
MarkLogic 10 Product DocumentationScalability, Availability, and Failover Guide — Chapter 5
High Availability of Data Nodes With Failover
MarkLogic provides support for two varieties of failover at the forest level: local-disk failover and shared-disk failover. Local-disk failover allows you to specify a forest on another host to serve as a replica forest which will take over in the event of the forest's host going offline. Shared-disk failover allows you to specify alternate instances of MarkLogic Server to host forests in the event of a forest's primary host going offline. Both varieties of failover provide a high-availability solution for data nodes. This chapter describes failover, and includes the following sections:
- Problems Failover Addresses
- Two Types of Failover
- How Failover Works
- Requirements for Local-Disk Failover
- Requirements for Shared-Disk Failover
- Failover Host Must Be Ready to Take Over
- Scenarios that Cause a Forest to Fail Over
- Architecting a Failover Solution
For details about creating and managing forests and databases, see the Administrator's Guide. For details about configuring failover, see Configuring Local-Disk Failover for a Forest and Configuring Shared-Disk Failover for a Forest.
Problems Failover Addresses
Failover for MarkLogic Server provides high availability for data nodes in the event of a data node or forest-level failure. Data node failures can include operating system crashes, MarkLogic Server restarts, power failures, or persistent system failures (hardware failures, for example). A forest-level failure is any disk I/O or other failure that results in an error state on the forest. With failover enabled and configured, a forest can go down and the MarkLogic Server cluster automatically and gracefully recovers from the outage, continuing to process queries without any immediate action needed by an administrator.
In MarkLogic Server, if a forest becomes unavailable (for example, because of a hardware or power failure on the host managing the forest), then the database to which the forest is attached becomes unavailable for query operations. Without failover, such a failure requires an administrator to either reconfigure the forest to another host or to remove the forest from the configuration. With failover, you can configure the forest to automatically switch to a different host.
This unattended kind of recovery can make the difference between eliminating or greatly reducing down times and suffering prolonged and stressful down times. Sometimes, you can create administrative procedures to achieve similar goals, but these types of procedures are error prone, and can be risky if there are transactions updating content on the system.
Failover is designed to handle operating system and hardware failures on data nodes, which can take some time to repair. For example, if the operating system crashes, it can take many minutes or longer for the system to come back up; it can often take much longer if disk recovery is needed upon startup or if some part of the system does not come up correctly on restart. If MarkLogic Server itself suffers a failure or restarts for some reason, it typically restarts very quickly (often, it takes less than a few seconds). Because this restarting is so quick, failover should not occur during such events, and the data node will become available again on its own.
Failover provides both high levels of availability and data integrity in the event of a data node or forest failure. Failover maintains data and transactional integrity during failure events. For example, it allows a single host to attempt any writing or recovery operations to a given forest at any particular time.
Two Types of Failover
Databases in a MarkLogic cluster have forests that hold their content, and each forest is served by a single host in the cluster. To guard against a host going down and being disconnected from the cluster or forest-level failures, each forest allows you to set up one of two types of failover:
Both types of failover are controlled and configured at the forest level. This section describes the two types of failover and highlights the advantages of each.
Local-Disk Failover
Local-disk failover creates one or more replica forests for each failover forest. The replicas contain the exact same data as the primary forest, and are kept up to date transactionally as updates to the forest occur. Each replica forest should be on a different host from the primary forest so that, in the event of the host for the primary forest going down, another host with a copy of the primary forest's data can take over.
Each forest has its own host, and each host has disk space allocated for the forest. The primary forest is the forest that is attached to the database. Any replica forests configured for the primary forest have their own local disk. As updates happen to the database, the primary forest is updated as well as each configured replica forest.
The following figure shows three hosts that each have a forest configured. Host 1 has the primary forest (F1), and Host 2 has a replica forest Replica. The Replica forest is a stored disk local to the respective host. As updates are committed to the forest F1 (via transactions against the database to which F1 is attached), they are simultaneously committed to the Replica forest.
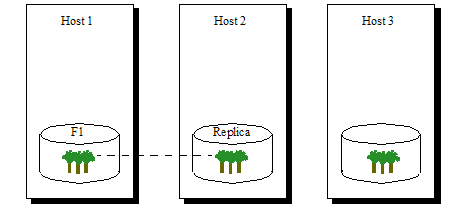
In the event that Host 1 goes down or an I/O error on the F1 forest, the MarkLogic Server cluster will wait until the specified timeout and then it will automatically remove the F1 forest from the cluster. Because all of the forests in a database must be available for queries to run, the database is unavailable at this time. At this point, the system fails over the forest to the first available replica forest, and the Replica forest is automatically attached to the database. The database once again becomes available. If the failed forest comes back online, it will resume as a replica. If you want that forest to become the primary forest again, you must restart the forest that is currently the primary forest, as described in Reverting a Failed Over Forest Back to the Primary Host.
While each replica forest maintains all of the committed documents that are in the primary forest, it is not an exact byte-for-byte copy of the forest. It is a forest in its own right, and will merge when it needs to merge, which might not be at the same times that the primary forest merges. So assuming the replica forest is replicating normally (sync replicating, as described in Forest Mount States), it will contain the same committed documents as the primary forest. The host that services each replica forest must meet the needed disk space requirements and be sized appropriately so that merges can occur as needed on the forest.
Shared-Disk Failover
Shared-disk failover uses a clustered filesystem to store the forest data. The clustered filesystem must be available with the same path on each host that is configured as a failover host. In the event of a host that is assigned a shared-disk failover forest going down, another host can take over the assignment of that forest. For a list of supported clustered filesystems, see Either a Supported NFS or a Supported Clustered Filesystem Required, Available to All Failover Hosts.
After the cluster has determined that a host is down and disconnected it from the cluster, if failover is enabled and configured for that forest, then one of the failover hosts will attempt to mount the forest locally. The host that attempts to mount the forest is determined based on the list of failover hosts in the forest configuration, and the host that is highest on the list will be the first to attempt to mount the forest. If that host is not available, then the next one in the list will attempt to mount the forest, and so on until the forest is either mounted or there is no failover hosts available. After the forest is mounted locally, the other hosts in the cluster will mount it remotely.
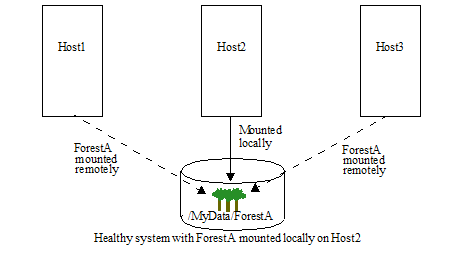
The following figure shows a healthy system with the forest data in the file ForestA mounted locally on Host2.
The following figure shows the same system after Host2 has been disconnected from the cluster, and Host1 has taken over by mounting ForestA locally.
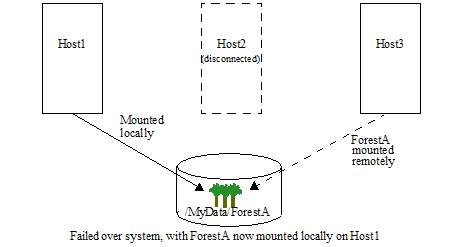
If the forest on Host2 comes back online, it will automatically connect to the cluster. However, Host1 will continue to host the primary forest until the forest is restarted. This avoids having the forest ping pong between hosts in the event that the primary host has a recurring problem that takes some time to solve. For details on mounting the forest on the original host after the host has reconnected to the cluster, see Reverting a Failed Over Forest Back to the Primary Host.
Choosing Between Local-Disk and Shared-Disk Failover
As with most administrative choices, there are advantages and disadvantages to each type of failover. When choosing between local-disk and shared-disk failover, consider the following advantages, disadvantages, and costs of each.
The following are some of the advantages of local-disk failover:
- There is no need for an expensive and complex clustered filesystem.
- If the primary forest fails, you failover to the replica forest.
- It keeps a usable copy of the forest in each replica forest.
- You can use commodity storage for the filesystem.
The following are some of the disadvantages of local-disk failover:
- Local-disk failover requires disk space for the primary forest as well as for each replica forest (including 1.5 times the forest size to accommodate for merges, as described in the MarkLogic Server requirements in the Installation Guide).
- Local-disk failover requires at least one replica forest per primary forest, so there will be more forests to create and manage.
- Because there are more forests to manage, there are more forests that you must monitor for system health.
- Each replica host requires the CPU capacity to update and merge the forest, even when the forest is not failed over.
The following are some of the advantages of shared-disk failover:
- There is only a single filesystem to manage (although it must be one of the filesystems described in Either a Supported NFS or a Supported Clustered Filesystem Required, Available to All Failover Hosts).
- It takes advantage of the high-availability features of a clustered filesystem.
- Can be used with forest data directories mounted with Network File System (NFS).
The following are some of the disadvantages of shared-disk failover:
- Clustered filesystems can be complex and expensive.
- Shared disk failover does not keep multiple copies of the forest around on different filesystems (although clustered filesystems tend to have redundancy built in). This means failover will only work if the host that has the forest mounted locally fails or if the XDQP communication between the host and disk is interrupted. Unlike local-disk failover, if the shared forest fails due to a disk failure, there is no backup forest.
- Forest that are configured for shared-disk failover always perform their updates using strict journaling mode, which explicitly performs a file synchronization after each commit. While strict journaling is safer because it protects against the computer unexpectedly going down and not just against MarkLogic Server unexpectedly going down, it makes updates slower. For details on strict versus fast journaling, see Understanding the Locking and Journaling Database Settings for Bulk Loads in the Loading Content Into MarkLogic Server Guide.
How Failover Works
This section describes the mechanism for how MarkLogic Server automatically fails an unresponsive host over to another computer, keeping replica forests on other hosts up to date (for local-disk failover) and keeping any forests hosted by the downed host available (for shared-disk failover). This section includes the following parts:
- Failover at the Forest Level
- Enabling Failover
- Forest Mount States
- Cluster Determines If a Host is Down
- Different Host Takes Over the Forest
The basic mechanism used for automatic failover is the same for local-disk failover (keep distinct replicated forests on different hosts) and for shared-disk failover (keep a single physical forest on a clustered filesystem available to multiple hosts). For details on the two types of failover, see Local-Disk Failover and Shared-Disk Failover.
Failover at the Forest Level
D-node failover in MarkLogic Server is at the forest level, not at the database level. Each forest must have one or more failover hosts configured (for shared-disk failover) or one or more replica forests configured (for local-disk failover) before it can fail over to another host. You can configure up to as many failover hosts as the number of other hosts in the cluster, or up to as many replica forests as available forests in the cluster. For example, if you have 10 hosts in a cluster, you can configure between 1 and 9 failover hosts for a single forest.
Enabling Failover
You must enable failover before you can use it. Enabling failover requires failover enabled at the group level in the Admin Interface and failover to be enabled for the individual forest. The group-level parameter allows you to easily disable failover for an entire group (or for an entire cluster), allowing convenient failover administration on complex systems. For details on configuring failover, see Configuring Shared-Disk Failover for a Forest.
Forest Mount States
When any instance of MarkLogic Server starts up (or when a forest is restarted), each host tries to mount all of the forests configured for the entire cluster. A forest is mounted if MarkLogic Server has read the forest information from the forest. If the forest is hosted on the local instance of MarkLogic Server, then the forest is mounted locally on the host. If the forest is hosted on a different instance of MarkLogic Server (that is, on a different host), then the forest is mounted remotely on that host.
This local and remote mounting allows you to query both local and remote forests from any host in the cluster. Forest mounting occurs automatically on system startup or forest startup, and each time a forest is mounted, a message is logged in the ErrorLog.txt log file indicating if the forest is mounted remotely or mounted locally on that host. For shared-disk failover, the host that currently is servicing a forest is the one that has it mounted locally. The state of a forest that is mounted locally is open.
For local-disk failover, each forest can be in the following states:
- sync replicating: The forest is a stand-by replica and it is synchronously updated with the primary forest (that is, the one that is in the open state).
- async replicating: The forest is catching up to the primary forest, and it does this asynchronously. This typically occurs if you add a new replica forest to a forest that already has content in it. After it catches up, it will change to the sync replicating state.
- wait replicating: The forest is waiting to get into one of the other replicating states. Typically, this happens directly after forest or host startup or after a failover occurs. After it starts replicating, it will change to either the sync replicating or the async replicating state.
Both shared-disk and local-disk failover can have forests in error states:
Cluster Determines If a Host is Down
Hosts in a MarkLogic Server cluster communicate their status periodically with each other via a heartbeat mechanism (for details, see Communication Between Nodes). This communication occurs whether failover is enabled or not. One of the purposes for this communication is to determine if any host has gone down.
The cluster uses a voting algorithm to determine if a host is down. The voting algorithm gets its data from each host's view of the cluster. If there is a quorum of hosts, each of whose view of the cluster is such that it believes a particular host is down, then the other hosts in the cluster treat that host as if it is down and try to go on without it, disconnecting it from the cluster. If the disconnected host has no forests mounted locally, then everything else in the cluster can continue as normal; only requests initiated against the disconnected host will fail.
If the disconnected host had any forests mounted locally, however, then those forests will need to be either mounted to another host or detached from the database before any requests against that database can complete. If failover is not enabled and configured, then an administrator must perform those tasks. If failover is enabled and configured for a forest, however, then another host (a failover host) will attempt to mount that forest automatically.
Different Host Takes Over the Forest
After the cluster has determined that a host is down and disconnected it from the cluster, if failover is enabled and configured for that forest, then one of the failover hosts will attempt to take over hosting that forest. If you are using local-disk failover, then the replica host will take over with its copy of the forest, making it the primary forest. If you are using shared-disk failover, then the first configured failover host will attempt to mount the forest locally.
For more details on how the two types of failover work, see Local-Disk Failover and Shared-Disk Failover.
Requirements for Local-Disk Failover
This section describes the requirements for setting up local-disk failover in MarkLogic Server, and includes the following requirements:
Enterprise Cluster Required
Because local-disk failover requires another host available to take over the failed host, you need a cluster configured in order to set up failover. Additionally, a minimum of three hosts are required for the cluster. Three or more hosts ensure reliable voting to determine if a host is offline, which in turn determines if forests need to be failed over.
Each Host Requires Sufficient Disk Space for Its Forests
To provide for merges, each host requires the disk space necessary to manage any forests assigned to the host, including replica forests. Each forest needs to be on a filesystem that is 1.5 times the size of the forest (using the default 32 GB max merge size setting). For details on disk space requirements, see Memory, Disk Space, and Swap Space Requirements in the Installation Guide. The disk space is important because, if a forest does not have sufficient disk space, you will not be able to perform any updates to that forest and it will go into an error state. You cannot fail over to a replica forest that is in an error state. To correct an error state caused by insufficient disk space, you must either free space on the device or add space to the device, and then restart the forest.
Requirements for Shared-Disk Failover
This section describes the requirements for setting up shared-disk failover in MarkLogic Server, and includes the following requirements:
- Enterprise Cluster Required
- Public Forest Required
- Either a Supported NFS or a Supported Clustered Filesystem Required, Available to All Failover Hosts
Enterprise Cluster Required
Because failover requires a host available to take over the forest from the failed host, you need a cluster configured in order to set up failover. Additionally, a minimum of three hosts are required for the cluster. Three or more hosts ensure reliable voting to determine if a host is offline, which in turn determines if forests need to be failed over.
Public Forest Required
To enable shared-disk failover for a forest, the forest data directory must be accessible from the primary host and the failover host(s), and it must have the same directory path on each host. Such a forest is known as a public forest, where the data can be accessed by multiple hosts. It cannot be in the default data directory. If the forest is stored in the default data directory for MarkLogic Server (for example, /var/opt/MarkLogic or c:/Program Files/MarkLogic), it is known as a private forest, and it cannot be used with failover; you first move that forest data to a public directory (for a procedure, see Configuring the Security and Auxiliary Databases to Use Failover Forests) before it can be configured as a failover forest.
Either a Supported NFS or a Supported Clustered Filesystem Required, Available to All Failover Hosts
In addition to a public forest directory (described above), shared-disk failover requires the forest to have its data directory reside on either a supported clustered filesystem (CFS) or on a supported implementation of NFS. The CFS or NFS must be accessible from the primary host and the failover host(s), and it must have the same directory path on each host.
Shared-disk failover in MarkLogic Server is supported on the following CFSs:
Shared-disk failover is supported on the following NFS (NAS) implementation:
Shared-disk failover is supported for the following HDFS implementations:
Failover Host Must Be Ready to Take Over
When you configure a host as a failover host, it should be ready to take over the job of hosting the forest. A failover host must be connected to the cluster in order for a forest to fail over to it, and it must be online and available at the time of host failure. Also, the machine should be capable of handling the load of hosting the forest or forests that fail over to it, at least temporarily.
If the failover host already hosts other forests, this means that the machine needs to be able to handle the additional load that may be placed on it in the event of a failover. For example, if a host manages two forests and is configured as a failover host for a third, the machine should have sufficient memory and CPU resources to manage the third forest, at least temporarily. In more complex deployments, you should consider the potential load induced by the failure of multiple hosts. In some cases, the cause of system failure can impact multiple hosts, and failover system can themselves fail as a result of such a multi-host concurrent or sequential failure not being anticipated during original system architecture.
Scenarios that Cause a Forest to Fail Over
In general, failover provides the ability for a forest to change hosts in the event that its host becomes unresponsive for some reason. This section lists the scenarios in which a forest will fail over to another host, assuming the forest and the cluster are configured to failover. For more information about how failover works, see How Failover Works. For information about the forest mount states, see Forest Mount States.
A forest will fail over in the following scenarios:
- The host that currently has the forest mounted locally is shut down. After the host is shut down, the other hosts in the MarkLogic Server cluster will stop getting heartbeats from the shut down host, and will disconnect it from the cluster. This causes one of the other configured failover hosts to mount the forest locally.
- The host that currently has the forest mounted locally becomes unresponsive to the rest of the cluster. The other hosts determine a host's responsiveness based on heartbeats it receives (or heartbeats it does not receive) from that host. When a quorum of the cluster determines a host is unresponsive (that is, they have not received a heartbeat for the
host timeout), it disconnects from the cluster. If the disconnected host is actually still alive and still has the forest mounted locally, then the forest will not fail over; it will only fail over after the host that has it mounted locally stops accessing the forest (to prevent multiple hosts writing to the forest at the same time). For more details on the host timeout parameters, see XDQP Timeout, Host Timeout, and Host Initial Timeout Parameters. - Restarting the forest. When you click the
restartbutton on the Forest Status page in the Admin Interface, the forest is unmounted by all hosts. It then is automatically mounted by the primary host (or if the primary host is unavailable, by a failover host).
Architecting a Failover Solution
This section describes things to think about when designing an architecture for your failover solution, and includes the following parts:
- Local-Disk Failover Architectures
- Shared-Disk Failover Architectures
- Deciding Which Type of Failover to Use
Local-Disk Failover Architectures
A simple deployment for local-disk failover is to have one replica forest for each primary forest in the database. The hosts that have the replica forests must be sized appropriately in terms of CPU, memory, and disk space to perform all of the duties of hosting the forest (for example, updates and merges). If the replica forest hosts had the same number of forests as the primary forest hosts, then the replica hosts would need the same configuration as the primary hosts.
You might decide to use slower and/or less expensive machines to host the replica systems. This would likely mean that performance of the application might suffer some during the failed over period, but if that is acceptable to your application, and if your operations team is set up to restore the failed system in a timely fashion, then that might be a tradeoff worth considering.
Whatever tradeoffs you decide are acceptable, you must make sure that the replica hosts can at least handle the load of hosting the forest in the event of a host fails over. It might be acceptable to have a period of somewhat decreased performance after a failover, but it likely is not acceptable for the system to be inadequate for the load.
Shared-Disk Failover Architectures
The simplest conceptual deployment for shared-disk failover is to have a secondary shadow host in the cluster with identical hardware configuration to your target d-node. If the d-node in question fails, the shadow host can take over for it and provide forest services at exactly the same levels of performance as you had previously.
Of course, this architecture is overly simplistic for many deployments. For instance, if you had multiple d-nodes that you wanted to be able to fail over, this approach would require multiple shadow hosts sitting around waiting for failure. Alternatively, with shared-disk failover, the same shadow host could be designated as the failover target for all of the d-nodes, in which case should two d-nodes fail in the same time period, the shadow host could easily be overwhelmed.
The simplest model also fails to take advantage of the latent performance and capability of the shadow host during periods of normal operations. Given that normalcy is what one strives for in operations, this seems like a lost opportunity to deliver additional levels of performance during normal operations.
Consider a three-host cluster deployed as described in the diagrams Shared-Disk Failover. One host might be used for e-node services, one for d-node services, and one acts as the spare awaiting d-node failure. These three hosts might be used more profitably if the d-node services were divided between the d-node and the spare--each host hosting half of the forests in your databases. In this configuration, each of the two d-nodes could act as the failover host for forests mounted locally on the other host. Consequently, failover can happen in either direction. During periods of normal operations, the cluster has twice the resources available for d-node services.
In a larger cluster, one can consider configuring a series of forests and hosts in an n-way format, so that if a single host fails, its forests are all failed over to different failover hosts, thereby maximally distributing the incremental load encountered by any one host, and minimizing any discernible change in performance felt by the end user. So long as the d-node hosts have sufficient resources to be able to support the additional forest load, such a configuration may be able to absorb the failure of multiple hosts in the cluster, and can continue to service queries at levels that meet or exceed your committed service levels. Alternatively, if you chose not to overspec your hardware with respect to your service level commitments during periods of normal operations, such a configuration may be able to continue servicing queries at a (potentially significantly) degraded level of performance, depending on your system load.
Deciding Which Type of Failover to Use
When deciding how to implement your failover solution for your forests, you must first decide which type of failover to use: local-disk or shared-disk. Local-disk failover keeps a replica of the forest, so it provides redundancy as well as failover protection. Shared-disk failover allows you to manage fewer forests (because you do not have to create replicas) with the tradeoff of requiring a clustered filesystem to store the forest data. With local-disk failover, the hosts that manage the replica forest remain active as the forest gets updated. With shared-disk failover, the failover hosts do not have to do much work while they are standing by to be failed over to. You must analyze your own requirements and environment to choose the failover type that is right for your environment. For more details, see Choosing Between Local-Disk and Shared-Disk Failover.
Architecting a production environment for failover involves combining the functional support for failover available in MarkLogic Server with your operational procedures, your software license agreements (SLAs), the magnitude of system failure you need to be able to sustain, and your budget for maintaining excess system capacity. The MarkLogic Professional Services organization can help you identify trade-offs and make the appropriate decisions for what architecture makes sense for your needs.