Overview
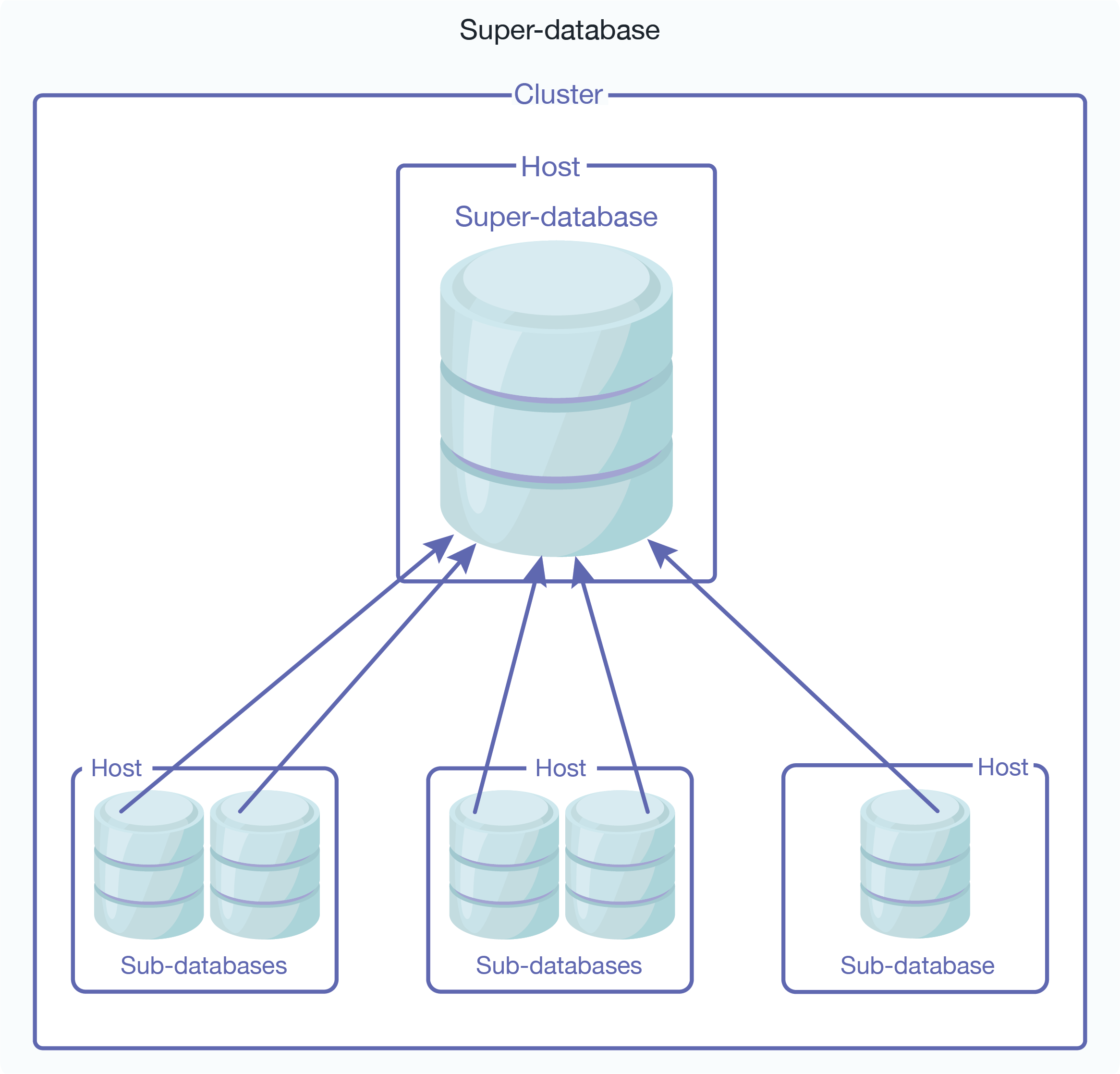
Updates are made on the sub-databases and then made visible for read in the super-database. Here is an illustration of a super-database and its sub-databases configured on a single cluster:
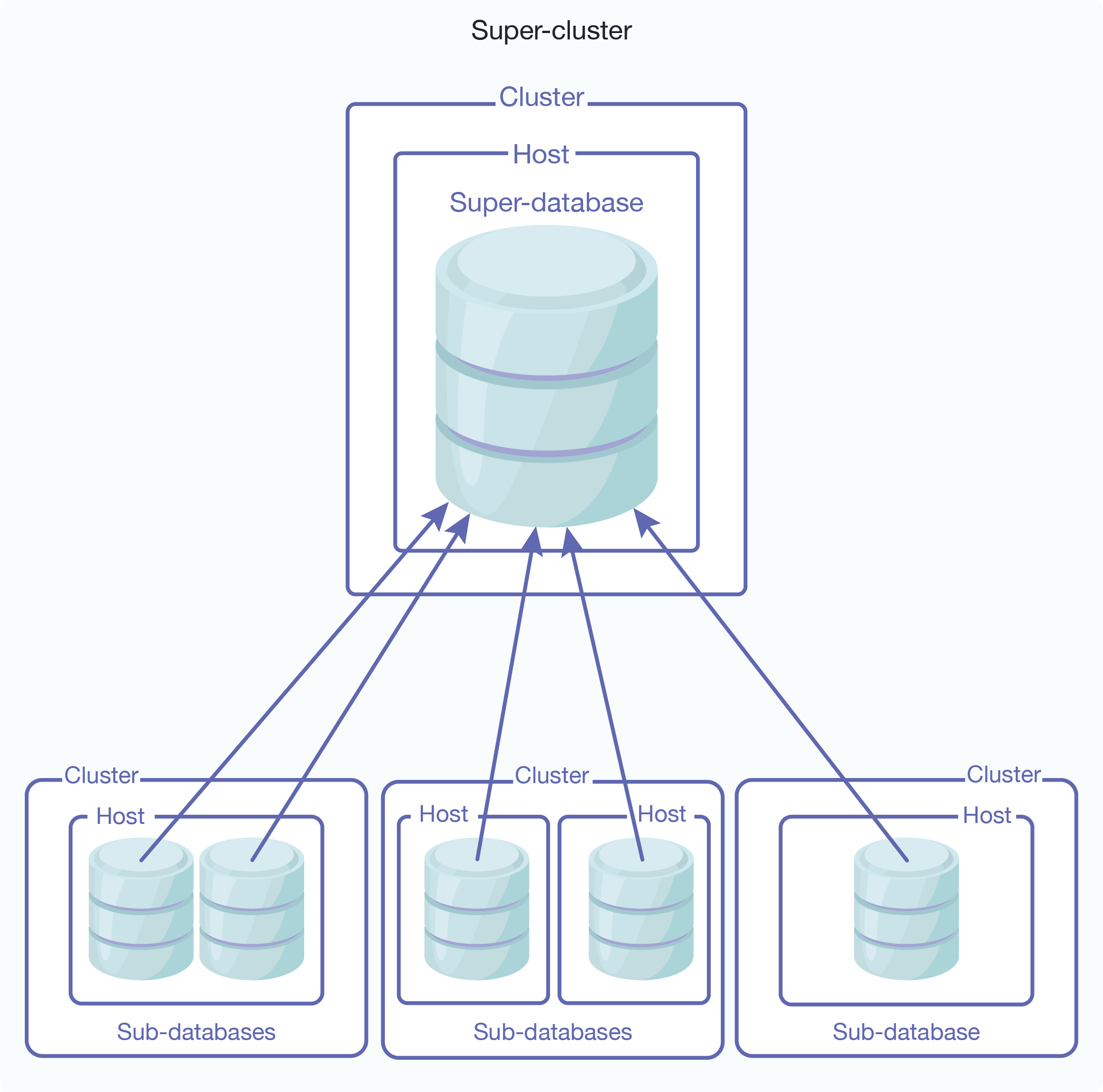
Here is an illustration of is a super-database configured with sub-databases on different clusters. The cluster hosting the super-database must be coupled with the foreign clusters hosting the sub-databases. For details on how to couple clusters, see Coupling Clusters.
Note
Each foreign cluster should have multiple bootstrap hosts so that, if one bootstrap host goes down, the super-database can use the other bootstrap host to query the sub-databases on that cluster.
The following list describes the characteristics of super-databases and sub-databases:
Only one level of sub-databases is supported for a super-database, which means that a sub-database cannot also be configured as a super-database with sub-databases of its own.
Updates to the sub-databases are made visible on the super-database. You cannot write to a super-database and have the update propagated to its sub-databases. A super-database must have local forests for it to be updated. However, configuring a super-database with local forests is not recommended.
Sub-databases and their super-databases must have the same index settings. Otherwise, queries will not work.
Because super-databases and their sub-databases are effectively a single database, you cannot have documents with the same URI in super-databases and their sub-databases. It is a best practice to use directories to ensure that your document URIs are unique.
You cannot run Flexible Replication on a super-database.
When sub-databases are distributed across foreign clusters, the Security and Schemas databases must be the same for accessing the databases on each cluster. To ensure this, you should use Database Replication to replicate the Security and Schemas database on each cluster.
When inserting data to a sub-database on a foreign cluster, you can read the inserted document on the super-database after the
request-timestampmoves past the commit timestamp of the insert. Typically, this takes a few seconds.