
MarkLogic Server 11.0 Product DocumentationScalability, Availability, and Failover Guide — Chapter 8
Configuring Shared-Disk Failover for a Forest
This chapter describes the procedure for configuring shared-disk failover for a forest. For details about how failover works and the requirements for failover, see High Availability of Data Nodes With Failover. For details on configuring local-disk failover, see Configuring Local-Disk Failover for a Forest. This chapter includes the following sections:
- Setting Up Shared-Disk Failover for a Forest
- Reverting a Failed Over Forest Back to the Primary Host
For other failover administrative procedures that apply to both local-disk and shared-disk failover, see Other Failover Configuration Tasks.
Setting Up Shared-Disk Failover for a Forest
Setting up shared-disk failover for a forest is a relatively simple administrative process. This section describes this procedure. There are two basic parts to the procedure:
- Enabling Failover in a Group
- Setting Journaling Database Option to Strict
- Configuring Shared-Disk Failover For a Forest
Enabling Failover in a Group
For each group in which you want to host a failover forest, perform the following steps:
- Before setting up failover, ensure that you have met all the requirements for failover, as described in Requirements for Shared-Disk Failover.
- In the groups configuration page for the group in which the failover host belongs, make sure the
failover enablebutton is set totrue.This group-level
failover enablebutton provides global control, at the group level, for enabling and disabling failover for all forests in that group.

You can enable or disable failover at the group level at any time. It does not stop you from configuring failover for forests; it only stops failover from actually occurring.
Setting Journaling Database Option to Strict
In the database in which you plan to attach shared-disk failover forests, MarkLogic recommends setting the journaling option to strict. The strict setting does an explicit file sync to the journal before committing the transaction. The default fast setting syncs to the operating system, but does not do an explicit file sync, and instead relies on the operating system to write to the disk. If the operating system fails suddenly (for example, a power failure or a system crash) after the transaction is committed but before the journal has been written to disk, in fast mode, it is possible to lose a transaction, but in strict mode you will not lose any transactions.
Setting the journaling option to strict will slow each transaction down (because it has to wait for the filesystem to report back that the journal file was written to disk). In some cases, the slowdown can be significant, and in other cases it can be relatively modest, but in all cases it will be slower. If you are doing many small transactions one after another, the slowdown can be considerable. In these cases, the best practice is to batch the updates into larger transactions (for example, update 100 documents per transaction instead of 1 document per transaction). The optimal size of your batches will vary based on the size of your documents, the hardware in which you are running MarkLogic Server, and other factors. You should perform your own performance benchmarks with your own workload to determine your optimum batch size.
The reason for setting the option to strict for shared-disk failover is that, with shared-disk failover, you are specifically trying to guard against hosts going down with only a single copy of the data. With local-disk failover, the replica forests each store a copy of the data, so not synchronizing the filesystem for each transaction is less risky (because the master host as well as all of the replica hosts would need to have the operating system fail suddenly in order to potentially lose a transaction), and it therefore tends to be more of an acceptable performance trade-off to set journaling to fast (although you could use strict if you want to be even safer). You should evaluate your requirements and SLAs when making these trade-offs, as what is acceptable for one environment might not be acceptable for another.
To set the journaling database option to strict, perform the following steps:
- In the Admin Interface, navigate to the database configuration page for the database to which you will attach your shared-disk failover forests.
- On the database configuration page, find the
journalingoption and set it tostrict. - Click OK to save the changes.
All forests attached to this database will use strict journaling.
Configuring Shared-Disk Failover For a Forest
To set up shared-disk failover on a forest, perform the following steps:
- Before setting up failover, ensure that you have met all the requirements for failover, as described in Requirements for Shared-Disk Failover and enable failover for the group, as described in Enabling Failover in a Group.
- Either create a new forest or enable failover for an existing forest with a data directory on a supported CFS. If you are modifying an existing forest, skip to step 6. To create a new forest, first click the Forests link in the left tree menu, then click the Create tab. The Create Forest page appears.
- Enter a name for the forest.
- In the Host drop-down list, choose the primary host for this forest. This is the host that will service this forest unless the forest fails over to another host.
- Specify a data directory for the forest that is on a supported CFS. For example, if the CFS is mounted to
/veritas/marklogicon your primary host and all of your failover hosts, specify/veritas/marklogic. - Select
trueforfailover enable. Note thatfailover enablemust be set totrueat both the forest and the group level, as described in Enabling Failover in a Group, for failover to be active. - In the first drop-down list in the
failover hostssection, choose a failover host. If you are specifying more than one failover host, choose additional failover hosts in the drop-down lists below. - Click OK to create or modify the forest.

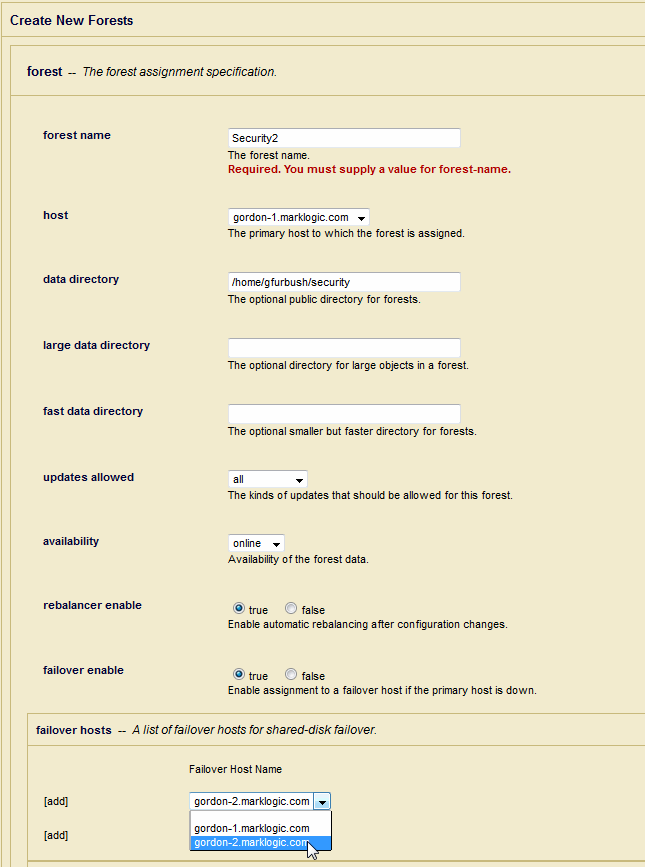
The forest is now configured with failover hosts. You must attach the forest to a database before you can use the forest, but it is ready and set up for failover.
Reverting a Failed Over Forest Back to the Primary Host
If a forest fails over to a failover host, it will remain mounted locally to the failover host until the host unmounts the forest. If you have a failed over forest and want to revert it back to the primary host (unfailover the forest), you must either restart the forest or restart the host in which the forest is locally mounted. After restarting, the forest will automatically mount locally on the primary host if the primary host is back online and corrected. To check the status of the hosts in the cluster, see the Cluster Status Page in the Admin Interface.
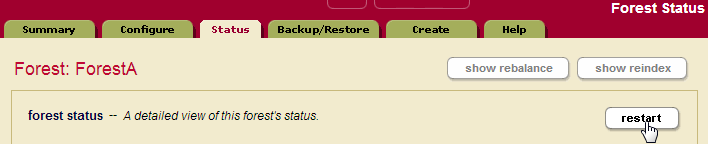
To restart the forest, perform the following steps:
- Navigate to the Status page for the forest that has failed over. For example, if the forest name is myFailoverForest, click Forests > myFailoverForest in the left tree menu, then click the Status tab.
- On the Forest Status page, click the restart button.
- Click OK on the Restart Forest confirmation page.
- When the Forest Status page returns, if the Mount State is
unmounted, the forest might not have completed mounting. Refresh the page and the Mount State should indicate that the forest is open.
The forest is restarted, and if the primary host is available, the primary host will mount the forest. If the primary host is not available, the first failover host will try to mount the forest, and so on until there are no more failover hosts to try. If you look in the ErrorLog.txt log file for the primary host, you will see a message similar to the following:
2007-03-28 13:20:29.644 Info: Mounted forest myFailoverForest locally on /veritas/marklogic/Forests/myFailoverForest
If you look at the ErrorLog.txt log file for any other host in the cluster, you will see a message similar to the following:
2007-03-28 13:20:29.644 Info: Mounted forest myFailoverForest remotely on seymour.marklogic.com