
MarkLogic 9 Product DocumentationMarkLogic Connector for Hadoop Developer's Guide — Chapter 3
Apache Hadoop MapReduce Concepts
This chapter provides a very brief introduction to Apache Hadoop MapReduce. If you are already familiar with Apache Hadoop MapReduce, skip this chapter. For a complete discussion of the MapReduce and the Hadoop framework, see the Hadoop documentation, available from the Apache Software Foundation at http://hadoop.apache.org
This chapter covers the following topics:
- MapReduce Overview
- Example: Calculating Word Occurrences
- Understanding the MapReduce Job Life Cycle
- How Hadoop Partitions Map Input Data
- Configuring a MapReduce Job
- Running a MapReduce Job
- Viewing Job Status and Logs
MapReduce Overview
Apache Hadoop MapReduce is a framework for processing large data sets in parallel across a Hadoop cluster. Data analysis uses a two step map and reduce process. The job configuration supplies map and reduce analysis functions and the Hadoop framework provides the scheduling, distribution, and parallelization services.
The top level unit of work in MapReduce is a job. A job usually has a map and a reduce phase, though the reduce phase can be omitted. For example, consider a MapReduce job that counts the number of times each word is used across a set of documents. The map phase counts the words in each document, then the reduce phase aggregates the per-document data into word counts spanning the entire collection.
During the map phase, the input data is divided into input splits for analysis by map tasks running in parallel across the Hadoop cluster. By default, the MapReduce framework gets input data from the Hadoop Distributed File System (HDFS). Using the MarkLogic Connector for Hadoop enables the framework to get input data from a MarkLogic Server instance. For details, see Map Task.
The reduce phase uses results from map tasks as input to a set of parallel reduce tasks. The reduce tasks consolidate the data into final results. By default, the MapReduce framework stores results in HDFS. Using the MarkLogic Connector for Hadoop enables the framework to store results in a MarkLogic Server instance. For details, see Reduce Task.
Although the reduce phase depends on output from the map phase, map and reduce processing is not necessarily sequential. That is, reduce tasks can begin as soon as any map task completes. It is not necessary for all map tasks to complete before any reduce task can begin.
MapReduce operates on key-value pairs. Conceptually, a MapReduce job takes a set of input key-value pairs and produces a set of output key-value pairs by passing the data through map and reduce functions. The map tasks produce an intermediate set of key-value pairs that the reduce tasks uses as input. The diagram below illustrates the progression from input key-value pairs to output key-value pairs at a high level:
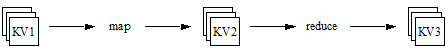
Though each set of key-value pairs is homogeneous, the key-value pairs in each step need not have the same type. For example, the key-value pairs in the input set (KV1) can be (string, string) pairs, with the map phase producing (string, integer) pairs as intermediate results (KV2), and the reduce phase producing (integer, string) pairs for the final results (KV3). See Example: Calculating Word Occurrences.
The keys in the map output pairs need not be unique. Between the map processing and the reduce processing, a shuffle step sorts all map output values with the same key into a single reduce input (key, value-list) pair, where the value is a list of all values sharing the same key. Thus, the input to a reduce task is actually a set of (key, value-list) pairs.
The key and value types at each stage determine the interfaces to your map and reduce functions. Therefore, before coding a job, determine the data types needed at each stage in the map-reduce process. For example:
- Choose the reduce output key and value types that best represents the desired outcome.
- Choose the map input key and value types best suited to represent the input data from which to derive the final result.
- Determine the transformation necessary to get from the map input to the reduce output, and choose the intermediate map output/reduce input key value type to match.
Control MapReduce job characteristics through configuration properties. The job configuration specifies:
- how to gather input
- the types of the input and output key-value pairs for each stage
- the map and reduce functions
- how and where to store the final results
For more information on job configuration, see Configuring a MapReduce Job. For information on MarkLogic specific configuration properties, see Input Configuration Properties and Output Configuration Properties.
Example: Calculating Word Occurrences
This example demonstrates the basic MapReduce concept by calculating the number of occurrence of each each word in a set of text files. For an in-depth discussion and source code for an equivalent example, see the Hadoop MapReduce tutorial at:
http://hadoop.apache.org/mapreduce/docs/current/mapred_tutorial.html
Recall that MapReduce input data is divided into input splits, and the splits are further divided into input key-value pairs. In this example, the input data set is the two documents, document1 and document2. The InputFormat subclass divides the data set into one split per document, for a total of 2 splits:
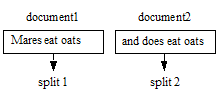
A (line number, text) key-value pair is generated for each line in an input document. The map function discards the line number and produces a per-line (word, count) pair for each word in the input line. The reduce phase produces (word, count) pairs representing aggregated word counts across all the input documents.
Given the input data shown above, the map-reduce progression for the example job is:

The output from the map phase contains multiple key-value pairs with the same key: The oats and eat keys appear twice. Recall that the MapReduce framework consolidates all values with the same key before entering the reduce phase, so the input to reduce is actually (key, values) pairs. Therefore, the full progression from map output, through reduce, to final results is:

Understanding the MapReduce Job Life Cycle
This section briefly sketches the life cycle of a MapReduce job and the roles of the primary actors in the life cycle. The full life cycle is much more complex. For details, refer to the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
Though other configurations are possible, a common Hadoop cluster configuration is a single master node where the Job Tracker runs, and multiple worker nodes, each running a Task Tracker. The Job Tracker node can also be a worker node.
When the user submits a MapReduce job to Hadoop:
- The local Job Client prepares the job for submission and hands it off to the Job Tracker.
- The Job Tracker schedules the job and distributes the map work among the Task Trackers for parallel processing.
- Each Task Tracker spawns a Map Task. The Job Tracker receives progress information from the Task Trackers.
- As map results become available, the Job Tracker distributes the reduce work among the Task Trackers for parallel processing.
- Each Task Tracker spawns a Reduce Task to perform the work. The Job Tracker receives progress information from the Task Trackers.
All map tasks do not have to complete before reduce tasks begin running. Reduce tasks can begin as soon as map tasks begin completing. Thus, the map and reduce steps often overlap.
Job Client
The Job Client prepares a job for execution.When you submit a MapReduce job to Hadoop, the local JobClient:
- Validates the job configuration.
- Generates the input splits. See How Hadoop Partitions Map Input Data.
- Copies the job resources (configuration, job JAR file, input splits) to a shared location, such as an HDFS directory, where it is accessible to the Job Tracker and Task Trackers.
- Submits the job to the Job Tracker.
Job Tracker
The Job Tracker is responsible for scheduling jobs, dividing a job into map and reduce tasks, distributing map and reduce tasks among worker nodes, task failure recovery, and tracking the job status. Job scheduling and failure recovery are not discussed here; see the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
When preparing to run a job, the Job Tracker:
- Fetches input splits from the shared location where the Job Client placed the information.
- Creates a map task for each split.
- Assigns each map task to a Task Tracker (worker node).
The Job Tracker monitors the health of the Task Trackers and the progress of the job. As map tasks complete and results become available, the Job Tracker:
- Creates reduce tasks up to the maximum enableed by the job configuration.
- Assigns each map result partition to a reduce task.
- Assigns each reduce task to a Task Tracker.
A job is complete when all map and reduce tasks successfully complete, or, if there is no reduce step, when all map tasks successfully complete.
Task Tracker
A Task Tracker manages the tasks of one worker node and reports status to the Job Tracker. Often, the Task Tracker runs on the associated worker node, but it is not required to be on the same host.
When the Job Tracker assigns a map or reduce task to a Task Tracker, the Task Tracker:
- Fetches job resources locally.
- Spawns a child JVM on the worker node to execute the map or reduce task.
- Reports status to the Job Tracker.
The task spawned by the Task Tracker runs the job's map or reduce functions.
Map Task
The Hadoop MapReduce framework creates a map task to process each input split. The map task:
- Uses the
InputFormatto fetch the input data locally and create input key-value pairs. - Applies the job-supplied map function to each key-value pair.
- Performs local sorting and aggregation of the results.
- If the job includes a
Combiner, runs theCombinerfor further aggregation. - Stores the results locally, in memory and on the local file system.
- Communicates progress and status to the Task Tracker.
Map task results undergo a local sort by key to prepare the data for consumption by reduce tasks. If a Combiner is configured for the job, it also runs in the map task. A Combiner consolidates the data in an application-specific way, reducing the amount of data that must be transferred to reduce tasks. For example, a Combiner might compute a local maximum value for a key and discard the rest of the values. The details of how map tasks manage, sort, and shuffle results are not covered here. See the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
When a map task notifies the Task Tracker of completion, the Task Tracker notifies the Job Tracker. The Job Tracker then makes the results available to reduce tasks.
Reduce Task
The reduce phase aggregates the results from the map phase into final results. Usually, the final result set is smaller than the input set, but this is application dependent. The reduction is carried out by parallel reduce tasks. The reduce input keys and values need not have the same type as the output keys and values.
The reduce phase is optional. You may configure a job to stop after the map phase completes. For details, see Configuring a Map-Only Job.
Reduce is carried out in three phases, copy, sort, and merge. A reduce task:
- Fetches job resources locally.
- Enters the copy phase to fetch local copies of all the assigned map results from the map worker nodes.
- When the copy phase completes, executes the sort phase to merge the copied results into a single sorted set of
(key, value-list)pairs. - When the sort phase completes, executes the reduce phase, invoking the job-supplied reduce function on each
(key, value-list)pair. - Saves the final results to the output destination, such as HDFS.
The input to a reduce function is key-value pairs where the value is a list of values sharing the same key. For example, if one map task produces a key-value pair (eat, 2) and another map task produces the pair (eat, 1), then these pairs are consolidated into (eat, (2, 1)) for input to the reduce function. If the purpose of the reduce phase is to compute a sum of all the values for each key, then the final output key-value pair for this input is (eat, 3). For a more complete example, see Example: Calculating Word Occurrences.
Output from the reduce phase is saved to the destination configured for the job, such as HDFS or MarkLogic Server. Reduce tasks use an OutputFormat subclass to record results. The Hadoop API provides OutputFormat subclasses for using HDFS as the output destination. The MarkLogic Connector for Hadoop provides OutputFormat subclasses for using a MarkLogic Server database as the destination. For a list of available subclasses, see OutputFormat Subclasses. The connector also provides classes for defining key and value types; see MarkLogic-Specific Key and Value Types.
How Hadoop Partitions Map Input Data
When you submit a job, the MapReduce framework divides the input data set into chunks called splits using the org.apache.hadoop.mapreduce.InputFormat subclass supplied in the job configuration. Splits are created by the local Job Client and included in the job information made available to the Job Tracker.
The JobTracker creates a map task for each split. Each map task uses a RecordReader provided by the InputFormat subclass to transform the split into input key-value pairs. The diagram below shows how the input data is broken down for analysis during the map phase:
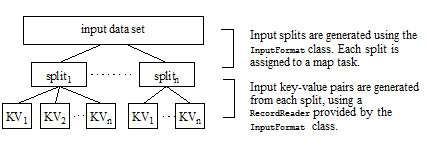
The Hadoop API provides InputFormat subclasses for using HDFS as an input source. The MarkLogic Connector for Hadoop provides InputFormat subclasses for using MarkLogic Server as an input source. For a list of available MarkLogic-specific subclasses, see InputFormat Subclasses.
Configuring a MapReduce Job
This section covers the following topics:
- Configuration Basics
- Setting Properties in a Configuration File
- Setting Properties Using the Hadoop API
- Setting Properties on the Command Line
- Configuring a Map-Only Job
Configuration Basics
Hadoop configuration is controlled by multiple layers of configuration files and property settings. You may set configuration properties in configuration files, programmatically, and on the command line. For details, see the documentation for your Hadoop distribution, or the Apache Hadoop MapReduce documentation at http://hadoop.apache.org.
Configuration properties can include the following:
- Hadoop MapReduce properties
- Application-specific properties, such as the properties defined by the MarkLogic Connector for Hadoop API in
com.marklogic.mapreduce.MarkLogicConstants - Job-specific properties. For example, the
mapreduce.linkcount.baseuriproperty used by theLinkCountInDocsample application
A MapReduce application must configure at least the following:
- Mapper: Define a subclass of
org.apache.hadoop.mapreduce.Mapper, usually overriding at least theMap.map()method. - InputFormat: Select a subclass of
org.apache.hadoop.mapreduce.InputFormatand pass it toorg.apache.hadoop.mapreduce.Job.setInputFormatClass.
If the job includes a reduce step, then the application must also configure the following:
- Reducer: Define a subclass of
org.apache.hadoop.mapreduce.Reducer, usually overriding at least theReducer.reduce()method. - OutputFormat: Select a subclass of
org.apache.hadoop.mapreduce.OutputFormatand pass it toorg.apache.hadoop.mapreduce.Job.setOutputFormatClass. - Output key and value types for the map and reduce phases. Set the key and value types appropriate for your
InputFormatandOutputFormatsubclasses using the Job API functions, such asorg.apache.hadoop.mapreduce.Job.setMapOutputKeyClass.
For details about configuring MapReduce jobs, see the documentation for your Hadoop distribution. For details about connector-specific configuration options, see Using MarkLogic Server for Input and Using MarkLogic Server for Output.
Setting Properties in a Configuration File
Configuration files are best suited for static configuration properties. By default, Apache Hadoop looks for configuration files in $HADOOP_CONF_DIR. You may override this location on the hadoop command line. Consult the documentation for your Hadoop distribution for the proper location, or see the Apache Hadoop Commands Guide at http://hadoop.apache.org.
Job configuration files are XML files with the following layout:
<?xml version=1.0?> <?xml-stylesheet type=text/xsl href=configuration.xsl?> <configuration> <property> <name>the.property.name</name> <value>the.property.value</value> </property> <property>...</property> </configuration>
Setting Properties Using the Hadoop API
You can use the Apache Hadoop API to set properties that cannot be set in a configuration file or that have dynamically calculated values. For example, you can set the InputFormat class by calling org.apache.hadoop.mapreduce.Job.setInputFormatClass.
Set properties prior to submitting the job. That is, prior to calling org.apache.mapreduce.Job.submit or org.apache.mapreduce.Job.waitForCompletion.
To set an arbitrary property programmatically, use the org.apache.hadoop.conf.Configuration API. This API includes methods for setting property values to string, boolean, numeric, and class types. Set the properties prior to starting the job. For example, to set the MarkLogic Connector for Hadoop marklogic.mapreduce.input.documentselector property, at runtime, you can do the following:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.mapreduce.Job; import com.marklogic.mapreduce.MarkLogicConstants; ... public class myJob { ... public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); Job job = new Job(conf); // Build up the document selectory dynamically... String mySelector = ...; conf = job.getConfiguration(); conf.set(MarkLogicConstants.DOCUMENT_SELECTOR, mySelector); ... System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Setting Properties on the Command Line
You can set properties on the hadoop command line using the -D command line option. For example:
$ hadoop -Dproperty_name=value jar myJob.jar myClass
Configuring a Map-Only Job
Some jobs can complete all their work during the map phase. For example, the ContentLoader sample application, which loads documents from HDFS into MarkLogic Server, performs document loading in the map tasks and then stops without using reduce tasks. See ContentLoader.
To stop a job after the map completes, set the number of reduce tasks to zero by setting the property mapred.reduce.tasks to 0 in your job configuration file, or by calling org.apache.hadoop.Configuration.setNumReduceTasks(0) in your application.
Running a MapReduce Job
Use the hadoop jar command to execute a job. For example:
$ hadoop jar /path/myJob.jar my.package.Class options
For specific examples, see Using the Sample Applications. For details about the hadoop command line, consult the documentation for your Hadoop distribution or see the Apache Hadoop MapReduce Command Guide at http://hadoop.apache.org.
Viewing Job Status and Logs
A running job reports progress and errors to stdout and stderr. If Hadoop is configured for standalone mode, this output is all that is available. If Hadoop is configured in pseudo-distributed or fully distributed mode, logs are recorded in the Hadoop logs directory by default. The location of the logs directory is dependent on your Hadoop distribution. You can also view job status and results using the Job Tracker and NameNode web consoles.
This section assumes your Hadoop distribution uses the same logging mechanism as Apache Hadoop. Consult the documentation for your distribution for details.
Use the Job Tracker web console to view job status. By default, the Job Tracker console is available on port 50030. For example:
http://localhost:50030
Use the NameNode web console to browse HDFS, including job results, and to look at job related logs. By default, the NameNode console is available on port 50070. For example:
http://localhost:50070
- Navigate to the NameNode console on port 50070.
- Click the Namenode Logs link at the top of the page. A listing of the logs directory appears.
- To check for errors, click on a Job Tracker log file, such as
hadoop-your_username-jobtracker-your_hostname.log. The contents of the log file appears. - Click on your browser Back button to return to the log directory listing.
- To view output output from your job, click on userlogs at the bottom of the logs directory listing. A user log listing appears.
- Locate the run corresponding to your job by looking at the timestamps. A log directory is created for each map task and each reduce task.
Map tasks have _m_ in the log directory name. Reduce tasks have _r_ in the log directory name. For example,
attempt_201111020908_0001_m_000001_0/represents a map task. - Click on the map or reduce task whose output you want to examine. A directory listing of the stdout, stderr, and syslog for the select task.
- Click on the name of a log to see what the task output to that destination. For example, click stderr to view text written to stderr by the task.