
MarkLogic 10 Product DocumentationScalability, Availability, and Failover Guide — Chapter 2
Getting Started with Distributed Deployments
MarkLogic supports large-scale high-performance architectures through multi-host distributed architectures. These architectures introduce additional complexity to both the planning and the deployment processes. This chapter introduces key concepts and terminology, outlines some alternative distribution strategies, and provides a high-level guide to configuring a cluster from scratch. The following topics are included:
- Terminology
- Fundamentals
- Advantages to Distributing
- Considerations for a Distributed System
- Configuring a Cluster
Terminology
It is important to understand the following terminology when considering a distributed implementation of MarkLogic Server:
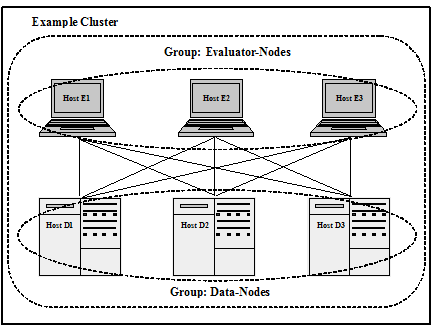
The following diagram illustrates how the concepts of clusters, hosts and groups are implemented in an example multi-host distributed architecture. The diagram shows a single cluster involving six hosts that are segmented into two groups:
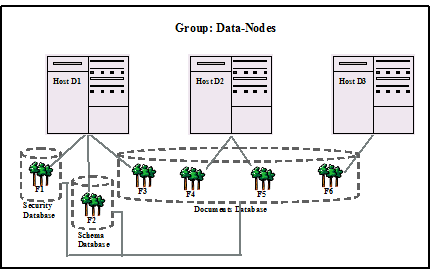
This second diagram shows how a single database called Documents could comprise four forests spread across the three hosts in the group Data-Nodes from the above diagram. The diagram also illustrates two internal databases maintained by the system for administrative usage:
Fundamentals
With the key terminology introduced, here is a short list of fundamentals to keep in mind while considering any multi-host deployment:
- All hosts in a cluster must run on the same platform.
Because MarkLogic Server takes advantage of platform-specific optimizations, it is not possible to mix and match platforms in a single cluster. This means that you will need to consider the pros and cons of different CPU architectures and operating systems across all hosts in your cluster when planning a multi-host deployment.
- Backups are not portable across platforms.
Not only must clusters be platform homogeneous, the internal data formats used by forests are platform-specific. Consequently, forests and forest backups are not portable across platforms. To move database or forest content from a MarkLogic Server implementation running on one platform to an implementation running on another platform, the database must be unloaded from the first system and loaded from scratch into the second database.
- All hosts in a cluster run identical software.
Even though each host in a cluster can be configured to perform a different task, the full MarkLogic Server software runs on each host. Consequently, software installation is identical across the nodes. However, hosts can be reconfigured rapidly--on an individual or cluster-wide basis--to perform whatever role is required of them. Of course, it is quite possible that different hardware configurations will be used for different hosts in the cluster, depending on the roles they are expected to play.
- Front-end query distribution is the responsibility of external infrastructure.
Multi-host deployments may incorporate multiple hosts running the same HTTP, WebDAV, or XDBC server applications, allowing queries to be distributed between those hosts for improved performance. MarkLogic Server transparently manages the distribution of content storage across forests within databases and the distribution of query execution across the hosts managing those forests. However, MarkLogic Server does not manage the distribution of queries across front-end hosts configured with equivalent HTTP, WebDAV, or XDBC server applications. The multi-host deployment relies on surrounding infrastructure for this load-balancing task.
- There is no master host in the cluster.
Many distributed architectures rely on a single designated master to direct and manage the operations of the cluster. In MarkLogic's distributed architecture, all hosts are considered equal, regardless of the roles for which they are configured. Consequently, there is no designated master in the cluster. However, there are one or more bootstrap hosts in a cluster that handle the initial connection between clusters.
- Administration can be carried out through any host offering appropriate services.
With no designated master in the cluster, administrative operations can be conducted on any cluster host configured to offer browser-based administrative operations or to accept XQuery-based administrative directives.
- Each forest is assigned to a single host.
All queries that need to check for content stored in that forest or retrieve content from that forest will be routed to that host for processing. If you are using local-disk failover, you can replicate a forest across multiple hosts (for details, see High Availability of Data Nodes With Failover).
Advantages to Distributing
A single MarkLogic Server architecture can constrain its scalability and performance in several ways:
- Query capacity is constrained by the number of CPUs that can be put to work processing queries simultaneously.
- Content volume can be constrained both by available address space and by the amount of memory installed in the server.
- Data access rates across multiple queries can be gated by the limited I/O path(s) inherent in single server architectures.
The MarkLogic distributed architecture has been designed specifically to address these issues. Distributed deployments can be used to support scalability and performance across multiple dimensions:
- Large volumes of content can be supported by increasing the number of hosts hosting forests.
- High data access rates can be supported by distributing the storage I/O requirements across more hosts.
- Large query volumes can be supported by increasing the number of hosts performing query evaluation.
In addition, the MarkLogic distributed architecture enables significantly more cost-effective implementations. MarkLogic allows data centers to distribute workload across a number of less-expensive entry-level servers or bladed infrastructures rather than requiring an investment in large expensive SMP systems.
For data centers with existing investments in SMP architectures, MarkLogic can still make effective use of those platforms.
Considerations for a Distributed System
Just as there are different reasons to deploy a distributed architecture, there are different issues to consider in determining a distribution strategy. Each strategy provides certain benefits and involves certain other compromises. In order to determine how best to deploy MarkLogic Server to meet your requirements, you should obtain assistance from MarkLogic's professional services group.
This section includes the following topics:
Hosts with Distinct Roles
Distributed deployments of MarkLogic Server can be configured using hosts which all play similar roles or hosts which play distinct roles, as illustrated below.
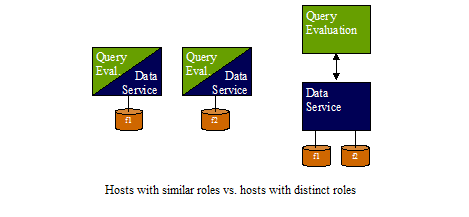
A first-cut approach to small-scale distribution will have a number of hosts, each providing query evaluation and data service capability. This model can work well in static environments, and when the anticipated loads for each role map well.
In more dynamic environments, when the scale of the environment relative to individual host capacity is large, or when the anticipated scales of the query evaluation and data service loads differ markedly, the recommended approach is to partition the hosts into different roles. This architecture makes it easier to scale role-based capacity independently, and can also have some configuration advantages when different services operating at different scales are being offered out of the same cluster.
Scale of System
MarkLogic Server can be deployed on a small number of relatively larger-scale systems, or a larger number of relatively small-scale systems. Data center platform and system standards will be the primary driver for this architecture decision.
There is no requirement that all systems in a cluster be of the same scale. In fact, as outlined below, there are potential tuning advantages to be obtained from customizing systems within the cluster based on the role played by the hosts operating on that system.
Hardware Configuration
While MarkLogic Server requires that all hosts in a cluster run on the same platform, the systems for each host can be configured to optimize performance for that host's particular function.
In deployments architected following a distinct role strategy, it is to be expected that the data service nodes would be configured differently from the query evaluation nodes. The configuration differences will begin with storage connectivity, but will likely extend to memory configuration and possibly to processor count.
Storage Architecture
In addition to the alternatives outlined above, the underlying storage architecture can have a significant impact on scalability and performance.
Storage that is locally attached to each host offering data service can be cost- and performance-effective, but difficult to manage from a data center viewpoint. Centralized storage options include both NAS (network attached storage) and SAN (storage area network) approaches, with their own distinct trade-offs. Consult your MarkLogic professional services consultant for detailed deployment architecture advice.
Configuring a Cluster
When first configuring and deploying a cluster, the best place to start is with the overall architecture and distribution strategy. With the right strategy in hand, you can rapidly develop the actual configuration parameter sets that you will need. This section includes the following topics:
Building a Cluster from Scratch
There are four key stages to build a cluster from scratch:
- Installing the initial host in the cluster
- Configuring the initial host with the groups and databases that you will be using in the cluster
- Filling out the cluster by installing the additional hosts and adding them to the cluster
- Configuring the forest layout within the cluster.
The purpose of this process guide is to outline the overall workflow involved in setting up a cluster. For detailed explanations of each step below, see the Installation Guide. The following are the steps to building a cluster:
- Installing the Initial Host
- Configuring the Initial Host
- Filling Out the Cluster
- Configuring Forest Layout
Installing the Initial Host
To install the initial host in the cluster:
- Install MarkLogic on one of the systems that will act as a host in the cluster. Follow the directions outlined in the section Installing MarkLogic Server in the Installation Guide.
The system on which you install the first host of the cluster will be the system on which the cluster's default Security and Schema databases will reside. Consequently, do not choose a system on whose role is solely a query evaluator.
If you are installing MarkLogic 9.0-4 or later, you may have to install MarkLogic Converters package separately. For more details, see MarkLogic Converters Installation Changes Starting at Release 9.0-4 in the Installation Guide.
- Start the server as outlined in the section Starting MarkLogic Server in the Installation Guide.
- Enter a license key, as described in Entering a License Key in the Installation Guide.
- Configure the host by following the steps outlined in the section Configuring a Single Host or the First Host in a Cluster in the Installation Guide.
- Configure an initial administrative user in response to the Security Setup screen.
Once the Admin Interface displays, you have completed the first stage in the process.
Configuring the Initial Host
To configure the initial host that you will be using in the system:
- Access the Admin Interface through port 8001 on the initial host.
- Use the Admin Interface to configure each of the databases that you will use in the cluster.
Configuring Databases at this time will simplify the next step of configuring groups.
Because the cluster does not yet include all of its hosts, you will not be able to configure Forests at this time. Set up the databases without any forests.
- Use the Admin Interface to configure each of the groups that you will use in the cluster.
Configuring groups at this time will accelerate the process of deploying the cluster.
Filling Out the Cluster
To fill out the cluster by installing the additional hosts and adding them to the cluster, repeat the following steps for each system that will be a host in the cluster:
- Install MarkLogic on the system. Follow the directions outlined in the section Installing MarkLogic Server in the Installation Guide.
If you are installing MarkLogic 9.0-4 or later, you may have to install MarkLogic Converters package separately. For more details, see MarkLogic Converters Installation Changes Starting at Release 9.0-4 in the Installation Guide.
- Start the server as outlined in the section Starting MarkLogic Server in the Installation Guide.
- Join the cluster as outlined in the section Configuring an Additional Host in a Cluster in the Installation Guide.
Refer to your distribution strategy and configuration plan to determine the Group to which this host should belong.
Once the Admin Interface displays, you have added this new host to the cluster. Repeat these steps for each host you want to add.
Configuring Forest Layout
To configure forest layout and complete database configuration across the cluster:
- Access the Admin Interface through port 8001 on any of the hosts you have configured in a group that offers the Admin Interface.
- Use the Admin Interface to configure forests throughout the cluster.
- Use the Admin Interface to complete database configuration by attaching forests to the databases.
- Use the Admin Interface to complete any other required configuration activities.
At this point, your cluster should be ready to load content and evaluate queries. See the Administrator's Guide for more detailed information on any of the configuration steps outlined above.
Increasing the Size of an Existing Cluster
Adding a new host to an existing cluster is a simple task, outlined in the section Configuring an Additional Host in a Cluster in the Installation Guide. Once the new host has been added, you may need to reconfigure how hosts in your cluster are used to redistribute workload. See the Administrator's Guide for the appropriate procedures.