Matches for cat:guide/rest-dev (cat:guide/rest-dev (url-encode)) have been highlighted.


MarkLogic Server 11.0 Product DocumentationREST Application Developer's Guide — Chapter 5
Reading and Writing Multiple Documents
The REST Client API includes interfaces that enable you to read or write multiple documents in a single request. You can select documents for a bulk read using a list of URIs or a query.
- Terms and Definitions
- Writing Multiple Documents
- Reading Multiple Documents by URI
- Reading Multiple Documents Matching a Query
- Bulk Read Response Overview
Terms and Definitions
This chapter uses the following terms and definitions:
| Term | Definition |
|---|---|
| content part | A part of a multipart/mixed request body or response that contains document content. Content must be XML, JSON, Text, or Binary. |
| metadata part | A part of a multipart/mixed request body or response that contains document metadata such as properties, collections, quality, permissions, and key-value metadata. The content in a metadata part must XML or JSON and use the syntax described in Working with Metadata. |
| system default metadata | The default metadata values configured into MarkLogic Server. There are no defaults for collections or properties. |
| request default metadata | During bulk write, request-specific metadata that applies to documents without document-specific metadata. Request default metadata supersedes system default metadata. For details, see Constructing a Metadata Part. |
| document-specific metadata | During bulk write, a metadata part that applies to a specific document. Document-specific metadata supersedes request default metadata and system default metadata. For details, see Constructing a Metadata Part. |
Writing Multiple Documents
To write multiple documents in a single request, send a POST request to the /documents service with a URL of the following form and set the Content-Type header to multipart/mixed.
http://host:port/version/documents
The request must not include a uri or extension request parameter and the Content-Type header value must be multipart/mixed. Each part in the request body contains either content or metadata, which is indicated by the Content-Disposition part header.
MarkLogic Server creates or updates the documents and metadata in a bulk write request in a single transaction. If a single insertion or update fails, the entire batch of document operations fails.
When you use bulk write, pre-existing document properties are preserved, but other categories of metadata are completely replaced. If you want to preserve pre-existing metadata, use a single document write, such as a PUT request to /documents. For details, see Manipulating Documents.
When running the examples in this section, do not cut and paste the example multipart/mixed POST bodies. A multipart/mixed request body contains control characters that are not preserved when you copy the text. For details, see Generating Example Payloads with XQuery.
For details, see the following topics.
- Example: Loading Multiple Documents
- Request Body Overview
- Response Overview
- Constructing a Content Part
- Understanding Metadata Scoping
- Understanding When Metadata is Preserved or Replaced
- Constructing a Metadata Part
- Applying a Write Transformation
- Example: Controlling Metadata Through Defaults
- Example: Reverting to System Default Metadata
- Example: Adding Documents to a Collection
- Generating Example Payloads with XQuery
Example: Loading Multiple Documents
This example provides a quick introduction to using the bulk write feature. It creates an XML document and a JSON document.
The XML document uses the system default metadata since the document part is not preceded by any document-specific or request default metadata. The JSON document uses the document-specific metadata included in the request.
The POST body contains three parts: An XML content part for a document with URI doc1.xml, a JSON metadata part for a document with URI doc2.json, and a content part for a JSON document with URI doc2.json.
The part Content-Type header indicates the MIME type of the part contents. The part Content-Disposition header indicates whether a part contains content or metadata. For details, see Request Body Overview.
The following graphic shows the breakdown of the parts.

You cannot create a working multipart POST body by cutting and pasting from the examples in this guide. If your development environment does not include other tools or libraries for constructing a multipart HTTP request body, you can use the following XQuery to generate the payload using the technique described in Generating Example Payloads with XQuery.
xquery version "1.0-ml"; declare variable $OUTPUT-FILENAME := "/example/simple-body"; declare variable $BOUNDARY := "BOUNDARY"; let $xml-doc:= document{ <root><a>Some data in an XML document</a></root> } let $json-metadata := text { '{"quality" : 2 }'} let $json-doc :=text{'{"key":"value"}'} let $manifest := <manifest> <!-- doc1.xml content --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc1.xml"</Content-Disposition> </headers> </part> <!-- doc2.json metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="doc2.json"; category=metadata</Content-Disposition> </headers> </part> <!-- doc2.json content --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="doc2.json"</Content-Disposition> </headers> </part> </manifest> return xdmp:save($OUTPUT-FILENAME, xdmp:multipart-encode( $BOUNDARY, $manifest, ($xml-doc,$json-metadata,$json-doc) ) )
The following command writes the documents and receives a JSON response. Use the Accept header to control whether the request returns an XML or JSON response. The boundary in the header must match the boundary that separates the parts in the request body.
$ curl --anyauth --user user:password -X POST \ --data-binary @/example/simple-body -i \ -H "Accept: application/json" \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/documents
MarkLogic Server responds with the following data. The response includes a document entry for each created or updated document. Each document entry provides enough information to retrieve the associated document and/or its metadata. For details, see Response Overview.
HTTP/1.1 200 OK Server: MarkLogic Content-Type: text/xml; charset=UTF-8 Content-Length: 449 Connection: Keep-Alive Keep-Alive: timeout=5 <rapi:documents xmlns:rapi="http://marklogic.com/rest-api"> <rapi:document> <rapi:uri>doc1.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>doc2.json</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/json</rapi:mime-type> </rapi:document> </rapi:documents>
Request Body Overview
The multipart body of a bulk write request represents a stream of document metadata and/or content. Each part contains either content or metadata. The request body has the following key features:
- Document content can be heterogeneous. You can create any combination of XML, JSON, Text, and Binary documents in a single request.
- Metadata can be expressed in XML or JSON.
- You can create documents with the system default metadata, request default metadata, or document-specific metadata. You can mix these metadata sources in the same request.
For example, a request with the following parts in the POST body creates 2 JSON documents, a binary document, and an XML document. The XML document has document-specific metadata, while the other documents use the request default metadata from the first part.

For a complete example, see Example: Loading Multiple Documents.
The part headers describe the kind of part (content or metadata), the MIME type of the part body, and additional part-specific options. The table below outlines the role of the headers for content and metadata parts.
Response Overview
If a bulk write request is successful, the response body contains a list of document descriptors, one per document created, in the order of creation. The response can be XML or JSON, depending on the Accept header.
If there is an error creating one of the documents, the entire batch is rejected and the database is unchanged. In the event of an error, MarkLogic Server responds with error status code and the response body includes details about the failing document.
For example, the following response data reflects successful creation of 3 documents. Both metadata and content are available for doc1.xml and doc2.json, but only metadata is available for doc3.xml.
You can use the data in the response to retrieve the inserted documents. For example, you can retrieve doc2.json using the following GET request, where the MIME type in the Accept header comes from the response mime-type element/key value and the uri and category request parameter values come from the corresponding response element/key values.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: application/json" \ 'http://localhost:8000/LATEST/documents?uri=doc2.json&category=content'
The following table provides more details on the information returned about each document:
Constructing a Content Part
When constructing a content part, you must include a Content-Type header that controls the document type and a Content-Disposition header that controls the document URI. The Content-Disposition header can also include additional options.
A content part is distinguished from a metadata part by the absence of category=metadata in the Content-Disposition header.
For details, see the following topics:
- Controlling Document Type
- Specifying an Explicit Document URI
- Automatically Generating a Document URI
- Adding Content Options
- Example Content Part Headers
Controlling Document Type
You can create JSON, XML, Binary, and Text documents in a bulk write. The MIME type of the part Content-Type header determines the database document type.
You are responsible for ensuring the MIME type and the part contents match. MarkLogic Server does not sniff the contents or perform implicit content conversions.
The MarkLogic Server MIME type mapping determines the document type for XML, Text, and Binary documents. For example, the following header creates an XML document because the MIME type application/xml is mapped to XML in the default server MIME type mapping.
Content-Type: application/xml
To review or change the MIME type mapping, see the Mimetypes subsection of the Groups section of the Admin Interface.
For JSON documents, content is assumed to be JSON if the MIME type begins with application/, optionally followed by some-format+, and ends with json. For example, all the following headers indicate a part that contains JSON:
Content-Type: application/json Content-Type: application/rdf+json
Specifying an Explicit Document URI
To include an explicit URI for a document, set the content disposition of the metadata and/or content part to attachment and put the URI in the filename parameter. That is, use the following header template:
Content-Disposition: attachment;filename=/your/uri
A metadata part of the above form signifies document-specific metadata. If the request includes content for the same document, the corresponding content part must immediately follow the document-specific metadata part. For details, see Constructing a Metadata Part.
For examples, see Example Content Part Headers.
Automatically Generating a Document URI
To have MarkLogic Server generate the URI for a document, set the content disposition to inline and include an extension parameter that specifies the URI extension. You can also include an optional directory parameter that specifies a destination database directory. That is, use one of the following header templates:
Content-Disposition: inline;extension=suffix Content-Disposition: inline;extension=suffix;directory=/your/dir/
Do not include a separator in the extension value. MarkLogic Server will prefix your suffix with a period ( . ).
A directory path must end with a slash ( / ).
Best practice is to use an extension suffix for which there is a MIME type mapping in MarkLogic Server. The part Content-type should match the MIME type corresponding to the extension. To review or change the MIME type mapping, see the Mimetypes subsection of the Groups section of the Admin Interface.
You can only use server-generated URIs on content parts. Metadata for documents with server-assigned URIs can only come from request default metadata or system default metadata. For details, see Constructing a Metadata Part.
For example, the following headers signify a JSON content part with a server-generated URI that uses the directory /my/dir and ends with .json, such as /my/dir/1234567890.json.
Content-type: application/json Content-Disposition: inline;extension=json;directory=/my/dir/
For more examples, see Example Content Part Headers.
Adding Content Options
Use the Content-Disposition header to include document-specific options such as lang, repair, or extract. For example, the use of extract=properties in the following header tells MarkLogic Server to extract metadata from a binary document and save it as a document property.
Content-type: image/jpeg Content-Disposition: attachment;filename=my.jpg;extract=properties
For option details, refer to the API reference for POST:/v1/documents.
Example Content Part Headers
The table below shows example headers for several kinds of content part.
Understanding Metadata Scoping
This topic describes how metadata is selected for documents created or updated with a bulk write. For details on the structure of a metadata part, see Constructing a Metadata Part.
For performance reasons, pre-existing metadata other than properties is completely replaced during a bulk write operation, either with values supplied in the request or with system defaults.
Metadata in a bulk write can be drawn from 3 possible sources, as shown in the table below. The table lists the metadata sources from highest to lowest precedence, so a source supersedes those below it if both are present.
The following rules determine what metadata applies during document creation.
- If a content part is immediately preceded by a corresponding document-specific metadata part, use it.
- If a content part is not immediately preceded by document-specific metadata, then use the most recent preceding request default metadata part.
- If there is no request default metadata and no document-specific metadata, then use the system default metadata.
- Any request metadata part entirely replaces previous in-scope request metadata. For performance reasons, no merging occurs.
- A metadata category not included in the part body is either set to the system default metadata value or left unchanged, depending upon whether or not the request includes a content update. For details, see Understanding When Metadata is Preserved or Replaced.
If a request body includes both content and document-specific metadata for the same document, the metadata part must immediately precede the content part.
Each occurrence of request default metadata completely replaces any preceding request default metadata. Similarly, request default metadata and document-specific metadata are not merged. For example, if a document-specific metadata part contains only a collections setting, it inherits quality, permissions and properties from the system default metadata, not from any preceding request default metadata.
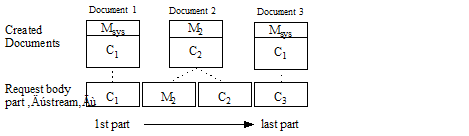
The following examples illustrate application of these rules. In these examples, Cn represents a content part for the Nth document, Mn represents document-specific metadata for the Nth document, Mdfn represents the Nth occurrence of request default metadata, and Msys is the system default metadata.
The following input creates 3 documents. Documents 1 and Document 3 use system default metadata. Document 2 uses document-specific metadata.
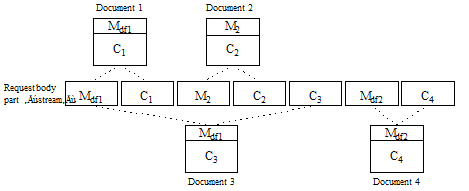
The following input creates four documents, using a combination of request default metadata and document-specific metadata. Document 1, Document 3, and Document 4 use request default metadata. Document 2 uses document-specific metadata. Document 1 and Document 3 use the first block of request default metadata, Mdf1. After Document 3 is created, Mdf2 replaces Mdf1 as the request default metadata, so Document 4 uses the metadata in Mdf2.
Understanding When Metadata is Preserved or Replaced
This topic discusses when a bulk write preserves or replaces pre-existing metadata. You can skip this section if your bulk write operations only create new documents or you do not need to preserve pre-existing metadata such as permissions, document quality, collections, and properties.
When there is no request default metadata and no document-specific metadata, all metadata categories other than properties are set to the system default values. Properties are unchanged.
In all other cases, either request default metadata or document-specific metadata is used when creating a document, as described in Understanding Metadata Scoping.
When you update both content and metadata for a document in the same bulk write request, the following rules apply, whether applying request default metadata or document-specific metadata:
- The metadata in scope is determined as described in Understanding Metadata Scoping.
- Any metadata category that has a value in the in-scope metadata completely replaces that category.
- Any metadata category other than properties that is missing or empty in the in-scope metadata is completely replaced by the system default value.
- If the in-scope metadata does not include properties, then existing properties are preserved.
- If the in-scope metadata does not include collections, then collections are reset to the default. There is no system default for collections, so this results in a document being removed from all collections if no default collections are specified for the user role performing the update.
When you include a document-specific metadata part, but no content part, you update only the metadata for a document. In this case, the following rules apply:
- Any metadata category that has a value in the document-specific metadata completely replaces that category.
- Any metadata category that is missing or empty in the document-specific metadata is preserved.
The table below shows how pre-existing metadata changes if a bulk write updates just the content, just the collections metadata (via document-specific metadata), or both content and collections metadata (via request default metadata or document-specific metadata).
The results are similar if the metadata update modifies other metadata categories.
Constructing a Metadata Part
This section describes how metadata values are applied during a bulk write and how to construct a request default or document-specific metadata part. Metadata must expressed as XML or JSON and must be specified using the syntax described in Working with Metadata.
The following topics are covered:
- Constructing a Request Default Metadata Part
- Constructing a Document-Specific Metadata Part
- Disabling Request Default Metadata
Constructing a Request Default Metadata Part
A request default metadata part applies to all documents created from the occurrence of the metadata part until the next request default metadata part or the end of the POST body, except for documents that have document-specific metadata.
A request default metadata part must use headers of the following form, where metadata-MIME-type is a MIME type that maps to XML or JSON metadata content:
Content-Type: metadata-MIME-type Content-Disposition: inline; category=metadata
For example, use following headers on a default metadata part that contains JSON metadata:
Content-Type: application/json Content-Disposition: inline; category=metadata
The part contents must be document metadata of the form described in Working with Metadata.
For a complete example, see Example: Controlling Metadata Through Defaults.
Constructing a Document-Specific Metadata Part
Document-specific metadata applies to a single document. The part must use headers of the following form, where metadata-MIME-type is a MIME type that maps to XML or JSON metadata content and document-uri is the database URI of the target document.
Content-Type: metadata-MIME-type Content-Disposition: attachment; filename=document-uri; category=metadata
If both content and metadata for the document are included in the POST request, then the document-specific metadata part must occur immediately before the content part.
If the input includes document specific metadata without an accompanying content part, the document must already exist. Only the metadata of the document changes.
Any metadata sub-category other than properties that is not included in the part body is set to the request default value, if one is in scope. Otherwise, it is set to the system default value. However, there is no system default for collections or properties. Existing properties are unchanged if not included. For collections, if the user performing the update has a role that includes default collections, then that default is used. If there are no default collections for the role, then the document is removed from all collections.
When updating permissions, you do not need to include the default rest-reader and rest-writer roles.
Any explicitly specified permissions are combined with the default permissions for the role of the current user.
For example, suppose a pre-existing document has the following customized metadata:
- document quality of 2
- membership in a collection named April 2014
- read permissions for a custom role
- a custom property named custom-prop.
That is, if you retrieve the metadata for this document using GET /version/documents, then the response contains metadata similar to the following. The metadata values that differ from the system default are shown in bold.
If you use a bulk write to update the metadata for this document, specifying only a new document quality of 1, then the permissions and collections are reset to the system default, but the custom property is preserved. Assuming out-of-the box MarkLogic Server system defaults, the updated document is no longer be in any collections, and the read permission for custom-role is removed, resulting in the following metadata:
Disabling Request Default Metadata
A request default metadata part applies until the next default request metadata part or the end of the POST body. To turn off request default metadata and revert to the system default metadata, create a request default metadata part that contains no metadata values.
In JSON, use "{}" to express empty metadata content. In XML, use a <rapi:metadata> element with no child elements.
For example, the following part erases any previous request default metadata. In the absence of additional metadata parts, documents created on behalf of subsequent parts use system default metadata.
Content-Type: application/json Content-Disposition: inline; category=metadata Content-Length: 3 { }
The following is an equivalent empty XML metadata part:
Content-Type: application/xml Content-Disposition: inline; category=metadata Content-Length: 98 <?xml version="1.0" encoding="UTF-8"?> <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"/>
For a complete example, see Example: Reverting to System Default Metadata.
Applying a Write Transformation
A content write transformation is a user-defined XQuery function or XSLT style sheet used to modify documents during insertion, as described in Working With Content Transformations.
You can apply a content transformation to all documents created by a bulk write request by making a POST request with a URL of the following form:
http://host:port/version/documents?transform=name&trans:param=value
For example, the following URL specifies a transform function named example with a value of me for the function parameter named reviewer.
http://myhost:8000/LATEST/documents?transform=example&trans:reviewer=me
Transform parameters are optional, depending on the transform interface. The same transform parameter values are applied to every document in the request.
MarkLogic Server applies the transformation prior to inserting each document into the database. Your transform can choose not to make any modifications, but it will be invoked for every document.
You cannot specify more than one transform per request. However, your transform function can import and call other transformation functions to get the same effect.
For details, see Working With Content Transformations.
Example: Controlling Metadata Through Defaults
This example creates documents that use the system default, request default, and document specific metadata, as described in Constructing a Metadata Part.
Payload Description
This example uses document quality to illustrate how default metadata affects the documents you create. The document quality setting used in this example result in creation of the following documents:
sys-default.xmlwith document quality 0, from the system default metadatareq-default.jsonwith document quality 2, from Mdf1doc-specific.xmlwith document quality 1, from M3
The following picture represents the parts in the request body and the documents created from them. In the picture, Mn represents metadata, Cn represents content. Note that the metadata is not literally embedded in the created documents; content and metadata are merely grouped here for illustrative purposes.
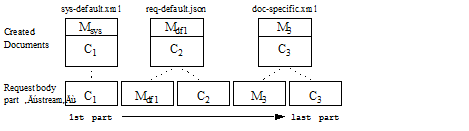
The following multipart body implements the pictured bulk write input. The annotations on the right indicate the start of each part in the graphic above. These annotations are not present in the actual POST body.
--BOUNDARY Content-Type: application/xml (C1) Content-Disposition: attachment; filename="sys-default.xml" Content-Length: 86 <?xml version="1.0" encoding="UTF-8"?> <root>a doc with system default metadata</root> --BOUNDARY Content-Type: application/json (Mdfl) Content-Disposition: inline; category=metadata Content-Length: 16 {"quality" : 2 } --BOUNDARY Content-Type: application/json (C2) Content-Disposition: attachment; filename="req-default.json" Content-Length: 45 {"key":"a doc with request default metadata"} --BOUNDARY Content-Type: application/xml (M3) Content-Disposition: attachment; filename="doc-specific.xml"; category=metadata Content-Length: 147 <?xml version="1.0" encoding="UTF-8"?> <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:quality>1</rapi:quality> </rapi:metadata> --BOUNDARY Content-Type: application/xml (C3) Content-Disposition: attachment; filename="doc-specific.xml" Content-Length: 89 <?xml version="1.0" encoding="UTF-8"?> <root>a doc with document-specific metadata</root> --BOUNDARY--
Generating the POST Body
This section contains an XQuery query you can use to generate the POST body, using the technique described in as described in Generating Example Payloads with XQuery. Skip this section if you use other tools to generate the request body.
Before running this query in Query Console, modify $OUTPUT-FILENAME for your environment:
xquery version "1.0-ml"; declare variable $OUTPUT-FILENAME := "/example/default_metadata"; declare variable $BOUNDARY := "BOUNDARY"; let $sys-default:= document{ <root>a doc with system default metadata</root> } let $req-specific := text{'{"key":"a doc with request default metadata"}' } let $doc-specific := document{ <root>a doc with document-specific metadata</root> } let $req-metadata := text { '{"quality" : 2 }'} let $sys-default-json := text { '{ "key": "a doc with system default metadata" }' } let $empty-metadata := text { '{ }' } let $doc-metadata := document { <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:quality>1</rapi:quality> </rapi:metadata> } let $manifest := <manifest> <!-- content, using system default metadata --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="sys-default.xml"</Content-Disposition> </headers> </part> <!-- Request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; category=metadata</Content-Disposition> </headers> </part> <!-- JSON document using request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="req-default.json"</Content-Disposition> </headers> </part> <!-- document specific metadata, in XML --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc-specific.xml"; category=metadata</Content-Disposition> </headers> </part> <!-- XML document with document specific metadata --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc-specific.xml"</Content-Disposition> </headers> </part> </manifest> return xdmp:save($OUTPUT-FILENAME, xdmp:multipart-encode( $BOUNDARY, $manifest, ($sys-default, $req-metadata, $req-specific, $doc-metadata, $doc-specific) ) )
Executing the Request
The following command executes the bulk write request, assuming /example/default_metadata contains the POST body. Modify the value of the --data-binary option to the file that contains your POST body.
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/default_metadata \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/documents
MarkLogic Server returns output similar to the following. For details, see Response Overview.
HTTP/1.1 200 OK Server: MarkLogic Content-Type: text/xml; charset=UTF-8 Content-Length: 656 Connection: Keep-Alive Keep-Alive: timeout=5 <?xml version="1.0"?> <rapi:documents xmlns:rapi="http://marklogic.com/rest-api"> <rapi:document> <rapi:uri>sys-default.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>req-default.json</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/json</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>doc-specific.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> </rapi:documents>
For a JSON response, set the Accept header to application/json:
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/default_metadata \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" \ -H "Accept: application/json" \ http://localhost:8000/LATEST/documents
Verifying the Results
You can retrieve the document quality for the created documents individually, or you can use the following bulk read command to retrieve the quality for all the documents in a single request. This example requests JSON metadata; you can also retrieve metadata as XML. MarkLogic Server returns a multipart/mixed response where each response body part contains the requested data for a different document. For details, see Reading Multiple Documents by URI.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/documents?category=quality&format=json&uri=sys-default.xml&uri=req-default.json&uri=doc-specific.xml' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY Server: MarkLogic Content-Length: 701 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=sys-default.xml; category=quality; format=json Content-Length: 13 {"quality":0} --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=req-default.json; category=quality; format=json Content-Length: 13 {"quality":2} --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=doc-specific.xml; category=quality; format=json Content-Length: 13 {"quality":1} --BOUNDARY--
Example: Reverting to System Default Metadata
This example demonstrates how to erase request default metadata, bringing the system default metadata back into scope in the middle of a request. This example builds on Example: Controlling Metadata Through Defaults.
Payload Description
To revert to the system default metadata, include a metadata part that contains no metadata, as described in Disabling Request Default Metadata.
This example extends the POST body from Example: Controlling Metadata Through Defaults by appending 2 parts to the payload: An empty metadata part and a 4th document, sys-default.json, that uses the system default metadata. This gives sys-default.json a document quality of 0 (the system default). All documents created after Mempty use the system default metadata in the absence of additional metadata parts.
The graphic below illustrates the parts in the request body and the documents it creates:
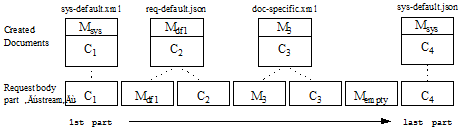
The following POST body implements the bulk write illustrated by the graphic. The annotations on the right indicate the start of each part in the graphic. These annotations are not present in the actual POST body.
--BOUNDARY Content-Type: application/xml (C1) Content-Disposition: attachment; filename="sys-default.xml" Content-Length: 86 <?xml version="1.0" encoding="UTF-8"?> <root>a doc with system default metadata</root> --BOUNDARY Content-Type: application/json (Mdfl) Content-Disposition: inline; category=metadata Content-Length: 16 {"quality" : 2 } --BOUNDARY Content-Type: application/json (C2) Content-Disposition: attachment; filename="req-default.json" Content-Length: 45 {"key":"a doc with request default metadata"} --BOUNDARY Content-Type: application/xml (M3) Content-Disposition: attachment; filename="doc-specific.xml"; category=metadata Content-Length: 147 <?xml version="1.0" encoding="UTF-8"?> <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:quality>1</rapi:quality> </rapi:metadata> --BOUNDARY Content-Type: application/xml (C3) Content-Disposition: attachment; filename="doc-specific.xml" Content-Length: 89 <?xml version="1.0" encoding="UTF-8"?> <root>a doc with document-specific metadata</root> --BOUNDARY-- Content-Type: application/json (Mempty) Content-Disposition: inline; category=metadata Content-Length: 3 { } --BOUNDARY Content-Type: application/json (C4) Content-Disposition: attachment; filename="sys-default.json" Content-Length: 53 { "key": "another doc with system default metadata" } --BOUNDARY--
Generating the POST Body
This section contains an XQuery query you can use to generate the POST body, using the technique described in as described in Generating Example Payloads with XQuery. Skip this section if you use other tools to generate the request body.
Before running this query in Query Console, modify $OUTPUT-FILENAME for your environment:
xquery version "1.0-ml"; declare variable $OUTPUT-FILENAME := "/example/reset_metadata"; declare variable $BOUNDARY := "BOUNDARY"; let $sys-default:= document{ <root>a doc with system default metadata</root> } let $req-specific := text{'{"key":"a doc with request default metadata"}' } let $doc-specific := document{ <root>a doc with document-specific metadata</root> } let $req-metadata := text { '{"quality" : 2 }'} let $sys-default-json := text { '{ "key": "a doc with system default metadata" }' } let $empty-metadata := text { '{ }' } let $doc-metadata := document { <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:quality>1</rapi:quality> </rapi:metadata> } let $manifest := <manifest> <!-- content, using system default metadata --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="sys-default.xml"</Content-Disposition> </headers> </part> <!-- Request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; category=metadata</Content-Disposition> </headers> </part> <!-- JSON document using request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="req-default.json"</Content-Disposition> </headers> </part> <!-- document specific metadata, in XML --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc-specific.xml"; category=metadata</Content-Disposition> </headers> </part> <!-- XML document with document specific metadata --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc-specific.xml"</Content-Disposition> </headers> </part> <!-- reset request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; category=metadata</Content-Disposition> </headers> </part> <!-- Content that gets the system default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="sys-default.json"</Content-Disposition> </headers> </part> </manifest> return xdmp:save($OUTPUT-FILENAME, xdmp:multipart-encode( $BOUNDARY, $manifest, ($sys-default,$req-metadata,$req-specific,$doc-metadata,$doc-specific,$empty-metadata,$sys-default-json) ) )
Executing the Request
The following command executes the bulk write request, assuming /example/reset_metadata contains the POST body. Modify the value of the --data-binary option to refer to the path to the file containing your POST body.
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/reset_metadata \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" http://localhost:8000/LATEST/documents
MarkLogic Server returns output similar to the following. For details, see Response Overview.
<?xml version="1.0"?> <rapi:documents xmlns:rapi="http://marklogic.com/rest-api"> <rapi:document> <rapi:uri>sys-default.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>req-default.json</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/json</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>doc-specific.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>sys-default.json</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/json</rapi:mime-type> </rapi:document> </rapi:documents>
For a JSON response, set the Accept header to application/json:
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/reset_metadata \ -H "Accept: application/json" \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" http://localhost:8000/LATEST/documents
Verifying the Results
Use the following command to retrieve the document quality for the inserted documents. Notice that req-default.json uses the request default document quality of 2, but sys-default.json, which is created after resetting the request default metadata, has the default document quality, zero.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/documents?category=quality&format=json&uri=req-default.json&uri=sys-default.json' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY Server: MarkLogic Content-Length: 327 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=req-default.json; category=quality; format=json Content-Length: 13 {"quality":2} --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=sys-default.json; category=quality; format=json Content-Length: 13 {"quality":0} --BOUNDARY--
Example: Adding Documents to a Collection
This example demonstrates using request default metadata to add all documents to the same collection during insertion.
You can add selected documents to a different collection using document-specific metadata or by including an additional request default metadata part that uses a different collection; see Example: Controlling Metadata Through Defaults.
Since the metadata in the example request only includes settings for collections metadata, other metadata categories such as permissions and quality use the system default settings. For an example of more complex metadata, see Extending the Example.
For more information on metadata syntax, see Working with Metadata.
- Payload Description
- Generating the POST Body
- Executing the Request
- Verifying the Results
- Extending the Example
Payload Description
The payload contains 3 parts: A metadata part that specifies a collection and JSON and XML content parts for documents that are placed into that collection. The documents are added to the collection April 2014. The metadata is expressed as JSON. Both documents use server-assigned URIs.

To use XML metadata instead of JSON, modify the Content-Type of the first part to application/xml and change the part contents to the following:
<rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:collections> <rapi:collection>April 2014</rapi:collection> </rapi:collections> </rapi:metadata>
Generating the POST Body
This section contains an XQuery query you can use to generate the POST body, using the technique described in as described in Generating Example Payloads with XQuery. Skip this section if you use other tools to generate the request body.
Before running this query in Query Console, modify $OUTPUT-FILENAME for your environment:
xquery version "1.0-ml"; declare variable $OUTPUT-FILENAME := "/example/coll-body"; declare variable $BOUNDARY := "BOUNDARY"; let $xml-content := document{ <root>some content</root> } let $metadata := text { '{"collections" : ["April 2014"] }'} let $json-content := text { '{ "key": "value" }' } let $manifest := <manifest> <!-- Request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; category=metadata</Content-Disposition> </headers> </part> <!-- JSON document --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; extension=json; directory=/example/</Content-Disposition> </headers> </part> <!-- XML document --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>inline; extension=xml; directory=/example/</Content-Disposition> </headers> </part> </manifest> return xdmp:save($OUTPUT-FILENAME, xdmp:multipart-encode( $BOUNDARY, $manifest, ($metadata,$json-content,$xml-content) ) )
To use XML metadata instead of JSON metadata, replace the value of $metadata with the following declaration and change the Content-Type header for the first part to application/xml.
<rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:collections> <rapi:collection>April 2014</rapi:collection> </rapi:collections> </rapi:metadata>
Executing the Request
Use the following command to create the two documents. MarkLogic Server responds with status code 200 OK and includes the documents URIs and additional information about the created documents in the response body, as XML.
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/coll-body \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/documents ... HTTP/1.1 200 OK Server: MarkLogic Content-Type: text/xml; charset=UTF-8 Content-Length: 498 Connection: Keep-Alive Keep-Alive: timeout=5 <?xml version="1.0"?> <rapi:documents xmlns:rapi="http://marklogic.com/rest-api"> <rapi:document> <rapi:uri>/example/11572018736249878991.json</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/json</rapi:mime-type> </rapi:document> <rapi:document> <rapi:uri>/example/5255172137182404803.xml</rapi:uri> <rapi:category>metadata</rapi:category> <rapi:category>content</rapi:category> <rapi:mime-type>application/xml</rapi:mime-type> </rapi:document> </rapi:documents>
To get JSON results, set the Accept header to application/json or use the format=json request parameter. The following is an example of the equivalent JSON response data:
{ "documents": [ { "uri": "/example/11572018736249878991.json", "mime-type": "application/json", "category": [ "metadata", "content" ] }, { "uri": "/example/5255172137182404803.xml", "mime-type": "application/xml", "category": [ "metadata", "content" ] } ] }
For details, see Response Overview.
Verifying the Results
You can use the following combined query with the /search service to verify the documents added to the April 2014 collection, or use the Explore feature of Query Console to examine the database contents. For more information, see Specifying Dynamic Query Options with Combined Query or the Query Console User Guide.
$ cat coll-query.xml
<search xmlns="http://marklogic.com/appservices/search">
<query>
<collection-query>
<uri>April 2014</uri>
</collection-query>
</query>
<options>
<transform-results apply="empty-snippet" />
<return-metrics>false</return-metrics>
</options>
</search>
$ curl --anyauth --user user:password -X POST -i \
-H "Content-type: application/xml"
-H "Accept: application/xml" -d @./coll-query.xml \
http://localhost:8000/LATEST/searchYou should get output similar to the following. The search results contain a match for the two documents previously created.
Extending the Example
You can include more than one category of metadata in a metadata part. For example, if you change the metadata part contents in this example to the following, then the created documents are readable by users with the readers role and have the user-defined source property, as well as being in the April 2014 collection.
For more details about working with metadata using the REST API, see the following topics:
Generating Example Payloads with XQuery
This section describes how to generate a multipart/mixed payload using XQuery and QueryConsole. Each bulk write example includes a suitable XQuery query for generating its payload. If your development environment includes other HTTP client tools or libraries for payload generation, you can use those instead.
A multipart payload must contain CRLF control characters in specific places. For details, see RFC 1341, available at the following URL:
http://www.w3.org/Protocols/rfc1341/7_2_Multipart.html
Cutting and pasting text from the documentation will not preserve these control characters. Editing a multipart body with many text editors also corrupts the control characters. Therefore, it is best to generate the example multipart bodies programmatically.
The procedure below uses xdmp:multipart-encode to create a multipart payload and xdmp:save to save the result to a file you can use as input to the curl command.
The xdmp:multipart-encode builtin function accepts a manifest and a sequence of nodes as input. The nodes are the part contents. The manifest contains the headers for each part. The calling sequence is:
xdmp:multpart-encode($part-boundary, $manifest, $part-contents)
The manifest must contain a <part/> element for each content part in the $part-contents sequence, in the same order as the content parts. See the example below.
Follow this procedure to write a multipart/mixed payload to a file. If you are not familiar with Query Console, see the Query Console User Guide.
- Open Query Console. For example, navigate to the following URL in your browser:
http://yourhost:8000/qconsole
- Create a new query by clicking on the + symbol at the top of the query editor.
- Replace the default query contents with a body generation query. For example, replace the default query contents with the following query that generates 4 parts: JSON metadata, JSON content, XML metadata, and XML content.
xquery version "1.0-ml"; declare variable $OUTPUT-FILENAME := "/example/bulk-write-body"; declare variable $BOUNDARY := "BOUNDARY"; let $json-metadata1 := text { '{"quality" : 2 }'} let $json-doc1 := text { '{ "key": "some json content" }' } let $xml-metadata2 := document { <rapi:metadata xmlns:rapi="http://marklogic.com/rest-api"> <rapi:quality>1</rapi:quality> </rapi:metadata> } let $xml-doc2 := document{ <root>some xml content</root> } let $manifest := <manifest> <!-- JSON request default metadata --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>inline; category=metadata</Content-Disposition> </headers> </part> <!-- JSON document --> <part> <headers> <Content-Type>application/json</Content-Type> <Content-Disposition>attachment; filename="doc1.json"</Content-Disposition> </headers> </part> <!-- XML document-specific metadata --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc2.xml"; category=metadata</Content-Disposition> </headers> </part> <!-- XML content --> <part> <headers> <Content-Type>application/xml</Content-Type> <Content-Disposition>attachment; filename="doc2.xml"</Content-Disposition> </headers> </part> </manifest> return xdmp:save($OUTPUT-FILENAME, xdmp:multipart-encode( $BOUNDARY, $manifest, ($json-metadata1,$json-doc1,$xml-metadata2,$xml-doc2) ) )
- Change the
$OUTPUT-FILENAMEvariable value to the full path where you want the payload to be saved. This directory must be writable by MarkLogic Server. - Click the Run button just below the query editor. The payload is saved to
$OUTPUT-FILENAME.
If the output file is not created properly, check that the destination directory permissions permit MarkLogic Server to write a file to that location.
Depending on the editor you use, editing the saved file with a text editor can corrupt the payload by removing or converting the CRLF characters. Avoid editing the payload file unless you know your editor will preserve the CRLFs.
You can use the resulting output as input to the curl command using the --data-binary option. Use the same part boundary marker in your curl command that you used as the first parameter to xdmp:http-encode in the generation query.
For example, assuming you save the query output to /example/bulk-write-body, then the following command uses it as input to a bulk write request:
$ curl --anyauth --user user:password -X POST -i \ --data-binary @/example/bulk-write-body \ -H "Content-type: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/documents
Reading Multiple Documents by URI
You can retrieve multiple documents by URI in a single request by sending a GET request to the /documents service with multiple uri parameters and an Accept header of multipart/mixed. The URL should be of the following form:
http://host:port/version/documents?uri=uri-1&uri=uri-2&...
For example, the following command retrieves content for two documents, aardvark.xml and camel.xml:
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/documents?uri=aardvark.xml&uri=camel.xml'
MarkLogic Server returns a multipart/mixed response, with each part containing a requested document or its metadata. For details, see Bulk Read Response Overview.
The available request options are the same ones available when retrieving a single document and/or its metadata. For example:
- Use the
categoryparameter to retrieve content, metadata (all or a subset), or both. For details, see Retrieving Documents from the Database. - Use the
formatparameter to request metadata as either XML or JSON. - Use the
transformparameter to apply a read transform. For details, see Transforming Content During Retrieval.Applying a transform creates an additional in-memory copy of each document, rather than streaming each document directly out of the database, so memory consumption is higher.
If you read both metadata and content for JSON documents, you should set format explicitly. Otherwise, the metadata format will vary depending upon whether your request includes one or multiple URIs.
For more details, see GET:/v1/documents in the MarkLogic REST API Reference.
Reading Multiple Documents Matching a Query
You can retrieve all documents that match a query by sending a GET or POST request to the /search or /qbe service with an Accept header value of multipart/mixed. You can retrieve content, metadata, or a combination of content and metadata for all matching documents.
- Overview of Bulk Read By Query
- Example: Using Query By Example (QBE)
- Example: Using a String, Structured, or Combined Query
- Extracting a Portion of Each Matching Document
- Including Search Results in the Response
- Paginating Results
Overview of Bulk Read By Query
To retrieve all documents from the database that match a query, use one of the following request methods, with the Accept header set to multipart/mixed:
For example, the following command uses a string query to retrieve all documents containing the word bird:
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/search?q=bird
MarkLogic Server returns a multipart/mixed response, with each part containing a matching document or its metadata. For details, see Bulk Read Response Overview.
For a more complete example, see Example: Using a String, Structured, or Combined Query.
Using a query to retrieve documents is the same as using /search and /qbe for a normal search, with the following exceptions:
- The Accept header must be
multipart/mixed. This distinguishes your request from a normal search operation. - No search response is included by default, but you can still request inclusion. For details, see Including Search Results in the Response.
- If you include a
transformrequest parameter, the transform function is called on the returned documents and the search response but not on metadata. The transform must therefore be prepared to handle multiple kinds of input. - Use the
categoryparameter to specify the document data you want to retrieve: Content, metadata, or a metadata subset. You can retrieve a combination of these; for details, see Bulk Read Response Overview. - Since a search response is not returned by default, the page range in the response is returned in vendor-specific response headers. For details, see Paginating Results.
- If there are no matches to the query, MarkLogic Server responds with status code 200 (OK) and an empty response body.
As with a normal search operation, you can include query options either by pre-installing them and naming them in the options request parameter, or by including them in a combined query in the POST body.
You can use a structured or combined query with the /search service to express complex queries. You can supply a structured query through the structuredQuery parameter on a GET request or in the body of a POST request. You can only supply a combined query in a POST request body.
See the following topics for more information on the query interfaces available through the REST API:
Example: Using Query By Example (QBE)
This example demonstrates using a QBE to retrieve documents from the database using the /qbe service. You should be familiar with the basic /qbe REST API; for details, see Using Query By Example to Prototype a Query.
The following QBE matches documents with a kind XML element or JSON property with the value bird:
| Format | Query |
|---|---|
| XML | <q:qbe xmlns:q="http://marklogic.com/appservices/querybyexample"> <q:query> <kind>bird</kind> </q:query> </q:qbe> |
| JSON | { "$query": { "kind": "bird" } } |
The following command uses the above query to retrieve all matching documents. Since the request does not include any category parameters, only document content is returned, one document per part. The number of documents matching the input query is returned in the vnd.marklogic.result-estimate response header. This number is equivalent to @total on a search response. The document URI, document type, and part contents are returned in the Content-Disposition header; for details, see Bulk Read Response Overview.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X POST -d @query.xml -i \ -H "Content-type: application/xml" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/qbe' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 1 vnd.marklogic.pageLength: 10 vnd.marklogic.result-estimate: 6 Server: MarkLogic Content-Length: 4222 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: application/xml Content-Disposition: attachment; filename=/animals/vulture.xml; category=content; format=xml ...
To make the equivalent request using a JSON QBE, change the Content-Type header to application/json. Note that the format of a QBE (XML or JSON) can affect the kinds of documents that match the query. For details, see Scoping a Search by Document Type in the Search Developer's Guide.
To return metadata as JSON rather than XML, use the format request parameter. For example, the following command returns document quality expressed as JSON:
$ curl --anyauth --user user:password -X POST -d @query.xml -i \ -H "Content-type: application/xml" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/qbe?category=quality&format=json' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 1 vnd.marklogic.pageLength: 10 vnd.marklogic.result-estimate: 6 Server: MarkLogic Content-Length: 4222 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: application/json Content-Disposition: attachment; filename=/animals/vulture.xml; category=quality; format=json ...
If you use a GET request rather than a POST, you must URL-encode the query parameter value. For example, the following query uses the URL-encoded representation of the JSON query: { "$query": { "kind": "bird" } }.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/qbe?query=%7B%20%22%24query%22%3A%20%7B%20%22kind%22%3A%20%22bird%22%20%7D%20%7D'
Use the options request parameter to include persistent query options in your request. Use the transform parameter to apply a read transform. For example:
$ curl --anyauth --user user:password -X POST -d @query.json -i \ -H "Content-type: application/json" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/qbe?options=my-options&transform=my-enrichment
Example: Using a String, Structured, or Combined Query
This example demonstrates using a string, structured, or combined query to retrieve documents from the database using the /search service. The basic method is the same, no matter what query format you choose. You should be familiar with the basic /search REST API; for details, see Querying Documents and Metadata.
The following command uses a simple string query supplied through the q request parameter to retrieve all documents that contain bird. Since the request does not include any category parameters, only document content is returned, one document per part. The number of documents matching the input query is returned in the vnd.marklogic.result-estimate response header. This number is equivalent to @total on a search response. The document URI, document type, and part contents are returned in the Content-Disposition header; for details, see Bulk Read Response Overview.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/search?q=bird ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 1 vnd.marklogic.pageLength: 10 vnd.marklogic.result-estimate: 6 Server: MarkLogic Content-Length: 1476 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: text/xml Content-Disposition: attachment; filename=/animals/vulture.xml; category=content; format=xml Content-Length: 93 <?xml version="1.0" encoding="UTF-8"?> <animal><name>vulture</name><kind>bird</kind></animal> ...
To retrieve both documents and metadata, use the category parameter. The following example retrieves the document contents and the quality metadata. The response contains 2 parts for each matching document: A metadata part, immediately followed by the corresponding content part.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/search?q=bird&category=content&category=quality' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 1 vnd.marklogic.pageLength: 10 vnd.marklogic.result-estimate: 6 Server: MarkLogic Content-Length: 4222 Connection: Keep-Alive Keep-Alive: timeout=5 --BOUNDARY Content-Type: application/xml Content-Disposition: attachment; filename=/animals/vulture.xml; category=quality; format=xml Content-Length: 299 ?xml version="1.0" encoding="UTF-8"?> <rapi:metadata uri="/animals/vulture.xml" ...> <rapi:quality>0</rapi:quality> </rapi:metadata> --BOUNDARY Content-Type: text/xml Content-Disposition: attachment; filename=/animals/vulture.xml; category=content; format=xml Content-Length: 93 ...
To return the metadata as JSON rather than XML, add format=json to the request:
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/search?q=bird&category=content&category=quality&format=json'
You can supply a structured query through the structuredQuery parameter on a GET request or in the body of a POST request. You can only supply a combined query in a POST request body. For example, assuming query.json contains a structured or combined query, the following command retrieves metadata for documents containing bird.
$ curl --anyauth --user user:password -X POST -d @./query.json -i -H "Content-Type: application/xml" \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/search?category=metadata&format=json'
Use the options request parameter to include persistent query options in your request. Use the transform parameter to apply a read transform. For example:
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ http://localhost:8000/LATEST/search?q=bird&options=my-options&transform=my-enrichment
Extracting a Portion of Each Matching Document
You can use the extract-document-data query option to return selected portions of each matching document instead of the whole document.
For example, the following combined query specifies that the search should only return the portions of matching documents that match the path /parent/body/target.
<search xmlns="http://marklogic.com/appservices/search"> <qtext>content</qtext> <options xmlns="http://marklogic.com/appservices/search"> <extract-document-data selected="include"> <extract-path>/parent/body/target</extract-path> </extract-document-data> <return-results>false</return-results> </options> </search>
If one of the matching documents contains the following data:
{"parent": { "a": "foo", "body": { "target":"content" }, "b": "bar"} }
Then the search returns the following sparse projection for this document:
{ "context":"fn:doc(\"/extract/doc2.json\")", "extracted":[{"target":"content"}] }
For details, see Extracting a Portion of Matching Documents in the Search Developer's Guide.
If you use extract-document-data with a simple search, rather than a multi-document read, the sparse projections are embedded in the search response instead of returned as individual documents. That is, you get projected documents when the Accept header is multipart/mixed and embedded projections when the Accept header is application/xml or application/json.
Including Search Results in the Response
By default, no search response is included in the request response when you perform a bulk read based on a query. To return search results in addition to matching documents or metadata, set the view request parameter.
For the complete set of values accepted by the view parameter, see GET:/v1/search in the MarkLogic REST API Reference.
The search response is returned as XML by default. You can request a JSON search response by setting the format request parameter to json. If you request a JSON search response, your input query must also be JSON if it is not a string query. The format parameter also controls the format of returned metadata.
For example, the following command returns a search response, plus the documents matching the query:
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/search?q=bird&view=results' ... HTTP/1.1 200 OK ... --BOUNDARY Content-Type: application/xml Content-Disposition: inline Content-Length: 3177 <?xml version="1.0" encoding="UTF-8"?> <search:response snippet-format="snippet" total="6" ...> ... </search:response> --BOUNDARY Content-Type: text/xml Content-Disposition: attachment; filename=/animals/vulture.xml; category=content; format=xml Content-Length: 93 <?xml version="1.0" encoding="UTF-8"?> <animal><name>vulture</name><kind>bird</kind></animal> ...
Paginating Results
As with a normal search operation, you can use the start and pageLength request parameters to retrieve results in batches. Use start to specify the index of the first result to return and pageLength to control the number results to return.
By default, queries return the first 10 matches. That is, the default start position is 1 and the default page length is 10. You can fetch successive results by incrementing the start position by the page length in each call.
In a normal search operation, the page range included in the response body is returned via the start and page-length attributes (or JSON properties) on the search response. Since a bulk read via query does not necessarily include a search response, the page range is returned in the vendor-specific response headers vnd.marklogic.start and vnd.marklogic.pageLength. If a search response is returned by your request, the start and page-length value in the search response match the header values.
Similarly, an estimate of the total number of matches is returned in the vendor-specific header vnd.marklogic.result-estimate. This is equivalent to the total value in a search response. As with any search, the actual number of matches might be different, depending upon whether you use filtered or unfiltered search.
For more information, see the Search Developer's Guide and Fast Pagination and Unfiltered Searches in the Scalability, Availability, and Failover Guide.
The following example command fetches the first 5 documents containing bird. Notice that the response includes page range details in the vnd.marklogic.* headers.
# Windows users, see Modifying the Example Commands for Windows $ curl --anyauth --user user:password -X GET \ 'http://localhost:8000/LATEST/search?q=castle&start=1&pageLength=5' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 1 vnd.marklogic.pageLength: 5 vnd.marklogic.result-estimate: 16 Server: MarkLogic Content-Length: 1225 Connection: Keep-Alive Keep-Alive: timeout=5 ...
To fetch the next set of matching documents, increment start by pageLength (5):
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/search?q=bird&start=6&pageLength=5' ... HTTP/1.1 200 OK Content-type: multipart/mixed; boundary=BOUNDARY vnd.marklogic.start: 6 vnd.marklogic.pageLength: 5 vnd.marklogic.result-estimate: 16 Server: MarkLogic Content-Length: 1225 Connection: Keep-Alive Keep-Alive: timeout=5 ...
When the page length returned in vnd.marklogic.pageLength is less than the request pageLength, no more matching documents are available.
Bulk Read Response Overview
When you retrieve multiple documents in a single request using a list of URIs or a query, the results are returned in a multipart/mixed response that contains a part for each returned document or document metadata.
If you request both content and metadata, the content and metadata are returned in separate parts, with the metadata part immediately preceding the content part. If you request multiple metadata sub-categories, such as quality and permissions, then each metadata part contains all the requested subcategory values. The diagram below illustrates the response part stream for a request the returns both content and metadata.

When you retrieve multiple documents using a query, the response can also include the search response as the first part; for details, see Including Search Results in the Response.
The part Content-Type header contains the MIME type of the data in the part body. The Content-Type of a part is determined as follows:
- For a content part, the MIME type is determined by the MarkLogic Server MIME type mapping corresponding to the document URI extension. To review or change the MIME type mapping, see the Mimetypes subsection of the Groups section of the Admin Interface.
- For a metadata part, the MIME type is always
application/xmlorapplication/json. The default format is XML. Use theformatrequest parameter to control the metadata MIME type. - If a search response is included in the response, its MIME type is XML unless you use the
format=jsonrequest parameter. For details, see Including Search Results in the Response.
The Content-Disposition header contains the source document URI, the kind of data in the part, and format of the data. The Content-Disposition header for a part has the following form:
Content-Disposition: attachment;filename=doc-uri; category=data-category;...format=data-format
Where doc-uri is the database URI of the document from which the content or metadata in the part was extracted, and data-category is either content, metadata, or a specific metadata sub-category such as permissions or quality. For metadata, format is always xml or json. For content, format corresponds to the database document type: xml, json, text, or binary.
If optimistic locking or content versioning is enabled, the Content-Disposition header for a content part also contains a document version id of the form versionId=id; for details, see Using Optimistic Locking to Update Documents.
For example, the following bulk read request retrieves content, permissions, and document quality, so a content and a metadata part is returned for each document. The Content-Disposition header for each metadata part includes both category=permissions and category=quality.
$ curl --anyauth --user user:password -X GET -i \ -H "Accept: multipart/mixed; boundary=BOUNDARY" \ 'http://localhost:8000/LATEST/documents?category=content&category=permissions&category=quality&uri=...' --BOUNDARY Content-Type: application/xml Content-Disposition: attachment; filename=...; category=permissions; category=quality; format=xml ... --BOUNDARY Content-Type: text/xml Content-Disposition: attachment; filename=...; category=content; format=xml ...
The table below contains additional examples of returned part headers.