
MarkLogic 9 Product DocumentationApplication Developer's Guide — Chapter 23
Aggregate User-Defined Functions
This chapter describes how to create user-defined aggregate functions. This chapter includes the following sections:
- What Are Aggregate User-Defined Functions?
- In-Database MapReduce Concepts
- Implementing an Aggregate User-Defined Function
What Are Aggregate User-Defined Functions?
Aggregate functions are functions that take advantage of the MapReduce capabilities of MarkLogic Server to analyze values in lexicons and range indexes. For example, computing a sum or count over an element, attribute, or field range index. Aggregate functions are best used for analyses that produce a small number of results, rather than analyses that produce results in proportion to the number of range index values or the number of documents processed.
MarkLogic Server provides a C++ interface for defining your own aggregate functions. You build your aggregate user-defined functions (UDFs) into a dynamically linked library, package it as a native plugin, and install the plugin in MarkLogic Server. To learn more about native plugins, see Using Native Plugins.
A native plugin is automatically distributed throughout your MarkLogic cluster. When an application calls your aggregate UDF, your library is dynamically loaded into MarkLogic Server on each host in the cluster that participates in the analysis. To understand how your aggregate function runs across a cluster, see How In-Database MapReduce Works.
This chapter covers how to implement an aggregate UDF. For information on using aggregate UDFs, see Using Aggregate User-Defined Functions in the Search Developer's Guide.
In-Database MapReduce Concepts
MarkLogic Server uses In-Database MapReduce to efficiently parallelize analytics processing across the hosts in a MarkLogic cluster, and to move that processing close to the data.
This section covers the following topics:
You can explicitly leverage In-Database MapReduce efficiencies by using builtin and user-defined aggregate functions. For details, see Using Aggregate Functions in the Search Developer's Guide.
What is MapReduce?
MapReduce is a distributed, parallel programming model in which a large data set is split into subsets that are independently processed by passing each data subset through parallel map and reduce tasks. Usually, the map and reduce tasks are distributed across multiple hosts.
Map tasks calculate intermediate results by passing the input data through a map function. Then, the intermediate results are processed by reduce tasks to produce final results.
MarkLogic Server supports two types of MapReduce:
- In-database MapReduce distributes processing across a MarkLogic cluster when you use qualifying functions, such as builtin or user-defined aggregate functions. For details, see How In-Database MapReduce Works.
- External MapReduce distributes work across an Apache Hadoop cluster while using MarkLogic Server as the data source or result repository. For details, see the MarkLogic Connector for Hadoop Developer's Guide.
How In-Database MapReduce Works
In-Database MapReduce takes advantage of the internal structure of a MarkLogic Server database to do analysis close to the data. When you invoke an Aggregate User-Defined Function, MarkLogic Server executes it using In-Database MapReduce.
MarkLogic Server stores data in structures called forests and stands. A large database is usually stored in multiple forests. The forests can be on multiple hosts in a MarkLogic Server cluster. Data in a forest can be stored in multiple stands. For more information on how MarkLogic Server organizes content, see Understanding Forests in the Administrator's Guide and Clustering in MarkLogic Server in the Scalability, Availability, and Failover Guide.
In-Database MapReduce analysis works as follows:
- Your application calls an In-Database MapReduce function such as cts:sum-aggregate or cts:aggregate. The e-node where the function is evaluated begins a MapReduce job.
- The originating e-node distributes the work required by the job among the local and remote forests of the target database. Each unit of work is a task in the job.
- Each participating host runs map tasks in parallel to process data on that host. There is at least one map task per forest that contains data needed by the job.
- Each participating host runs reduce tasks to roll up the local per stand map results, then returns this intermediate result to the originating e-node.
- The originating e-node runs reduce tasks to roll up the results from each host.
- The originating e-node runs a finish operation to produce the final result.
Implementing an Aggregate User-Defined Function
You can create an aggregate user-defined function (UDF) by implementing a subclass of the marklogic::AggregateUDF C++ abstract class and deploying it as a native plugin.
The section covers the following topics:
- Creating and Deploying an Aggregate UDF
- Implementing AggregateUDF::map
- Implementing AggregateUDF::reduce
- Implementing AggregateUDF::finish
- Registering an Aggregate UDF
- Aggregate UDF Memory Management
- Implementing AggregateUDF::encode and AggregateUDF::decode
- Aggregate UDF Error Handling and Logging
- Aggregate UDF Argument Handling
- Type Conversions in Aggregate UDFs
Creating and Deploying an Aggregate UDF
An aggregate user-defined function (UDF) is a C++ class that performs calculations across MarkLogic range index values or index value co-occurrences. When you implement a subclass of marklogic::AggregateUDF, you write your own in-database map and reduce functions usable by an XQuery, Java, or REST application. The MarkLogic Server In-Database MapReduce framework handles distributing and parallelizing your C++ code, as described in How In-Database MapReduce Works.
An aggregate UDF runs in the same memory and process space as MarkLogic Server, so errors in your plugin can crash MarkLogic Server. Before deploying an aggregate UDF, you should read and understand Using Native Plugins.
To create and deploy an aggregate UDF:
- Implement a subclass of the C++ class
marklogic::AggregateUDF. See marklogic_dir/include/MarkLogic.hfor interface details. - Implement an
extern "C"function calledmarklogicPluginto perform plugin registration. See Registering a Native Plugin at Runtime. - Package your implementation into a native plugin. See Packaging a Native Plugin.
- Install the plugin by calling the XQuery function plugin:install-from-zip. See Installing a Native Plugin.
A complete example is available in marklogic_dir/Samples/NativePlugins. You should use the sample Makefile as the basis for building your plugin. For more details, see Building a Native Plugin Library.
The table below summarizes the key methods of marklogic::AggregateUDF that you must implement:
Implementing AggregateUDF::map
AggregateUDF::map has the following signature:
virtual void map(TupleIterator&, Reporter&);
Use the marklogic::TupleIterator to access the input range index values. Store your map results as members of the object on which map is invoked. Use the marklogic::Reporter for error reporting and logging; see Aggregate UDF Error Handling and Logging.
This section covers the following topics:
Iterating Over Index Values with TupleIterator
The marklogic::TupleIterator passed to AggregateUDF::map is a sequence of the input range index values assigned to one map task. You can do the following with a TupleIterator:
- Iterate over the tuples using
TupleIterator::nextandTupleIterator::done. T - Determine the number of values in each tuple using
TupleIterator::width. - Access the values in each tuple using
TupleIterator::value. - Query the type of a value in a tuple using
TupleIterator::type.
If your aggregate UDF is invoked on a single range index, then each tuple contains only one value. If your aggregate UDF is invoked on N indexes, then each tuple represents one N-way co-occurrence and contains N values, one from each index. For more information, see Value Co-Occurrences Lexicons in the Search Developer's Guide.
The order of values within a tuple corresponds to the order of the range indexes in the invocation of your aggregate UDF. The first index contributes the first value in each tuple, and so on. Empty (null) tuple values are possible.
If you try to extract a value from a tuple into a C++ variable of incompatible type, MarkLogic Server throws an exception. For details, see Type Conversions in Aggregate UDFs.
In the following example, the map method expects to work with 2-way co-occurrences of <name> (string) and <zipcode> (int). Each tuple is a (name, zipcode) value pair. The name is the 0th item in each tuple; the zipcode is the 1st item.
#include "MarkLogic.h" using namespace marklogic; ... void myAggregateUDF::map(TupleIterator& values, Reporter& r) { if (values.width() != 2) { r.error("Unexpected number of range indexes."); // does not return } for (; !values.done(); values.next()) { if (!values.null(0) && !values.null(1)) { String name; int zipcode; values.value(0, name); values.value(1, zipcode); // work with this tuple... } }
Controlling the Ordering of Map Input Tuples
MarkLogic Server passes input data to your map function through a marklogic::TupleIterator. By default, the tuples covered by the iterator are in descending order. You can control the ordering by overriding AggregateUDF::getOrder.
The following example causes input tuples to be delivered in ascending order:
#include "MarkLogic.h" using namespace marklogic; ... RangeIndex::getOrder myAggregateUDF::getOrder() const { return RangeIndex::ASCENDING; }
Implementing AggregateUDF::reduce
AggregateUDF::reduce folds together the intermediate results from two of your aggregate UDF objects. The object on which reduce is called serves as the accumulator.
The reduce method has the following signature. Fold the data from the input AggregateUDF into the object on which reduce is called. Use the Reporter to report errors and log messages; see Aggregate UDF Error Handling and Logging.
virtual void reduce(const AggregateUDF*, Reporter&);
MarkLogic Server repeatedly invokes reduce until all the map results are folded together, and then invokes finish to produce the final result.
For example, consider an aggregate UDF that computes the arthimetic mean of a set of values. The calculation requires a sum of the values and a count of the number of values. The map tasks accumulate intermediate sums and counts on subsets of the data. When all reduce tasks complete, one object on the e-node contains the sum and the count. MarkLogic Server then invokes finish on this object to compute the mean.
For example, if the input range index contains the values 1-9, then the mean is 5 (45/9). The following diagram shows the map-reduce-finish cycle if MarkLogic Server distributes the index values across 3 map tasks as the sequences (1,2,3), (4,5), and (6,7,8,9):
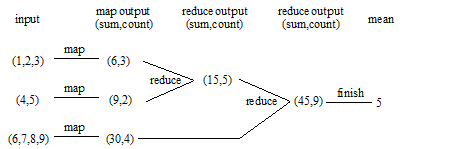
The following code snippet is an aggregate UDF that computes the mean of values from a range index (sum/count). The map method (not shown) computes a sum and a count over a portion of the range index and stores these values on the aggregate UDF object. The reduce method folds together the sum and count from a pair of your aggregate UDF objects to eventually arrive at a sum and count over all the values in the index:
#include "MarkLogic.h" using namespace marklogic; class Mean : public AggregateUDF { public: void reduce(const AggregateUDF* o, Reporter& r) sum += o->sum; count += o->count; } // finish computes the mean from sum and count .... protected: double sum; double count; };
For a complete example, see marklogic_dir/Samples/NativePlugin.
Implementing AggregateUDF::finish
AggregateUDF::finish performs final calculations and prepares the output sequence that is returned to the calling application. Each value in the sequence can be either a simple value (int, string, DateTime, etc.) or a key-value map (map:map in XQuery). MarkLogic Server invokes finish on the originating e-node, once per job. MarkLogic Server invokes finish on the aggregate UDF object that holds the cumulative reduce results.
AggregateUDF::finish has the following signature. Use the marklogic::OutputSequence to record your final values or map(s). Use the marklogic::Reporter to report errors and log messages; see Aggregate UDF Error Handling and Logging.
virtual void finish(OutputSequence&, Reporter&);
Use OutputSequence::writeValue to add a value to the output sequence. To add a value that is a key-value map, bracket paired calls to OutputSequence::writeMapKey and OutputSequence::writeValue between OutputSequence::startMap and OutputSequence::endMap. For example:
void MyAggregateUDF::finish(OutputSequence& os, Reporter& r) { // write a single value os.writeValue(int(this->sum/this-count)); // write a map containing 2 key-value pairs os.startMap(); os.writeMapKey("sum"); os.writeValue(this->sum); os.writeMapKey("count"); os.writeValue(this->count); os.endMap(); }
For information on how MarkLogic Server converts types between your C++ code and the calling application, see Type Conversions in Aggregate UDFs.
Registering an Aggregate UDF
You must register your Aggregate UDF implementation with MarkLogic Server to make it available to applications.
Register your implementation by calling marklogic::Registry::registerAggregate from marklogicPlugin. For details on marklogicPlugin, see Registering a Native Plugin at Runtime.
Calling Registry::registerAggregate gives MarkLogic Server a pointer to a function it can use to create an object of your UDF class. MarkLogic Server calls this function whenever an application invokes your aggregate UDF. For details, see Aggregate UDF Memory Management.
Call the template version of marklogic::Registry::registerAggregate to have MarkLogic Server use the default allocator and constructor. Call the virtual version to use your own object factory. The following code snippet shows the two registration interfaces:
// From MarkLogic.h namespace marklogic { typedef AggregateUDF* (*AggregateFunction)(); class Registry { public: // Calls new T() to allocate an object of your UDF class template<class T> void registerAggregate(const char* name); // Calls your factory func to allocate an object of your UDF class virtual void registerAggregate(const char* name, AggregateFunction); ... }; }
The string passed to Registry::registerAggregate is the name applications use to invoke your plugin. For example, as the second parameter to cts:aggregate in XQuery:
cts:aggregate("pluginPath", "ex1", ...)
Or, as the value of the aggregate parameter to /values/{name} using the REST Client API:
GET /v1/values/theLexicon?aggregate=ex1&aggregatePath=pluginPath
The following example illustrates using the template function to register MyFirstAggregate with the name ex1 and the virtual member function to register a second aggregate that uses an object factory, under the name ex2.
#include "MarkLogic.h" using namespace marklogic; ... AggregateUDF* mySecondAggregateFactory() {...} extern "C" void marklogicPlugin(Registry& r) { r.version(); r.registerAggregate<MyFirstAggregate>("ex1"); r.registerAggregate("ex2", &mySecondAggregateFactory); }
Aggregate UDF Memory Management
This section gives an overview of how MarkLogic Server creates and destroys objects of your aggregate UDF class.
Aggregate UDF Object Lifetime
Objects of your aggregate UDF class are created in two ways:
- When you register your plugin, the registration function calls
marklogic::Registry::registerAggregate, giving MarkLogic Server a pointer to function that creates objects of yourAggregateUDFsubclass. This function is called when an application invokes one of your aggregate UDFs, prior to callingAggregateUDF::start. - MarkLogic Server calls
AggregateUDF::cloneto create additional objects, as needed to execute map and reduce tasks.
MarkLogic Server uses AggregateUDF::clone to create the transient objects that execute your algorithm in map and reduce tasks when your UDF is invoked. MarkLogic Server creates at least one clone per forest when evaluating your aggregate function.
When a clone is no longer needed, such as at the end of a task or job, MarkLogic Server releases it by calling AggregateUDF::close.
The clone and close methods of your aggregate UDF may be called many times per job.
Using a Custom Allocator With Aggregate UDFs
If you want to use a custom allocator and manage your own objects, implement an object factory function and supply it to marklogic::Registry::registerAggregate, as described in Registering an Aggregate UDF.
The factory function is called whenever an application invokes your plugin. That is, once per call to cts:aggregate (or the equivalent). Additional objects needed to execute map and reduce tasks are created using AggregateUDF::clone.
The factory function must conform to the marklogic::AggregateFunction interface, shown below:
// From MarkLogic.h namespace marklogic { typedef AggregateUDF* (*AggregateFunction)(); }
The following example demonstrates passing an object factory function to Registry::registerAggregate:
#include "MarkLogic.h" using namespace marklogic; ... AggregateUDF* myAggregateFactory() { ... } extern "C" void marklogicPlugin(Registry& r) { r.version(); r.registerAggregate("ex2", &myAggregateFactory); }
The object created by your factory function and AggregateUDF::clone must persist until MarkLogic Server calls your AggregateUDF::close method.
Use the following entry points to control the allocation and deallocation of your your aggregate UDF objects:
Implementing AggregateUDF::encode and AggregateUDF::decode
MarkLogic Server uses Aggregate::encode and Aggregate::decode to serialize and deserialize your aggregate objects when distributing aggregate analysis across a cluster. These methods have the following signatures:
class AggregateUDF { public: ... virtual void encode(Encoder&, Reporter&) = 0; virtual void decode(Decoder&, Reporter&) = 0; ... };
You must provide implementations of encode and decode that adhere to the following guidelines:
- Encode/decode the implementation-specific state on your objects.
- You can encode data members in any order, but you must be consistent between encode and decode. That is, you must decode members in the same order in which you encode them.
Encode/decode your data members using marklogic::Encoder and marklogic::Decoder. These classes provide helper methods for encoding and decoding the basic item types and an arbitrary sequence of bytes. For details, see marklogic_dir/include/MarkLogic.h.
The following example demonstrates how to encode/decode an aggregate UDF with 2 data members, sum and count. Notice that the data members are encoded and decoded in the same order.
#include "MarkLogic.h" using namespace marklogic; class Mean : public AggregateUDF { public: ... void encode(Encoder& e, Reporter& r) { e.encode(this->sum); e.encode(this->count); } void decode(Decoder& d, Reporter& r) { d.decode(this->sum); d.decode(this->count); } ... protected: double sum; double count; };
Aggregate UDF Error Handling and Logging
Use marklogic::Reporter to log messages and notify MarkLogic Server of fatal errors. Your code should not report errors to MarkLogic Server by throwing exceptions.
Report fatal errors using marklogic::Reporter::error. When you call Reporter::error, control does not return to your code. The reporting task stops immediately, no additional related tasks are created on that host, and the job stops prematurely. MarkLogic Server returns XDMP-UDFERR to the application. Your error message is included in the XDMP-UDFERR error.
The job does not halt immediately. The task that reports the error stops, but other in-progress map and reduce tasks may still run to completion.
Report non-fatal errors and other messages using marklogic::Reporter::log. This method logs a message to the MarkLogic Server error log, ErrorLog.txt, and returns control to your code. Most methods of AggregateUDF have marklogic::Reporter input parameter.
The following example aborts the analysis if the caller does not supply a required parameter and logs a warning if the caller supplies extra parameters:
#include "MarkLogic.h" using namespace marklogic; ... void ExampleUDF::start(Sequence& arg, Reporter& r) { if (arg.done()) { r.error("Required parameter not found."); } arg.value(target_); arg.next(); if (!arg.done()) { r.log(Reporter::Warning, "Ignoring extra parameters."); } }
Aggregate UDF Argument Handling
This section covers the following topics:
- Passing Arguments to an Aggregate UDF
- Processing Arguments in AggregateUDF::start
- Example: Passing Arguments to an Aggregate UDF
Passing Arguments to an Aggregate UDF
Arguments can only be passed to aggregate UDFs from XQuery. The Java and REST client APIs do not support argument passing.
From XQuery, pass an argument sequence in the 4th parameter of cts:aggregate. The following example passes two arguments to the count aggregate UDF:
cts:aggregate( "native/samplePlugin", "count", cts:element-reference(xs:QName("name"), (arg1,arg2))
The arguments reach your plugin as a marklogic::Sequence passed to AggregateUDF::start. For details, see Processing Arguments in AggregateUDF::start.
For a more complete example, see Example: Passing Arguments to an Aggregate UDF.
Processing Arguments in AggregateUDF::start
MarkLogic Server makes your aggregate-specific arguments available through a marklogic::Sequence passed to AggregateUDF::start.
class AggregateUDF { public: ... virtual void start(Sequence& arg, Reporter&) = 0; ... };
The Sequence class has methods for iterating over the argument values (next and done), checking the type of the current argument (type), and extracting the current argument value as one of several native types (value).
Type conversions are applied during value extraction. For details, see Type Conversions in Aggregate UDFs.
If you need to propagate argument data to your map and reduce methods, copy the data to a data member of the object on which start is invoked. Include the data member in your encode and decode methods to ensure the data is available to remote map and reduce tasks.
Example: Passing Arguments to an Aggregate UDF
Consider an aggregate UDF that counts the number of 2-way co-occurrences where one of the index values matches a caller-supplied value. In the following example, the caller passes in the value 95008 to cts:aggregate:
xquery version "1.0-ml"; cts:aggregate("native/sampleplugin", "count", (cts:element-reference(xs:QName("zipcode")) ,cts:element-reference(xs:QName("name")) ), 95008 )
The start method shown below extracts the argument value from the input Sequence and stores it in the data member ExampleUDF::target: The value is automatically propagated to all tasks in the job when MarkLogic Server clones the object on which it invokes start.
using namespace marklogic; ... void ExampleUDF:: start(Sequence& arg, Reporter& r) { if (arg.done()) { r.error("Required argument not found."); } else { arg.value(this->target); arg.next(); if (!arg.done()) { r.log(Reporter::Warning, "Ignoring extra arguments."); } } }
Type Conversions in Aggregate UDFs
The MarkLogic native plugin API models XQuery values as equivalent C++ types, using either primitive types or wrapper classes. You should understand these type equivalences and the type conversions supported between them because values passed between your aggregate UDF and a calling application pass through the MarkLogic Server XQuery evaluator core even if the application is not implemented in XQuery.
Where Type Conversions Apply
Your plugin interacts with native XQuery values in the following places:
- Arguments passed to your plugin from the calling application through
marklogic::Sequence. - Range index values passed to
AggregateUDF::mapthroughmarklogic::TupleIterator. - Results returned to the application by
AggregateUDF::finishthroughmarklogic::OutputSequence.
All these interfaces (Sequence, TupleIterator, OutputSequence) provide methods for either inserting or extracting values as C++ types. For details, see marklogic_dir/include/Marklogic.h.
Where the C++ and XQuery types do not match exactly during value extraction, XQuery type casting rules apply. If no conversion is available between two types, MarkLogic Server reports an error such as XDMP-UDFBADCAST and aborts the job. For details on XQuery type casting, see:
http://www.w3.org/TR/xpath-functions/#Casting
Type Conversion Example
In this example, the aggregate UDF expects an integer value and the application passes in a string that can be converted to a numeric value using XQuery rules. You can extract the value directly as an integer. If the calling application passes in "12345":
(: The application passes in the arg "12345" :) cts:aggregate("native/samplePlugin", "count", "12345")
Then your C++ code can safely extract the arg directly as an integral value:
// Your plugin can safely extract the arg as int void YourAggregateUDF::start(Sequence& arg, Reporter& r) { int theNumber = 0; arg.value(theNumber); }
If the application instead passes a non-numeric string such "dog", the call to Sequence::value raises an exception and stops the job.
C++ and XQuery Type Equivalences
The table below summarizes the type equivalences between the C++ and XQuery types supported by the native plugin API. All C++ class types below are declared in marklogic_dir/include/MarkLogic.h.