
MarkLogic 10 Product DocumentationSemantic Graph Developer's Guide — Chapter 6
Semantic Queries
This chapter discusses the principal techniques and tools used for performing semantic queries on RDF triples. Just as with loading and deleting triples, you can select your preferred method for querying RDF triples in MarkLogic. You can query triples in several ways, though the main focus in this chapter is using SPARQL to query triples.
MarkLogic supports the syntax and capabilities in SPARQL 1.1. SPARQL is a query language specification for querying over RDF triples. The SPARQL language is a formal W3C recommendation from the RDF Data Access Working Group. It is described in the SPARQL Query Language for RDF recommendation:
http://www.w3.org/TR/rdf-sparql-query/
SPARQL queries are executed natively in MarkLogic to query either in-memory triples or triples stored in a database. When querying triples stored in a database, SPARQL queries execute entirely against the triple index. For examples of running SPARQL queries, see Querying Triples.
You can combine SPARQL with XQuery or JavaScript. For example, you can restrict a SPARQL query by passing in a cts:query (XQuery) or cts.query (JavaScript) and you can call built-in functions (including cts:contains or cts.contains for full-text search) as part of your SPARQL query. For more details, see Using Built-in Functions in a SPARQL Query.
You can use the following methods to query triples:
- SPARQL mode in Query Console. For details, see Querying Triples with SPARQL
- XQuery using the semantics functions, and Search API, or a combination of XQuery and SPARQL. For details, see Querying Triples with XQuery or JavaScript.
- HTTP via a SPARQL endpoint. For details, see Using Semantics with the REST Client API.
SPARQL keywords are shown in uppercase in this chapter, however SPARQL keywords are not case sensitive.
This chapter includes the following sections:
- Querying Triples with SPARQL
- Querying Triples with XQuery or JavaScript
- Querying Triples with the Optic API
- Serialization
- Security
Querying Triples with SPARQL
This section is a high-level overview of the SPARQL query capabilities in MarkLogic and includes the following topics:
- Types of SPARQL Queries
- Executing a SPARQL Query in Query Console
- Specifying Query Result Options
- Selecting Results Rendering
- Constructing a SPARQL Query
- Prefix Declaration
- Query Pattern
- Target RDF Graph
- Result Clauses
- Query Clauses
- Solution Modifiers
- Property Path Expressions
- SPARQL Aggregates
- SPARQL Resources
The examples in this section use the
persondata-en.ttldataset from http://downloads.dbpedia.org/2016-10/core-i18n/en/persondata_en.ttl.bz2. See Downloading the Dataset.
Types of SPARQL Queries
You can query an RDF dataset using any of these SPARQL query forms:
- SELECT Queries - A SPARQL
SELECTquery returns a solution, which is a set of bindings of variables and values. - CONSTRUCT Queries - A SPARQL
CONSTRUCTquery returns triples as a sequence of sem:triple values in an RDF graph. These triples are constructed by substituting variables in a set of triple templates to create new triples from existing triples. - DESCRIBE Queries - A SPARQL
DESCRIBEquery returns a sequence of sem:triple values as an RDF graph that describes the resources found. - ASK Queries - A SPARQL
ASKquery returns a boolean (trueorfalse) indicating whether a query pattern matches the dataset.
Executing a SPARQL Query in Query Console
- In a Web browser, navigate to the Query Console:
http://hostname:8000/qconsole
- From the Query Type drop-down list, select SPARQL Query.
The Query Console supports syntax highlighting for SPARQL keywords.
Select SPARQL Update when you are working with SPARQL Update. See SPARQL Update for more information.
- Construct your SPARQL query. See Constructing a SPARQL Query.
- From the Content Source drop-down list
,select the target database. - In the control bar below the query window, click Run.
If the triple index is not enabled for the target database, an XDMP-TRPLIDXNOTFOUND exception is thrown. See Enabling the Triple Index for details.
Specifying Query Result Options
In the Query Console, SPARQL results are returned as a sequence of json:object values in the case of a SELECT query, a sequence of sem:triple values in the case of a CONSTRUCT or DESCRIBE query, or a single xs:boolean value in the case of an ASK query. The results for each will look different in Query Console.
This section discusses the following topics:
Auto vs. Raw Format
The results of a SPARQL query displays triples or SELECT solutions. Solution objects show a mapping from variable names to typed values. Each heterogeneous item in the result sequence will have specific rendering, which is by default shown in Auto format.
For example, this SELECT query returns a solution:
PREFIX db: <http://dbpedia.org/resource/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX onto: <http://dbpedia.org/ontology/> SELECT ?person ?name WHERE { ?person onto:birthPlace db:Brooklyn; foaf:name ?name .}
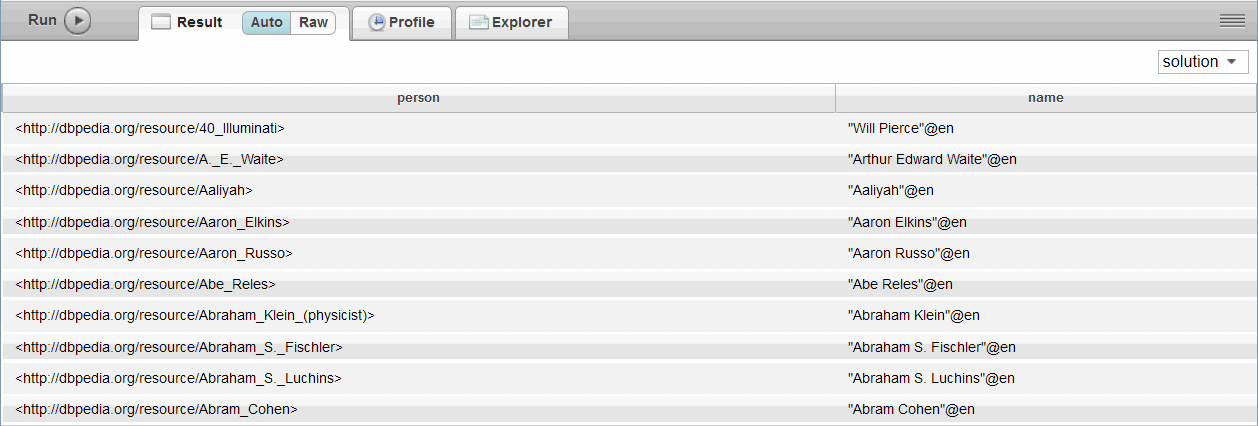
To change the display format to Raw, click Raw on the Result tab. In Raw format, the results for the same query are displayed in RDF/JSON serialization:
[ { "person":"<http://dbpedia.org/resource/40_Illuminati>", "name":"\"Will Pierce\"@en" }, { "person":"<http://dbpedia.org/resource/A._E._Waite>", "name":"\"Arthur Edward Waite\"@en" }, { "person":"<http://dbpedia.org/resource/Aaliyah>", "name":"\"Aaliyah\"@en" }, { "person":"<http://dbpedia.org/resource/Aaron_Elkins>", "name":"\"Aaron Elkins\"@en" }, { "person":"<http://dbpedia.org/resource/Aaron_Russo>", "name":"\"Aaron Russo\"@en" }, { "person":"<http://dbpedia.org/resource/Abe_Reles>", "name":"\"Abe Reles\"@en" }, { "person":"<http://dbpedia.org/resource/Abraham_Klein_(physicist)>", "name":"\"Abraham Klein\"@en" }, { "person":"<http://dbpedia.org/resource/Abraham_S._Fischler>", "name":"\"Abraham S.Fischler\"@en" }, { "person":"<http://dbpedia.org/resource/Abraham_S._Luchins>", "name":"\"Abraham S.Luchins\"@en" }, { "person":"<http://dbpedia.org/resource/Abram_Cohen>", "name":"\"Abram Cohen\"@en" } ]
If you run a similar DESCRIBE query, the output is returned in Query Console in triples format:
PREFIX db: <http://dbpedia.org/resource/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX onto: <http://dbpedia.org/ontology/> DESCRIBE ?person ?name WHERE { ?person onto:birthPlace db:Brooklyn; foaf:name ?name .} => @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/40_Illuminati> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Brooklyn> , <http://dbpedia.org/resource/New_York> ; <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://xmlns.com/foaf/0.1/Person> ; <http://xmlns.com/foaf/0.1/surname> "Pierce"@en ; <http://purl.org/dc/elements/1.1/description> "Rapper"@en ; <http://xmlns.com/foaf/0.1/givenName> "Will"@en ; <http://xmlns.com/foaf/0.1/name> "Will Pierce"@en . <http://dbpedia.org/resource/A._E._Waite> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Brooklyn> ; <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://xmlns.com/foaf/0.1/Person> ; <http://xmlns.com/foaf/0.1/givenName> "Arthur Edward"@en ; <http://xmlns.com/foaf/0.1/name> "Arthur Edward Waite"@en ; <http://purl.org/dc/elements/1.1/description> "English writer"@en ; <http://xmlns.com/foaf/0.1/surname> "Waite"@en . <http://dbpedia.org/resource/Aaliyah> <http://dbpedia.org/ontology/deathPlace> <http://dbpedia.org/resource/Abaco_Islands> , <http://dbpedia.org/resource/Marsh_Harbour> , <http://dbpedia.org/resource/The_Bahamas> ; <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Brooklyn> , <http://dbpedia.org/resource/New_York_City> ; <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> <http://xmlns.com/foaf/0.1/Person> ; <http://xmlns.com/foaf/0.1/name> "Aaliyah"@en ; <http://purl.org/dc/elements/1.1/description> "Singer, dancer, actress, model"@en ; <http://dbpedia.org/ontology/birthDate> "1979-01-16"^^xs:date ; <http://dbpedia.org/ontology/deathDate> "2001-08-25"^^xs:date . . . . .
When you run a query that returns triples as a subgraph, the default output serialization is Turtle.
The DESCRIBE clause has a limit of 9999 triples in the server. If a query includes a DESCRIBE clause with one IRI or few IRIs that total more than 9999 triples, triples will be truncated from the results. The server does not provide any warning or message that this has occured.
Selecting Results Rendering
Use the solution as: drop-down list options to choose the display for query results. For example, this DESCRIBE query returns triples in Turtle serialization:
PREFIX db: <http://dbpedia.org/resource/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX onto: <http://dbpedia.org/ontology/> DESCRIBE ?person ?name WHERE { ?person onto:birthPlace db:Brooklyn; foaf:name ?name .}
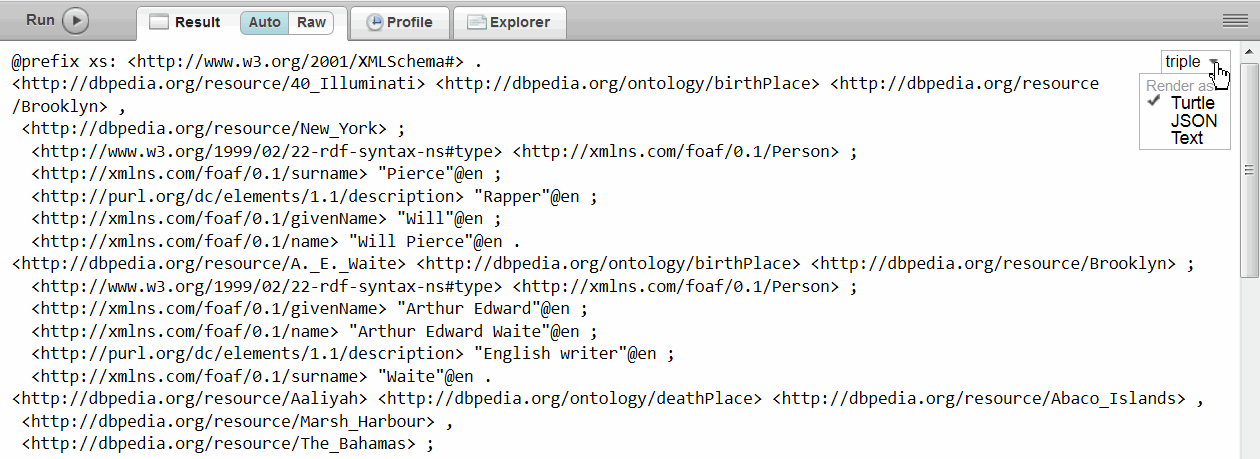
Or you can select JSON or text as the format for the results.
For a DESCRIBE query, the rendering options are Turtle, JSON, or Text. Rendering options may be different for queries that use cts:search, a combination of SPARQL and cts: queries, or use query results that are serialized by a serialization function.
Constructing a SPARQL Query
You can construct a SPARQL query to ask specific questions about triples or to create new triples from triples in your triple store. A SPARQL query typically contains the following (in order):
- Prefix Declaration - abbreviates prefix IRIs
- Query Pattern - specifies what to query in the RDF graph, compares and matches query patterns
- Target RDF Graph - identifies the dataset to query
- Result Clauses - specifies the information to return from the graph
- Query Clauses - extends or restricts the scope of your query
- Solution Modifiers - specifies the order in which to return the results and the number of results
The query pattern and a result clause are the minimum required components for a query. The prefix declaration, target RDF graph, query clauses, and solution modifiers are optional components that structure and define your query.
The following example is a simple SPARQL SELECT query that contains a query pattern to find people whose birthplace is Paris:
SELECT ?s WHERE {?s <http://dbpedia.org/ontology/birthPlace/> <http://dbpedia.org/resource/Paris> }
The following sections discuss the components of the SPARQL query in more detail, and how to compose simple and complex queries.
Prefix Declaration
IRIs can be long and unwieldy, and the same IRI may be used many times in a query. To make queries concise, SPARQL allows the definition of prefixes and base IRIs. Defining prefixes saves time, makes the query more readable, and can reduce errors. The prefix for a commonly used vocabulary is also known as a CURIE (Compact URI Expression).
In this example, the prefix definitions are declared and the query pattern is written with abbreviated prefixes:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT * WHERE { ?s dc:description "Physicist"@en ; rdf:type foaf:Person ; onto:birthPlace db:England . }
The query results returns the people described as Physicist who were born in England. The @en language tag means that you are searching for the English word Physicist. The query will match only triples with Physicist and an English language tag.
Query Pattern
At the heart of a SPARQL query is a set of triple patterns called a graph pattern. Triple patterns are like RDF triples except the subject, predicate, and object nodes may be a variable.
A graph pattern matches a subgraph of the RDF data when RDF terms from that subgraph may be substituted for the variables, and the result is an RDF graph equivalent to the subgraph.
The graph pattern is one or more triple patterns contained within curly braces ({ }). The following types of graph patterns for the query pattern are discussed in this chapter:
- Basic graph pattern - a set of triple patterns must match against triples in the triple store
- Group graph pattern - a set of graph patterns must all match using the same variable substitution
- Optional graph pattern - additional patterns may extend the solution
- Union graph pattern - where two or more possible patterns are tried
- Graph graph pattern - where patterns are matched against named graphs
SPARQL variables are denoted with a question mark (?) or a dollar symbol ($). The variables can be positioned to match any subject, predicate, or object node, and match any value in that position. Thus, the variable may be bound to an IRI or a literal (string, boolean, date, and so on). Each time a triple pattern matches a triple in the triple store, it produces a binding for each variable.
This example shows a basic graph pattern with variables to match the subject (?s) and predicate (?p) of triples where the object is db:Paris - to find subjects who were born or died in Paris. The query consists of two parts; the SELECT clause specifies what is in the query results (subject and predicate) and the WHERE clause provides the basic graph pattern to match against the data graph:
PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> SELECT ?s ?p WHERE {?s ?p db:Paris }
This query will return every person in your dataset who was born or died in Paris. You may want to limit the number of results by adding LIMIT 10 to the end of the query. SeeThe LIMIT Keyword for details.
A variable may only be bound once. The ?s and ?p in the SELECT clause are the same variables as in the WHERE clause.
The results of the query include the subject and predicate IRIs (for birthPlace and deathPlace) where db:Paris is in the object position of the triple:
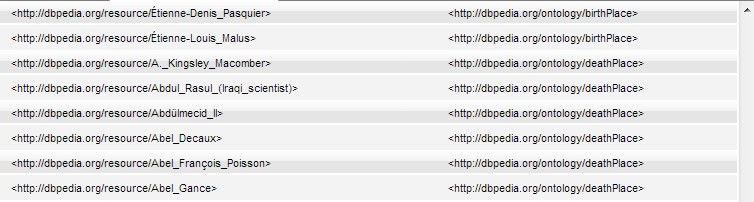
A SPARQL SELECT query returns a solution, which is a set of bindings of variables and values. By default, the results of SELECT queries are returned in Auto format, a formatted view made for easy viewing. You can change the output display. For details, see Specifying Query Result Options.
The previous example is a single triple pattern match (the basic graph pattern). You can query with SPARQL using multiple triple pattern matching. SPARQL uses a syntax similar to Turtle for expressing query patterns, where each triple pattern ends with a period.
Similar to an AND clause in SQL queries, every triple in the query pattern must be matched exactly. For example, consider place names in our dataset that can be found in different countries such as Paris, Texas or Paris, France.
The following example returns the IRIs for all resources born in Paris, France that are described as Footballers:
PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?s ?p WHERE {?s onto:birthPlace db:Paris . ?s onto:birthPlace db:France . ?s dc:description "Footballer"@en . }
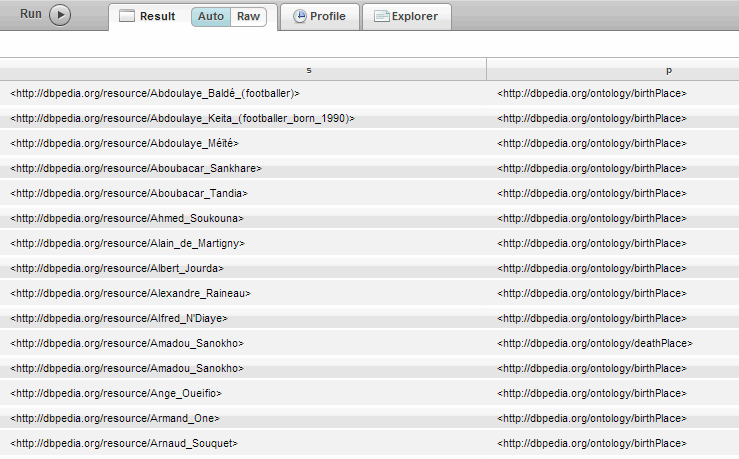
An alternative way to write the query pattern above is to use a semicolon (;) in the WHERE clause to separate triple patterns that share the same subject.
PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?s WHERE {?s onto:birthPlace db:Paris ; onto:birthPlace db:France ; dc:description "Footballer"@en . }
The SPARQL specification allows you to use a blank node as subject and object of a triple pattern in a query.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?desc WHERE { _:p rdf:type foaf:Person ; dc:description ?desc . }
The query returns the role or title for resources as defined in the triples in the dataset:
If there are blank nodes in the queried graph, blank node identifiers may be returned in the results.
Target RDF Graph
A SPARQL query is executed against an RDF dataset that contains graphs. These graphs can be:
- A single default graph - a set of triples with no name attached to them
- One or more named graphs - where inside a
GRAPHclause, each named graph is a pair, made up of a name and a set of triples
For example, this query will be executed on the graph named http://my_collections:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?name ?mbox ?date FROM <http://my_collections> WHERE { ?g dc:publisher ?name ; dc:date ?date . GRAPH ?g { ?person foaf:name ?name ; foaf:mbox ?mbox } }
The GRAPH Keyword describes the use of GRAPH in a query.
The FROM and FROM NAMED keywords are used to specify an RDF dataset in a SPARQL query, as described in the W3C SPARQL Query Language for RDF:
http://www.w3.org/TR/rdf-sparql-query/#specifyingDataset
In the absence of FROM or FROM NAMED keywords, a SPARQL query executes against all graphs that exist in the database. In other words, if you don't specify a graph name with a query, the UNION of all graphs will be queried.
Using XQuery, REST, or Javascript you can also specify one or more graphs to be queried by using:
- a
default-graph-uri*- Selects the graph name(s) to query, usually a subset of the available graphs. - a
named-graph-uri* -Used withFROMNAMEDandGRAPHto specify the IRI(s) to be substituted for a name within particular kinds of queries. You can have one or morenamed-graph-uri*parameters specified as part of a query.
If you specify default-graph-uri*, one or more graph names that you specify will be queried. The * indicates that one or more default-graph-uri or named-graph-uri parameters can be specified.
This default-graph-uri is not the "default" graph that contains unnamed triples - http://marklogic.com/semantics#default-graph.
In this example a SPARQL query is wrapped in XQuery, to search the data set in the http://example.org/bob/foaf.rdf graph:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql(' PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?g ?name WHERE {graph ?g { ?alum foaf:schoolHomepage <http://www.ucsb.edu/> . ?alum foaf:knows ?person . ?person foaf:name ?name } } ' () ("default-graph-uri=http://example.org/bob/foaf.rdf")
The FROM in a SPARQL query functions the same as default-graph-uri, and the FROM NAMED functions the same as named-graph-uri. These two clauses function in the same way as part of the SPARQL query, except that one is written into queries (wrapped in the query), while the other is specified outside of the query.
This section discusses the following topics:
The FROM Keyword
The FROM clause in a SPARQL query tells SPARQL where to get data to query, which graph to query. To use FROM as part of a query, there has to be a graph with the name in the FROM clause. Graph names in MarkLogic are implemented as collections, which you can view using Explore or the cts:collections function in the Query Console.
This SPARQL query uses the FROM keyword to search data in the info:govtrack/people graph:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?name FROM <http://marklogic.com/semantics#info:govtrack/people/> WHERE { ?x foaf:name ?name } LIMIT 10
See Preparing to Run the Examples for information about the GovTrack dataset.
The default graph is the result of an RDF merge of the graphs (a union of graphs) referred to in one or more FROM clauses. Each FROM clause contains an IRI that indicates a graph to be used to form the default graph.
For example, graph1 and graph2 are merged to form the default graph:
FROM graph1 FROM graph2
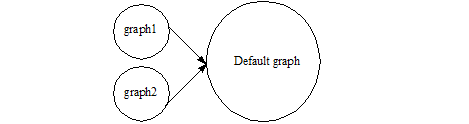
When we talk about the default graph in this sense, it is not the same as the default collections, http://marklogic.com/semantics#default-graph.
This example shows a SPARQL SELECT query that returns all triples where Alice is in the object position. The RDF dataset contains a single default graph and no named graphs:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?p ?o FROM <http://example.org/foaf/alice> WHERE {?s foaf:name "Alice"; ?p ?o .}
The FROM keyword must be placed before the WHERE clause. Placing the FROM keyword after the WHERE clause causes a syntax error.
The FROM NAMED Keywords
A query can supply IRIs for the named graphs in the dataset using the FROM NAMED clause. Each IRI is used to provide one named graph in the dataset. Having multiple FROM NAMED clauses causes multiple graphs to be added to the dataset. With FROM NAMED, every graph name you use in the query will be matched only to the graph provided in the clause.
You can set the named-graph at load time using mlcp with the collection parameter -output_collections http://www.example.org/my_graph. See Specifying Collections and a Directory. You can also set the named-graph using the REST client with PUT /v1/graphs.
A named graph is typically created when you load RDF data. See Loading Triples.
In a query, FROM NAMED is used to identify a named graph that is queried from the WHERE clause by using the GRAPH keyword.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?who ?g ?mbox FROM <http://example.org/foaf/aliceFoaf> FROM NAMED <http://example.org/alice> FROM NAMED <http://example.org/bob> WHERE { ?g dc:publisher ?who . GRAPH ?g { ?x foaf:mbox ?mbox } }
In the example, the FROM and FROM NAMED keywords are used together. The FROM NAMED is used to scope the graphs that are considered during query evaluation, and the GRAPH construct specifies one of the named graphs.
When FROM or FROM NAMED keywords are used, the graphs you can use in a GRAPH clause potentially become restricted.
The GRAPH Keyword
The GRAPH keyword instructs the query engine to evaluate part of the query against the named graphs in the dataset. A variable used in the GRAPH clause may also be used in another GRAPH clause or in a graph pattern matched against the default graph in the dataset.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?name ?mbox ?date WHERE { ?g dc:publisher ?name ; dc:date ?date . GRAPH ?g { ?person foaf:name ?name ; foaf:mbox ?mbox } }
You must enable the collection lexicon when you use a GRAPH construct in a SPARQL query. You can enable the collection lexicon from the database configuration pages or the Admin Interface.
Triples inside of a GRAPH clause with an explicit IRI, such as GRAPH <....uri...> { ...graph pattern... }, are matched against the dataset using the IRI specified in the graph clause.
Result Clauses
Querying the dataset with different types of SPARQL queries returns different types of results. These SPARQL query forms return the following result clauses:
- SELECT Queries - returns a sequence of variable bindings
- CONSTRUCT Queries - returns an RDF graph constructed by substituting variables in a set of triple templates
- DESCRIBE Queries - returns an RDF graph that describes the resources found
- ASK Queries - returns a boolean indicating whether a query pattern matches
SELECT Queries
The SPARQL SELECT keyword indicates that you are requesting data from a dataset. This SPARQL query is the most widely used of the query forms. SPARQL SELECT queries return a sequence of bindings as a solution, that satisfies the query. Selected variables are separated by white spaces, not commas.
You can use the asterisk wildcard symbol (*) with SPARQL SELECT as shorthand for selecting all the variables identified in the query pattern.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT * WHERE{?s foaf:givenName ?fn . ?s foaf:surname ?ln . }
In single triple patterns, a period at the end is optional. In a query pattern with multiple triple patterns, the period at the end of final triple is also optional.
In the example, the SELECT query returns a sequence of bindings that includes the IRI for the subject variable (?s), along with the first name (?fn) and last name (?ln) of resources in the dataset.
SPARQL SELECT query results are serialized as XML, JSON, or passed to another function as a map. The results of a SELECT query may not always be triples.
CONSTRUCT Queries
You can create new triples from existing triples by using SPARQL CONSTRUCT queries. When you execute a construct query, the results are returned in a sequence of sem:triple values as triples in memory.
This example creates triples for Albert Einstein from the existing triples in the database:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> CONSTRUCT {?person ?p ?o .} WHERE {?person foaf:givenName "Albert"@en ; foaf:surname "Einstein"@en ; ?p ?o .}
The CONSTRUCT queries return an RDF graph created from variables in the query pattern.
These triples are created for Albert Einstein from the existing triples in the dataset:
@prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Baden-Wºrttemberg> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/German_Empire> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://dbpedia.org/ontology/deathPlace> <http://dbpedia.org/resource/Princeton,_New_Jersey> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Ulm> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://dbpedia.org/ontology/deathPlace> <http://dbpedia.org/resource/United_States> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://xmlns.com/foaf/0.1/givenName> "Albert"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://xmlns.com/foaf/0.1/name> "Albert Einstein"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://xmlns.com/foaf/0.1/surname> "Einstein"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Albert_Einstein> <http://purl.org/dc/elements/1.1/description> "Physicist"@en .
These triples are constructed in memory and not added to the database.
The @en language tag means that this is an English word and will match differently than any other language tag.
DESCRIBE Queries
SPARQL DESCRIBE queries return a sequence of sem:triple values. The DESCRIBE query result returns RDF graphs that describe one or more of the given resources. The W3C specification leaves the details implementation dependent. In MarkLogic, we return a Concise Bounded Description of the IRIs identified, which includes all triples which have the IRI as a subject, and for each of those triples that has a blank node as an object, all triples with those blank nodes as a subject. This implementation does not provide any reified statements, and will return a maximum of 9999 triples.
For example, this query finds triples containing Pascal Bedrossian:
DESCRIBE <http://dbpedia.org/resource/Pascal_Bedrossian>
The triples found by the DESCRIBE query are returned in Turtle format. You can also select JSON or Text as the format.
@prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/France> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthPlace> <http://dbpedia.org/resource/Marseille> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/surname> "Bedrossian"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/givenName> "Pascal"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://xmlns.com/foaf/0.1/name> "Pascal Bedrossian"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://purl.org/dc/elements/1.1/description> "footballer"@en . @prefix xs: <http://www.w3.org/2001/XMLSchema#> . <http://dbpedia.org/resource/Pascal_Bedrossian> <http://dbpedia.org/ontology/birthDate> "1974-11-28"^^xs:date .
The DESCRIBE clause has a limit of 9999 triples in the server, which means if a query includes a DESCRIBE clause with one IRI or few IRIs that total more than 9999 triples, triples will be truncated from the results. The server does not provide any warning or message that this has occurred.
ASK Queries
SPARQL ASK queries return a single xs:boolean value. The ASK clause returns true if the query pattern has any matches in the dataset and false if there is no pattern match.
For example, in the persondata dataset are the following facts about two members of the Kennedy family: Carolyn Bessette-Kennedy and Eunice Kennedy-Shriver:
- Eunice Kennedy-Shriver, the founder of the Special Olympics precursor and a sister of John F. Kennedy was born on 1921-07-10.
- Carolyn Bessette-Kennedy, a publicist, and wife of JFK Junior, was born on 1966-01-07.
This query asks if Carolyn was born after Eunice.
PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> ASK { db:Carolyn_Bessette-Kennedy onto:birthDate ?by . db:Eunice_Kennedy_Shriver onto:birthDate ?bd . FILTER (?by>?bd). } => true
Query Clauses
Add the following query clauses to extend or reduce the number of potential results returned:
- The OPTIONAL Keyword
- The UNION Keyword
- The FILTER Keyword
- Comparison Operators
- Negation in Filter Expressions
- BIND Keyword
- Values Sections
The OPTIONAL Keyword
The OPTIONAL keyword is used to return additional results if there is a match in an optional graph pattern. For example, this query pattern returns triples in the database consisting of the first name (?fn), last name (?ln) and mail address (?mb):
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?fn ?ln WHERE{?x foaf:givenName ?fn . ?x foaf:surname ?ln . ?x foaf:email ?mb . }
Only triples that match all the triple patterns are returned. In the persondata dataset there may be people with no email address. In this case, the Query Console will silently leave these people out of the result set.
You can use the optional graph pattern (also known as a left join) to return matching values of any variables in common, if they exist. Since the OPTIONAL keyword is also a graph pattern, it has its own set of curly braces (inside the curly braces of the WHERE clause).
This example extends the previous example to return one or more email addresses, and just the first name and last name if there is no email address:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?fn ?ln WHERE {?x foaf:givenName ?fn . ?x foaf:surname ?ln . OPTIONAL{?x foaf:email ?mb .} }
Optional patterns may yield unbound variables. See ORDER BY Keyword for more about unbound variables.
The UNION Keyword
Use the UNION keyword to match multiple patterns from multiple different sets of data, and then combine them in the query result. The UNION keyword is placed inside the curly braces of the WHERE clause. The syntax is:
{ triple pattern } UNION { triple pattern }
The UNION pattern combines graph patterns; each alternative possibility can contain more than one triple pattern (logical disjunction).
This example finds people who are described as Authors or Novelists and their date of birth:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX onto: <http://dbpedia.org/ontology/> SELECT ?person ?desc ?date WHERE { ?person rdf:type foaf:Person . ?person dc:description ?desc . ?person onto:birthDate ?date . { ?person dc:description "Novelist"@en . } UNION { ?person dc:description "Author"@en . } }
You can also group triple patterns into multiple graph patterns using a group graph pattern structure.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?person ?desc WHERE {{?person rdf:type foaf:Person } {?person dc:description ?desc } {{?person dc:description "Author"@en } UNION { ?person dc:description "Novelist"@en . } } }
Note that each set of braces contains a triple. This is semantically equivalent to this next query and would yield the same results.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?person WHERE {?person rdf:type foaf:Person ; dc:description ?desc . {?person dc:description "Author"@en } UNION {?person dc:description "Novelist"@en . } }
You can use multiple UNION patterns in a SPARQL query. The results from the OPTIONAL and UNION queries differ in that the UNION query allows a subgraph of another solution, while an OPTIONAL query explicitly does not.
The FILTER Keyword
There are multiple methods for limiting the results of a SPARQL query. You can use the FILTER, DISTINCT, or the LIMIT keywords to restrict the number of matching results that are returned.
You can use one or more SPARQL FILTER keywords to specify the variables by which to constrain results. The FILTER constraint is placed inside the curly braces of the WHERE clause and can contain symbols for logical, mathematical, or comparison operators such as greater than (>), less than(<), equal to (=), and so on. The FILTER constraints use boolean conditions to return matching query results. There are also a number of built-in SPARQL tests you can use such as isURI, isBlank, and so forth.
This table lists some of the SPARQL unary operators in FILTER constraints:
For a full list of operations, see Operator Mapping in the SPARQL Query Language for RDF.
This example is a query pattern that provides meaning to the variable ?bd (a person's birth date). The FILTER clause of the query pattern compares the variable value to the date January 1st, 1999 and returns people born after the given date:
PREFIX onto: <http://dbpedia.org/ontology/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> SELECT ?s WHERE {?s rdf:type foaf:Person . ?s onto:birthDate ?bd . FILTER (?bd > "1999-01-01"^^xsd:date) }
The SPARQL keyword a is a shortcut for the common predicate rdf:type, giving the class of a resource. For example, the WHERE clause could be written as:
WHERE {?s a foaf:Person . ?s onto:birthDate ?bd .
You can express a FILTER clause with a regular expression pattern by using the regex function. For example:
SELECT ?s ?p ?o WHERE {?s ?p ?o FILTER (regex (?o, "Lister", "i")) }
The SPARQL query returns all matching results where the text in the object position contains the string Lister in any case. Regular expression matches are made case-insensitive with the i flag.
This type of FILTER query is the equivalent of the fn:match XQuery function. Regular expressions are not optimized in SPARQL. Use cts:contains for optimized full text searching.
The regular expression language is defined in XQuery 1.0 and XPath 2.0 Functions and Operators, section 7.6.1 Regular Expression Syntax.
Using Built-in Functions in a SPARQL Query
In addition to SPARQL functions, you can use XQuery or JavaScript built-in functions (for example, functions with the prefix fn, cts, math, or xdmp) in a SPARQL query where you can use a function, which includes FILTER, BIND, and the expressions in a SELECT statement.
A built-in function is one that can be called without using import module in XQuery or var <module> = require in JavaScript. These functions are called extension functions when used in a SPARQL query. You can find a list of built-in functions at http://docs.marklogic.com by selecting Server-Side JavaScript APIs (or Server-Side XQuery APIs). The built-ins listed are under MarkLogic Built-In Functions and W3C-Standard Functions. See Using Semantic Functions to Query for more information.
Extension functions in SPARQL are identified by IRIs in the form of http://www.w3.org/2005/xpath-functions#name where name is the local name of the function and the string before the # is the prefix IRI of the function, for example http://www.w3.org/2005/xpath-functions#starts-with. For the prefix IRIs commonly associated with fn, cts, math, and xdmp (or any other prefix IRIs that do not end with a "/" or "#"), append a # to the prefix IRI and then the function local name, for example: http://marklogic.com/cts#contains.
You can access built-in functions like cts using PREFIX in the SPARQL query. In this example, cts:contains is added as using PREFIX and then included as part of the FILTER query:
PREFIX cts: <http://marklogic.com/cts#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema/> PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT * WHERE{ ?s ?p ?o . FILTER cts:contains(?o, cts:or-query(("Monarch", "Sovereign"))) FILTER(?p IN (dc:description, rdfs:type)) }
This is full-text search for the words Monarch or Sovereign where the predicate is either a description or a type. In the second FILTER clause, the use of IN specifies the predicates to filter on. The results include people that have a title of Monarch (of a kingdom, state or sovereignty) and things that have a description of Monarch such as the Monarch butterfly or Monarch Islands.
In this example the XPath function starts-with is used in a SPARQL query to return the roles or titles of people whose description begins with Chief. The function is imported by including the IRI as part of the FILTER query:
PREFIX dc: <http://purl.org/dc/elements/1.1/> SELECT ?desc WHERE {?s dc:description ?desc FILTER (<http://www.w3.org/2005/xpath-functions#starts-with>( ?desc, "Chief" ) )}
You can use the FILTER keyword with the OPTIONAL and UNION keywords.
Comparison Operators
The IN and NOT IN comparison operators are used with the FILTER clause to return a boolean true if a matching term is in the set of expressions, or false if not. For example:
ASK {
FILTER(2 IN (1, 2, 3))
}
=>
true
ASK {
FILTER(2 NOT IN (1, 2, 3))
}
=>
falseNegation in Filter Expressions
Negation can be used with the FILTER expression to eliminate solutions from the query results. There are two types of negation - one type filters results depending on whether a graph pattern does or does not match in the context of the query solution being filtered, and the other type is based on removing solutions related to another pattern. MarkLogic supports SPARQL 1.1 Negation (using EXISTS, NOT EXISTS, and MINUS)for use with FILTER.
The examples for negation use this data:
PREFIX : <http://example.org/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> :alice rdf:type foaf:Person . :alice foaf:name "Alice" . :bob rdf:type foaf:Person .
This section contains these topics:
EXISTS
The filter expression EXISTS checks to see whether the query pattern can be found in the data. For example, the EXISTS filter in this examples checks for the pattern ?person foaf:name ?name in the data:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?person
WHERE
{
?person rdf:type foaf:Person .
FILTER EXISTS { ?person foaf:name ?name }
}
=>
person
<http://example.org/aliceThe result of the query is Alice. The EXISTS filter does not generate any additional bindings.
NOT EXISTS
With the NOT EXISTS filter expression, the query tests whether a graph pattern does not match a dataset, given the values of variables in the group graph pattern in which the filter occurs. This query tests whether the ?person foaf:name ?name does not occur in the data:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?person
WHERE
{
?person rdf:type foaf:Person .
FILTER NOT EXISTS { ?person foaf:name ?name }
}
=>
person
<http://example.org/bob>The graph pattern for <http://example.org/bob> does not have a predicate foaf:name for ?person, so the query returns Bob as the result for this query. The NOT EXISTS filter does not generate any additional bindings.
MINUS
The another type of SPARQL negation is MINUS, which evaluates both its arguments, then calculates solutions in the left-hand side that are not compatible with the solutions on the right-hand side of the pattern.
For this example we will add additional data:
PREFIX : <http://example.org/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> :alice foaf:givenName "Alice" ; foaf:familyName "Smith" . :bob foaf:givenName "Bob" ; foaf:familyName "Jones" . :carol foaf:givenName "Carol" ; foaf:familyName "Smith" .
This query looks for patterns in the data that do not match ?s foaf:givenName "Bob" and returns those results:
PREFIX : <http://example.org/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT DISTINCT ?s
WHERE {
?s ?p ?o .
MINUS {
?s foaf:givenName "Bob" .
}
}
=>
<http://example.org/carol>
<http://example.org/alice>The results are Carol and Alice.
The filters NOT EXISTS and MINUS represent two ways of approaching negation. The NOT EXISTS approach tests whether a pattern exists in the data, based on the bindings determined by the query pattern. The MINUS approach removes matches based on the evaluation of two patterns. In some cases, they can produce different results. The MINUS filter does not generate any additional bindings.
Differences Between NOT EXISTS and MINUS
The filter expressions NOT EXISTS and MINUS represent two ways of using negation. The NOT EXISTS filter tests whether a pattern exists in the data, given the bindings already determined by the query pattern. The MINUS filter removes matches from the result set based on the evaluation of two patterns in the query. In some cases, these two approaches can produce different answers.
Example: Sharing of variables
@prefix : <http://example.com/> . :a :b :c .
SELECT *
{
?s ?p ?o
FILTER NOT EXISTS {?x ?y ?x}
}
=>
(This query has no results)The result set will be empty because {?x ?y ?x} matches all triples in the data, which the NOT EXISTS filter eliminates from the results.
When we use MINUS in the same query, there is no shared variable between the first part (?s ?p ?o) and the second part (?x ?y ?z), so no bindings are eliminated:
SELECT *
{
?s ?p ?o
FILTER MINUS {?x ?y ?x}
}
=>
s p o
<http://example.com/a> <http://example.com/b> <http://example.com/c>Example: Fixed pattern
Another case where the results will be different for NOT EXISTS and MINUS is where there is a concrete pattern (no variables) in the example query.
This query uses NOT EXISTS as the filter for negation:
PREFIX : <http://example.com/>
SELECT *
{
?s ?p ?o
FILTER NOT EXISTS {:a :b :c}
}
=>
(This query has no results) This query uses MINUS as the filter:
PREFIX : <http://example.com/>
SELECT *
{
?s ?p ?o
MINUS {:a :b :c}
}
=>
s p o
<http://example.com/a> <http://example.com/b> <http://example.com/c>Since there is no match of bindings, no solutions are eliminated, and the solution includes a, b, and c.
Example: Inner FILTERs
Differences in results will also occur because in a filter, variables from the group are in scope. In this example, the FILTER inside the NOT EXISTS has access to the value of ?n for the solution being considered. For this example, we will use this dataset:
PREFIX : <http://example.com/> :a :p 1 . :a :q 1 . :a :q 2 . :b :p 3.0 . :b :q 4.0 . :b :q 5.0 .
When using FILTER NOT EXISTS, the test is on each possible solution to ?x :p ?n in this query:
PREFIX : <http://example.com/>
SELECT * WHERE {
?x :p ?n
FILTER NOT EXISTS {
?x :q :m .
FILTER (?n = ?m)
}
}
=>
x n
<http://example.com/b> 3.0With MINUS, the FILTER inside the pattern does not have a value for ?n and it is always unbound.
PREFIX : <http://example.com/>
SELECT * WHERE {
?x ?p ?n
MINUS {
?x :q ?m .
FILTER (?n = ?m)
}
}
=>
x n
<http://example.com/b> 3.0
<http://example.com/a> 1Combination Queries with Negation
A combination query operates on triples embedded in documents. The query searches both the document and any triples embedded in the document. You can add negation with the FILTER keyword to constrain the results of the query.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $query := ' PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?country WHERE { <http://example.org/news/Nixon> <http://example.org/wentTo> ?country FILTER NOT EXISTS {?country foaf:isIn ?location . ?location foaf:isIn "Europe"} . }' let $store := sem:store((),cts:and-query( ( cts:path-range-query( "//triples-context/confidence", ">=", 80) , cts:path-range-query( "//triples-context/pub-date", ">", xs:date("1974-01-01")), cts:or-query( ( cts:element-value-query( xs:QName("source"), "AP Newswire" ), cts:element-value-query( xs:QName("source"), "BBC" ) ))))) let $result := sem:sparql($query, (), (), $store) return <result>{$result}</result>
The cts:path-range-query requires the path index to be configured to work correctly. See Understanding Range Indexes in the Administrator's Guide.
This is a modification of an earlier query that says Find all of the documents containing triples that have information about countries that Nixon visited. From that group, return only those triples that have a confidence level of 80% or above and a publication date after January 1st, 1974. And only return triples with a source element of AP Newswire or BBC. The MINUS filter removes any countries that are located in Europe from the results.
SPARQL Update will not modify triples embedded in documents. SPARQL Update can be used to insert new triples into graphs as part of a combination query, or to modify managed triples. See Unmanaged Triples for more information about triples in documents.
BIND Keyword
The BIND keyword allows a value to be assigned to a variable from a basic graph pattern or property path expression. The use of BIND ends the preceding basic graph pattern. The variable introduced by the BIND clause must not have been used in the group graph pattern up to the point of use in BIND. When you assign a computed value to a variable in the middle of a pattern, the computed value can then be used in other patterns, such as a CONSTRUCT query. The syntax is (expression AS ?var). For example:
PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> SELECT ?person WHERE { BIND (db:London AS ?location) ?person onto:birthPlace ?location . } LIMIT 10
Values Sections
You can use SPARQL VALUES sections to provide inline data as an unordered solution sequence that is joined with the results of the query evaluation. The VALUES section allows multiple variables to be specified in the data block. For example:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT * WHERE { ?a foaf:name ?n . VALUES ?n { "John" "Jane" }}
This query says find subjects with foaf:name John or Jane - supplying the values the ?n can have instead of searching for ?n in the dataset. This is the same as a query using the longer form where the parameter lists are contained in parentheses:
VALUES (?z) { ("John") ("Jane") }
A VALUES block of data can appear in a query pattern or at the end of a SELECT query or subquery.
Solution Modifiers
A solution modifier modifies the result set for SELECT queries. This section discusses how you can modify what your query returns using the following solution modifiers:
- The DISTINCT Keyword
- The LIMIT Keyword
- ORDER BY Keyword
- The OFFSET Keyword
- Subqueries
- Projected Expressions
With the exception of
DISTINCT, modifiers appear after theWHEREclause.
The DISTINCT Keyword
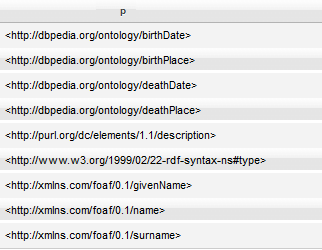
Use the DISTINCT keyword to remove duplicate results from a results set.
SELECT DISTINCT ?p WHERE {?s ?p ?o}
The query returns all of the predicates - just once - for all the triples in the persondata dataset.
The LIMIT Keyword
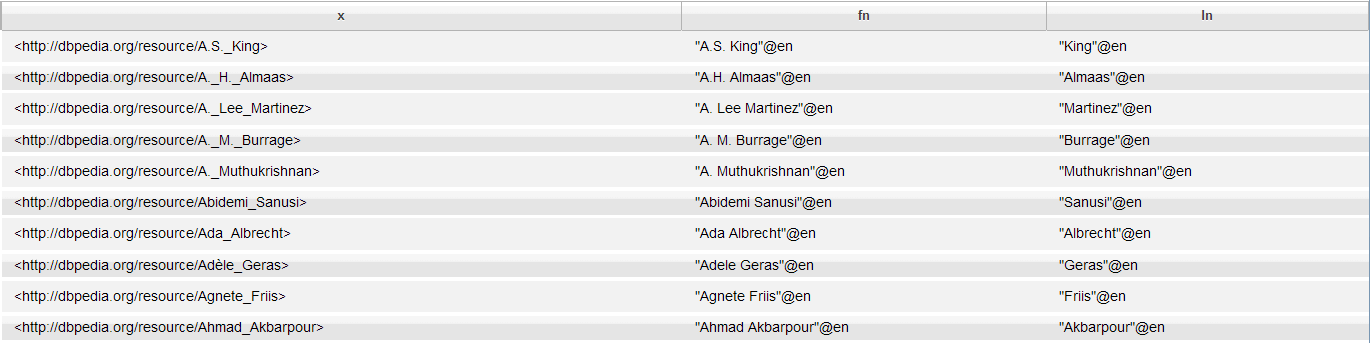
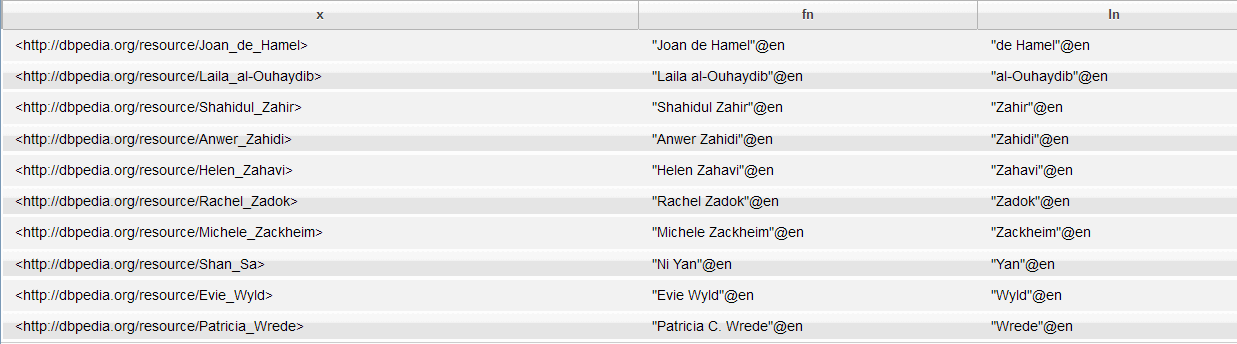
Use the LIMIT keyword to further restrict the results of a SPARQL query that are displayed. For example, in the DBPedia dataset, there could be thousands of authors that match this query:
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX foaf:<http://xmlns.com/foaf/0.1/> SELECT ?x ?fn ?ln WHERE{?x dc:description "Author"@en ; foaf:name ?fn ; foaf:surname ?ln.}
To specify the number matching results to display, add the LIMIT keyword after the curly braces of the WHERE clause with an integer (not a variable).
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX foaf:<http://xmlns.com/foaf/0.1/> SELECT ?x ?fn ?ln WHERE{?x dc:description "Author"@en ; foaf:name ?fn ; foaf:surname ?ln.} LIMIT 10
The results of the query are limited to the first ten matches:
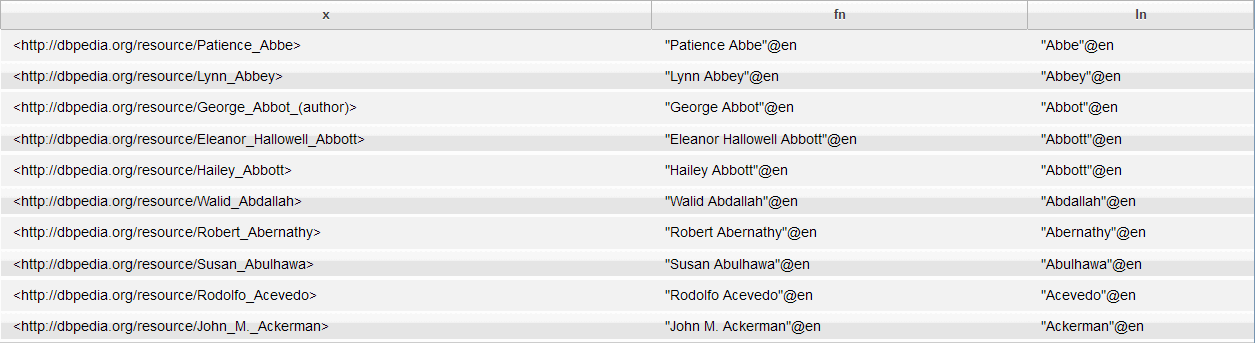
ORDER BY Keyword
Use the ORDER BY clause to specify the values of one or more variable by which to sort the query results. SPARQL provides an ordering for unbound variables, blank nodes, IRIs, or RDF literals as described in the SPARQL 1.1 Query Language recommendation:
http://www.w3.org/TR/sparql11-query/#modOrderBy
The default ordering is ascending order.
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?x ?fn ?ln WHERE{?x dc:description "Author" ; foaf:name ?fn ; foaf:surname ?ln.} ORDER BY ?ln ?fn LIMIT 10
The results are ordered by the author's last name (?ln) and then by the author's first name (?fn):
To change the order of results to descending order, use the DESC keyword and place the variable for the values to be returned in brackets. For example:
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?x ?fn ?ln WHERE{?x dc:description "Author"@en ; foaf:name ?fn ; foaf:surname ?ln .} ORDER BY DESC (?ln) LIMIT 10
The OFFSET Keyword
The OFFSET modifier is used for pagination, to skip a given number of matching query results before returning the remaining results. This keyword can be used with the LIMIT and ORDER BY keywords to retrieve different slices of data from a dataset. For example, you can create pages of results from different offsets.
This example queries for Authors in ascending order and limits the results to the first twenty, skipping the first eight matches and starting the list at position nine:
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?x ?fn ?ln WHERE{?x dc:description "Author"@en ; foaf:name ?fn ; foaf:surname ?ln.} ORDER BY ?x OFFSET 8 LIMIT 20
The results are returned, skipping the first eight matches.

SPARQL uses a 1-based index, meaning the first item is 1 and not 0, so an offset of 8 will skip items one through eight.
Subqueries
You can combine the results of several queries by using subqueries. You can nest one or more queries inside another query. Each subquery is enclosed in separate pairs of curly braces. Typically, subqueries are used with solution modifiers. This example queries for Politicians who were born in London and then limits the results to the first ten:
PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX db: <http://dbpedia.org/resource/> PREFIX onto: <http://dbpedia.org/ontology/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?name ?location ?date WHERE { ?person dc:description "Politician"@en . {SELECT ?location WHERE{?person onto:birthPlace db:London . ?person onto:birthPlace ?location } } {SELECT ?date WHERE{?person onto:birthDate ?date . } } {SELECT ?name WHERE{ ?person foaf:name ?name } } } LIMIT 10
Projected Expressions
You can use projected expressions within SPARQL SELECT queries to project arbitrary SPARQL expressions, rather than only bound variables. This allows the creation of new values in a query.
This type of query uses values derived from a variable, constant IRIs, constant literal, function calls, or other expressions in the SELECT list for columns in a query result set.
Functions could include both SPARQL built-in functions and extension functions supported by an implementation.
Projected expressions must be in parentheses and must be given an alias using the AS keyword. The syntax is (expression AS ?var).
PREFIX ex: <http://example.org/> SELECT ?Item (?price * ?qty AS ?total_price) WHERE { ?Item ex:price ?price. ?Item ex:quantity ?qty }
The query returns values for ?total_price that do not occur in the graphs contained in the RDF dataset.
De-Duplication of SPARQL Results
MarkLogic has implemented dedup=on and dedup=off options to sem:sparql(). Here are some examples of how deduplication works, based on a simple sem:sparql() example.
First, insert the same triple twice:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; (: load an rdf triple that will match the SPARQL query :) sem:rdf-insert( sem:triple(sem:iri("http://www.example.org/dept/108/invoices/20963"), sem:iri("http://www.example.org/dept/108/invoices/paid"), "true") , xdmp:default-permissions(), "test-dedup") ; (: returns the URI of the document that contains the triple :) import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; (: load an rdf triple that will match the SPARQL query :) sem:rdf-insert( sem:triple(sem:iri("http://www.example.org/dept/108/invoices/20963"), sem:iri("http://www.example.org/dept/108/invoices/paid"), "true") , xdmp:default-permissions(), "test-dedup") ; (: returns the URI of the document that contains the triple :)
Then use a SPARQL query with dedup=off:
sem:sparql(' PREFIX inv: <http://www.example.org/dept/108/invoices/> SELECT ?predicate ?object WHERE { inv:20963 ?predicate ?object } ' , (), "dedup=off" ) => <http://www.example.org/dept/108/invoices/paid> "true" <http://www.example.org/dept/108/invoices/paid> "true"
Two identical triples are returned.
This SPARQL query uses dedup=on, which is the default:
sem:sparql(' PREFIX inv: <http://www.example.org/dept/108/invoices/> SELECT ?predicate ?object WHERE { inv:20963 ?predicate ?object } ' , (), "dedup=on" ) => <http://www.example.org/dept/108/invoices/paid> "true"
Only one instance of the triple is returned.
The dedup=on option is the default, standards-compliant behavior. The dedup=off option for sem:sparql may well give the same results if you never insert duplicate triples, but it entails a considerable performance overhead (for example, with filtering in search), so it's important to consider using this option.
Property Path Expressions
Property paths enable you to traverse an RDF graph. You can follow possible routes through a graph between two graph nodes. You can use property paths to answer questions like show me all of the people who are connected to John, and all the people who know people who know John. You can use property paths to query paths of any length in a dataset graph by using an XPath-like syntax. A property path query retrieves pairs of connecting nodes where the paths that link those nodes match the given property path. This makes it easier to follow and use relationships expressed as triples.
Query evaluation determines all matches of a path expression and binds subject or object as appropriate. Only one match per route through the graph is recorded - there are no duplicates for any given path expression.
Enumerated Property Paths
The following table describes the supported enumerated path operators ( |, ^, and /) that can be combined with predicates in a property path:
The following examples illustrate property paths using this simple graph model:
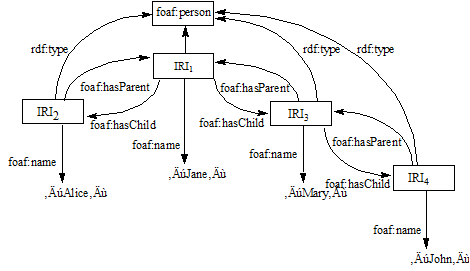
Here is that same graph model expressed as triples in Turtle format:
@prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> . @prefix p0: <http://marklogic.com/semantics/> . p0:alice foaf:hasParent p0:jane ; a foaf:Person ; foaf:name "Alice" . p0:jane foaf:hasChild p0:alice, p0:mary; a foaf:Person ; foaf:name "Jane" . p0:mary foaf:hasParent p0:jane ; a foaf:Person ; foaf:hasChild p0:john ; foaf:name "Mary" . p0:john foaf:hasParent p0:mary ; a foaf:Person ; foaf:name "John".
This example query uses paths (the / operator) to find the name of Alice's parent:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?s ?name
WHERE {?s foaf:name "Alice".
?s foaf:hasParent/foaf:name ?name .
}
=>
s name
<http://marklogic.com/semantics/alice> "Jane"This query finds the names of people two links away from John (his grandparent):
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?s ?name
WHERE {?s foaf:name "John".
?s foaf:hasParent/foaf:hasParent/foaf:name ?name .
}
=>
s name
<http://marklogic.com/semantics/john> "Jane"This query reverses the property path direction (swaps the roles of subject and object using the ^ operator) to find the name of Mary's mother:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s WHERE { <http://marklogic.com/semantics/mary> ^foaf:hasChild ?s } => s <http://marklogic.com/semantics/Jane>
Unenumerated Property Paths
Unenumerated paths enable you to query triple paths and discover relationships, along with simple facts. This table describes the unenumerated path operators (+, *, or ?) that can be combined with predicates in a property path:
A path element may itself be composed of path constructs.
The inverse operator (^) can be used with the enumerated path operators. Precedence of these operators is left-to-right within groups.
For these next examples, we can use sem:rdf-insert to add these triples to express the concept of foaf:knows:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $string := ' @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix p0: <http://marklogic.com/semantics/> . p0:alice foaf:knows p0:jane . p0:jane foaf:knows p0:mary, p0:alice . p0:mary foaf:knows p0:john, p0:jane . p0:john foaf:knows p0:mary .' return sem:rdf-insert(sem:rdf-parse($string, "turtle"))
To find the names of all the people who are connected to Mary, use foaf:knows with the + path operator:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?name WHERE {?s foaf:name "Mary" . ?s foaf:knows+/foaf:name ?name .} => s name <http://marklogic.com/semantics/mary> "Jane" <http://marklogic.com/semantics/mary> "John" <http://marklogic.com/semantics/mary> "Mary" <http://marklogic.com/semantics/mary> "Alice"
This query will match all of the triples connected to Mary by foaf:knows where one or more paths exist. You can use foaf:knows with the * operator to find the names of anyone who is connected to Mary (including Mary) by zero or more paths.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?name WHERE {?s foaf:name "Mary" . ?s foaf:knows*/foaf:name ?name .}
In this case the results will be same as in the previous example because the number of people connected to Mary by zero or more paths (the * path operator) is the same as the number connected by one or more paths.
Using the ? operator finds the triples connected to Mary by one path element.
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?name WHERE {?s foaf:name "Mary" . ?s foaf:knows?/foaf:name ?name .} => s name <http://marklogic.com/semantics/mary> "Jane" <http://marklogic.com/semantics/mary> "John" <http://marklogic.com/semantics/mary> "Mary"
You can also use a property path sequence to discover connections between triples.
For example, this query will find triples connected to Mary by three path elements:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?name WHERE { ?s foaf:name "Mary" . ?s foaf:knows/foaf:knows/foaf:knows/foaf:name ?name . } s name <http://marklogic.com/semantics/mary> "John" <http://marklogic.com/semantics/mary> "Jane" <http://marklogic.com/semantics/mary> "John" <http://marklogic.com/semantics/mary> "Jane"
The duplicate results are due to the different paths traversed by the query. You could add a DISTINCT keyword in the SELECT clause to return only one instance of each result and elimate the duplicates.
The SPARQL modifier ! has not been implemented in MarkLogic. Using this modifier to invert a property path value results in a syntax error.
You can combine SPARQL queries using property paths with a cts:query parameter to restrict results to only some documents (a combination query).
This combination query will find all the people connected to Alice who have children:
PREFIX cts: <http://marklogic.com/cts#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?s ?name WHERE { ?s foaf:name "Mary" . ?s foaf:knows+/foaf:name ?name . ?s ?p ?o . FILTER cts:contains(?p, cts:word-query("http://xmlns.com/foaf/0.1/hasChild")) } => <http://marklogic.com/semantics/mary> "Alice" <http://marklogic.com/semantics/mary> "Jane" <http://marklogic.com/semantics/mary> "John" <http://marklogic.com/semantics/mary> "Mary"
You could also use a cts:query parameter to restrict the query to a collection or directory.
Inference
You can use unenumerated paths to do simple inference using thesaural relationships. (A thesaural relationship is a simple ontology).
For example, you can infer all the possible types of a resource, including supertypes of resources using this pattern:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?x ?type { ?x rdf:type/rdfs:subClassOf* ?type }
For example, this query will find the products that are subclasses of shirt:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX ex: <http://example.com> SELECT ?product WHERE { ?product rdf:type/rdfs:subClassOf* ex:Shirt ; }
For more about inference, see Inference.
SPARQL Aggregates
You can do simple analytic queries over triples using SPARQL aggregate functions. An aggregate function performs an operation over values or value co-occurrences in triples.
For example, you can use an aggregate function to compute the sum of values. This SPARQL query uses SUM to find the total sales:
PREFIX demov: <http://demo/verb/> PREFIX vcard: <http://www.w3.org/2006/vcard/ns/> SELECT (SUM (?sales) as ?sum_sales) FROM <http://marklogic.com/semantics/COMPANIES100/> WHERE { ?company a vcard:Organization . ?company demov:sales ?sales }
These SPARQL aggregate functions are supported:
Here is a SPARQL query using the aggregate function COUNT over a large number of triples:
PREFIX demor: <http://demo/resource/> PREFIX demov: <http://demo/verb/> PREFIX vcard: <http://www.w3.org/2006/vcard/ns/> # count the companies # (more precisely, count things of type organization) (SELECT ( COUNT (?company) AS ?count_companies ) FROM <http://marklogic.com/semantics/test/COMPANIES100/> WHERE { ?company a vcard:Organization . }=> 100
Here is another example using COUNT and ORDER BY DESC:
PREFIX demor: <http://demo/resource/> PREFIX demov: <http://demo/verb/> PREFIX vcard: <http://www.w3.org/2006/vcard/ns/> SELECT DISTINCT ?object (COUNT(?subject) AS ?count) WHERE { ?subject <http://www.w3.org/1999/02/22-rdf-syntax-ns#type/> ?object } GROUP BY ?object ORDER BY DESC (?count) LIMIT 10
This query uses aggregates (MAX) to find the baseball player with the highest uniform number, and then get all the triples that pertain to him (or her). It uses an arbitrary triple (bb:number) that it knows every player in the dataset has, stores the subject in ?key, then queries for all triples and filters out where the subject in the outer query matches the ?key value:
PREFIX bb: <http://marklogic.com/baseball/players/> PEFIX bbr: <http://marklogic.com/baseball/rules/> PREFIX xs: <http://www.w3.org/2001/XMLSchema#> SELECT * FROM <Athletics> { ?s ?p ?o . { SELECT(MAX(?s1) as ?key) WHERE { ?s1 bb:number ?o1 . } } FILTER (?s = ?key) } ORDER BY ?p
This complex nested query uses COUNT AVG to find the ten cheapest vendors for a specific product type, selected by the highest percentage of their product below the average cost, and then filters for vendors containing either name1 or name2:
PREFIX bsbm: <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/> PREFIX bsbm-inst: <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX cts: <http://marklogic.com/cts#> SELECT ?vendor (xsd:float(?belowAvg)/?offerCount As ?cheapExpensiveRatio) { { SELECT ?vendor (count(?offer) As ?belowAvg) { { ?product a <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/ProductType459> . ?offer bsbm:product ?product . ?offer bsbm:vendor ?vendor . ?offer bsbm:price ?price . { SELECT ?product (avg(xsd:float(xsd:string(?price))) As ?avgPrice) { ?product a <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/ instances/ProductType459> . ?offer bsbm:product ?product . ?offer bsbm:vendor ?vendor . ?offer bsbm:price ?price . } GROUP BB ?product } } . FILTER (xsd:float(xsd:string(?price)) < ?avgPrice) } GROUP BY ?vendor } { SELECT ?vendor (count(?offer) As ?offerCount) { ?product a <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/ instances/ProductType459> . ?offer bsbm:product ?product . ?offer bsbm:vendor ?vendor . } GROUP BY ?vendor } FILTER cts:contains(?vendor, cts:or-query(("name1", "name2"))) } ORDER BY desc(xsd:float(?belowAvg)/?offerCount) ?vendor LIMIT 10
Using the Results of sem:sparql
Here is an example of using the results of sem:sparql in a query:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; cts:search( fn:doc(), cts:triple-range-query( (), "takenIn", (: Use sem:sparql to run a query, then use the ! operator to : convert the solution to a sequence of strings :) sem:sparql( 'select ?countryIRI { ?continentIRI <http://www.w3.org/2004/02/skos/core#prefLabel> ?continentLabel . ?countryIRI <http://dbpedia.org/property/continent> ?continentIRI . }', map:entry("continentLabel", rdf:langString("Countries in South America", "en")) ) ! map:get(., "countryIRI") ))
SPARQL Resources
The SPARQL recommendation is closely related to these specifications:
- The SPARQL Protocol for RDF [SPROT] specification defines the remote protocol for issuing SPARQL queries and receiving the results. http://www.w3.org/TR/rdf-sparql-protocol/
- MarkLogic supports simple entailment, as described in the W3C recommendation: http://www.w3.org/TR/rdf-mt/#entail
- The SPARQL Query Results XML Format specification defines an XML document format for representing the results of SPARQL
SELECTandASKqueries. http://www.w3.org/TR/rdf-sparql-XMLres/ - SPARQL 1.1 Graph Store HTTP Protocol: http://www.w3.org/TR/2012/CR-sparql11-http-rdf-update-20121108/
There are a variety of tutorials available for learning more about the SPARQL query language. For example:
- Learning SPARQL by Bob DuCharme (Publisher: O'Reilly)
- Semantic Web for the Working Ontologist by Dean Allemang and Jim Hendler (Publisher: Morgan Kaufmann)
Additional useful resources include:
- SPARQL Implementations: http://www.w3.org/wiki/SparqlImplementations
- SPARQL Working Group: http://www.w3.org/2009/sparql/wiki/Main_Page
- SPARQL query results - JSON format: http://www.w3.org/TR/2012/PR-sparql11-results-json-20121108/
- SPARQL Frequently Asked Questions: http://thefigtrees.net/lee/sw/sparql-faq
Querying Triples with XQuery or JavaScript
This section contains examples of using XQuery or JavaScript with semantic data. When you use JavaScript or XQuery to query triples in MarkLogic, you can use the Semantics API library, built-in functions, the Search API built-in functions, or a combination of these.
This section includes the following topics:
- Preparing to Run the Examples
- Using Semantic Functions to Query
- Using Bindings for Variables
- Viewing Results as XML and RDF
- Working with CURIEs
- Using Semantics with cts Searches
Preparing to Run the Examples
These examples for querying triples with XQuery or Javascript assume that you have the GovTrack dataset stored on Archive.org. If you prefer to use your own dataset or cannot access the datasets mentioned here, you can skip this section.
The links to the datasets have moved since this section was written. They can be found at https://web.archive.org/web/20170718121008/https://www.govtrack.us/data/rdf/
This data is free, publicly available legislative information about bills in the US Congress, representatives, and voting records. The information originates from a variety of official government Web sites. The Govtrack.us data from Archive.org applies the principles of open data to legislative transparency.
Before installing the GovTrack dataset, make sure you have the following:
- MarkLogic Server 8.0-4 or later.
- MarkLogic Content Pump (mlcp). See in the mlcp User Guide
- The GovTrack dataset from Archive.org and access to https://web.archive.org/web/20170718121008/https://www.govtrack.us/data/rdf/
Follow this procedure to download the GovTrack dataset and load it into MarkLogic Server.
- Download the following files into a directory on your local file system:
- Create a
govtrackdatabase and forest. For these examples you can use the application server on port 8000 with the GovTrack data. This default server can function as an XDBC server and REST instance as well.To create your own XDBC server and REST instance see Setting Up Additional Servers in this guide and Administering REST Client API Instances in the in the REST Application Developer's Guide for more information.
- Verify that the triples index and the collection lexicon are enabled for the
govtrackdatabase. See Enabling the Triple Index. - Import the data into your
govtrackdatabase with mlcp, specifying the collections ofinfo:govtrack/peopleandinfo:govtrack/bills. See Loading Triples with mlcp. Your import command on Windows will look similar to the following:mlcp.bat import -host localhost -port 8000 -username admin ^ -password password -database govtrack -input_file_type rdf ^ -input_file_path c:\space\GovTrack -input_compressed true^ -input_compression_codec gzip ^ -output_collections "info:govtrack/people,info:govtrack/bills"
Modify the
host,port,username,password, and-input_file_pathoptions to match your environment. In this example, long lines have been broken for readability and Windows continuation characters (^) have been added.Be sure to add the
-databaseparameter to the command. If you leave this parameter out, the data will go into the default Documents database.The equivalent command for UNIX is:
mlcp.sh import -host localhost -port 8000 -username admin \ -password password -database govtrack -input_file_type RDF \ -input_file_path /space/GovTrack -input_compressed true \ -input_compression_codec gzip \ -output_collections 'info:govtrack/people,info:govtrack/bills'
In this example, the long lines have been broken and the UNIX continuation characters (\) have been added.
It is important to specify the
-input_file_typeas RDF to invoke the correct parser.
Using Semantic Functions to Query
You can execute SPARQL SELECT, ASK, and CONSTRUCT queries with the sem:sparql and sem:sparql-values functions in XQuery, and with the sem.sparql and sem.sparqlValues functions in Javascript. For details about the function signatures and descriptions, see the Semantics functions documentation and the XQuery Library Modules in the MarkLogic XQuery and XSLT Function Reference.
The following examples execute SPARQL queries against the triples index of the govtrack database. See Preparing to Run the Examples.
Although some of the semantics functions are built-in, others are not, so we recommend that you import the Semantics API library into every XQuery module or JavaScript module that uses the Semantics API.
Using XQuery, the import statement is:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy";
For Javascript, the import statement is:
var sem = require("/MarkLogic/semantics.xqy");
sem:sparql
You can use the sem:sparql function to query RDF data in the database in the same way you would in the SPARQL language. To use sem:sparql, you pass the SPARQL query to the function as a string.
Using XQuery the query would look like:
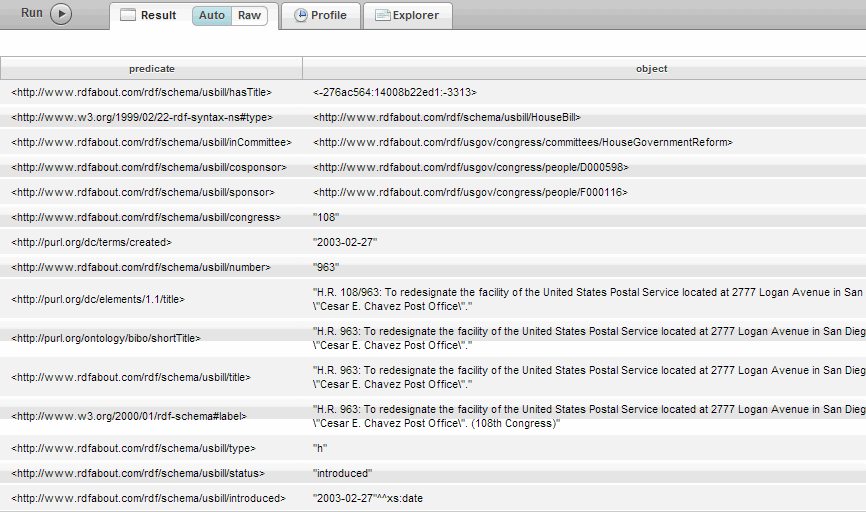
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:sparql(' PREFIX bill: <http://www.rdfabout.com/rdf/usgov/congress/108/bills/> SELECT ?predicate ?object WHERE { bill:h963 ?predicate ?object } ')
Using Javascript, the query would be:
var sem = require("/MarkLogic/semantics.xqy"); sem.sparql( + 'PREFIX bill: <http://www.rdfabout.com/rdf/usgov/congress/108/bills/>' + 'SELECT ?predicate ?object' + 'WHERE { bill:h963 ?predicate ?object }' )
In JavaScript, you must either use a left-quote (...Äò) at the beginning of a literal string that spans multiple lines. Otherwise, you must use a + or \ to concatenate the substrings.
The XQuery code returns an array as a sequence, whereas the JavaScript code returns a Sequence. See Sequence in the JavaScript Reference Guide for more information.
The result of the example query for all triples where the subject is bill number h963 would look like this:
For more information about constructing SPARQL queries, see Constructing a SPARQL Query.
You can also construct your SPARQL query as an input string in a FLWOR statement. In the following example, the let statement contains the SPARQL query. This is a SPARQL ASK query, to find out if there are any male politicians who are members of the Latter Day Saints:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $sparql := ' PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX politico: <http://www.rdfabout.com/rdf/schema/politico/> PREFIX govtrack: <http://www.rdfabout.com/rdf/schema/usgovt/> PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0/> ASK { ?x rdf:type politico:Politician ; foaf:religion "Latter Day Saints" ; foaf:gender "male". } ' return sem:sparql($sparql) => true
sem:sparql-values
Use the sem:sparql-values function to allow sequences of bindings to restrict what a SPARQL query returns. In this example, a sequence of values are bound to the subject IRIs that represent two members of congress.
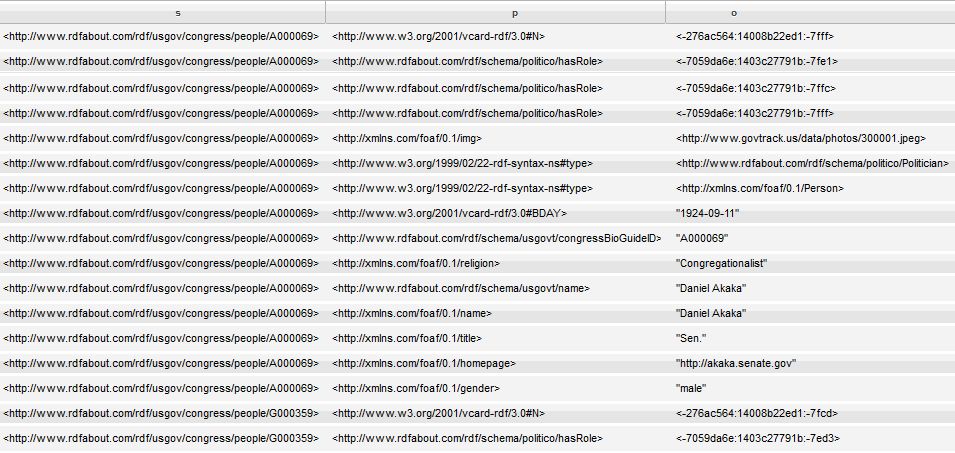
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $bindings := ( map:entry("s", sem:iri("http://www.rdfabout.com/rdf/usgov/congress/people/A000069")), map:entry("s", sem:iri("http://www.rdfabout.com/rdf/usgov/congress/people/G000359")) ) return sem:sparql-values("select * { ?s ?p ?o }",$bindings)
The results are returned as sequences of values for the two members of congress:
The sem:sparql-values function can be considered as equivalent to the SPARQL 1.1 facility of an outermost VALUES block. See Values Sections for more information.
Everywhere you use a variable in a SPARQL values query, you can set the variable to a fixed value by passing in external bindings as arguments to sem:sparql-values. See Using Bindings for Variables.
sem:store
The sem:store function contains a set of criteria used to select the set of triples to be passed in to sem:sparql, sem:sparql-values, or sem:sparql-update and evaluated as part of the query. The triples included in sem:store come from the current database's triple index, restricted by the options and the cts:query argument in sem:store (for instance, all triples in documents matching this query). If multiple sem:store constructors are supplied, the triples from all the sources are merged and queried together.
If a sem:store constructor is not supplied as an option for sem:sparql, sem:sparql-values, or sem:sparql-update, then the default sem:store constructor for the query will be used (the default database's triple index).
Querying Triples in Memory
You can use sem:in-memory-store to query triples in memory.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $triples := sem:rdf-parse($string, ("turtle", "myGraph")) let $query := ' PREFIX ad: <http://marklogic.com/addressbook/> PREFIX d: <http://marklogic.com/id/> CONSTRUCT{ ?person ?p ?o .} FROM <myOtherGraph> WHERE { ?person ad:firstName "Elvis" ; ad:lastName "Presley" ; ?p ?o . } ' for $result in sem:sparql($query, (), (), sem:in-memory-store($triples)) order by sem:triple-object($result) return <result>{$result}</result>
This query constructs a graph of triples in memory named myGraph containing persons named Elvis with a last name of Presley. The source of these triples is myOtherGraph and the results are returned in order.
Using Bindings for Variables
Extensions to standard SPARQL enable you to use bindings for variables in the body of a query statement. Everywhere you use a variable in a SPARQL query, you can set the variable to a fixed value by passing in external bindings as arguments to sem:sparql.
Bindings for variables can also be used as values in OFFSET and LIMIT clauses (in the syntax where they previously were not allowed). This example query uses bindings for variables with both LIMIT and OFFSET.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; import module namespace json = "http://marklogic.com/xdmp/json" at "MarkLogic/json/json.xqy"; declare namespace jbasic = "http://marklogic.com/xdmp/json/basic"; let $query := ' PREFIX bb: <http://marklogic.com/baseball/players/> SELECT ?firstname ?lastname ?team FROM <SportsTeams> { { ?s bb:firstname ?firstname . ?s bb:lastname ?lastname . ?s bb:team ?team . ?s bb:position ?position . FILTER (?position = ?pos) } } ORDER BY ?lastname LIMIT ?lmt ' let $mymap := map:map() let $put := map:put($mymap, "pos", "pitcher") let $put := map:put($mymap, "lmt", "3") let $triples := sem:sparql($query, $mymap) let $triples-xml := sem:query-results-serialize($triples, "xml") return <results>{$triples-xml}</results> => <results> <sparql xmlns="http://www.w3.org/2005/sparql-results/"> <head> <variable name="firstname"></variable> <variable name="lastname"></variable> <variable name="team"></variable> </head> <results> <result> <binding name="firstname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Fernando</literal> </binding> <binding name="lastname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Abad</literal> </binding> <binding name="team"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Athletics</literal> </binding> </result> <result> <binding name="firstname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Jesse</literal> </binding> <binding name="lastname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Chavez</literal> </binding> <binding name="team"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Athletics</literal> </binding> </result> <result> <binding name="firstname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Ryan</literal> </binding> <binding name="lastname"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Cook</literal> </binding> <binding name="team"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Athletics</literal> </binding> </result> </results> </sparql> </results>
Bindings can be used with SPARQL (sem:sparql), SPARQL values (sem:sparql-values), and SPARQL Update (sem:sparql-update). See Bindings for Variables for an example of bindings for variables used with SPARQL Update.
Viewing Results as XML and RDF
You can use sem:query-results-serialize and sem:rdf-serialize functions to view results in XML, JSON, or RDF serialization.
In this example, the sem:sparql query finds the cosponsors of bill number 1024 and passes the value sequence into sem:query-results-serialize to return the results as variable bindings in default XML format:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:query-results-serialize(sem:sparql(' PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> SELECT ?bill ?person ?name WHERE {?bill rdf:type bill:SenateBill ; bill:congress "108" ; bill:number "1024" ; bill:cosponsor ?person . ?person foaf:name ?name .} '))
The results are returned in W3C SPARQL Query Results format:
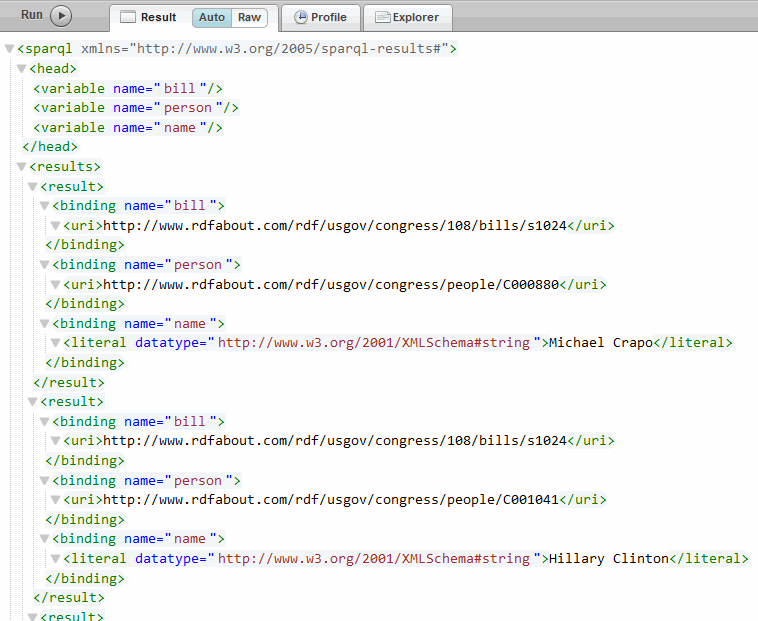
To view the same results in JSON serialization, add the format option after the query.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:query-results-serialize(sem:sparql(' PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX bill: <http://www.rdfabout.com/rdf/schema/usbill/> SELECT ?bill ?person ?name WHERE {?bill rdf:type bill:SenateBill ; bill:congress "108" ; bill:number "1024" ; bill:cosponsor ?person . ?person foaf:name ?name .} '), "json")
When you use the sem:rdf-serialize function, you pass the triple to return as a string, or optionally you can specify a parsing serialization option.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:rdf-serialize( sem:triple( sem:iri( "http://www.rdfabout.com/rdf/usgov/congress/people/D000060"), sem:iri("http://www.rdfabout.com/rdf/schema/usgovt/name"), "Archibald Darragh"), "rdfxml")
This table describes the serialization options available for the output:
| Serialization | Output As |
|---|---|
| ntriple | xs:string |
| nquad | xs:string |
| turtle | xs:string |
| rdfxml | an element |
| rdfjson | a json:object |
| triplexml | a sequence of sem:triple elements |
You can also select different ways to display results. See Selecting Results Rendering.
Working with CURIEs
A CURIE (Compact URI Expression) is a shortened version of a URI signifying a specific resource. With MarkLogic, lengthy IRIs can be shortened using a mechanism similar to that built into the SPARQL language. As a convenience, the definitions of several common prefixes are built in, as shown in the examples in this section.
CURIEs are composed of two components: a prefix, and a reference. The prefix is separated from the reference by a colon (:), for example, dc:description is a prefix for Dublin Core and the reference - http://purl.org/dc/elements/1.1/ - is the description.
These are the most common prefixes and their mapping:
map:entry("atom", "http://www.w3.org/2005/Atom/"), map:entry("cc", "http://creativecommons.org/ns/"), map:entry("dc", "http://purl.org/dc/elements/1.1/"), map:entry("dcterms", "http://purl.org/dc/terms/"), map:entry("doap", "http://usefulinc.com/ns/doap/"), map:entry("foaf", "http://xmlns.com/foaf/0.1/"), map:entry("media", "http://search.yahoo.com/searchmonkey/media/"), map:entry("og", "http://ogp.me/ns/"), map:entry("owl", "http://www.w3.org/2002/07/owl/"), map:entry("prov", "http://www.w3.org/ns/prov/"), map:entry("rdf", "http://www.w3.org/1999/02/22-rdf-syntax-ns"), map:entry("rdfs", "http://www.w3.org/2000/01/rdf-schema/"), map:entry("result-set", "http://www.w3.org/2001/sw/DataAccess/tests/result-set/"), map:entry("rss", "http://purl.org/rss/1.0/"), map:entry("skos", "http://www.w3.org/2004/02/skos/core/"), map:entry("vcard", "http://www.w3.org/2006/vcard/ns/"), map:entry("void", "http://rdfs.org/ns/void/"), map:entry("xhtml", "http://www.w3.org/1999/xhtml/"), map:entry("xs","http://www.w3.org/2001/XMLSchema#")
You can use the sem:curie-expand and sem:curie-shorten functions to work with CURIEs in MarkLogic. When you use sem:curie-expand, you eliminate the need to declare common prefixes.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:curie-expand("foaf:name") => <http://xmlns.com/foaf/0.1/name>
In this example, the cts:triple-range-query finds a person named Lamar Alexander. Note that the results are returned from a cts:search to find the sem:triple elements where the foaf:name equals Lamar Alexander. The predicate CURIE is displayed as the fully expanded IRI for foaf:name.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $query := cts:triple-range-query((), sem:curie-expand("foaf:name"), "Lamar Alexander", "sameTerm") return cts:search(fn:collection()//sem:triple, $query) => <sem:triples xmlns="http://marklogic.com/semantics"> <sem:subject> http://www.rdfabout.com/rdf/usgov/congress/people/A000360/ </sem:subject> <sem:predicate> http://xmlns.com/foaf/0.1/name </sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string"> Lamar Alexander </sem:object> </sem:triples>
In the following example, the query includes a series of cts:triples function calls and sem:curie-expand to find the name of the congressperson who was born on November 20, 1917. The person's name is returned as an RDF literal string from the object position (sem:triple-object) of the returned triple statement:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $person-triples := cts:triples((), sem:curie-expand("vcard3:BDAY", map:entry("vcard3", "http://www.w3.org/2001/vcard-rdf/3.0/")), "1917-11-20") let $subject := sem:triple-subject($person-triples) let $name-triples := cts:triples($subject, sem:curie-expand("foaf:name"), ()) let $name := sem:triple-object($name-triples) return ($name) => Robert Byrd
Use the sem:curie-shorten to compact an IRI to a CURIE. Evaluating the function involves replacing the CURIE with a concatenation of the value represented by the prefix and the part after the colon (the reference).
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:curie-shorten(sem:iri("http://www.w3.org/1999/02/ 22-rdf-syntax-ns#resource/")) => rdf:resource
Although CURIEs map to IRIs, do not use them as values for attributes or other content that are specified to contain only IRIs.
For example, the following query will return an empty sequence since the cts:triple-range-query expects an IRI (sem:iri) in that position not a sem:curie-shorten, which is a string:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $query := cts:triple-range-query((), sem:curie-shorten(sem:iri("http://xmlns.com/foaf/0.1/name")), "Lamar Alexander", "sameTerm") return cts:search(fn:collection()//sem:triple, $query)
Instead, either of the following can be used:
let $query := cts:triple-range-query((), sem:curie-expand("foaf:name"), "Lamar Alexander", "sameTerm")
Or alternatively expand the prefix to the full IRI:
let $query := cts:triple-range-query((), sem:iri("http://xmlns.com/foaf/0.1/name/"), "Lamar Alexander", "sameTerm")
The sameTerm function that is defined in SPARQL, performs the value equality operation. It differs from the equality operator (=) in the way that types are handled. In MarkLogic, types and timezones are the only things that make sameTerm different from =.For example, sameTerm(A,B) implies A=B. In SPARQL terms, using sameTerm semantics to match graphs to the graph patterns in a SPARQL query is called simple entailment. For more information, see Triple Values and Type Information.
Using Semantics with cts Searches
This section discusses using cts searches to return RDF data from a MarkLogic triple store. It includes the following topics:
cts:triples
The cts:triples function retrieves the parameter values from the triple index. Triples can be returned in any of the sort orders present in the triple index.
In this example, the subject IRI for a member of congress is passed as the first parameter for the subject IRI:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $r := cts:triples (sem:iri( "http://www.rdfabout.com/rdf/usgov/congress/people/D000060"), ) return ($r)
The matching results return triples for that member of congress (Archibald Darragh):
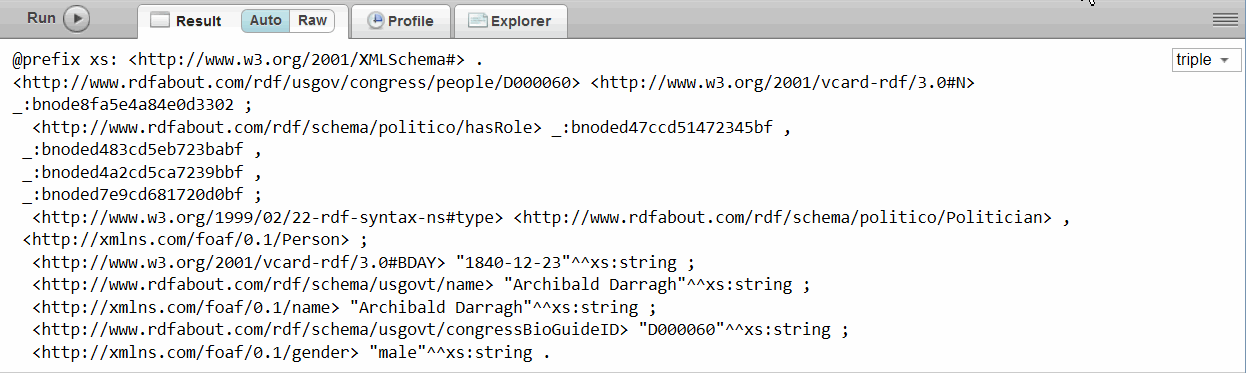
cts:triple-range-query
Access to the triple index is provided through the cts:triple-range-query function. The first parameter in this example is an empty sequence for the subject. The predicate and object parameters are provided, along with the sameTerm operator to find someone named Lamar Alexander:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $query := cts:triple-range-query((), sem:iri("http://xmlns.com/foaf/0.1/name"), "Lamar Alexander", "sameTerm") return cts:search(fn:collection()//sem:triple, $query)
cts:search
The built-in cts search functions are XQuery functions used to perform text searches. In this example, the cts:search queries against the info:govtrack/bills collection of XML docs to determine how many bills have the word Guam in the document (the cts:word-query of the specified string).
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; let $search := cts:search(//sem:triple, cts:and-query((cts:collection-query("info:govtrack/bills"), cts:word-query("Guam")) ) )[1] return cts:remainder($search) => 16
You can use a combination of cts:query and comparison operators. The cts:triple-range-query function in this example is used within a cts:search to find the sem:triple elements, where the foaf:name equals Lamar Alexander or where Alexander's subject IRI contains a foaf:img property conveying an image IRI.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; declare namespace dc = "http://purl.org/dc/elements/1.1/"; cts:search(collection()//sem:triple, cts:or-query(( cts:triple-range-query((), sem:curie-expand("foaf:name"), "Lamar Alexander", "sameTerm"), cts:triple-range-query( sem:iri ("http://www.rdfabout.com/rdf/usgov/congress/people/A000360"), sem:curie-expand("foaf:img"), (), "=" ) )))
You can construct sequences in SPARQL expressions and the SPARQL 1.1 IN and NOT IN operators to make effective use of built-in cts functions such as cts:and-query, which expect a sequence of cts:query values as the first argument.
You can also use cts:order constructors as an option to cts:search to to specify an ordering. This lets you order cts search results using a specified index for better, predictable performance. See Creating a cts:order Specification in the Query Performance and Tuning Guide.
cts:contains
You can use the cts:contains function in SPARQL expressions, which occur in FILTER and BIND clauses. For an example, see The FILTER Keyword.
Since cts:contains allows any value as the first argument, you can pass a variable that is bound by a triple pattern in the query as the first argument. The triple pattern uses the full-text index to reduce the results it returns during the lookup in the triple index. For example:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; fn:count(sem:sparql(' PREFIX cts: <http://marklogic.com/cts#> SELECT DISTINCT * WHERE { ?s ?p ?o . FILTER cts:contains(?o, cts:word-query("Environment")) } ') ) => 53
The following example is a query to verify if there is a bill number hr543.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; cts:contains(collection("info:govtrack/bills")//sem:subject, cts:word-query('hr543')) => true
Querying Triples with the Optic API
The Optic API can also be used for server-side queries of triples. The following Optic example query returns a list of the people who were born in Brooklyn in the form of a table with two columns, person and name.
xquery version "1.0-ml"; import module namespace op="http://marklogic.com/optic" at "/MarkLogic/optic.xqy"; let $resource := op:prefixer("http://dbpedia.org/resource/") let $foaf := op:prefixer("http://xmlns.com/foaf/0.1/") let $onto := op:prefixer("http://dbpedia.org/ontology/") let $person := op:col("person") return op:from-triples(( op:pattern($person, $onto("birthPlace"), $resource("Brooklyn")), op:pattern($person, $foaf("name"), op:col("name")))) => op:result()
This query uses the same data set as the one used for queries earlier in this chapter (see Querying Triples with SPARQL). The results would look like this:
For more about the Optic API, see Optic API for Multi-Model Data Access and Data Access Functions in the Application Developer's Guide and op:from-triples or op.fromTriples in the Optic API for more about server-side queries using Optic.
Serialization
You can set the output serialization for results in a variety of ways. These options can be set at the query level as part of the JSON or XQuery function to override any default options, or you could set the method in an XQuery declaration, or the method can be configured in the app server. These output options affect how data returned from the App Server or sent over REST is serialized.
Setting the Output Method
You can set the output method for the results of your query in the following ways. Each method overrides the next method in the list:
- set an option to
xdmp:quote() - set
xdmp:set-response-output-method() - set the XSLT output method
- Use a static declaration in XQuery (or JavaScript)
- Configure the output in app server
In other words, any configuration you have set in the app server will be overwritten by a static declaration in XQuery or Javascript.
To set the output method in an XQuery declaration use:
declare option xdmp:output "method = sparql-results-json"To set the output method as part of an XQuery function use:
set-response-output-method("sparql-results-json")As part of a server-side JavaScript function use to set the output method:
setResponseOutputMethod("sparql-results-json")Security
If you have a document with unmanaged triples, or you have TDE-extracted triples, those triples share the same security characteristics as the source documents. That is, if you can read the document containing the values that create the triples, you can read the triples.
With managed triples, the document inherits create permissions from the graph. When you set graph permissions, the documents created from those triples have the permissions you set on that graph.
The triple index, cts:triples, and sem:sparql queries only returns triples from documents which the database user has permission to read.
Named graphs inherit the write protection settings available to collections.
| Task | Privilege |
|---|---|
Executing sem:sparql |
http://marklogic.com/xdmp/privileges/sem-sparql |
For more information about MarkLogic security, see Document Permissions in the Security Guide.