script is installed as an executable script in /opt/MarkLogic/bin/mlcmd.
In order to run mlcmd, you must be logged into the host and running as root or with root privileges. You must also have Java installed and the java command in the PATH or JAVA_HOME set to the JRE or JDK home directory. The first time you start MarkLogic on your server the /var/local/mlcmd.conf file is created, which is required to use the mlcmd script. Once the /var/local/mlcmd.conf file is created, it is not necessary to start MarkLogic to use the mlcmd script.
The syntax of mlcmd is as follows:
mlcmd command
The mlcmd commands are listed below:
| mlcmd Command | Description |
|---|---|
| sync-volumes-from-mdb | Attaches EBS volumes not currently attached to this instance. |
| sync-volumes-to-mdb | Synchronizes the EBS volumes currently attached to the system and stores them in the Metadata Database. |
| init-volumes-from-system | Initialize volumes identical to the process performed on startup. |
| leave-cluster | Removes the host on which it is executed from the cluster. Note that this is a privileged operation, so the user running the script should have the ability to read all information in /etc/marklogic.conf. |
sync-volumes-from-mdb
This command looks in the Metadata Database and does the following:
- Locates any EBS volumes not currently attached to this instance and attaches them.
- If the volume does not contain a filesytem, a filesystem is created (ext4).
- Mounts the device to the mount point indicated in the Metadata Database.
- Applies all tags from the current EC2 instance prefixed by
marklogic:to the EBS volume.
sync-volumes-to-mdb
This command can be run any time after the initial startup. It synchronizes the EBS volumes currently attached to the system and stores them in the Metadata Database so that on the next restart they will be attached and mounted. The following steps are performed:
- Locates all EBS volumes to the system.
- For all volumes in the managed range enters an entry to the Metadata Database indicating the following:
- For volumes which are attached but not mounted then the mount point is set to the default mount point for that volume (see the Default EBS Mount Points table below).
No changes to existing attachments, filesystem, or mount points are performed.
The following table lists the default EBS Mount Points. EBS volumes are exposed as NVMe block devices on Nitro-based instances. The device names that you specify in a block device mapping are renamed using NVMe device names (/dev/nvme[0-26]n1). For more information on EBS and NVMe on Linux Instances, see https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/nvme-ebs-volumes.html.
init-volumes-from-system
This command looks at the current system and attempts to initialize volumes identical to the process performed on startup.
leave-cluster
This command can be executed on a host to remove that host from the cluster. This command also removes the host from the cluster configuration information stored in the Metadata Database. The command leaves the host server in pre-initialized state (same as a fresh install). If the server is restarted, then it will re-join the cluster the same manner as an initial start.
Use the optional -terminate argument to terminate the instance and decrement the DesiredCount attribute of the AutoScaling group by one after leaving the cluster. After the node was first joined to the cluster, the MARKLOGIC_ADMIN_PASSWORD field is no longer present in the mlcmd.conf file. In order to get the leave-cluster command to execute successfully, manually add that field back to the mlcmd.conf file.
Leaving the cluster is a privileged operation. So you will need to run the script as a privileged user that has access to the information stored in /etc/marklogic.conf.
Configuring MarkLogic for Amazon Simple Storage Service (S3)
Amazon S3 storage can be used for backups and as a read-only forest in a tiered storage configuration. MarkLogic does not support regular or replica forests on Amazon S3 storage.
Amazon S3 support is built into MarkLogic Server as an available file system type. You configure S3 access at the group level. Once you have configured a group for S3, any forest in the group can be placed on S3 by specifying an S3 Path. Additionally, any host in the group can do backups to S3, restore from S3, as well as read and write directories and files on S3.
Transaction journaling does not work on S3 because the S3 file system cannot do the file operations necessary to maintain a journal. Unless your S3 forest is configured with a fast data directory or updates allowed is set to read-only, you must set the journaling option on your database to off before attaching the forest to the database. This is not a requirement for backup/restore operations on a database, however.
To configure MarkLogic to access Amazon S3, do the following:
- Set up an S3 Bucket
- Configure the S3 Endpoint for your Group
- Configure AWS Credentials
- Set an S3 Path in Forest Data Directory
- Load Content into MarkLogic to Test
Set up an S3 Bucket
Follow the directions in http://docs.aws.amazon.com/AmazonS3/latest/gsg/CreatingABucket.htmlto set up your S3 bucket.
There can be multiple problems if the bucket name contains a period (.). Instead use a dash (-) for maximum compatibility with S3.
Bucket names are global and they are not scoped to your account. You should choose bucket names that have a good chance of being universally unique. For example:
- Bad:
test - Good:
zippy-software-org-testDo not use the S3 Management Console to upload your content to S3. Instead, follow any of the procedures described in the Loading Content Into MarkLogic Server Guide after you have completed the configuration procedures.
Configure the S3 Endpoint for your Group
The S3 Endpoint is configured by specifying the S3 properties for your MarkLogic group.
- Log into the Admin Interface.
- Click the name of your group under the Groups icon on the left tree menu.
- In the Group Configuration page, scroll down to the bottom to locate the S3 fields:
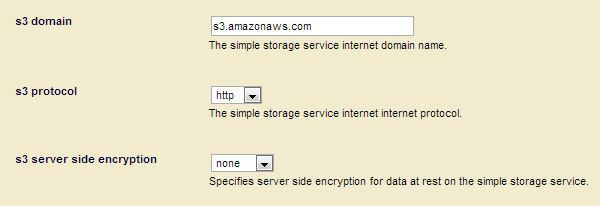
| Setting | Description |
|---|---|
| s3 domain | The domain used for the S3 endpoint. The default value is set for your region. However, you can change it, if necessary. References to the regional endpoints can be found at http://docs.aws.amazon.com/general/latest/gr/rande.html#s3_region. |
| s3 protocol | You can choose either http or https for communication with S3. The default is http. |
| s3 server side encryption | Storage on S3 can participate in server-side encryption. The default is none but you can set aes256 to enable server-side encryption. |
Configure AWS Credentials
In order to use AWS you must supply AWS credentials. You can configure AWS credentials in one of three ways:
- Configuring an IAM Role with an AWS Access Policy
- Configuring AWS Credentials in Environment Variables
- Configuring AWS Credentials in the Security Database
The order of precedence for locating AWS credentials is:
Configuring an IAM Role with an AWS Access Policy
Your IAM Role will be used for your security credentials so you do not need to store any AWS Credentials in MarkLogic or on the EC2 instance in order access AWS resources. This is the most secure way of accessing AWS.
If you run an EC2 instance with an associated IAM Role, you can select a policy template that provides S3 access, such as Amazon S3 Full Access or Amazon S3 Read Only Access.
IAM roles are only used on the server if the MARKLOGIC_AWS_ROLE environment variable is set. This happens automatically for you unless you disable the EC2 configuration (such as setting MARKLOGIC_EC2_HOST=0), in which case the server will not use the MARKLOGIC_AWS_ROLE variable.
Configuring AWS Credentials in the Security Database
If you are only using S3, it is best to use the Admin Interface to store your AWS credentials because the credentials are securly stored in the MarkLogic Security database.
If you are using KMS, you cannot put your credentials in the Security database because, on startup, MarkLogic needs the credentials before it can access AWS. In this case, follow the procedure described in Configuring AWS Credentials in Environment Variables.
In the Security, Credentials, Configure tab are fields for specifying the AWS credentials.
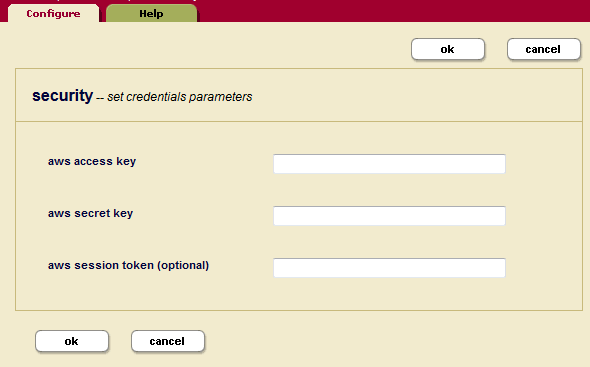
Configuring AWS Credentials in Environment Variables
You can set a pair of environment variables that the server will use as AWS Credentials. These can be passed in as AWS User Data or set into the environment in which MarkLogic runs.
- MARKLOGIC_AWS_ACCESS_KEY -- Your AWS Access Key
- MARKLOGIC_AWS_SECRET_KEY -- Your AWS Secret Key
- MARKLOGIC_AWS_SESSION_TOKEN -- Your optional AWS Session Token
On Linux, set the environment variables in the marklogic.conf file, as deascribed in Configuration using the /etc/marklogic.conf File. It is a good practice to protect the marklogic.conf file so that it is system readable only.
In Windows, set the environment variables as System Variables, then restart MarkLogic.
Set an S3 Path in Forest Data Directory
Set the data directory for the forest to a valid S3 path. For details on setting the forest data directory, see Creating a Forest in the Administrator's Guide. Multiple forests can be configured for the same bucket.
s3://bucket/directory/file
| Item | Description |
|---|---|
| bucket | The name of your S3 bucket. |
| directory | Zero or more directory names, separated by forward slashes (/). |
| file | The filename, if the path is to a specific file. |
For a directory path (such as a Forest data directory), then a bucket by itself is sufficient and files will be placed in the bucket root.
Example paths to S3 directories:
s3://my-company-bucket s3://my-company-bucket/directory s3://my-company-bucket/dir1/dir2/dir3
s3://my-company-bucket/file.xml s3://my-company-bucket/directory/file.txt s3://my-company-bucket/dir1/dir2/dir3/file.txt
Unless your S3 forest is configured with a fast data directory or updates allowed is set to read-only, you must set journaling on your database to off before attaching the forest to the database. Failure to do so will result in a forest error and you will have to restart the forest after you have disabled journaling on the database.
Setting a Proxy Server to Access S3 Storage
You can optionally set up a proxy server through which to access S3 storage. You can specify the URL to the proxy server by setting the MARKLOGIC_S3_PROXY in the /etc/marklogic.conf file, or use the Admin Interface to configure MarkLogic Server to access S3 Storage through a proxy server, as follows:
- Log into the Admin Interface.
- Click the Groups icon on the left tree menu.
- Click the Configure tab at the top right.
- Locate the group for which you want to view settings.
- Click the icon for this group.
- Enter the URL for the proxy server used to access the S3 storage. The proxy URL should start with
https://(for example,https://proxy.marklogic.com:8080). If you don't specify the port number, MarkLogic assumes the proxy server is listening on port8080.
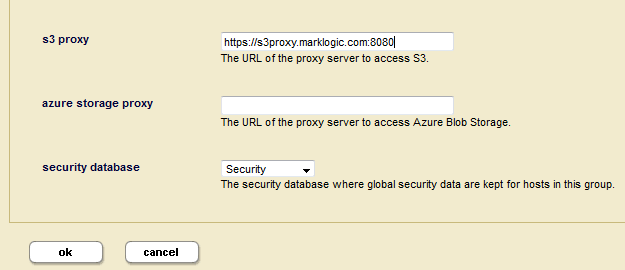
If the MARKLOGIC_S3_PROXY environment variable is set and the Admin Interface group configuration s3 proxy is not set, the value of MARKLOGIC_S3_PROXY will be used as the proxy URL to access S3. If environment variable MARKLOGIC_S3_PROXY is set and group configuration s3 proxy is also set, the value of group configuration s3 proxy will be used as the proxy URL to access S3.
Load Content into MarkLogic to Test
Load content into your S3 database using any of the methods described in Loading Content Into MarkLogic Server Guide and run a query to confirm you have successfully configured MarkLogic Server with S3.
Content uploaded directly to your bucket using the S3 Management Console will not be recognized by MarkLogic Server.
Configuring a VPC for MarkLogic Telemetry
If you have an existing VPC or if you are not using the VPC template described in Deploying MarkLogic on EC2 Using CloudFormation, follow the procedure in this section to configure your VPC for the MarkLogic telemetry feature described in Telemetry in the Monitoring MarkLogic Guide.
MarkLogic telemetry requires that the subnets containing your EC2 instances be configured for outbound access. To configure your VPC to enable your EC2 instances to access the outside internet, do the following:
- Create a NAT Gateway, as described in:
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/vpc-nat-gateway.html#nat-gateway-working-with
- Create a route table for the subnets containing your EC2 instances, as described in:
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Route_Tables.html#WorkWithRouteTables
- In the route table, add the following route:
Configuring a VPC for MarkLogic Clients
If you have an existing VPC or if you are not using the VPC template described in Deploying MarkLogic on EC2 Using CloudFormation, follow the procedure in this section to configure your VPC to enable access by clients, such as mlcp, Java Client API, DMSDK, Node.js Client API, and so on.
MarkLogic clients require that the subnets containing your EC2 instances be configured for inbound access. The procedures for this are as follows.
- Create an Internet Gateway and attach it to your VPC, as described in:
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Internet_Gateway.html
If your EC2 instance is in a public subnet, do the following:
- Enable the public IP address on the EC2 instance, as described in:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-instance-addressing.html#concepts-public-addresses
- Create a route table for the subnets containing your EC2 instances, as described in:
https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Route_Tables.html#WorkWithRouteTables
- In the route table, add the following route:
If your EC2 instance is in a private subnet, do the following:
- Create a public subnet, as described in:
https://docs.aws.amazon.com/appstream2/latest/developerguide/managing-network-internet-default.html
- Follow Steps 2 and 3, above.
Scaling Cluster Resources on EC2
If you have created your stack using the 3+ Cloud Formation template, you can temporarily add nodes and forests to scale up your cluster for periods of heavy use and then remove them later when less resources are needed.
Adding more hosts to a cluster is simple. Simply use the Update Stack feature to reapply the 3+ Cloud Formation template and provide a larger number for the NodesPerZone setting. Alternatively, you can add hosts by means of your Auto Scaling Groups. The recommended way to scale up the data capacity of your cluster is to add additional volumes, as described in Creating an EBS Volume and Attaching it to an Instance.
Scaling a cluster down involves some manual intervention. The procedure is as follows:
- Use MarkLogic and AWS tools to identify equal number of hosts in each ASG to delete. Never delete the host with the Security database, or any of the other built-in MarkLogic databases, such as Meters, App-Services, Modules, and so on.
- Delete or move the data from the hosts to be removed to other hosts. This can be done by using the REST Management API or XQuery
tieredstorageAPI to migrate partitions or forests to a volume on another host. For details on migrating data, see Migrating Forests and Partitions in the Administrator's Guide. - As a super user, run the leave-cluster
-terminatecommand on each host to be removed. This will cause the node to leave the cluster, and adjust the AutoScaling GroupDesiredCountsetting. For details, see leave-cluster. - Delete any unused volumes.
- Update the Cloud Formation template to represent downsized cluster and use the Update Stack feature to reapply the template to the stack to alert AWS of the updated configuration.
Upgrading MarkLogic on AWS
You can upgrade from any version of MarkLogic instance on AWS to a later version. To upgrade a MarkLogic instance on AWS, you must update the AMI IDs in your original CloudFormation template.
You cannot upgrade your CloudFormation template to a different version. You must keep your original CloudFormation template. Upgrades are supported by updating the AMI IDs in your original CloudFormation template with the AMI IDs from the MarkLogic version to which you are upgrading.
To use a later version of the CloudFormation template, you can set up a new cluster, move data and configuration to the new template, and switch to the new cluster after testing.
The following procedure describes how to upgrade your stack to use AMI IDs for a later version of MarkLogic:
- Download the CloudFormation template for the later version of MarkLogic at https://developer.marklogic.com/products/cloud/aws.
- Navigate to your AWS CloudFormation console, and select your original CloudFormation template used to create the stack. Download your original template currently used by the stack to ensure any modifications made to the CloudFormation template are preserved after the upgrade.
- Locate the AMI IDs in your downloaded original template, and find the corresponding AMI IDs in the new template. For example, the
LicenseRegion2AMIandAWSRegionArch2AMIdefinitions in your original template might look like the following:CloudFormation templates for MarkLogic 9.0-5 or a later version of MarkLogic are in YAML data format. CloudFormation templates for MarkLogic 9.0-4 or an earlier version of MarkLogic are in JSON data format.
LicenseRegion2AMI us-east-1: Enterprise: ami-08dcfd988a2988e01 BYOL: ami-078c0f5757e1ffdd7
"AWSRegionArch2AMI": { "us-east-1": { "HVM": "ami-4464743e" }, ... }
If, for example, your instance is located in the
us-east-1region, open the new template, locateLicenseRegion2AMI, and copy the AMI IDs for theus-east-1region. For example, the new template contains the following:us-east-1 Enterprise: ami-0ac019c39cac73c89 BYOL: ami-0ea837234c4c34363
In the original template, you can modify
LicenseRegion2AMIorAWSRegionArch2AMIas follows:LicenseRegion2AMI us-east-1: Enterprise: ami-0ac019c39cac73c89 BYOL: ami-0ea837234c4c34363
"AWSRegionArch2AMI": { "us-east-1": { "HVM": "ami-0ac019c39cac73c89" }, ... }
- Take a backup for each database on your cluster. If the backup fails, use MarkLogic database backup and restore. For details, see Backup and Restore Overview in the Administrator's Guide.
MarkLogic database backup and restore does not back up your configuration.
Do not use EBS Volume snapshot for backup purposes unless MarkLogic is completely stopped at the time of the snapshot.
- Navigate to your AWS CloudFormation console, and select the CloudFormation template used to create the stack.
- In the EC2 Dashboard, terminate one instance at a time, called a rolling upgrade. After terminating an instance, wait for the terminated instance to come up and reconnect without any UI interaction. After the instance comes up, navigate to the Admin Interface to check the software version installed on each host. For details, see Understanding Rolling Upgrades in the Administrator's Guide.
Before terminating your instance, MarkLogic recommends you stop all traffic to the cluster during the upgrade.
You must revert forest replicas back to the original primary hosts. Otherwise, you will experience degraded performance. For details, see Reverting a Failed Over Forest Back to the Primary Host in the Scalability, Availability, and Failover Guide.
- After terminating your last instance, navigate to the Admin Interface (8001 port) where the security database upgrade prompt will be displayed. (
security-upgrade.xqyscreen) - Click OK and wait for the upgrade to complete on the instance.
Monitoring (CloudWatch)
AWS provides robust monitoring of EC2 instances, EBS volumes, and other services via the CloudWatch service. You can use CloudWatch to set thresholds on individual AWS services and send notifications via SMS or Email when these thresholds have been exceeded. For example, you can set a threshold on excessive storage throughput. You can also create your own metrics to monitor with CloudWatch. For example, you might write a custom metric to monitor the current free memory on your instances and to alarm or trigger an automatic response should a memory threshold be exceeded.
For details on the use of CloudWatch, see http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html.
Migrating from Enterprise Data Center to EC2
This section describes to steps for migrating your data and configuration from a data center to EC2.
There are a number of ways you could migrate from a local data center to EC2. The following is one possible procedure.
- Copy an existing backup of your databases to S3 storage. If you prefer to backup your databases directly to S3, set your S3 security credentials, as described in Configure AWS Credentials, on your local MarkLogic cluster and, for your backup directory, provide the path to your S3 bucket, as described in Set an S3 Path in Forest Data Directory.
- Export all of the configuration data for your cluster.
- Create a Cloud Formation template, as described in Deploying MarkLogic on EC2 Using CloudFormation, to recreate the hosts for your cluster on EC2.
- Import your configuration data into your EC2 cluster.
- Restore your backed-up data from S3 to your configured EC2 forests.
For more detail about exporting and importing a configuration, see https://help.marklogic.com/Knowledgebase/Article/View/686/0/transporting-configuration-to-a-new-cluster.
Creating an EBS Volume and Attaching it to an Instance
This section describes how to create an EBS volume and attach it to your MarkLogic Server instance.
In general, it is a best practice to have one volume per node and one forest per volume. The recommendation is to use large EBS volumes as opposed to multiple smaller ones because larger EBS volumes (gp2) have faster IO as described by the Amazon EBS Volume types and you have to keep enough spare capacity on each EBS volume to allow for merges. Additionally, it is recommended that you have one large EBS data volume per node - while it's possible to have multiple volumes per instance, it is not typically worth the additional administrative complexity. When resizing, adopt a vertical scaling approach (growing into a single bigger EBS volume versus adding multiple smaller volumes per node). Note that S3 storage is eventually consistent, therefore S3 can only be used for backups or read-only forests in MarkLogic Server (otherwise you risk the possibility of data loss).
Creating and EBS Volume
Use the following procedure to create an EBS volume.
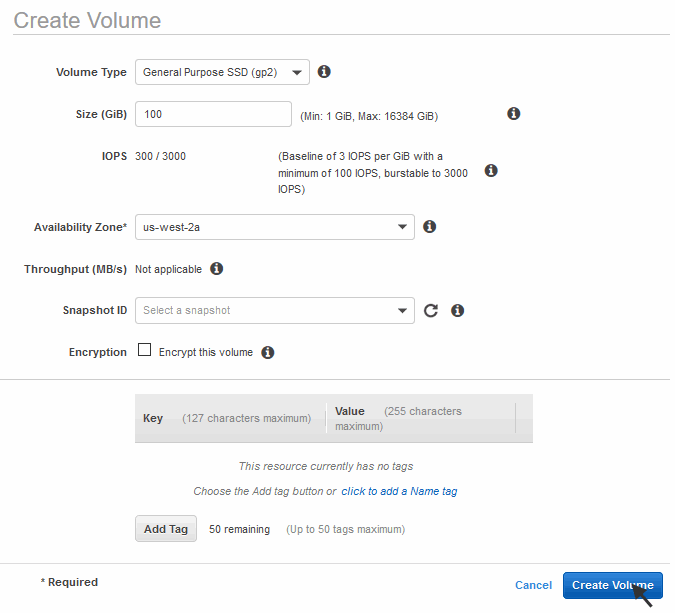
- Open the EC2 Dashboard, select Volumes from the left-hand navigation section. In the EBS Volumes page, select Create Volume:
- In the Create Volume window, specify the Volume Type from the pull-down menu.
- Specify a volume size large enough for your needs and the same availability zone associated with your instance. Specify the same zone as the instance to which you intend to attach the volume. You can also optionally specify an EBS snapshot. See Help on the EBS snapshot page for details on how to create a snapshot.
Do not use an EBS Volume snapshot for backup purposes.
The zones for your instance and EBS volume may not be the same by default.
When finished, click Create Volume. Locate the reference to this new volume in the right-hand section of the management console and verify that the State is
available.
Attaching an EBS Volume to an Instance
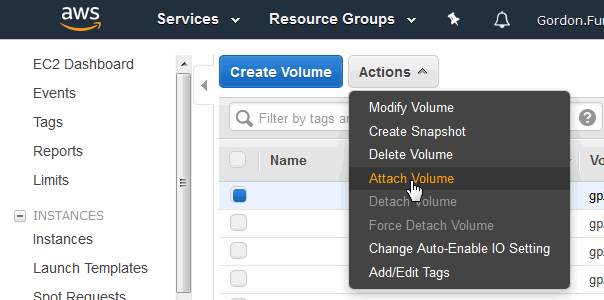
This section describes how to use the EC2 Dashboard to attach a volume to an instance.
- Select Volumes from the left-hand navigation section and then click Attach Volume.
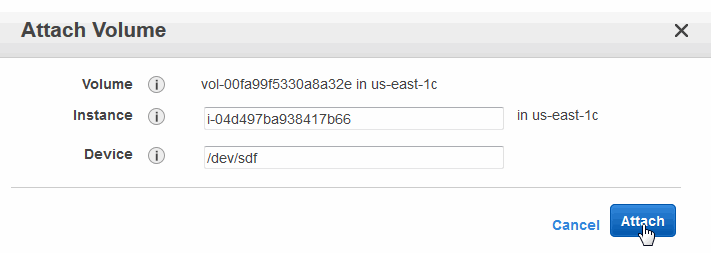
- In the Attach Volume window, specify the instance you launched from the MarkLogic Server AMI. For the Device selection, use
/dev/sdf. Click Yes, Attach when you are finished. Locate the reference to this volume in the right-hand section of the management console and verify that the status is "in-use". If the status is not in-use, continue to click Refresh until the status changes to in-use.
- SSH into the instance, and mount the attached volume by executing the init-volumes-from-system command. You can execute the init-volumes-from-system command to create a filesystem for the volume, mount the attached volume, and update the Metadata Database with the new volume configuration. The init-volumes-from-system command will output a detailed report of what it is doing. Note the mount directory of the volume from this report. Alternatively, you can stop and then start MarkLogic Server to mount the attached volume. Execute the
/sbin/service MarkLogic stopcommand to stop MarkLogic Server and then the/sbin/service MarkLogic startcommand to start MarkLogic Server. To learn more about stopping and starting MarkLogic Server, see Stopping the Server and Starting the Server. - Once the volume is attached and mounted to the instance, log into the Administrator Interface on that host and create a forest, specifying host name of the instance and the mount directory of the volume as the forest Data Directory. For details on how to create a forest, see Creating a Forest in the Administrator's Guide.
Hibernating a MarkLogic Cluster
At any time, you can hibernate the cluster by using the Update Stack feature to reapply the Cloud Formation template to your stack and setting the NodesPerZone value to 0. You must later restart the cluster by resetting the NodesPerZone value to the previously set value. For example, assume the NodesPerZone value is 3. Set the value to 0 to hibernate the cluster, and reset the value back to 3 to restart the cluster.
You must revert all forest replicas back to their original primary hosts. To do this, restart the server. For details, see Restarting the Server in the Administrator's Guide.
Hibernating a MarkLogic cluster deletes all nodes and related root volumes in your cluster. Restarting a hibernated MarkLogic cluster recreates nodes and related root volumes. In addition, data volumes are preserved and reattached to nodes.
Do not manually stop your MarkLogic instances from the EC2 dashboard, as each AutoScaling Group will detect that they have stopped and will automatically recreate them. The same is true if you shutdown MarkLogic from the Admin Interface, by means of a MarkLogic API call, or with the appropriate system command for your platform.
Resizing a MarkLogic Cluster
At any time, you can resize the cluster by using the Update Stack feature to change the instance type. Before you resize the cluster, you must hibernate the cluster by setting the NodesPerZone value to 0. After you resize the cluster, you must restart the cluster by resetting the NodesPerZone value to the previously set value, as described in Hibernating a MarkLogic Cluster. Resizing a MarkLogic Cluster on AWS can be done horizontally and not just vertically (as described above), similar to how it is done with on-premise deployments. For changing the number of instances (horizontal scaling), use the Update Stack feature by changing the NodesPerZone setting on the CFT. Alternatively, you can use the auto-scaling groups. For more details, see Scaling Cluster Resources on EC2. Data capacity can be resized in two different ways: resizing using AWS snapshot and resizing using MarkLogic's rebalancing feature. While vertical scale out is significantly easier on AWS versus on-premise deployments, note that MarkLogic requires at least some degree of horizontal scaling as high availability (HA) requires at least three nodes in a cluster. Whether you are scaling nodes or data capacity, horizontally or vertically, it is recommended to: test your scale out procedure thoroughly before implementing as well as take full backups of your data before making changes to your cluster.
MarkLogic recommends taking a full backup before changing the instance type.
Terminating a MarkLogic Cluster
To terminate your MarkLogic cluster, you can delete the stack, as described in Deleting a CloudFormation Stack.