Matches for cat:guide (cat:guide (cat:guide/rest-dev)) have been highlighted.


MarkLogic Server 11.0 Product DocumentationREST Application Developer's Guide — Chapter 4
Using and Configuring Query Features
This chapter covers the following topics:
- Query Feature Overview
- Querying Documents and Metadata
- Querying Lexicons and Range Indexes
- Using Query By Example to Prototype a Query
- Analyzing Lexicons and Range Indexes With Aggregate Functions
- Specifying Dynamic Query Options with Combined Query
- Querying Triples
- Retrieving Rows
- Searching Values Metadata Fields
- Configuring Query Options
- Using Namespace Bindings
- Generating Search Facets
- Paginating Results
- Customizing Search Results
- Generating Search Term Completion Suggestions
Query Feature Overview
The REST Client API includes several services for querying content in a MarkLogic Server database. The usage model for the query features is:
- Optionally, use the
/config/queryservice to install a set of named query options to apply to future queries. The name is used to apply the options to subsequent queries. For details, see Configuring Query Options. You can also specify options at query time for requests that accept a combined query; for details see Specifying Dynamic Query Options with Combined Query. - Optionally, use the
/config/namespacesservice to install namespace bindings for namespace aliases you will use in queries. For details, see Using Namespace Bindings. - Use
/search,/qbe, or/valuesto perform a query.- Depending on the service, the query might be expressed using a request parameter or in the request body. For details, see the reference documentation for each method.
- Apply options by specifying the name of previously installed query options in the
optionsrequest parameter and/or providing dynamic query options in the request body using a combined query. For details, see Adding Query Options to a Request. - Specify the content type (XML or JSON) of the query results using the format request parameter or Accept headers.
- Query results of the requested content type are returned in the response body.
By default, a search operation returns search response data that summarizes the matches and can contain snippets of matching content. This chapter focuses on such operations. However, you can also use /search and /qbe to retrieve the matching documents or metadata instead of a search response; for details, see Reading and Writing Multiple Documents.
This chapter also covers lexicon and range-index query and analysis, and the configuration of persistent query options. The /search and /values services use query options to control and configure queries and search results. For details, see Appendix: Query Options Reference in the Search Developer's Guide.
The following table gives a brief summary of each query related service.
| Service | Description |
|---|---|
/search |
Use string, structured, cts and combined queries to search documents and metadata. Queries may be expressed in XML or JSON. For details, see Querying Documents and Metadata. |
| /qbe | Use Query By Example (QBE) for rapid prototyping of XML and JSON document searches. Queries using QBE syntax may be expressed in XML or JSON. For details, see Using Query By Example to Prototype a Query. |
/values |
Query lexicon and range index values and value co-occurrences; analyze lexicon and range index values and value-co-occurrences with builtin and user-defined aggregate functions. For details, see Querying Lexicons and Range Indexes. |
| /rows | Extract relational and semantic data as rows, using an Optic API plan. For details, see Retrieving Rows. |
/config/query |
Use XML or JSON to configure persistent query options for use with services such as /search, /qbe, and /values. For details, see Configuring Query Options. |
/config/namespaces |
NOTE: This service is deprecated. Use the REST Management API instead. Configure bindings between namespace prefixes and namespace URIs so you can use QNames in query contexts where it is not possible to dynamically specify a namespace. For details, see Using Namespace Bindings. |
Querying Documents and Metadata
This section describes how to use the /search service to search documents and metadata.
- Constraining a Query by Collection or Directory
- Searching With String Queries
- Searching With Structured Queries
- Searching With cts:query
- Debugging /search Queries With Logging
You can use /search to retrieve a search response, matching documents and metadata, or both. The examples in this section only return a search response. To retrieve whole documents and/or their metadata, see Reading Multiple Documents Matching a Query.
If you need to retrieve search results across multiple requests that reflect the state of the database at a fixed point in time, see Performing Point-in-Time Operations.
Constraining a Query by Collection or Directory
Use the collection and directory request parameters to the /search service to limit search results to matches in specific collections or database directories.
You can specify multiple collections or directories. For example, the following URL finds documents containing julius in the tragedy and comedy collections:
http://localhost:8000/LATEST/search?q=julius&collection=tragedy&collection=comedy
You can use collection and directory constraints together. For example, by adding a directory to the above search, you can further limit matches to documents in the /shakespeare/plays directory:
http://localhost:8000/LATEST/search?q=julius&collection=tragedy&collection=comedy&directory=/shakespeare/plays
For details about collections and directories, see Collections in the Search Developer's Guide and Directories in the Application Developer's Guide.
Searching With String Queries
The MarkLogic Server Search API default search grammar allows you to quickly construct simple searches such as cat, cat AND dog, or cat NEAR dog. You can also customize the search grammar. For details, see Search Grammar in the Search Developer's Guide.
To search for matches to a simple string query, send a GET or POST request to the /search service with a URL of the form:
http://host:port/version/search?q=query_string
Where query_string is a string conforming to the search grammar.
On a GET request, you can include both a string query and a structured query or cts:query in the same request using the structuredQuery request parameter.
On a POST request, put the structured or cts:query in the POST body, either standalone or as part of a combined query. The queries are AND'd together. For more information, see Searching With Structured Queries, Searching With cts:query, and Specifying Dynamic Query Options with Combined Query.
You can request search results in XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
For details on the structure of search results, see Appendix: Query Options Reference in the Search Developer's Guide.
For a complete list of parameters available with the /search service, see GET:/v1/search in the REST Resources API.
Searching With Structured Queries
Structured queries enable you to create complex queries, represented in XML or JSON. For details, see Searching Using Structured Queries in the Search Developer's Guide.
To search using a structured query, send a GET or POST request to the /search service. To pass the structured query as a request parameter, send a GET request with a URL of the form:
http://host:port/version/search?structuredQuery=query
Where query is an XML or JSON representation of a structured query.
To pass a structured query in the request body, send a POST request of the following form and place a structured or combined query in the POST body. Set the Content-type header appropriately:
http://host:port/version/search
If the request also includes a string query, the string query and structured query are AND'd together. For details, see Searching With String Queries and Specifying Dynamic Query Options with Combined Query.
You can request search results in XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
For a complete list of parameters available with the /search service, see GET:/v1/search or POST:/v1/search in the REST Resources API.
The following example combines a structured query equivalent to Yorick NEAR Horatio and a string query for knew, requesting search results in JSON. The effect is equivalent to searching for (Yorick NEAR Horatio) AND knew.
$ cat sq.xml
<search:query xmlns:search="http://marklogic.com/appservices/search">
<search:near-query>
<search:term-query>
<search:text>Yorick</search:text>
</search:term-query>
<search:term-query>
<search:text>Horatio</search:text>
</search:term-query>
</search:near-query>
</search:query>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@"./sq.xml" \
-H 'Content-type: application/xml' \
-H 'Accept: application/json' \
'http://localhost:8000/LATEST/search?q=knew'Searching With cts:query
In addition to querying the database with higher level search abstractions such as string query and structured query, you can also use a lower level cts:query, represented in XML or JSON. To learn more about cts:query, see Composing cts:query Expressions in the Search Developer's Guide.
To search using a cts:query, send a GET or POST request to the /search service. To pass the cts:query as a request parameter, send a GET request with a URL of the form:
http://host:port/version/search?structuredQuery=ctsquery
Where ctsquery is an XML or JSON representation of a cts:query.
To pass a cts:query in the request body, send a POST request of the following form and place the JSON or XML serialization of a cts:query in the POST body. Set the Content-type header appropriately.
http://host:port/version/search
For information on creating a serialized cts:query string in XML and JSON, see Serializations of cts:query Constructors in the Search Developer's Guide. Note that the JSON representation of a cts:query must have a ctsquery root JSON property:
{ "ctsquery": { serializedCtsQuery } }
If the request also includes a string query, the string query and cts:query are AND'd together. For details, see Searching With String Queries.
You can request search results in XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
For a complete list of parameters available with the /search service, see GET:/v1/search or POST:/v1/search in the REST Resources API.
The following example combines a cts:query equivalent to Yorick NEAR Horatio and a string query for knew, requesting search results in JSON. The effect is equivalent to searching for (Yorick NEAR Horatio) AND knew.
$ cat cts_near.xml
<cts:near-query distance="10" xmlns:cts="http://marklogic.com/cts">
<cts:word-query>
<cts:text xml:lang="en">Yorick</cts:text>
</cts:word-query>
<cts:word-query>
<cts:text xml:lang="en">Horatio</cts:text>
</cts:word-query>
</cts:near-query>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@"./cts_near.xml" \
-H 'Content-type: application/xml' \
-H 'Accept: application/json' \
'http://localhost:8000/LATEST/search?q=knew'The following query is the equivalent cts:near-query, expressed in JSON.
{"ctsquery":{ "nearQuery":{ "queries":[ {"wordQuery":{"text":["Yorick"], "options":["lang=en"]}}, {"wordQuery":{"text":["Horatio"], "options":["lang=en"]}} ], "distance":10 }} }
Debugging /search Queries With Logging
When you enable the debug REST API instance property and make queries using /search, query details are sent to the MarkLogic Server error log. Enable this logging by setting the debug property to true, as described in Configuring Instance Properties.
When you enable debug logging, requests to /search log the following information helpful in debugging queries:
- EFFECTIVE OPTIONS. These are the query options in effect for your query. If the request does not include an
optionsrequest parameter or a combined query, these are the default options. - CTS-QUERY. Your query, expressed as a
cts:queryobject. Acts:queryobject is the low level XML representation of any query expression. For details, see Understanding cts:query in the Search Developer's Guide. - SEARCH-QUERY. Your query, expressed as a
search:queryobject. This information is only included if your request includes a structured query. Asearch:queryis the XML representation of a structured query. For details, see Searching Using Structured Queries in the Search Developer's Guide.
Examining the logging output can help you understand how MarkLogic Server sees your query. In the following example, notice that a string query for Welles is really a cts:word-query for the text string Welles. With the addition of a structured query in the request body to limit the query to occurrences of Welles to documents that also include John when it occurs near Huston, the logging output includes a cts:query and a search:query that reflect the result of combining the string query and structured query.
- Enable debug logging for your REST API instance.
$ cat debug-on.xml <properties xmlns="http://marklogic.com/rest-api"> <debug>true</debug> </properties> $ curl --anyauth --user user:password -X PUT \ -d @./debug-on.xml -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/properties
- Issue a query to
/search.$ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/search?q="Welles" ...search matches returned
- View the debug output in the MarkLogic Server error log, located in MARKLOGIC_DIR
/Logs/ErrorLog.txt. There is nosearch:queryin the log because this is a simple string query. (The timestamp and Info: header on each log line have been elided).$ tail -15 /var/opt/MarkLogic/Logs/ErrorLog.txt ... Request environment: ... GET /v1/search?q=Douglas ... Rewritten to: /MarkLogic/rest-api/endpoints/search-list-query.xqy?q=Douglas ... ACCEPT */* ... PARAMS: ... q: (Welles) ... ... Endpoint Details: ... EFFECTIVE OPTIONS: ... <options xmlns="http://marklogic.com/appservices/search"> ... <search-option>unfiltered</search-option> ... <quality-weight>0</quality-weight> ... </options> ... CTS-QUERY: ... <cts:word-query qtextref="cts:text" xmlns:cts="http://marklogic.com/cts"> <cts:text>Welles</cts:text> </cts:word-query>
- Add a structured query to the search to constrain matches to documents that also contain John occurring near Huston.
$ cat ./structq.json {"query": {"near-query": {"queries":[ {"term-query":{"text":"John"}}, {"term-query":{"text":"Huston"}} ]} } } $ curl --anyauth --user user:password -X POST -d@./structq.json \ -H "Content-type: application/json" \ http://localhost:8000/LATEST/search?q=Welles ...search results returned - View the logging output again and notice the inclusion of a search:query section in the log. Also, notice that the
cts:queryand thesearch:queryrepresent the combined string and structured queries.... Request environment: ... POST /v1/search?q=Welles ... Rewritten to: /MarkLogic/rest-api/endpoints/search-list-query.xqy?q=Welles ... ACCEPT */* ... PARAMS: ... q: (Welles) ... ... Endpoint Details: ... EFFECTIVE OPTIONS: ... <options xmlns="http://marklogic.com/appservices/search"> ... <search-option>unfiltered</search-option> ... <quality-weight>0</quality-weight> ... </options> ... CTS-QUERY: ... cts:and-query( ( cts:word-query("Welles", ("lang=en"), 1), cts:near-query(( cts:word-query("John", ("lang=en"), 1), cts:word-query("Huston", ("lang=en"), 1)), 10, (), 1) ), () ) ... SEARCH-QUERY: ... <search:query xmlns:search="http://marklogic.com/appservices/search"> ... <search:qtext>Welles</search:qtext> ... <search:near-query> ... <search:term-query> ... <search:text>John</search:text> ... </search:term-query> ... <search:term-query> ... <search:text>Huston</search:text> ... </search:term-query> ... </search:near-query> ... </search:query>
Querying Lexicons and Range Indexes
The /values service supports the following operations:
- Query the values in a single lexicon or range index, or
- Find co-occurrences of values in multiple range indexes
- Analyze range index values or value co-occurrences using builtin or user-defined aggregate functions. For details, see Analyzing Lexicons and Range Indexes With Aggregate Functions.
For related search concepts, see Browsing With Lexicons in the Search Developer's Guide.
This section covers the following topics:
- Querying the Values in a Lexicon or Range Index
- Finding Value Co-Occurrences in Lexicons
- Using a Query to Constrain Results
- Identifying Lexicon and Range Index Values in Query Options
- Creating Indexes on JSON Properties
- Limiting the Number of Results
If you need to retrieve lexicon and range index data across multiple requests that reflect the state of the database at a fixed point in time, see Performing Point-in-Time Operations.
Querying the Values in a Lexicon or Range Index
Use the /values/{name} service to query the values in a lexicon or range index. Such queries must be supported by query options that include a <values/> element identifying the target lexicon or index; for details, see Defining Queryable Lexicon or Range Index Values.
To query the values in a lexicon or range index, use the /values/{name} service as follows:
- Install query options or define dynamic query options that include a
valuesoption naming the target lexicon or index. For details, see Adding Query Options to a Request. - Send a GET or POST request to the
/values/{name}service, where name is the name of avaluesdefinition in the query options from Step 1 or in the default query options. If you use persistent query options, include theoptionsparameter and replace options_name with the name under which the query options are installed.http://host:port/version/values/name?options=options_name
When constructing your request:
- Substitute a named
valuesspecification for name in the URL. This must be avaluesrange specification in the query options named by theoptionsparameter, in theoptionsportion of a combined query in the POST body, or in the default query options. - To use custom query options, specify them using the
optionsparameter and/or theoptionsportion of a combined query in the POST body. For details, see Identifying Lexicon and Range Index Values in Query Options and Adding Query Options to a Request. - To use the default query options, omit the
optionsparameter andoptionsportion of a combined query. The default query options should include a range specification matching name. - To constrain the analysis to values in certain fragments, specify a query using the
qand/orstructuredQueryparameters, or a structured or combined query in the POST body. For details, see Using a Query to Constrain Results. - Specify the input (POST only) and output content type (XML or JSON) using the
formatparameter or the HTTP Content-type and Accept headers. For details, see Controlling Input and Output Content Type.
Additional request parameters are available. For details, see the MarkLogic REST API Reference.
The following example assumes the query options shown in the table below are installed under the name index-options:
Then the example command below queries /values/speaker to retrieve the values of all SPEAKER elements:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/values/speaker?options=index-options ... <values-response name="speaker" type="xs:string" \ xmlns="http://marklogic.com/appservices/search" \ xmlns:xs="http://www.w3.org/2001/XMLSchema"> <distinct-value frequency="1">[GOWER]</distinct-value> <distinct-value frequency="1">[PROSPERO]</distinct-value> ... </values-response>
If you use the format parameter to request JSON output from the same request, the results are similar to the following:
{ "values-response": { "name": "speaker", "type": "xs:string", "distinct-value": [ { "frequency": 1, "_value": "[GOWER]" }, { "frequency": 1, "_value": "[PROSPERO]" }, ... ], "metrics": { "values-resolution-time": "PT0.016665S", "aggregate-resolution-time": "PT0.00001S", "total-time": "PT0.018102S" } } }
If you add a string query and/or a structured or cts query to the request, you can limit the results to index values in matching fragments. For example, the following requests returns only the SPEAKER values in fragments containing HAMLET:
$ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/values/speaker?options=index-options&q="HAMLET"'
Finding Value Co-Occurrences in Lexicons
A co-occurrence is a set of index or lexicon values occurring in the same document fragment. The REST Client API enables you to query for n-way co-occurrences. That is, tuples of values from multiple lexicons or indexes, occurring in the same fragment.
Use this procedure to query for co-occurrences of values in lexicons or range indexes with the /values/{name} service:
- Specify query options that include a
tuplesspecification for the target lexicons or indexes. For details, see Defining Queryable Lexicon or Range Index Co-Occurrences and Adding Query Options to a Request. - Send a GET or POST request of the following form to the
/values/{name}service, where name is the name of atuplesdefinition in the query options from Step 1. If you use persistent query options, include theoptionsparameter and replace options_name with the name under which the query options are installed.http://host:port/version/values/name?options=options_name
When constructing your request:
- Substitute a named
tuplesspecification for name in the URL. This must be atuplesrange specification in the query options named by theoptionsparameter, in theoptionsportion of a combined query in the POST body, or in the default query options ifoptionsis omitted. - To use custom query options, specify them using the
optionsparameter and/or theoptionsportion of a combined query in the POST body. For details, see Identifying Lexicon and Range Index Values in Query Options and Adding Query Options to a Request. - To use the default query options, omit the
optionsparameter andoptionsportion of a combined query. The default query options should include a range specification matching name. - To constrain the analysis to values in certain fragments, specify a query using the
qand/orstructuredQueryparameters, or a structured, cts, or combined query in the POST body. For details, see Using a Query to Constrain Results. - Specify the input (POST only) and output content type (XML or JSON) using the
formatparameter or the HTTP Content-type and Accept headers. For details, see Controlling Input and Output Content Type.
Additional request parameters are available. For details, see the MarkLogic REST API Reference.
For more information about co-occurrences, see Value Co-Occurrences Lexicons in the Search Developer's Guide.
The following example assumes the query options shown in the table below are installed under the name index-options. Note that the options include a <tuples/> definition named speaker-scene.
Given these query options, this example queries /values/speaker-scene to retrieve co-occurrences of SPEAKER and scene titles:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/values/speaker-scene?options=index-options ... <values-response name="speaker-scene" xmlns="http://marklogic.com/appservices/search" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <tuple frequency="1"> <distinct-value xsi:type="xs:string" ...>A Lord</distinct-value> <distinct-value ...>SCENE II. The forest.</distinct-value> </tuple> ... </values-response>
If you add a string query and/or a structured or cts query to the request, you can limit the results to co-occurrences in matching fragments. For example, the following requests returns only the SPEAKER values in fragments containing HAMLET:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/values/speaker-scene?options=index-options&q="HAMLET"'
Using a Query to Constrain Results
You can use a string query, structured query, cts:query, or combined query with /values/{name} to limit results to fragments that match the query. The values must occur in fragments matching the query. The fragments are selected in the same manner as an unfiltered cts:search; for details, see Understanding Unfiltered Searches in the Query Performance and Tuning Guide.
If you use a string query, the query is treated as a word query; for details, see cts:word-query. Supply a string query using one of the following:
- The
qrequest parameter of a POST or GET request - The
qtextXML element or JSON property of a combined query supplied in the body of a POST request.
Specify a structured query or cts:query in either XML or JSON using one of the following:
- The
structuredQueryrequest parameter on a GET request. - In a combined query supplied in the body of a POST request.
- In the body of a POST request that does not use a combined query.
The following example limits the results to just those fragments containing the word moon:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/values/speaker?options=index-options&q=moon'
For the full example without a query constraint, see Querying the Values in a Lexicon or Range Index.
Identifying Lexicon and Range Index Values in Query Options
When you use the /values/{name} service, the in-scope query options must include a values or tuples option specification with the given name. Use the values option to make the values in a single lexicon or index available. Use the tuples option to make co-occurrences of values in multiple lexicons or indexes available.
This section covers the following topics:
- Defining Queryable Lexicon or Range Index Values
- Defining Queryable Lexicon or Range Index Co-Occurrences
Defining Queryable Lexicon or Range Index Values
Use this procedure to make the values in a lexicon or range index available through the /values/{name} service:
- Create a lexicon or range index on the database, as described in Range Indexes and Lexicons in the Administrator's Guide and
- Associate a name with the index or lexicon by defining a
<values/>element (or JSON property) in query options. - Supply the query options from Step 2 in your request, as described in Adding Query Options to a Request.
For more information on lexicons and range indexes, see Browsing With Lexicons in the Search Developer's Guide and Creating Indexes on JSON Properties.
For example, if the database configuration includes an element range index on SPEAKER, such as the one shown below:
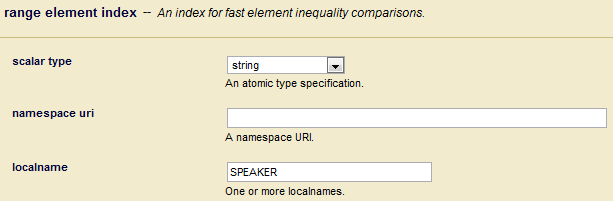
Then the following query options enable the SPEAKER element values to be referenced using as the resource /values/speaker:
You can pre-install the options using the /config/query/{name} service and specify them in the name in the options request parameter, or you can supply the options as part of a combined query in the POST body.
The following example command installs the XML query options with the name index-options:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT \ -d@"./index-options.xml" -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/index-options
Now, you can query the SPEAKER index using the /values/speaker resource with the query options named index-options. For example:
$ curl --anyauth --user user:password -i -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/values/speaker?options=index-options'
Alternatively, use a POST request and specify the options in the request body using a combined query. For example:
$ cat > combo.xml <search xmlns="http://marklogic.com/appservices/search"> <options> <values name="speaker"> <range type="xs:string"> <element ns="" name="SPEAKER"/> </range> </values> </options> </search> ^D $ curl --anyauth --user user:password -i -X POST \ -H "Content-type: application/xml" -H "Accept: application/xml" \ -d @./combo.xml \ 'http://localhost:8000/LATEST/values/speaker'
Defining Queryable Lexicon or Range Index Co-Occurrences
A <tuples/> element in query options specifies the indexes to use in constructing n-way value co-occurrences. For more information about co-occurrences, see Value Co-Occurrences Lexicons in the Search Developer's Guide.
Use this procedure to make co-occurrences of values in multiple lexicons or range indexes available through the /values/{name} service:
- Create the lexicons or range indexes on the database, as described in Range Indexes and Lexicons in the Administrator's Guide.
- Associate a name with the lexicon/index tuple by defining a
<tuples>element in query options (or a tuples object in JSON). - Supply the query options from Step 2 in your request, as described in Adding Query Options to a Request.
For example, suppose the database configuration contains a string-valued element range index on <SPEAKER> and a path range index on the XPath expression /PLAY/ACT/SCENE/TITLE. The following query options enable querying co-occurrences of these two indexes under the name speaker-scene:
You can pre-install the options using the /config/query/{name} service and specify them by name in the options request parameter, or you can supply the options as part of a combined query in the POST body.
The following example command installs the XML query options with the name index-options:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT \ -d@"./index-options.xml" -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/index-options
Now, you can query the SPEAKER index using the /values/speaker-scene resource with the query options named index-options. For example:
$ curl --anyauth --user user:password -i -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/values/speaker-scene?options=index-options'
Alternatively, use a POST request and specify the options in the request body using a combined query. For example:
$ cat > combo.xml <search xmlns="http://marklogic.com/appservices/search"> <options> <tuples name="speaker-scene"> <range type="xs:string"> <element ns="" name="SPEAKER"/> </range> <range type="xs:string"> <path-index>/PLAY/ACT/SCENE/TITLE</path-index> </range> </tuples> </options> </search> ^D $ curl --anyauth --user user:password -i -X POST \ -H "Content-type: application/xml" -H "Accept: application/xml" \ -d @./combo.xml \ 'http://localhost:8000/LATEST/values/speaker-scene'
Creating Indexes on JSON Properties
To efficiently search using JSON properties, you should define indexes on the properties. For example,a json-property structured query performs best when you define a range index on the property you're querying. In addition, range queries require a backing index.
To create an index on a JSON property, treat the JSON property as an XML element for purposes of index creation. That is, use the interfaces for creating element index, such as an element range index.
For details, see Creating Indexes and Lexicons Over JSON Documents in the Application Developer's Guide.
Limiting the Number of Results
You can use the limit, start, and pageLength request parameters to limit the number of values or co-occurrences returned by GET:/v1/values or POST:/v1/values.
The limit parameter specifies the maximum number of value to retrieve from a lexicon. Use start and pageLength to return results one page at a time, similar to the way you can page through results from the /search service. If limit is present, then start and pageLength are applied to the subset of values selected by limit, so the values on a page never extend beyond the values selected by limit.
For example, in the following request, at most 2 values or tuples are returned because start + pageLength would extend beyond the 5 values selected by limit.
GET /LATEST/values?limit=5&start=4&pageLength=3
If you specify a start value, you must also specify a pageLength. For a detailed discussion of how these parameters affect the results returned by values requests, see Returning Lexicon Values With search:values in the Search Developer's Guide.
Using Query By Example to Prototype a Query
This section describes how to search XML and JSON documents using a Query By Example (QBE). You cannot use QBE to search other document types or to search metadata.
This section covers the following topics:
What is QBE
A Query By Example (QBE) enables rapid prototyping of queries for documents that look like this using search criteria that resemble the structure of documents in your database.
For example, if your documents include an author element or key, you can use the following QBE to find documents with an author value of Mark Twain.
| Format | Example |
|---|---|
XML |
<q:qbe xmlns:q="http://marklogic.com/appservices/querybyexample"> <q:query> <author>Mark Twain</author> </q:query> </q:qbe> |
JSON |
{ "$query": { "author": "Mark Twain" } } |
You can only use QBE to search XML and JSON documents. Metadata search is not supported. You can search by element, element attribute, and JSON property; fields are not supported. For structural details, see Searching Using Query By Example in Search Developer's Guide.
When you're satisfied with your prototype or ready to use more powerful Search API features, you can use the API to convert a QBE into a combined query for use with the /search service.
The REST Client API includes the following support for QBE through the /qbe service:
Searching Documents With QBE
To search using QBE, send a GET or POST request to the /qbe service. To pass the QBE as a request parameter, send a GET request with a URL of the form:
http://host:port/version/qbe?query=your-qbe
Where your-qbe is an XML or JSON representation of a QBE.
To pass a QBE in the request body, send a POST request of the following form and place a QBE in the POST body. Set the Content-type header appropriately.
http://host:port/version/qbe
You can also create a multipart POST request that contains a QBE and query options in the request body. A request of this form enables you to specify dynamic query options with a QBE, similar to using a combined query with POST:/v1/search and enables you to specify the QBE and query options in different formats. When you use a multipart request body, the QBE must be the first part and the query options must be the second part. For details, see POST:/v1/qbe.
You can request search results in XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
You can validate the correctness of your input QBE as part of your search or as a standalone operation. For details, see Validating a QBE.
For a complete list of parameters available with the /qbe service, see GET:/v1/qbe or POST:/v1/qbe in the REST Resources API.
The following example matches XML documents that have an author element value of Mark Twain. Results are returned as XML.
$ cat qbe.xml
<q:qbe xmlns:q="http://marklogic.com/appservices/querybyexample">
<q:query>
<author>Mark Twain</author>
</q:query>
</q:qbe>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@"./qbe.xml" \
-H 'Content-type: application/xml' \
'http://localhost:8000/LATEST/qbe'The following example shows an equivalent search using JSON.
$ cat qbe.sjon
{"$query": {
"author": "Mark Twain"
} }
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@"./qbe.json" \
-H 'Content-type: application/json' \
-H 'Accept: application/json' \
'http://localhost:8000/LATEST/qbeThe /qbe service supports most of the same features as the /search service, such as using pre-installed persistent query options, result pagination, and search result transformations. For details, see GET:/v1/qbe or POST:/v1/qbe in the REST Resources API.
You can also use /qbe to retrieve matching documents and metadata. The examples in this section only return a search response. To retrieve whole documents and/or their metadata, see Reading Multiple Documents Matching a Query.
Validating a QBE
When you perform a search, MarkLogic Server does not verify the correctness of your QBE. If your QBE is syntactically or semantically incorrect, you might get errors or surprising results. To avoid such issues, you can validate your QBE prior to or as part of a search.
To validate your query as a standalone operation, add the request parameter view=validate to a GET or POST request to the /qbe service. Rather than performing a search, MarkLogic Server checks your QBE for correctness and returns an indication of validity returned.
For example, the following command validates a JSON QBE:
$ curl --anyauth --user user:password -i -X POST \ -H "Content-type: application/json" -d @./qbe.json \ 'http://localhost:8000/LATEST/qbe?view=validate'
If your query is valid, MarkLogic Server responds with status 200 (OK) and the response body contains a valid-query element, similar to the following:
<q:valid-query xmlns:q="http://marklogic.com/appservices/querybyexample"/>
If your query is invalid, MarkLogic Server can respond with either a status 200 (OK) or status 400 (Bad Request), depending on the nature of the error. When the status code is 400, the response body contains an error. When the status code is 200, the response body contains an invalid-query element that encapsulates the reason validation failed. For example:
<q:invalid-query xmlns:q="http://marklogic.com/appservices/querybyexample"> <q:report id="QBE-QUERY">Query can only contain a filtered flag, score configuration, composers, word queries, and criteria</q:report> </q:invalid-query>
To validate a query as part of your search, use the request parameters view=validate in conjunction with view=results. If your query is valid, the search proceeds as usual. If you query is not valid, an error report is returned.
$ curl --anyauth --user user:password -i -X POST \ -H "Content-type: application/json" -d @./qbe.json \ 'http://localhost:8000/LATEST/qbe?view=validate&view=results'
Generating a Combined Query from a QBE
Generating a combined query from a QBE has the following potential benefits:
- Improve search performance.
- Access a wider array of search features.
- Debug your QBE by examining the lower level Search API constructs it generates.
To generate a combined query from a QBE, add the view=structured request parameter to a GET or POST request to the /qbe service. Rather than performing a search, the request returns a combined query in the response. You can use the resulting query with the /search service.
You cannot combine view=structured with other view settings, such as validate or results.
The following command generates a combined query from a QBE:
$ cat qbe.xml
<q:qbe xmlns:q="http://marklogic.com/appservices/querybyexample">
<q:query>
<author>Mark Twain</author>
</q:query>
</q:qbe>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@"./qbe.xml" \
-H 'Content-type: application/xml' \
'http://localhost:8000/LATEST/qbe?view=structured'
HTTP/1.1 200 OK
...
<search:search xmlns:search="http://marklogic.com/appservices/search">
<search:query>
<search:value-query>
<search:element ns="" name="author"/>
<search:text>Mark Twain</search:text>
<search:term-option>exact</search:term-option>
</search:value-query>
</search:query>
<search:options>
<search:search-option>unfiltered</search:search-option>
<search:quality-weight>0</search:quality-weight>
<search:result-decorator apply="href-decorator"
ns="http://marklogic.com/rest-api/lib/href-decorator"
at="/MarkLogic/rest-api/lib/rest-result-decorator.xqy"/>
</search:options>
</search:search>For more details, see Searching Using Structured Queries in Search Developer's Guide and Specifying Dynamic Query Options with Combined Query.
Analyzing Lexicons and Range Indexes With Aggregate Functions
This section covers the following topics:
- Aggregate Function Overview
- Using Query Options to Apply Aggregate Functions
- Using Request Parameters to Apply Aggregate Functions
- Example: Applying a Builtin Aggregate Function
- Example: Applying an Aggregate UDF
Aggregate Function Overview
An aggregate function performs an operation over values or value co-occurrences in lexicons and range indexes. For example, you can use an aggregate function to compute the sum of values in a range index.
There are two kinds of aggregate functions, builtin and user-defined. MarkLogic Server provides builtin aggregate functions for several common analytical functions; see the list in Using Builtin Aggregate Functions in the Search Developer's Guide.
In addition, you can also implement aggregate user-defined functions (UDFs) in C++ and deploy them as native plugins. Aggregate UDFs must be installed before you can use them. For details, see Implementing an Aggregate User-Defined Function in the Application Developer's Guide.
You can use the REST Client API to apply aggregate functions using /values/{name} in two ways:
- Include one or more
<aggregate/>elements (XML) or sub-objects (JSON) in a<values/>or<tuples/>range specification in the query options. - Include one or more
aggregaterequest parameters.
If aggregate functions are specified through both query options and request parameters, the request parameter(s) overrides the aggregates specified in the query options.
You can only specify multiple aggregate UDFs from more than one plugin using query options.
You cannot use the REST Client API to apply aggregate UDFs that require additional parameters.
Using Query Options to Apply Aggregate Functions
To specify an aggregate function in query options, include an <aggregate/> element in a <values/> or <tuples/> range specification. If you include multiple <aggregate/> specifications, MarkLogic Server applies all the functions.
For a builtin aggregate, specify the function name in the apply attribute of an <aggregate/> element. For example, the query options below specify the builtin aggregate count, which is equivalent to the XQuery builtin cts:count-aggregate.
An aggregate UDF is identified by the function name and a relative path to the plugin that implements the aggregate, as described in Using Aggregate User-Defined Functions in the Search Developer's Guide. Specify the function name with the apply attribute and the plugin path with the udf attribute in an <aggregate/> element or object. For example, the following query options specify a native UDF called count provided by a plugin installed under native/sampleplugin:
To use query options to apply an aggregate function:
- Define query options that include one or more aggregate definitions, as shown above.
- Supply the query options from Step 1 in your request, as described inAdding Query Options to a Request.
- Apply the aggregate by sending a GET or POST request to
/values/{name}and including the options from Step 2. For example:GET /LATEST/values/speaker?options=index-options.
For details on using query options, see Configuring Query Options.
Using Request Parameters to Apply Aggregate Functions
To analyze lexicon or index values or co-occurrences with builtin aggregate function, make a GET or POST request to the /values/{name} service with a URL of the form:
http://host:port/version/values/name?aggregate=aggr_name&options=options_name
To analyze lexicon or index values or co-occurrences with a previously installed aggregate UDF, make a GET request to the /values/{name} service with a URL of the form:
http://host:port/version/values/name?aggregate=aggr_name&aggregatePath=aggr_path&options=options_name
When constructing the request:
- Substitute a named range specification for name in the URL. This must be a range specification (
<values/>or<tuples/>)in the query options supplied in the request, or in the default query options if options are omitted. - To use custom query options, specify them using the
optionsparameter and/or theoptionsportion of a combined query in the POST body. For details, see Adding Query Options to a Request. - To use the default query options, omit the
optionsparameter andoptionsportion of a combined query. The default query options should include a range specification matching name. - Specify the aggregate function name using the
aggregateparameter.The name must be one of the builtin aggregate functions listed in Using Builtin Aggregate Functions the Search Developer's Guide, or a function implemented by the plugin identified by
aggregatePath. - If you're applying an aggregate UDF, specify the relative path to the plugin implementing the aggregate function using the
aggregatePathparameter. - To constrain the analysis to values in certain fragments, specify a query using the
qand/orstructuredQueryparameters, or a structured or combined query in the POST body. For details, see Using a Query to Constrain Results. - Specify the result content type (XML or JSON) using the
formatparameter or the HTTP Accept headers. The default content type is XML. For details, see Controlling Input and Output Content Type. - If you only want the aggregate value in the results, set the
viewparameter toaggregate. By default, MarkLogic Server returns both the lexicon or index values and the aggregate result.
Additional request parameters are available. For details see the MarkLogic REST API Reference.
When applying an aggregate UDF, the output is dependent on the UDF. Aggregate UDFs return a sequence of items, which can be atomic values or key-value maps. For details, see Aggregate User-Defined Functions in the Application Developer's Guide and the XQuery builtin function cts:aggregate.
Example: Applying a Builtin Aggregate Function
The following example counts the number of values in the index identified as speaker in index-options (options=index-options). The counted values include only those in fragments containing HAMLET (q=HAMLET). The output should contain only the aggregate result (view=aggregate).
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/values/speaker?options=index-options&aggregate=count&view=aggregate&q=HAMLET' ... <values-response name="speaker" type="xs:string" xmlns="http://marklogic.com/appservices/search" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <aggregate-result name="count">92</aggregate-result> <metrics> <aggregate-resolution-time>PT0.001108S</aggregate-resolution-time> <total-time>PT0.003719S</total-time> </metrics> </values-response>
Example: Applying an Aggregate UDF
This example demonstrates using an aggregate user-defined function to count the number of values in an element range index using /values/{name}. The aggregate UDF is specified via request parameters, as described in Using Request Parameters to Apply Aggregate Functions.
This example assumes the following pre-requisites are already met:
- A native plugin is installed with the path native/sampleplugin.
- The plugin implements a count function that counts the values in a range index. That is, a function equivalent to the count builtin aggregate function.
- Query options are installed with the name index-options.
- The query options include a range specification named speaker for the SPEAKER element range index.
The following command uses the count aggregate UDF to count the number of values in the SPEAKER index in fragments containing HAMLET. The output only contains the aggregate result (view=aggregate).
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/values/speaker?options=index-options&aggregate=count&aggregatePath=native/sampleplugin&view=aggregate&q=HAMLET'
The use of view=aggregate limits the output to only the aggregate results, as shown below. XML is the default output format. Use the format parameter or the HTTP Accept headers to request JSON output.
Specifying Dynamic Query Options with Combined Query
A combined query is an XML or JSON wrapper around a string and/or a structured query, cts query or QBE, and query options. Use a combined query to specify query options at runtime without first persisting the options as named options using the /config/query service. Combined queries are useful for rapid prototyping during development, and for applications that need to modify query options on a per query basis.
To use a combined query, send a POST request to /v1/search or /v1/values/{name} with the combined query in the request body. See the following topics for more details:
- Syntax and Semantics
- Interaction with Queries in Request Parameters
- Interaction with Persistent Query Options
- Performance Considerations
- Combined Query Examples
Syntax and Semantics
A combined query can contain a string query, a structured query, a QBE, a cts query, query options, or a combination of these. For example, you can create a combined query that contains only query options, only a structured query, or a structured query, string query, and query options.
The following table shows the structure of a combined query. See the usage notes after the table for more details.
You should be aware of the following usage notes:
- Within the combined query wrapper, the queries and options use the same syntax as when they occur standalone.
- You can include at most one of a structured query, a cts query, or a QBE. You can combine this query with a string query (
qtextelement or JSON property), in which case the two queries are AND'd together. - You can include a SPARQL query in a combined query if and only if you are using the combined query with
POST:/v1/graphs/sparqlto perform a semantic query. In this case, the other portions of the combined query are used used to perform a search that further constrains the result of the SPARQL query. For details, seePOST:/v1/graphs/sparql. - Not all query options are applicable to all query types. For example, if you define a range constraint in the options, it is only usable as part of a string or structured query.
- When you use a QBE, you include only the
qbe:queryXML element or$queryJSON property. This means theresponseandformatportions of a QBE are not available. You can use query options to express the equivalent of theresponsecustomizations, but there is no equivalent toformat. If you need to useformat, use a standalone QBE or express your query using a cts:query or structured query.
For examples, see Combined Query Examples.
For details on sub-query and query options syntax, see the following sections of the Search Developer's Guide:
Interaction with Queries in Request Parameters
When making a POST:/v1/search or POST:/v1/values/{name} request, you can use a combined query in conjunction with the q request parameter. The string query in the request parameter value is AND'd with the sub-query(s) in the combined query.
The following table summarizes the interaction between the q request parameter and the sub-queries of a combined query. Note that the queries in the table are an abstraction rather than actual example queries.
Interaction with Persistent Query Options
Dynamic query options supplied in a combined query are merged with persistent and default options that are in effect for the search. If the same non-constraint option is specified in both the combined query and persistent options, the setting in the combined query takes precedence.
When a combined search supplies query options, persisted options are only merged with request options if the options parameter specifies the options by name. Default persisted options are not merged.
Constraints are overridden by name. That is, if the dynamic and persistent options contain a <constraint/> element with the same @name, the definition in the dynamic query options is the one that applies to the query. Two constraints with different name are both merged into the final options.
<options xmlns="http://marklogic.com/appservices/search"> <fragment-scope>properties</fragment-scope> <return-metrics>false</return-metrics> <constraint name="same"> <collection prefix="http://server.com/persistent/"/> </constraint> <constraint name="not-same"> <element-query name="title" ns="http://my/namespace" /> </constraint> </options>
Further, suppose you submit a POST:/v1/search request that uses my-options and includes the following query options in a combined query in the request body:
$ cat body.xml
<search xmlns="http://marklogic.com/appservices/search">
<options>
<return-metrics>true</return-metrics>
<debug>true</debug>
<constraint name="same">
<collection prefix="http://server.com/dynamic/"/>
</constraint>
<constraint name="different">
<element-query name="scene" ns="http://my/namespace" />
</constraint>
</options>
</search>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST \
-d@./body.xml -H "content-type: application/xml" \
'http://localhost:8000/LATEST/search?q=TRAGEDY&options=my-options'The query is evaluated with the following merged options. The persistent options contribute the fragment-scope option and the constraint named not-same. The dynamic options in the combined query contribute the return-metrics and debug options and the constraints named same and different. The return-metrics setting and the constraint named same from my-options are discarded.
<options xmlns="http://marklogic.com/appservices/search"> <fragment-scope>properties</fragment-scope> <return-metrics>true</return-metrics> <debug>true</debug> <constraint name="same"> <collection prefix="http://server.com/dynamic/"/> </constraint> <constraint name="different"> <element-query name="scene" ns="http://my/namespace" /> </constraint> </options> <constraint name="not-same"> <element-query name="title" ns="http://my/namespace" /> </constraint> </options>
Performance Considerations
Using persistent query options usually performs better than using a combined query. In most cases, the difference between the two approaches is slight.
When MarkLogic Server processes a combined query, the per request query options must be parsed and merged with named and default options on every search. When you only use persistent named or default query options, you reduce this overhead.
If your application does not require dynamic per-request query options, you should use the /config/query/{name} service to persist your options under a name and use the options request parameter to associate the options with a simple string, structured, or values query. For details, see Configuring Query Options.
Combined Query Examples
This section includes the following examples:
- Example: Overriding Persistent Constraints
- Example: Modifying the Search Response
- Example: Including a cts Query in a Combined Query
- Example: Including a QBE in a Combined Query
Example: Overriding Persistent Constraints
The following example uses a bucketed constraint, backed by an element range index, to group items into facets by price. Assume following options that define price range buckets are stored as persistent options using the /config/query/{name} service, as described in Creating or Modifying Query Options.
<options xmlns="http://marklogic.com/appservices/search"> <constraint name="price" facet="true"> <range type="xs:int"> <element ns="" name="price"/> <bucket name="under50" ge="0" lt="50">under $50</bucket> <bucket name="under100" ge="50" lt="101">$50-$100</bucket> <bucket name="over100" ge="101">over $100</bucket> </range> </constraint> </options>
The application can use these persistent options to generate a faceted navigation page that allows users to browse by price. You can use dynamic query options to render a page that includes a custom facet from a price range entered by the user. The resulting combined query might look like the following if the user defined a price range of $100-150:
<search xmlns="http://marklogic.com/appservices/search"> <options> <constraint name="price" facet="true"> <range type="xs:int"> <element ns="" name="price"/> <bucket name="under50" ge="0" lt="50">under $50</bucket> <bucket name="under100" ge="50" lt="101">$50-$100</bucket> <bucket name="over100" ge="101">over $100</bucket> <bucket name="custom" ge="100" lt="151">$100 to $150</bucket> </range> </constraint> </options> <query> <range-constraint-query> <constraint-name>price</constraint-name> <value>custom</value> </range-constraint-query> <query> </search>
Example: Modifying the Search Response
The following example uses a combined query that contains only query options to enable the return-query option on the fly to explore how a string query is represented as a cts:query after parsing. The return-query setting in the dynamic options overrides any return-query setting in the default options. All other settings in the default options are unchanged and apply to the query evaluation.
$ cat combo-query.xml
<search xmlns="http://marklogic.com/appservices/search">
<options>
<return-query>true</return-query>
</options>
</search>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST \
-d@./combo-query.xml -H "content-type: application/xml" \
'http://localhost:8000/LATEST/search?q=Horatio NEAR Yorick'
<search:response snippet-format="snippet" total="0" start="1" ...>
<search:qtext>Horation NEAR Yorick</search:qtext>
<search:query>
<cts:near-query qtextjoin="NEAR" strength="30" ...>
<cts:word-query qtextref="cts:text">
<cts:text>Horatio</cts:text>
</cts:word-query>
<cts:word-query qtextref="cts:text">
<cts:text>Yorick</cts:text>
</cts:word-query>
</cts:near-query>
</search:query>
...
</search:response>For details, see Interaction with Persistent Query Options.
Example: Including a cts Query in a Combined Query
The following example illustrates how to use a serialized cts query in a combined query. The query is a word query on the term henry where it appears in a TITLE XML element or JSON property.
The options in the combined query do the following:
- Suppress the generation of snippets (
transform-results) - Extract just the title from the matched documents (
extract-document-data) - Force a filtered search
For more information about serializing cts queries, see Serializations of cts:query Constructors in the Search Developer's Guide.
Example: Including a QBE in a Combined Query
The following example illustrated using a QBE in a combined query. The XML QBE is a word query on the term henry when it appears in a TITLE element. The JSON QBE is a word query on the term henry when it appears in a JSON property named TITLE.
The options in the combined query do the following:
- Suppress the generation of snippets (
transform-results) - Extract just the title from the matched documents (
extract-document-data) - Force a filtered search
Note that options such as extract-document-data and transform-results take the place of response customizations available to a standalone QBE in the qbe:response XML element or $response JSON property. Since only the query portion of a QBE can be included in a combined query, you must use query options to achieve equivalent results.
Recall that an XML QBE matches only XML documents and a JSON QBE matches only JSON documents by default. With a standalone QBE, you can override this behavior using the qbe:format XML element or $format JSON property, but this is not available when using QBE in a combined query. If you need to use this feature, use a standalone QBE.
You can include a string query in the combined query along with your QBE. The two queries are AND'd together in this case. The following example demonstrates a combined query that includes both a string query and a QBE:
Querying Triples
You can query semantic data in the database by sending a GET request to the /graphs/sparql service with a URL of the following form:
http://host:port/version/graphs/sparql?query=sparql-query
Optionally, you can define the RDF Dataset over which to query by specifying one or more graph URIs using the named-graph-uri and/or default-graph-uri request parameters:
http://host:port/version/graphs/sparql?query=sparql-query&named-graph-uri=graph-uri&default-graph-uri=graph-uri
You can also specify the dataset within the query. If you specify a dataset in both the request parameters and the query, the dataset defined with named-graph-uri and default-graph-uri takes precedence. If no dataset is defined in the request parameters or in the query, the dataset includes all triples, regardless of graph.
The SPARQL query in the query request parameter must be URL-encoded.
You can also put the query in the body of a POST request to /graphs/sparql. As with the GET request, define the RDF Dataset using named-graph-uri and/or default-graph-uri. For example, make a POST request with a URL of the following form:
http://host:port/version/graphs/sparql?named-graph-uri=graph-uri&default-graph-uri=graph-uri
The collection lexicon must be enabled on your database before you can use the semantics REST services or use the GRAPH '?g' construct in a SPARQL query.
When you use POST, the request body can contain either a SPARQL query or a combined query that includes a SPARQL query. For details, see POST:/v1/graphs.
If you need to read graphs or query results across multiple requests that reflect the state of the database at a fixed point in time, see Performing Point-in-Time Operations.
For more details on working with semantic data, see Configuring the Database to Work with Triples and Semantic Queries in the Semantics Developer's Guide.
Retrieving Rows
MarkLogic REST API enables you to perform relational operations on indexed values and documents and view the results as row data. The /rows service of the REST Client API enables you to invoke a query and retrieve the results. The query can be sent as an Optic query in JSON AST, JavaScript Query DSL, or QBV (Query Based View) XML format, as an SQL SELECT statement, or as an SPARQL SELECT statement.
This section covers the following topics:
- Generating a Plan
- Invoking a Plan
- Controlling the Inclusion of Type Information in a Row Set
- Generating a Row Set
- Passing Parameters into a Plan
- Handling Complex Column Values
- Generating an Execution Plan
The Query DSL is an alternative to generating a plan. Invoke on your edited Query DSL. See Query DSL for Optic API in the Application Developer's Guide.
Generating a Plan
Use the export capability of the XQuery or Server-Side JavaScript Optic API, or PlanBuilder.ExportablePlan.export in the Java Client API to generate an Optic API query plan.
For more details, see the following topics:
- Exporting and Importing a Serialized Optic Query in the Application Developer's Guide
com.marklogic.client.expression.PlanBuilder.ExportablePlanin the Java Client API Documentation
Invoking a Plan
To invoke a previously exported Optic API query plan send a GET or POST request of the following form to the /rows service:
http://host:port/version/rows
For a GET request, specify a URI-encoded exported Optic plan as the value of the plan request parameter. The plan must be expressed as JSON. For example:
http://localhost:8000/LATEST/rows?plan=...
For a POST request, put the serialized Optic plan in the request body. The plan must be expressed as JSON.
If your plan uses placeholder parameters, use the bind request parameters to specify values for placeholders. You must specify a binding for every placeholder parameter. For details, see Passing Parameters into a Plan.
The /rows service can produce two categories of response data: A row set resulting from execution of a plan, or an execution plan produced by the Optic explain feature. The default response is a row set. To generate an execution plan, use output=explain. For more details, see Generating an Execution Plan.
When generating a row set, you can use the following request parameters plus the Accept header MIME type to tailor the structure of the row set.
output- Specify whether to return a row set or an execution plan, whether to a row set in the form of a JSON array or JSON object (when returning JSON), and what form of input to pass to a mapper or reducer specified in the plan.column-types- Controls whether value datatype information is embedded in each row or provided only once, in the column header.row-format- Controls whether the row parts should be formatted as JSON or XML when generating a multi-part response.node-columns- Controls the handling of non-atomic column values when generating a multi-part response. This information can be included inline or by reference. For details, see Handling Complex Column Values.
For more details and examples of layout variations, see the following:
- Generating a Row Set
GET:/v1/rowsin the MarkLogic REST API ReferencePOST:/v1/rowsin the MarkLogic REST API Reference
Controlling the Inclusion of Type Information in a Row Set
By default, most row format layouts embed column value type information in each row. You can use the column-types request parameter to provide type information only in the column header data instead of each row.
// embed type info in each row (default behavior) http://host:port/LATEST/rows?column-types=rows // embed type info in the column header info http://host:port/LATEST/rows?column-types=header
Only use column-types=header if your column value types are consistent across rows or the type information is not important to your application.
For example, if you generate a row set in the form of a single JSON object, each column value includes a type property, as shown in the row below. For a complete example of this row set, see Single JSON Object.
{ "columns": [ {"name":"main.employees.EmployeeID"}, {"name":"main.employees.FirstName"}, {"name":"main.employees.LastName"} ], "rows":[ { "main.employees.EmployeeID":{"type":"xs:integer","value":1}, "main.employees.FirstName":{"type":"xs:string","value":"John"}, "main.employees.LastName":{"type":"xs:string","value":"Widget"} }, ...
If you use column-types=header, the type information is moved to the columns property, as shown here:
{ "columns": [ { "name":"main.employees.EmployeeID", "type":"xs:integer" }, {"name":"main.employees.FirstName", "type":"xs:string" }, {"name":"main.employees.LastName", "type":"xs:string" } ], "rows":[ { "main.employees.EmployeeID":1, "main.employees.FirstName":"John", "main.employees.LastName":"Widget" },...
The examples in Generating a Row Set demonstrate how column-types=rows and column-types=header affects the output for each row set layout.
Generating a Row Set
The default output from GET/POST /v1/rows is a row set. You can use the Accept headers and request parameters to tailor the layout of the row set to meet the needs of your application. This section provides guidelines and examples for these variations.
See the following topics for settings and examples of generating each type of row set:
- Example Input Plan
- Single JSON Object
- Single JSON Array
- Single XML Element
- Line Delimited JSON Objects
- Line Delimited JSON Arrays
- Comma-Separated Text (CSV)
- Comma-Separated Arrays
- Multipart With Rows as JSON Objects
- Multipart With Rows as XML Elements
You can also use the /rows service to generate an execution plan rather than a row set. For details, see Generating an Execution Plan.
Example Input Plan
The examples in this section use the data, templates, and a plan from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide. If you want to run the examples, you should use the quick start to configure a database, load the data, and create templates.
The curl commands in this section use the following exported plan as input to POST:/v1/rows. This plan was generated using the Optic API explain method and is applicable to the quick start configuration and data.
{"$optic":{ "ns":"op", "fn":"operators", "args":[ {"ns":"op", "fn":"from-view", "args":["main", "employees", null, null]}, {"ns":"op", "fn":"select", "args":[[ {"ns":"op", "fn":"col", "args":["EmployeeID"]}, {"ns":"op", "fn":"col", "args":["FirstName"]}, {"ns":"op", "fn":"col", "args":["LastName"]} ], null ] }, {"ns":"op", "fn":"order-by", "args":[[{"ns":"op", "fn":"col", "args":["EmployeeID"]}]] } ] }}
For an example of how to export a plan, see the AccessPlan.prototype.export JavaScript function or the op:export XQuery function.
You can use the same plan with GET:/v1/rows, but it must be URI encoded when passing it as the value of the plan request parameter.
Single JSON Object
The following example generates a response payload that contains a single JSON object with columns and rows properties. To get this output:
- Set the Accept header to application/json
- Set the
outputrequest parameter toobjector leave it unset
The value of the rows property is an array containing one item per row. Each row is represented as a JSON object whose property names correspond to the column names. The structure of the row property values depends on the column-types request parameter.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: application/json" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=object' { "columns": [ {"name":"main.employees.EmployeeID"}, {"name":"main.employees.FirstName"}, {"name":"main.employees.LastName"} ], "rows":[ { "main.employees.EmployeeID":{"type":"xs:integer","value":1}, "main.employees.FirstName":{"type":"xs:string","value":"John"}, "main.employees.LastName":{"type":"xs:string","value":"Widget"} }, { "main.employees.EmployeeID":{"type":"xs:integer","value":2}, "main.employees.FirstName":{"type":"xs:string","value":"Jane"}, "main.employees.LastName":{"type":"xs:string","value":"Lead"} }, { "main.employees.EmployeeID":{"type":"xs:integer","value":3}, "main.employees.FirstName":{"type":"xs:string","value":"Steve"}, "main.employees.LastName":{"type":"xs:string","value":"Manager"} }, ... ] }
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information is included in the columns property, instead of with each row.
{ "columns": [ { "name":"main.employees.EmployeeID", "type":"xs:integer" }, {"name":"main.employees.FirstName", "type":"xs:string" }, {"name":"main.employees.LastName", "type":"xs:string" } ], "rows":[ { "main.employees.EmployeeID":1, "main.employees.FirstName":"John", "main.employees.LastName":"Widget" }, ... ] }
Single JSON Array
The following example generates a response payload that contains a single JSON array. To get this output:
Each item of the top level array is an array. The first item is an array containing the column names. Each subsequent item is an array representing one row, with one item per column value. The order of the columns is consistent for the header and each row in the row set. The structure of the column values depends on the column-types request parameter.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: application/json" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=array' [ [ {"name":"main.employees.EmployeeID"}, {"name":"main.employees.FirstName"}, {"name":"main.employees.LastName"} ],[ {"type":"xs:integer","value":1}, {"type":"xs:string","value":"John"}, {"type":"xs:string","value":"Widget"} ],[ {"type":"xs:integer","value":2}, {"type":"xs:string","value":"Jane"}, {"type":"xs:string","value":"Lead"} ],[ {"type":"xs:integer","value":3}, {"type":"xs:string","value":"Steve"}, {"type":"xs:string","value":"Manager"} ], ... ]
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information is included in the column header array, instead of in each row.
[ [ {"name":"main.employees.EmployeeID","type":"xs:integer"}, {"name":"main.employees.FirstName","type":"xs:string"}, {"name":"main.employees.LastName","type":"xs:string"} ], [1,"John","Widget"], [2,"Jane","Lead"], [3,"Steve","Manager"], ... ]
Single XML Element
The following example generates a response payload that contains a single XML element that represents a table. To get this output:
You might also choose to set the output request parameter as it affects the form of input to any mapper or reducer used by the plan, but the response payload is not affected by this parameter when generating XML.
The response is rooted at a single <table/> element. The table contains one <columns/> element containing column header data and one <rows/> element containing the row data. The order of the columns is consistent for the header and each row in the row set. The structure of the data also depends on the column-types request parameter.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/rows?database=SQLdata' <t:table xmlns:t="http://marklogic.com/table"> <t:columns> <t:column name="main.employees.EmployeeID"/> <t:column name="main.employees.FirstName"/> <t:column name="main.employees.LastName"/> </t:columns> <t:rows> <t:row> <t:cell name="main.employees.EmployeeID" type="xs:integer">1</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">John</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Widget</t:cell> </t:row> <t:row> <t:cell name="main.employees.EmployeeID" type="xs:integer">2</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">Jane</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Lead</t:cell> </t:row> <t:row> <t:cell name="main.employees.EmployeeID" type="xs:integer">3</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">Steve</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Manager</t:cell> </t:row> ... </t:rows> </t:table>
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information is included in the column header element, rather than in each row element.
<t:table xmlns:t="http://marklogic.com/table"> <t:columns> <t:column name="main.employees.EmployeeID" type="xs:integer"/> <t:column name="main.employees.FirstName" type="xs:string"/> <t:column name="main.employees.LastName" type="xs:string"/> </t:columns> <t:rows> <t:row> <t:cell name="main.employees.EmployeeID">1</t:cell> <t:cell name="main.employees.FirstName">John</t:cell> <t:cell name="main.employees.LastName">Widget</t:cell> </t:row> ... </t:rows> </t:table>
Line Delimited JSON Objects
The following example generates a response payload that contains line-delimited JSON objects. To get this output:
- Set the Accept header to application/json-seq
- Set the
outputrequest parameter toobjector leave it unset
The application/json-seq MIME type is based on the following RFC: https://tools.ietf.org/html/rfc7464.
The first line in the response is an object containing the column names. The following lines each represent a row, expressed as a JSON object. The property names of each row object correspond to the column names. The structure of the row property values depends on the column-types request parameter.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: application/json-seq" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=object' {"columns":[{"name":"main.employees.EmployeeID"},{"name":"main.employees.FirstName"},{"name":"main.employees.LastName"}]} {"main.employees.EmployeeID":{"type":"xs:integer","value":1},"main.employees.FirstName":{"type":"xs:string","value":"John"},"main.employees.LastName":{"type":"xs:string","value":"Widget"}} {"main.employees.EmployeeID":{"type":"xs:integer","value":2},"main.employees.FirstName":{"type":"xs:string","value":"Jane"},"main.employees.LastName":{"type":"xs:string","value":"Lead"}} {"main.employees.EmployeeID":{"type":"xs:integer","value":3},"main.employees.FirstName":{"type":"xs:string","value":"Steve"},"main.employees.LastName":{"type":"xs:string","value":"Manager"}} ...
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information is included in the column header row, rather than in each row.
{"columns":[{"name":"main.employees.EmployeeID","type":"xs:integer"},{"name":"main.employees.FirstName","type":"xs:string"},{"name":"main.employees.LastName","type":"xs:string"}]} {"main.employees.EmployeeID":1,"main.employees.FirstName":"John","main.employees.LastName":"Widget"} {"main.employees.EmployeeID":2,"main.employees.FirstName":"Jane","main.employees.LastName":"Lead"} {"main.employees.EmployeeID":3,"main.employees.FirstName":"Steve","main.employees.LastName":"Manager"} ...
Line Delimited JSON Arrays
The following example generates a response payload that contains line-delimited JSON arrays. To get this output:
The application/json-seq MIME type is based on the following RFC: https://tools.ietf.org/html/rfc7464.
The first line in the response is an array containing the column names (as JSON objects). The following lines each represent a row, expressed as a JSON array of objects, with each object representing a column value. The property names of each row object correspond to the column names. The structure of the row property values depends on the column-types request parameter.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: application/json-seq" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=array' [{"name":"main.employees.EmployeeID"},{"name":"main.employees.FirstName"},{"name":"main.employees.LastName"}] [{"type":"xs:integer","value":1},{"type":"xs:string","value":"John"},{"type":"xs:string","value":"Widget"}] [{"type":"xs:integer","value":2},{"type":"xs:string","value":"Jane"},{"type":"xs:string","value":"Lead"}] [{"type":"xs:integer","value":3},{"type":"xs:string","value":"Steve"},{"type":"xs:string","value":"Manager"}] ...
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information is included in the column header line, rather than each row.
[{"name":"main.employees.EmployeeID","type":"xs:integer"},{"name":"main.employees.FirstName","type":"xs:string"},{"name":"main.employees.LastName","type":"xs:string"}] [1,"John","Widget"] [2,"Jane","Lead"] [3,"Steve","Manager"] ...
Comma-Separated Text (CSV)
The following example generates a response payload that contains a row set as CSV data. To get this output:
The first line in the response is a comma-separated list of column names. The following lines each represent a row, with comma-separated column values.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: text/csv" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=object' main.employees.EmployeeID,main.employees.FirstName,main.employees.LastName 1,John,Widget 2,Jane,Lead 3,Steve,Manager ...
Comma-Separated Arrays
The following example generates a response payload that contains a row set as CSV data. To get this output:
The first line in the response is an array containing the column names. The following lines each represent a row, expressed as an array. Each array item is a column value.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" -H "Accept: text/csv" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=array' ["main.employees.EmployeeID", "main.employees.FirstName", "main.employees.LastName"] [1, "John", "Widget"] [2, "Jane", "Lead"] [3, "Steve", "Manager"] ...
Multipart With Rows as JSON Objects
The following example generates a multipart response payload that contains a part for the column names, and a part for each row, with the row data expressed as a JSON object. To get this output:
- Set the Accept header to multipart/mixed
- Set the
outputrequest parameter toobject, or leave it unset - Set the
row-formatrequest parameter tojson, or leave it unset
The first part contains the column names, expressed as a JSON object. The Content-Disposition part header includes a kind=columns specifier. By default, each subsequent part contains the contents of one row, expressed as a JSON object whose property names correspond to the column names. The Content-Disposition part header for a row includes a kind=row specifier.
The structure of the values also depends on the column-types and node-columns request parameters. See the examples below and Handling Complex Column Values.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=object' --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=columns {"columns":[{"name":"main.employees.EmployeeID"},{"name":"main.employees.FirstName"},{"name":"main.employees.LastName"}]} --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row {"main.employees.EmployeeID":{"type":"xs:integer","value":1},"main.employees.FirstName":{"type":"xs:string","value":"John"},"main.employees.LastName":{"type":"xs:string","value":"Widget"}} --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row {"main.employees.EmployeeID":{"type":"xs:integer","value":2},"main.employees.FirstName":{"type":"xs:string","value":"Jane"},"main.employees.LastName":{"type":"xs:string","value":"Lead"}} --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row {"main.employees.EmployeeID":{"type":"xs:integer","value":3},"main.employees.FirstName":{"type":"xs:string","value":"Steve"},"main.employees.LastName":{"type":"xs:string","value":"Manager"}} --BOUNDARY-- ...
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information appears in the column part instead of in each row part.
--BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=columns {"columns":[{"name":"main.employees.EmployeeID","type":"xs:integer"},{"name":"main.employees.FirstName","type":"xs:string"},{"name":"main.employees.LastName","type":"xs:string"}]} --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row {"main.employees.EmployeeID":1,"main.employees.FirstName":"John","main.employees.LastName":"Widget"}
Multipart With Rows as JSON Arrays
The following example generates a multipart response payload that contains a part for the column names, and a part for each row, with the row data expressed as JSON arrays. To get this output:
- Set the Accept header to multipart/mixed
- Set the
outputrequest parameter toarray - Set the
row-formatrequest parameter tojson, or leave it unset
The first part contains the column names, expressed as a JSON array. The Content-Disposition part header includes a kind=columns specifier.
By default, each subsequent part contains the contents of one row, expressed as a JSON array. Each array item represents one column value. The Content-Disposition part header for a row includes a kind=row specifier.
The structure of the column values also depends on the column-types and node-columns request parameters. See the examples below and Handling Complex Column Values.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=array' --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=columns [{"name":"main.employees.EmployeeID"},{"name":"main.employees.FirstName"},{"name":"main.employees.LastName"}] --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row [{"type":"xs:integer","value":1},{"type":"xs:string","value":"John"},{"type":"xs:string","value":"Widget"}] --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row [{"type":"xs:integer","value":2},{"type":"xs:string","value":"Jane"},{"type":"xs:string","value":"Lead"}] --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row [{"type":"xs:integer","value":3},{"type":"xs:string","value":"Steve"},{"type":"xs:string","value":"Manager"}] --BOUNDARY ...
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. The type information appears in the column part instead of in each row part.
--BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=columns [{"name":"main.employees.EmployeeID","type":"xs:integer"},{"name":"main.employees.FirstName","type":"xs:string"},{"name":"main.employees.LastName","type":"xs:string"}] --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row [1,"John","Widget"]
Multipart With Rows as XML Elements
The following example generates a multipart response payload that contains a part for the column names, and a part for each row, with the data expressed XML elements. To get this output:
You might also choose to set the output request parameter as it affects the form of input to any mapper or reducer used by the plan, but the response payload is not affected by this parameter when generating XML.
The first part contains the column names, expressed as columns XML element. The Content-Disposition part header includes a kind=columns specifier. Each subsequent part contains the contents of one row, expressed as a row XML element. The Content-Disposition part header for a row includes a kind=row specifier.
The structure of the column values also depends on the column-types and node-columns request parameters. See the examples below and Handling Complex Column Values.
For example, the following request produces the output shown after the curl command when run against the data from SQL on MarkLogic Server Quick Start in the SQL Data Modeling Guide and the plan from Example Input Plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&row-format=xml' --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=columns <t:columns xmlns:t="http://marklogic.com/table"> <t:column name="main.employees.EmployeeID"/> <t:column name="main.employees.FirstName"/> <t:column name="main.employees.LastName"/> </t:columns> --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=row <t:row xmlns:t="http://marklogic.com/table" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <t:cell name="main.employees.EmployeeID" type="xs:integer">1</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">John</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Widget</t:cell> </t:row> --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=row <t:row xmlns:t="http://marklogic.com/table" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <t:cell name="main.employees.EmployeeID" type="xs:integer">2</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">Jane</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Lead</t:cell> </t:row> --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=row <t:row xmlns:t="http://marklogic.com/table" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <t:cell name="main.employees.EmployeeID" type="xs:integer">3</t:cell> <t:cell name="main.employees.FirstName" type="xs:string">Steve</t:cell> <t:cell name="main.employees.LastName" type="xs:string">Manager</t:cell> </t:row> --BOUNDARY ...
You can use the column-types request parameter to extract just the value of each column, without type information. For example, if you set column-types to header, you see output similar to the following. Type information is included in the column part instead of each row part.
--BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=columns <t:columns xmlns:t="http://marklogic.com/table"> <t:column name="main.employees.EmployeeID" type="xs:integer"/> <t:column name="main.employees.FirstName" type="xs:string"/> <t:column name="main.employees.LastName" type="xs:string"/> </t:columns> --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-Disposition: inline; kind=row <t:row xmlns:t="http://marklogic.com/table" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <t:cell name="main.employees.EmployeeID">1</t:cell> <t:cell name="main.employees.FirstName">John</t:cell> <t:cell name="main.employees.LastName">Widget</t:cell> </t:row>
Passing Parameters into a Plan
If your plan uses placeholder parameters, use the bind request parameter to pass values for the placeholders into the plan.
You can specify just a value for the named parameter, or a value and a type, or a value and a language code. If you do not specify a type, the value is interpreted as a string. For more details, see Parameterizing a Plan in the Application Developer's Guide.
For example, if you defined a placeholder variable named start in your plan definition, then you can specify a value for the parameter in the following ways:
http://localhost:8000/LATEST/rows?bind:start=apple http://localhost:8000/LATEST/rows?bind:start:string=apple http://localhost:8000/LATEST/rows?bind:start@en=apple
Handling Complex Column Values
If a row contains column values with non-atomic type, such as XML element, JSON array, JSON object, binary, or text nodes, MarkLogic serializes them inline by default. If the non-atomic type is not native to the serialization format, such as an XML element column value in a row serialized as JSON, you can optionally extract as a separate part and refer to it by reference in the serialized row by using the node-columns=reference request parameter.
For example, suppose you extract rows in which one column contains an XML element value and another column contains a JSON object value. If you serialize the row as JSON, then the JSON object column values can be represented natively, but the XML elements become just a string:
{ "row":1, "elem":"<alpha><a>true</a></alpha>", "obj":{"alpha":10} }
If you generate a multipart/mixed response, then you can use the node-columns request parameter to generate rows containing a reference to the non-native complex values instead of inlining them. The referenced value is provided in a separate part. For example:
curl --anyauth --user username:password -i -X POST -d @./complex.json \ -H "Content-type: application/json" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&node-columns=reference' ... --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=columns {"columns":[{"name":"row"},{"name":"elem"},{"name":"obj"}]} --BOUNDARY Content-Type: application/json; charset=utf-8 Content-Disposition: inline; kind=row {"row":{"type":"xs:integer","value":1},"elem":{"type":"cid","value":"cid:elem[0]"},"obj":{"type":"object","value":{"alpha":10}}} --BOUNDARY Content-Type: application/xml; charset=utf-8 Content-ID: <elem[0]> Content-Disposition: inline; kind=row-attachment <alpha><a>true</a></alpha> ...
The row parts are identifiable by the kind=row in the Content-disposition header. The complex value parts are identifiable by kind=row-attachment in the Content-disposition header. The row attachment parts have a Content-Type part header that accurately reflects the MIME type of the complex column value.
The value part reference uses the id from the Content-id part header on the referenced value part. The content id is based on the column name and row number. The content id uses the standard Content-id/CID format described in the following RFC: https://tools.ietf.org/html/rfc2392.
For example, if you have the following value part:
Content-Type: application/xml; charset=utf-8 Content-ID: <elem[0]> Content-Disposition: inline; kind=row-attachment <alpha><a>true</a></alpha>
Then a row referencing this part has the following form if you do not use any row formatting parameters. Notice the use of cid:elem[0] to reference the value part.
{"row":{"type":"xs:integer","value":1},"elem":{"type":"cid","value":"cid:elem[0]"},"obj":{"type":"object","value":{"alpha":10}}}
The layout of the column value varies, depending on your use of formatting parameters such as output, column-types, and row-format. The following examples illustrate a few variants:
// using output=array [{"type":"xs:integer","value":1}, {"type":"cid","value":"cid:elem[0]"}, {"type":"object","value":{"alpha":10}}] // using output=object and column-types=header {"row":1,"elem":"cid:elem[0]","obj":{"alpha":10}} // using row-format=xml <t:row xmlns:t="http://marklogic.com/table" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <t:cell name="row" type="xs:integer">1</t:cell> <t:cell name="elem" type="cid">cid:elem[0]</t:cell> <t:cell name="obj" type="object">{"alpha":10}</t:cell> </t:row>
For more complete examples of output formatting variations, see Generating a Row Set.
Generating an Execution Plan
An Optic API execution plan expresses the logical dataflow of a plan as a sequence of atomic operations. For more details, see Optic Execution Plan in the Application Developer's Guide.
You can generate an execution plan with the /rows service by setting the output parameter value to explain. Use the Accept header to specify either a JSON or XML response.
For example, the following command generates a JSON execution plan.
curl --anyauth --user username:password -i -X POST -d @./plan.json \ -H "Content-type: application/json" \ -H "Accept: application/json" \ 'http://localhost:8000/LATEST/rows?database=SQLdata&output=explain'
Searching Values Metadata Fields
Values metadata, sometimes called key-value metadata, can only be searched if you define a metadata field on the keys you want to search. Once you define a field on a metadata key, use the normal field search capabilities to include a metadata field in your search. For example, you can use a cts:field-word-query or a structured query word-query on a metadata field, or define a constraint on the field and use the constraint in a string query.
For more details, see Metadata Fields in the Administrator's Guide. For some examples, see Example: Structured Search on Key-Value Metadata Fields or Searching Key-Value Metadata Fields in the Search Developer's Guide.
Configuring Query Options
Use the /config/query resources to install, list, and manage sets of query options. Use the options request parameter to apply installed query options to requests to /search, /qbe, /values, and /suggest. This section covers the following topics:
- Controlling Queries With Options
- Adding Query Options to a Request
- Creating or Modifying Query Options
- Checking Index Availability
- Retrieving Options
- Retrieving a List of Installed Query Options
- Removing Query Options
- Removing All Named Query Options
Controlling Queries With Options
You can use persistent or dynamic query options to customize your queries. MarkLogic Server comes configured with default query options. You can extend and modify the default options using /config/query/default.
Use the options request parameter to the /search, /qbe, /values, and /suggest services to customize your queries. Query options provide capabilities such as:
- define word, value and element constraints
- define lexicon and range index specifications
- control search characteristics such as case sensitivity and ordering
- extend the search grammar
- customize query results including pagination, snippeting, and filtering
For details on these and other options, see Appendix: Query Options Reference in the Search Developer's Guide.
You can also create custom persistent or dynamic query options. Persistent query options are named, pre-defined query options that you install using the /config/query/{name}. Dynamic query options are per-request, transient options defined in a combined query. For details, see Creating or Modifying Query Options and Specifying Dynamic Query Options with Combined Query
Once you install query options under a name, you can apply them to a /search, /qbe, /values, or /suggest request using the options request parameter. The following example searches for the word julius, using the query options named my-options:
http://localhost:8000/LATEST/search?q=julius&options=my-options
Adding Query Options to a Request
You can customize a query with query options in the following ways:
- Use the
optionsrequest parameter of a GET request to/search,/qbe,/values/{name}, or/suggestto supply the name of pre-installed persistent options. - Use the
optionsparameter of a POST request to/search,/qbe,/values/{name}, or/suggestto supply the name of pre-installed persistent options. - Use the
optionselement (XML) or sub-object (JSON) of a combined query passed in the body of a POST request to/searchor/values/{name}to supply dynamic options.
Pre-installed, persistent query options usually provide better performance. Using dynamic query options introduces option parsing and merging overhead to every query.
Persistent and dynamic query options can be specified in either XML or JSON. Persistent options must be installed before you can use them; for details, see Creating or Modifying Query Options.
Dynamic options are only usable with services that support POSTing a combined query in the request body. Methods that support combined query allow you to specify persistent and dynamic options in the same request. Where both are present, they are merged; in case of a conflict, a dynamic option setting overrides a persistent option setting. For details, see Specifying Dynamic Query Options with Combined Query.
Creating or Modifying Query Options
To install or modify named persistent query options, send a PUT or POST request to the /config/query service with a URL of the form:
http://host:port/version/config/query/name
When constructing the request:
- Set the name portion of the URL to a unique name for these options, or to
default. Use the name to identify the query options in subsequent request, as described in Controlling Queries With Options. - Place the XML or JSON option data in the request body.
For syntax details, see Appendix: Query Options Reference in the Search Developer's Guide.
- Specify the MIME type of the body content in the
formatparameter or the HTTPContent-typeheader, as described in Controlling Input and Output Content Type. You may only send XML or JSON. The default format is XML.
When choosing the HTTP verb, consider the following:
- To install new query options, use either PUT or POST.
- To replace the named query options, use PUT.
- To add options to the named query options, use POST. Any options not included in the payload remain unchanged. New options are added.
If query option validation is enabled, the request will fail if it results in invalid query options. If the request fails, the options are unchanged. Option validation is enabled by default. You can disable option validation using the validate-options instance configuration property. For details, see Configuring Instance Properties.
The following example installs query options named title-only that define a search constraint named title. The constraint limits queries to terms appearing in a TITLE element. The query options are then used to find occurrences of julius in TITLE elements:
$ cat bill-options.txt
<options xmlns="http://marklogic.com/appservices/search">
<constraint name="title">
<word>
<element ns="" name="TITLE" />
</word>
</constraint>
</options>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -T './bill-options.txt' \
-H "Content-type: application/xml" \
http://localhost:8000/LATEST/config/query/title-only
...
HTTP/1.1 204 Content Updated
$ curl --anyauth --user user:password -X GET \
'http://localhost:8000/LATEST/search?q=title:julius&options=title-only'
...
<search:response total="1" start="1" page-length="10"
xmlns="" xmlns:search="http://marklogic.com/appservices/search">
...
</search:response>To add case-sensitivity to the query options installed above, this example sends a POST request to /config/query. The body content type, JSON, is given via the Content-type header.
$ cat add-cs.json
{
"options":
{ "term":
{ "term-option":"case-sensitive" }
}
}
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X POST -d@'add-cs.json' \
-H "Content-type: application/json" \
http://localhost:8000/LATEST/config/query/title-only
...
HTTP/1.1 201 Content CreatedTo confirm the change, the modified option is fetched using a GET request:
$ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/config/query/title-only ... <options xmlns="http://marklogic.com/appservices/search"> <constraint name="title"> <word> <element ns="" name="TITLE"/> </word> </constraint> <term> <term-option>case-sensitive</term-option> </term> </options>
Creating or Modifying One Option
To add or modify just one setting in a set of query options, send a PUT or POST request to the /config/query service with a URL of the form:
http://host:port/version/config/query/name/option_name
When constructing the request:
- Set the name portion of the URL to the name of the enclosing query options, or to
default. - Set the option_name portion of the URL to a query option name, such as
constraintorterm. - Place the XML or JSON option data in the request body. The data should be an
optionsnode (XML) or map (JSON) that includes the option named in the URL. - Specify the content type of the body in the
formatparameter or the HTTPContent-typeheader, as described in Controlling Input and Output Content Type. You may only send XML or JSON. The default format is XML.
The option_name portion of the URL must be the name of an option that can appear as an immediate child of a query options XML node or JSON object. Finer grained access is not supported. For details on query options names and structure, see Appendix: Query Options Reference in the Search Developer's Guide.
When choosing the HTTP verb, consider the following:
- To add a new option to the set, use either PUT or POST.
- To replace all existing options of the same name, use PUT.
- To add a new occurrence of an existing option that can appear multiple times, use POST. For example, query options can contain multiple
<constraint/>elements.
If query option validation is enabled, the request will fail if it results in invalid query options. If the request fails, the options are unchanged. Option validation is enabled by default. You can disable option validation using the validate-options instance configuration property. For details, see Configuring Instance Properties.
Checking Index Availability
Some query options require the database configuration to include supporting indexes. For example, if your query options contain a range constraint, then you can only use those options on a database whose configuration includes a corresponding range index.
You can use the /config/indexes service to compare query options to the database configuration and get a report on whether or not all required indexes are present. For missing indexes, the report includes information to help create the missing index. You can either check all query options configurations, or a particular one (by name).
To check all query options configurations, send a GET request to the /config/indexes service of the form:
http://host:port/version/config/indexes
To check a specific query options configuration, send a GET request to the /config/indexes/{name} service of the form:
http://host:port/version/config/indexes/name
Where name is the name under which the options were installed using the /config/query/{name} service, as described in Creating or Modifying Query Options.
You can request an index report in XML, JSON, or HTML, using either the format request parameter or the HTTP Accept headers. The HTML report is a user-friendly report that contains more details.
For example, suppose the following query options are installed under the name tuples. These options require 2 range indexes: An element range index on <SPEAKER/> and a path range index on the XPath expression /PLAY/ACT/SCENE/TITLE:
<options xmlns="http://marklogic.com/appservices/search"> <tuples name="speaker-title"> <range type="xs:string"> <element ns="" name="SPEAKER"/> </range> <range type="xs:string"> <path-index>/PLAY/ACT/SCENE/TITLE</path-index> </range> </tuples> </options>
The following command requests an index check check report in XML for the tuples options. Use the format parameter or the Accept headers to request a different report format.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/config/indexes/tuples
The table below shows the generated report. Notice that the report indicates that the index configuration is not complete, and shows which query option is not complete. You can use the path-index value to create the required path range index.
Retrieving Options
To retrieve previously installed persistent query options, send a GET request to the /config/query service with a URL of the form:
http://host:port/version/config/query/name
Where name is the name of the query options.
MarkLogic Server responds with the contents of the named query options, as XML or JSON. XML is the default format. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
You can also retrieve the settings for a specific option within the query options by sending a GET request with a URL of the form:
http://host:port/version/config/query/name/option_name
Where option_name is an option name. For details, see Appendix: Query Options Reference in the Search Developer's Guide.
As when retrieving a whole set, results can be requested as XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type. No version information is returned when examining only one option.
The following example retrieves the contents of the query options called title-only:
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X GET \
http://localhost:8000/LATEST/config/query/title-only
...
<options xmlns="http://marklogic.com/appservices/search">
<constraint name="title">
<word>
<element ns="" name="TITLE"/>
</word>
</constraint>
<term>
<term-option>case-sensitive</term-option>
</term>
</options>The following example retrieves only the term option of the title-only query options:
$ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/config/query/title-only/term ... <options xmlns="http://marklogic.com/appservices/search"> <term> <term-option>case-sensitive</term-option> </term> </options>
Retrieving a List of Installed Query Options
To retrieve a list of the names of all installed query options, send a GET request to /config/query with a URL of the form:
http://host:port/version/config/query
MarkLogic Server responds with a list of names in XML or JSON. XML is the default format. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
If there are no custom query options installed, MarkLogic Server responds with an empty XML <options> node or JSON array.
The following example retrieves the list of named query options as XML. The results show 2 sets of query options, named title-only and play-type.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/config/query ... <rapi:query-options xmlns:rapi="http://marklogic.com/rest-api"> <rapi:options> <rapi:name>title-only</rapi:name> <rapi:uri>/v1/config/query/title-only</rapi:uri> </rapi:options> <rapi:options> <rapi:name>play-type</rapi:name> <rapi:uri>/v1/config/query/play-type</rapi:uri> </rapi:options> </rapi:query-options>
The following example requests the same information as JSON, using the format request parameter:
$ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/config/query ... [ {"name":"title-only","uri":"/v1/config/query/title-only"} {"name":"play-type","uri":"/v1/config/query/play-type"} ]
Removing Query Options
You can remove a single setting, one set of query options, or all query options, as described in the following topics:
Removing Query Options
To remove the query options installed under a particular name, send a DELETE request to the /config/query service with a URL of the form:
http://host:port/version/config/query/name
Where name is the name of the query options to remove. MarkLogic Server responds with 204 if the option set is successfully deleted.
Removing a Single Option
To remove a specific setting in a set of query options, send a DELETE request to the /config/query service with a URL of the form:
http://host:port/version/config/query/name/option_name
Where option_name is the name of the option to remove and name is the name of the containing query options. MarkLogic Server responds with 204 if the option is successfully deleted.
The option_name portion of the URL must be the name of an option that can appear as an immediate child of a query options XML node or JSON object. Finer grained access is not supported. All options with this name are removed. For example, if the query options named my-options contain multiple <constraint/> options, then the following request removes all of them:
DELETE http://localhost:8000/LATEST/config/query/my-options/constraint
For details on query options names and structure, see Appendix: Query Options Reference in the Search Developer's Guide.
If query option validation is enabled, the request will fail if it results in invalid query options. If the request fails, the options are unchanged. Option validation is enabled by default. You can disable option validation using the validate-options instance configuration property. For details, see Configuring Instance Properties.
For details on query option names, see Appendix: Query Options Reference in the Search Developer's Guide.
Removing All Named Query Options
To remove all named query options from a REST Client API instance, send a DELETE request to the /config/query service with a URL of the form:
http://host:port/version/config/query
MarkLogic Server responds with 204 if the options successfully deleted.
Using Namespace Bindings
The /config/namespaces service is deprecated. You should use the Management REST API to manage namespace bindings instead.
This sections covers the following topics:
- When Do You Need a Namespace Binding
- Creating or Updating a Namespace Binding
- Creating or Updating Multiple Namespace Bindings
- Listing Available Namespace Bindings
- Deleting Namespace Bindings
When Do You Need a Namespace Binding
The /config/namespaces service is deprecated. Use the REST Management API to manage namespace bindings instead. See the namespaces property of PUT:/manage/LATEST/servers/[id-or-name]/properties and GET:/manage/LATEST/servers/[id-or-name]/properties.
Use the /config/namespaces service to pre-define namespace prefixes for contexts in which you cannot define a namespace binding in the request.
Creating or Updating a Namespace Binding
The /config/namespaces service is deprecated. Use the REST Management API to manage namespace bindings instead. See the namespaces property of PUT:/manage/LATEST/servers/[id-or-name]/properties.
This section describes how to create a single namespace binding. You can also define multiple bindings in a single request; for details, see Creating or Updating Multiple Namespace Bindings.
To define a namespace binding, send a PUT request to the /config/namespaces/{name} service with a URL of the form:
http://host:port/version/config/namespaces/name
Where name is the namespace prefix you want to define. If a binding already exists for this prefix, it is replaced.
When constructing your request:
- Set the name portion of the URL to the desired namespace prefix.
- Place the XML or JSON binding definition in the request body. See the table below.
- Specify the content type of the body in the
formatparameter or the HTTPContent-typeheader, as described in Controlling Input and Output Content Type. You may only send XML or JSON. The default format is XML.
The request body must have the following form:
| Format | Body |
|---|---|
| XML | <namespace xmlns="http://marklogic.com/rest-api"> <prefix>the_prefix</prefix> <uri>the_uri</uri> </namespace> |
| JSON | { "prefix" : "the_prefix", "uri" : "the_uri" } |
The following example binds the prefix bill to the namespace URI http://marklogic.com/examples/shakespeare:
$ cat ns-binding.xml <namespace xmlns="http://marklogic.com/rest-api"> <prefix>bill</prefix> <uri>http://marklogic.com/examples/shakespeare</uri> </namespace> # Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT -d@./ns-binding.xml \ -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/namespaces/bill
You can examine the binding by sending a GET request to /config/namespaces/{name} or to /config/namespaces. The latter lists all bindings. For example:
$ curl --anyauth --user user:password -X GET \ http://localhost:8000/LATEST/config/namespaces/bill <rapi:namespace xmlns:rapi="http://marklogic.com/rest-api"> <rapi:prefix>bill</rapi:prefix> <rapi:uri>http://marklogic.com/examples/shakespeare</rapi:uri> </rapi:namespace>
To get the equivalent output as JSON, use the format parameter or specify application/json in the HTTP Accept header. For example:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/json" \ http://localhost:8000/LATEST/config/namespaces/bill { "prefix":"bill", "uri":"http://marklogic.com/examples/shakespeare" }
Creating or Updating Multiple Namespace Bindings
The /config/namespaces service is deprecated. You should use the REST Management API to manage namespace bindings instead. For details, see PUT:/manage/v2/servers/[id-or-name]/properties.
This section describes how to define multiple namespace bindings with a single request. You can also define a specific single binding; for details, see Creating or Updating a Namespace Binding.
To define multiple namespace bindings, send a PUT or POST request to the /config/namespaces service with a URL of the form:
http://host:port/version/config/namespaces
When constructing your request:
- Choose PUT to replace all bindings with those the request body. Choose POST to append to existing bindings.
- Place the XML or JSON binding definitions in the request body. See the table below.
- Specify the content type of the body in the
formatparameter or the HTTPContent-typeheader, as described in Controlling Input and Output Content Type. You may only send XML or JSON. The default format is XML.
If you use POST and a binding already exists for one defined in the request body, MarkLogic Server returns status 400 (Bad Request).
The request body must have the following form:
The following example binds the prefix one to the namespace URI http://marklogic.com/examples/one and the prefix two to the namespace URI http://marklogic.com/examples/two:
$ cat ns-bindings.xml
<namespace-bindings xmlns="http://marklogic.com/rest-api">
<namespace>
<prefix>one</prefix>
<uri>http://marklogic.com/examples/one</uri>
</namespace>
<namespace>
<prefix>two</prefix>
<uri>http://marklogic.com/examples/two</uri>
</namespace>
</namespace-bindings>
# Windows users, see Modifying the Example Commands for Windows
$ curl --anyauth --user user:password -X PUT -d@./ns-bindings.xml \
-H "Content-type: application/xml" \
http://localhost:8000/LATEST/config/namespacesThe following example creates equivalent bindings using JSON input:
$ cat ns-bindings.json
{
"namespace-bindings": [
{
"prefix": "one",
"uri": "http:\/\/marklogic.com\/examples\/one"
},
{
"prefix": "two",
"uri": "http:\/\/marklogic.com\/examples\/two"
}
]
}
$ curl --anyauth --user user:password -X PUT -d@./ns-bindings.json \
-H "Content-type: application/json" \
http://localhost:8000/LATEST/config/namespacesYou can examine the binding by sending a GET request to /config/namespaces/{name} or to /config/namespaces.
Listing Available Namespace Bindings
The /config/namespaces service is deprecated. You should use the REST Management API to manage namespace bindings instead. For details, see GET:/manage/v2/servers/[id-or-name]/properties.
To list all available namespace bindings, send a GET request to /config/namespaces with a URL of the form:
http://host:port/version/config/namespaces
To retrieve the binding for a single namespace prefix, send a GET request to /config/namespaces/{name} with a URL of the form:
http://host:port/version/config/namespaces/name
Where name is a bound namespace prefix.
You can request output as either XML or JSON. Use the Accept header or format request parameter to select the output content type. For details, see Controlling Input and Output Content Type.
The following example command requests all namespace bindings, as XML:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/config/namespaces
The output from the command is shown in the table below, assuming two namespace bindings are installed, for the prefixes one and two.
When you use GET /config/namespaces/{name}, the output is similar, but without the namespace-bindings wrapper. For example to retrieve the binding for the one prefix:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/config/namespaces/one <rapi:namespace xmlns:rapi="http://marklogic.com/rest-api"> <rapi:prefix>one</rapi:prefix> <rapi:uri>http://marklogic.com/examples/one</rapi:uri> </rapi:namespace>
The following command retrieves the same information as JSON:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/json" \ http://localhost:8000/LATEST/config/namespaces/one {"prefix":"one","uri":"http://marklogic.com/examples/one"}
Deleting Namespace Bindings
The /config/namespaces service is deprecated. You should use the REST Management API to manage namespace bindings instead. For details, see PUT:/manage/v2/servers/[id-or-name]/properties.
To remove all namespace bindings, send a DELETE request to /config/namespaces with a URL of the form:
http://host:port/version/config/namespaces
To remove a specific binding, send a DELETE request to /config/namespaces/{name} with a URL of the form:
http://host:port/version/config/namespaces/name
Where name is a bound namespace prefix. If no binding exists for name, MarkLogic Server returns status 404 (Not Found).
The following example deletes just the binding for the prefix one:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X DELETE \ http://localhost:8000/LATEST/config/namespaces/one
Generating Search Facets
The MarkLogic Server Search API enables you to expose search facets in your application. Facets enable users to filter search results by narrowing down the search criteria. To learn more about facets, see Constrained Searches and Faceted Navigation in the Search Developer's Guide.
To generate facet information in search results, use query options that include constraints that support facets, such as collection and element constraints. You can also define custom constraints; see Creating a Custom Constraint in the Search Developer's Guide.
The following example returns facet information about play types and enables searching by the facet type, assuming the documents in the database have been added to the collections /play-type/Comedy, /play-type/Tragedy, and /play-type/History. For more examples, see Constraint Options in the Search Developer's Guide.
This example uses a collection constraint, which requires the collection lexicon to be enabled on the database.
To enable the play type facet, create query options that define a collection constraint:
Install the options with the name facet-options:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT \ -d@"./facet-options.xml" -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/facet-options
If you query /search or /qbe using index-options as the query options, facet results are included in the search results. For example, the following query finds all occurrences of castle and the search response includes a count of the matches for each play type:
$ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?options=facet-options&q=castle' ... <search:response snippet-format="snippet" total="88" ...> <search:result /> <search:facet name="type" type="collection"> <search:facet-value name="Comedy" count="5"> Comedy </search:facet-value> <search:facet-value name="History" count="35"> History </search:facet-value> <search:facet-value name="Tragedy" count="47"> Tragedy </search:facet-value> </search:facet> ... </search:response>
To get the equivalent results as JSON, use format=json or include application/json in the HTTP Accept header. For example:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/json" \ 'http://localhost:8000/LATEST/search?options=facet-options&q=castle' ... { "snippet-format": "snippet", "total": 88, "start": 1, "page-length": 10, "results": [...], "facets": { "type": { "type": "collection", "facetValues": [ { "name": "Comedy", "count": 5 }, { "name": "History", "count": 35 }, { "name": "Tragedy", "count": 47 } ] } }, "qtext": "castle", ... }
You can query by facet by including a facet-name:facet-value search term. The following command matches occurrences of castle in plays of type Comedy:
$ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?options=facet-options&q=castle type:Comedy'
Paginating Results
When you query the database, you can paginate the query results using the start and pageLength request parameters. Use start to specify the index of the first result to return, and pageLength to control the number results to return.
By default, queries return the first 10 results. That is, the default start position is 1 and the default page length is 10. You can fetch successive non-overlapping pages of results by incrementing the start position by the page length in each call.
For more information, see the Search Developer's Guide and Fast Pagination and Unfiltered Searches in the Scalability, Availability, and Failover Guide.
The following example command fetches the first 5 results matching castle. Notice that the search response includes the total number of matches and each search:result includes an index.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?q=castle&start=1&pageLength=5' ... <search:response snippet-format="snippet" total="88" start="1" page-length="5" ...> <search:result index="1" uri="/shakespeare/plays/hen_vi_2.xml" .../> <search:result index="2" uri="/shakespeare/plays/rich_ii.xml" .../> <search:result index="3" uri="/shakespeare/plays/macbeth.xml" .../> <search:result index="4" uri="/shakespeare/plays/hen_vi_3.xml" .../> <search:result index="5" uri="/shakespeare/plays/othello.xml" .../> ... </search:response>
To fetch the next 5 results, increment start by 5:
$ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?q=castle&start=6&pageLength=5' ... <search:response snippet-format="snippet" total="88" start="1" page-length="5" ...> <search:result index="6" uri="/shakespeare/plays/lear.xml" .../> <search:result index="7" uri="/shakespeare/plays/hamlet.xml" .../> <search:result index="8" uri="/shakespeare/plays/rich_iii.xml" .../> <search:result index="9" uri="/shakespeare/plays/hen_v.xml" .../> <search:result index="10" uri="/shakespeare/plays/m_wives.xml" .../> ... </search:response>
Customizing Search Results
This section covers several features that the REST Client API provides for search result customization.
- The
transform-resultsquery option enables you to fine tune the default snippets. For example, you can control how many matches to return. - Custom snippet extensions identified in query options enable you to modify the contents of snippets returned in the
search:matchportion of asearch:response. - Transform functions enable you to completely change the structure returned by a search or values query. Your transform takes a
search:responseor a matched document as input and produces a result document. - The
extract-document-dataquery option enables you to return a portion of each matching document. For details, see Extracting a Portion of Matching Documents in the Search Developer's Guide.
The following topics cover these features:
Customizing Search Snippets
Search results usually include portions of matching documents with the search matches highlighted, perhaps with some text showing the context of the search matches. These search result pieces are known as snippets. MarkLogic Server has a default search snippet format, but you can customize the snippet format by either modifying the configuration of the default snippet function or creating a custom snippet extension.
This section covers the following topics:
- Customizing the Default Search Snippets
- Creating Your Own Snippet Extension
- Generating Custom JSON Snippets
Customizing the Default Search Snippets
MarkLogic Server creates snippets by applying a default transformation to search results. You can modify the results of the default transformation using the transform-results query option, as described in Modifying Your Snippet Results in the Search Developer's Guide. To use this feature with the REST API:
- Create query options that contain a
transform-resultsXML element or JSON object. - Install these query options under a name or as the default options using the
/config/queryservice, or include them directly in a combined query. For details, see Configuring Query Options. - If you installed the configuration as named query options, apply the options to your query by supplying the name in the
optionsrequest parameter. For details, see Controlling Queries With Options. - If you installed the configuration as default options, they will be automatically applied to search results returned by any query that does not use named query options.
The following example searches for the term hamlet in a collection of Shakespeare plays using the default snippet options. The search results include four snippets in each match.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/search?q=hamlet <search:response snippet-format="snippet" total="20" ...> <search:result index="1" uri="/shakespeare/plays/hamlet.xml" ...> <search:snippet> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/TITLE">The Tragedy of <search:highlight>Hamlet</search:highlight>, Prince of Denmark </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/PERSONAE/PERSONA[2]"><search:highlight>HAMLET</search:highlight>, son to the late, and nephew to the present king. </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/PERSONAE/PERSONA[4]">HORATIO, friend to <search:highlight>Hamlet</search:highlight>. </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/PERSONAE/PERSONA[16]">GERTRUDE, queen of Denmark, and mother to <search:highlight>Hamlet</search:highlight>. </search:match> </search:snippet> </search:result> ... </search:response>
If you request results as JSON, you get snippets of the following form instead of the XML shown above.
... "matches": [ { "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")\/PLAY\/TITLE", "match-text": [ "The Tragedy of ", { "highlight": "Hamlet" }, ", Prince of Denmark" ] }, ] ...
Notice that the resulting snippets are from the <TITLE/> and <PERSONAE/> elements. If you apply the options below to the search instead, at most three snippets are returned and only matches in <LINE/> elements are included.
This example installs the above XML options and applies them to the same query:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT \ -d @./transform-results.xml \ -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/snippet-lines $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ http://localhost:8000/LATEST/search?q=hamlet&options=snippet-lines<search:response snippet-format="snippet" total="20" ...> <search:result index="1" uri="/shakespeare/plays/hamlet.xml" ...> <search:snippet> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[6]">Dared to the combat; in which our valiant <search:highlight>Hamlet</search:highlight>-- </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[17]">His fell to <search:highlight>Hamlet</search:highlight>. Now, sir, young Fortinbras, </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[59]/LINE[6]">Unto young <search:highlight>Hamlet</search:highlight>; for, upon my life, </search:match> </search:snippet> </search:result> ... </search:response>
To install the equivalent JSON options, set the Content-type header to application/json. For example:
$ curl --anyauth --user user:password -X PUT \ -d @./transform-results.json \ -H "Content-type: application/json" \ http://localhost:8000/LATEST/config/query/snippet-lines
To receive JSON search results, set the Accept header to application/json or use the format request parameter. For example:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/json" \ 'http://localhost:8000/LATEST/search?q=hamlet&options=snippet-lines' { "snippet-format": "snippet", "total": 20, "start": 1, "page-length": 10, "results": [ { "index": 1, "uri": "\/shakespeare\/plays\/hamlet.xml", "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")", "score": 158720, "confidence": 0.80079, "fitness": 1, "matches": [ { "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")\/PLAY\/ACT[1]\/SCENE[1]\/SPEECH[48]\/LINE[6]", "match-text": [ "Dared to the combat; in which our valiant ", { "highlight": "Hamlet" }, "--" ] }, { "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")\/PLAY\/ACT[1]\/SCENE[1]\/SPEECH[48]\/LINE[17]", "match-text": [ "His fell to ", { "highlight": "Hamlet" }, ". Now, sir, young Fortinbras," ] }, { "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")\/PLAY\/ACT[1]\/SCENE[1]\/SPEECH[59]\/LINE[6]", "match-text": [ "Unto young ", { "highlight": "Hamlet" }, "; for, upon my life," ] } ] } ], ... }
Alternatively, you can use a combined query that contains your options, instead of installing persistent options. For example, you can pass the following query in the body of a POST:/v1/search request. For details, see Generating a Combined Query from a QBE.
<search xmlns="http://marklogic.com/appservices/search"> <qtext>hamlet</qtext> <options> <transform-results apply="snippet"> <max-matches>3</max-matches> <preferred-elements> <element ns="" name="LINE" /> </preferred-elements> </transform-results> <search-option>filtered</search-option> </options> </search>
Creating Your Own Snippet Extension
If the transform-results query options with the default snippet format does not meet the needs of your application, you can create a custom snippet transformation function, as described in Specifying Your Own Code in transform-results in the Search Developer's Guide.
Install custom snippet transformations using the /ext service to load them into the Modules database associated with your REST API instance. Use the apply, at, and ns attributes of the transform-results query option to specify your custom module.
To create and use a custom snippeting function:
- Create an XQuery library module that implements your custom snippet function, as described in Specifying Your Own Code in transform-results in the Search Developer's Guide.
- Install your module in the modules database of your REST API instance using the
/extservice, similar to installing a dependent library for a resource service extension. For details, see Installing or Updating an Asset. - Create and install query options that include a
transform-resultsoption that uses your custom snippeting function. For details, see Search Customization Via Options and Extensions in the Search Developer's Guide. - Apply the options to your query by supplying the name of the options with the
optionsrequest parameter. For details, see Controlling Queries With Options.
If your application requires non-trivial JSON snippet customization, your snippet function must generate the XML representation of the desired JSON. For details, see Generating Custom JSON Snippets.
The following example builds on the example from Customizing the Default Search Snippets. The example searches for the term hamlet in a collection of Shakespeare plays using the default snippet format with the custom options that extract the first three matches in lines of dialog. These options are installed under the name snippet-lines. With the default snippet transformation function, the search produces the following results:
# Install the options # Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X PUT \ -d @./transform-results.xml \ -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/snippet-lines # Use the options in a query $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/search?q=hamlet&options=snippet-lines' <search:response snippet-format="snippet" total="20" ...> <search:result index="1" uri="/shakespeare/plays/hamlet.xml" ...> <search:snippet> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[6]">Dared to the combat; in which our valiant <search:highlight>Hamlet</search:highlight>-- </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[17]">His fell to <search:highlight>Hamlet</search:highlight>. Now, sir, young Fortinbras, </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[59]/LINE[6]">Unto young <search:highlight>Hamlet</search:highlight>; for, upon my life, </search:match> </search:snippet> </search:result> ... </search:response>
The custom snippeting function below returns the act, scene, speech and line number in each match, instead of the text surrounding the search term.
xquery version "1.0-ml"; module namespace example = "http://marklogic.com/example"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; declare function example:snippet( $result as node(), $ctsquery as schema-element(cts:query), $options as element(search:transform-results)? ) as element(search:snippet) { let $default-snippet := search:snippet($result, $ctsquery, $options) return element { fn:QName(fn:namespace-uri($default-snippet), fn:name($default-snippet)) } { $default-snippet/@*, for $child in $default-snippet/node() return if ($child instance of element(search:match)) then element {fn:QName(fn:namespace-uri($child), fn:name($child)) } { $child/@*, let $parts := fn:tokenize( fn:substring-after($child/@path, "/PLAY/ACT["), "\[") let $location := fn:concat( "Act ", fn:substring-before($parts[1], "]"), ", Scene ", fn:substring-before($parts[2], "]"), ", Speech ", fn:substring-before($parts[3], "]"), ", Line ", fn:substring-before($parts[4], "]")) return text {$location} } else $child } };
If the above module is installed in the instance modules database with the URI /ext/my.domain/my-snippets.xqy, then we can use the following options to generate custom snippets by supplying the local name of the custom function (snippet) in apply, the namespace of the module (http://marklogic.com/example) in ns, and the URI of the module in the instance modules database (/my.domain/my-snippets.xqy) in at.
This example installs the above XML options and applies them to the query for hamlet to produce snippets that display the act, scene, speech and dialog number of each match:
# Windows users, see Modifying the Example Commands for Windows # Install the custom snippeting module $ curl --anyauth --user user:password -X PUT \ -d @./my-snippets.xqy \ -H "Content-type: application/xquery" \ http://localhost:8000/LATEST/ext/my.domain/my-snippets.xqy # Install the options $ curl --anyauth --user user:password -X PUT \ -d @./transform-results.xml \ -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/custom-snippet # Use the options in a query $ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ "http://localhost:8000/LATEST/search?q=hamlet&options=custom-snippet" <search:response snippet-format="custom" total="20" start="1" ...> <search:result index="1" uri="/shakespeare/plays/hamlet.xml" path="fn:doc("/shakespeare/plays/hamlet.xml")" ...> <search:snippet> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[6]">Act 1, Scene 1, Speech 48, Line 6 </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[17]">Act 1, Scene 1, Speech 48, Line 17 </search:match> <search:match path="fn:doc("/shakespeare/plays/hamlet.xml")/PLAY/ACT[1]/SCENE[1]/SPEECH[59]/LINE[6]">Act 1, Scene 1, Speech 59, Line 6 </search:match> </search:snippet> </search:result> ... </search:response>
To generate the equivalent results in JSON, change the Accept header to application/json. For example:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/json" \ "http://localhost:8000/LATEST/search?q=hamlet&options=custom-snippet" { "snippet-format": "custom", "total": 20, "start": 1, "page-length": 10, "results": [ { "index": 1, "uri": "/shakespeare/plays/hamlet.xml", "path": "fn:doc(\"/shakespeare/plays/hamlet.xml\")", "score": 158720, "confidence": 0.80079, "fitness": 1, "matches": [ { "path": "fn:doc(\"\/shakespeare/plays/hamlet.xml\")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[6]", "match-text": [ "Act 1, Scene 1, Speech 48, Line 6" ] }, { "path": "fn:doc(\"\/shakespeare\/plays\/hamlet.xml\")/PLAY/ACT[1]/SCENE[1]/SPEECH[48]/LINE[17]", "match-text": [ "Act 1, Scene 1, Speech 48, Line 17" ] }, { "path": "fn:doc(\"/shakespeare/plays/hamlet.xml\")/PLAY/ACT[1]/SCENE[1]/SPEECH[59]/LINE[6]", "match-text": [ "Act 1, Scene 1, Speech 59, Line 6" ] } ] } ], ... }
Generating Custom JSON Snippets
If you need to create custom JSON snippets that cannot be expressed as XML, set @format to "json" on the search:snippet you return, and populate the search:snippet with serialized JSON. For example:
declare function my:snippeter( $result as node(), $ctsquery as schema-element(cts:query), $options as element(search:transform-results)? ) as element(search:snippet) { element search:snippet { attribute format { "json" }, text {'{"MY":"CUSTOM SNIPPET"}'} } };
You cannot change just a portion of the snippet to serialized JSON. For example, you cannot just change the search:match text.
Transforming the Search Response
You can make arbitrary changes to the response from a search or values query by applying a transformation function to the response.
Search response transforms use the same interface and framework as content transformations applied during document ingestion. For details on the interface and on installing a transform, see Working With Content Transformations.
This following topics cover additional details specific to working with search transforms:
Basic Search Transform Usage
- Create a transform function according to the interface described in Writing Transformations. For additional details, see What to Expect as Input Content.
- Install your transform function on the REST API instance following the instructions in Installing Transformations.
- Apply your transform to a request to the
/searchor/valuesservice by specifying the name in thetransformrequest parameter, as described in Applying Transformations.
For example, assuming you installed a transform function under the name example, the following command applies the function to the results of a search:
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?q=dog&transform=example'
What to Expect as Input Content
Search response transforms use the interface and framework described in Working With Content Transformations. A search transform can be invoked on either a database document or a search results summary (search response), depending on the search request context. Any customizations made by the transform-results query option or result decorators are applied before calling your transform function.
Your transform should be prepared to receive multiple documents types in the content parameter:
- When the input to a transform is a document matched by the search, the
contentparameter is the matched document, so it may be any supported document type (XML, JSON, Text, Binary). - When the input is a search response, the type of the document in the
contentparameter can be either XML or JSON, depending on the result format requested by the client.When the search response is expressed as XML, the input document node has a
<search:response/>root element, in thecontentparameter.
For example, suppose you send a query to /search that finds matches in 1 XML document and 1 JSON document. The following table summarizes the number of times your transforms is invoked and with what content, in several request contexts. (The order of invocation is not guaranteed.)
You can probe the document type to test whether the input to your transform receives JSON or XML input. For example, in server-side JavaScript, you can test the documentFormat property of a document node:
function myTransform(context, params, content) {
if (content.documentFormat == "JSON") {
// handle as JSON or a JavaScript object
} else {
// handle as XML
}
...
}In XQuery and XSLT, you can test the node kind of the root of the document, which will be element for XML and object for JSON.
declare function dumper:transform( $context as map:map, $params as map:map, $content as document-node() ) as document-node() { if (xdmp:node-kind($content/node() eq "element") then(: process as XML :) else (: process as JSON :)
As with read and write transforms, the content object is immutable in JavaScript, so you must call toObject to create a mutable copy:
const output = content.toObject(); ...modify output... return output;
Expected Output
A search transform function is expected to return a document node of the same type as the document node passed in via the content parameter. If your transform returns a document node that is not the same type, set the new output type on the context parameter.
The type of document returned must be consistent with the output-type context value in an XQuery or XML transform, or the outputType context property in a JavaScript transform.
Generating Search Term Completion Suggestions
Use the /suggest service to generate search term completion suggestions that match a wildcard terminated string. For example, if the user enters the text doc into a search box, you can query /suggest with doc to retrieve a list of terms matching doc*, and then display them to user. This service is analogous to calling the XQuery function search:suggest.
The following topics are covered:
- Basic Steps
- Example: Generating Search Suggestions Using GET
- Example: Generating Search Suggestions Using POST
- Where to Find More Information
Basic Steps
To retrieve a list of search suggestions using the REST Client API, use the following procedure. For a detailed example, see Example: Generating Search Suggestions Using GET.
- Configure at least one index on the XML element, XML attribute, or JSON property you want to include in the search for suggestions. For performance reasons, a range or collection index is recommended over a word lexicon; for details, see
search:suggest. - Define query options that use your index as a suggestion source by including it in the definition of a
default-suggestion-sourceorsuggestion-source option. For details, see Search Term Completion Using search:suggest in the Search Developer's Guide. - Send a GET or POST request to the
/suggestservice with a URL of the following form, wherepartial-qis the text for which to retrieve suggestions.http://host:port/version/suggest?partial-q=text_to_match&options=your_options
If you use a GET request to generate suggestions, you must pre-install the query options. For details, see Configuring Query Options.
If you use a POST request to generate suggestions, the POST body must contains a combined query. You can use persistent query options and/or include dynamic query options in the combined query. For details, see Specifying Dynamic Query Options with Combined Query.
If you define your suggestion source in the default query options, you can omit the options request parameter or dynamic query options.
You can further constrain the suggestions by including one or more additional queries using the q request parameter or in the combined query of a POST request body. The request returns only suggestions in documents that also match the additional queries. Multiple additional queries are AND'd together. The following example URL returns only those suggestions found in fragments that match the query prefix:xdmp.
http://localhost:8000/LATEST/suggest/partial-q=doc&q=prefix:xdmp
Additional request parameters allow you to limit the number of suggestions returned and specify a substring of partial-q to match against. For details, see GET:/v1/suggest or POST:/v1/suggest in MarkLogic REST API Reference.
Example: Generating Search Suggestions Using GET
This example walks you through configuring your database and REST instance to try retrieving search suggestions. The Documents database is assumed in this example, but you can use any database.
- If you do not already have a REST API instance, create one. This example assumes your instance is on port 8000.
- Initialize the Database.
- Install Query Options
- Retrieve Unconstrained Search Suggestions
- Retrieve Constrained Search Suggestions
Initialize the Database
Run the following query in Query Console to load the sample data into your database, or use PUT or POST requests to /documents to create equivalent documents. The example will retrieve suggestions for the <name/> element, with and without a constraint based on the <prefix/> element.
xdmp:document-insert("/suggest/load.xml", <function xmlns="http://marklogic.com/example"> <prefix>xdmp</prefix> <name>document-load</name> </function> ); xdmp:document-insert("/suggest/insert.xml", <function xmlns="http://marklogic.com/example"> <prefix>xdmp</prefix> <name>document-insert</name> </function> ); xdmp:document-insert("/suggest/query.xml", <function xmlns="http://marklogic.com/example"> <prefix>cts</prefix> <name>document-query</name> </function> ); xdmp:document-insert("/suggest/search.xml", <function xmlns="http://marklogic.com/example"> <prefix>cts</prefix> <name>search</name> </function> );
To create the range index used by the example, run the following query in Query Console, or use the Admin Interface to create an equivalent index on the name element. The following query assumes you are using the Documents database; modify as needed.
xquery version "1.0-ml"; import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; admin:save-configuration( admin:database-add-range-element-index( admin:get-configuration(), xdmp:database("Documents"), admin:database-range-element-index( "string", "http://marklogic.com/example", "name", "http://marklogic.com/collation/", fn:false()) ) );
Install Query Options
This step installs persistent query options that define name as the default suggestion source, plus an additional value constraint on prefix. Copy the following query options into a file named suggest-options.xml:
<options xmlns="http://marklogic.com/appservices/search"> <default-suggestion-source> <range type="xs:string" facet="true"> <element ns="http://marklogic.com/example" name="name"/> </range> </default-suggestion-source> <constraint name="prefix"> <value> <element ns="http://marklogic.com/example" name="prefix"/> </value> </constraint> </options>
Install the options using the /config/query service, as described in Creating or Modifying Query Options. Use a command similar to the following:
$ curl --anyauth --user user:password -X PUT \ -d @./suggest-options.xml -i -H "Content-type: application/xml" \ http://localhost:8000/LATEST/config/query/opt-suggest
The database and REST API instance are now configured to retrieve the example search suggestions.
Retrieve Unconstrained Search Suggestions
The following request returns all values of <name/> that match the wildcard string doc*:
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/suggest?partial-q=doc&options=opt-suggest' ... <search:suggestions xmlns:search=...> <search:suggestion>document-insert</search:suggestion> <search:suggestion>document-load</search:suggestion> <search:suggestion>document-query</search:suggestion> </search:suggestions>
If you perform the same request with an Accept header of application/json, the response data looks like the following:
{ "suggestions": [ "document-insert", "document-load", "document-query" ] }
Retrieve Constrained Search Suggestions
Recall that the query options include a value constraint on the prefix element:
<options xmlns="http://marklogic.com/appservices/search"> <default-suggestion-source> <range type="xs:string" facet="true"> <element ns="http://marklogic.com/example" name="name"/> </range> </default-suggestion-source> <constraint name="prefix"> <value> <element ns="http://marklogic.com/example" name="prefix"/> </value> </constraint> </options>
The following command uses this constraint in the additional query prefix:xdmp to limit results to suggestions in fragments with the prefix value xdmp. This eliminates the function document-query from the results because it has the prefix cts.
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/suggest?partial-q=doc&options=opt-suggest&q=prefix:xdmp' ... <search:suggestions xmlns:search=...> <search:suggestion>document-insert</search:suggestion> <search:suggestion>document-load</search:suggestion> </search:suggestions>
If you perform the same request with an Accept header of application/json, the response data looks like the following:
{ "suggestions": [ "document-insert", "document-load" ] }
Example: Generating Search Suggestions Using POST
This example uses a POST request with the following combined query to limit results to suggestions in fragments with the prefix value xdmp. The example assumes your database contains the documents loaded in Initialize the Database.
<search xmlns="http://marklogic.com/appservices/search" > <query> <value-query> <element ns="http://marklogic.com/example" name="prefix"/> <text>xdmp</text> </value-query> </query> <options xmlns="http://marklogic.com/appservices/search"> <default-suggestion-source> <range type="xs:string" facet="true"> <element ns="" name="name"/> </range> </default-suggestion-source> </options> </search>
Note that you do not need to pre-install persistent query options in this case because the options are included in the query.
The following command uses this query to retrieve suggestions for the input string "doc".
$ curl --anyauth --user user:password -X GET \ -H "Accept: application/xml" \ 'http://localhost:8000/LATEST/suggest?partial-q=doc ... <search:suggestions xmlns:search=...> <search:suggestion>document-insert</search:suggestion> <search:suggestion>document-load</search:suggestion> </search:suggestions>
The following query is the equivalent combined query, expressed as JSON:
{ "search": { "qtext": [ "document" ], "query": { "value-query": { "element": { "ns": "http://marklogic.com/example", "name": "prefix" }, "text": [ "xdmp" ] } }, "options": { "default-suggestion-source": { "range": { "type": "xs:string", "facet": true, "element": { "ns": "", "name": "name" } } } } } }
If you perform the same request with an Accept header of application/json, the response data looks like the following:
{ "suggestions": [ "document-insert", "document-load" ] }
Where to Find More Information
For more details on using search suggestions, including performance recommendations and additional examples, see the following:
search:suggest(XQuery function)- Search Term Completion Using search:suggest in Search Developer's Guide.
- default-suggestion-source in the Search Developer's Guide
- suggestion-source in the Search Developer's Guide
- Specifying Dynamic Query Options with Combined Query