
MarkLogic 10 Product DocumentationApplication Developer's Guide — Chapter 4
Working With Binary Documents
This section describes configuring and managing binary documents in MarkLogic Server. Binary documents require special consideration because they are often much larger than text or XML content. The following topics are included:
- Terminology
- Loading Binary Documents
- Configuring MarkLogic Server for Binary Content
- Developing Applications That Use Binary Documents
- Useful Built-ins for Manipulating Binary Documents
Terminology
The following table describes the terminology used related to binary document support in MarkLogic Server.
| Term | Definition |
|---|---|
| small binary document | A binary document whose contents are managed by the server and whose size does not exceed the large size threshold. |
| large binary document | A binary document whose contents are managed by the server and whose size exceeds the large size threshold. |
| external binary document | A binary document whose contents are not managed by the server. |
| large size threshold | A database configuration setting defining the upper bound on the size of small binary documents. Binary documents larger than the threshold are automatically classified as large binary documents. |
| Large Data Directory | The per-forest area where the contents of large binary documents are stored. |
| static content | Content stored in the modules database of the App Server. MarkLogic Server responds directly to HTTP range requests (partial GETs) of static content. See Downloading Binary Content With HTTP Range Requests. |
| dynamic content | Dynamic content is content generated by your application, such as results returned by XQuery modules. MarkLogic Server does not respond directly to HTTP range requests (partial) GET requests for dynamic content. See Downloading Binary Content With HTTP Range Requests. |
Loading Binary Documents
Loading small and large binary documents into a MarkLogic database does not require special handling, other than potentially explicitly setting the document format. See Choosing a Binary Format in the Loading Content Into MarkLogic Server Guide.
External binaries require special handling at load time because they are not managed by MarkLogic. For more information, see Loading Binary Documents.
Configuring MarkLogic Server for Binary Content
This section covers the MarkLogic Server configuration and administration of binary documents.
- Setting the Large Size Threshold
- Sizing and Scalability of Binary Content
- Selecting a Location For Binary Content
- Monitoring the Total Size of Large Binary Data in a Forest
- Detecting and Removing Orphaned Binaries
Setting the Large Size Threshold
The large size threshold database setting defines the maximum size of a small binary, in kilobytes. Any binary documents larger than this threshold are large and are stored in the Large Data Directory, as described in Choosing a Binary Format. The threshold has no effect on external binaries.
For example, a threshold of 1024 sets the size threshold to 1 MB. Any (managed) binary document larger than 1 MB is automatically handled as a large binary object.
The range of acceptable threshold values on a 64-bit machine is 32 KB to 512 MB, inclusive.
Many factors must be considered in choosing the large size threshold, including the data characteristics, the access patterns of the application, and the underlying hardware and operating system. Ideally, set the threshold such that smaller, frequently accessed binary content such as thumbnails and profile images are classified as small for efficient access, while larger documents such as movies and music, which may be streamed by the application, are classified as large for efficient memory usage.
The threshold may be set through the Admin Interface or by calling an admin API function. To set the threshold through the Admin Interface, use the large size threshold setting on the database configuration page.To set the threshold programmatically, use the XQuery built-in admin:database-set-large-size-threshold:
xquery version "1.0-ml"; import module namespace admin = "http://marklogic.com/xdmp/admin" at "/MarkLogic/admin.xqy"; let $config := admin:get-configuration() return admin:save-configuration( admin:database-set-large-size-threshold( $config, xdmp:database("myDatabase"),2048)
When the threshold changes, the reindexing process automatically moves binary documents into or out of the Large Data Directory as needed to match the new setting.
Sizing and Scalability of Binary Content
This section covers the following topics:
- Determining the In Memory Tree Size
- Effect of External Binaries on E-node Compressed Tree Cache Size
- Forest Scaling Considerations
For more information on sizing and scalability, see the Scalability, Availability, and Failover Guide and the Query Performance and Tuning Guide.
Determining the In Memory Tree Size
The in memory tree size database setting must be at least 1 to 2 megabytes greater than the larger of the large size threshold setting or the largest non-binary document you plan to load into the database. That is, 1-2 MB larger than:
max(large-size-threshold, largest-expected-non-binary-document)
As described in Selecting a Location For Binary Content, the maximum size for small binary documents is 512 MB on a 64-bit system. Large and external binary document size is limited only by the maximum file size supported by the operating system.
To change the in memory tree size setting, see the Database configuration page in the Admin Interface or admin:database-set-in-memory-limit in the XQuery and XSLT Reference Guide.
Effect of External Binaries on E-node Compressed Tree Cache Size
If your application makes heavy use of external binary documents, you may need to increase the compressed tree cache size Group setting.
When a small binary is cached, the entire document is cached in memory. When a large or external binary is cached, the content is fetched into the compressed tree cache in chunks, as needed.
The chunks of a large binary are fetched into the compressed tree cache of the d-node containing the fragment or document. The chunks of an external binary are fetched into the compressed tree cache of the e-node evaluating the accessing query. Therefore, you may need a larger compressed tree cache size on e-nodes if your application makes heavy use of external binary documents.
To change the compressed tree cache size, see the Groups configuration page in the Admin Interface or admin:group-set-compressed-tree-cache-size in the XQuery and XSLT Reference Guide.
Forest Scaling Considerations
When considering forest scaling guidelines, include all types of binary documents in fragment count estimations. Since large and external binaries are not fully cached in memory on access, memory requirements are lower. Since large and external binaries are not copied during merges, you may exclude large and external binary content size from maximum forest size calculation.
For details on sizing and scalability, see Scalability Considerations in MarkLogic Server in the Scalability, Availability, and Failover Guide.
Selecting a Location For Binary Content
Each forest contains a Large Data Directory that holds the binary contents of all large binary documents in the forest. The default physical location of the Large Data Directory is inside the forest. The location is configurable during forest creation. This flexibility allows different hardware to serve small and large binary documents. The Large Data Directory must be accessible to the server instance containing the forest. to specify an arbitrary location for the Large Data Directory, use the $large-data-directory parameter of admin:forest-create or the large data directory forest configuration setting in the Admin Interface. We will need to document the best practice for configuring forest Large data directories which is to put them somewhere other than the default of /var/opt/MarkLogic. In other words, using non-default directories for forest large data directories is considered a good practice.
The external file associated with an external binary document must be located outside the forest containing the document. The external file must be accessible to any server instance evaluating queries that manipulate the document. That is, the external file path used when creating an external-binary node must be resolvable on any server instance running queries against the document.
External binary files may be shared across a cluster by placing them on a network shared file system, as long as the files are accessible along the same path from any e-node running queries against the external binary documents. The reference fragment containing the associated external-binary node may be located on a remote d-node that does not have access to the external storage.
The diagram below demonstrates sharing external binary content across a cluster with different host configurations. On the left, the evaluator node (e-node) and data node (d-node) are separate hosts. On the right, the same host serves as both an evaluator and data node. The database in both configurations contains an external binary document referencing /images/my.jpg. The JPEG content is stored on shared external storage, accessible to the evaluator nodes through the external file path stored in the external binary document in the database.
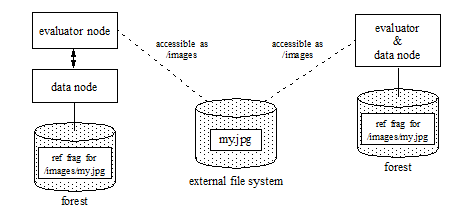
Monitoring the Total Size of Large Binary Data in a Forest
Use xdmp:forest-status or the Admin Interface to check the disk space consumed by large binary documents in a forest. The size is reported in megabytes. For more details on MarkLogic Server's monitoring capability, see the Monitoring MarkLogic Guide.
To check the size of the Large Data Directory using the Admin Interface:
- Open the Admin Interface in your browser. For example, http:yourhost:8001.
- Click Forests in the left tree menu. The Forest summary is displayed.
- Click the name of a forest to display the forest configuration page.
- Click the Status tab at the top to display the forest status page.
- Observe the Large Data Size status, which reflects the total size of the contents of the large data directory.
The following example uses xdmp:forest-status to retrieve the size of the Large Data Directory:
xquery version "1.0-ml"; declare namespace fs = "http://marklogic.com/xdmp/status/forest"; fn:data( xdmp:forest-status( xdmp:forest("samples-1"))/fs:large-data-size)
Detecting and Removing Orphaned Binaries
Large and external binary content may require special handling to detect and remove orphaned binary data no longer associated with a document in the database. This section covers the following topics related to managing orphaned binary content:
- Detecting and Removing Orphaned Large Binary Content
- Detecting and Removing Orphaned External Binary Content
Detecting and Removing Orphaned Large Binary Content
As discussed in Choosing a Binary Format in the Loading Content Into MarkLogic Server Guide, the binary content of a large binary document is stored in the Large Data Directory.
Normally, the server ensures that the binary content is removed when the containing forest no longer contains references to the data. However, content may be left behind in the Large Data Directory under some circumstances, such as a failover in the middle of inserting a binary document. Content left behind in the Large Data Directory with no corresponding database reference fragment is an orphaned binary.
If your data includes large binary documents, periodically check for and remove orphaned binaries. Use xdmp:get-orphaned-binaries and xdmp:remove-orphaned-binary to perform this cleanup. For example:
xquery version "1.0-ml"; for $fid in xdmp:forests() for $orphan in xdmp:get-orphaned-binaries($fid) return xdmp:remove-orphaned-binary($fid, $orphan)
Detecting and Removing Orphaned External Binary Content
Since the external file associated with an external binary document is not managed by MarkLogic Server, such documents may be associated with non-existent external files. For example, the external file may be removed by an outside agency. The XQuery API includes several builtins to help you check for and remove such documents in the database.
For example, to remove all external binary documents associated with the external binary file /external/path/sample.jpg, use xdmp:external-binary-path:
xquery version "1.0-ml"; for $doc in fn:collection()/binary() where xdmp:external-binary-path($doc) = "/external/path/sample.jpg" return xdmp:document-delete(xdmp:node-uri($doc))
To identify external binary documents with non-existent external files, use xdmp:filesystem-file-exists. Note, however, that xdmp:filesystem-file-exists queries the underlying filesystem, so it is a relatively expensive operation. The following example generates a list of document URIs for external binary documents with a missing external file:
xquery version "1.0-ml"; for $doc in fn:collection()/binary() where xdmp:binary-is-external($doc) return if (xdmp:filesystem-file-exists(xdmp:external-binary-path($doc))) then xdmp:node-uri($doc) else ()
Developing Applications That Use Binary Documents
This section covers the following topics of interest to developers creating applications that manipulate binary content:
- Adding Metadata to Binary Documents Using Properties
- Downloading Binary Content With HTTP Range Requests
- Creating Binary Email Attachments
Adding Metadata to Binary Documents Using Properties
Small, large, and external binary documents may be annotated with metadata using properties. Any document in the database may have an associated properties document for storing additional XML data. Unlike binary data, properties documents may participate in element indexing. For more information about using properties, see Properties Documents and Directories.
MarkLogic Server offers the XQuery built-in, xdmp:document-filter, and JavaScript method, xdmp.documentFilter, to assist with adding metadata to binary documents. These functions extract metadata and text from binary documents as a node, each of whose child elements represent a piece of metadata. The results may be used as document properties. The text extracted contains little formatting or structure, so it is best used for search, classification, or other text processing.
For example, the following code creates properties corresponding to just the metadata extracted by xdmp:document-filter from a Microsoft Word document:
xquery version "1.0-ml"; let $the-document := "/samples/sample.docx" return xdmp:document-set-properties( $the-document, for $meta in xdmp:document-filter(fn:doc($the-document))//*:meta return element {$meta/@name} {fn:string($meta/@content)} )
The result properties document contains properties such as Author, AppName, and Creation_Date, extracted by xdmp:document-filter:
<prop:properties xmlns:prop="http://marklogic.com/xdmp/property"> <content-type>application/msword</content-type> <filter-capabilities>text subfiles HD-HTML</filter-capabilities> <AppName>Microsoft Office Word</AppName> <Author>MarkLogic</Author> <Company>Mark Logic Corporation</Company> <Creation_Date>2011-09-05T16:21:00Z</Creation_Date> <Description>This is my comment.</Description> <Last_Saved_Date>2011-09-05T16:22:00Z</Last_Saved_Date> <Line_Count>1</Line_Count> <Paragraphs_Count>1</Paragraphs_Count> <Revision>2</Revision> <Subject>Creating binary doc props</Subject> <Template>Normal.dotm</Template> <Typist>MarkLogician</Typist> <Word_Count>7</Word_Count> <isys>SubType: Word 2007</isys> <size>10047</size> <prop:last-modified>2011-09-05T09:47:10-07:00</prop:last-modified> </prop:properties>
Downloading Binary Content With HTTP Range Requests
HTTP applications often use range requests (sometimes called partial GET) to serve large data, such as videos. MarkLogic Server directly supports HTTP range requests for static binary content. Static binary content is binary content stored in the modules database of the App Server. Range requests for dynamic binary content are not directly supported, but you may write application code to service such requests. Dynamic binary content is any binary content generated by your application code.
This section covers the following topics related to serving binary content in response to range requests:
- Responding to Range Requests with Static Binary Content
- Responding to Range Requests with Dynamic Binary Content
Responding to Range Requests with Static Binary Content
When an HTTP App Server receives a range request for a binary document in the modules database, it responds directly, with no need for additional application code. Content in the modules database is considered static content. You can configure an App Server to use any database as modules database, enabling MarkLogic to respond to directly to range requests for static binary content.
For example, suppose your database contains a large binary document with the URI /images/really_big.jpg and you create an HTTP App Server on port 8010 that uses this database as its modules database. Sending a GET request of the following form to port 8010 directly fetches the binary document:
GET http://host:8010/images/really_big.jpg
If you include a range in the request, then you can incrementally stream the document out of the database. For example:
GET http://host:8010/images/really_big.jpg Range: bytes=0-499
MarkLogic returns the first 500 byes of the document /images/really_big.jpg in a Partial Content response with a 206 (Partial Content) status, similar to the following (some headers are omitted for brevity):
HTTP/1.0 206 Partial Content Accept-Ranges: bytes Content-Length: 500 Content-Range: bytes 0-499/3980 Content-Type: image/jpeg [first 500 bytes of /images/really_big.jpg]
If the range request includes multiple non-overlapping ranges, the App Server responds with a 206 and a multi-part message body with media type multipart/byteranges.
If a range request cannot be satisfied, the App Server responds with a 416 status (Requested Range Not Satisfiable).
The following request types are directly supported on static content:
Responding to Range Requests with Dynamic Binary Content
The HTTP App Server does not respond directly to HTTP range requests for dynamic content. That is, content generated by application code. Though the App Server ignores range requests for dynamic content, your application XQuery code may still process the Range header and respond with appropriate content.
The following code demonstrates how to interpret a Range header and return dynamically generated content in response to a range request:
xquery version "1.0-ml"; (: This code assumes a simple range like 1000-2000; your :) (: application code may support more complex ranges. :) let $data := fn:doc(xdmp:get-request-field("uri"))/binary() let $range := xdmp:get-request-header("Range") return if ($range) then let $range := replace(normalize-space($range), "bytes=", "") let $splits := tokenize($range, "-") let $start := xs:integer($splits[1]) let $end := if ($splits[2] eq "") then xdmp:binary-size($data)-1 else xs:integer($splits[2]) let $ranges := concat("bytes ", $start, "-", $end, "/", xdmp:binary-size($data)) return (xdmp:add-response-header("Content-Range", $ranges), xdmp:set-response-content-type("image/JPEG"), xdmp:set-response-code(206, "Partial Content"), xdmp:subbinary($data, $start+1, $end - $start + 1)) else $data
If the above code is in an XQuery module fetch-bin.xqy, then a request such the following returns the first 100 bytes of a binary. (The -r option to the curl command specifies a byte range).
$ curl -r "0-99" http://myhost:1234/fetch-bin.xqy?uri=sample.jpg
The response to the request is similar to the following:
HTTP/1.1 206 Partial Content Content-Range: bytes 0-99/1442323 Content-type: image/JPEG Server: MarkLogic Content-Length: 100 [first 100 bytes of sample.jpg]
Creating Binary Email Attachments
To generate an email message with a binary attachment, use xdmp:email and set the content type of the message to multipart/mixed. The following example generates an email message with a JPEG attachment:
xquery version "1.0-ml"; (: generate a random boundary string :) let $boundary := concat("blah", xdmp:random()) let $newline := " " let $content-type := concat("multipart/mixed; boundary=",$boundary) let $attachment1 := xs:base64Binary(doc("/images/sample.jpeg")) let $content := concat( "--",$boundary,$newline, $newline, "This is a test email with an image attached.", $newline, "--",$boundary,$newline, "Content-Type: image/jpeg", $newline, "Content-Disposition: attachment; filename=sample.jpeg", $newline, "Content-Transfer-Encoding: base64", $newline, $newline, $attachment1, $newline, "--",$boundary,"--", $newline) return xdmp:email( <em:Message xmlns:em="URN:ietf:params:email-xml:" xmlns:rf="URN:ietf:params:rfc822:"> <rf:subject>Sample Email</rf:subject> <rf:from> <em:Address> <em:name>Myself</em:name> <em:adrs>me@somewhere.com</em:adrs> </em:Address> </rf:from> <rf:to> <em:Address> <em:name>Somebody</em:name> <em:adrs>somebody@somewhere.com</em:adrs> </em:Address> </rf:to> <rf:content-type>{$content-type}</rf:content-type> <em:content xml:space="preserve"> {$content} </em:content> </em:Message>)
Useful Built-ins for Manipulating Binary Documents
The following XQuery built-ins are provided for working with binary content. For details, see the XQuery and XSLT Reference Guide.
- xdmp:subbinary
- xdmp:binary-size
- xdmp:external-binary
- xdmp:external-binary-path
- xdmp:binary-is-small
- xdmp:binary-is-large
- xdmp:binary-is-external
In addition, the following XQuery built-ins may be useful when creating or testing the integrity of external binary content: