
MarkLogic Server 11.0 Product DocumentationFlexible Replication Guide — Chapter 1
Flexible Replication in MarkLogic Server
This chapter describes Flexible Replication in MarkLogic Server in general terms, and includes the following sections:
- Terms Used in this Guide
- Understanding Flexible Replication
To enable Flexible Replication, a license key that includes Flexible Replication is required. For details on purchasing a Flexible Replication license, contact your MarkLogic sales representative.
Terms Used in this Guide
The following are the definitions for the replication terms used in this guide:
- To Replicate is to create a copy of a document in another database and to keep that copy in sync (possibly with some time-lag/latency) with the original.
- The Master is the repository that gets updated by the applications. The master, in turn, replicates the updates to other repositories, known as replicas.
- A Replica is a repository that receives replicated updates from the master.
- A Master Copy is the content being replicated. For any piece of replicated content there is a master and at least one copy.
- A Master Cluster is the cluster on which the replicated documents are updated by the applications.
- Flexible Replication is an implementation of replication based on the MarkLogic Server Content Processing Framework (CPF). Flexible replication is single-master, asynchronous, and provides a medium level of throughput and latency.
- Replication Domain is the specification of the set of documents to be replicated. This may be a collection or some other set definition.
- A Filter is an XQuery program that modifies the replicated documents in some manner, determines whether to replicate a change, or selects which parts of a document will be replicated.
- Asynchronous Replication refers to a configuration in which the Master does not wait for confirmation that the update has been received by the Replica before sending further updates. Flexible Replication is asynchronous.
- Transaction-aware refers to a configuration in which all updates that make up a transaction on the master are applied as a single transaction on the replica.
- Zero-day Replication refers to replicating the data in the replicated domains that existed before replication was configured.
Understanding Flexible Replication
Flexible Replication is the process of maintaining copies of data on multiple MarkLogic Servers. The purpose of replication is to make data continuously available to mission-critical applications and to enhance application performance. Some of the benefits of replication include:
- High Availability: You can maintain duplicate data on two or more MarkLogic Servers. In the event of a software or hardware failure on one server, the data is available from another server.
- Disaster Recovery: In the event of some irreversible disaster on the Master server, duplicate data is preserved on its Replica.
- Performance: Companies with geographically dispersed clusters can use replication to maintain common data on each local cluster. Queries and updates done locally, are faster and the workload can be scaled across clusters, so that each cluster handles less of the query and update load.
In a replicated environment, the original content is created by an application on the Master MarkLogic Server. Replication then copies the content to one or more Replica MarkLogic Servers. The Master and Replica servers are typically in different clusters, which may be in the same location or in different locations.
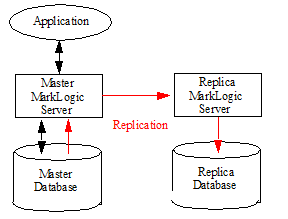
Flexible Replication is asynchronous, which means that the Master does not wait for confirmation that the update has been received by the Replica before sending further updates. Replication from the Master to the Replica occurs as soon as possible after the document is added or updated by the application.
MarkLogic Server uses the Content Processing Framework (CPF) as the underlying replication mechanism. The documents to be replicated are defined by a CPF domain. The scope of a domain may be a document, a collection of documents, or a directory. For more details about domains, see Understanding and Using Domains in the Content Processing Framework Guide. You can replicate multiple domains either to the same Replica or to different Replicas, as shown is the illustrations below.
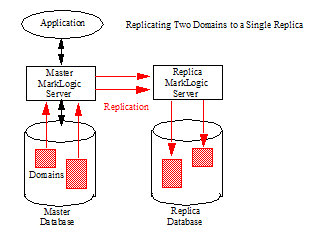
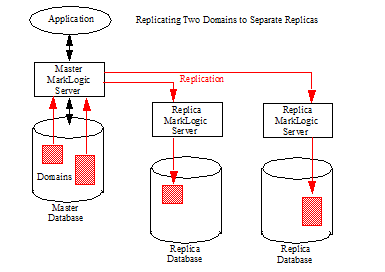
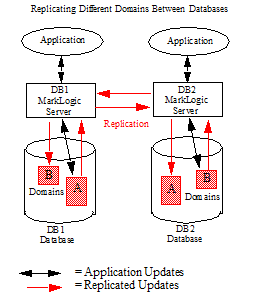
Replicated databases do not necessarily need to be configured as entirely a Master or a Replica in the replication scheme. For example, you may have two databases, DB1 and DB2, where DB1 replicates updates to the documents in Domain A to DB2 and DB2 replicates updates to the documents in Domain B to DB1.
This is not a multi-master replication configuration, as the documents updated by each application must be in different domains. Any overlap between the replicated domains may result in unpredictable behavior.
Another possible Master/Replica configuration is where a Master replicates updates to a Replica/Master that replicates the updates to another Replica. For example, you may have three databases, DB1, DB2, and DB3, where DB1 replicates updates to DB2 and DB2 replicates updates to DB3.
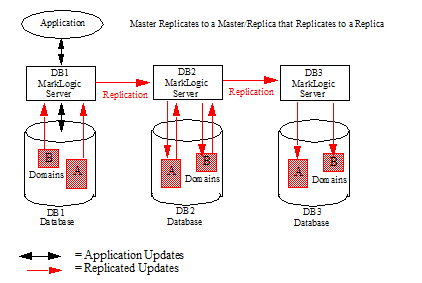
You can set up filters that narrow the scope of what documents and what parts of the documents are replicated within a domain. For example, you can set up a filter to replicate only XML documents, or you can create filters to only replicate inserts and updates (not deletes), or only replicate a particular node or element within each document.
Replication can be configured to either push or pull updates from the Master to the Replica. Push replication means that the Master pushes updates to the Replica. Pull replication means the Replica pulls updates from the Master. Push replication is triggered whenever an update is made on the Master database. Pull replication can only be configured as a scheduled task, as described in Configuring Pull Replication. Typically, you should use push replication, unless the Master and Replica are separated by a firewall through which a Replica server can only pull content from a Master server outside the firewall.