MarkLogic 10 Product DocumentationAdministrator's Guide — Chapter 20
Backing Up and Restoring a Database
MarkLogic Server provides a facility to make a consistent backup of a database. This section describes the backup and restore architecture and provides procedures for backing up and restoring a database. The following topics are included:
- Backup and Restore Overview
- Backing Up Databases with Journal Archiving
- Incremental Backup
- Backing Up a Database
- Restoring a Database from a Backup
- Backing up and Restoring a Database Following Local Disk Failover
Backup and Restore Overview
Database backup and restore operations in MarkLogic Server are distributed over all of the data nodes in a cluster (that is, all of the nodes that contain forests), and provide consistent database-level backups and restores.
The directory you specify for a backup or restore operation must exist on each data node associated with the database (it can be either a shared or unshared directory). For example, if you have a data node on Host1 with forests F1 and F2, and another data node on Host2 with forests F3 and F4, then the backup directory you specify must exist on both Host1 and Host2. The following figure shows such a configuration, where the Schemas and Security databases have forests F5 and F6 respectively, and they are also attached to Host1.
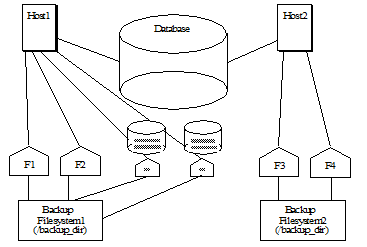
Consistent, Database-Level Backup
By default, when you back up a database you backup everything associated with it, including the following:
- The configuration files.
- The Security database, including all of its forests.
- The Schemas database, including all of its forests.
- All of the forests of the database you are backing up.
If you choose to back up all forests, you will have a backup that you can restore to the exact same state as when the backup begins copying files.
You can also backup any individual forests that you choose, choosing only the ones you need to backup. These forest-level backups are consistent for the data in the forest and any other forests included in the backup, but might not be consistent with changes that occur in other forests not included in the backup.
You can also choose not to backup the Security and Schemas databases. While having backups of these databases that are synchronized with the database backups is important to get the exact same view of the system as when the backup began, you might have separate processes for backing up these databases that can ensure proper consistency. For example, if they do not change frequently, you may only need to back them up when they change.
The database-level backup and restore in MarkLogic Server provides the flexibility for you to decide how much or how little you want to backup or restore. The choices you make depend on the amount of change in your system and your unique backup and restore requirements.
Admin Interface
You use the Admin Interface to initiate backup and restore operations. Use the Backup/Restore tab for each database configured in your system to initiate backup and restore operations. For specific procedures for backup and restore operations, see Backing Up a Database and Restoring a Database without Journal Archiving.
Backup and Restore Transactions
Backup and restore operations are transactional and therefore guarantee a consistent view of the data. They do not lock the database, however. Therefore, if the data in a database changes after a backup or restore operation begins but before it completes, those changes are not reflected in the backup or restore operation. Similarly, changes to the Security and Schemas databases during a backup or restore operation are allowed, but will not be reflected in the backup or restore.
Database and Forest administrative tasks such as drop, clear, and delete cannot take place during a backup; any such operation is queued up and will initiate after the backup transaction has completed.
Backup Directory Structure
When you back up a database, you specify a backup directory. That directory must exist on each host in your configuration, and must be readable and writable by the user running MarkLogic Server (by default daemon on UNIX and the local System user on Windows). Because of the importance of database backup integrity, MarkLogic recommends backing up to a reliable filesystem. The backup directory structure for each host is the same, except that the forests are only backed up on the host from which they are served.
Below the specified backup directory, a subdirectory is created with a name based on the date when the backup begins. Each of these subdirectories contain one backup. The following is the basic backup directory structure.
<specified_backup_dir>/ <date_1>-1/ *.xml BackupTag.txt Forests/ <security_forest_1>/ <forest_files_and_directories> <security_forest_n>/ <forest_files_and_directories> <schemas_forest_1>/ <forest_files_and_directories> <schemas_forest_n>/ <forest_files_and_directories> <database_forest_1>/ <forest_files_and_directories> <database_forest_n>/ <forest_files_and_directories> <triggers_forest_1>/ <forest_files_and_directories> <triggers_forest_n>/ <forest_files_and_directories> <date_1>-n/ <backup_directory structure> <date_n>-1/ <backup_directory structure> <date_n>-n/ <backup_directory structure>
For example, if you back up a database to the /space/backups directory on September 1, 2004, a directory structure similar to the following is created:
/space/backups 20040901-1/ *.xml BackupTag.txt Forests/ Documents/ Label 000001e1/ Journals/ Schemas/ Label 000001e1/ Journals/ Security/ Label 000001e1/ Journals/ Triggers/ Label 000001e1/ Journals/
Incremental backups are stored in the directory under the full backup. In this first example, the backup directory (backup-dir) is /space/backup and the incremental backup directory (incremental-dir) is not used:
/space/backups 20140801-1223942093224 (full backup on 8/1) 20140802 331006226070 (incremental backup on 8/2) 20130803 1341007528950 (incremental backup on 8/3)
The first part, 20140801, is the year, month and day of the backup. The second part, 1223942093224, is the hour, minute, second, and nanosecond of the backup.
In this example, the backup directory (backup-dir) is /space/backup and the incremental backup directory (incremental-dir) is /space/incremental.
/space/backups 20140801-1223942093224 (full backup on 8/1) /space/incremental 20140801-1223942093224 20140802 331006226070 (incremental backup on 8/2) 20140803 341007528950 (incremental backup on 8/3)
The directory 20130801-1223942093224 is created on /space/incremental so that when the backup 20130801-1223942093224 is purged, its incremental backups can be purged easily.
If an incremental backup directory is specified, after the first incremental backup is done, the full backup can be archived to another location. The subsequent incremental backups do not need to examine the full backup.
Once you restore an incremental backup, you can no longer use the previous full backup location for ongoing incremental backups. After the restore, you need to make a fresh full backup and use the full backup location for ongoing incremental backups. This means that after restore of an incremental backup, scheduled backups need to be updated to use the fresh full backup location.
Phases of Backup or Restore Operation
Backup and restore operations are divided into the following phases:
The following figure shows the phases of a backup or restore operation:

Validation Phase
The validation phase is where the backup directories are checked to make sure that all of the needed files exist and that all of the needed backup directories exist and are writable. For backup operations, they are checked for sufficient disk space. For restore operations, the configuration files are read and the other backup files are checked to make sure they appear to be valid. The validation phase does not actually write any data and is completely asynchronous.
Copy Phase
The copy phase is where the files are actually copied to or from the backup directory. The configuration files are copied at the beginning of the backup operation, and at this point a timestamp is written to the BackupTag.txt file. The copy phase might take a significant amount of time, depending on the size of the database. The start of the copy phase starts a transaction; if the transaction fails on a restore operation, the database remains unchanged from its original state.
Synchronization Phase
During a backup or restore operation, the synchronization phase is where cleanup tasks such as deleting temporary files takes place, leaving the database in a consistent state. During a restore operation, the synchronization phase also takes the old version of the database offline and replaces it with the newly restored version.
Any cold administrative tasks (tasks that require a server restart) will cause any backup or restore operations to fail. Do not perform any cold administrative tasks during a backup or restore operation. For a list of hot and cold operations, see Appendix A: 'Hot' versus 'Cold' Admin Tasks.
Notes about Backup and Restore Operations
This section provides notes and restrictions about backing up and restoring MarkLogic Server databases.
- For backing and restoring a database with encryption, see Backup and Restore in the Security Guide.
- The backup files are platform specific--backups on a given platform should only be restored onto the same platform. This is true for both database and forest backups.
- You can restore an individual forest using a database backup by unchecking all forests except the one you want to restore on the Confirm Restore screen (see step 11 in Restoring a Database without Journal Archiving).
- We recommend using the database-level backup/restore, not the forest-level backup/restore. If you do use the forest-level backup/restore, note that you cannot restore a backup created with the forest-level backup as a database-level restore operation; forest-level backups created with the forest backup/restore utility must be restored from the forest restore utility. For details, see Restoring a Forest.
- The restore operation is designed to restore into a database that has the same configuration settings as the one that was backed up, but it neither requires nor checks that the configurations are the same. The restore operation must occur on a database that has its configuration defined. Also, the restore operation does not change the database configuration files. Because the configuration files hold all of the database configuration information such as index options, fragmentation, range indexes, and so on, the restored database will take on the configuration information of the database to which it is restored. If this configuration information is different from the database that was backed up, and if reindexing is enabled, the database will reindex to the new configuration after the restore completes.
- If a database's backup is canceled, the in-flight backup is deleted. A database backup can be canceled by clicking the cancel button for the backup in the host status page in the Admin Interface, by the host or cluster being restarted (either from the Admin Interface or from the xdmp:restart command), or by errors in the backup (such as out-of-disk space errors). The process of deleting the in-flight backup during a clean restart might take some time, which can increase the time it takes to restart MarkLogic Server. If you are restarting using the startup scripts (
/sbin/service MarkLogic<command>)on UNIX systems and the control panel on Windows systems), then the script will delete as much of the backup as it can in 20 seconds; if any backup is in-flight during these types of system shutdown or restart operations, then you should manually remove them after the operation. - After you restore from an incremental backup, you can't use the previous full backup location for ongoing incremental backups. You will need to make a fresh full backup after the restore and use that full backup location for the ongoing incremental backups. This means that after the restore of an incremental backup, any scheduled backups will need to be updated to use the new full backup location.
Backing Up Databases with Journal Archiving
The backup/restore operations with journal archiving enabled provide a point-in-time recovery option that enables you to restore database changes to a specific point in time between full backups with the input of a wall clock time. When journal archiving is enabled, journal frames are written to backup directories by near synchronously streaming frames from the current active journal of each forest.
When you create scheduled backups with journal archiving enabled, and then later delete the backup, it does not stop journal archiving from occuring even though the backups stop happening. The xdmp:stop-journal-archiving function must be to explicitly called to stop journal archiving.
When journal archiving is enabled, you will experience longer restore times and slightly increased system load as a result of the streaming of journal frames.
Journal archiving can only be enabled at the time of a full backup. If you restore a backup and want to reenable journal archiving, you must perform a full backup at that time.
When journal archiving is enabled, you can set a lag limit value that specifies the amount of time (in seconds) in which frames being written to the forest's journal can differ from the frames being streamed to the backup journal. For example, if the lag limit is set to 30 seconds, the archived journal can lag behind a maximum of 30 seconds worth of transactions compared to the active journal. If the lag limit is exceeded, transactions are halted until the backup journal has caught up.
The active and backup journal are synchronized at least every 30 seconds. If the lag limit is less than 30 seconds, synchronization will be performed at least once in that period. If the lag limit is greater than 30 seconds, synchronization will be performed at least once every 30 seconds. The default lag limit is 15 seconds.
The decision on setting a lag limit time is determined by your Recovery Point Objective (RPO), which is the amount of data you can afford to lose in the event of a disaster. A low RPO means that you will restore the most data at the cost of performance, whereas a higher RPO means that you will potentially restore less data with the benefit of less impact to performance. In general, the lag limit you chose depends on the following factors:
Incremental Backup
An incremental backup stores only the data that has changed since the previous full or incremental backup. Typically a series of incremental backups are done between full backups. Incremental backups are more compact than archived journals and are faster to restore. It is possible to schedule frequent incremental backups (for example, by ranges of hours) because an incremental backup generally takes less time to complete than a full backup. In normal conditions, it is recommended an incremental backup not be configured for a frequency less than every four hours.
To enable an incremental backup, set Incremental backup to true while initiating or scheduling a backup. See Backing Up a Database for details. Full and incremental backups need to be scheduled separately. An example configuration might be:
A full backup and a series of incremental backups can allow you to recover from a situation where a database has been lost. Incremental backup can be used with or without journal archiving. If you enable both incremental backup and journal archiving, you can replay the journal starting from the last incremental backup timestamp. See Backing Up Databases with Journal Archiving for more about journal archiving.
When you restore from an incremental backup, you need to do a full backup before you can continue with incremental backups.
Incremental backup and journal archiving both provide disaster recovery. Incremental backup uses less disk space than journal archiving, and incremental backup is faster than using journal archiving.
If MarkLogic Server cannot memory-map files from the backup in the underlying file system, it cannot create an incremental backup. So MarkLogic incremental backups require that the backup file system support memory-mapping operations (mmap).
For recovery you only need to specify the timestamp for the recovery to start and the server will figure out which full backup and which incremental backup(s) to use. You only need to schedule the incremental backup; the server will link together (or chain) the sequence the incremental backups automatically. See Restoring from an Incremental Backup with Journal Archiving for details.
Incremental Backup of New Forest
Incremental backup supports backup of a forest added since last full backup. If you add a new forest after a full backup of your database, you can include the new forest as part of your next incremental backup.
After you attach a new forest to your database, it will be included in the list of forests to be backed up in the Confirm backup step (Step 12 in Backing Up a Database Immediately).
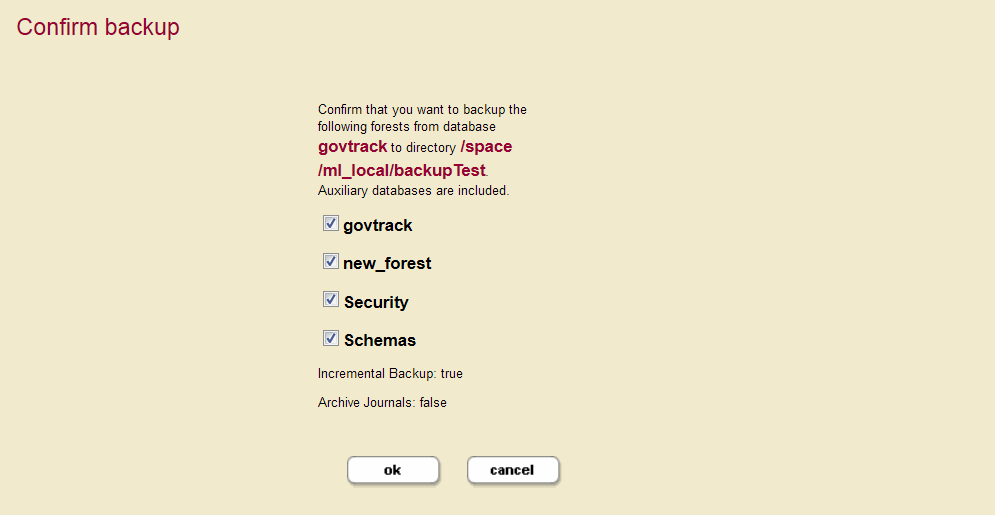
Select the forest to include it in the backup and click ok. See Backing Up a Database for more information.
Incremental Backup with Journal Archiving
Incremental backup improves restore both time and space requirements over journal archiving, but it's not an either/or decision. You can, and should, use both where appropriate. If your goal is to be able to restore to any arbitrary point in time, while minimizing potential data loss, we suggest the following:
- Configure a scheduled full backup at some coarse granularity (for example, weekly) and enable journal archiving
- Configure a scheduled incremental backup as some finer granularity (for example, hourly), and specify
purge-journal-archiving=true. - Set
retain until backupon the database Merge Policy so that deleted fragments are retained until they have been included in an incremental backup. See Setting Merge Policy or admin:database-set-retain-until-backup for details.
This configuration means that journal archives are only needed for the most recent hour, and the older ones are purged once there is an incremental backup that covers that hour. Enabling retain until backup ensures that the incremental backups have sufficient state to restore the database to any point since the previous incremental backup.
When you restore, the full and incremental backups can be used to return to any point in time prior to the most recent backup, and the journal archive will only be used if your restore point is more recent than the last incremental backup.
Backing Up a Database
You can either initiate a database backup immediately or you can schedule a backup to occur in the future with the following procedures:
The backup procedures include options to specify journal archiving and/or incremental backup. You can choose to do a full backup or incremental backup, with or without journal archiving enabled.
Backing Up a Database Immediately
Perform the following steps to initiate a database backup:
- Log into the Admin Interface as a user with the
adminrole. - Click the
Databaseslink in the left menu of the Admin Interface. - Click the database name for the database you want to back up, either from the tree menu or on the summary page.
- Click the
Backup/Restoretab. The Backup/Restore screen appears. - Enter the directory to which you want the database backed up in the
Backup to directoryfield.The backup directory path must exist on all hosts that serve any forests in the database. The directory you specified can be an operating system mounted directory path, it can be an HDFS path, or it can be an S3 path. For details on using HDFS and S3 storage in MarkLogic, see Disk Storage Considerations in the Query Performance and Tuning Guide. Additionally, if you are using Windows and are backing up to a remote Windows path, you must set the registry settings and permissions as described in Windows Shared Disk Registry Settings and Permissions.
- If you want to encrypt your backup, enter an encryption password.
- If you have configured forests for local-disk failover, you can optionally set I
nclude Replica Foreststo true if you want to include the replica forests in the backup. For details on configuring forests for local-disk failover, see Configuring Local-Disk Failover for a Forest in the Scalability, Availability, and Failover Guide. - Set
Incremental backupto true to create an incremental backup. The default is a full backup (false). - Set
Archive Journalsto true and set theJournal Archiving Lag Limitif you want to enable point-in-time recovery. TheJournal Archiving Lag Limitis described in Backing Up Databases with Journal Archiving.If Journal Archiving is enabled, you cannot include auxiliary forests, as they should have their own separate backups.
- Click OK.
- If a directory creation error appears, then the directory is not writable. Either change the permissions on an existing directory or create a new directory with the proper permissions (readable and writable by the user running MarkLogic Server, by default
daemonon UNIX and the local System user on Windows) and click OK again. - The
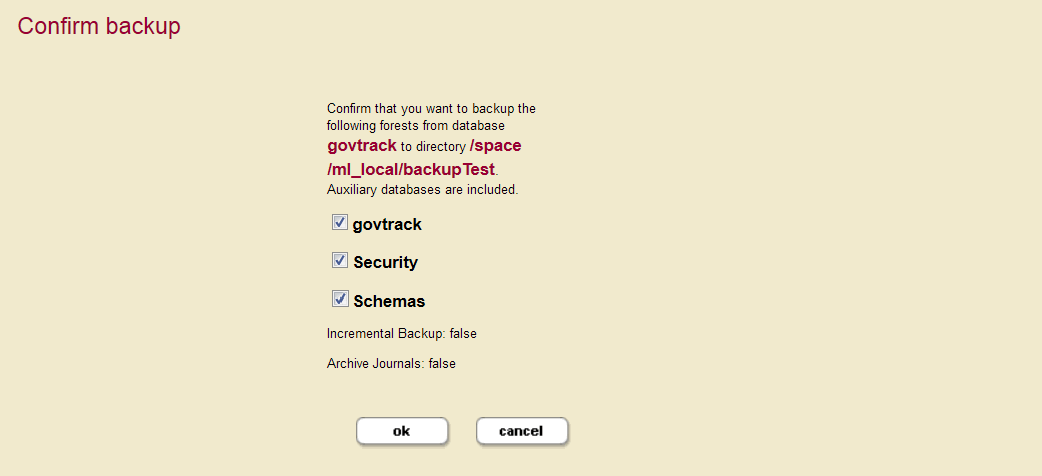
Confirm backupscreen appears and lists all the forest selected for back up. - Click OK to begin the backup immediately, or deselect forests that you do not want to back up.
If you deselect any of the forests to backup, you might not have a completely consistent view of the database to restore. Only deselect any forests if you are sure you understand the implications of what you are backing up. To guarantee the exact same view of the database, backup all of the forests associated with the database, including the Schemas and Security database forests.
- After the backup is underway, the Admin Interface redirects you to the Database Status page.
- You can refresh the Database Status screen to view the progress of the backup. The Backups table lists when the backup was started, provides an estimate of the amount of time left, and lists other status information about the backup operation.
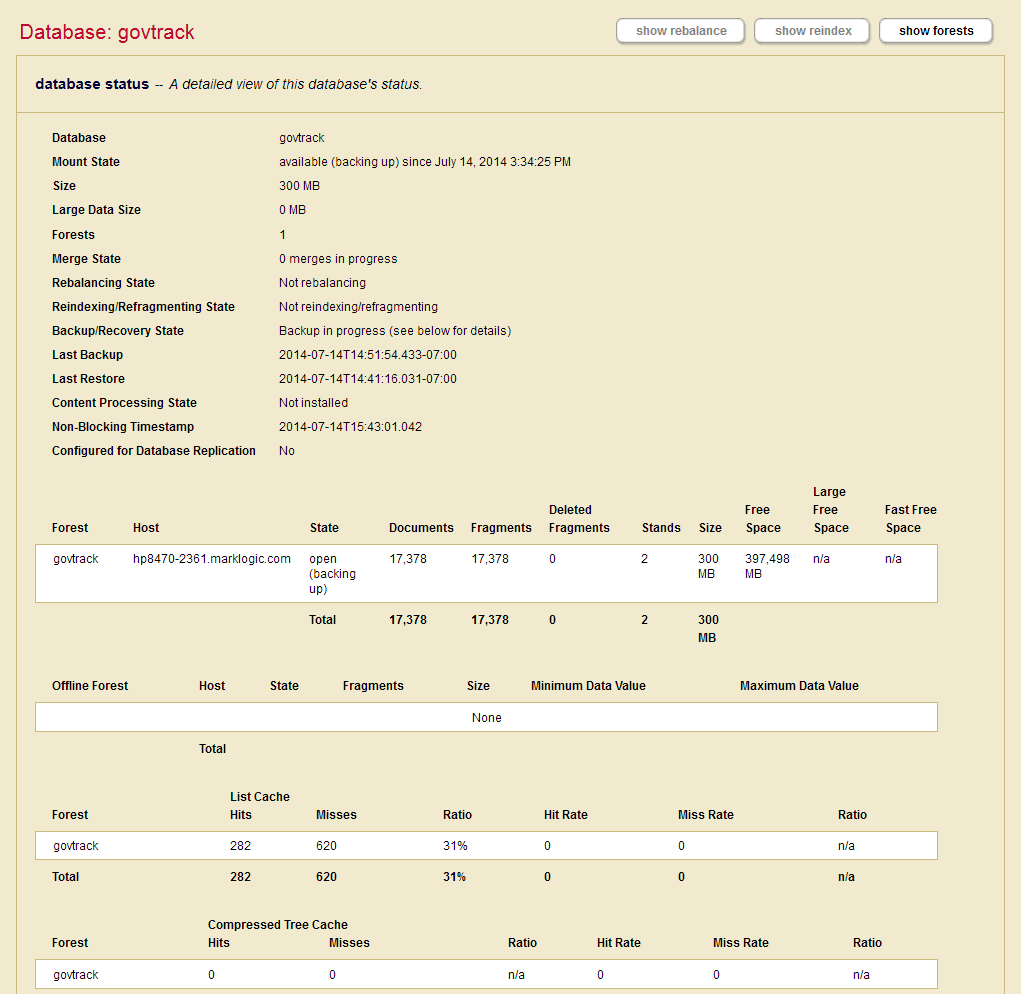
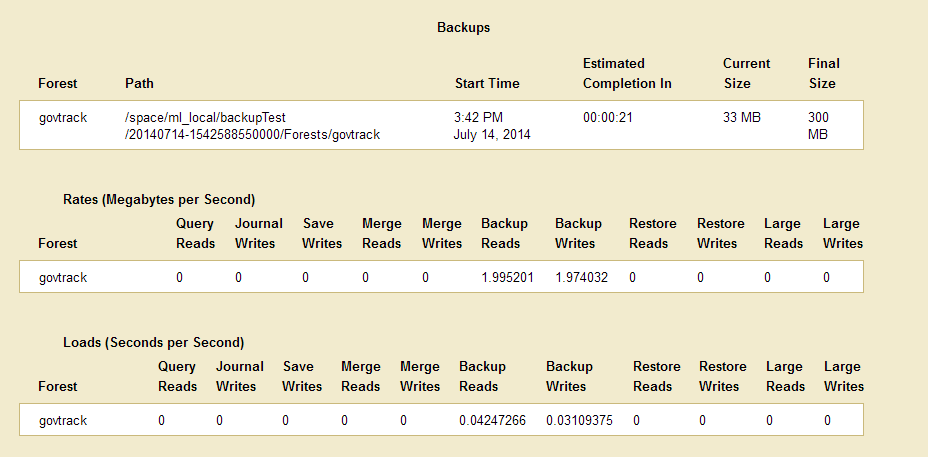
When the backup is complete, the entry in the backup table disappears.
If the status for any of the forests was something besides completed, then an error occurred during the backup operation. Check the Mark_Logic_Data/Logs/ErrorLog.txt file for any errors, correct them, and try the backup operation again.
Scheduling a Database Backup
You can schedule database backups to periodically back up a database. You can schedule backups to occur daily, weekly, monthly, or you can schedule a one-time backup. You can create as many scheduled backups as you want. To create a scheduled backup, perform the following steps using the Admin Interface:
- Click the
Databasesicon on the left tree menu. - Select the database for which you want to schedule a backup, either on the tree menu or from the
Database Summarypage. TheDatabase Configurationpage appears. - Click the
Scheduled Backuplink in the tree menu for the database. TheScheduled Backup Configurationpage appears. - On the
Scheduled Backup Configurationpage, you can delete any existing scheduled backups if you no longer need them. - Click the
Createtab. TheSchedule a Database Backuppage appears: - Enter the absolute path to the backup directory. The backup directory must have permissions such that the MarkLogic Server process can read and write to it.
The backup directory path must exist on all hosts that serve any forests in the database. The directory you specified can be an operating system mounted directory path, it can be an HDFS path, or it can be an S3 path. For details on using HDFS and S3 storage in MarkLogic, see Disk Storage Considerations in the Query Performance and Tuning Guide.
- Choose a scheduled or one-time for the backup type:
- For minutely, enter how many minutes between each backup.
- For hourly, enter how many hours between each backup. The
Backup Minutesetting specifies how many minutes after the hour the backup is to start. Note that theBackup Minutesetting does not add to the interval. - For daily, enter how many days between each backup and the time of day.
- For weekly, enter how many weeks between each backup, check one or more days of the week, and the time of day for the backup to start.
- For monthly, enter how many months between each backup, select one day of the month (1-31), and the time of day for the backup to start.
- For one-time, enter the backup start date in MM/DD/YYYY notation (for example, 07/29/2009 for July 29, 2009) and time in 24:00 notation.
- Enter the time of day to start the backup.
- Enter the maximum number of backups to keep. When you reach the specified maximum number of backups, the next backup will delete the oldest backup. Specify 0 to keep an unlimited number of backups.
- Choose whether you want the backups to include the security database, the schemas database, and/or the triggers database for this scheduled backup.
- Choose whether you want the backups to include the replica forests, as well as the master forests.
- Choose whether you want to schedule an incremental backup or a full backup.
- Choose whether you want the backups to enable Journal Archiving for point-in-time recovery. For details on Journal Archiving, see Backing Up Databases with Journal Archiving.
If Journal Archiving is enabled, you cannot include auxiliary forests, as they should have their own separate backups.
- If you have enabled Journal Archiving, you can change the lag limit to control the amount of time in seconds in which a journal being backed up can differ from the current active journal.
- Click OK to create the scheduled backup.
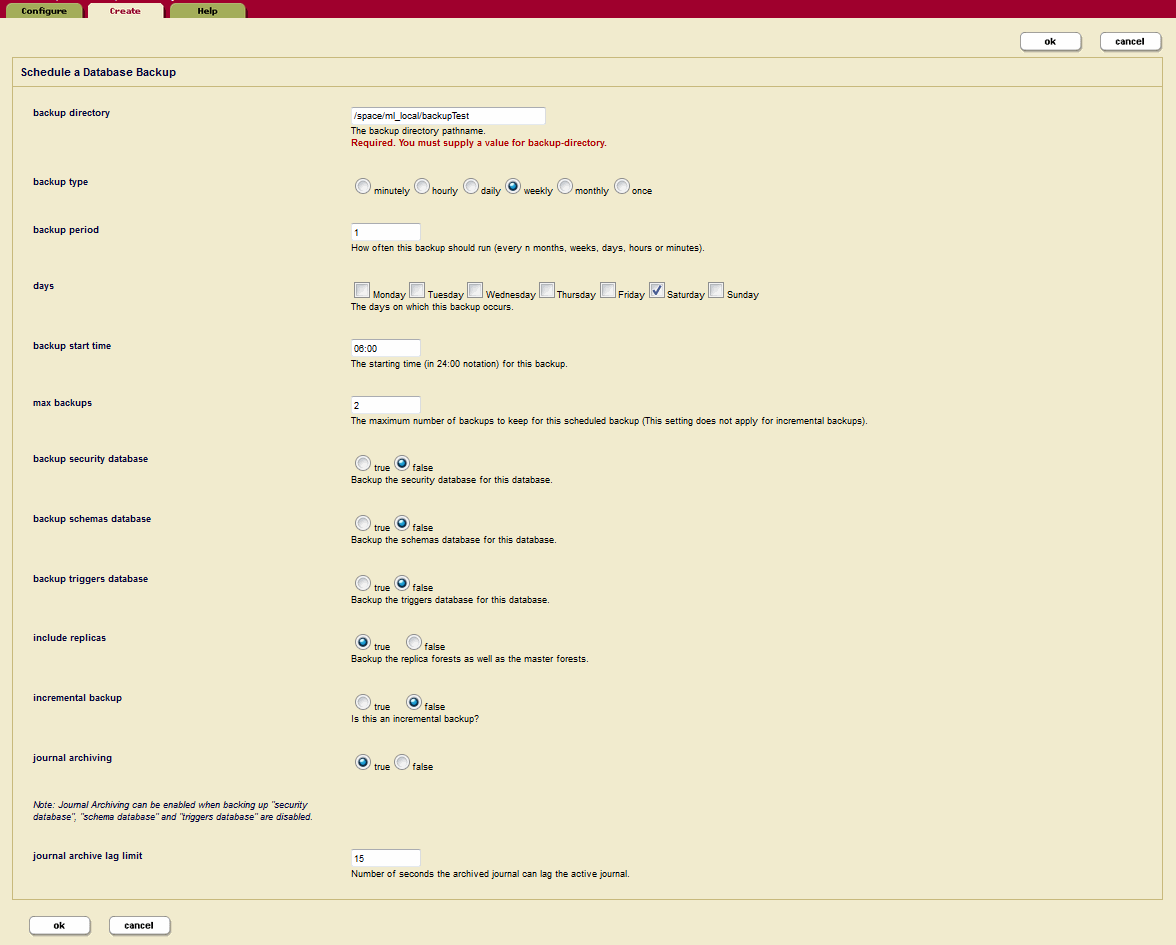
The backups will automatically start according to the specified schedule.
Restoring a Database from a Backup
There are a number of ways to restore a database from a backup, as described in the following sections.
- Admin Interface for Database Restore
- Restoring a Database without Journal Archiving
- Restoring Databases with Journal Archiving
- Restoring from an Incremental Backup with Journal Archiving
- Restoring to the Safe Timestamp
- Restoring to a Specific Timestamp
- Restoring Based on Sample Documents
- Restoring a Reconfigured Database
Depending on how the backup was made and what has changed since then, some restore operations may require a combination of these procedures.
Do not restore the App-Services database from another cluster because this type of backup causes the following error:
MANAGE-TIMESTAMPOLD: Config files out of date on host.
Admin Interface for Database Restore
This section describes the Admin Interface used to restore a database.
To access the database restore page, perform the following steps:
- Log into the Admin Interface as a user with the
adminrole. - Click the
Databaseslink in the left menu of the Admin Interface. - Click the database name for the database you want to restore, either on the tree menu or on the summary page. This database should have the same configuration settings (index options, fragmentation, range indexes) as the one that was backed up.
- Click the
Backup/Restoretab. The Backup/Restore screen appears.
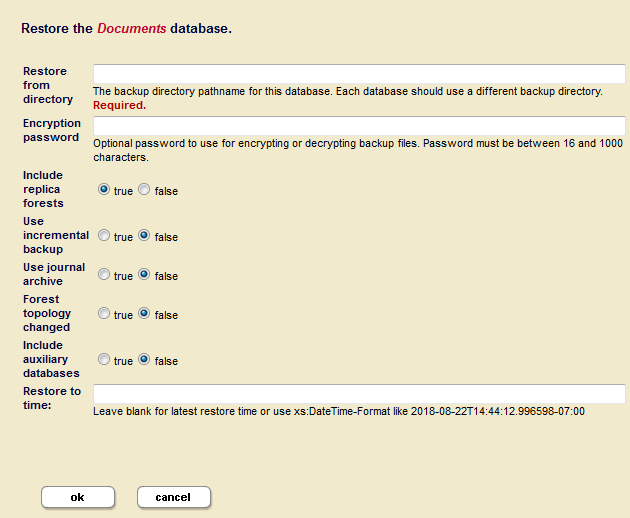
The database restore settings are described in the table below.
Restoring a Database without Journal Archiving
This section describes how to restore a database if no journal archiving was enabled for the last backup.
If your last backup enabled Journal Archiving, stop here and follow the procedure described in Restoring Databases with Journal Archiving.
To restore an entire database from a backup, perform the following steps:
- Log into the Admin Interface as a user with the
adminrole. - Click the
Databaseslink in the left menu of the Admin Interface. - Click the database name for the database you want to restore, either on the tree menu or on the summary page. This database should have the same configuration settings (index options, fragmentation, range indexes) as the one that was backed up.
- Click the
Backup/Restoretab. The Backup/Restore screen appears. - Enter the directory in which the back up exists in the
Restore From Directoryfield. - If the backup was encrypted, enter the encryption password.
If you enter a directory that contains multiple backups of the same database, the latest one is used. If you want to choose a particular backup to restore, enter the date_stamp subdirectory corresponding to the backup you want to restore. For details of the directory structure, see Backup Directory Structure.
- If you have configured forests for local-disk failover, you can optionally set
Include Replica Foreststo true if you want to restore the replica forests from the backup. In order to use this option, you must have enabled the option to include the replica forests in the backup. For details on configuring forests for local-disk failover, see Configuring Local-Disk Failover for a Forest in the Scalability, Availability, and Failover Guide. - If you want to restore an incremental back up, set
Use Incremental Backuptotrue.If you restore from an incremental backup, you can't use the previous full backup location for ongoing incremental backups. You need to make a fresh full backup after the restore and use the full backup location for the ongoing incremental backups. After doing a restore from an incremental backup, any scheduled backups will need to be updated to use the new full backup location.
- Leave
Use Journal Archivefalse. - Click OK.
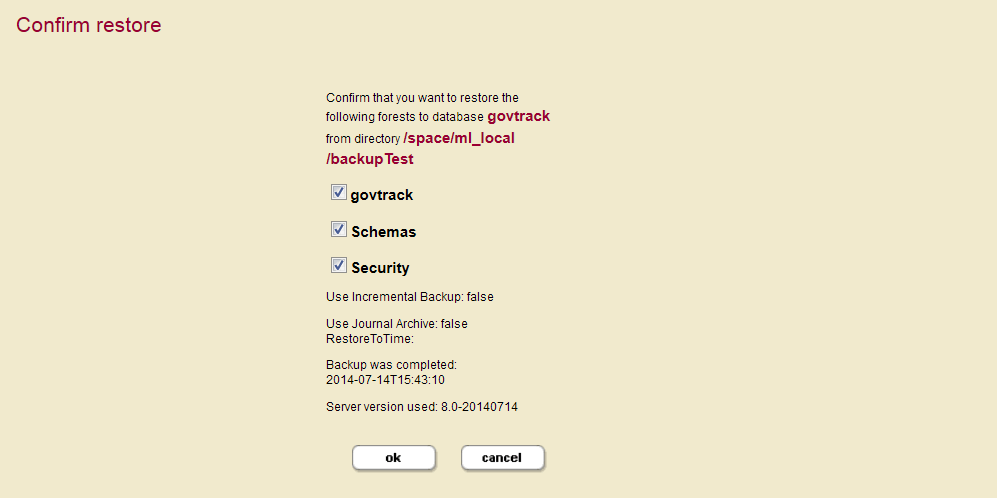
- The
Confirm Restorescreen appears and lists all the forest selected for restoring.The
Confirm Restorescreen also lists the date the backup was performed and the server version used for the backup you selected. - By default, all of the forests associated with a database are checked to restore. If you do not want to restore all of the forests, deselect any forests you do not want to restore.
If you deselect any of the forests to restore, you might not be restoring a completely consistent view of the database. Only deselect any forests if you are sure you understand the implications of what you are restoring. To guarantee the exact same view of the database, restore all of the forests associated with the database, including the Schemas and Security database forests.
- Click OK to begin the restore operation.
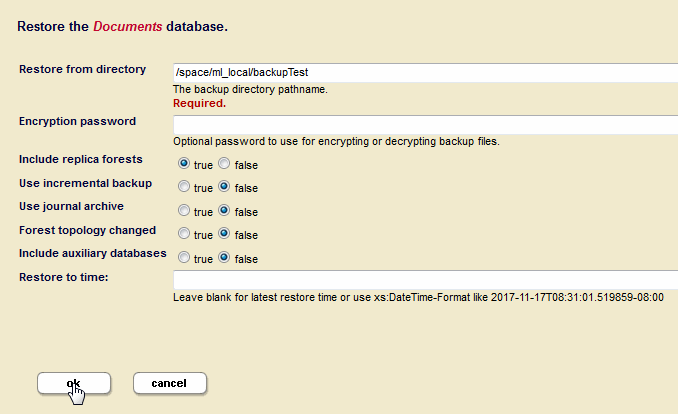
The Restores table lists when the restore was started, provides an estimate of the amount of time left, and lists other status information about the restore operation. 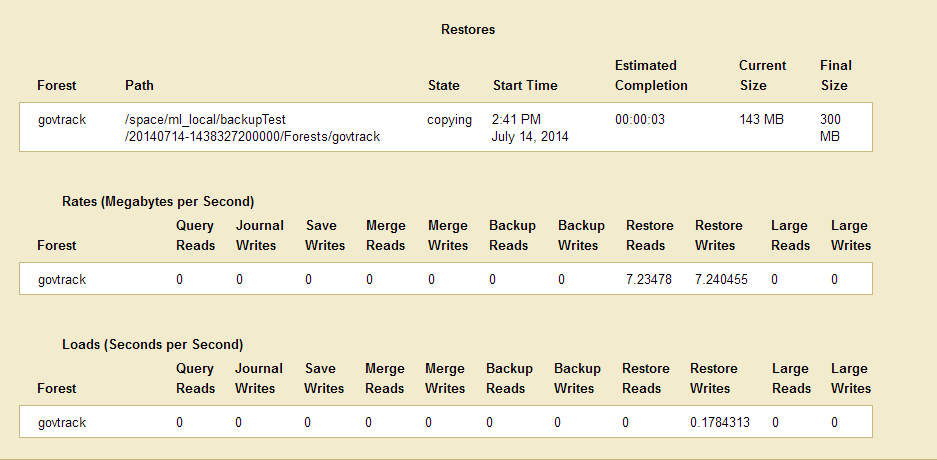
When the restore is complete, the entry in the backup table disappears. If the status for any of the forests was something besides completed, then an error occurred during the restore operation. Check the Mark_Logic_Data/Logs/ErrorLog.txt file for any errors, correct them, and try the restore operation again.
Restoring Databases with Journal Archiving
After you restore a database with Journal Archiving enabled, each forest will likely have committed its last transaction at different timestamps.
For example, the illustration below shows four forests and their committed transactions. Updates for each transaction are identified by the convention 'T#-u#' and commits are identified by a 'C'. Each forest completed its last commit at a different point in time when the restore is finished. In this example, we are restoring from timestamp 0 to 6, Forest A has only committed transactions up to timestamp 3 while Forest B has committed transactions up to timestamp 6. This means that, in order to return the database to a transactionally consistent state, all forests must be rolled back to timestamp 3 or earlier.

Your options for recovering your data and returning the database to a transactionally consistent state are as follows:
- Restore as much data as possible. Follow the procedure described in Restoring to the Safe Timestamp.
- Restore data at a specific timestamp. Follow the procedure described in Restoring to a Specific Timestamp.
- Restore data at a specific timestamp based on the state of some sample documents. Follow the procedure described in Restoring Based on Sample Documents.
The following sections describe how to use the XQuery API to restore the database. You can also use the Admin Interface to accomplish some of the tasks.
If you are using XA distributed transaction processing, a restore to a point in time may revive some XA transactions that were prepared before the target restore time, and committed/aborted after that time. For details on how to identify XA transactions, see Heuristically Completing a MarkLogic Server Transaction in the XCC Developer's Guide
You cannot roll back through a database clear operation, so you should check the server logs for points in time that any clear operations occurred.
Restoring from an Incremental Backup with Journal Archiving
To restore from an incremental backup, the server uses the base backup in the backup tag to get a series of incremental backups that lead to the full backup. The restore then starts with a full backup and restores using the incremental backups in reverse order. You need to specify the full backup directory and optionally the incremental backup directory. If no restore timestamp is specified, the server finds the latest backup from which to restore. Once you have completed this process, you can use journal archiving to restore the database to the current time.
If a restore timestamp is specified, the server finds a backup where the restore timestamp is between the minimum query timestamp and the backup timestamp. If no backup meets the requirement and there is a journal archive, the server finds the latest backup with backup timestamp smaller than the restored timestamp. It restores to that backup and then replays the journal to the restored timestamp.
If the journal archive exists, the server will find the backup timestamp of the last incremental backup and replay the journal starting from that timestamp.
Once you restore from an incremental backup, you can no longer use the previous full backup location for ongoing incremental backups. After the restore, you need to make a fresh full backup and use that full backup location for the ongoing incremental backups. This means after the restore from an incremental backup, any scheduled backups will need to be updated to use the new full backup location. Using the old full backup location for incremental backup after a restore will cause an error.
This procedure describes how to restore a database to the current point in time using a full backup, one or more incremental backup, and journal archiving. You need to have a full backup using journal archiving and one or more incremental backups using journal archiving.
- Log into the Admin Interface as a user with the
adminrole. Click the Databases link in the left menu of the Admin Interface. - Click the database name for the database you want to restore, either on the tree menu or on the summary page. This database should have the same configuration settings (index options, fragmentation, range indexes) as the one that was backed up.
For journal archiving, you need either the timestamp for the restore target or the current timestamp. This example uses a blank field (latest restore time/current timestamp) for the restore target.
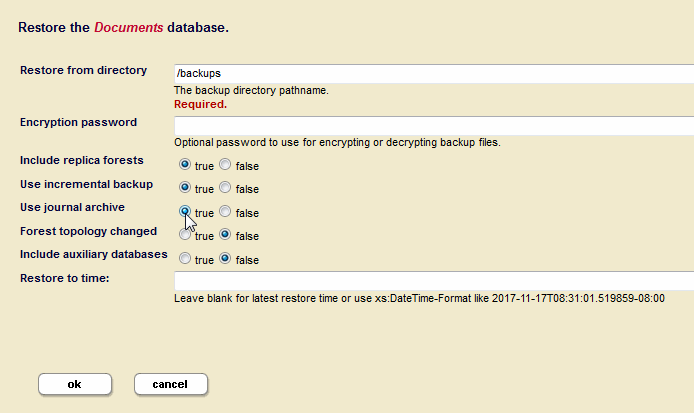
- Click the
Backup/Restoretab. The Backup/Restore screen appears. In the Restore from directory field, enter the directory where the backup exists.If you enter a directory that contains multiple backups of the same database, the latest one is used. If you want to choose a particular backup to restore, enter the date_stamp subdirectory corresponding to the backup you want to restore. For details of the directory structure, see Backup Directory Structure.
- If you have configured forests for local-disk failover, you can optionally set I
nclude Replica Foreststotrueif you want to restore the replica forests from the backup. In order to use this option, you must have enabled the option to include the replica forests in the backup. For details on configuring forests for local-disk failover, see Configuring Local-Disk Failover for a Forest in the Scalability, Availability, and Failover Guide. - Set
Use incremental backuptotrue. SetUse Journal Archivetotrue. Leave theRestore to timeblank or enter a time inxs:DataTime-Format.For Journal archiving to work, you need a Restore to time, otherwise the restore will proceed with last Incremental backup it finds at the location. Also, the Merge Timestamp should be older than the Restore Time.
When restoring a backup with journal archiving enabled, be sure to change the merge timestamp from 0 to a non-zero value. Using zero for the merge timestamp will result in an error when restoring with journal archiving and restore-to-time set to zero. The merge timestamp must be set to a non-zero value.
- Click OK to begin the restore process.
- The Confirm restore screen lists the options you selected for restoring. Click OK.
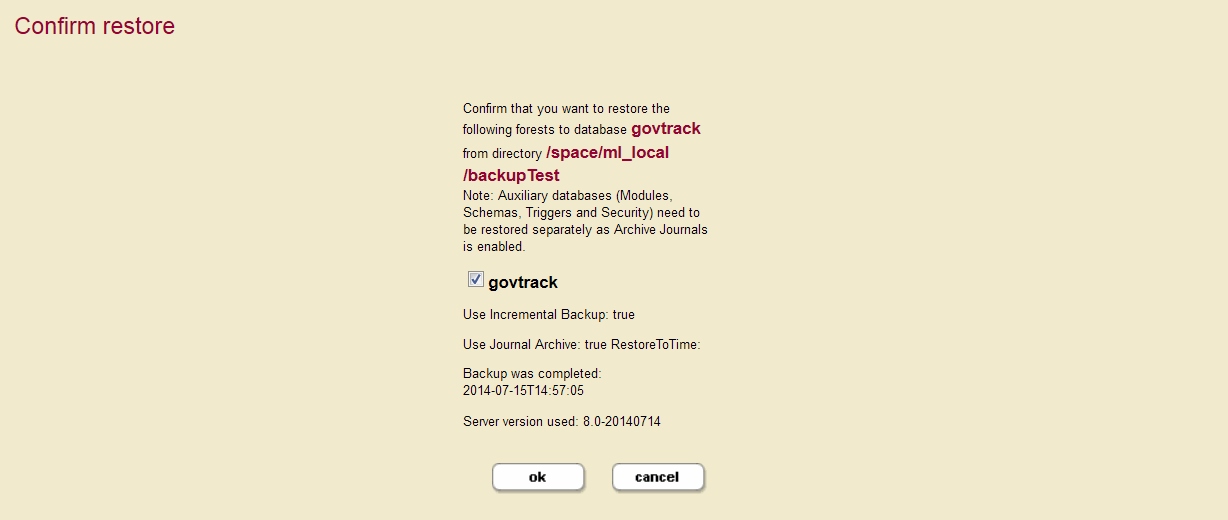
The Restores table lists when the restore was started, provides an estimate of the amount of time left, and lists other status information about the restore operation. 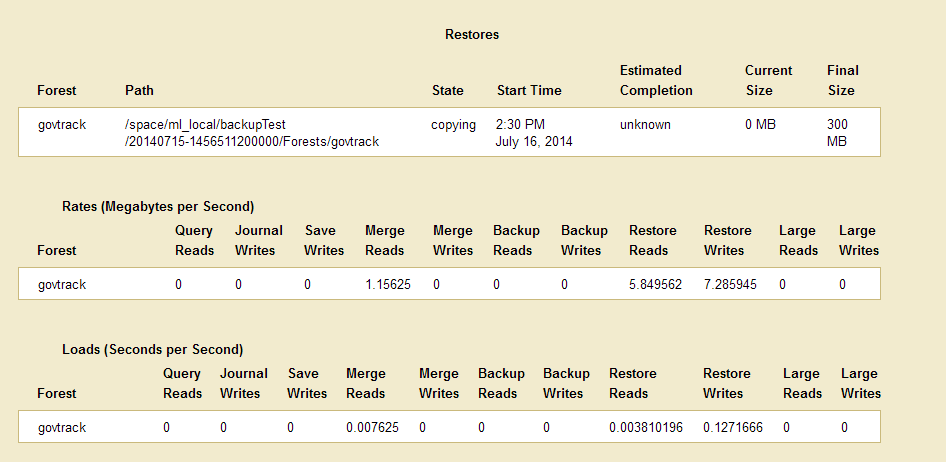
When the process is complete, the Restores table entry will disappear.
Restoring to the Safe Timestamp
If you want to restore as much data as possible, you can restore your data to the minimum safe timestamp.
For example, the database you want to restore has four forests, as shown below. You use the xdmp:host-status function to locate the safe-restore-to-time value, which is earliest of the four last-commit timestamps. In this example, the safe-restore-to-time is the timestamp of the last committed transaction in Forest A.

The following procedure describes how to restore to the minimum timestamp using the XQuery API.
This same procedure can be done using the Admin Interfaces described in Setting Merge Policy, Admin Interface for Database Restore, and Rolling Back a Transaction.
- Use the admin:database-get-merge-timestamp function to get the current merge timestamp. Save this value so it can be reset after you have completed the rollback operation.
- Use the admin:database-set-merge-timestamp function to set the merge timestamp to any time before your minimum safe timestamp. This will preserve fragments in merge after this timestamp until you have rolled back your forest data.
- Use the xdmp:database-restore function with
$journal-archivingset tofn:true()and$restoreToTimeset tonull( )to restore the database to the latest timestamp. - After the restore operation has completed, use the xdmp:forest-rollback function to roll back the forests to the
safe-restore-to-timetimestamp returned by the xdmp:host-status function.For example, if you are restoring the Documents database, you can use the following query to rollback your forest data:
xquery version "1.0-ml"; declare namespace host = "http://marklogic.com/xdmp/status/host"; let $timestamp := xdmp:wallclock-to-timestamp( xs:dateTime(xdmp:host-status(xdmp:host("your-host.com")) /host:restore-jobs/host:restore-job/host:safe-restore-to-time /fn:data(.))) return xdmp:forest-rollback( xdmp:database-forests(xdmp:database("Documents")), $timestamp) - Use admin:database-set-merge-timestamp function to set the merge timestamp back to the value you saved in Step 1.
Restoring to a Specific Timestamp
The following procedure describes how to restore a database to a specific timestamp using the XQuery API.
This same procedure can be done using the Admin Interfaces described in Setting Merge Policy, Admin Interface for Database Restore, and Rolling Back a Transaction.
- Use the admin:database-get-merge-timestamp function to get the current merge timestamp. Save this value so it can be reset after you have completed the rollback operation.
- Use the admin:database-set-merge-timestamp function to set the merge timestamp to any time before the restore timestamp. This will preserve fragments in merge after this timestamp until you have rolled back your forest data.
- Use the xdmp:database-restore function with
$journal-archivingset tofn:true()and$restoreToTimeset to the restore timestamp to restore the database. - After the restore operation has completed, use the xdmp:forest-rollback function to roll back the forests to the restore timestamp. For example, if you are restoring the Documents database and the restore timestamp is 2011-09-13T10:50:21.201832-07:00, your xdmp:forest-rollback function call would be:
xdmp:forest-rollback( xdmp:database-forests(xdmp:database("Documents")), xdmp:wallclock-to-timestamp( xs:dateTime("2011-09-13T10:50:21.201832-07:00")))
- Use admin:database-set-merge-timestamp function to set the merge timestamp back to the value you saved in Step 1.
Restoring Based on Sample Documents
You may want to use the state of some sample documents to determine the time at which to restore the database.
The following procedure describes how to restore to the state of some documents using the XQuery API.
This same procedure can be done using the Admin Interfaces described in Setting Merge Policy, Admin Interface for Database Restore, and Rolling Back a Transaction.
- Use the admin:database-get-merge-timestamp function to get the current merge timestamp. Save this value so it can be reset after you have completed the rollback operation.
- Use the admin:database-set-merge-timestamp function to set the merge timestamp to any time before the backup was taken. This will preserve fragments in merge after this timestamp until you have rolled back your forest data.
- Use the xdmp:database-restore function with
$journal-archivingset totrueand$restoreToTimeset to null( )to restore the database to the latest timestamp. - After the restore operation has completed, use point-in-time queries described in the Point-In-Time Queries chapter in the Application Developer's Guide to determine the time at which the sample documents last looked correct.
- Use the xdmp:forest-rollback function to roll back the forests to the timestamp used for the successful point-in-time queries. For example, if you are restoring the Documents database and the documents at the timestamp 2011-09-13T10:57:25.201832-07:00 look correct, your xdmp:forest-rollback function call would be:
xdmp:forest-rollback( xdmp:database-forests(xdmp:database("Documents")), xdmp:wallclock-to-timestamp( xs:dateTime("2011-09-13T10:50:21.201832-07:00")))
- Use admin:database-set-merge-timestamp function to set the merge timestamp back to the value you saved in Step 1.
Restoring a Reconfigured Database
You can restore a database from a backup, even if forests have been added to or subtracted from the database after the backup. When the number of database forests are asymmetrical to the backup forests, the following mapping rules apply:
- Restore a single database forest from a single backup forest.
- Restore a single database forest from multiple backup forests.
When restoring a database that has added or subtracted forests since the backup, click on the Backup/Restore tab, go to the Restore section of the page, enable the Forest topology changed option, and click Ok.
The Confirm Restore page appears, showing the existing forests for the database on the left and the backed up forests as pull down menus on the right.
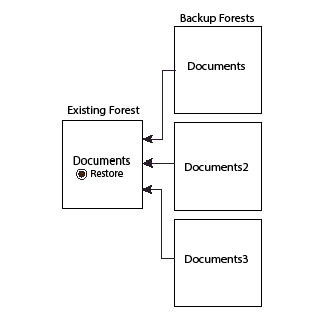
For example, you want to restore from a backup that was done when the Documents database had only one forest (Documents) and the restore operation is done after adding two more forests (Documents2 and Documents3) to the Documents database. You can only restore a backup forest to a single existing forest. In this example, we are populating the Documents forest from the backup of the Documents forest.
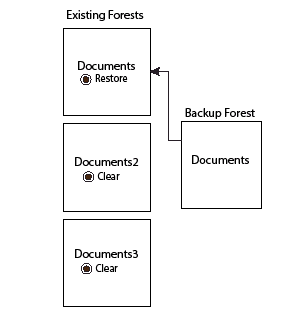
The Confirm Restore page below shows the restore operation. This operation is restoring the Documents forest from the Documents backup forest. To ensure that the Documents database is restored with the data from the backup, set the Documents2 and Documents3 forests to clear to remove any data added since the backup.
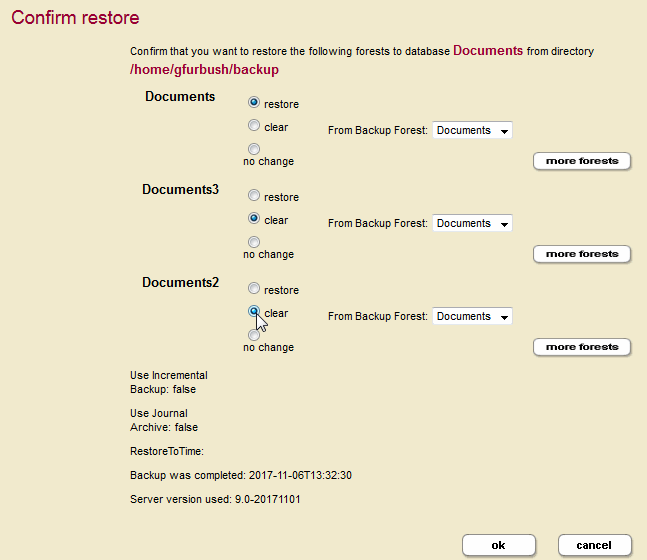
The following are the restore options for each existing forest.
To restore from a backup that contains more than one forest, select More Forests and chose the additional backup forests from the pull down menus, as shown below.
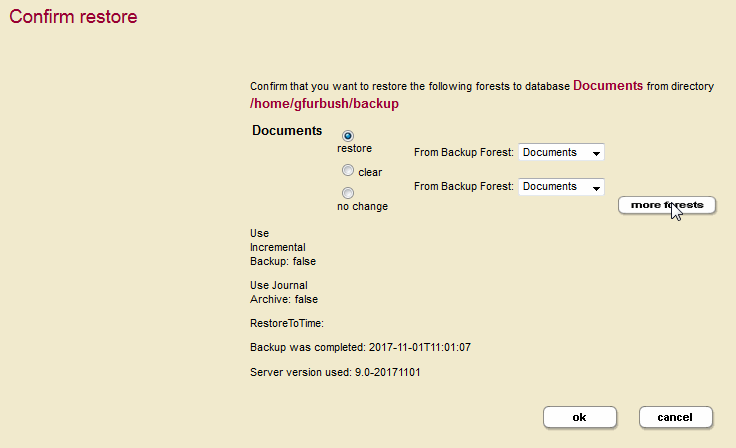
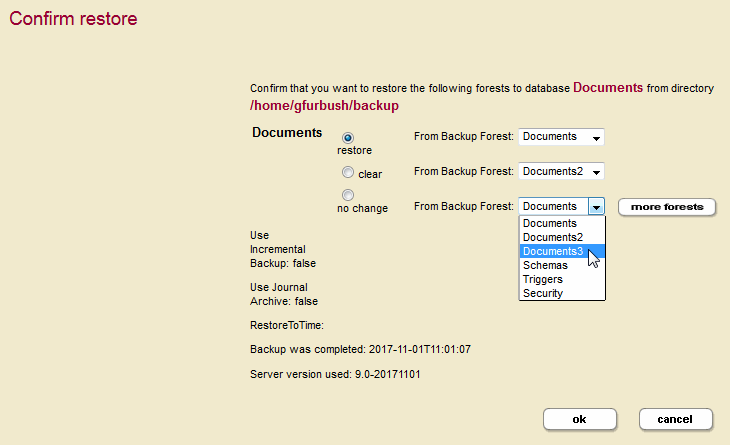
For example, you want to restore from a backup that was done when the Documents database had three forests, Documents, Documents2, and Documents3 and the restore operation is done after deleting the Documents2 and Documents3 forests. In this example, we are populating the singular Documents forest from the Documents, Documents2, and Documents3 backup forests.
The Confirm Restore page below illustrates the restore operation.
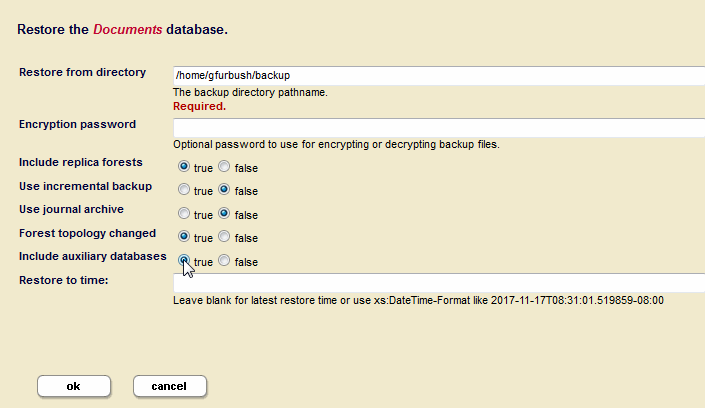
To restore a database that has added or subtracted forests since the backup, along with the auxiliary databases (Security, Schemas, and Triggers); click on the Backup/Restore tab; go to the Restore section of the page; enable the Forest topology changed and Include auxiliary databases options, and click Ok.
The Include auxiliary databases option is only relevant when Forest topology changed is enabled.
Backing up and Restoring a Database Following Local Disk Failover
Following a failure of a host that contains a master forest configured for local disk failover, the database attached to the master forest fails over to the replica forest. This section describes how to back up the surviving replica forest data and restore the data after the host containing the master forest has been restored. In the example procedure described in this section, the Documents database is attached to the Documents-master forest on one host and is configured for local-disk failover to the Documents-rep forest on another host.
For details on how to configure local disk failover, see the Configuring Local-Disk Failover for a Forest chapter in the Scalability, Availability, and Failover Guide.
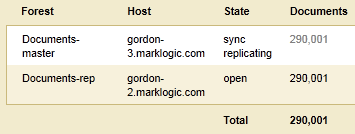
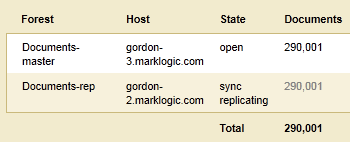
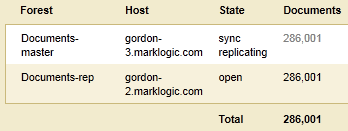
- Before the failure, the
Documents-masterforest is in theopenstate and theDocuments-repforest is in thesync replicatingstate. - A failure occurs on the host containing the
Documents-masterforest and theDocumentsdatabase automatically fails over to theDocuments-repforest. TheDocuments-repforest is now in theopenstate and servicing updates on behalf of theDocumentsdatabase.The configuration of the
Documentsdatabase remains unchanged from before the failover.
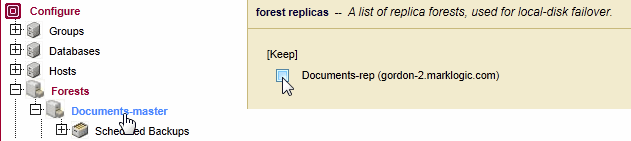
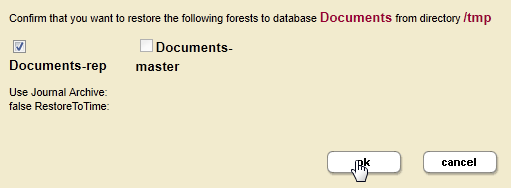
To back up the Documents-rep forest, do the following.
Both the backup and restore procedures must be done on the host that contains the Documents-rep forest.
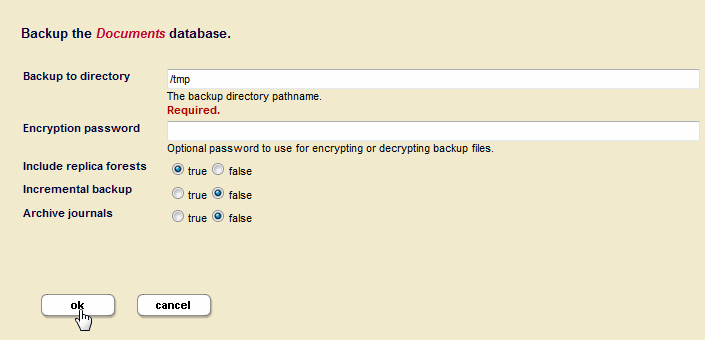
- On the host machine that contains the
Documents-repforest, backup theDocumentsdatabase. LeaveInclude Replica Forestsset totrue. - Select only the
Documents-repforest for backup. - Once the host containing the
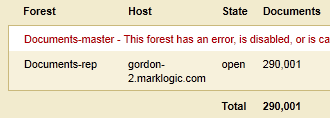
Documents-masterforest is restored, theDocuments-masterforest becomes the replica forest and receives replicated updates from theDocuments-repforest.
Before you can restore data from the Documents-rep forest that you backed up after the failover, you must reconfigure local disk failover from the Documents-rep forest to the Documents-master forest, so that the Documents-master forest is the new replica forest.
- In the configuration page
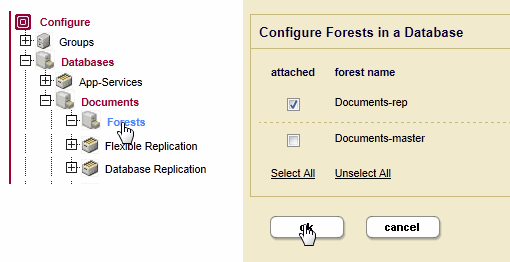
Documents-masterforest, disable replication toDocuments-repforest. - Navigate to the Forests configuration page for the
Documentsdatabase. Unattach theDocuments-masterforest and attach theDocuments-repforest. - Navigate to the configuration page for the
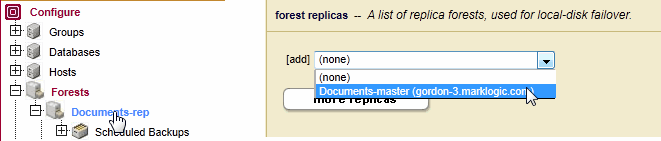
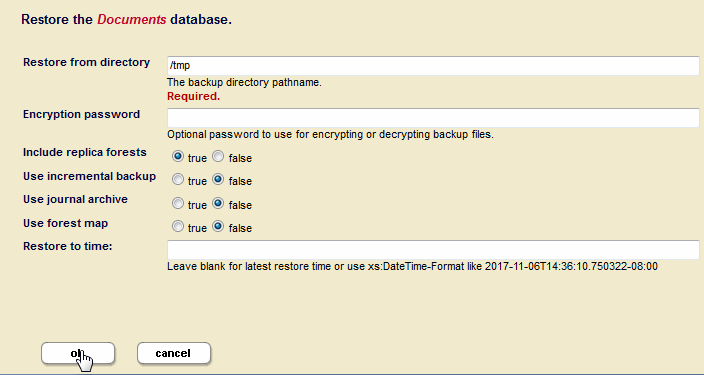
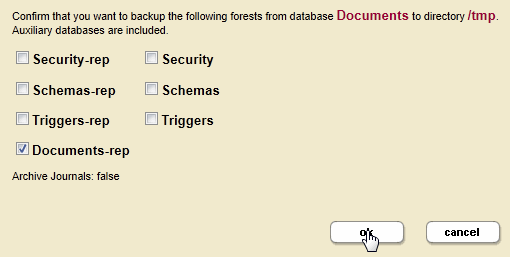
Documents-repforest and select theDocuments-masterforest for local-disk failover. - On the host containing the
Documents-repforest, confirm that the forest is in theopenstate and restore theDocumentsdatabase from the backup taken after the failover. - Make sure only the
Documents-repforest is selected for restoration. - Once the
Documents-repforest is restored, the updates are replicated to theDocuments-masterforest.