Matches for cat:guide (cat:guide/xquery (cat:guide/xquery (cat:guide))) have been highlighted.


MarkLogic Server 11.0 Product DocumentationXQuery and XSLT Reference Guide — Chapter 4
XQuery Language
The chapter describes selected parts of the XQuery language. It is not a complete language reference, but it touches on many of the widely used language constructs. For complete details on the language and complete syntax for the language, see the W3C XQuery specification (http://www.w3.org/TR/xquery/). Additionally, there are many third-party books available on the XQuery language which can help with the basics of the language. This chapter has the following sections:
- Expressions Return Items
- XML and XQuery
- JSON and XQuery
- XQuery Modules
- XQuery Prolog
- XQuery Comments
- XQuery Expressions
- XQuery Comparison Operators
This chapter describes a subset of the XQuery 1.0 recommendation syntax, which is used in the
1.0and1.0-mldialects. For an overview of the different XQuery dialects, see XQuery Dialects in MarkLogic Server.
Expressions Return Items
The fundamental building block in XQuery is the XQuery expression, which is what the XQuery specification refers to as one or more ExprSingle expressions. Each XQuery expression returns a sequence of items; that is, it returns zero or more items, each of which can be anything returned by XQuery (for example, a string, a node, a numeric value, and so on).
Any valid XQuery expression is a valid XQuery. For example, the following is a valid XQuery:
"Hello World"
It returns the string Hello World. It is a simple string literal, and is a valid XQuery. You can combine expressions together using the concatenation operator, which is a comma ( , ), as follows:
"Hello", "World"
This expression also returns a sequence of two string Hello and World. It is two expressions, each returning a single item (therefore it returns a sequence of two strings). In some contexts (a browser, for example), the two strings will be concatenated together into the string Hello World.
Expressions can also return no items (the empty sequence), or they can return sequences of items. The following adds a third expression:
"Hello", "World", 1 to 10
This expression returns the sequence Hello World 1 2 3 4 5 6 7 8 9 10, where the sequence 1 to 10 is a sequence of numeric values. You can create arbitrarily complex expressions in XQuery, and they will always return zero or more items.
XML and XQuery
XQuery is designed for working with XML, and there are several ways to construct and return XML from XQuery expressions. This section describes some of the basic ways to combine XML and XQuery, and contains the following parts:
- Direct Element Constructors: Switching Between XQuery and XML Using Curly Braces
- Computed Element and Attribute Constructors
- Returning XML From an XQuery Program
Direct Element Constructors: Switching Between XQuery and XML Using Curly Braces
As described in the previous section, an XQuery expression by itself is a valid XQuery program. You can create XML nodes as XQuery expressions. Therefore, the following is valid XQuery:
<my-element>content goes here</my-element>
It simply returns the element. The XQuery syntax also allows you to embed XQuery between XML, effectively switching back and forth between an XML syntax and an XQuery syntax to populate parts of the XML content. The separator characters to switch back and forth between XML and XQuery are the open curly brace ( { ) and close curly brace ( } ) characters. For example, consider the following XQuery:
<my-element>{fn:current-date()}</my-element>
This expression returns an XML element named my-element with content that is the result of evaluating the expression between the curly braces. This expression returns the current date, so you get an element that looks like the following:
<my-element>2008-06-25-07:00</my-element>
You can create complex expressions that go back and forth between XML and XQuery as often as is needed. For example, the following is slightly more complex:
<my-element id="{xdmp:random()}">{fn:current-date()}</my-element>
This returns an element like the following:
<my-element id="9175848626240925436">2008-06-25-07:00</my-element>
This technique of constructing XML are called direct element constructors. There are many more rules for how to use these direct element constructors to create XML nodes. For more details, see the of the XQuery specification (http://www.w3.org/TR/xquery/#doc-xquery-DirCommentConstructor).
Computed Element and Attribute Constructors
You can also create XML nodes by using computed constructors. There are computed constructors for all types of XML nodes (element, attribute, document, text, comment, and processing instruction). The following is the basic syntax for computed constructors:
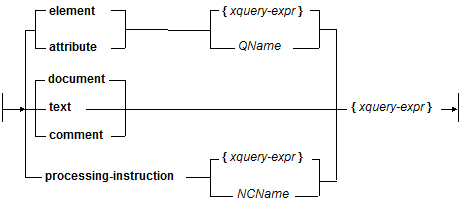
The following is an example of some XML that is created using computed constructors:
element hello { attribute myatt { "world" } , "hello world" } (: returns the following XML: <hello myatt="world">hello world</hello> :)
In this example, the comma operator concatenates a constructed attribute (the myatt attribute on the hello element) and a literal expression (hello world, which becomes the element text node content) to create the content for the element node. The following example shows how you can compute the QName with an XQuery expression:
element {xs:QName("hello")} { attribute myatt { "world" } , "hello world" } (: returns the following XML: <hello myatt="world">hello world</hello> :)
Returning XML From an XQuery Program
Using the direct and computed constructors described above, it is natural to have the output of an XQuery program be XML. Besides computed and direct constructors, XML can be the result of an XPath expression, a cts:search expression, or any other expression that returns XML. The XML can be constructed as any well-formed XML.
When you construct XML in XQuery, the XQuery evaluator will always construct well-formed XML (assuming your XQuery is valid). Compared with other languages where you construct strings that represent XML, the fact that the XQuery rules ensure that an XML node is well formed tends to eliminate a whole class of bugs in your code that you might encounter using other languages.
JSON and XQuery
You can construct JSON nodes using computed constructors, just as you can create XML nodes. The MarkLogic API includes constructors for JSON nodes such as objects, arrays, numbers, and booleans. You can also construct JSON documents from a serialized string representation, using xdmp:unquote. For details, see Constructing JSON Nodes in the Application Developer's Guide.
XQuery Modules
While expressions are the building blocks of XQuery coding, modules are the building blocks of XQuery programs. There are two kinds of XQuery modules: main modules and library modules. This section describes XQuery modules and includes the following sections:
This section provides some basic syntax for XQuery modules. For the complete syntax of XQuery modules, see the XQuery specification (http://www.w3.org/TR/xquery/#doc-xquery-Module).
XQuery Version Declaration
Every XQuery module (both main and library) can have an optional XQuery version declaration. The version declaration tells MarkLogic Server which dialect of XQuery to use. MarkLogic Server supports the following values for the XQuery version declaration: 1.0-ml, 1.0, and 0.9-ml.
XQuery dialect 0.9-ml has been deprecated. MarkLogic recommends that you use either 1.0-ml or 1.0.
For details on dialects 1.0 and 1.0-ml, including rules for the combining different dialects, see XQuery Dialects in MarkLogic Server.
The following is the basic syntax of the XQuery version declaration:
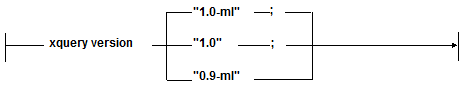
The following is an example of an XQuery version declaration:
xquery version "1.0-ml";
Main Modules
A main module contains an XQuery program to be evaluated. You can call a main module directly and it will return the results of the evaluation. A main module contains an optional XQuery version declaration, a prolog (the prolog can be empty, so it is in effect optional), and a body. The XQuery body can be any XQuery expression.
In 1.0-ml, you can construct programs that have multiple main modules separated by semi-colons, as described in Semi-Colon as Transaction Separator.
The following is an example of a very simple main module:
xquery version "1.0-ml"; "hello world"
For another example of a main module, see the example at the end of the Library Modules.
Library Modules
A library module contains function definitions and/or variable definitions. You cannot call a library module to directly evaluate it, and it cannot have a query body. To use a library module, it must be imported from another module (main or library). A library module contains a module declaration followed by a prolog. For details on the prolog, see XQuery Prolog. The following is the basic syntax of a library module:
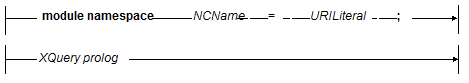
The following is a very simple XQuery library module
xquery version "1.0-ml"; module namespace my-library="my.library.uri" ; declare function hello() { "hello" };
If you stored this module under an App Server root as hello.xqy, you could call this function with the following very simple main module:
xquery version "1.0-ml"; import module namespace my-library="my.library.uri" at "hello.xqy"; my-library:hello() (: this returns the string "hello" :)
XQuery Prolog
The XQuery prolog contains any module imports, namespace declarations, function definitions, and variable definitions for a module. You can have a prolog in either a main module or a library module. The prolog is optional, as you can write an XQuery program with no prolog. This section briefly describes the following parts of the XQuery prolog:
- Importing Modules or Schemas
- Declaring Namespaces
- Declaring Options
- Declaring Functions
- Declaring Variables
- Declaring a Default Collation
Importing Modules or Schemas
You can import modules and schemas in the XQuery prolog. The following are sample module and schema import declarations:
import module namespace my-library="my.library.uri" at "hello.xqy"; import schema namespace xhtml="http://www.w3.org/1999/xhtml" at "xhtml1.1.xsd";
The library module location and the schema location are not technically required. The location must be supplied for module imports, however, as they are used to determine the location of the library module and the module will not be found without it. Also, all modules for a given namespace must be imported with a single import statement (with comma-separated locations). For schema imports, if the location is not supplied, MarkLogic Server resolves the schema URI using the in-scope schemas (schemas in the schemas database and the <marklogic-dir>/Config directory). If there are multiple schemas with the same URI, MarkLogic Server chooses one of them. Therefore, to ensure you are importing the correct schema, use the location for the schema import, too. For details on the rules for resolving the locations, see Importing XQuery Modules, XSLT Stylesheets, and Resolving Paths in the Application Developer's Guide.
For more details on imports, see the XQuery specification for schema imports (http://www.w3.org/TR/xquery/#id-schema-import) and for module imports (http://www.w3.org/TR/xquery/#id-module-import).
Declaring Namespaces
Namespace declarations are used to bind a namespace prefix to a namespace URI. The following is a sample namespace declaration:
declare namespace my-namespace="my.namespace.uri";
For more details on namespace declarations, see the XQuery specification (http://www.w3.org/TR/xquery/#id-namespace-declaration)
Declaring Options
XQuery provides vendor-specific options that are declared in the prolog. This section describes the MarkLogic Server options you can declare in the XQuery prolog, and includes the following prolog options:
- xdmp:mapping
- xdmp:update
- xdmp:commit
- xdmp:transaction-mode
- xdmp:copy-on-validate
- xdmp:output
- xdmp:coordinate-system
xdmp:mapping
declare option xdmp:mapping "false";
The xdmp:mapping option sets whether function mapping is enabled in a module. For details on function mapping, see Function Mapping.
xdmp:update
declare option xdmp:update "true";
The xdmp:update option forces a request to either be an update ("true"), a query ("false"), or to determine the update mode of the query at compile time ("auto"). Without this option, the request will behave as if the option is set to "auto" and determine at compile time whether to run as an update statement (in readers/writers mode) or whether to run at a timestamp. For details on update statements versus query statements, see Understanding Transactions in MarkLogic Server in the Application Developer's Guide.
xdmp:commit
declare option xdmp:commit "explicit";
The xdmp:commit option specifies whether MarkLogic treats each XQuery statement as a single-statement, auto-commit transaction ("auto") or a multi-statement transaction that must be explicitly committed or rolled back ("explicit"). The default behavior is auto.
For more details, see Understanding Transactions in MarkLogic Server in the Application Developer's Guide.
xdmp:transaction-mode
This option is deprecated. Use xdmp:update and xdmp:commit, instead.
Use xdmp:transaction-mode to change the runtime model for newly created transactions. The transaction mode affects when transactions are created, whether or not they span statement boundaries, and when and how they are committed. The default mode is auto:
declare option xdmp:transaction-mode "auto";
You can specify the following values for xdmp:transaction-mode, as string literals:
These values correspond to the equivalent settings for the xdmp:set-transaction-mode XQuery function. Use the option, rather than the API function, if you need to set the transaction mode before creating any transactions.
For details on transaction modes, see Transaction Mode in the Application Developer's Guide, and the discussion of xdmp:set-transaction-mode in MarkLogic XQuery and XSLT Function Reference.
xdmp:copy-on-validate
declare option xdmp:copy-on-validate "true";
The xdmp:copy-on-validate option defines the behavior of the validate expression. You can set the option to make a copy of the node during schema validation. For details, see Validate Expression.
xdmp:output
The xdmp:output option determines how the output is serialized. The options mirror the serialization options for xslt using the <xsl:output> XSLT instruction. The following example causes html serialization:
declare option xdmp:output "method = html";
For details on the <xsl:output> XSLT instruction, from which many of the xdmp:output options are derived, see http://www.w3.org/TR/xslt#output in the XSLT specification. You can combine options by having multiple declare option statements.
Valid values for the xdmp:output option are (the values must be string literals):
method = xmlmethod = htmlmethod = textmethod = sparql-results-jsonmethod = n-triplesmethod = n-quadsmethod = sparql-results-csvmethod = rows-jsonmethod = rows-json-seqmethod = rows-json-multipartmethod = rows-xmlmethod = rows-xml-multipartmethod = rows-json-uniformmethod = rows-json-seq-uniformmethod = rows-json-multipart-uniformmethod = rows-xml-uniformmethod = rows-xml-multipart-uniformmethod = rows-json-multipart-nodemethod = rows-json-multipart-uniform-nodemethod = rows-xml-multipart-nodemethod = rows-xml-multipart-uniform-nodecdata-section-elements = <QName>encoding = <encoding>use-character-maps=xdmp:sgml-entities-normaluse-character-maps=xdmp:sgml-entities-mathuse-character-maps=xdmp:sgml-entities-pubmedia-type = <media>byte-order-mark = yesbyte-order-mark = noindent = yesindent = noindent-untyped = yesindent-untyped = noindent-tabs = yesindent-tabs = noinclude-content-type = yesinclude-content-type = noescape-uri-attributes = yesescape-uri-attributes = nodoctype-public = <publicid1>doctype-system = <systemid1>omit-xml-declaration = noomit-xml-declaration = yesstandalone = yesstandalone = nonormalization-form = NFCnormalization-form = NFDnormalization-form = NFKDdefault-attributes = nodefault-attributes = yes
Additionally, these are all available in XSLT as attributes on the <xsl:output> instruction. In the <xsl:output> instruction, use these attributes in the form:
attribute-name="value"
The exceptions to this are the MarkLogic extensions indent-untyped and default-attributes. When using these attributes, use the namespace prefix xdmp with the attributes (and you must define the prefix in your stylesheet XML). For example:
<xsl:output xdmp:default-attributes="no" xdmp:intent-untyped="yes" xmlns:xdmp="http://marklogic.com/xdmp"/>
xdmp:coordinate-system
Use xdmp:coordinate-system to override the App Server default geospatial coordinate system and precision. For example, the following declaration specifies that a module will use the wgs84 coordinate system and double precision in geospatial operations.
declare option xdmp:coordinate-system "wgs84/double";
The coordinate system name can be any of the canonical names generated by geo:coordinate-system-canonical, including the following:
Single precision is implied where the name does not explicitly include double.
Declaring Functions
Functions are a fundamental part of programming in XQuery. Functions provide more than a mechanism to modularize your code (although they certainly are that), as functions allow you to easily perform recursive actions. This is a powerful design pattern in XQuery.
Functions can optionally be typed, both for parameters to the function and for results of the function. The following is a very simple function declaration that takes a string as input and returns a sentence indicating the length of the string:
declare function simple($input as xs:string) as xs:string* { fn:concat('The string "', $input, '" is ', (fn:string-length($input)), ' characters in length.') } ;
Declaring Variables
You can declare variables in a main or library module to reference elsewhere in your programs. If you put variable definitions in a library module, you can reference those variables from any module that imports the library module. Because the content of a variable can be any valid XQuery expression, you can create variables with dynamic content. The following is a variable declaration that returns a string indicating if it is January or not:
declare variable $is-it-january as xs:string := if ( fn:month-from-date(fn:current-date()) eq 1 ) then "it is January" else "it is not January" ;
If this variable were defined in a library module named mylib.xqy stored under your App Server root, and if you imported that library module bound to the namespace prefix mylib into a main module, then you can reference this variable in the main module as follows:
xquery version "1.0-ml"; import module namespace mylib="my.library.uri" at "mylib.xqy"; $mylib:is-it-january
Declaring a Default Collation
The default collation declaration defines the collation that is in effect for a query. In general, everything that uses a collation in a query with a default collation declaration will use the collation specified. The exceptions are for functions that have options which explicitly override the default collation, and for FLWOR expressions that explicitly state the collation in the order by clause. The following is a sample collation declaration:
declare default collation "http://marklogic.com/collation/";
For more details on collations, see the Encodings and Collations chapter of the Application Developer's Guide.
XQuery Comments
You can add comments throughout an XQuery program. Comments are surrounded by smiley face symbols. The open parenthesis followed by the colon characters ( (: ) denote the start of a comment, and the colon followed by a close parenthesis characters ( (: ) denote the end of a comment. Comments can be nested within comments, which is useful when cutting and pasting code with comments in it into a comment. The following is an example of an XQuery that starts with a comment:
(: everything between the smiley faces is a comment :) "some XQuery goes here"
You cannot put a comment inside of a text literal or inside of element content. For example, the following is not interpreted as having a comment:
<node>(: not a comment :)</node>XQuery Expressions
This section describes the following XQuery expressions:
- XPath Expressions
- FLWOR Expressions
- The typeswitch Expression
- The if Expression
- Quantified Expressions (some/every ... satisfies ...)
- Validate Expression
XPath Expressions
XPath expressions search for XML content. They can be combined with other XQuery expressions to form other arbitrarily complex expressions. For more details on XPath expressions, see XPath Quick Reference.
FLWOR Expressions
The FLWOR expression (for, let, where, order by, return) is used to generate items or sequences. A FLWOR expression binds variables, applies a predicate, orders the data set, and constructs a new result:
The following is the basic syntax of a FLWOR expression:

The following sections examine each of the five clauses in more detail:
The for Clause
The for clause is used for iterating over one or more sequences:

The for clause iterates over each item in the expression to which the variable is bound. In the return clause, an action is typically performed on each item in the variable bound to the expression. For example, the following binds a sequence of integers to a variable and then performs an action (multiplies it by 2) on each item in the sequence:
for $x in (1, 2, 3, 4, 5) return $x * 2 (: returns the sequence (2, 4, 6, 8, 10) :)
As is common in XQuery, order is significant, and the items are bound to the variable in the order they are output from the expression.
You can also bind multiple variables in one or more for clauses. The FLWOR expression then iterates over each item in the subsequent variables once for each item in the first variable. For example:
for $x in (1,2,3) for $y in (4,5,6) return $x * 2 (: returns the sequence (2, 2, 2, 4, 4, 4, 6, 6, 6) :)
In this case, the inner for loop (with $y) is executed one complete iteration for each of the items in the outer for loop (the one with $x). Even though it does not return anything from $y, the expression in the return clause is evaluated once for each item in $y, and that happens once for each item in $x.
You could return something from each iteration of $y, as in the following example:
for $x in (1,2,3) for $y in (4,5,6) return ($x * 2, $y * 3) (: returns the sequence (2, 12, 2, 15, 2, 18, 4, 12, 4, 15, 4, 18, 6, 12, 6, 15, 6, 18) :)
Alternately, you could write the two for clauses as follows, with the same results:
for $x in (1,2,3), $y in (4,5,6)
When you have multiple variables bound in for clauses, it is an effective way of joining content from one variable with the other. Note that if the content from each variable comes from a different document, then multiple for clauses in a FLOWR expression ends up performing a join of the documents.
The let Clause
The let clause is used for binding variables (without iteration) to a single value or to sequences of values:

A let clause produces a single binding for each variable. Consequently, let clauses do not affect the number of binding tuples evaluated in a FLWOR expression. Variables bound in a let clause are available to anything that follows in the FLWOR expression (for example, subsequent for or let clauses, the where clause, the order by clause, or the return clause).
In its simplest form, the let clause allows you to build a FLWOR expression that outputs the sequence to which the variable is bound. For example, the following expression:
let $seq := ("hello", "goodbye") return $seq
is equivalent to the following expression:
"hello", "goodbye"
They each return the two item sequence hello goodbye.
A typical use for a let clause is to bind a sequence to a variable, then use the variable in a for clause to iterate over each item. For example:
let $x := (1 to 5) for $y in $x return $x * 2 (: returns the sequence (2, 4, 6, 8, 10) :)
Again, this is a trivial example, but it could be that the expression in the let binding is complicated, and this technique allows you to cleanly structure your code.
The where Clause
The where clause specifies a filter condition on the tuples emerging from the for-let portion of a FLWOR expression:
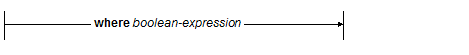
Only tuples for which the boolean-expression evaluates to true will contribute to the result sequence of the FLWOR expression The where clause preserves the order of tuples, if any. boolean-expression may contain and, or and not, among other operators.
Typically, you use comparison operators to test for some condition in a where clause. For example, if you only want to output from the FLWOR items that start with the letter a, you can do something like the following:
for $x in ("a", "B", "c", "A", "apple") where fn:starts-with(fn:lower-case($x), "a") return $x (: returns the sequence ("a", "A", "apple") :)
The order by Clause
The order by clause specifies the order (ascending or descending) to sort items returned from a FLWOR expression, and also provides an option to specify a collation URI with which to determine the order:
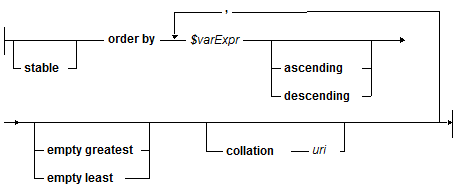
The order by clause can be used to specify an order in which the tuple sequence will be passed to the return clause. The order by clause can specify any sort key, regardless of whether that sort key is contained in the result sequence. You can reorder sequences on an ascending or descending basis.
The following example sorts the sequence bound to $x (in collation order) by each item:
for $x in ( "B", "c", "a", "d") order by $x return $x (: returns the sequence ("a", "B", "c", "d") :)
The following example specifies multiple sort keys:
xquery version "1.0-ml"; for $x in ( <data><a>1</a><b>10</b></data>, <data><a>20</a><b>5</b></data>, <data><a>20</a><b>25</b></data> ) order by $x/a descending, $x/b return $x (: returns the following sequence : <data><a>20</a><b>25</b></data> : <data><a>20</a><b>5</b></data> : <data><a>1</a><b>10</b></data> :)
The return Clause
The return clause constructs the result of a FLWOR expression:
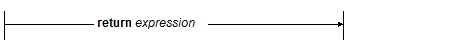
The return expression is evaluated once for each tuple of bound variables. This evaluation preserves the order of tuples, if any, or it can impose a new order using the order by clause.
Because the return clause specifies an expression, any legal XQuery expression can be used to construct the result, including another FLWOR expression.
The typeswitch Expression
The typeswitch expression allows conditional evaluation of a set of sub-expressions based on the type of a specified expression:
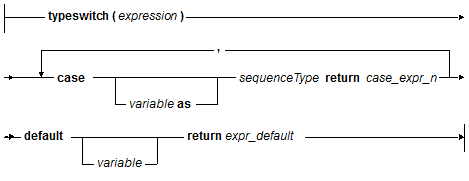
A typeswitch expression evaluates the first case_expr whose sequenceType matches the type of the specified expression. If there is no sequenceType match, expr_default is evaluated.
Typeswitch provides a powerful mechanism for processing node contents:
typeswitch ($address) case $a as element(*, USAddress) return handleUS($a) case $a as element(*, CanadaAddress) return handleCanada($a) default return handleUnknown($address)
This code snippet determines the sequenceType of the variable $address, then evaluates one of three sub-expressions. In this case:
- If
$addressis of typeUSAddress, the functionhandleUS($a)is evaluated. - If
$addressis of typeCanadaAddress, the functionhandleCanada($a)is evaluated. - If the type of variable
$addressmatches none of the above, the functionhandleUnknown($a)is evaluated.
A sequenceType can also be a kind test (such as an element test). It is possible to construct case clauses in which a particular expression matches multiple sequenceTypes. In this case, the case_expr of only the first matching sequenceType is evaluated. You can also use the typeswitch expression in a recursive function to iterate through a document and perform transformation of the document. For details about using recursive typeswitches, see the Transforming XML Structures With a Recursive typeswitch Expression chapter of the Application Developer's Guide.
The if Expression
The if expression allows conditional evaluation of sub-expressions:
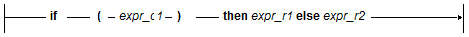
If expression expr_c1 evaluates to true, then the value of the if expression is the value of expression expr_r1, otherwise the value of the if expression is the value of expr_r2. The else clause is not optional; if no action is to be taken, use an empty sequence for expr_r2; there is no end if or similar construct in XQuery:
if (1 eq 2) then "this is strange" else ()
The extent of expr_r1 and expr_r2 is limited to a single expression. If a more complex set of actions are required, an element constructor, sequence, or function call must be used.
if ($year < 1994) then <available>archive</available> else if ($year = $current_year) then <available>current</available> else <available>inventory</available>
Quantified Expressions (some/every ... satisfies ...)
XQuery provides predicates that simplify the evaluation of quantified expressions. The basic syntax for these expressions follows:

These expressions are particularly useful when trying to select a node based on a condition satisfied by at least one or alternatively all of a particular set of its children.
Imagine an XML document containing log messages. The document has the following structure:
<log> <event> <program> .... </program> <message> .... </message> <level> .... </level> <error> <code> .... </code> <severity> .... </severity> <resolved> .... </resolved> </error> <error> .... </error> .... </event> .... </log>
Every <event> node has <program>, <message>, and <level> children. Some <event> nodes have one or more <error> children.
Consider a query to report on those events that have unresolved errors:
for $event in /log/event where some $error in $event/error satisfies $error/resolved = "false" return $event
This query returns only those <event> nodes in which there is an <error> node with a <resolved> element whose value is false.
Validate Expression
The validate expression is used to validate element and document nodes against in-scope schemas (schemas that are in the schemas database). The following is the basic syntax of the validate expression:
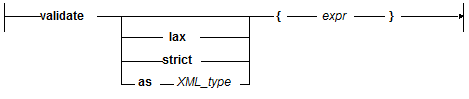
The expression to validate must be a node referencing an in-scope schema. The node can reference a schema. The default validation mode is strict. When performing lax validation, the validate expression first tries to validate the node using an in-scope schema, and then if no schema is found and none is referenced in the node, the validation occurs without a schema. If a node is not valid, an exception is thrown. If a node is valid, then the node is returned. For more details, see the XQuery specification (http://www.w3.org/TR/xquery/#id-validate).
You can also set a prolog option to determine if the node returned is a copy of the original node (losing its context) or the original node (keeping its context). The XQuery specification calls for the node to be a copy, but it is often useful for the node to retain its original context (for example, so you can look at its ancestor elements). The following is the prolog option:
declare option xdmp:copy-on-validate "true";
You can specify true or false. This option is true by default in the 1.0 dialect, and false by default in the 1.0-ml dialect.
The following is a simple validate expression:
xquery version "1.0-ml"; validate { <p xmlns="http://www.w3.org/1999/xhtml">hello there</p> } (: validates against the in-scope xhtml schema and returns the element: <p xmlns="http://www.w3.org/1999/xhtml">hello there</p> :)
The as XML_type validation mode allows you to specify the type to validate as (rather than use the in-scope schema definitions for the type). This mode is an extension to the XQuery 1.0 syntax and is only available in the 1.0-ml dialect.
xquery version "1.0-ml"; validate as xs:boolean { <foo>{fn:true()}</foo> }
In the 1.0 dialect (or also in the 1.0-ml dialect), you can specify the an xdmp:validate-type pragma before an expression to perform the same as XML_type validation, but without the validate as syntax, as in the following example:
xquery version "1.0"; declare namespace xdmp="http://marklogic.com/xdmp"; (# xdmp:validate-type xs:boolean #) { <foo>{fn:true()}</foo> }
XQuery Comparison Operators
This section lists the comparison operators in XQuery. The purpose of the operators are to compare expressions. This section includes the following parts:
Node Comparison Operators
You can specify node comparisons to test if two nodes are before or after each other (in document order), or if the nodes are the exact same node. These tests return true or false. The following are the node comparison operators:
Node comparison tests are useful when creating logic that relies on document order. For example, if you wanted to verify if a particular node came before another node, you can test as follows:
$x << $y
If this test returns true, you know that the node bound to $x comes before the node bound to $y, based on document order.
Sequence and Item Operators
XQuery has separate operators for to compare sequences and items. The following table lists XQuery operators for sequences and for items, along with a description and example for each operator. These operators are used to form expressions that compare values, and those expressions return a boolean value. This section consists of the following parts:
Sequence Operators
The following operators work on sequences. Note that a single item is a sequence, so the sequence operators can work to compare single items. A sequence operator is true if any of the comparisons are true.
Item Operators
The following operators work on items. If you use these operators on a sequence, in the 1.0-ml dialect they will perform function mapping, and the value will be the effective boolean value of the sequence of results. In the 1.0 dialect, they will throw an XDMP-MANYITEMSEQ exception if you try to compare a sequence of more than one item.