
MarkLogic 9 Product DocumentationSemantics Developer's Guide — Chapter 9
Using Semantics with the REST Client API
This section describes how to use MarkLogic Semantics with the REST Client API to view, query, and modify triples and graphs using REST (Representational State Transfer) over HTTP. The REST Client API enables a client application to perform SPARQL queries and updates. A MarkLogic SPARQL endpoint (/v1/graphs/sparql) is available to use with SPARQL query and SPARQL Update to access triples in MarkLogic. The /v1/graphs/sparql service is a compliant SPARQL endpoint, as defined by the SPARQL 1.1 Protocol: http://www.w3.org/TR/2013/REC-sparql11-protocol-20130321/#terminology. If your client requires configuration of a SPARQL Update or Query endpoint, use this service.
A SPARQL endpoint is a web service that implements the SPARQL protocol and can respond to SPARQL queries. RDF data published to the web using a SPARQL endpoint can be queried to answer a specific question, instead of downloading all of the data. If you have an application that does standard queries and updates over a SPARQL endpoint, you can point the application to this endpoint.
The SPARQL endpoint URL is addressed as:
http://host:port/v1/graphs/sparql
The graph endpoint is used for CRUD procedures on graphs; creating, reading, updating, and deleting graphs. The URL is addressed as:
http://host:port/v1/graphs
The things endpoint is used for viewing content in the database. The URL is addressed as:
http://host:port/v1/graphs/things
The following table shows the supported operations available for Semantics (viewing, querying, inserting, or deleting content):
For more information about usage and parameters for a service, see the REST Client APIs for Semantics.
This chapter includes the following sections:
- Assumptions
- Specifying Parameters
- Supported Operations for the REST Client API
- Serialization
- Examples Using curl and REST
- Response Output Formats
- SPARQL Query with the REST Client API
- SPARQL Update with the REST Client API
- Listing Graph Names with the REST Client API
- Exploring Triples with the REST Client API
- Managing Graph Permissions
To use the SPARQL endpoint or graphs endpoints with SPARQL query, you must have the rest-reader privilege, along with any security requirements for your environment. To use SPARQL Update with the SPARQL endpoint or graphs endpoints, you must have the rest-writer privilege. See Controlling Access to Documents Created with the REST API in the REST Application Developer's Guide for more information about permissions.
Assumptions
To follow along with the examples later in this section the following assumptions are made:
- You have access to the GovTrack dataset. For details, see Preparing to Run the Examples. If you do not have access to the GovTrack data or prefer to use your own data, you can modify queries to fit your data.
- You have
curlor an equivalent command-line tool for issuing HTTP requests is installed.Though the examples rely on
curl, you can use any tool capable of sending HTTP requests. If you are not familiar withcurlor do not havecurlon your system, see the Introduction to the curl Tool in the REST Application Developer's Guide.
Specifying Parameters
A variety of parameters can be used with REST services. The complete list can be found in the REST Client APIs, for instance POST /v1/graphs/sparql. This section describes a selection of those parameters that can be used with SPARQL query and/or SPARQL Update.
For the parameters, * and ? both imply that a parameter is optional. * means that you can use a parameter 0 or more times and ? means that you can use a parameter 0 or 1 times.
SPARQL Query Parameters
Some of the parameters supported for SPARQL query on the SPARQL endpoint, using POST /v1/graphs/sparql or GET /v1/graphs/sparql, include:
query- SPARQL query to executedefault-graph-uri*- The URI of the graph or graphs to use as the default graphs in the query operation. This is addressed ashttp://host:port/v1/graphs/sparql?default-graph-uri=<default-graph-uri*>named-graph-uri*- The URI of the graph or graphs to include in the query operation. This is addressed ashttp://host:port/v1/graphs/sparql?named-graph-uri=<named-graph-uri*>The
*indicates that one or moredefault-graph-uriornamed-graph-uriparameters can be specified. The named-graph-uri parameter is used withFROM NAMEDandGRAPHin queries to specify the IRI(s) to be substituted for a name within particular kinds of queries. You can have one or more named-graph-uri specified as part of a query.database?- The database on which to perform the query.base?- The initial base IRI for the query.bind:{name}*- A binding name and value. This format assumes that the type of the bind variable is an IRI.bind:{name}:{type}*- A binding name, type, and value. This parameter accepts an XSD type, for example string, date or unsignedLong.bind:{name}@{lang}*- A binding name, language tag, and value. Use this pattern to bind to language-tagged strings.txid?- The transaction identifier of the multi-statement transaction in which to service this request. Use the/transactionsservice to create and manage multi-statement transactions.start?- The index of the first result to return. Results are numbered beginning with 1. The default is 1.pageLength?- The maximum number of results to return in this request.
These optional search query parameters can be used to constrain which documents will be searched with the SPARQL query:
q?- A string query.structuredQuery?- A structured search query string, a serialized representation of asearch:queryelement.options?- The name of query options.
If you do not specify a graph name with a query, the UNION of all graphs will be queried. If you specify default-graph-uri, one or more graph names that you specify will be queried (this is not the default graph that contains the unnamed triples). You can also query http://marklogic.com/semantics#default-graph, where unnamed triples are stored.
Any valid IRI can be used for these graph names (for example, /my_graph/ or http://www.example.com/rdf-graph-store/). The default-graph-uri is used to specify one or more default graphs to query as part of the operation, and the named-graph-uri can specify one or more additional graphs to use in the operation. If no dataset is defined, the dataset will include all triples (the UNION of all graphs).
If you specify a dataset in both the request parameters and the query, the dataset defined with named-graph-uri or default-graph-uri takes precedence. When you specify more than one default-graph-uri or named-graph-uri in a query via the REST Client API, the format will be http://host:port/v1/graphs/sparql?named-graph-uri=<named-graph-uri*> for each graph named in the query.
For example, this is a simple REST request to send the SPARQL query in the bills.sparql file and return the results as JSON:
curl --anyauth --user admin:admin -i -X POST \ --data-binary @./bills.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/sparql-results+json" \ http://localhost:8000/v1/graphs/sparql => HTTP/1.1 200 OK Content-type: application/sparql-results+json; charset=UTF-8 Server: MarkLogic Content-Length: 1268 Connection: Keep-Alive Keep-Alive: timeout=5 {"head":{"vars":["bill","title"]}, "results":{"bindings":[ {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1171"}, "title":{"type":"literal", "value":"H.R. 108/1171: Iris Scan Security Act of 2003", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1314"}, "title":{"type":"literal", "value":"H.R. 108/1314: Screening Mammography Act of 2003", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1384"}, "title":{"type":"literal", "value":"H.R. 108/1384: To amend the Railroad Retirement Act of 1974 to eliminate a limitation on benefits.", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1418"}, "title":{"type":"literal", "value":"H.R. 108/1418: Veterans' Housing Equity Act", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, ... }]}}
In the command line example above, long lines have been broken into multiple lines using the UNIX line continuation character '\' and extra line breaks have been added for readability. Extra line breaks for readability have been added in the results.
SPARQL Update Parameters
In addition to the query parameters, these parameters can be used with SPARQL Update on the POST /v1/graphs/sparql endpoint:
update- The URL-encoded SPARQL Update operation. Only use this parameter when you put the request parameters in the request body and useapplication/x-www-form-urlencodedas the request content type.using-graph-uri*- The URI of the graph or graphs to address as part of a SPARQL Update operation. This is addressed ashttp://host:port/v1/graphs/sparql?using-graph-uri=<using-graph-uri*>using-named-graph-uri*- The URI of a named graph or graphs to address as part of a SPARQL update operation. This is addressed ashttp://host:port/v1/graphs/sparql?using-named-graph-uri=<using-named-graph-uri*>perm:{role}*- Assign permissons to the inserted graph(s), and the permission has a role and a capability. When you insert a new graph, you can set its permissions to allow a certain capability for a certain role. Valid values for the permissions:read,update,execute. These permissions only apply to newly created graphs. See Managing Graph Permissions for more about permissions.txid?- The transaction identifier of the multi-statement transaction in which to service this request. Use the/transactionsservice to create and manage multi-statement transactions.database?- The database on which to perform the query.base?- The initial base IRI for the query.bind:{name}*- A binding name and value. This format assumes that the type of the bind variable is an IRI.bind:{name}:{type}*- A binding name, type, and value. This parameter accepts an XSD type, for example string, date or unsignedLong.bind:{name}@{lang}*- A binding name, language tag, and value. Use this pattern to bind to language-tagged strings.
See Target RDF Graph for more information about graphs. See Querying Triples in the REST Application Developer's Guide for more infomation about using the REST Client API with RDF triples.
Supported Operations for the REST Client API
For the /v1/graphs/sparql endpoint, these operations are supported:
For SPARQL Update, only POST /v1/graphs/sparql is suported.
There is also a /v1/graphs endpoint and a /v1/graphs/things endpoint to access and view RDF data. For the /v1/graphs endpoint, these verbs are supported:
And for the /v1/graphs/things endpoint, the verb GET is supported for REST requests:
| Operation | Description | Method | Privilege |
|---|---|---|---|
| Retrieve | Retrieves a list of all graph nodes in the database, or a specified set of nodes. | GET | rest-reader |
Serialization
Serialization of RDF data occurs whenever it is loaded, queried, or updated. The data can be serialized in a variety of ways. The supported serializations are shown in the table shown in Supported RDF Triple Formats.
Several types of optimized serialization are available for SPARQL results (solutions - sets of bindings) and RDF (triples) over REST. Using these serializations in your interactions will make them faster. These serializations specify a MIME type for the input and output format. Formats are specified as part of the accept headers of the REST request.
We recommend using one of the following choices for optimized serialization of SPARQL results when using the /v1/graphs/sparql endpoint:
For CONSTRUCT or DESCRIBE all of the supported triples formats are supported. See the table in Supported RDF Triple Formats.
N-Quads and TriG formats are quad formats, not triple formats, and REST does not serialize quads.
For optimized RDF results (triple or quads), choose one of these serialization options when using the /v1/graphs endpoint:
| Format | RDF Query Type
/v1/graphs |
MIME Type/Accept Header |
|---|---|---|
n-triples |
CONSTRUCT or DESCRIBE |
application/n-triples |
n-quads |
SELECT or ASK |
application/quads |
This information is shown in a different way in SPARQL Query Types and Output Formats. For more about serialization, see Setting Output Options for an HTTP Server in the Administrator's Guide.
Unsupported Serialization
A GET or POST request for a response in an unsupported serialization yields a 406 Not Acceptable error. If the SPARQL payload fails to parse, the response yields a 400 Bad Request error.
<rapi:error xmlns:rapi="http://marklogic.com/rest-api"> <rapi:status-code>400</rapi:status-code> <rapi:status>Bad Request</rapi:status> <rapi:message-code>RESTAPI-INVALIDCONTENT</rapi:message-code> <rapi:message>RESTAPI-INVALIDCONTENT: (err:FOER0000) Invalid content: Unexpected Payload: c:\space\example.ttl</rapi:message> </rapi:error>
For more about the REST Client API error handling, see Error Reporting in the REST Application Developer's Guide.
Examples Using curl and REST
These two examples use curl with cygwin (Linux) and Windows to do Semantic queries over REST. This SPARQL query is encoded and used in the examples:
SELECT * WHERE { ?s ?p ?o }
For readability, the character ( \ ) is used in the cygwin (Linux) example to indicate a line break. The actual request must be entered on one continuous line. The query looks like this:
curl --anyauth --user user:password "http://localhost:8000/v1/graphs/sparql" \ -H "Content-type:application/x-www-form-urlencoded" \ -H "Accept:application/sparql-results+xml" \ -X POST --data-binary 'query=SELECT+*+WHERE+{+%3fs+%3fp+%3fo+}' => <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="s"/> <variable name="p"/> <variable name="o"/> </head> <results> <result> <binding name="s"><uri>http://example/book1/</uri></binding> <binding name="p"><uri>http://purl.org/dc/elements/1.1/title</uri></binding> <binding name="o"><literal>A new book</literal></binding> </result> <result> <binding name="s"> <uri>http://example/book1/</uri> </binding> <binding name="p"> <uri>http://purl.org/dc/elements/1.1/title</uri> </binding> <binding name="o"> <literal>Inside MarkLogic Server</literal> </binding> </result> <result> <binding name="s"> <uri>http://www.w3.org/2000/01/rdf-schema#subClassOf</uri> </binding> <binding name="p"> <uri>http://www.w3.org/2000/01/rdf-schema#domain</uri> </binding> <binding name="o"> <uri>http://www.w3.org/2000/01/rdf-schema#Class</uri> </binding> </result> <result> <binding name="s"> <uri>http://www.w3.org/2000/01/rdf-schema#subClassOf</uri> </binding> <binding name="p"> <uri>http://www.w3.org/2000/01/rdf-schema#range</uri> </binding> <binding name="o"> <uri>http://www.w3.org/2000/01/rdf-schema#Class</uri> </binding> </result> </results></sparql>
The results have been formatted for clarity.
In the Windows example, the character ( ^ ) is used to indicate a line break for readability. The actual request must be entered on one continuous line. The Windows query looks like this:
curl --anyauth --user user:password "http://localhost:8000/v1/graphs/sparql" ^ -H "Content-type:application/x-www-form-urlencoded" ^ -H "Accept:application/sparql-results+xml" ^ -X POST --data-binary 'query=SELECT+*+WHERE+{+%3fs+%3fp+%3fo+}' => <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="s"/> <variable name="p"/> <variable name="o"/> </head> <results> <result> <binding name="s"> <uri>http://example.org/marklogic/people/Jack_Smith</uri> </binding> <binding name="p"> <uri>http://example.org/marklogic/predicate/livesIn</uri> </binding> <binding name="o"><literal>Glasgow</literal> </binding> </result> <result> <binding name="s"> <uri>http://example.org/marklogic/people/Jane_Smith</uri> </binding> <binding name="p"> <uri>http://example.org/marklogic/predicate/livesIn</uri> </binding> <binding name="o"> <literal>London</literal> </binding> </result> <result> <binding name="s"> <uri>http://example.org/marklogic/people/John_Smith</uri> </binding> <binding name="p"> <uri>http://example.org/marklogic/predicate/livesIn</uri> </binding> <binding name="o"> <literal>London</literal> </binding> </result> </results></sparql>
Response Output Formats
This section describes the header types and response output formats available when using SPARQL endpoints with the REST Client API. Examples of results in different formats are included. These topics are covered:
- SPARQL Query Types and Output Formats
- Example: Returning Results as XML
- Example: Returning Results as JSON
- Example: Returning Results as HTML
- Example: Returning Results as CSV
- Example: Returning Results as N-triples
- Example: Returning a Boolean as XML or JSON
SPARQL Query Types and Output Formats
When you query the SPARQL endpoint with REST Client APIs (GET /v1/graphs/sparql or POST /v1/graphs/sparql), you can specify the result output format. The response type format depends on the type of query and the MIME type in the HTTP Accept header.
A SPARQL SELECT query can return results as XML, JSON, HTML, or CSV, while a SPARQL CONSTRUCT query can return the results as triples in N-Triples or N-Quads format, or XMLor JSON triples in any of the supported triples formats. A SPARQL DESCRIBE query returns triples in XML, N-Triples, or N-Quads format describing the triples found by the query. Using SPARQL ASK query will return a boolean (true or false) in either XML or JSON. See Types of SPARQL Queries for more information about query types.
This table describes the MIME types and Accept Header/Output formats (MIME type) for different types of SPARQL queries.
| Query Type | Format | Accept Header MIME Type |
|---|---|---|
xml |
See Example: Returning Results as XML and Example: Returning a Boolean as XML or JSON. |
|
json |
||
html |
||
csv |
See Example: Returning Results as CSV. Note: Only preserves the order of the results, not the type. |
|
Note: ASK queries return a boolean (true or false). |
||
n-triples |
For faster serialization - see Example: Returning Results as N-triples. Note: If you want triples returned as JSON, the proper MIME type is |
|
| other | CONSTRUCT or DESCRIBE queries return RDF triples in any of the available formats. See Supported RDF Triple Formats |
|
You can request any of the triple MIME types (application/rdf+xml, text/turtle, and so on), but use application/n-triples for best performance. See Serialization for details.
The following examples use this SPARQL SELECT query to find US Congress bills that were sponsored by Robert Andrews (A000210):
#filename bills.sparql PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> PREFIX people: <http://www.rdfabout.com/rdf/usgov/congress/people/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?bill ?title WHERE { ?bill rdf:type bill:HouseBill ; dc:title ?title ; bill:sponsor people:A000210 . } LIMIT 5
The SPARQL query is saved as bills.sparql. The query limits responses to 5 results. Using curl and the REST Client API, you can query the SPARQL endpoint and get the results back in a variety of formats.
If you use curl to make a PUT or POST request and read in the request body from a file, use --data-binary rather than -d to specify the input file. When you use --data-binary, curl inserts the data from the file into the request body as-is. When you use -d, curl strips newlines from the input, which can make your triple data or SPARQL syntactically invalid.
Example: Returning Results as XML
The SPARQL SELECT query in the bills.sparql file returns the response in XML format in this example.
curl --anyauth --user admin:password -i -X POST \ --data-binary @./bills.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/sparql-results+xml" \ http://localhost:8050/v1/graphs/sparql => HTTP/1.1 200 OK Content-type: application/sparql-results+xml Server: MarkLogic Content-Length: 1528 Connection: Keep-Alive Keep-Alive: timeout=5 <sparql xmlns="http://www.w3.org/2005/sparql-results/"> <head><variable name="bill"/> <variable name="title"/> </head> <results> <result> <binding name="bill"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1171 </uri> </binding><binding name="title"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> H.R. 108/1171: Iris Scan Security Act of 2003 </literal> </binding> </result> <result> <binding name="bill"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1314/ </uri> </binding> <binding name="title"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> H.R. 108/1314: Screening Mammography Act of 2003</literal> </binding> </result> <result> <binding name="bill"><uri>http://www.rdfabout.com/rdf/usgov /congress/108/bills/h1384/</uri> </binding> ... </result> </results> </sparql>
In the example above, long lines have been broken into multiple lines using the UNIX line continuation character '\' and extra line breaks have been added for readability. Extra line breaks for readability have also been added in the results.
Example: Returning Results as JSON
The SPARQL SELECT query in the bills.sparql file returns the response in JSON format in this example:
curl --anyauth --user admin:password -i -X POST \ --data-binary @./bills.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/sparql-results+json" \ http://localhost:8050/v1/graphs/sparql => HTTP/1.1 200 OK Content-type: application/sparql-results+json Server: MarkLogic Content-Length: 1354 Connection: Keep-Alive Keep-Alive: timeout=5 {"head":{"vars":["bill","title"]}, "results":{"bindings":[ {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1171"}, "title":{"type":"literal", "value":"H.R. 108/1171: Iris Scan Security Act of 2003", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1314"}, "title":{"type":"literal", "value":"H.R. 108/1314: Screening Mammography Act of 2003", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1384"}, "title":{"type":"literal", "value":"H.R. 108/1384: To amend the Railroad Retirement Act of 1974 to eliminate a limitation on benefits.", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, {"bill":{"type":"uri", "value":"http://www.rdfabout.com/rdf/usgov/congress/108/ bills/h1418"}, "title":{"type":"literal", "value":"H.R. 108/1418: Veterans' Housing Equity Act", "datatype":"http://www.w3.org/2001/XMLSchema#string"}}, ... }]}}
In the command line example above, long lines have been broken into multiple lines using the UNIX line continuation character '\' and extra line breaks have been added for readability. Extra line breaks for readability have also been added in the results.
Example: Returning Results as HTML
The same SPARQL SELECT query in the bills.sparql file returns the response in HTML format in this example:
curl --anyauth --user admin:password -i -X POST \ --data-binary @./bills.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: text/html" http://localhost:8050/v1/graphs/sparql" => HTTP/1.1 200 OK Content-type: text/html; charset=UTF-8 Server: MarkLogic Content-Length: 1448 Connection: Keep-Alive Keep-Alive: timeout=5 <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>SPARQL results</title> </head> <body><table border="1"> <tr> <th>bill</th> <th>title</th></tr> <tr> <td><a href="/v1/graphs/things?iri=http%3a//www.rdfabout.com/ rdf/usgov/congress/108/bills/h1171">http://www.rdfabout.com/ rdf/usgov/congress/108/bills/h1171</a> </td> <td>H.R. 108/1171: Iris Scan Security Act of 2003</td> </tr><tr> <td><a href="/v1/graphs/things?iri=http%3a//www.rdfabout.com/ rdf/usgov/congress/108/bills/h1314">http://www.rdfabout.com/ rdf/usgov/congress/108/bills/h1314</a> </td> <td>H.R. 108/1314: Screening Mammography Act of 2003</td> </tr><tr> <td><a href="/v1/graphs/things?iri=http%3a//www.rdfabout.com/ rdf/usgov/congress/108/bills/h1384">http://www.rdfabout.com/ rdf/usgov/congress/108/bills/h1384</a> </td> <td>H.R. 108/1384: To amend the Railroad Retirement Act of 1974 to eliminate a limitation on benefits. </td> </tr> ... </table> </body> </html>
In the preceding example, long lines have been broken into multiple lines using the UNIX line continuation character '\' and extra line breaks have been added for readability. Extra line breaks for readability have also been added in the results.
Example: Returning Results as CSV
Here is the same SPARQL SELECT query (bills.sparql) with the results returned in CSV format:
curl --anyauth --user Admin:janem-3 -i -X POST --data-binary \ @./bills.sparql -H "Content-type: application/sparql-query" \ -H "Accept: text/csv" http://janem-3:8000/v1/graphs/sparql => bill,title http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1171,H.R. 108/1171: Iris Scan Security Act of 2003 http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1314,H.R. 108/1314: Screening Mammography Act of 2003 http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1384,H.R. 108/1384: To amend the Railroad Retirement Act of 1974 to eliminate a limitation on benefits. http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1418,H.R. 108/1418: Veterans' Housing Equity Act http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1419,H.R. 108/1419: Seniors' Family Business Enhancement Act[jmckean@janem-3 ~]$
In the preceding example, long lines have been broken into multiple lines using the UNIX line continuation character '\' and extra line breaks have been added for readability. Extra line breaks for readability have also been added in the results.
Example: Returning Results as N-triples
For this example, we will use a DESCRIBE query that was introduced and used earlier:
DESCRIBE <http://dbpedia.org/resource/Pascal_Bedrossian>
The following command uses this query to match triples that describe Pascal and return the results as N-Triples. Long lines in the command below have been broken with the UNIX line continuation character \. The query is URL encoded and passed as the value of the query request parameter.
curl -X GET --digest --user "admin:password" \ -H "Accept: application/n-triples" \ -H "Content-type: application/x-www-form-urlencoded"\ "http://localhost:8321/v1/graphs/sparql?query=DESCRIBE%20%3Chttp\ %3A%2F%2Fdbpedia.org%2Fresource%2FPascal_Bedrossian%3E" => <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/France> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Marseille> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/surname> "Bedrossian"@en . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/givenName> "Pascal"@en . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/name> "Pascal Bedrossian"@en . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://purl.org/dc/elements/1.1/description> "footballer"@en . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthDate> "1974-11-28"^^<http://www.w3.org/2001/XMLSchema#date> .
Example: Returning a Boolean as XML or JSON
In this example, a SPARQL ASK query (from an earlier example) is used to determine whether Carolyn Kennedy was born after Eunice Kennedy.
Here are the contents of the ask-sparql.sparql file used in the following query:
#file: ask-sparql.sparql PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> ASK { db:Carolyn_Bessette-Kennedy onto:birthDate ?by . db:Eunice_Kennedy_Shriver onto:birthDate ?bd . FILTER (?by>?bd). }
If you use curl to make a PUT or POST request and read in the request body from a file, use --data-binary rather than -d to specify the input file. When you use --data-binary, curl inserts the data from the file into the request body as-is. When you use -d, curl strips newlines from the input, which can make your triple data or SPARQL syntactically invalid.
This request, containing SPARQL ASK query, returns the boolean result as XML:
curl --anyauth --user user:password -i -X POST \ --data-binary @./ask-sparql.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/sparql-results+xml" \ http://localhost:8050/v1/graphs/sparql => HTTP/1.1 200 OK Content-type: application/sparql-results+xml Server: MarkLogic Content-Length: 89 Connection: Keep-Alive Keep-Alive: timeout=5 <sparql <xmlns="http://www.w3.org/2005/sparql-results/"> <boolean>true</boolean> </sparql>
Here is the same request (containing the SPARQL ASK query) where the boolean result is returned as JSON:
curl --anyauth --user user:password -i -X POST \ --data-binary @./ask-sparql.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/sparql-results+json" \ http://localhost:8050/v1/graphs/sparql => HTTP/1.1 200 OK Content-type: application/sparql-results+json Server: MarkLogic Content-Length: 17 Connection: Keep-Alive Keep-Alive: timeout=5 {"boolean":true}
SPARQL Query with the REST Client API
SPARQL queries (SELECT, DESCRIBE, CONSTRUCT, and ASK) can be used with either POST or GET and the REST Client API. For more about query types and output, see the table in SPARQL Query Types and Output Formats.
This section includes the following:
SPARQL Queries in a POST Request
This section describes how SPARQL query can be used to manage graphs and triple data through /v1/graphs/sparql endpoint.
http://hostname:port/v1/graphs/sparql
where the hostname and port are the host and port on which you are running MarkLogic.
You can specify your input SPARQL query to POST /v1/graphs/sparql in the following ways:
This is a SPARQL DESCRIBE query used to find out about US Congress bill 44. The query is saved as a file, named bill44.sparql.
#file name bill44.sparql PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> DESCRIBE ?x WHERE { ?x rdf:type bill:HouseBill ; bill:number "44" . }
If you use curl to make a PUT or POST request and read in the request body from a file, use --data-binary rather than -d to specify the input file. When you use --data-binary, curl inserts the data from the file into the request body as-is. When you use -d, curl strips newlines from the input, which can make your triple data or SPARQL syntactically invalid.
The endpoint requires a SPARQL query to be either a parameter or in the POST body. In the following example, the bill44.sparql file with the DESCRIBE query is passed to the body of the POST request:
# Windows users, see Modifying the Example Commands for Windows curl --anyauth --user admin:password \ -i -X POST --data-binary @./bill44.sparql \ -H "Content-type: application/sparql-query" \ -H "Accept: application/rdf+xml" \ http://localhost:8000/v1/graphs/sparql
The request body MIME type is specified as application/sparql-query and the requested response MIME type (the Accept:) is specified as application/rdf+xml. The output is returned as triples in XML format. See Response Output Formats for more details.
The query returns the following triples describing bill 44:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns"> <OfficialTitle rdf:ID="bnodebnode309771418819f878" xmlns="http://www.rdfabout.com/rdf/schema/usbill/"> <rdf:typerdf:resource="http://www.rdfabout.com/rdf/schema/usbill /OfficialTitle"/> <rdf:value rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> To amend the Internal Revenue Code of 1986 to provide reduced capital gain rates for qualified economic stimulus gain and to index the basis of assets of individuals for purposes of determining gains and losses.</rdf:value></OfficialTitle> <ShortTitle rdf:ID="bnodebnode30b47143b819db78" xmlns="http://www.rdfabout.com/rdf/schema/usbill/"> <rdf:type rdf:resource="http://www.rdfabout.com/rdf/schema/usbill /ShortTitle"/> <rdf:value rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> Investment Tax Incentive Act of 2003</rdf:value></ShortTitle> <ShortTitle rdf:ID="bnodebnodee1860b72fb58b315" xmlns="http://www.rdfabout.com/rdf/schema/usbill/"> <rdf:type rdf:resource="http://www.rdfabout.com/rdf/schema/usbill /ShortTitle"/> <rdf:value rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> Investment Tax Incentive Act of 2003</rdf:value></ShortTitle> <HouseBill rdf:about="http://www.rdfabout.com/rdf/usgov/congress/108 /bills/h44" xmlns="http://www.rdfabout.com/rdf/schema/usbill/"> <inCommittee rdf:resource="http://www.rdfabout.com/rdf/usgov /congress/committees/HouseWaysandMeans"/> <cosponsor rdf:resource="http://www.rdfabout.com/rdf/usgov/congress /people/A000358"/> <cosponsor rdf:resource="http://www.rdfabout.com/rdf/usgov/congress /people/B000208"/> <cosponsor rdf:resource="http://www.rdfabout.com/rdf/usgov/congress /people/B000575"/> <cosponsor .....
Another way to use the POST request is to specify the URL-encoded query as the value of the query parameter and use application/x-www-form-urlencoded as the request body MIME type, as described in the Semantics documentation of the REST Client API.
The following SPARQL SELECT query finds the House of Congress bills that were cosponsored by the person with a Congress BioGuideID of A000358:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> PREFIX people: <http://www.rdfabout.com/rdf/usgov/congress/people/> SELECT ?x WHERE { ?x rdf:type bill:HouseBill ; bill:cosponsor people:A000358. }
In this example, the SELECT query is URL-encoded and then sent as form-encoded data:
curl -X POST --anyauth --user admin:password \ -H "Accept:application/sparql-results+xml" --data-binary \ "query=PREFIX%20rdf%3A%20%3Chttp%3A%2F%2Fwww.w3.org%2F1999%2F02%2F22-r df-syntax-ns\ %23%3E%20%0APREFIX%20bill%3A%20%3Chttp%3A%2F%2Fwww.rdfabout.com%2Frdf\ %2Fschema%2Fusbill%2F%3E%0APREFIX%20people%3A%20%3Chttp%3A%2F%2Fwww.rdfabout.com\ %2Frdf%2Fusgov%2Fcongress%2Fpeople%2F%3E%0ASELECT%20%3Fx%20WHERE%20%7B%20%3Fx\ %20rdf%3Atype%20bill%3AHouseBill%20%3B%20bill%3Acosponsor%20%20people%3AA000358.%20%7D%0A"\ -H "Content-type:application/x-www-form-urlencoded" \ http://localhost:8000/v1/graphs/sparql => <sparql xmlns="http://www.w3.org/2005/sparql-results/"> <head><variable name="x"/></head> <results> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1036 </uri></binding></result> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1057 </uri></binding></result> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1078 </uri></binding></result> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h110 </uri></binding></result> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1117 </uri></binding></result> <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h1153 </uri></binding></result> ....... <result><binding name="x"> <uri>http://www.rdfabout.com/rdf/usgov/congress/108/bills/h975 </uri></binding></result> </results> </sparql>
For readability, the long command line is broken into multiple lines using the UNIX line continuation character '\'. Extra line breaks have been inserted for readability of the URL-encoded query.
SPARQL Queries in a GET Request
For a GET request, the SPARQL query in the query request parameter must be URL-encoded. Here is the SPARQL DESCRIBE query, searching for a US Congress bill (44), before it is encoded:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> DESCRIBE ?x WHERE { ?x rdf:type bill:HouseBill ; bill:number "44" . }
In this example curl sends an HTTP GET request to execute the SPARQL DESCRIBE query :
curl -X GET --digest --user "user:password" \ -H "accept: application/sparql-results+xml" \ "http://localhost:8000/v1/graphs/sparql?query=PREFIX%20rdf%3A%20%3C\ http%3A%2F%2Fwww.w3.org%2F1999%2F02%2F22-rdf-syntax-ns%23%3E%20%0A\ PREFIX%20bill%3A%20%3Chttp%3A%2F%2Fwww.rdfabout.com%2Frdf%2Fschema\ %2Fusbill%2F%3E%0ADESCRIBE%20%3Fx%20WHERE%20%7B%20%3Fx%20rdf%3Atype\ %20bill%3AHouseBill%20%3B%20%20bill%3Anumber%20%2244%22%20.%20%7D"
Your results will be similar to these triples:
<http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://purl.org/dc/elements/1.1/title> "H.R. 108/44: Investment Tax Incentive Act of 2003" . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://purl.org/dc/terms/created> "2003-01-07" . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://purl.org/ontology/bibo/shortTitle> "H.R. 44: Investment Tax Incentive Act of 2003" . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://www.rdfabout.com/rdf/schema/usbill/congress> "108" . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://www.rdfabout.com/rdf/schema/usbill/cosponsor> <http://www.rdfabout.com/rdf/usgov/congress/people/A000358> . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://www.rdfabout.com/rdf/schema/usbill/cosponsor> <http://www.rdfabout.com/rdf/usgov/congress/people/B000208> . <http://www.rdfabout.com/rdf/usgov/congress/108/bills/h44> <http://www.rdfabout.com/rdf/schema/usbill/cosponsor> <http://www.rdfabout.com/rdf/usgov/congress/people/B000575> .
The triples describe information about bill 44 in the U.S. Congress; it's title, when it was created, who cosponsored the bill, and so on.
SPARQL Update with the REST Client API
This section describes how SPARQL Update can be used to manage graphs and triple data through /v1/graphs/sparql endpoint.
http://hostname:port/v1/graphs/sparql
where the hostname and port are the host and port on which you are running MarkLogic.
You can specify your SPARQL Update (which is a DELETE/INSERT) to POST /v1/graphs/sparql in the following ways:
- Include a SPARQL Update as a file in the
POSTbody in the form of:http://host:port/v1/graphs/sparql content-type:application/sparql-update
- Include the SPARQL Update as URL-encoded data in the form of:
http://host:port/v1/graphs/sparql content-type:application/x-www-form-urlencoded
The examples in this section use a POST request, with no URL encoding, and with content-type:application/sparql-update.
You can specify the RDF dataset against which to execute the update using the using-graph-uri and using-named-graph-uri request parameters, or within the update. If the dataset is specified in both the request parameters and the update, the dataset defined by the request parameters is used. If neither is specified, all graphs (the UNION of all graphs) are included in the operation.
Including the using-graph-uri or using-named-graph-uri parameters, with a SPARQL 1.1 Update request that contains an operation that uses the USING, USING NAMED, or WITH clause, will cause an error.
See Specifying Parameters for details on specifying parameters for use with the REST Client API. See Supported Operations for the REST Client API and the list of verbs supported by the Graph store endpoint for SPARQL Update for more about POST. See POST /v1/graphs/sparql for more about the SPARQL endpoint.
This section includes the following:
SPARQL Update in a POST Request
You can send requests using the POST method by including SPARQL Update in the request body. Set the Content-type HTTP header to application/sparql-update.
Here is the SPARQL Update before it is added to the request body:
PREFIX dc: <http://purl.org/dc/elements/1.1/> WITH <BOOKS> DELETE {?b dc:title "A new book"} INSERT {?b dc:title "Inside MarkLogic Server" } WHERE {?b dc:title "A new book".}
In the graph named <BOOKS>, SPARQL Update matches a triple with dc:title in the predicate position and A new book in the object position and deletes it. Then a new triple is inserted (?b dc:title "MarkLogic Server").
In this example, the SPARQL Update is sent in the request body using application/sparql-update and the -d option for the query:
# Windows users, see Modifying the Example Commands for Windows curl --anyauth --user admin:admin -i -X POST \ -H "Content-type:application/sparql-update" \ -H "Accept:application/sparql-results+xml" \ -d 'PREFIX dc: <http://purl.org/dc/elements/1.1/> \ WITH <BOOKS> \ DELETE {?b dc:title "A new book"} \ INSERT {?b dc:title "Inside MarkLogic Server" } \ WHERE {?b dc:title "A new book".}' \ http://localhost:8000/v1/graphs/sparql
For clarity, long command lines are broken into multiple lines using the line continuation characters \ . Remove the line continuation characters when you use the curl command. (For Windows the line continution character is ^.)
Alternatively, you can use curl to execute a SPARQL Update from a file as part of a POST request. The SPARQL Update is saved in a file named booktitle.sparql. Here are the file contents:
PREFIX dc: <http://purl.org/dc/elements/1.1/> INSERT DATA { <http://example/book1> dc:title "book title" ; dc:creator "author name" . }
The POST request with the SPARQL Update in a file would look like this:
curl --anyauth --user admin:admin -i -X POST \ --data-binary @./booktitle.sparql \ -H "Content-type:application/sparql-update" \ -H "Accept:application/sparql-results+xml" \ http://localhost:8000/v1/graphs/sparql
Notice that the request uses the --data-binary option instead of -d to call the file containing the SPARQL Update. You can include using-graph-uri, using-named-graph-uri and role-capability as HTTP request parameters. The perm parameter is expected in this syntax, with role and capability.
perm:admin=update&perm:admin=execute
See Default Permissions and Required Privileges for more about permissions.
SPARQL Update via POST with URL-encoded Parameters
You can also send update protocol requests via the HTTP POST method by URL-encoding the parameters. When you do this, URL percent-encode all parameters and include them as parameters within the request body via the application/x-www-form-urlencoded media type. The content type header of the HTTP request is set to application/x-www-form-urlencoded.
This next example uses SPARQL Update and POST with URL-encoded parameters to insert data (along with a set of permissions) into graph C1.
curl --anyauth --user admin:admin -i -X POST \ --data-urlencode update='PREFIX dc: <http://purl.org/dc/elements/1.1/> \ INSERT DATA \ {<http://example/book1> dc:title "book title" ; \ dc:creator "author name" .}' \ -H "Content-type:application/x-www-form-urlencoded" \ -H "Accept:application/sparql-results+xml" \ 'http://localhost:8000/v1/graphs/sparql?using-named-graph-uri=C1 \ &perm:admin=update&perm:admin+execute'
If you supply the using-graph-uri or using-named-graph-uri parameters when using this protocol to convey a SPARQL 1.1 Update request that uses the USING NAMED, or WITH clause, the operation will result in an error.
This curl example uses POST with URL-encoding for the SPARQL Update and permissions:
curl --anyauth --user admin:admin -i -X POST \ -H "Content-type:application/x-www-form-urlencoded" \ -H "Accept:application/sparql-results+xml" \ --data-urlencode update='PREFIX dc: <http://purl.org/dc/elements/1.1/> INSERT DATA{ GRAPH <C1> {http://example/book1/> dc:title "C book"} }' \ --data-urlencode perm:rest-writer=read \ --data-urlencode perm:rest-writer=update \ http://localhost:8321/v1/graphs/sparql
If a new RDF graph is created, the server responds with a 201 Created message. The response to an update request indicates success or failure of the request via HTTP response status code (200 or 400). If the request body is empty, the server responds with 204 No Content.
Listing Graph Names with the REST Client API
You can list the graphs in your database with the REST Client API using the things endpoint.
http://hostname:port/v1/things
where the hostname and port are the host and port on which you are running MarkLogic.
For example when this endpoint is called with no parameters, a list of graphs in the database is returned:
http://localhost:8000/v1/things
The request might return graphs like these:
graphs/MyDemoGraph http://marklogic.com/semantics#default-graph http://marklogic.com/semantics#graphs
Exploring Triples with the REST Client API
The following endpoint provides RESTful access to knowledge (things) referred to in the database. This endpoint retrieves a list of all subject nodes in the database:
http://hostname:port/v1/graphs/things
where the hostname and port are the host and port on which you are running MarkLogic.
http://localhost:8050/v1/graphs/things
You can also specify a set of subject nodes to be returned. When this endpoint is called with no parameters, a list of subject nodes in the database is returned for all triples in the database.
This example shows the response, a list of nodes as IRIs, in a Web browser:
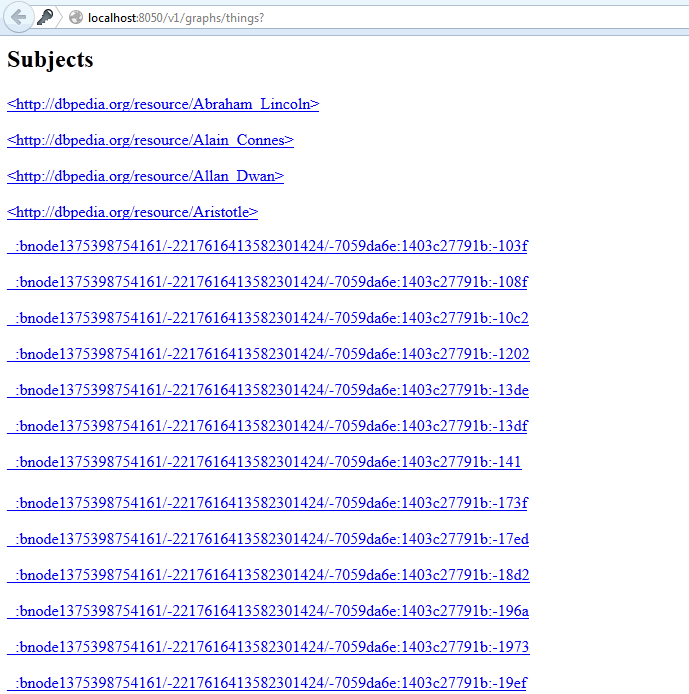
This endpoint has a hard-coded limit of 10,000 items to display, and does not support pagination.
You can traverse and navigate the triples in the database by clicking on the links and drilling down the nodes. Clicking on an IRI may return one or more related triples:

You can use an optional iri parameter to specify particular IRIs about which to return information, in Turtle triple serialization.
For example, you could paste this request into your browser:
http://localhost:8050/v1/graphs/things?iri=http://dbpedia.org/resource /Abraham_Lincoln
The nodes selected by the IRI http://dbpedia.org/resources/Abraham_Lincoln are returned in Turtle serialization:
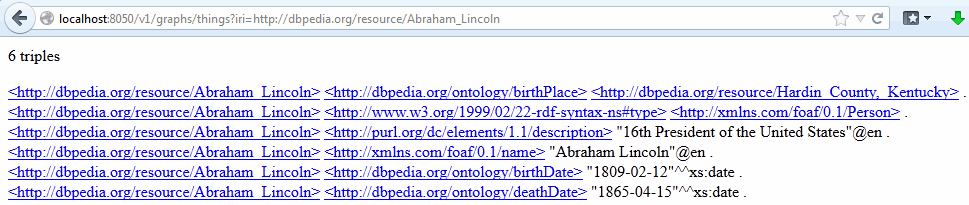
If you are using curl or an equivalent command-line tool for issuing HTTP requests, you can specify the following MIME types in the request Accept header:
- When no parameters are specified, use
text/htmlin the request Accept header. - When you use the
iriparameter, use one of the MIME types listed in SPARQL Query Types and Output Formats. See Supported RDF Triple Formats for additional information about RDF triple formats.
In this example, the GET request returns the nodes selected by the given iri parameter in Turtle triple serialization:
curl --anyauth --user admin:password -i -X GET \ -H "Accept: text/turtle" \ http://localhost:8051/v1/graphs/things?iri=http://dbpedia.org/resource/Aristotle => HTTP/1.1 200 OK Content-type: text/turtle; charset=UTF-8 Server: MarkLogic Content-Length: 628 Connection: Keep-Alive Keep-Alive: timeout=5 @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Aristotle> <http://dbpedia.org/ontology/deathPlace> <http://dbpedia.org/resource/Chalcis> . <http://dbpedia.org/resource/Aristotle> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Stagira_(ancient_city)> . <http://dbpedia.org/resource/Aristotle> <http://www.w3.org/1999/02/22-rdf-syntax -ns#type/> <http://xmlns.com/foaf/0.1/Person> . <http://dbpedia.org/resource/Aristotle> <http://xmlns.com/foaf/0.1/name> "Aristotle" . <http://dbpedia.org/resource/Aristotle> <http://purl.org/dc/elements/1.1/description> "Greek philosopher" .
If a given IRI does not exist, the response is 404 Not Found. A GET request for a response in an unsupported serialization will yield 406 Not Acceptable.
Managing Graph Permissions
This section covers the REST Client API support for setting, modifying, and retrieving graph permissions. If you are not already familiar with the MarkLogic security model, review the Security Guide.
The following topics are covered:
- Default Permissions and Required Privileges
- Setting Permissions as Part of Another Operation
- Setting Permissions Standalone
- Retrieving Graph Permissions
Default Permissions and Required Privileges
All graphs created and managed using the REST Client API grant read capability to the rest-reader role and update capability to the rest-writer role. These default permissions are always assigned to a graph, even if you do not explicitly specify them.
For example, if you create a new graph using PUT /v1/graphs and do not specify any permissions, the graph will have permissions similar to the following:
If you explicitly specify other permissions when creating the graph, the above default permissions are still set, as well as the permissions you specify.
You can use custom roles to limit access to selected users on a graph by graph basis. Your custom roles must include equivalent rest-reader and rest-writer privileges. Otherwise, users with these roles cannot use the REST Client API to manage or query semantic data.
For details, see Security Requirements in the REST Application Developer's Guide.
Setting Permissions as Part of Another Operation
Use the perm request parameter to set, overwrite, or add permissions as part of another graph operation. To manage permissions when not modifying graph content, use the category parameter instead. For details, see Setting Permissions Standalone.
The perm parameter has the following form:
perm:role=capability
Where role is the name of a role defined in MarkLogic and capability is one of read, insert, update, or execute.
You can specify the perm parameter multiple times to grant multiple capabilities to the same role or set permissions for multiple roles. For example, the following set of parameters grants the readers role the read capability and the writers role the update capability:
perm:readers=read&perm:writers=update
Setting or changing the permissions on a graph does not effect the permissions on documents that contain embedded triples in that graph.
You can use the perm parameter with the following operations:
The following restrictions apply:
- When you use the
permparameter with/v1/graphs, you must also include either thegraphor thedefaultrequest parameter. - You cannot use the
permparameter in conjunction withcategory=permissionsorcategory=metadata. - When you use the
permparameter to specify permissions as part of a SPARQL Update operation, the permissions only affect graphs created as part of the update. The permissions on pre-existing graphs remain unchanged.
Setting Permissions Standalone
Set the category request parameter to permissions to manage permissions without affecting the contents of a graph. For example, a request of the following form that includes permissions metadata in the request body sets the permissions on the default graph, but does not change the graph contents.
PUT /v1/graphs?default&category=permissions
To set or add permissions along with your graph content, use the perm request parameter. For details, see Setting Permissions as Part of Another Operation.
You can set the category parameter to either permissions or metadata. They are equivalent in the context of graph management.
The request body must contain permissions metadata. In XML, the metadata can be rooted at either a metadata element or the permissions element. Also, in XML, the metadata must be in the namespace http://marklogic.com/rest-api.
For example, all of the following are acceptable:
Setting or changing the permissions on a graph does not effect the permissions on documents that contain embedded triples in that graph.
You can use the category=permissions pattern to manage graph permissions with the following methods. In all cases, the graph contents are unaffected.
Retrieving Graph Permissions
To retrieve permissions metadata about a named graph, make a GET request of the following form:
GET /v1/graphs?graph=graphURI&category=permissions
To retrieve permissions metadata about the default graph, make a GET request of the following form:
GET /v1/graphs?default&category=permissions
You can request metadata in either XML or JSON. The default format is XML.
For example, the following command retrieves permissions for the graph with URI /my/graph, as XML. In this case, the graph includes both the default rest-writer and read-reader permissions and permissions for a custom role named GroupA.
curl --anyauth --user user:password -X GET -i \ -H "Accept: application/xml" \ 'http://localhost:8000/v1/graphs?graph=/my/graph&category=permissions' HTTP/1.1 200 OK Content-type: application/xml; charset=utf-8 Server: MarkLogic Content-Length: 868 Connection: Keep-Alive Keep-Alive: timeout=5 <rapi:metadata uri="/my/graph" ... xmlns:rapi="http://marklogic.com/rest-api" ...> <rapi:permissions> <rapi:permission> <rapi:role-name>rest-writer</rapi:role-name> <rapi:capability>update</rapi:capability> </rapi:permission> <rapi:permission> <rapi:role-name>rest-reader</rapi:role-name> <rapi:capability>read</rapi:capability> </rapi:permission> <rapi:permission> <rapi:role-name>GroupA</rapi:role-name> <rapi:capability>read</rapi:capability> <rapi:capability>update</rapi:capability> </rapi:permission> </rapi:permissions> </rapi:metadata>
The following data is the equivalent permissions metadata, expressed as JSON:
{"permissions":[ {"role-name":"rest-writer","capabilities":["update"]}, {"role-name":"rest-reader","capabilities":["read"]}, {"role-name":"GroupA","capabilities":["read","update"]} ]}