
MarkLogic Server 11.0 Product DocumentationContent Processing Framework Guide — Chapter 4
Understanding and Using Pipelines
This chapter describes pipelines in the MarkLogic Server Content Processing Framework, and includes the following sections:
- Pipeline Architecture
- Viewing Pipelines in the Admin Interface
- Loading Pipelines With the Admin Interface
- XML Format of a Pipeline
- XQuery Functions to Manage Pipelines
Pipeline Architecture
A core component of the Content Processing Framework is the pipeline. A pipeline is an XML document that defines document states as a document moves through stages of content processing. In addition to defining document states, a pipeline specifies actions that occur under certain conditions. A condition is an XQuery module or an XSLT stylesheet that evaluates to true or false. An action is an XQuery module or an XSLT stylesheet that is called when the condition associated with an action is either true or if there is no condition.
This section includes the following topics about pipelines:
- Automatic Status (Event) Handling
- Transitioning Between States
- Pipelines Can Flow Through Other Pipelines
Automatic Status (Event) Handling
Robust content processing applications must be able to gracefully move documents in and out of active processing, and they must be able to cleanly recover from failures. Common reasons to move a document in or out of active processing are when a document is first created or when it changes, for example upon a create, update, or delete event. When you want the result of these changes to move a document in or out of document processing, it is known as a status change.
When a document that is in a content processing domain is created, updated, or deleted, the Content Processing Framework automatically handles the document status change events (create, update, and delete) and sets a state (or cleans up in the case of delete) for the document. This has the effect of activating content processing for that document. Similarly, if there is a failure that causes the system to go down, the content processing must recover gracefully. The Status Change Handling pipeline, installed when you install content processing in a database, performs these tasks automatically.
Transitioning Between States
You attach pipelines to domains, and the domains determine the documents on which a pipeline acts. The pipeline then facilitates the transitioning of the document from one state to another, calling XQuery modules to perform the content processing between states. The following figure shows how a simplified pipeline can move a document from one state to another.
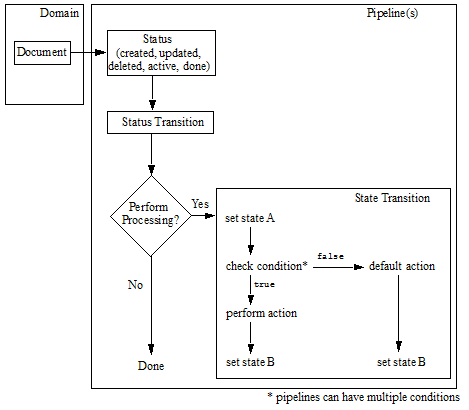
While setting a state on a document is a common outcome of a status transition or a state transition, it is not a requirement.
Pipelines Can Flow Through Other Pipelines
All of your content processing states need not be defined by a single pipeline; document processing can flow from one pipeline to another. The following figure shows how states can flow in and out of different pipelines.
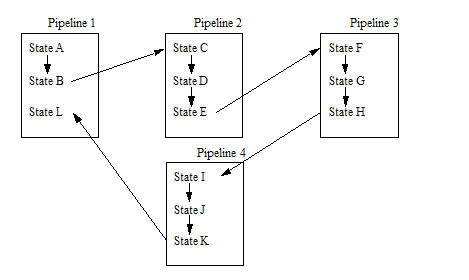
Having the processing flow through multiple pipelines allows for flexibility and modularity in the way you design your pipelines. For example, you might have a pipeline that defines states that are common to several kinds of processing. Factoring out the common processing stages into a separate pipeline allows you to have different pipelines transition into a common pipeline used by multiple applications. There is enough flexibility to set up your pipelines to be very simple or very complex.
Viewing Pipelines in the Admin Interface
You can use the Admin Interface to view pipelines already loaded in a database. To view an existing pipeline, navigate to Databases > database_name > Content Processing > Pipelines > pipeline_name in the Admin Interface tree menu. The Admin Interface displays the following information for each pipeline:
The URI paths to XQuery modules in a pipeline are relative to the module root specified in the domain to which the pipeline is attached. You should load the XQuery modules into the specified database as a stored module, with execute permissions for users that need to run it. It is also possible to reference modules stored in the modules directory on the filesystem, but MarkLogic recommends loading your modules under the database root specified in the domain.
Loading Pipelines With the Admin Interface
You can use the Admin Interface to load XML files into the database as pipelines. Pipelines are stored in the triggers database, therefore any pipelines you load for a given database through the Admin Interface are loaded into the triggers database for that database. Note the following about loading pipelines:
- If there is no triggers database configured, then an error will occur when you try to load the pipeline.
- Pipeline names must be unique.
- If you load a pipeline with the same name as an existing pipeline, the new pipeline definition will replace the old one.
Perform the following steps to load a pipeline into the database:
- Create a valid pipeline XML document and save it to a filesystem accessible from the machine on which the Admin Interface is running. For details on the XML format of a pipeline, see XML Format of a Pipeline.
- In the Admin Interface menu, click the Databases link and then click the name of the database to which you want to load a pipeline.
- Under the database name, click Content Processing.
- If content processing is already installed for your database, you will see links for Domains and Pipelines. Click Pipelines.
If content processing is not installed, install it as described in Install Content Processing Framework in Database.
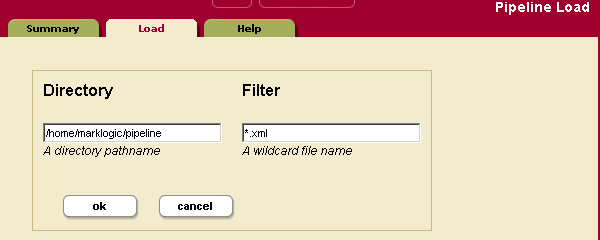
- Click the Load tab. The Pipeline Load page appears.
- Enter the directory where your pipeline XML file is stored.
- Enter a wildcard filter to search on. For example, entering
*.xmlwill look for all pipeline files in the directory with filenames ending with.xml. - Click OK.
- On the Pipeline Load confirmation page, examine the name of the pipeline(s) displayed. Only XML documents that are in the
http://marklogic.com/cpf/pipelinesnamespace are displayed. If the pipeline displayed is correct, click OK to load the pipeline into the database.
The pipeline is loaded into the triggers database associated with the database in which you are defining content processing. If the pipeline does not conform to the pipelines.xsd schema, the load will fail.
XML Format of a Pipeline
A pipeline is an XML document, and it must conform to the pipelines.xsd schema, located as follows:
<install_dir>/Config/pipelines.xsd
The pipeline document defines the properties of the pipeline, including the pipeline name, the success and failure actions, any status transitions, any state transitions, and all of the actions associated with the various stages of the pipeline. Once you create the XML pipeline document, you must load it into the database to use it, as described in Loading Pipelines With the Admin Interface.
This section describes the pipeline XML format and includes the following topics:
Sample Pipeline XML Document
The following is a sample pipeline XML document.
<!-- Copyright 2002-2010 MarkLogic Corporation. All Rights Reserved. --> <?xml-stylesheet href="/cpf/pipelines.css" type="text/css"?> <pipeline xmlns="http://marklogic.com/cpf/pipelines" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://marklogic.com/cpf/pipelines pipelines.xsd"> <pipeline-name>HTML Conversion</pipeline-name> <pipeline-description>Additional conversion rules for HTML. This pipeline should be used in conjunction with the basic conversion pipeline and the status change handling pipeline. </pipeline-description> <success-action> <module>/MarkLogic/cpf/actions/success-action.xqy</module> </success-action> <failure-action> <module>/MarkLogic/cpf/actions/failure-action.xqy</module> </failure-action> <state-transition> <annotation> Convert HTML documents and only HTML documents. </annotation> <state>http://marklogic.com/states/initial</state> <on-success>http://marklogic.com/states/converted</on-success> <on-failure>http://marklogic.com/states/error</on-failure> <priority>9200</priority> <execute> <condition> <module>/MarkLogic/cpf/actions/mimetype-condition.xqy</module> <options xmlns="/MarkLogic/cpf/actions/mimetype-condition.xqy"> <mime-type>text/html</mime-type> </options> </condition> <action> <module>/MarkLogic/conversion/actions/convert-html-action.xqy</module> <options xmlns="/MarkLogic/conversion/actions/convert-html-action.xqy"> <destination-root/> <destination-collection/> </options> </action> </execute> </state-transition> <!-- States converted and error not handled here --> </pipeline>
Success-Action and Failure-Action
The success-action and failure-action elements in the pipeline are where you specify the clean-up activities to perform when the processing for a state or status transition action succeeds or when it fails. The failure-action is only called if a transition fails; when a status or state transition action succeeds, it is not called. The success-action is called only if no success action is specified in a status or state transition, and if the transition has no default action. The success-action.xqy and failure-action.xqy XQuery modules are designed to handle these actions, calling the functions cpf:success or cpf:failure to advance the state as appropriate.
Your XQuery action modules or XSLT stylesheets for state transitions should call cpf:success or cpf:failure to advance the state, as described in Action Modules Use try/catch With cpf:success and cpf:failure. The default success-action and failure-action modules are only called either if there is no action specified in a state transition or if the pipeline catches an exception.
You should use the default actions in all of your pipelines. While it is possible to create your own success/failure actions, MarkLogic recommends using the default success-action.xqy and failure-action.xqy XQuery modules for these actions.
Status Transitions
A status transition is an action that happens after a document has a status change (for example, document create, update, or delete). The Status Change Handling pipeline, installed when you install content processing in a database, keeps track of the status during content processing.
The Status Change Handling pipeline sets the state of a document to http://marklogic.com/states/initial on creation (unless the document is created with an initial state), sets the state to http://marklogic.com/states/updated on update, and cleans up links on delete.
You should not need to create any of your own status transitions. While it is possible to create your own status transitions, MarkLogic recommends using the status transitions supplied in the Status Change Handling pipeline. Changing the Status Change Handling pipeline can cause compatibility problems in future upgrades and releases of MarkLogic Server.
Status transitions have the following parts:
Status
The status is defined by the Status Change Handling pipeline, and has the following possible values:
The Status Change Handling Pipeline and corresponding XQuery modules automatically handle status changes. Setting the status in your application code, especially on a document whose status is anything except done, can cause unexpected behavior; do not set the status in your application code.
On Success and On Failure
The on-success and on-failure part of the status transition defines the next state if the status transition is successful (in the case of success) and defines the next state if the status transition is not successful (in the case of failure). In each case, they reference an XQuery module that is called when the status transition succeeds or fails. If you do not specify an on-success or on-failure state, the document remains in its current state after the status transition success or failure.
Default Action
The default action references an XQuery module that is called if no other actions are activated. The status transition will execute the first of the following that occurs:
Priority
The priority is used to determine which pipeline should be executed first in the event that there are multiple pipelines attached to a domain that act on the same status. Status transitions with a higher priority number execute before ones with a lower number. In the event of a tie (that is, if two priorities are the same number), it is indeterminate which one will execute first. For the pipelines supplied with MarkLogic Server, the order is set such that conversion executes first, then entity enrichment, then modular documents (xinclude), then alerting, and finally schema validation.
Execute
The execute part of the status transition runs the XQuery module referenced in the condition, and then runs the XQuery module referenced by the action if the condition returns true or if there is no condition specified. If there are multiple execute elements in a single status transition, you should design them so that at most one execute element has a condition that returns true. If multiple conditions return true, then the first one to return true has its action executed. The reason for this is that all of the XQuery modules execute in separate transactions, and it is non-deterministic which one will return first. Therefore, if you have multiple conditions that return true, either the first one will come first (in the case of a single pipeline) or you cannot guarantee which one will come first and execute its action (in the case of multiple pipelines).
If a condition fails (for example, throws an exception), the condition is handled as if it returns false.
Execute nodes for status transitions can also include options nodes. The options nodes are the same as the ones for state transitions, described in Execute.
State Transitions
Pipelines that define your content processing are generally made up of one or more state transitions. A state transition performs some work and then moves a document from one state to another. Each state is stored as a property in the properties document corresponding to the document URI. You define success or failure states in the on-success or on-failure part of the transition definition.
The state transitions have the following parts:
State
The state is a string that is stored in a properties document. A state can be any valid URI. States are used by pipelines to begin a state transition. When the transition is complete, the pipeline specifies a new state for the document. The new state, in turn, is caught by another state transition, and so on until there are no state transitions for the new document state.
On Success and On Failure
The on-success and on-failure part of the state transition is where you specify the state to which the document is set if the state transition returns successfully (on-success) or if it fails (on-failure). If you do not specify an on-success or on-failure state, the document remains in its current state after the state transition success or failure, thereby completing processing for that document.
Default Action
The default action references an XQuery module that is called if no other actions are activated. The state transition will execute the first of the following that occurs:
- Any action whose condition in the state transition returns
trueor is absent. - The default action for any transition for this state.
- The success-action.
You can use the default action to move a document to the next state if the processing you want to perform is the default action. The following is a sample state-transition node that contains a default action:
<state-transition> <annotation> Default action example </annotation> <state>http://marklogic.com/states/initial</state> <on-success>http://marklogic.com/states/collected</on-success> <on-failure>http://marklogic.com/states/error</on-failure> <priority>5000</priority> <default-action> <module>/pipeline/mypipes/default-action.xqy</module> </default-action> </state-transition>
If you want the move the state to one that is different from the state transition's on-success state, you can use the $override-state parameter to the cpf:success function in your default action XQuery module. You should move the state to a different state from the document's current state. An example of a module that does this is the /MarkLogic/cpf/actions/state-setting-action.xqy under the Modules directory.
Priority
The priority is used to determine which pipeline state should be executed first in the event that there are multiple pipelines states attached to a domain that act on the same state. State transitions with a higher priority number execute before ones with a lower number. In the event of a tie (that is, if two priorities are the same number), it is indeterminate which one will execute first. For the pipelines supplied with MarkLogic Server, the order is set such that conversion executes first, then entity enrichment, then modular documents (xinclude), then alerting, and finally schema validation.
Execute
The execute part of the state transition runs the XQuery module or XSLT stylesheet referenced in the condition, and then runs the XQuery module or XSLT stylesheet referenced by the action if the condition returns true or if there is no condition specified. If there are multiple execute elements in a single state transition, you should design them so that at most one execute element has a condition that returns true. If multiple conditions return true, then the first one to return true has its action executed. The reason for this is that all of the XQuery modules or XSLT stylesheets execute in separate transactions, and it is non-deterministic which one will return first. Therefore, if you have multiple conditions that return true, either the first one will come first (in the case of a single pipeline) or you cannot guarantee which one will come first and execute its action (in the case of multiple pipelines).
If a condition fails (for example, throws an exception), the condition is handled as if it returns false.
You can also include an options node, which allows you to pass an external variable and/or an options node to code in the action XQuery moduleor XSLT stylesheet. The options node should have the namespace of the action module, or the namespace of the options node called in the XQuery function (xdmp:tidy, for example). The following is a sample options node within a condition:
<condition> <module>/MarkLogic/cpf/actions/mimetype-condition.xqy</module> <options xmlns="/MarkLogic/cpf/actions/mimetype-condition.xqy"> <mime-type>text/html</mime-type> </options> </condition>
The pipeline passes the options node as an external variable ($cpf:options) to the module that tests for the condition (mimetypes-condition.xqy, in this sample).
XQuery Functions to Manage Pipelines
The Admin Interface provides all of the functionality for loading pipelines. However, if you want to load and manage pipelines without using the Admin Interface, the pipelines.xqy XQuery module contains functions to manage pipelines. This XQuery file is installed into the following location:
<install_dir>/Modules/MarkLogic/cpf/pipelines.xqy
For details on the functions in this module, see the MarkLogic XQuery and XSLT Function Reference.