
MarkLogic 10 Product DocumentationContent Processing Framework Guide — Chapter 9
The Default Conversion Option
This chapter describes the Default Conversion Option, which is designed to convert Microsoft Office, Adobe PDF, and HTML files to XHTML and DocBook. It includes the following sections:
- Installing the Conversion Pipelines and Framework
- Simple Drag-and-Drop Conversion
- What the Conversion Pipeline Generates
- Understanding and Using the Default Conversion Option
- Modifying the Default Conversion Option
Installing the Conversion Pipelines and Framework
The Default Conversion Option installation installs the Content Processing Framework for your database, sets up the domain for the pipeline, loads the needed triggers into the triggers database, and performs other pipeline initialization tasks. You need to install the Default Conversion Option for each database in which you plan on using conversion.
Complete the following steps to install the Default Conversion Option into a database.
- If it is not already installed, install MarkLogic Server.
- If you are installing MarkLogic 9.0-4 or later, you will have to install MarkLogic Converters package separately. For more details, see MarkLogic Converters Installation Changes Starting at Release 9.0-4 in the Installation Guide.
- Open the Admin Interface to the database page for the database in which you want to install the Default Conversion Option. For example, if you want to install the pipeline into the Documents database, open the database page for the Documents database.
MarkLogic recommends creating a new database to use when testing the Default Conversion Option.
- On the database configuration page, select a
triggers databaseto use with your database (for example, Triggers). You can use any database for the triggers database. It can be the same database as the one you are configuring (for example, you can set the Documents database as the triggers database for the Documents database) or it can be a different database (for example, the Triggers database created as part of the installation process). - Click OK to apply the changes to the database configuration.
- In the left tree menu, click the Content Processing link under the database to which you want to install the Default Conversion Option. The Content Processing Summary page appears.
- On the Content Processing Summary page, click the Install tab. The Content Processing Installation page appears.
- On the Content Processing Installation page, select
truefor theenable conversionoption and click Install. Make sureenable conversionis set totrue. If this is set tofalse, then you will only install the Content Processing Framework, not the Default Conversion Option. - Click OK to confirm the installation of content processing in your database.
- When the installation is complete, the Content Processing Summary page appears. It displays content processing installed in your database.
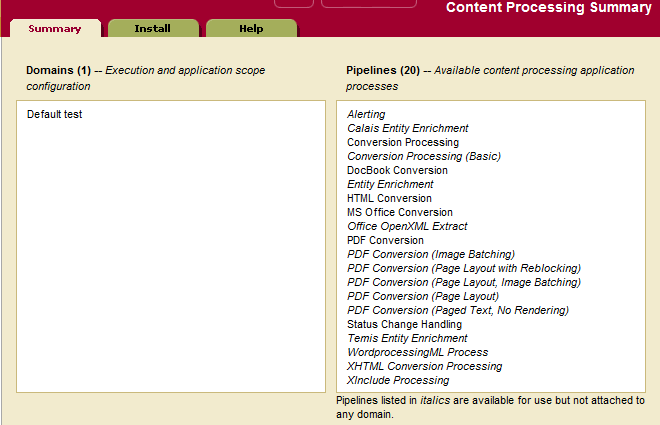
The Default Conversion Option is now installed for the database. The default domain determines which documents are processed, and by default it has a document scope that applies to any document in the database with a URI starting with a slash ( / ).You can modify the domain settings if you want the Default Conversion Option to apply to a different set of documents. To modify the domain settings, click the default domain for your database (for example, Default Documents if you chose the Documents database) on the Content Processing Summary pages and make the needed modifications. For details on domains, see Understanding and Using Domains.
Simple Drag-and-Drop Conversion
To try out the pipeline, you need to load some Adobe PDF, Microsoft Office, and/or HTML files into the database. You can load the documents using any method you like. This section describes an easy way to load documents using a WebDAV server and client. You can then use this configuration to test document conversion with the Default Conversion Option. For more information on WebDAV servers, see WebDAV Servers in the Administrator's Guide.
Complete the following steps to load and process documents in a database.
- Create a WebDAV server with root
/that accesses the database in which you installed the Content Processing Pipeline.- In the Admin Interface, go to the Groups > Default > AppServers page.
- Click the Create WebDAV tab.
- Enter a server name (for example,
CPF). - Enter
/for the root. - Enter a port number (for example,
9999). - Select the database in which you installed the content processing pipeline (for example,
Documents). - Click OK.
- If you will not be logging into the WebDAV client as a privileged user, set up the needed security requirements for your WebDAV root directory and your WebDAV user. For a sample of how to set this up, see Set the Needed Permissions on the Root Directory.
- Create a WebDAV client that accesses the WebDAV server you just created. For example, the following procedure applies to Windows XP; other versions of Windows or other WebDAV clients have slightly different procedures:
- Double-click My Network Places from your desktop.
- Double-click Add Network Place.
- For the location of the network place, enter the address with the hostname and port number of the WebDAV server you created. For example, if your server is on port 9999 of the local machine, enter the following:
http://localhost:9999
- Click the Next button.
- If prompted, enter a username and password for your WebDAV server.
- Enter a name for your WebDAV folder (for example,
conversion). - Click Finish.
- If prompted, enter the username and password for your WebDAV server.
- Drag-and-drop Microsoft Word, Excel, Powerpoint, and/or Adobe PDF files into the WebDAV folder. This loads the documents in the database.
- After some time has passed, refresh the WebDAV folder (for example, View > Refresh). The amount of time it takes to convert depends on the number, size, and the complexity of the documents being converted. For simple and small documents, it will take just a few seconds. For larger documents, it might take significantly longer.
The converted documents, as well as the original documents and any parts generated as part of the conversion, will appear in the WebDAV folder. If you have large documents or if you load many documents into the database, the processing might continue for several minutes or longer.
What the Conversion Pipeline Generates
After the conversion process is finished, for each HTML, Word, Excel, Powerpoint, and PDF document you loaded, the Default Conversion Option produces the following:
- The original document
- An XHTML document (
*.xhtml) - A simplified DocBook XML document (*
.xml) - A directory (
*_parts) containing various parts generated as part of the conversion process. The parts are typically any images that were in the original document, a cascading style sheet document (conv.css), and a document containing an analysis of the stylesheet (css.xml). PDF documents also include toc.xml, which is an analysis of the table of contents structure.
The generated XHTML and XML documents have a URI that includes the suffix of the original document. For example, a document called word.doc produces word_doc.xml and word_doc.xhtml.
Understanding and Using the Default Conversion Option
The Default Conversion Option uses the components of Content Processing Framework, as well as converters to create XML documents from Microsoft Office and Adobe PDF files, to create a unified conversion process which converts Microsoft Office, Adobe PDF, and HTML files to well-structured XHTML and simplified DocBook format XML documents. This section provides some background on how the default conversion process works, and includes the following sections:
- Components of the Default Conversion Option
- Steps in the Conversion Process
- Default Conversion Option States
- Errors, Troubleshooting, Debugging, and Recovery
The Default Conversion Option does not support documents written in Microsoft 2007 or later format (Office Open XML). To convert these files, follow the steps in Microsoft Office 2007 and Later Documents.
The MarkLogic Converters package may generate temporary files. These temporary files are not supported by encryption at rest.
Components of the Default Conversion Option
The Default Conversion Option includes the following components:
- Status Change Handling Pipeline
- Microsoft Office Pipeline
- PDF Pipelines
- HTML Pipeline
- Supporting XQuery modules
- Microsoft Office XML converter
- Adobe PDF XML converter
- The xdmp:tidy function built into MarkLogic Server
There are also supporting XQuery modules for the Default Conversion Option for the following:
- Generic Conversion
- PDF Conversion
- DocBook Conversion
- CSS Conversion
- XHTML Conversion
- Microsoft Office Conversion
These XQuery modules include the XQuery source code, so you can analyze them and use their functions in your own applications. The XQuery modules are installed into the following directory:
<install_dir>/Modules/MarkLogic/conversion
For details on these functions, see the MarkLogic XQuery and XSLT Function Reference.
Steps in the Conversion Process
The steps in the conversion process differ for the different document formats (Microsoft Office, Adobe PDF, and HTML). The steps are defined in the following pipelines:
Generally, the conversion process perform the following tasks:
- Check to see what kind of document it is.
- Convert the document to XHTML based on its type.
- Cleans up the converted XHTML.
- Extract the style information into a CSS document.
- Transform the XHTML to infer the table of contents structure for the document.
- Transform the XHTML to create a simplified DocBook structured format for the document.
Default Conversion Option States
The conversion states are defined in the pipelines and are stored in the properties document for each document. The conversion process includes the following states:
- http://marklogic.com/states/initial
- http://marklogic.com/states/updated
- http://marklogic.com/states/xhtml
- http://marklogic.com/states/cleaned-xhtml
- http://marklogic.com/states/structured-xhtml
- http://marklogic.com/states/enhanced-xhtml
- http://marklogic.com/states/pdf-xhtml
- http://marklogic.com/states/analyzed-styles
- http://marklogic.com/states/final
Errors, Troubleshooting, Debugging, and Recovery
This section describes the following error and troubleshooting situations you might encounter with the Default Conversion Option:
- Microsoft Word 95 and Other Microsoft Office Errors
- Set the Needed Permissions on the Root Directory
- Default or Inherited Collections and Permissions
- Enable Debugging Capabilities
- Create Your Own Error Handling Pipeline
Microsoft Word 95 and Other Microsoft Office Errors
The Default Conversion Option only converts documents written in Microsoft Office 97 to Microsoft 2003; it cannot convert Microsoft Office 95 and earlier documents. If you try to convert Microsoft Word 95 or older documents (or other Microsoft Office 95 documents), the conversion will fail, putting the document in the http://marklogic.com/states/error state. If this happens, you can do the following:
- Find all of the documents that are in the error state (For details, see Find Documents in the Error State).
- Open the documents in a newer version of Microsoft Word and then re-save them (as newer Word documents, not Word 95 or older documents).
- Reload the saved files into the database.
Once you reload the documents into a database with content processing installed and configured, the new documents will be converted.
There are other types of errors you might get with Microsoft Office documents. For example, if a document is password protected, the conversion will fail because it needs the password to open the document. In general, you can address these types of issues by opening the document in the appropriate Microsoft Office application, changing the cause of the error (for example, removing the password protection), re-saving the document, and reloading the document into the conversion domain.
Set the Needed Permissions on the Root Directory
When you add documents to the database for conversion, the user who adds the documents must have the needed permissions to add and modify documents. If you are using WebDAV server to drag-and-drop documents into the database, the root directory of the WebDAV server must also have the needed permissions.
One simple way to accomplish these security requirements is to do the following:
- Create a URI privilege for the URI that is configured as the root directory of your WebDAV server.
- Create a role that has the URI privilege and has default permissions of read. insert, and update for the role.
- Set the permissions on the WebDAV root directory for the role you created. For example, if the role you created is named
webdav, and the root directory has the URI/webdav/root/, run a query (as a privileged user) similar to the following:xdmp:document-set-permissions("/webdav/root/", ( xdmp:permission("webdav", "read"), xdmp:permission("webdav", "insert"), xdmp:permission("webdav", "update") ) )
You can check the permissions with the following query:
xdmp:document-get-permissions("/webdav/root/")
- Grant the new role (
webdavin the example above) to the user who accesses the WebDAV server.
Default or Inherited Collections and Permissions
If you are using a collection in the domain to specify which documents to convert, the new documents created by the conversion process must be created as part of the collection specified in the domain. You can do this in the following ways:
- Set the
inherit collectionsoption at the database level totrueand make sure the parent directory belongs to the collection. - The user who runs the Default Conversion Option (that is, the user who originally creates the documents to be converted, whether by drag and dropping into a WebDAV folder or by some other means) can have the collection specified as a default collection (or a role to which the user is assigned).
- You can explicitly set the collection on a document (for example, in your XQuery module code or through XDBC).
Otherwise only the first phase of conversion will occur (because documents created during the conversion process will not be part of the collection specified in the domain). Similarly, you must have either the appropriate default permissions assigned to the user (or a role to which the user is assigned) or you should set the permissions to inherit at the database level.
For information on inherited collections and inherited permissions, see the Administrator's Guide. For information on permissions, see Security Guide.
Enable Debugging Capabilities
If you need debugging capabilities, you can set trace events on the server for the Content Processing Framework. For details, see Debugging and Recovering from Error Conditions.
Create Your Own Error Handling Pipeline
If you have special error handling needs, you can always extend the Default Conversion Option application by adding your own custom error handling pipeline. For details on pipelines and creating custom code, see Understanding and Using Pipelines and Using the Framework to Create Custom Applications.
Modifying the Default Conversion Option
This section describes ways to modify the Default Conversion Option, and includes the following subsections:
Copy Defaults and Modify
All of the XQuery code and all of the pipelines for the Default Conversion Option are installed with MarkLogic Server. The pipelines are installed in the following directory:
<install_dir>/Installer
The XQuery modules are installed under the Modules directory in the following location:
<install_dir>/Modules/MarkLogic/conversion/actions
You can create your own pipelines by copying and modifying the Default Conversion Option code to suit your needs. Make sure you understand domains, pipelines, the concepts of the Content Processing Framework, and the rules for XQuery modules in content processing applications before modifying the pipelines. For information on these topics, see the rest of this document.
The modification possibilities are endless. You can add phases to the pipeline to do your own processing, add email notification to your application, add entity extraction from a semantic tagging service, and so on. For information on creating custom applications, see Using the Framework to Create Custom Applications.
PDF Alternate Pipelines
There are several alternate PDF pipelines available to attach to a domain instead of the default PDF pipeline. The Default Conversion Option is designed to have only one PDF pipeline attached to a domain at a time; do not attach several alternate PDF pipelines to the same domain. The following table lists the PDF pipelines with a description of each (choose the one that best matches your needs).
Modifying the Options for Default Conversion
The Default Conversion Option uses the built-in functions xdmp:excel-convert, xdmp:pdf-convert, xdmp:powerpoint-convert, xdmp:tidy, and xdmp:word-convert. The pipelines reference various XQuery modules that call these functions. Each of these functions takes an options node to control its behavior. The options are set to somewhat generic defaults that work well with a large variety of documents. Your own documents might have some more specific needs, however, and the pipelines are designed with the ability to pass in options nodes which specify conversion options.
Each condition and action step in the MarkLogic pipelines has an options node. The options node is defined in a namespace with a URI corresponding to the module path invoked by that step. In these option nodes, you can enter options from any of the Document Conversion functions (xdmp:excel-convert, xdmp:pdf-convert, xdmp:powerpoint-convert, xdmp:tidy, xdmp:word-convert) in the namespace corresponding to that conversion function.
For example, the action for the default PDF Pipeline (pdf-pipeline.xml) has the following options node:
<action> <module>/MarkLogic/conversion/actions/convert-pdf-action.xqy</module> <options xmlns="/MarkLogic/conversion/actions/convert-pdf-action.xqy"> <destination-root/> <wrap xmlns="xdmp:tidy">0</wrap> <tidy-mark xmlns="xdmp:tidy">false</tidy-mark> <show-warnings xmlns="xdmp:tidy">false</show-warnings> </options> </action>
In this options node, the destination-root is an option for this pipeline step. The wrap element is an option passed into the xdmp:tidy built-in function (which the PDF Pipeline uses to clean the generated xhtml), and the tidy-mark and show-warnings elements are also options passed into tidy.
Suppose the PDF documents you want to convert all are password protected and all have the same password. You can then add the following to the options node to specify a password:
<password xmlns="xdmp:pdf-convert">your_password</password>
Notice the namespace of the password option is xdmp:pdf-convert, and this option will be passed in when the pipeline processing calls xdmp:pdf-convert.
All of the pipelines have options nodes, and you can pass in any option to each pipeline. You can change the default options or add other options that make sense for your content. See the MarkLogic XQuery and XSLT Function Reference for the options for each of the Document Conversion functions. Also, the format conversion steps in a pipeline have the following options:
The destination-root option specifies an alternate directory URI where the output of the conversion processing is saved. The default-language option is only used on the Microsoft Office conversion pipelines, and it specifies the value of an xml:lang attribute to put on the root node of the converted Office documents.