
MarkLogic Server 11.0 Product DocumentationSemantic Graph Developer's Guide — Chapter 10
XQuery and JavaScript Semantics APIs
This chapter describes the XQuery and JavaScript Semantics APIs, which include an XQuery library module, built-in semantics functions, and support for SPARQL, SPARQL Update, and RDF. The Semantics API is designed for large-scale, production triple stores and applications. The complete list of semantic functions can be found at https://docs.marklogic.com/sem/semantic-functions.
This chapter includes examples of using the Semantics API, which is an API designed to create, query, update, and delete triples and graphs in MarkLogic.
Additionally, the following APIs support the MarkLogic Semantics features; XQuery API, REST API, Node.js Client API, and Java Client API, using a variety of query styles, as described in the Loading Semantic Triples, Semantic Queries and Inserting, Deleting, and Modifying Triples with XQuery and Server-Side JavaScript chapters of this guide.
This chapter includes the following sections:
- XQuery Library Module for Semantics
- Generating Triples
- Extracting Triples from Content
- Parsing Triples
- Exploring Data
Semantics is a separately licensed product: you need a valid semantics license key to use semantics.
XQuery Library Module for Semantics
Some of the Semantics XQuery functions are built-in functions that do not require an import statement, while others are implemented in an XQuery library module that requires an import statement. To simplify things, MarkLogic recommends that you import the Semantics API library into every XQuery module or JavaScript module that uses the Semantics API.
Importing the Semantics Library Module with XQuery
You can use the Semantics API library module with XQuery by importing the module into your XQuery with the following prolog statement:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy";
The prefix for all semantic functions in XQuery is http://marklogic.com/semantics. The Semantics API uses the prefixes sem: or rdf:, which are defined in the server. For details about the function signatures and descriptions, see the Semantics documentation under XQuery Library Modules in the XQuery and XSLT Reference Guide and the MarkLogic XQuery and XSLT Function Reference.
Importing the Semantics Library Module with JavaScript
For JavaScript you can use the Semantics API library module by importing the module into your JavaScript with this statement:
var sem = require("/marklogic/semantics.xqy");
The prefix for all semantic XQuery functions in JavaScript is /marklogic.com/semantics.xqy. With JavaScript, the Semantics API uses the prefix sem. , which is defined in the server. For details about the function signatures and descriptions, see the Semantics documentation under JavaScript Library Modules in the JavaScript Reference Guide and the MarkLogic XQuery and XSLT Function Reference.
Generating Triples
The XQuery sem:rdf-builder function is a powerful tool for dynamically generating triples in the Semantics API. (For JavaScript, the function is sem.rdfBuilder.)
The function builds triples from the CURIE and blank node syntaxes. Blank nodes specified with a leading underscore ( _ ) are assigned blank node identifiers, and maintain state across multiple invocations; for example, "_:person1" refers to the same node as a later invocation that also mentions "_:person1". For example:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $builder := sem:rdf-builder((), sem:iri("my-named-graph")) let $t1 := $builder("_:person1", "a", "foaf:Person") let $t2 := $builder("_:person2", "a", "foaf:Person") let $t3 := $builder("_:person1", "foaf:knows", "_:person2") return ($t1,$t2,$t3) => @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://marklogic.com/semantics/blank/4892021155019117627> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://xmlns.com/foaf/0.1/Person> . <http://marklogic.com/semantics/blank/6695700652332466909> <http://xmlns.com/foaf/0.1/knows> _:bnode4892021155019117627 ; <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://xmlns.com/foaf/0.1/Person> .
In the example, there are three triples generated in Turtle serialization using sem:rdf-builder. The triples represent the following facts; that person1 and person2 are people, and that their relationship is that person1 knows person2.
- The first parameter accepts an optional set of prefix mappings, which in this example is an empty argument. Since empty means default, the
$common-prefixesare used for the first argument. The second argument is a named graph for the sem:rdf-builder output. - In the predicate position, the special value of
"a"is expanded to the full IRI forrdf:type. - Human-readable CURIEs for common prefixes are used, such as
foaf:knowsinstead of long IRIs. See Working with CURIEs. - The blank nodes produced in the third triple match the identity of those defined in the first and second.
Extracting Triples from Content
With the sem:rdf-builder function you can easily extract triples from existing content or the results of a SPARQL query and quickly construct RDF graphs for querying or inserting into your database.
Assume that you have a web page that lists cities and countries that are sorted and ranked by the cost of living (COL), which is based on a Consumer Priced Index (CPI) and CPI-based inflation rate. The inflation rate is defined as the annual percent change in consumer prices compared with the previous year's consumer prices. Using a reference point of Monterrey, Mexico with an assigned a value of 100, the Inflation value of every other city in the database is calculated by comparing their COL to that of Monterrey. For example, an Inflation value of 150, means that the COL is 50% more expensive than living in Monterrey.
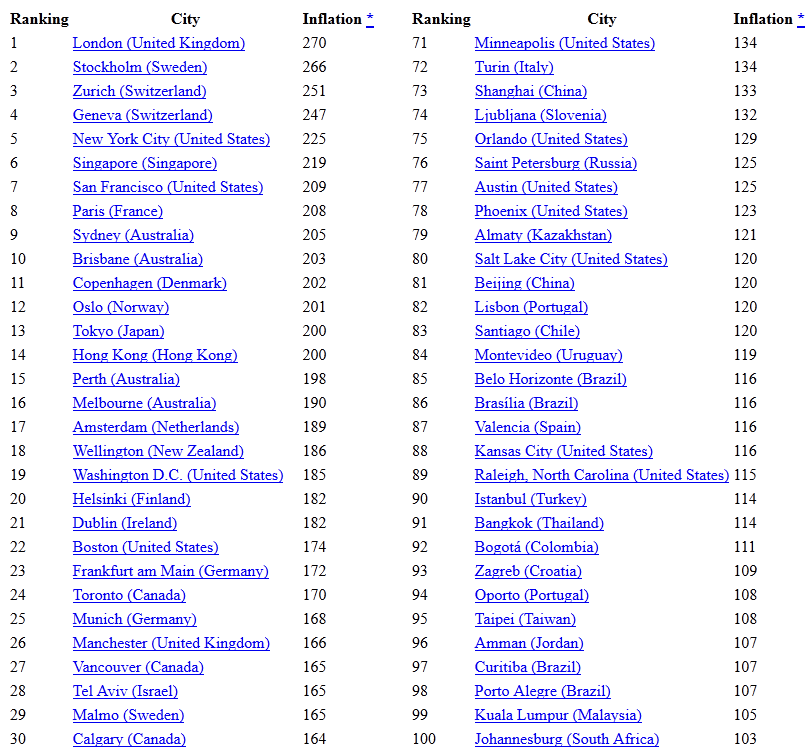
These values are fictional and are not based on any official sources.
The underlying HTML code for the COL table may resemble the following:
<table class="city-index" style="max-width:58%;float:left;margin-right:2em;"> <thead> <tr> <th>Ranking</th> <th class="city-name">City</th> <th class="inflation">Inflation <a href="#inflation-explanation">*</a></th> </tr> </thead> <tbody><tr> <td class="ranking">1</td> <td class="city-name"> <a href="http://www.example.org/IncreasedCoL/london"> London (United Kingdom)</a></td> <td class="inflation">270</td> </tr> <tr> <td class="ranking">2</td> <td class="city-name"> <a href="http://www.example.org/IncreasedCoL/stockholm"> Stockholm (Sweden)</a></td> <td class="inflation">266</td> </tr> <tr> <td class="ranking">3</td> <td class="city-name"> <a href="http://www.example.org/IncreasedCoL/zurich"> Zurich (Switzerland)</a></td> <td class="inflation">251</td> </tr> <tr> <td class="ranking">4</td> <td class="city-name"> <a href="http://www.example.org/IncreasedCoL/geneva"> Geneva (Switzerland)</a></td> <td class="inflation">247</td> </tr> <tr> <td class="ranking">5</td> <td class="city-name"> <ahref="http://www.example.org/IncreasedCoL/new-york"> New York City (United States)</a></td> <td class="inflation">225</td> </tr>
This example uses the sem:rdf-builder function to extract triples from the HTML content. The function takes advantage of the fact that the HTML code is already well-formed and has a useful classification node (@class):
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; declare namespace html="http://www.w3.org/1999/xhtml"; let $doc := xdmp:tidy(xdmp:document-get("C:\Temp\CoLIndex.html", <options xmlns="xdmp:document-get"> <repair>none</repair> <format>text</format> </options>))[2] let $rows := ($doc//html:tr)[html:td/@class eq 'ranking'] let $builder := sem:rdf-builder (sem:prefixes("my: http://example.org/vocab/")) for $row in $rows let $bnode-name := "_:" || $row/html:td[@class eq 'ranking'] return ( $builder($bnode-name, "my:rank", xs:decimal( $row/html:td[@class eq 'ranking'] )), $builder($bnode-name, "rdfs:label", xs:string( $row/html:td[@class eq 'city-name'] )), $builder($bnode-name, "my:coli", xs:decimal( $row/html:td[@class eq 'inflation'] )) )
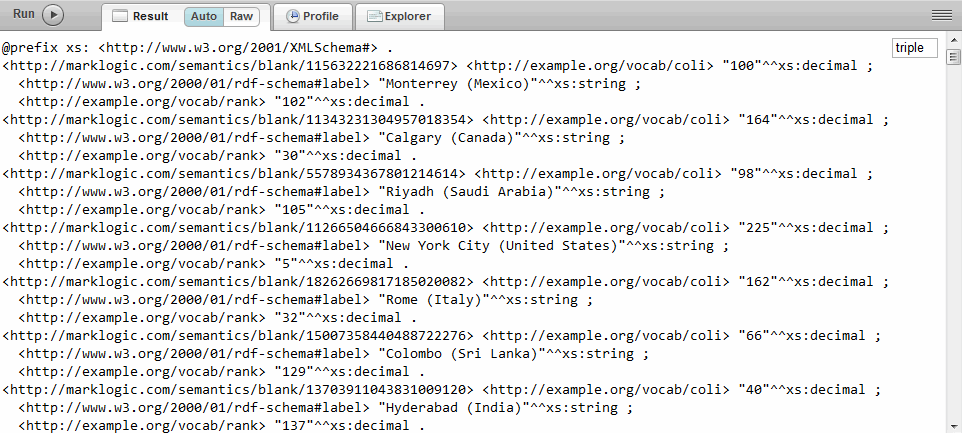
Parsing Triples
This example extends the previous example and inserts parsed triples into the database by using the sem:rdf-insert function:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; declare namespace html="http://www.w3.org/1999/xhtml"; let $doc := xdmp:tidy(xdmp:document-get("C:\Temp\CoLIndex.html", <options xmlns="xdmp:document-get"> <repair>none</repair> <format>text</format> </options>))[2] let $rows := ($doc//html:tr)[html:td/@class eq 'ranking'] let $builder := sem:rdf-builder( sem:prefixes("my: http://example.org/vocab/")) for $row in $rows let $bnode-name := "_:" || $row/html:td[@class eq 'ranking'] let $triples := $row return (sem:rdf-insert(( $builder($bnode-name, "my:rank", xs:decimal ( $row/html:td[@class eq 'ranking'] )), $builder($bnode-name, "rdfs:label", xs:string ( $row/html:td[@class eq 'city-name'] )), $builder($bnode-name, "my:coli", xs:decimal ( $row/html:td[@class eq 'inflation'] ))) ))
The document IRIs are returned as strings:
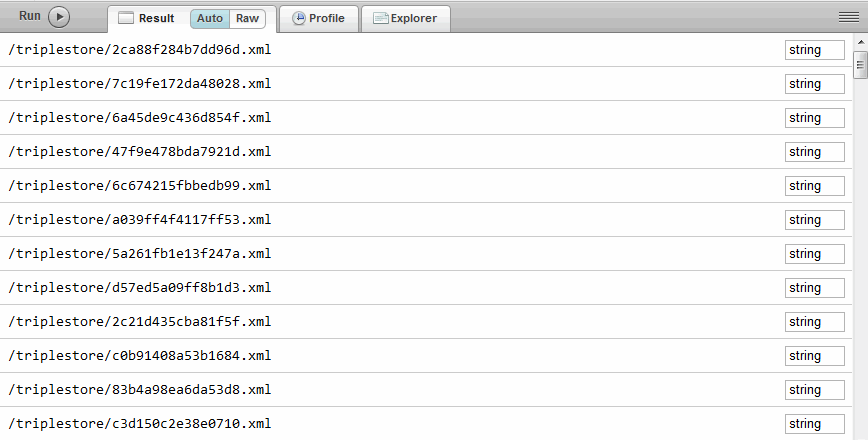
For more information about inserting and parsing triples with XQuery, see Loading Triples with XQuery.
The parser ensures well-formed markup as the triples are inserted as schema-valid triples and indexed with the Triples index, provided it is enabled. See Enabling the Triple Index.
Use fn:doc to view the contents of the documents and verify the triples.
fn:doc("/triplestore/2ca88f284b7dd96d.xml")
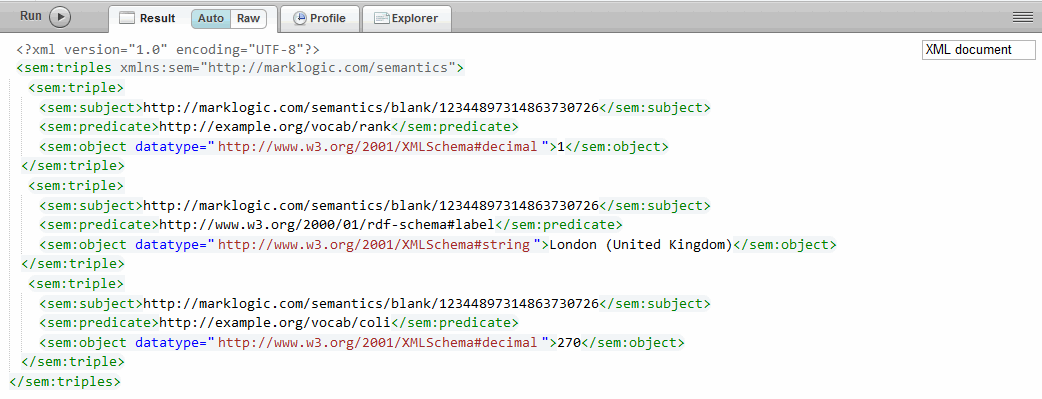
One document is created for each blank node identifier ($bnode-name).
During the generation process $builder maintains state eliminating the need to keep track of every blank node label and ensuring that they map to the same sem:blank value.
The Semantics API includes a repair option for the N-Quad and Turtle parsers. During a normal operation, the RDF parsers perform these tasks:
- Turtle parsing uses the base IRI to resolve relative IRIs. If the result is relative, an error is raised.
- N-Quad parsing does not resolve using the base IRI. If a IRI in the document is relative, an error is raised.
During a repair operation the RDF parsers perform this task:
Exploring Data
The Semantics API provides functions to access RDF data in a database. This section focuses on the following topics:
sem:triple Functions
This table describes the sem:triple functions used to define or search for triple data:
| Function | Description |
|---|---|
| sem:triple | Creates a triple object that represents an RDF triple containing atomic values representing the subject, predicate, object, and optionally a graph identifier (graph IRI) |
| sem:triple-subject | Returns the subject from a sem:triple value |
| sem:triple-predicate | Returns the predicate from a sem:triple value |
| sem:triple-object | Returns the object from a sem:triple value |
| sem:triple-graph | Returns the graph identifier (graph IRI) from a sem:triple value |
In this example, the sem:triple function is used to create a triple that includes a CURIE for the predicate and an rdf:langString value as the object, with English (en) as the given language tag:
sem:triple(sem:iri("http://id.loc.gov/authorities/subjects/ sh85040989"), sem:curie-expand("skos:prefLabel"), rdf:langString("Education", "en")) => @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://id.loc.gov/authorities/subjects/sh85040989> <http://www.w3.org/2004/02/skos/core#prefLabel/> "Education"@en .
Transitive Closure
Transitive closure is a way to traverse a large section of a graph with a single lookup, applying a follow relationship X recursively.
Understanding Transitive Closure
A common use case is a thesaurus, where you have a term, and you want to find all broader terms, all broader terms for those terms, and all broader terms for those broader terms, and so forth. For example, if you have a taxonomy organized like this:
If you want to find all terms that are narrower terms for mammal, you can do a transitive closure of mammal over narrower term and find cat, dog, cow, Bichon, Siamese, Alsatian, chihuahua, Friesian, Jersey, and so forth.
Transitive closure queries are commonly used to explore taxonomies and ontologies such as the Simple Knowledge Organization System (SKOS). SKOS is a common data model for knowledge organization systems such as thesauri, classification schemes, subject heading systems and taxonomies as described by the W3C SKOS Simple Knowledge Organization System Reference:
http://www.w3.org/TR/skos-reference/
sem:transitive-closure
The sem:transitive-closure function has the following signature:
sem:transitive-closure( $seeds as sem:iri*, $predicates as sem:iri*, $limit as xs:integer ) as sem:iri* |
This function takes seeds (subjects), predicates (relationships), and the depth to which to search, and returns all unique node IRIs.
Use the sem:transitive-closure function to traverse RDF graphs to answer reachability questions and discover more information about your RDF data. (In JavaScript, you would use the sem.transitiveClosure function.)
For example, assume that you have a file composed of triples for subject headings that relate to US Congress bills and that the triples are marked up with the SKOS vocabulary. The triples may look similar to this extract:
<http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://www.w3.org/2004/02/skos/core#Concept/> . <http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/2004/02/skos/core#prefLabel/> "Agricultural education"@en . <http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/2008/05/skos-xl#altLabel/> _:bnode7authoritiessubjectssh85002310 . _:bnode7authoritiessubjectssh85002310 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://www.w3.org/2008/05/skos-xl#Label/> . _:bnode7authoritiessubjectssh85002310 <http://www.w3.org/2008/05/skos-xl#literalForm/> "Education, Agricultural"@en . <http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/2004/02/skos/core#broader/> <http://id.loc.gov/authorities/subjects/sh85133121/> . <http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/2004/02/skos/core#narrower/> <http://id.loc.gov/authorities/subjects/sh85118332/> . <http://id.loc.gov/authorities/subjects/sh85133121/> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://www.w3.org/2004/02/skos/core#Concept/> . <http://id.loc.gov/authorities/subjects/sh85133121/> <http://www.w3.org/2004/02/skos/core#prefLabel/> "Technical education"@en .
In this dataset, Technical education is a broader subject heading for Agricultural education as defined by the skos:broader predicate:
<http://id.loc.gov/authorities/subjects/sh85002310/> <http://www.w3.org/2004/02/skos/core#broader/> <http://id.loc.gov/authorities/subjects/sh85133121/> .
This example uses cts:triples to find the subject IRI for a triple where the predicate is a CURIE for skos:prefLabel and the object is Agricultural education. The subject IRI found in the cts:triples query is subsequently used with skos:broader to determine broader subject terms to a depth of 3:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $triple-subject := sem:triple-subject(cts:triples((), sem:curie-expand("skos:prefLabel"), rdf:langString("Agricultural education", "en"))) return sem:transitive-closure($triple-subject, sem:curie-expand("skos:broader"), 3) => <http://id.loc.gov/authorities/subjects/sh85133121/> <http://id.loc.gov/authorities/subjects/sh85002310/> <http://id.loc.gov/authorities/subjects/sh85026423/> <http://id.loc.gov/authorities/subjects/sh85040989/>
Notice that in addition to the expected IRIs, for the following subjects:
<http://id.loc.gov/authorities/subjects/sh85002310/><http://id.loc.gov/authorities/subjects/sh85133121/>
IRIs were returned also in the results for the following subjects:
<http://id.loc.gov/authorities/subjects/sh85040989/><http://id.loc.gov/authorities/subjects/sh85026423/>
When we take a closer look at the dataset, the IRIs for Education and Civilization are also returned, since they are broader subjects still to Agricultural education and Technical Education:
<http://id.loc.gov/authorities/subjects/sh85040989/> <http://www.w3.org/2004/02/skos/core#prefLabel/> "Education"@en . <http://id.loc.gov/authorities/subjects/sh85040989/> <http://www.w3.org/2004/02/skos/core#broader/> <http://id.loc.gov/authorities/subjects/sh85026423/> . ... <http://id.loc.gov/authorities/subjects/sh85026423/> <http://www.w3.org/2004/02/skos/core#prefLabel/> "Civilization"@en . ...