
MarkLogic Server 11.0 Product DocumentationLoading Content Into MarkLogic Server — Chapter 8
Repairing XML Content During Loading
MarkLogic Server can perform the following types of XML content repair during content loading:
- Correct content that does not conform to the well-formedness rules in the XML specification
- Modify inconsistently structured content according to a specific XML schema
- Assign namespaces and correct unresolved namespace bindings
- Restructure content using XPath or XQuery
Not all programming language interfaces support the full spectrum of XML content repair. MarkLogic Server does not validate content against predetermined XSchema (DDML) or DTDs.
This chapter includes the following topics:
- Programming Interfaces and Supported Content Repair Capabilities
- Enabling Content Repair
- Auto-Close Repair of Empty Tags
- Schema-Driven Tag Repair
- Load-Time Default Namespace Assignment
- Load-Time Namespace Prefix Binding
- Query-Driven Content Repair
Programming Interfaces and Supported Content Repair Capabilities
The MarkLogic programming interfaces support repair options as described in the following table:
| Programming Interface | Content Repair Capabilities | More Details |
|---|---|---|
| MarkLogic Connector for Hadoop | Set the repair level. | MarkLogic Connector for Hadoop Developer's Guide |
| MarkLogic Content Pump | Tag repair and schema-driven repair, namespace prefix binding. | -xml_repair_level option. See Importing Content Into MarkLogic Server in the mlcp User Guide |
| MarkLogic Java API | Tag repair, schema-driven repair, namespace prefix binding. | Java Application Developer's Guide |
| REST Client API | General-purpose tag repair and schema-driven repair, namespace prefix binding. | repair parameter on PUT:/v1/documents in the REST Client API |
| XCC | General-purpose tag repair and schema-driven repair, namespace prefix binding. | DocumentRepairLevel enumeration class |
| XQuery | All types described in this chapter. |
Also see the MarkLogic XQuery and XSLT Function Reference |
Enabling Content Repair
The tag repair, schema-driven repair, and namespace prefix binding mechanisms are enabled using an option to the various content loading functions as listed above.
When no repair option is explicitly specified, the default is implicitly specified by the XQuery version of the caller. In XQuery 1.0 and 1.0-ml the default is none. In XQuery 0.9-ml the default is full.
Tag repair, schema-driven repair, and namespace prefix binding can be performed on all XML documents loaded from external sources. This includes documents loaded using the XQuery built-in functions, XCC document insertion methods, or the Java or REST client APIs.
General-Purpose Tag Repair
MarkLogic Server can apply a general-purpose, stack-driven tag repair algorithm to every XML document loaded from an external source. The algorithm is triggered by encountering a closing tag (for example, </tag>) that does not match the most recent opening tag on the stack.
How General-Purpose Tag Repair Works
Consider the following simple document markup example:
<p>This is <b>bold and <i>italic</i></b> within the paragraph.</p>
Each of the following variations introduces a tagging error common to hand-coded markup:
<p>This is <b>bold and <i>italic</b> within the paragraph.</p> <p>This is <b>bold and <i>italic</i></b></u> within the paragraph.</p>
In the first variation, the italic element is never closed. And in the second, the underline element is never opened.
When MarkLogic Server encounters an unexpected closing tag, it performs one of the following actions:
- Rule 1: If the QName (both the tag's namespace and its local name) of the unexpected closing tag matches the QName of a tag opened earlier and not yet closed, the loader automatically closes all tags until the matching opening tag is closed.
Consequently, in the first sample tagging error, the loader automatically closes the italic element when it encounters the tag closing the bold element:
<p>This is <b>bold and <i>italic</i></b> within the paragraph.</p>
The bold characters in the markup indicate the close tag dynamically inserted by the loader.
- Rule 2: If there is no match between the QName of the unexpected closing tag and all previously opened tags, the loader ignores the closing tag and proceeds.
Consequently, in the second tagging error shown above, the loader ignores the "extra" underline closing tag and proceeds as if it is not present:
<p>This is <b>bold and <i>italic</i></b></u> within the paragraph.</p>
The italic tag indicates the closing tag that the loader is ignoring.
<p>This is <b>bold and <i>italic</b></i> within the paragraph.</p>
In this circumstance, the first rule automatically closes the italic element when the closing bold tag is encountered. When the closing italic tag is encountered, it is simply discarded as there are no previously opened italic tags still on the loader's stack. The result is more than likely what the markup author intended:
<p>This is <b>bold and <i>italic</i></b> within the paragraph.</p>
Pitfalls of General-Purpose Tag Repair
While these two general repair rules produce sound results in most situations, their application can lead to repairs that may not match the original intent. Consider the following examples.
- This snippet contains a markup error: the bold element is never closed.
<p>This is a <b>bold and <i>italic</i> part of the paragraph.</p>
The general-purpose repair algorithm fixes this problem by inserting a closing bold tag before the closing paragraph tag, because this is the point at which it becomes apparent that there is a markup problem:
<p>This is a <b>bold and <i>italic</i> part of the paragraph.</b></p>
In this situation, the entire remainder of the paragraph is emboldened, because it is not otherwise apparent where the tag was closed. For cases other than this example, even a human is not always able to make the right decision.
- Rule 1 can also cause significant unwinding of the stack if a tag, opened much earlier in the document, is mistakenly closed mid-document. Consider the following markup error where
</d>is mistyped as</b>.<a> <b> <c> <d>...content intended for d...</b> ...content intended for c... </c> ...content intended for b... </b> ...content intended for a... </a>
The erroneous
</b>tag triggers rule 1 and the system closes all intervening tags between<b>and<d>. Rule 2 then discards the actual close tags for<b>and<c>that have now been made redundant (since they have been closed by rule 1). This results in an incorrectly flattened document as shown here (some indentation and line breaks have been added for illustrative purposes):<a> <b> <c> <d>...content intended for d...</d> </c> </b> ...content intended for c... ...content intended for b... ...content intended for a... </a>
Limitations
This section describes some known limitations of general-purpose tag repair.
XQuery Functions
For functions where the XML node provided as a parameter is either dynamically generated by the query itself (and is consequently guaranteed to be well-formed) or is explicitly defined within the XQuery code (in which case the query is not successfully parsed for execution unless it is well-formed), general-purpose tag repair is not performed. This includes XML content loaded using the following functions:
Root Element
General-purpose tag repair does not insert a missing closing root element tag into an XML document.
Previous Marklogic Versions
Versions of MarkLogic Server 2.0 and earlier would repair missing root elements, making it effectively impossible to identify truncated source content. Later versions of MarkLogic Server reports an error in these conditions.
Controlling General-Purpose Tag Repair
MarkLogic Server enables you to enable or disable general-purpose tag repair during any individual document load using an optional repair parameter. The specific parameter is language specific. For example, if you use XQuery xdmp:document-load, xdmp:unquote functions, you can use the repair parameter on the options node and specify a value of full or none. See the language specific documentation for more details.
Auto-Close Repair of Empty Tags
Empty tag auto-close is a special case of schema-driven tag repair and is supported in all versions of MarkLogic Server. This repair mechanism automatically closes tags that are identified as empty tags in a specially-constructed XML schema.
This approach addresses a common problem found in SGML and HTML documents. SGML and HTML both regard tags as markup rather than as the hierarchical element containers defined by the XML specification. In both the SGML and HTML worlds, it is acceptable to use a tag as an indication of some formatting directive, without any need to close the tag. This frequently results in the liberal use of empty tags within SGML and HTML content.
For example, an <hr> tag in an HTML document indicates a horizontal rule. Because there is no sense to containing anything within a horizontal rule, the tag is interpreted by browsers as an empty tag. Consequently, while HTML documents may be littered with <hr> tags, you rarely find a </hr> tag or even a <hr/> tag unless someone has converted the HTML document to be XHTML-compliant. The same can occur with <img> and <meta> tags, to name just two. In SGML documents, you can easily find <pgbrk>, <xref> and <graphic> used similarly.
Applying this type of content repair enables you to avoid the false nesting of content within otherwise unclosed empty tags.
What Empty Tag Auto-Close Repair Does
Consider the following simple SGML document snippet:
<book> <para>This is the first paragraph.</para> <pgbrk> <para>This paragraph has a cross-reference <xref id="f563t001"> in some <italic>italic</italic> text.</para> </book>
This snippet incorporates two tags, <pgbrk> and <xref>, that are traditionally viewed as empty tags. Working under default settings, MarkLogic Server views each of these two tags as opening tags that at some point later in the document will be closed, and consequently incorrectly views the following content as children of those tags. This results in a falsely nested document (indentation and line breaks added for clarification):
<book> <para> This is the first paragraph. </para> <pgbrk> <para> This paragraph has a cross-reference <xref id="f563t001"> in some <italic>italic</italic> text. </xref> </para> </pgbrk> </book>
The bold characters in the markup shown above indicate closing tags automatically inserted by the general-purpose tag repair algorithm.
This example demonstrates how unclosed empty tags can distort the structure of a document. Imagine how much worse this example could get if it had fifty <pgbrk> tags in it.
To understand the ramifications of this, consider how the markup applied above is processed by a query that specifies an XPath such as /doc/para. The first paragraph matches this XPath, but the second does not, because it has been loaded incorrectly as the child of a pgbrk element. While alternative XPath expressions such as /doc//para gloss over this difference, it is better to load the content correctly in the first place (indentation and line breaks added for clarification):
<book> <para> This is the first paragraph. </para> <pgbrk/> <para> This paragraph has a cross-reference <xref id="f563t001"/> in some <italic>italic</italic> text. </para> </book>
Defining a Schema to Support Empty Tag Auto-Close Repair
To use empty tag auto-close repair, you first define an XML schema that specifies which tags should be assumed to be empty tags. Using this information, when MarkLogic Server is loading content from an external source, it automatically closes these tags as soon as they are encountered. If some of the specified tags are, in fact, accompanied by closing tags, these closing tags are discarded by the general-purpose tag repair algorithm.
Here is an example of a schema that instructs the loader to treat as empty tags any <xref>, <graphic> and <pgbrk> tags found in documents governed by the http://www.mydomain.com/sgml namespace:
<xs:schema targetNamespace="http://www.mydomain.com/sgml" xsi:schemaLocation="http://www.w3.org/2001/XMLSchema XMLSchema.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <xs:complexType name="empty"/> <xs:element name="xref" type="empty"/> <xs:element name="graphic" type="empty"/> <xs:element name="pgbrk" type="empty"/> </xs:schema>
If the sample SGML document shown earlier is loaded under the control of this schema, it is repaired correctly.
To use XML schemas for content repair, two things are required:
Invoking Empty Tag Auto-Close Repair
There are multiple ways to invoke the empty tag auto-close functionality. The recommended procedure is the following:
- Write an XML schema that specifies which tags should be treated as empty tags. The schema shown in the preceding section, Defining a Schema to Support Empty Tag Auto-Close Repair, is a good starting point.
- Load the schema into MarkLogic. See Loading Schemas in the Application Developer's Guide for instructions.
- Make sure that the content to be loaded references the namespace of the applicable schema that you have loaded into MarkLogic. For the schema shown above, the document's root element could take one of two forms.
In the first form, the document implicitly references the schema through its namespace:
<document xmlns="http://www.mydomain.com/sgml"> ... </document>
MarkLogic Server automatically looks for a matching schema whenever a document is loaded.
In the second form, one of multiple matching schemas can be explicitly referenced by the document being loaded:
<document xmlns="http://www.mydomain.com/sgml" xsi:schemaLocation="http://www.mydomain.com/sgml /sch/SGMLEmpty.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema"> ... </document>
This example explicitly references the schema stored at URI
/sch/SGMLEmpty.xsdin the current schema database. If there is no schema stored at that URI, or the schema stored at that URI has a target namespace other thanhttp://www.mydomain.com/sgml, no schema is used.See Loading Schemas in the Application Developer's Guide for an in-depth discussion of the precedence rules that are applied in the event that multiple matching schemas are found.
- Load the content using xdmp:document-load or one of the other language interface document insertion methods.
When it is not feasible to modify your content so that it properly references a namespace in its root element, there are other approaches that can yield the same result:
- Write an XMLschema that specifies which tags should be treated as empty tags. Because the root
xs:schemaelement lacks atargetNamespaceattribute, the document below specifies a schema that applies to documents loaded in the unnamed namespace:<xs:schema xsi:schemaLocation="http://www.w3.org/2001/XMLSchema XMLSchema.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <xs:complexType name="empty"/> <xs:element name="xref" type="empty"/> <xs:element name="graphic" type="empty"/> <xs:element name="pgbrk" type="empty"/> </xs:schema>
- Load the schema into MarkLogic, remembering the URI name under which you loaded the schema. See Loading Schemas in the Application Developer's Guide for instructions on properly loading schema in MarkLogic Server.
- Construct an XQuery statement that temporarily imports the schema into the appropriate namespace and loads the content within that context.
- A simple example of importing a schema into the unnamed namespace might look like the following:
xquery version "0.9-ml" import schema namespace "myNS" at "schema-uri-you-specified-in-step-2"; xdmp:document-load("content-to-be-repaired.sgml", ...)
Be careful to restrict the content loading operations you carry out within the context of this
import schemadirective, as all documents loaded in the unnamed namespace are filtered through the empty tag auto close repair algorithm under the control of this schema.The target namespace specified in the
import schemaprolog statement and in the schema document itself must be the same, otherwise the schema import fails silently.
- A simple example of importing a schema into the unnamed namespace might look like the following:
- Run the query shown above to load and repair the content.
Scope of Application
Once a schema is configured and loaded for empty tag auto-closing, any content that references that schema and is loaded from an external source is automatically repaired as directed by that schema.
Disabling Empty Tag Auto-Close
There are several ways to disable load-time empty tag auto-close repair:
- Disable content repair at load-time using the applicable option for your chosen language interface.
- Remove the corresponding schema from the database and ensure that none of the content to be loaded in the future still references that schema.
- Modify the referenced schema to remove the empty tag definitions.
Schema-Driven Tag Repair
MarkLogic Server supports the use of XML schemas for more complex schema-driven tag repair. This enables you to use XML schemas to define a set of general rules that govern how various elements interact hierarchically within an XML document.
What Schema-Driven Tag Repair Does
For example, consider the following SGML document snippet:
<book> <section><para>This is a paragraph in section 1. <section><para>This is a paragraph in section 2. </book>
This snippet illustrates one of the key challenges created by interpreting markup languages as XML. Under default settings, the server repairs and loads this content as follows (indentation and line breaks added for clarification):
<book> <section> <para> This is a paragraph in section 1. <section> <para>This is a paragraph in section 2.</para> </section> </para> </section> </book>
The repaired content shown above is almost certainly not what the author intended. However, it is all that the server can accomplish using only general-purpose tag repair.
Schema-driven content repair improves the situation by allowing you to indicate constraints in the relationships between elements by using an XML schema. In this case, you can indicate that a <section> element may only contain <para> elements. Therefore, a <section> element cannot be a child of another <section> element. In addition, you can indicate that <para> element is a simple type that only contains text. Using the schema, MarkLogic Server can improve the quality of content repair that it performs. For example, the server can use the schema to know that it should check to see if there is an open <section> element on the stack whenever it encounters a new <section> element.
The resulting repair of the SGML document snippet shown above is closer to the original intent of the document author:
<book> <section> <para> This is a paragraph in section 1. </para> </section> <section> <para> This is a paragraph in section 2. </para> </section> </book>How it works
To take advantage of schema-driven tag repair, you must first define an XML schema that describes the constraints on the relationships between elements. Using this information, when tMarkLogic Server loads content from an external source, it automatically closes tags still open on its stack when it encounters an open tag that would violate the specified constraints.
Unlike general-purpose tag repair, which is triggered by unexpected closing tags, schema-driven tag repair is triggered by unexpected opening tags, so the two different repair models interoperate cleanly. In the worst case, schema-driven tag repair may, as directed by the governing schema for the document being loaded, automatically close an element sooner than that element is explicitly closed in the document itself. This case only occurs when the relationship between elements in the document is at odds with the constraints described in the schema, in which case the schema is used as the dominating decision factor.
The following is an example of a schema that specifies the following constraints:
<book>elements in thehttp://www.mydomain.com/sgmlnamespace can only contain<section>elements.<section>elements in thehttp://www.mydomain.com/sgmlnamespace can only contain<para>elements.<para>elements in thehttp://www.mydomain.com/sgmlnamespace can only contain text.<xs:schema targetNamespace="http://www.mydomain.com/sgml" xsi:schemaLocation="http://www.w3.org/2001/XMLSchema XMLSchema.xsd" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <xs:complexType name="book"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="section"/> </xs:choice> </xs:complexType> <xs:complexType name="section"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="para"/> </xs:choice> </xs:complexType> <xs:element name="book" type="book"/> <xs:element name="section" type="section"/> <xs:element name="para" type="xs:string"/> </xs:schema>
If the sample SGML document shown above is loaded under the control of this simple schema, it is corrected as specified.
How to Invoke Schema-Driven Tag Repair
There are multiple ways to do schema-driven correction. The recommended procedure is the following:
- Write an XML schema that describes the relationships between the elements.
- Load the schema into MarkLogic Server. See Loading Schemas in the Application Developer's Guide for instructions.
- In the content that you need to load, ensure that the root element properly references the appropriate schema. See Invoking Empty Tag Auto-Close Repair for examples of referencing the XML schema from inside the content.
- Load the content using xdmp:document-load or any of the other available document insertion methods.
If it is not feasible to modify the content so that it properly references the XML schema in its root element, there are other approaches that can yield the same result:
- Write a schema that describes the relationships between the elements, and omit a
targetNamespaceattribute from itsxs:schemaroot element. - Load the schema into MarkLogic Server, remembering the URI name under which you store the schema. See Loading Schemas for instructions on properly loading schema in MarkLogic Server.
- Construct an XQuery statement that temporarily imports the schema into the appropriate namespace and loads the content within that context. Following is a simple example of importing a schema into the unnamed namespace:
xquery version "0.9-ml" import schema namespace "myNS" at "schema-uri-you-specified-in-step-1"; xdmp:document-load("content-to-be-repaired.sgml", ...)
Be careful to restrict the content loading operations you carry out within the context of this
import schemadirective, as all documents loaded are filtered through the same schema-driven content repair algorithm.The target namespace specified in the
import schemaprolog statement and in the schema document itself must be the same, otherwise the schema import fails silently. - Run the query shown above to load and repair the content.
Scope of Application
Once a schema has been configured and loaded for schema-driven tag repair, any content that references that schema and is loaded from an external source is automatically repaired as directed by that schema.
Disabling Schema-Driven Tag Repair
There are several ways to turn off load-time schema-driven tag repair:
- Disable content repair at load-time using the appropriate parameter for your chosen content loading mechanism.
- Remove the corresponding schema from the database and ensure that none of the content loaded in the future references that schema.
- Modify the referenced schema to remove the empty tag definitions.
Load-Time Default Namespace Assignment
When documents are loaded into MarkLogic, every element is stored with a QName comprised of a namespace URI and a local name.
However, many XML files are authored without specifying a default namespace or a namespace for any of their elements. When these files are loaded from external sources , MarkLogic applies the default unnamed namespace to all the nodes that do not have an associated namespace.
In some situations this is not the desired result. Once the document is loaded without a specified namespace, it is difficult to remap each QName to a different namespace. It is better to load the document into MarkLogic Server with the correct default namespace in the first place.
The best way to specify a default namespace for a document is to add a default namespace attribute to the document's root node directly. When that is not possible, MarkLogic's load-time namespace substitution capability offers a good solution. If you are using XQuery or XCC for your document loading, you can specify a default namespace for the document at load-time, provided that the document root node does not already contain a default namespace specification.
This function is performed as described below if a default namespace is specified at load time, even if content repair is turned off.
The REST and Java client APIs do not provide a default namespace option. When you use these APIs for your document loading, it is best to add the appropriate namespace attribute to your documents before loading them to the database.
How Default Namespace Assignments Work
The xdmp:document-load function and the XCC setNamespace method (in the ContentCreateOptions class) allow you to optionally specify a namespace as the default namespace for an individual document loading operation.
MarkLogic uses that namespace definition as follows:
Rule 1: If the root node of the document does not contain the default namespace attribute, the server uses the provided namespace as the default namespace for the root node. The appropriate namespaces of descendant nodes are then determined through the standard namespace rules.
Rule 2: If the root node of the document incorporates a default namespace attribute, the server ignores the provided namespace.
Note that rule 2 means that the default namespace provided at load time cannot be used to override an explicitly specified default namespace at the root elementScope of Application
You can specify default namespaces at load-time when you use XQuery or XCC to load content. See the corresponding documentation for further details.
Load-Time Namespace Prefix Binding
The original XML specifications allow the use of colons in element names, for example, <myprefix:a>. However, according to the XML Namespace specifications (developed after the initial XML specifications), the string before a colon in an element name is interpreted as a namespace prefix. The use of prefixes that are not bound to namespaces is deemed as non-compliant with the XML Namespace specifications.
Prior to version 2.1, MarkLogic Server dropped unresolved prefixes from documents loaded into the database in order to conform to the XML Namespace specifications. Consider a document named mybook.xml that contains the following content:
<publisher:book> <section> This is a section. </section> </publisher:book>
If publisher is not bound to any namespace, mybook.xml is loaded into the database as:
<book> <section> This is a section. </section> <book>
Starting in 2.1, MarkLogic Server supports more powerful correction of XML documents with unresolved namespace bindings. If content repair is on, mybook.xml is loaded with a namespace binding added for the publisher prefix.
<publisher:book xmlns:publisher="appropriate namespace-see details below"> <section> This is a section. </section> </publisher:book>
If content repair is off, MarkLogic Server returns an error if unresolved namespace prefixes are encountered at load time.
How Load-Time Namespace Prefix Binding Works
If content repair is enabled, MarkLogic can create namespace bindings at load time for namespace prefixes that would otherwise be unresolved.
Namespace prefixes are resolved using the rules below. The rules are listed in order of precedence:
Rule 1: When the prefix is specified in the document, that binding is retained. In the following example, the binding for publisher to "http://publisherA.com" is specified in the document and is retained.
<publisher:book xmlns:publisher="http://publisherA.com"> <section> This is a section. </section> </publisher:book>
Rule 2: When the prefix is declared in the XQuery environment, that binding is used. For example, suppose that mybook.xml, the document being loaded, contains the following content:
<publisher:book> <section> This is a section. </section> </publisher:book>
In addition, suppose that publisher is bound to http://publisherB.com in the XQuery environment:
declare namespace publisher = "http://publisherB.com" xdmp:document-load("mybook.xml")
The code snippet loads the mybook.xml as:
<publisher:book xmlns:publisher="http://publisherB.com"> <section> This is a section. </section> </publisher:book>
This rule only applies in the XQuery environment.
Rule 3: If the prefix is declared in the Admin Interface for the HTTP or XDBC server through which the document is loaded, that binding is used.
For example, imagine a scenario in which the namespace prefix publisher is defined on the HTTP server named Test.
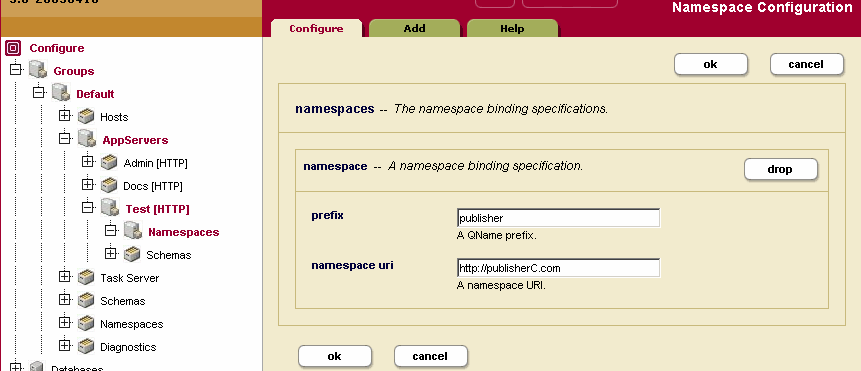
Then, suppose that the following code snippet is executed on Test:
xdmp:document-load("mybook.xml")
The initial document mybook.xml as shown in the second case is loaded as:
<publisher:book xmlns:publisher="http://publisherC.com"> <section> This is a section. </section> </publisher:book>
Rule 4: If no binding for the prefix is found, the server creates a namespace that is the same as the prefix and binds it to the prefix. In this instance, mybook.xml is loaded as:
<publisher:book xmlns:publisher="publisher"> <section> This is a section. </section> </publisher:book>
Interaction with Load-Time Default Namespace Assignment
While both load-time default namespace assignment and load-time namespace prefix binding involve document namespaces, the two features work independently. The former allows the assignment of a default namespace at the root element level, while the latter creates bindings for namespaces that are otherwise unresolved.
- This document has neither a binding for the
publisherprefix, nor a default namespace.<publisher:book> <section> This is a section. </section> </publisher:book>
Suppose a default namespace
http://publisher.com/default-namespaceis specified at load time, and the publisher prefix resolves tohttp://publisher.com/prefixaccording to the rules described in the previous section. The document is loaded as:<publisher:book xmlns:publisher="http://publisher.com/prefix" xmlns="http://publisher.com/default-namespace"> <section> This is a section. </section> </publisher:book>
In this case,
<book>is in the"http://publisher.com/prefix"namespace, while<section>is in the"http://publisher.com/default-namespace"namespace. - This document has a binding for the
publisherprefix, but does not specify a default namespace in the root node.<publisher:book xmlns:publisher="http://publisher.com/prefix"> <section> This is a section. </section> </publisher:book>
If
http://publisher.com/default-namespaceis specified as the default namespace at load time, the loaded document is the same as the document loaded in the example above. - This document specifies a default namespace, but does not contain a binding for the publisher prefix, this time, associated with the
<section>element.<book xmlns="http://publisher.com/original-namespace"> <publisher:section> This is a section. <paragraph> This is a paragraph. </paragraph> </publisher:section> </book>
If a default namespace
http://publisher.com/default-namespaceis specified at load time, it is ignored. Assume that publisher resolves topublisher. The document is loaded as shown below:<book xmlns="http://publisher.com/original-namespace"> <publisher:section xmlns:publisher="publisher"> This is a section. <paragraph> This is a paragraph. </paragraph> </publisher:section> </book>
<book> and <paragraph> elements are in the default namespace http://publisher.com/original-namespace, while the <section> element is in the publisher namespace.Scope of Application
If content repair is enabled, MarkLogic attempts to create bindings for unresolved namespace prefixes as a form of content repair for all documents loaded from external sources according to the rules described in How Load-Time Namespace Prefix Binding Works.
Disabling Load-Time Namespace Prefix Binding
MarkLogic enables you to disable content repair during any individual document load using a language specific repair parameter. See Programming Interfaces and Supported Content Repair Capabilities.
Query-Driven Content Repair
The content repair models described above influence the content as it is loaded, trying to ensure that the structure of the poorly or inconsistently formatted content is as close to the author's intent as possible when it is first stored in the database.
When a situation requires content repair that is beyond the scope of some combination of these four approaches, MarkLogic's schema-independent core makes XQuery itself a powerful content repair mechanism.
Once a document is loaded into MarkLogic, queries can be written to specifically restructure the content as required, without needing to reconfigure the database. Two approaches to query-driven content repair -- point repair and document walkers -- are described in the following sections. If you want to do something similar from other languages, use a transformation, a feature of the REST and Java client API's that lets you install XQuery or XSLT that you can use during document loading and retrieval.
Point Repair
Point repair uses XPath-based queries to identify document subtrees of interest, create repaired content structures from the source content, and then call xdmp:node-replace to replace the document subtree of interest. A simple example of such a query follows:
for $node-to-be-repaired in doc($uri-to-be-repaired)//italic return xdmp:node-replace($node-to-be-repaired, <i>{ $node-to-be-repaired/* }</i>)
This example code finds every element with local name italic in the default element namespace and changes its QName to local name i in the default element namespace. All of the element's attributes and descendants are inherited as is.
An important constraint of the XQuery shown above lies in its assumption that italic elements cannot be descendants of other italic elements, a constraint that should be enforced at load-time using schema-driven content repair. If such a situation occurs in the document specified by $uri-to-be-repaired, the above XQuery generates an error.
Document Walkers
Document walkers use recursive descent document processing functions written in XQuery to traverse either the entire document or a subtree within it, create a transformed (and appropriately repaired) version of the document, and then call xdmp:document-insert or xdmp:node-replace to place the repaired content back into the database.
Queries involving document traversal are typically more complex than point repair queries, because they deal with larger overall document context. Because they can also traverse the entire document, the scope of repairs that they can address is also significantly broader.
The walk-tree function shown here uses a recursive descent parser to traverse the entire document:
xquery version "1.0-ml"; declare function local:walk-tree( $node as node()) as node() { if (xdmp:node-kind($node) = "element") then (: Reconstruct node and its attributes; descend to its children :) element { fn:node-name($node) } { $node/@*, for $child-node in $node/node() return local:walk-tree($child-node) } else if (xdmp:node-kind($node) = "comment" or xdmp:node-kind($node) = "processing-instruction" or xdmp:node-kind($node) = "text") then (: Return the node as is :) $node else if (xdmp:node-kind($node) = "document") then document { (: Start descent from the document node's children :) for $child-node in $node/node() return local:walk-tree($child-node) } else (: Should never get here :) fn:error( fn:concat("Error: Could not process node of type '", xdmp:node-kind($node), "'") ) }; let $node := text {"hello"} return local:walk-tree($node) (: returns the text node containing the string "hello" :)
This function can be used as the starting point for any content repair query that needs to walk the entire document in order to perform its repair. By inserting further checks in each of the various clauses, this function can transform both the structure and the content. For example, consider the following modification of the first if clause:
if (xdmp:node-kind($node) = "element") then (: Reconstruct node and its attributes; descend to its children :) element { if (fn:local-name($node) != "italic") then fn:node-name($node) else fn:QName(fn:namespace-uri($node), "i") } { $node/@*, for $child-node in $node/node() return local:walk-tree($child-node) }
Inserting this code into the walk-tree function enables the function to traverse a document, finding any element whose local-name is italic, regardless of that element's namespace, and change that element's local-name to i, keeping its namespace unchanged.
You can use the above document walker as the basis for complex content transformations, effecting content repair using the database itself as the repair tool once the content has been loaded into the database.
Another common design pattern for recursive descent is to use a typeswitch expression. For details, see Transforming XML Structures With a Recursive typeswitch Expression in the Application Developer's Guide.