
Search Developer's Guide — Chapter 2
Search API: Understanding and Using
This chapter describes the Search API, which is an XQuery API designed to make it easy to create search applications that contain facets, search results, and snippets. This chapter includes the following sections:
- Understanding the Search API
- Controlling a Search With Query Options
- Search Term Completion Using search:suggest
- Creating a Custom Constraint
- Search Grammar
- Returning Lexicon Values With search:values
- JSON Support in the Search API
- More Search API Examples
This chapter provides background, design patterns, and examples of using the Search API. For the function signatures and descriptions, see the Search documentation under XQuery Library Modules in the MarkLogic XQuery and XSLT Function Reference.
Understanding the Search API
The Search API is an XQuery library that combines searching, search parsing, search grammar, faceting, snippeting, search term completion, and other search application features into a single API. You can interact with the Search API through XQuery, REST, Node.js, and Java, using a variety of query styles, as described in Support for Multiple Query Styles.
The Search API makes it easy to create search applications without needing to understand many of the details of the underlying cts:search and cts:query APIs. The Search API is designed for large-scale, production applications.
This section provides an overview and describes some of the features of the Search API, and contains the following topics:
- Making the Search API Available to Your Application
- Simple search:search Example and Response Output
- Automatic Query Text Parsing and Grammar
- Constrained Searches and Faceted Navigation
- Built-In Snippetting
- Search Term Completion
- Search Customization Via Options and Extensions
- Speed and Accuracy
Making the Search API Available to Your Application
The Search API is implemented as an XQuery library module. You can use it directly from XQuery. You can also access most of the Search API features through the REST, Node.js, and Java Client APIs; for details, see REST Application Developer's Guide, Node.js Application Developer's Guide, or Java Application Developer's Guide. Server-Side JavaScript applications can access similar features through the JSearch library; for details, see Creating JavaScript Search Applications.
To use the Search API from XQuery, import the Search API library module into your XQuery module with the following prolog statement:
import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy";
The Search API uses the namespace prefix search:, which is not predefined in the server. The Search API has the following core functions to perform searches and provide search results, snippets, and query-completion suggestions: search:search, search:snippet, and search:suggest. There are also other functions to perform these activities at finer granularities and to provide convenience tools.
For the Search API function signatures and details about each individual function, see the MarkLogic XQuery and XSLT Function Reference for the Search API.
Simple search:search Example and Response Output
The search:search function takes search terms, parses them into an appropriate cts:query, and returns a response with snippets and URIs for matching nodes in the database. You can get started with the Search API with a very simple query:
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; search:search("hello world") => <search:response total="1" start="1" page-length="10" xmlns="" xmlns:search="http://marklogic.com/appservices/search"> <search:result index="1" uri="/hello.xml" path="doc("/hello.xml")" score="136" confidence="0.67393" fitness="0.67393"> <search:snippet> <search:match path="doc("/hello.xml")/hello">This is where you say "<search:highlight>Hello</search:highlight> <search:highlight>World</search:highlight>". </search:match> </search:snippet> </search:result> <search:qtext>hello world</search:qtext> <search:metrics> <search:query-resolution-time>PT0.328S </search:query-resolution-time> <search:total-time>PT0.352S</search:total-time> </search:metrics> </search:response>
The output is a search:response element, and it contains everything needed to build a search results page. It includes an estimate of the total number of documents that match the search, the URI and XPath for each result, pagination of the search results, a snippet of the result content, the original query text submitted, and metrics on the response time. You can customize the data returned in each search:result using the result-decorator query option.
To try the Search API on your own content, run a simple search like the above example against a database of your own content, and then examine the search results.
The search:search function is highly customizable, but by default it includes sensible settings that will provide good results for many applications. With the results of search:search, it is easy to build useful results pages that are as simple or as complex as you like.
Automatic Query Text Parsing and Grammar
In a typical search application, a user enters query text into a search box in a browser. This text is a string query. The Search API automatically parses a string query into a cts:query for efficient and powerful searches. You can use string queries in XQuery, Java, Node.js, and REST, through interfaces such as the following:
- XQuery: The
search:search, search:parse, and search:resolvefunctions - Java: The
com.marklogic.client.query.QueryManagerclass - Node.js: The
DatabaseClient.documents.queryandqueryBuilder.parsedFromfunctions. - REST: The
/searchservice
The default string query grammar is similar to the Google grammar. The default grammar supports simple terms and double-quoted phrases, logical and relational operators (AND, OR, LT, GT), grouping with parentheses ( ( ) ), negation with a minus sign ( - ), and user-configured constraints with a colon ( : ).
The following is a summary of the default grammar. For details, see The Default String Query Grammar.
- Terms can be free standing:
cat
ANDandORoperators, withANDhaving higher precedence.- Parentheses can override default precedence:
(cat OR dog) AND horse
- Multiple terms are combined as an
AND:cat dog
- Phrases are surrounded by double-quotes:
"cat and dog"
- Terms are excluded through a leading minus:
cat ...Äìdog
- Colon operators indicate configured constraint or operator searches (for details, see Constraint Options and Operator Options):
tag:value
- Constraint and operator searches may operate over phrases:
tag:"a phrase value"
- A query text can comprise any number of these types of searches in any order.
- The default precedence for a search order provides preference to explicitly ordered (with parenthesis, for example) then for implicitly ordered. Therefore, multi-term queries using the explicit
ANDoperator do not parse as equivalent to the same string using the implicitANDbecause there is a difference in the way that precedence is applied. For example,A OR B AND Cparses to the equivalent ofA OR (B AND C), whileA OR B Cparses to the equivalent of(A OR B) and C.
String query parsing takes into account constraints and operators specified in an options node at search runtime. For details on the options node for the Search API, see Controlling a Search With Query Options.
Constrained Searches and Faceted Navigation
The Search API makes it easy to constrain your searches to a subset of the content. For example, you can create a search that only returns results for documents with titles that include the word hello, or you can create a search that constrains the results to a particular decade. The default string query grammar makes it easy to express these kinds of searches in a simple query text string. For example, you create a constraint through query options such that the following string query represents a search that constrains matches to a particular decade:
decade:2000s
These types of searches are useful in creating facets, which allow a user to drill down by narrowing the search criteria. Facets also typically have counts of the number of results that match. The Search, REST, Node.js, and Java Client APIs return these counts to use in facets.
The following is an example of a facet in an end-user application:
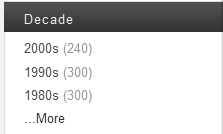
Users can click on any of the links to narrow the results of the search by decade. For example, the query generated by clicking the top link contains the string decade:2000s, and constrains the search to that decade.
The facet also includes counts for each constraint value. The number to the right of the link represents the number of search results returned if you constrain it to that decade.
The Search API returns XML in its response that contains all of the information to create a facet like the above example. The REST and Java Client APIs can return this information as XML or JSON; the Node.js Client API returns this information as JSON.
The facets returned by a search include the counts and values needed to generate the user interface. For example, the following XML, returned from the Search API, was used to create the above facet:
<search:response total="2370" start="1" page-length="10" xmlns="" xmlns:search="http://marklogic.com/appservices/search"> <search:facet name="decade"> <search:facet-value name="2000s" count="240"> 2000s</search:facet-value> <search:facet-value name="1990s" count="300"> 1990s</search:facet-value> <search:facet-value name="1980s" count="300"> 1980s</search:facet-value> <search:facet-value name="1970s" count="300"> 1970s</search:facet-value> <search:facet-value name="1960s" count="299"> 1960s</search:facet-value> <search:facet-value name="1950s" count="300"> 1950s</search:facet-value> <search:facet-value name="1940s" count="324"> 1940s</search:facet-value> <search:facet-value name="1930s" count="245"> 1930s</search:facet-value> <search:facet-value name="1920s" count="61"> 1920s</search:facet-value> </search:facet> </search:response>
The counts and values in the response are also filtered by any other active query in the search, so they represent the counts for that particular search.
You can generate facets from range, collection, geospatial, and custom constraints. To generate facets from a constraint and include them in your search results, set the facet XML attribute or JSON property to true on a constraint definition in your search options. For example:
<options xmlns="http://marklogic.com/appservices/search"> <constraint name="subject"> <collection prefix="/my-collections/" facet="true" /> </constraint> </options>
For more details, see Appendix: Query Options Reference.
There are many kinds of constraints and facets you can build with the Search, REST, and Java APIs. For more details about constraints, see Constraint Options.
Built-In Snippetting
A search results page typically shows portions of matching documents with the search matches highlighted, perhaps with some text showing the context of the search matches. These search result pieces are known as snippets. For example, a search for MarkLogic Server might produce the following snippet:
MarkLogic Server is an XML Server that provides the agility you need to build and ... Use MarkLogic Server's geospatial capability to create new dynamic ...
The Search API and the Node.js, Java, and REST Client APIs include snippets in the search:response output, making it easy to create search results pages that show the matches in the context of the document. Providing the best snippet for a given content set is often very application specific, however. Therefore, the Search API allows you to customize the snippets, either using the built-in snippetting algorithm or by adding your own snippetting code. For details on ways to customize the snippetting behavior for your searches, see Modifying Your Snippet Results.
Search Term Completion
Search applications often offer suggestions for search terms as the user types into the search box. The suggestions are based on terms that are in the database, and are typically used to make the user interface more interactive and to quickly suggest search terms that are appropriate to the application. The search:suggest function in the Search API is designed to supply the terms to a search-completion user interface. For more details on how to use search term completion, see Search Term Completion Using search:suggest.
Search Customization Via Options and Extensions
The Search, REST and Java APIs make it easy to customize your searches. A wide range of customizations are available directly through the query options that you pass into the search. There are a large number of options controlling nearly every aspect of the search you are performing.
For cases where the built-in options do not do what you need, there is an XQuery extension mechanism. The mechanism includes hooks which allow you to call out to your own XQuery code. The hooks allow you to specify the location and name of the function containing your own implementation of a function to replace the implementation of that function in the Search API. The Search API uses function values to pass your custom function as a parameter, replacing the default Search API functionality. For details on function values, see Function Values in the Application Developer's Guide.
The basic pattern to specify your extension function using the attributes apply, ns, and at as attributes on various elements in the search:options node. These correspond to the local name of your implemented function, the namespace of the function, and the location of the function library module in which the code exists, respectively. For example, consider the following:
<transform-results apply="my-snippet" ns="my-namespace" at="/my-module.xqy" />
In this example, the transform-results option specifies to use the my-snippet function in the library module my-module under your App Server root instead of the default snippeting function that the Search API uses. For additional details about working with transform-results, see Modifying Your Snippet Results.
Any search option that has an apply attribute can use this extension pattern to point to your own implementation for the functionality of that option, including transform-results, several grammar options, custom constraints, and so on.
Speed and Accuracy
The Search API, and the Client APIs (Node.js, Java, REST) that build upon it, are designed to be fast. When creating any search application, you make trade-offs between speed and guaranteed accuracy. The values of various options in the Search API control things like filtered versus unfiltered search, diacritic and case-sensitivity, and other options. These options affect the accuracy of search estimates in MarkLogic Server. The default values of these query options are designed to be sensible for most application. All applications are different, however, and MarkLogic gives you the tools to control what makes sense for your specific application.
Range constraints use lexicons to get fast accurate unique values and counts. Keep in mind, however, that certain operations might not produce accurate counts in all cases. For example, when you pass a cts:query into a lexicon API (which the Search API does in some cases), it filters the lexicon calls based on the index resolution of the cts:query, not on the filtered search values, and the index resolution is not guaranteed to be accurate for all queries. For details on how search index resolution works, see Fast Pagination and Unfiltered Searches in Query Performance and Tuning Guide.
Other factors such as fragmentation and what you search for (searchable-expression in the Search API options) can also contribute to whether the index resolution for a search is correct, as can various options to lexicons. The default values for these various options make the trade-offs that are sensible for many search applications. For example, the value of the total attribute in the search:response output is the result of a cts:remainder, which will always be fast but is not guaranteed to be accurate for all searches. For details, see Using fn:count vs. xdmp:estimate.
Controlling a Search With Query Options
Most search operations in the XQuery Search API and the Client APIs make use of optional query options. Query options enable you to specify the behavior and results format for a search. Default query options are pre-defined. You can override the defaults by supplying custom query options. For example, the XQuery function search:search accepts a search:options XML node as input.
The REST and Java Client APIs supports query options expressed in either JSON or XML. The Node.js Client API abstracts the representation from your application, but in most cases, this API uses the JSON representation.
For more details, see Search Customization Using Query Options and Appendix: Query Options Reference.
Search Term Completion Using search:suggest
The search:suggest function returns suggestions that match a wildcarded string, and it is used in query-completion applications.
A typical way to use the search:suggest function in an application is to have a Javascript event listen for changes in the text box, and then upon those changes it asynchronously submits a search:suggest call to MarkLogic Server. The result is that, after every letter is typed in, new suggestions appear in the user interface. The remainder of this sections describes the following details of the search:suggest function:
- default-suggestion-source Option
- Choose Suggestions With the suggestion-source Option
- Use Multiple Query Text Inputs to search:suggest
- Make Suggestions Based on Cursor Position
- search:suggest Examples
For information on using this feature with the Client APIs, see the following:
- REST: Generating Search Term Completion Suggestions in the REST Application Developer's Guide.
- Java: Generating Search Term Completion Suggestions in the Java Application Developer's Guide.
- Node.js: Generating Search Term Completion Suggestions in the Node.js Application Developer's Guide.
default-suggestion-source Option
To use search:suggest, it is best to specify a default-suggestion-source. The Search API uses the default-suggestion-source to look for search term suggestions. If no default-suggestion-source is specified, then any call to search:suggest returns only suggestions for constraints and operators, or if there are none, then it returns the empty sequence. The search:suggest function suggests constraint and operator names if they match the query text string, and in the case of range index-based constraints, it will suggest matching constraint values. For details on the syntax of the default-suggestion-source option, see the search:search options documentation in the MarkLogic XQuery and XSLT Function Reference.
For best performance, especially on large databases, use with a default-suggestion-source with a range or collection instead of one with a word lexicon.
The following default-suggestion-source example uses the string range index on the attribute named my-attribute as a source for suggesting terms. Range suggestion sources tend to perform the best, especially for large databases. The range index must exist or an exception is thrown at search runtime.
<default-suggestion-source> <range type="xs:string"> <element ns="my-namespace" name="my-localname"/> <attribute ns="" name="my-attribute"/> </range> </default-suggestion-source>
The following example specifies using a field lexicon to look for search term suggestions. Fields can work well for suggestion sources, especially if the field is a relatively small subset of the whole database. A field word lexicon for the specified field must exist or an exception is thrown at search runtime.
<default-suggestion-source> <word collation="http://marklogic.com/collation/"> <field name="my-field"/> </word> </default-suggestion-source>
For more details, see default-suggestion-source.
Choose Suggestions With the suggestion-source Option
For some applications, you want to have a very specific list from which to choose suggestions for a particular constraint. For example, you might have a constraint named name that has millions of unique values, but perhaps you only want to make suggestions for a specific 500 of them. In such cases, you can specify the suggestion-source option to override the suggestions that search:suggest returns for query text matching values in that constraint.
You specify the constraint to override in the in the name attribute of the suggestion-source element. For example, the following options specify to use the values from the short-list-name element instead of from the name element when make suggestions for the name constraint.
<constraint name="name"> <range collation="http://marklogic.com/collation" type="xs:string" facet="true"> <element ns="my-namespace" name="fullname"/> </range> </constraint> <suggestion-source ref="name"> <range collation="http://marklogic.com/collation" type="xs:string" facet="true"> <element ns="my-namespace" name="short-list-name"/> </range> </suggestion-source>
For cases where you have a named constraint to use for searching and facets, but might want to use a slightly (or completely) different source for type-ahead suggestions without needing to re-parse your search terms, use the suggestion-source option.
If you want a particular constraint to not return suggestion, add an empty suggestion-source for that constraint:
<suggestion-source ref="socialsecuritynumber" />
For more details, see suggestion-source.
Use Multiple Query Text Inputs to search:suggest
You can specify one or more query text parameters to search:suggest. When you specify a sequence of more than one query text for search:search, the first item (or the one corresponding to the $focus parameter) specifies the text to match against the suggestion source. Each of the other items in the sequence is parsed as a cts:query, and that query is used to constrain the search suggestions from the text-matching query text. Note that this is different from the other Search API functions, which combine multiple query texts with a cts:and-query.
Consider a user interface that looks as follows:
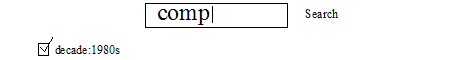
The search text box on top is where the user types text. The lower check box might be another control that the user can use to specify the decade. The decade:1980s text shown might be the query text that is the result of that user interface control (possibly from a facet, for example). You can then construct a search:suggest call from this user interface that uses the decade:1980s text as a constraint to the terms matching comp (from the specified suggestion source). The following is a search:suggest call that can be generated from this example:
search:suggest(("comp", "decade:1980s"), $options)
This ends up returning suggestions that match comp* on fragments that match search:parse("decade:1980s"). For example, it might return a sequence including the words competent, component, and computer.
Make Suggestions Based on Cursor Position
The search:suggest function makes search suggestions based on the position of the cursor (which you specify with the $cursor-position parameter. The idea is that when the user changes the cursor position, you should suggest terms based on where the user is currently entering text.
search:suggest Examples
The following are some example search:suggest queries with sample output.
Assume a constraint named filesize for the following example:
search:suggest("fi", $options) (: Returns the "filesize" constraint name first, followed by words from the default source of word suggestions: ("filesize:", "field", "file", "fitness", "five",) :)
The following example shows how search:suggest works with bucketed range constraints:
(: Assume $options contains the following: <constraint name="date"> <range type="xs:dateTime"> <bucket name="today"> <bucket name="yesterday"> <bucket name="thismonth"> <bucket name="thisyear"> ... :) search:suggest("date:", $options) (: bucket names from the "date" range constraint are used to create suggestions ("date:thismonth", "date:thisyear", "date:today", "date:yesterday") :)
Creating a Custom Constraint
By default, the Search API supports many, but not all, types of constraints. If you need to create a constraint for which there is not one pre-defined in the Search API, there is a mechanism to extend the Search API to use your own constraint type. This type of constraint, called a custom constraint, requires you to write XQuery functions to implement your own custom parsing and to generate your own custom facets. You specify your function implementations in the options XML as follows:
<constraint name="my-custom"> <custom facet="true"> <!-- or false --> <parse apply="parse" ns="..." at="..." /> <start-facet apply="start" ns="..." at="..." /> <finish-facet apply="finish" ns="..." at="..." /> </custom> </constraint>
The three functions you need to implement are parse, start-facet, and finish-facet. The apply attribute specifies the local name of the function, the ns attribute specifies the namespace, and the at attribute specifies the location of the module containing the function. This section describes how to create a custom constraint and includes some example code for creating a custom geospatial constraint. This section includes the following parts:
- Implementing the parse Function
- Implementing the start-facet Function
- Implementing the finish-facet Function
- Example: Creating a Simple Custom Constraint
- Example: Creating a Custom Constraint for Structured Queries
- Example: Creating a Custom Constraint Geospatial Facet
Implementing the parse Function
The purpose of the parse function is to parse the custom constraint and generate the correct cts:query from the query text.
This section covers the following topics:
- Choosing a Parser Interface
- Implementing a String Query parse Function
- Implementing a Structured Query parse Function
- Implementing a Multi-Format parse Function
Choosing a Parser Interface
The signature of your constraint parsing function varies depending on the type of query input (string query or structured query) and the API through which you make your queries.
If your constraint can be used in queries initiated from XQuery, such as by calling cts:search or search:search, choose one of the following solutions:
- If the input is always a string query, see Implementing a String Query parse Function.
- If the input is always a structure query, see Implementing a Structured Query parse Function.
- If the input can be either a string or structured query, see Implementing a Multi-Format parse Function.
If your constraint is only used in queries initiated through the REST, Java, or Node.js Client API and never through XQuery, you can use the structured query parse interface to service both string and structured queries; your query is converted internally as needed. The selections described above for XQuery are also usable with the REST, Node.js and Java Client APIs.
Implementing a String Query parse Function
For parsing your custom constraint in a string query, the custom function you implement must have a signature compatible with the following signature:
declare function example:parse-string( $constraint-qtext as xs:string, $right as schema-element(cts:query)) as schema-element(cts:query)
You can use any namespace and local name for the function, but the number and order of the parameters must be compatible and the return type must be compatible.
The $constraint-qtext parameter is the constraint name and joiner part of the query text for the portion of the query pertaining to this constraint. For example, if the constraint name is geo and the joiner is the default joiner, then the value of $constraint-qtext will be geo:. The $constraint-qtext value is used in the qtextconst attribute, which is needed by search:unparse to re-create the query text from the annotated cts:query.
The $right parameter contains the value of the constraint parsed as a cts:query. In other words, it is the text to the right of what is passed into $constraint-qtext in the query text, and then that text is parsed by the Search API as a cts:query, and returned to the parse function as the XML representation of a cts:query. The value of $right is what the parse function uses for generating its custom cts:query. For details on how cts:query constructors work, see Composing cts:query Expressions.
The parse function you implement takes the cts:query from the $right parameter, parses it as you see fit, and then returns a cts:query XML element. For example, if the value of $right is as follows:
<cts:word-query> <cts:text>1@2@3@4</cts:text> </cts:word-query>
Your code must process the cts:text element to construct the cts:query you need. For example, you can tokenize on the @ character of the cts:text element, then use each value to construct a part of the query. As part of constructing the cts:query, you can optionally add cts:annotation elements and annotation attributes to the cts:query you generate. These annotations allow the Search API to unparse the cts:query back into its original form. If you do not add the proper annotations, then search:unparse might not return the original query text. For a sample function that does something similar, see Example: Creating a Custom Constraint Geospatial Facet.
Implementing a Structured Query parse Function
To use a custom constraint in a structured query, your custom parse function must have a signature compatible with the following:
declare function example:parse-structured( $query-elem as element(), $options as element(search:options)) as schema-element(cts:query)
You can use any namespace and local name for the function, but the number and order of the parameters must be compatible and the return type must be compatible. For a full example, see Example: Creating a Custom Constraint for Structured Queries.
The $query-elem parameter is custom-constraint-query structured query that references your constraint. For details, see custom-constraint-query.
The custom constraint can return either a cts:query or the XML serialization of a cts:query. MarkLogic recommends that you return a cts:query.
Implementing a Multi-Format parse Function
You can create a single parse function capable of handling either a string query or a structured query as input by generalizing the parse function interface to accomodate both and using the XQuery instance of operator to determine the query type.
The following parse function skeleton generalizes the input query as an item() and the second parameter, which can be either a cts:query or search:options, to element(), and then uses instance of to detect the actual input query type:
declare function example:combo-parser( $query as item(), $right-or-option as element()) as schema-element(cts:query) { if ($query instance of element(search:query)) then ... (: handle as structured query :) else if ($query instance of xs:string) then ... (: handle as string query :) else ... (: error :) };
Once you determine the input query type, coerce the second parameter to the correct type and parse your query as you would in the appropriate string or structured query parse function, as described in Implementing a String Query parse Function and Implementing a Structured Query parse Function.
Implementing the start-facet Function
The sole purpose of the start-facet function is to make a lexicon API call that returns the values and counts that are used in constructing a facet. For details on lexicons, see Browsing With Lexicons. The custom function you implement must have a signature compatible with the following signature:
declare function my-namespace:start-facet( $constraint as element(search:constraint), $query as cts:query?, $facet-options as xs:string*, $quality-weight as xs:double?, $forests as xs:unsignedLong*) as item()*
You can use any namespace and local name for the function, but the number and order of the parameters must be compatible and the return type must be compatible.
Each of the parameters is passed into the function by the Search API. The $query parameter includes any custom query your parse function implements, combined with any other query that the Search API generates (which depends on other options passed into the original search such as additional-query). All other parameters are specified in the search:options XML node passed into the Search API call. You can choose to use them or not, as is needed to perform your custom action.
When implementing a lexicon call in the start-facet function, you must add the "concurrent" option to the $facet-options parameter and use the combined sequence as input to the $options parameter of the lexicon API. The "concurrent" option takes advantage of concurrency, and can greatly speed performance, especially for applications with many facets. For a sample function, see Example: Creating a Custom Constraint Geospatial Facet.
The start-facet function is optional, but is the recommended way to create a custom facet that uses any of the MarkLogic Server lexicon functions. If you do not use the start-facet function, then the finish-facet function must do all of the work to construct the facet (including constructing the values for the facet). For details on the lexicon functions, see the MarkLogic XQuery and XSLT Function Reference and Browsing With Lexicons.
Implementing the finish-facet Function
The finish-facet function takes input from the start-facet function (if it is used) and constructs the facet element. This function must have a signature compatible with the following signature:
declare function my-namespace:finish-facet( $start as item()*, $constraint as element(search:constraint), $query as cts:query?, $facet-options as xs:string*, $quality-weight as xs:double?, $forests as xs:unsignedLong*) as element(search:facet)
You can use any namespace and local name for the function, but the number and order of the parameters must be compatible and the return type must be compatible.
The parameters are passed into the function by the Search API. The $query parameter includes any custom query your parse function implemented, combined with any other query that the Search API generates (which depends on other options passed in to the original search such as additional-query). All of the remaining parameters are specified in the search:options XML passed into the Search API call. You can choose to use them or not, as is needed to perform your custom action. For a sample function, see Example: Creating a Custom Constraint Geospatial Facet.
If you do not use a start-facet function, then the empty sequence is passed in for the $start parameter. If you are not using a start-facet function, then the finish-facet function is responsible for constructing the values and counts used in the facet, as well as creating the facet XML.
Example: Creating a Simple Custom Constraint
The following is a library module that implements a very simple custom constraint for use with string queries. This constraint adds a cts:directory-query for the values specified in the constraint. This constraint has no facets, so it does not need the start-facet and finish-facet functions. This code does very minimal parsing; your actual code might parse the $right query more carefully.
xquery version "1.0-ml"; module namespace my="my-namespace"; declare variable $prefix := "/mydocs/" ; declare function part( $constraint-qtext as xs:string, $right as schema-element(cts:query)) as schema-element(cts:query) { let $query := <root>{ let $s := fn:string($right//cts:text/text()) let $dir := if ( $s eq "book") then fn:concat($prefix, "book-dir/") else if ( $s eq "api") then ( fn:concat($prefix, "api-dir1/"), fn:concat($prefix, "api-dir2/") ) (: if it does not match, just constrain on the prefix :) else $prefix return (: make these an or-query so you can look through several dirs :) cts:or-query(( for $x in $dir return cts:directory-query($x, "infinity") )) } </root>/* return (: add qtextconst attribute so that search:unparse will work - required for some search library functions :) element { fn:node-name($query) } { attribute qtextconst { fn:concat($constraint-qtext, fn:string($right//cts:text)) }, $query/@*, $query/node()} } ;
If you put this module in a file named my-module.xqy your App Server root, you can run this constraint with the following options node:
<options xmlns="http://marklogic.com/appservices/search"> <constraint name="part"> <custom facet="false"> <parse apply="part" ns="my-namespace" at="/my-module.xqy"/> </custom> </constraint> </options>
The following query text results in constraining this search to the /mydocs/book-dir/ directory:
part:book
Example: Creating a Custom Constraint for Structured Queries
The following is a library module that implements a very simple custom constraint to be used with structured queries. This constraint adds a cts:directory-query for the values specified in the constraint. This constraint has no facets, so it does not need the start-facet and finish-facet functions.
xquery version "1.0-ml"; module namespace my = "my-namespace"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; declare variable $prefix := "/mydocs/" ; declare function part( $query-elem as element(), $options as element(search:options) ) as schema-element(cts:query) { let $query := <root>{ let $s := $query-elem/search:text/text() let $dir := if ( $s eq "book") then fn:concat($prefix, "book-dir/") else if ( $s eq "api") then ( fn:concat($prefix, "api-dir1/"), fn:concat($prefix, "api-dir2/") ) (: if it does not match, just constrain on the prefix :) else $prefix return (: make these an or-query so you can look through several dirs :) cts:or-query(( for $x in $dir return cts:directory-query($x, "infinity") )) } </root>/* return (: add qtextconst attribute so that search:unparse will work - required for some search library functions :) element { fn:node-name($query) } { attribute qtextconst { fn:concat( $query-elem/search:constraint-name, ":", $query-elem/search:text/text()) }, $query/@*, $query/node()} } ;
If you put this module in a file named my-module.xqy your App Server root, you can run this constraint with the following options node:
<options xmlns="http://marklogic.com/appservices/search"> <constraint name="part"> <custom facet="false"> <parse apply="part" ns="my-namespace" at="/my-module.xqy"/> </custom> </constraint> </options>
The following structured query constrains the search to the /mydocs/book-dir/ directory:
<query xmlns="http://marklogic.com/appservices/search"> <custom-constraint-query> <constraint-name>part</constraint-name> <text>book</text> </custom-constraint-query> </query>
You can use the return-query query option to see the directory-query generated by the custom constraint. For example, if you add the following to your options node:
<return-query>true</return-query>
Then the search response will include a query similar to the following:
<search:response ...> <search:query> <cts:or-query xmlns:cts="http://marklogic.com/cts"> <cts:directory-query depth="infinity"> <cts:uri>/mydocs/book-dir/</cts:uri> </cts:directory-query> </cts:or-query> </search:query> ... </search:response>
Example: Creating a Custom Constraint Geospatial Facet
The following is a library module that implements a geospatial facet that uses a custom constraint. It tokenizes the constraint value on the @ character to produce input to the geospatial lexicon function. This is a simplified example, meant to demonstrate the design pattern, not meant for production, as it does not do any error checking to make it more robust at handling user input.
While you could use the code in this example, it is meant as an example of the design patterns you use to create custom constraints. If you want to use a geospatial constraint, use the built-in geospatial contraint types (geo-attr-pair, geo-elem-pair, and geo-elem) as described in Constraint Options.
xquery version "1.0-ml";
module namespace geoexample = "my-geoexample";
(:
Sample custom constraint for this example :
<constraint name="geo">
<custom>
<parse apply="parse" ns="my-geoexample"
at="/geoexample.xqy"/>
<start-facet apply="start-facet" ns="my-geoexample"
at="/geoexample.xqy"/>
<finish-facet apply="finish-facet" ns="my-geoexample"
at="/geoexample.xqy"/>
<annotation>
<yns:regions xmlns:yns=http://yourcompany.com/yournamespace>
<yns:region label="A">[0, -180, 30, -90]</yns:region>
<yns:region label="B">[0, -90, 30, 0]</yns:region>
<yns:region label="C">[30, -180, 45, -90]</yns:region>
<yns:region label="D">[30, -90, 45, 0]</yns:region>
<yns:region label="E">[45, -180, 60, -90]</yns:region>
<yns:region label="F">[45, -90, 60, 0]</yns:region>
<yns:region label="G">[45, 90, 60, 180]</yns:region>
<yns:region label="H">[60, -180, 90, -90]</yns:region>
<yns:region label="I">[60, -90, 90, 0]</yns:region>
<yns:region label="J">[60, 90, 90, 180]</yns:region>
</yns:regions>
</annotation>
</custom>
</constraint>
This example assumes the presence of an element-pair
geospatial index, on data structured as follows (note lat/lon
children of quake):
<quake>
<area>0</area>
<perimeter>0</perimeter>
<quakesx020>2</quakesx020>
<quakesx0201>26024</quakesx0201>
<catalog_sr>PDE</catalog_sr>
<year>1994</year>
<month>6</month>
<day>11</day>
<origin_tim>164453.48</origin_tim>
<lat>61.61</lat>
<lon>168.28</lon>
<depth>9</depth>
<magnitude>4.3</magnitude>
<mag_scale>mb</mag_scale>
<mag_source/>
<dt>1994-06-11T16:44:53.48Z</dt>
</quake>
:)
declare namespace search = "http://marklogic.com/appservices/search";
(:
The Search API calls the parse function during the parsing of the
query text. It accepts the parsed-so-far query text for this
constraint, parses that query, and outputs a serialized cts:query
for the custom part. The Search API passes the parameters to this
function based on the custom constraint in the search:options and
the query text passed into search:search.
:)
declare function geoexample:parse(
$qtext as xs:string,
$right as schema-element(cts:query) )
as schema-element(cts:query)
{
let $point := fn:tokenize(fn:string($right//cts:text), "@")
let $s := $point[1]
let $w := $point[2]
let $n := $point[3]
let $e := $point[4]
return
element cts:element-pair-geospatial-query {
attribute qtextconst {
fn:concat($qtext, fn:string($right//cts:text)) },
element cts:annotation {
"this is a custom constraint for geo" },
element cts:element { "quake" },
element cts:latitude {"lat"},
element cts:longitude {"lon"},
element cts:region {
attribute xsi:type { "cts:box" },
fn:concat("[", fn:string-join(($s, $w, $n, $e),
", "), "]")
},
element cts:option { "coordinate-system=wgs84" }
}
};
(:
The start-facet function starts the concurrent lexicon evaluation.
:)
declare function geoexample:start-facet(
$constraint as element(search:constraint),
$query as cts:query?,
$facet-options as xs:string*,
$quality-weight as xs:double?,
$forests as xs:unsignedLong*)
as item()*
{
let $latitude-bounds := (0, 30, 45, 60, 90)
let $longitude-bounds := (-180, -90, 0, 90, 180)
return
cts:element-pair-geospatial-boxes(
xs:QName("quake"), xs:QName("lat"), xs:QName("lon"), $latitude-bounds,
$longitude-bounds, ($facet-options, "concurrent", "gridded"),
$query, $quality-weight, $forests)
};
(:
The finish-facet function constructs the facet, based on the
values from $start returned by the start-facet function.
:)
declare function geoexample:finish-facet(
$start as item()*,
$constraint as element(search:constraint),
$query as cts:query?,
$facet-options as xs:string*,
$quality-weight as xs:double?,
$forests as xs:unsignedLong*)
as element(search:facet)
{
(: Uses the annotation from the constraint to extract the regions :)
let $labels := $constraint/search:custom/search:annotation/search:regions
return
element search:facet {
attribute name {$constraint/@name},
for $range in $start
return
element search:facet-value{
attribute name {
$labels/search:region[. eq fn:string($range)]/@label },
attribute count {cts:frequency($range)}, fn:string($range) }
}
};To run a custom constraint that references the above custom code, put the above module in the App Server root in a file names geoexample.xqy and run the following:
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; let $options := <options xmlns="http://marklogic.com/appservices/search"> <constraint name="geo"> <custom> <parse apply="parse" ns="my-geoexample" at="/geoexample.xqy"/> <start-facet apply="start-facet" ns="my-geoexample" at="/geoexample.xqy"/> <finish-facet apply="finish-facet" ns="my-geoexample" at="/geoexample.xqy"/> <annotation> <regions> <region label="A">[0, -180, 30, -90]</region> <region label="B">[0, -90, 30, 0]</region> <region label="C">[30, -180, 45, -90]</region> <region label="D">[30, -90, 45, 0]</region> <region label="E">[45, -180, 60, -90]</region> <region label="F">[45, -90, 60, 0]</region> <region label="G">[45, 90, 60, 180]</region> <region label="H">[60, -180, 90, -90]</region> <region label="I">[60, -90, 90, 0]</region> <region label="J">[60, 90, 90, 180]</region> </regions> </annotation> </custom> </constraint> </options> return search:search("geo:1@2@3@4", $options)
Search Grammar
The XQuery Search API and the REST, Node.js, and Java Client APIs use a built-in grammar to generate a search query from simple query text, which is typically text entered by an end-user in a simple HTML form. The default grammar provides a robust ability to generate complex queries. The following are some examples of queries that use the default grammar:
(cat OR dog) NEAR vetat least one of the terms
catordogwithin 10 terms (the default distance forcts:near-query) of the wordvetdog NEAR/30 vetcat -dog
the word cat where there is no word dog.
Customization of the string query grammar is available using the grammar query option.
For details, see Searching Using String Queries
Returning Lexicon Values With search:values
A lexicon is a list of unique words or values, either throughout an entire database (words only) or over a named element, attribute, or field (words or values). The search:values Search API function returns values from lexicons. You can optionally constrain the values with a structured query, choose a subset of the matching values, calculate aggregates based on the lexicon values, and find co-occurrences of values in multiple lexicons.
For general information about lexicons, see Browsing With Lexicons. This section covers the following related topics specific to the Search API.
- Specifying the Input Lexicons
- Constraining and Filtering Your Results
- Example: Using a Query to Constrain Results
- Example: Filtering with Starting Value, Limit, and Page Length
- Example: Finding Value Co-Occurrences
- Additional Interfaces
Specifying the Input Lexicons
The most basic search:values call has the following form:
search:values($spec-name, $options)
Where $spec-name is the name of a values or tuples specification defined in the search:options passed as the second parameter. Use a values specification to work with the values in a single lexicon. Use a tuples specification to work with co-occurrences of values in multiple lexicons.
Before you can query the values or words in an element, attribute, or field, you must define a corresponding range index or a word lexicon using the Admin Interface or Admin API. To you query the URI or collection lexicon, it must be enabled on the database. For details, see Creating Lexicons.
The following example returns all values of the <first-name/> element, assuming the existence of an element range index over the element.
xquery version "1.0-ml";
import module namespace search = "http://marklogic.com/appservices/search"
at "/MarkLogic/appservices/search/search.xqy";
let $options :=
<options xmlns="http://marklogic.com/appservices/search">
<values name="names">
<range type="xs:string">
<element ns="" name="first-name" />
</range>
</values>
</options>
return
search:values("names", $options)
<values-response name="names" type="xs:string"
xmlns="http://marklogic.com/appservices/search"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<distinct-value frequency="1">George</distinct-value>
<distinct-value frequency="1">Fred</distinct-value>
...
</values-response>For more examples of values and tuples specifications, see the API reference for search:values.
The search:values function accepts additional parameters you can use to constrain and filter your results; for details, see Constraining and Filtering Your Results. You can also apply a pre-defined or user-defined aggregate function to values or tuples by defining an aggregate in the search options; for details, see Using Aggregate Functions.
Constraining and Filtering Your Results
The search:values function has the following interface. Only the $spec-name and $options parameters are required.
search:values($spec-name, $options, $query, $limit, $start, $page-start, $page-length)
Use the $query, $limit, $start, $page-start, and $page-length parameters to filter the results returned by search:values, as described in the following table:
The $query, $limit, and $start parameters limit the values selected from the lexicon. The $page-start and $page-length parameters retrieve a subset of the selected values and can be used to page through the selected values in successive invocations.
You cannot use $page-start and $page-length to retrieve values outside the subset selected by $limit and/or $start. For example, if $page-start + $page-length exceeds $limit, then only ($limit - $page-start + 1) values are returned.
Most of the filtering parameters can be used independent of one another. That is, you can specify a limit without a query or a start value without a limit. However, if you specify $page-start, then you must also specify $page-length.
Example: Using a Query to Constrain Results
Imagine a set of documents describing animals. Each document includes an animal name and kind. For example, each document is of the following form:
<animal> <name>aardvark</name> <kind>mammal</kind> </animal>
If an element or field range index is defined on /animal/name, then the following query returns a result for all the animal names in the database:
xquery version "1.0-ml";
import module namespace search = "http://marklogic.com/appservices/search"
at "/MarkLogic/appservices/search/search.xqy";
let $options :=
<options xmlns="http://marklogic.com/appservices/search">
<values name="animals">
<range type="xs:string">
<field name="animal-name" />
</range>
</values>
</options>
return
search:values("animals", $options)
<values-response name="animals" type="xs:string"
xmlns="http://marklogic.com/appservices/search"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<distinct-value frequency="1">aardvark</distinct-value>
<distinct-value frequency="1">badger</distinct-value>
<distinct-value frequency="1">camel</distinct-value>
<distinct-value frequency="1">duck</distinct-value>
<distinct-value frequency="1">emu</distinct-value>
...
<distinct-value frequency="1">zebra</distinct-value>
</values-response>The following example adds a query that limits the results to values in documents that match the query mammal OR marsupial, eliminating duck, emu and other bird values from the result set. This example uses a structured query derived from a string query by calling search:parse, but you can use any structured query.
search:values("animals", $options,
search:parse("mammal OR marsupial", (), "search:query")
)
<values-response name="animals" type="xs:string"
xmlns="http://marklogic.com/appservices/search"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<distinct-value frequency="1">aardvark</distinct-value>
<distinct-value frequency="1">badger</distinct-value>
<distinct-value frequency="1">camel</distinct-value>
<distinct-value frequency="1">fox</distinct-value>
<distinct-value frequency="1">hare</distinct-value>
...
<distinct-value frequency="1">zebra</distinct-value>
</values-response>If you include other filtering parameters, such as $limit, they are applied after the query. For example, adding a limit of 4 returns the value set [aardvark badger camel fox] from the above results.
search:values("animals", $options, search:parse("mammal OR marsupial", (), "search:query"), 4) )
Example: Filtering with Starting Value, Limit, and Page Length
Assume your lexicon contains a string value for each lower-case letter in the alphabet so that the following query returns results for the values a,b,c...,z:
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; let $options := <options xmlns="http://marklogic.com/appservices/search"> <values name="alphabet"> <range type="xs:string"> <field name="letter" /> </range> </values> </options> return search:values("alphabet", $options)
The following query supplies a limit of 10, a start value of "c", a page start of 4, and page length of 3 to the above query:
search:values("alphabet", $options, (), 10, "c", 4, 3) (: $limit = 10 :) (: $start = "c" :) (: $page-start = 4 :) (: $page-length = 3 :)
The $limit and $start parameter values result in a subset of 10 values, beginning with "c", that are retrieved from the lexicon. The example below uses square brackets ( [ ] ) to delimit the selected subset.
a b [ c d e f g h i j k l ] m n ... x y z
Then, $page-start and $page-length parameter values define the final page of values returned by search:values. Since "f" is the 4th value in subset defined by $limit and $start, the final result subset contains the value f..h. The example below uses curly braces ( { } ) to delimit the selected page of values:
a b [ c d e { f g h } i j k l ] m n ... x y z
Note that $page-start and $page-length can never yield a result set that extends past the last value in the subset of values defined by $limit. Thus, in the example above, no value beyond "l" can be returned without varying $start or $limit.
The table below illustrates the values returned when applying various combinations of the $start, $limit, $page-start, and $page-length parameters and how search:values arrives at the final results. As above, square brackets ( [ ] ) delimit the values selected by $limit and/or $start, and curly braces ( { } ) delimit the values selected by $page-start and $page-length.
If a query parameter is included, the above filtering is applied to the results after applying the query.
Example: Finding Value Co-Occurrences
The following shows how to return co-occurrences (tuples) from the URI lexicon and an element, constraint on a query for hello AND goodbye, pulling data exclusively out of the range index:
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; let $options := <options xmlns="http://marklogic.com/appservices/search"> <tuples name="hello"> <uri/> <range type="xs:string" collation="http://marklogic.com/collation/"> <element ns="" name="hello"/> </range> </tuples> </options> return $values := search:values("hello", $options, search:parse("hello goodbye", (), "search:query"))
Additional Interfaces
You can also query lexicons using the following interfaces:
- The cts:values XQuery function. For details, see Browsing With Lexicons.
- The REST Client API methods GET /v1/values/{name} and POST /v1/values/{name}. For details, see Querying the Values in a Lexicon or Range Index and Finding Value Co-Occurrences in Lexicons in the REST Application Developer's Guide.
- The Java Client API
ValuesDefinitioninterface. For details, see the Javadoc and Search On Tuples (Tuples Query / Values Query) in the Java Application Developer's Guide. - The Node.js Client API DatabaseClient.values interface. For details, see Querying Lexicons and Range Indexes in the Node.js Application Developer's Guide.
JSON Support in the Search API
The options node in the Search API allows you to specify JSON property names when you have loaded JSON documents into the database and the values you are searching for are associated with JSON properties. The following options node shows some sample json-property specifications:
<!-- Example of enhanced options structures supporting JSON -->
<options xmlns="http://marklogic.com/appservices/search">
<!-- range constraint -->
<constraint name="foo">
<range type="xs:int">
<json-property>foo</json-property>
</range>
</constraint>
<!-- range values -->
<values name="foo-values">
<range type="xs:int">
<json-property>foo</json-property>
</range>
</values>
<!-- range tuples -->
<tuples name="foo-tuples">
<range type="xs:int">
<json-property>foo</json-property>
</range>
<range type="xs:string">
<json-property>bar</json-property>
</range>
</tuples>
<!-- default term with word -->
<term apply="term">
<default>
<word>
<json-property>bar</json-property>
</word>
</default>
<empty apply="all-results"/>
</term>
<constraint name="bar">
<word>
<json-property>bar</json-property>
</word>
</constraint>
<constraint name="baz">
<value>
<json-property>baz</json-property>
</value>
</constraint>
<operator name="sort">
<state name="score">
<sort-order direction="ascending">
<score/>
</sort-order>
</state>
<state name="foo">
<sort-order type="xs:int" direction="ascending">
<json-property>asc</json-property>
</sort-order>
</state>
</operator>
<sort-order type="xs:int" direction="descending">
<json-property>desc</json-property>
</sort-order>
<transform-results apply="snippet">
<preferred-matches>
<element ns="f" name="foo"/>
<json-property>chicken</json-property>
</preferred-matches>
</transform-results>
<extract-metadata>
<qname elem-ns="n" elem-name="p"/>
<json-property>name</json-property>
<json-property>title</json-property>
<json-property>affiliation</json-property>
</extract-metadata>
<debug>true</debug>
<return-similar>false</return-similar>
</options>More Search API Examples
This section shows the following examples that use the Search API:
Buckets Example
The following example shows how to create a search that defines several decades as buckets, and those buckets are used to generate facets and as a constraint in the search grammar. Buckets are a type of range constraint, which are described in Constraint Options.
Each bucket defines boundary conditions that determines what values fit into the bucket (@ge, @lt, etc.). Each bucket has a unique name (@name) that identifies the bucket search terms. For example, decade:1940s matches values that fit into the bucket with the name 1990s.
A bucket can also have a label as the element text data. The label has no functional use in a search, but it is returned in the facet data and can be used by the application for display purposes.
This example defines a constraint that uses a range index of type xs:gYear on a Wikipedia nominee/@year attribute.
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; let $options := <search:options> <search:constraint name="decade"> <search:range type="xs:gYear" facet="true"> <search:bucket ge="2000" name="2000s">Noughts</search:bucket> <search:bucket lt="2000" ge="1990" name="1990s">Nineties</search:bucket> <search:bucket lt="1990" ge="1980" name="1980s">Eighties</search:bucket> <search:bucket lt="1980" ge="1970" name="1970s">Seventies</search:bucket> <search:bucket lt="1970" ge="1960" name="1960s">Sixties</search:bucket> <search:bucket lt="1960" ge="1950" name="1950s">Fifties</search:bucket> <search:bucket lt="1950" ge="1940" name="1940s">Forties</search:bucket> <search:bucket lt="1940" ge="1930" name="1930s">Thirties</search:bucket> <search:bucket lt="1930" ge="1920" name="1920s">Twenties</search:bucket> <search:facet-option>limit=10</search:facet-option> <search:attribute ns="" name="year"/> <search:element ns="http://marklogic.com/wikipedia" name="nominee"/> </search:range> </search:constraint> </search:options> return search:search("james stewart decade:1940s", $options)
The following is a partial response from this query:
<search:response total="2" start="1" page-length="10" xmlns="" xmlns:search="http://marklogic.com/appservices/search"> <search:result index="1" uri="/oscars/843224828394260114.xml" path="doc("/oscars/843224828394260114.xml")" score="200" confidence="0.670319" fitness="1"> <search:snippet> <search:match path= "doc("/oscars/843224828394260114.xml")/*:nominee /*:name"><search:highlight>James</search:highlight> <search:highlight>Stewart</search:highlight></search:match> ....... </search:snippet> <search:snippet>.......</search:snippet> ....... </search:result> <search:facet name="decade"> <search:facet-value name="1940s" count="2">Forties</search:facet-value> </search:facet> <search:qtext>james stewart decade:1940s</search:qtext> <search:metrics> <search:query-resolution-time> PT0.152S</search:query-resolution-time> <search:facet-resolution-time> PT0.009S</search:facet-resolution-time> <search:snippet-resolution-time> PT0.073S</search:snippet-resolution-time> <search:total-time>PT0.234S</search:total-time> </search:metrics> </search:response>
Computed Buckets Example
The computed-bucket range constraint operates over xs:date and xs:dateTime range indexes. The constraint specifies boundaries for the buckets that are computed at runtime based on computations made at the current time. The anchor attribute on the computed-bucket element has the following values:
These values can also be used in ge-anchor and le-anchor attributes of the computed-bucket element.
The following search specifies a computed bucket and finds all of the documents that were updated today (this example assumes the maintain last-modified property is set on the database configuration):
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; search:search('modified:today', <options xmlns="http://marklogic.com/appservices/search"> <searchable-expression>xdmp:document-properties() </searchable-expression> <constraint name="modified"> <range type="xs:dateTime"> <element ns="http://marklogic.com/xdmp/property" name="last-modified"/> <computed-bucket name="today" ge="P0D" lt="P1D" anchor="start-of-day">Today</computed-bucket> <computed-bucket name="yesterday" ge="-P1D" lt="P0D" anchor="start-of-day">yesterday</computed-bucket> <computed-bucket name="30-days" ge="-P30D" lt="P0D" anchor="start-of-day">Last 30 days</computed-bucket> <computed-bucket name="60-days" ge="-P60D" lt="P0D" anchor="start-of-day">Last 60 Days</computed-bucket> <computed-bucket name="year" ge="-P1Y" lt="P1D" anchor="now">Last Year</computed-bucket> </range> </constraint> </options>)
The anchor attributes have a value of start-of-day, so the duration values specified in the ge and lt attributes are applied at the start of the current day. Note that this is not the same as the previous 24 hours, as the start-of-day value uses 12 o'clock midnight as the start of the day. The notion of time relative to days, months, and years, as opposed to relative to the exact current time, is the difference between relative buckets (computed-bucket) and absolute buckets (bucket). For an example that uses absolute buckets, see Buckets Example.
Sort Order Example
The following search specifies a custom sort order.
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; let $options := <search:options> <search:operator name="sort"> <search:state name="relevance"> <search:sort-order> <search:score/> </search:sort-order> </search:state> <search:state name="year"> <search:sort-order direction="descending" type="xs:gYear" collation=""> <search:attribute ns="" name="year"/> <search:element ns="http://marklogic.com/wikipedia" name="nominee"/> </search:sort-order> <search:sort-order> <search:score/> </search:sort-order> </search:state> </search:operator> </search:options> return search:search("lange sort:year", $options)
This search specifies to sort by year. The options specification allows you to specify year or relevance, and without specifying, sorts by score (which is the same as relevance in this example).