
MarkLogic Server 11.0 Product Documentationmlcp User Guide — Chapter 2
Installation and Configuration
This chapter describes how to install mlcp and configure your client environment and MarkLogic for most effective use of the tool. The following topics are included:
- Supported Platforms
- Required Software
- Installing mlcp
- Configuring Your MarkLogic Cluster
- Security Considerations
- Connecting to MarkLogic Using SSL
- Using mlcp With Kerberos
Supported Platforms
In local mode, mlcp is supported on the same platforms as MarkLogic Server, including 64-bit Linux, 64-bit Windows, and Macintosh OS X. For details, see Supported Platforms in the Installation Guide.
Installing mlcp
After downloading mlcp, follow these instructions to install mlcp.
- Download mlcp from http://developer.marklogic.com/products/mlcp.
- Unpack the mlcp distribution to a location of your choice. This creates a directory named
mlcp-version, where version is the mlcp version. For example, assuming/space/marklogiccontains zip file for mlcp version 1.3, then the following commands install mlcp under/space/marklogic/mlcp-1.3/:$ cd /space/marklogic $ unzip mlcp-1.3-bin.zip
- Optionally, put the mlcp bin directory on your path. For example:
$ export PATH=${PATH}:/space/marklogic/
mlcp-1.3/bin - Put the
javacommand on your path. For example:$ export PATH=${PATH}:$JAVA_HOME/bin
You might need to configure your MarkLogic cluster before using mlcp for the first time. For details, see Configuring Your MarkLogic Cluster.
On Windows, use the mlcp.bat command to run mlcp. On UNIX and Linux, use the mlcp.sh command. You should not use mlcp.sh in the Cygwin shell environment on Windows.
Configuring Your MarkLogic Cluster
The mlcp tool uses an XDBC App Server to communicate with each host in a MarkLogic Server cluster that has at least one forest attached to a database used in your mlcp job. Optionally, you can configure the mlcp tool to connect to a load balancer that sits in front of the MarkLogic Server cluster. When configured to use a load balancer, the mlcp tool communicates with the load balancer to reach the forests. The load balancer can communicate with hosts that are evaluator nodes, data nodes, or both. For details, see Controlling How mlcp Connects to MarkLogic.
When you use mlcp with MarkLogic 8 or later on the default port (8000), no special cluster configuration is necessary. Port 8000 includes a pre-configured XDBC App Server. The default database associated with port 8000 is the Documents database. To use mlcp with a different database and port 8000, use the -database, -input_database, or -output_database options. For example:
mlcp.sh import -host myhost -port 8000 -database mydatabase ...
When using MarkLogic 8 or later with a port other than 8000, the port should connect to either an XDBC App Server or an App Server with a rewriter that is set up to handle XDBC traffic.
Hosts within a group share the same App Server configuration, but hosts in different groups do not. Therefore, if all your forest hosts are in a single group, you only need to configure one App Server to handle XDBC traffic. If your forests are on hosts in multiple groups, then you must configure an App Server for XDBC that listens on the same port in each group.
For example, the cluster shown below is properly configured to use Database A as an mlcp input or output source. Database A has 3 forests, located on 3 hosts in 2 different groups. Therefore, both Group 1 and Group 2 must make Database A accessible via XDBC on port 9001.
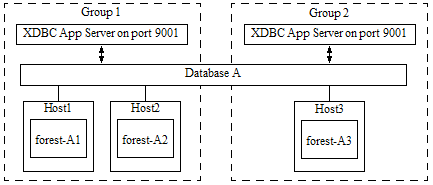
If the forests of Database A are only located on Host1 and Host2, which are in the same group, then you would only need to configure one XDBC App Server on port 9001.
If you use MarkLogic 8 or later and port 8000 instead of port 9001, then you do not need to explicitly create any XDBC App Servers to support the above database configuration because both group automatically have an XDBC App Server on port 8000. You might need to explicitly specify the database name (Database A) in your mlcp command, though, if it is not the default database associated with port 8000.
Security Considerations
When you use mlcp, you supply the name of a user(s) with which to interact with MarkLogic Server. If the user does not have admin privileges, then the user must have at least the privileges listed in the table below.
Additional privileges may be required. These roles only enable use of MarkLogic Server as a data source or destination. For example, these roles do not grant read or update permissions to the database.
By default, mlcp requires a username and password to be included in the command line options for each job. You can avoid passing a cleartext password between your mlcp client host and MarkLogic Server by using Kerberos for authentication. For details, see Using mlcp With Kerberos.
Connecting to MarkLogic Using SSL
When you connect to a MarkLogic App Server with mlcp, you can use an SSL-enabled connection to secure the communications. This applies to the import, export, and copy mlcp commands.
Enabling SSL on Your App Server
You can only use SSL to connect to MarkLogic through an SSL-enabled App Server. For more details, see Configuring SSL on App Servers in the Security Guide.
If you want to use SSL with both the source (input) and destination (output) App Servers during an mlcp copy job, both App Servers must be SSL enabled.
Configuring mlcp to Use SSL
By default, mlcp does not connect to MarkLogic using SSL. Use one of the following options to specify that mlcp should connect via SSL:
| mlcp Command | Command Line Option | For more information |
|---|---|---|
| import | -ssl |
Import Command Line Options |
| export | -ssl |
Export Command Line Options |
| copy | -input_ssl and/or -output_ssl |
Copy Command Line Options |
All these options accept a boolean argument value. As described in Command Line Summary, true is assumed if you leave the argument off.
If you have disabled the default SSL protocol on your App Server, you must also use one of the following options to explicitly specify the SSL protocol that mlcp should use when connecting to MarkLogic:
| mlcp Command | Command Line Option | For more information |
|---|---|---|
| import | -ssl_protocol |
Import Command Line Options |
| export | -ssl_protocol |
Export Command Line Options |
| copy | -input_ssl_protocol and/or -output_ssl_protocol |
Copy Command Line Options |
The above SSL protocol options are ignored in some cases when you use the SSL configuration technique describe in Using mlcp With Kerberos.
Using mlcp With Kerberos
You can use mlcp in local mode with Kerberos to avoid sending cleartext passwords between your mlcp client host and MarkLogic Server.
Before you can use Kerberos with mlcp, you must configure your MarkLogic installation to enable external security, as described in External Security in the Security Guide.
If external security is not already configured, you will need to perform at least the following procedures:
- Create a Kerberos external security configuration object. For details, see Creating an External Authentication Configuration Object in the Security Guide.
- Create a Kerberos keytab file and install it in your MarkLogic installation. For details, see Creating a Kerberos keytab File in the Security Guide.
- Create one or more users associated with an external name. For details, see Assigning an External Name to a User in the Security Guide.
- Configure your XDBC App Server to use kerberos-ticket authentication. For details, see Configuring an App Server for External Authentication in the Security Guide.
The following topics touch on additional details specific to mlcp.
Creating Users
Before you can use Kerberos for authentication, you must create at least one MarkLogic user with which mlcp can use Kerberos authentication to connect to MarkLogic Server, as described in Assigning an External Name to a User in the Security Guide.
This user must also be assigned roles and privileges required to enable your mlcp operations.
For example, if you're using mlcp to import documents into a database, then the user must have update privileges on the target database, as well as the minimum privileges required by mlcp. For details on the minimum privileges required by mlcp, see Security Considerations.
Configuring an XDBC App Server for Kerberos Authentication
The mlcp tool communicates with MarkLogic through an XDBC App Server. Configure your XDBC App Server to use Kerberos for external security, as described in Configuring an App Server for External Authentication in the Security Guide.
Configure your XDBC App Server to use kerberos-ticket authentication.
For example, if you create a configuration named kerb-conf, then configure your XDBC App Server with the following values for the authentication, internal security, and external security configuration settings in the Admin Interface:

You can use an existing XDBC App Server or create a new one. To create a new XDBC App Server, use the Admin Interface, the Admin API, or the REST Management API. For details, see Procedures for Creating and Managing XDBC Servers in the Administrator's Guide.
Configure the App Server to use kerberos-ticket authentication and the Kerberos external security configuration object you created following the instructions in Creating an External Authentication Configuration Object in the Security Guide.
When you install MarkLogic, an XDBC App Server and other services are available port 8000. Changing the security configuration for the App Server on port 8000 affects all the MarkLogic services available through this port, including the HTTP App Server and REST Client API instance.
Invoking mlcp
Once you configure your XDBC App Server and user for Kerberos external security, then you can do the following to use Kerberos authentication with mlcp:
- Use
kinitor a similar program on your mlcp client host to create and cache a Kerberos Ticket to Get Tickets (TGT) for a principal you assigned to a MarkLogic user. - Invoke mlcp with no
-usernameand no-passwordoption from the environment in which you cached the TGT.
For example, suppose you configured an XDBC App Server on port 9010 of host ml-host to use kerberos-ticket authentication. Further, suppose you associated the Kerberos principal name kuser with the user mluser. Then the following commands result in mlcp authenticating with Kerberos as user kuser, and importing documents into the database as mluser.
kinit kuser ... mlcp.sh import -host ml-host -port 9010 -input_file_path src_dir
You do not necessarily need to run kinit every time you invoke mlcp. The cached TGT typically has a lifetime over which it is valid.