
MarkLogic Server 11.0 Product DocumentationSemantic Graph Developer's Guide — Chapter 1
Introduction to Semantic Graphs in MarkLogic
The power of a knowledge graph is the ability to define the relationships between disparate facts and provides context for those facts. Graphs are semantic if the meaning of the relationships is embedded in the graph itself and exposed in a standard format. Semantic Graph technology, referred to in this documentation as semantics, describes a family of specific W3C standards to allow the exchange of information about relationships in data in machine-readable form, whether it resides on the Web or within organizations. MarkLogic Semantics, using RDF (Resource Description Framework), allows you to natively store, search, and manage RDF triples using SPARQL query, SPARQL Update, and JavaScript, XQuery, or REST.
Semantics requires a flexible data model (RDF), query tool (SPARQL), a graph and triple data management tool (SPARQL Update), and a common markup language (for example RDFa, Turtle, N-Triples). MarkLogic lets you natively store, manage, and search triples using SPARQL and SPARQL Update.
RDF is one of the core technologies of linked open data. The framework provides standards for disambiguating data, integrating, and interacting with data that may come from disparate sources, both machine-readable and human-readable. It makes use of W3C recommendations and formal, defined vocabularies for data to be published and shared across the Semantic Web.
SPARQL (SPARQL Protocol and RDF Query Language) is used to query data in RDF serialization. SPARQL Update is used to create, delete, and update (delete/insert) triple data and graphs.
You can derive additional semantic information from your data using inference. You can also enrich your data using Linked Open Data (LOD), an extension of the World Wide Web created from the additional semantic metadata embedded in data.
Semantics is a separately licensed product. To use SPARQL features, a license that includes the Semantics Option is required. Use of APIs leveraging Semantics without using SPARQL, such as the Optic API or SQL API, does not require a Semantics Option license.
For more information, see the following resources:
- http://www.w3.org/standards/semanticweb
- http://www.w3.org/RDF
- http://www.w3.org/TR/rdf-sparql-query
- http://www.w3.org/TR/sparql11-update
This document describes how to load, query, and work with semantic graph data in MarkLogic Server. This chapter provides an overview of Semantics in MarkLogic Server. This chapter includes the following sections:
Terminology
| Term | Definition |
|---|---|
| RDF | RDF (Resource Description Framework) is a data model used to represent facts as a triple made up of a subject, predicate, and an object. The framework is W3C specification with a defined vocabulary. |
| RDF Triple | An RDF statement containing atomic values representing a subject, predicate, object, and optionally a graph. Each triple represents a single fact. |
| Subject | A representation of a resource such as a person or an entity. A node in an graph or triple. |
| Predicate | A representation of a property or characteristics of the subject or of the relationship between the subject and the object. The predicate is also known as an arc or edge. |
| Object | A node representing a property value, which in turn may be the subject in a triple or graph. An object may be a typed literal. See RDF Datatypes. |
| Graph | A set of RDF triple statements or patterns. In a graph-based RDF model, nodes represent subject or object resources, with the predicate providing the connection between those nodes. Graphs that are assigned a name are referred to as Named Graphs. |
| Quad | A representation of a subject, predicate, object, and an additional resource node for the context of the triple. |
| Vocabularies | A standard format for classifying terms. Vocabularies such as FOAF (Friend of a Friend) and Dublin Core (DC) define the concepts and relationships used to describe and represent facts. For example, OWL is a Web Ontology Language for publishing and sharing ontologies across the World Wide Web. |
| Triple Index | An index that indexes triples ingested into MarkLogic to facilitate the execution of SPARQL queries. |
| RDF Triple Store | A storage tool for the persistent storage, indexing, and query access to RDF graphs. |
| IRI | An IRI (Internationalized Resource Identifier) is a compact string that is used for uniquely identifying resources in an RDF triple. IRIs may contain characters from the Universal Character Set (Unicode/ISO 10646), including Chinese or Japanese Kanji, Korean, Cyrillic characters, and so on. |
| CURIE | Compact URI Expression. |
| SPARQL | A recursive acronym for SPARQL Protocol and RDF Query Language (SPARQL), a query language designed for querying data in RDF serialization. SPARQL 1.1 syntax and functions are available in MarkLogic. |
| SPARQL Protocol | A means of conveying SPARQL queries from query clients to query processors, consisting of an abstract interface with bindings to HTTP (Hypertext Transfer Protocol) and SOAP (Simple Object Access Protocol). |
| SPARQL Update | An update language for RDF graphs that uses a syntax derived from the SPARQL Query language. |
| RDFa | Resource Description Framework in Attributes (RDFa) is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML, and various XML-based document types for embedding rich metadata within Web documents. |
| Blank node | A node in an RDF graph representing a resource for which a IRI or literal is not provided. The term bnode is used interchangeably with blank node. |
Linked Open Data
Linked Open Data enables sharing of metadata and data across the Web. The World Wide Web provides access to resources of structured and unstructured data as human-readable web pages and hyperlinks. Linked Open Data extends this by inserting machine-readable metadata about pages and how they are related to each other to present semantically structured knowledge. The Linked Open Data Cloud gives some sense of the variety of open data sets available on the Web.
For more about Linked Open Data, see http://linkeddata.org/
RDF Implementation in MarkLogic
This section describes the semantic technologies using RDF that are implemented in MarkLogic Server and includes the following concepts:
Using RDF in MarkLogic
RDF is implemented in MarkLogic to store and search RDF triples. Specifically, each triple is an RDF triple statement containing a subject, predicate, object, and optionally a graph.

The subject node is a resource named John Smith, the object node is London, and the predicate, shown as an edge linking the two nodes, describes the relationship. From the example, the statement John Smith lives in London can be derived.
This triple looks like this in XML (with a second triple added):
<sem:triples xmlns:sem="http://marklogic.com/semantics"> <sem:triple> <sem:subject> http://xmlns.com/foaf/0.1/name/"John Smith"</sem:subject> <sem:predicate> http://example.org/livesIn</sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string">"London"</sem:object> </sem:triple> </sem:triples>
In JSON this same triple would look like:
{ "my" : "data", "triple" : { "subject": "http://xmlns.com/foaf/0.1/name/John Smith", "predicate": "http://example.org/livesIn", "object": { "value": "London", "datatype": "xs:string" } } }
Sets of triples are stored as RDF graphs. In MarkLogic, the graphs are stored as collections. The following image is an example of a simple RDF graph model that contains three triples. For more information about graphs, see RDF Data Model.
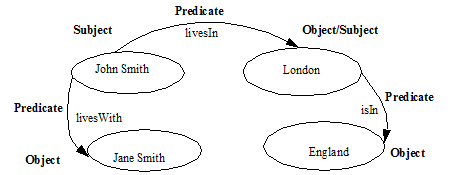
The object node of a triple can in turn be a subject node of another triple. In the example, the following facts are represented John Smith lives with Jane Smith, John Smith lives in London and London is in England.
The graph can be represented in tabular format:
| Subject | Predicate | Object |
|---|---|---|
| John Smith | livesIn | London |
| London | isIn | England |
| John Smith | livesWith | Jane Smith |
In JSON, these triples would look like this:
{ "my" : "data", "triple" : [{ "subject": "http://xmlns.com/foaf/0.1/name/John Smith", "predicate": "http://example.org/livesIn", "object": { "value": "London", "datatype": "xs:string" } },{ "subject": "http://xmlns.com/foaf/0.1/name/London", "predicate": "http://example.org/isIn", "object": { "value": "England", "datatype": "xs:string" } },{ "subject": "http://xmlns.com/foaf/0.1/name/John Smith", "predicate": "http://example.org/livesWith", "object": { "value": "Jane Smith", "datatype": "xs:string" } } ]}
Storing RDF Triples in MarkLogic
When you load RDF triples into MarkLogic, the triples are stored in MarkLogic-managed XML documents. You can load triples from a document using an RDF serialization, such as Turtle or N-Triple. For example:
<http://example.org/dir/js> <http://xmlns.com/foaf/0.1/firstname> "John" . <http://example.org/dir/js> <http://xmlns.com/foaf/0.1/lastname> "Smith" . <http://example.org/dir/js> <http://xmlns.com/foaf/0.1/knows> "Jane Smith" .
For more examples of RDF formats, see Example RDF Formats.
The triples in this example are stored in MarkLogic as XML documents, with sem:triples as the document root. These are managed triples because they have a document root element of sem:triples.
<?xml version="1.0" encoding="UTF-8"?> <sem:triples xmlns:sem="http://marklogic.com/semantics"> <sem:triple> <sem:subject>http://example.org/dir/js</sem:subject> <sem:predicate>http://xmlns.com/foaf/0.1/firstname</sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string">John </sem:object> </sem:triple> <sem:triple> <sem:subject>http://example.org/dir/js</sem:subject> <sem:predicate>http://xmlns.com/foaf/0.1/lastname</sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string"> Smith</sem:object> </sem:triple> <sem:triple> <sem:subject>http://example.org/dir/js</sem:subject> <sem:predicate>http://xmlns.com/foaf/0.1/knows</sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string"> Jane Smith</sem:object> </sem:triple> </sem:triples>
You can also embed triples within XML documents and load them into MarkLogic as-is. These are unmanaged triples, with a element node of sem:triple. You do not need the outer sem:triples element for unmanaged triples, but you do need the subject, predicate, and object elements within the sem:triple element.
Here is an embedded triple, contained in an XML document:
<?xml version="1.0" encoding="UTF-8"?> <article> <info> <title>News for April 9, 2013</title> <sem:triples xmlns:sem="http://marklogic.com/semantics"> <sem:triple> <sem:subject>http://example.org/article</sem:subject> <sem:predicate>http://example.org/mentions</sem:predicate> <sem:object>http://example.org/London</sem:object> <sem:triple> </sem:triples> ... </info> </article>
The loaded triples are automatically indexed with a special-purpose index called a triple index. The triple index allows you to immediately search the RDF data for which you have the required privileges.
Querying Triples
You can write native SPARQL queries in Query Console to retrieve information from RDF triples stored in MarkLogic or in memory. When queried with SPARQL, the question of who lives in England? is answered with John and Jane Smith. This is based on the assertion of facts from the above graph model. This is an example of a simple SPARQL SELECT query:
SELECT ?person ?place WHERE { ?person <http://example.org/livesIn> ?place . ?place <http://example.org/isIn> http://xmlns.com/foaf/0.1/name/London. }
You can also use XQuery to execute SPARQL queries with sem:sparql. For example:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql(" PREFIX kennedy:<http://example.org/kennedy> SELECT * WHERE { ?s ?p ?o . FILTER (regex(?o, 'Joseph', 'i')) } ")
For more information about using SPARQL and sem:sparql to query triples, see Semantic Queries.
Using XQuery, you can query across triples, documents, and values with cts:triples or cts:triple-range-query.
Here is an example using a cts:triples query:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $r := cts:triples(sem:iri("http://example.org/people/dir"), sem:iri("http://xmlns.com/foaf/0.1/knows"), sem:iri("person1")) return <result>{$r}</result>
The following is an example of a query that uses cts:triple-range-query:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" "at /MarkLogic/semantics.xqy"; let $query := cts:triple-range-query( sem:iri("http://example.org/people/dir"), sem:iri("http://xmlns.com/foaf/0.1/knows"), ("person2"), "sameTerm") return cts:search(fn:collection()//sem:triple, $query)
You can create combination queries with cts:query functions such as cts:or-query or cts:and-query.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "MarkLogic/semantics.xqy"; declare namespace dc = "http://purl.org/dc/elements/1.1/"; cts:search(collection()//sem:triple, cts:or-query(( cts:triple-range-query((), sem:curie-expand("foaf:name"), "Lamar Alexander", "="), cts:triple-range-query(sem:iri("http://www.rdfabout.com/rdf/usgov /congress/people/A000360"), sem:curie-expand("foaf:img"), (), "="))))
For more information about cts:triples and the cts:triple-range-query queries, see Semantic Queries.
You can also use the results of a SPARQL query with an XQuery search to create combination queries.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; import module namespace semi = "http://marklogic.com/semantics/impl" at "/MarkLogic/semantics/sem-impl.xqy"; declare namespace sr = "http://www.w3.org/2005/sparql-results"; let $results := sem:sparql( "prefix k: <http://example.org/kennedy> select * { ?s k:latitude ?lat . ?s k:longitude ?lon }" ) let $xml := sem:sparql($results) return for $sol in $xml/sr:results/sr:result let $point := cts:point(xs:float($sol/sr:binding[@name eq 'lat']/sr:literal), xs:float($sol/sr:binding[@name eq 'lon']/sr:literal)) return <place name="{$sol/sr:binding[@name eq 's']/*}" point="{$point}"/>
For more information about combination queries, see Querying Triples with XQuery or JavaScript.
RDF Data Model
RDF triples are a convenient way to represent facts: facts about the world, facts about a domain, facts about a document. Each RDF triple is a fact (or assertion) represented by a subject, predicate, and object, such as John livesIn London. The subject and predicate of a triple must be an IRI (Internationalized Resource Identifier), which is a compact string used to uniquely identify resources. The object may be either an IRI or a literal, such as a number or string.
- Subjects and predicates are IRI references with an optional fragment identifier. For example:
<http://xmlns.com/foaf/0.1/Person> foaf:person
- Literals are strings with an optional language tag or a number. These are used as objects in RDF triples. For example:
"Bob" "chat" @fr
- Typed literals may be strings, integers, dates and so on, that are assigned to a datatype. These literals are typed with a ^^ operator . For example:
"Bob"^^xs:string "3"^^xs:integer "26.2"^^xs:decimal
In addition, a subject or object may be a blank node (bnode or anonymous node), which is a node in a graph without a name. Blank nodes are represented with an underscore, followed by a colon (:) and then an identifier. For example:
_:a _:jane
For more information about IRIs, see IRIs and Prefixes.
Often the object of one triple is the subject of another, so a collection of triples forms a graph. In this document we represent graphs using these conventions:
Blank Node Identifiers
In MarkLogic, a blank node is assigned a blank node identifier. This internal identifier is maintained across multiple invocations. In a triple, a blank node can be used for the subject or object and is specified by an underscore (_). For example:
_:jane <http://xmlns.com/foaf/0.1/name> "Jane Doe". <http://example.org/people/about> <http://xmlns.com/foaf/0.1/knows> _:jane
Given two blank nodes, you can determine whether or not they are the same. The first node "_:jane" will refer to the same node as the second invocation that also mentions "_:jane". Blank nodes are represented as skolemized IRIs: blank nodes where existential variables are replaced with unique constants. Each blank node has a prefix of "http://marklogic.com/semantics/blank".
RDF Datatypes
RDF uses the XML schema datatypes. These include xs:string, xs:float, xs:double, xs:integer, and xs:date and so on, as described in the specification, XML Schema Part 2: Datatypes Second Edition:
http://www.w3.org/TR/xmlschema-2
All XML schema simple types are supported, along with all types derived from them, except for xs:QName and xs:NOTATION.
RDF can also contain custom datatypes that are named with a IRI. For example, a supported MarkLogic-specific datatype is cts:point.
Use of an unsupported datatype such as xs:QName, xs:NOTATION, or types derived from these will generate an XDMP-BADRDFVAL exception.
If you omit a datatype declaration, it is considered to be of type xs:string. A typed literal is denoted by the presence of the datatype attribute, or by an xml:lang attribute to give the language encoding of the literal, for example, en for English.
Datatypes in the MarkLogic Semantics data model allow for values with a datatype that has no schema. These are identified as xs:untypedAtomic.
IRIs and Prefixes
This section describes meaning and role of IRIs and prefixes, and includes the following concepts:
IRIs
IRIs (Internationalized Resource Identifiers) are internationalized versions of URIs (Uniform Resource Identifiers). URIs use a subset of ASCII characters and are limited to this set. IRIs use characters beyond ASCII, making them more useful in an international context. IRIs (and URIs) are unique resource identifiers that enable you to fetch a resource. A URN (Uniform Resource Name) can also be used to uniquely identify a resource.
An IRI may appear similar a URL and may or may not be an actual website. For example:
<http://example.org/addressbook/d> IRIs need to be heirarchical, or they cannot be resolved against the base URIs. Here is the start of a heirarchical URI:
some_scheme://
And here is the start of a non-heirarchical URI:
some_scheme:/
To use a non-hierarchical IRI, use the repair option to turn off hierarchical IRI parsing while loading.
IRIs are used instead of URIs, where appropriate, to identify resources. Since SPARQL specifically refers to IRIs, later chapters in this guide reference IRIs and not URIs.
IRIs are required to eliminate ambiguity in facts, particularly if data is received from different data sources. For example, if you are receiving information about books from different sources, one publisher may refer to the name of the book as title, another source may refer to the position of the author as title. Similarly, one domain may refer to the writer of the book as the author and another as creator.
Presenting the information with IRIs (and URNs ), we see a clearer presentation of what the facts mean. The following examples are three sets of N-Triples:
<http://example.org/people/title/sh1999> <http://www.w3.org/1999/02/22-rdf-syntax-ns#label> "Lucasian Professor of Mathematics" <urn:isbn:9780553380163> <http://purl.org/dc/elements/1.1/title> "A Brief History of Time" <urn:isbn:9780553380163> <http://purl.org/dc/elements/1.1/creator> "Stephen Hawking"
Note: Line breaks have been inserted for the purposes of formatting, which make this RDF N-Triple syntax invalid. Each triple would normally be on one line. (Turtle syntax allows for single triples to wrap across multiple lines.)
The IRI is a key component of RDF, however IRIs are usually long and are difficult to maintain. Compact URI Expressions (CURIEs) are supported as a mechanism for abbreviating IRIs. These are specified in the CURIE Syntax Definition:
Prefixes
Prefixes are identified by IRIs and often begin with the name of an organization or company. For example:
PREFIX js: <http://example.org/people/about/js/>
A prefix is a shorthand string used to identify a name. The designated prefix binds a prefix IRI to the specified string. The prefix can then be used instead of writing the full IRI each time it is referenced. When you use prefixes to write RDF, the prefix is followed by a colon. You can choose any prefix for resources that you define. For example, here is a SPARQL declaration:
PREFIX dir: <http://example.org/people/about/>
You can also use standard and agreed upon prefixes that are a part of a specification. This is a SPARQL declaration for rdf:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns/>
The prefix depends on the serialization that you use. The Turtle prefix declaration would be:
@prefix dir: <http://example.org/people/about/> .
All PREFIX declarations must end with a forward slash (/) or a hashtag (#). These separate the prefix from the final part of the IRI.
RDF Vocabulary
RDF vocabularies are defined using RDF Schema (RDFS) or Web Ontology Language (OWL) to provide a standard serialization for classifying terms. The vocabulary is essentially the set of IRIs for the arcs that form RDF graphs. For example, the FOAF vocabulary describes people and relationships.
The existence of a shared standard vocabulary is helpful, but not essential since it is possible to combine vocabularies or create a new one. Use the following prefix lookup to help decide which vocabulary to use:
There is an increasingly large number of vocabularies. Common RDF prefixes that are widely used and agreed upon include the following:
| Prefix | Prefix IRI | |
|---|---|---|
| cc | http://web.resource.org/cc#ns | Creative Commons |
| dc | http://purl.org/dc/elements/1.1/ | Dublin Core vocabulary |
| dcterms | http://purl.org/dc/terms | Dublin Core terms |
| rdfs | http://www.w3.org/2000/01/rdf-schema# | RDF schema |
| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# | RDF vocabulary |
| owl | http://www.w3.org/2002/07/owl# | Web Ontology Language |
| foaf | http://xmlns.com/foaf/0.1/ | FOAF (Friend of a Friend) |
| skos | http://www.w3.org/2004/02/skos/core | SKOS (Simple Knowledge Organization System) |
| vcard | http://www.w3.org/2001/vcard-rdf/3.0 | VCard vocabulary |
| void | http://rdfs.org/ns/void | Vocabulary of Interlinked Datasets |
| xml | http://www.w3.org/XML/1998/namespace | XML namespace |
| xhtml | http://www.w3.org/1999/xhtml | XHTML namespace |
| xs | http://www.w3.org/2001/XMLSchema# | XML Schema |
| fn | http://www.w3.org/2005/xpath-functions | XQuery function and operators |
Example Datasets
There is a growing body of data from domains such as Government and governing agencies, Healthcare, Finance, Social Media and so on, available as triples, often accessible via SPARQL for the purpose of:
There are a large number of datasets available for public consumption.
- FOAF: http://www.foaf-project.org- a project that provides a standard RDF vocabulary for describing people, what they do, and relationships to other people or entities.
- DBPedia: http://wiki.dbpedia.org/develop/datasets/ - data derived from Wikipedia with many external links to RDF datasets.
- Semantic Web: http://data.semanticweb.org - a database of thousands of unique triples about conference data.