
MarkLogic 10 Product DocumentationSemantic Graph Developer's Guide — Chapter 3
Loading Semantic Triples
You can load triples into a MarkLogic database from an XML document or JSON file that contains embedded triples elements, or from triples files containing serialized RDF data. This chapter includes the following sections:
You can also use SPARQL Update to load triples. See SPARQL Update for more information.
Loading Embedded RDF Triples
Load documents that contain embedded triples in XML documents or JSON documents with any of the ingestion tools described in Available Content Loading Interfaces in the Loading Content Into MarkLogic Server Guide.
The embedded triples must be in the MarkLogic XML format defined in the schema for sem:triple (semantics.xsd).
Triples ingested into a MarkLogic database are indexed by the triples index and stored for access and query by SPARQL. See Storing RDF Triples in MarkLogic for details.
Loading Triples
There are multiple ways to load documents containing triples serialized in a supported RDF serialization into MarkLogic. Supported RDF Triple Formats describes these RDF formats.
When you load one or more groups of triples, they are parsed into generated XML documents. A unique IRI is generated for every XML document. Each document can contain multiple triples.
The setting for the number of triples stored in documents is defined by MarkLogic Server and is not a user configuration.
Ingested triples are indexed with the triples index to provide access and the ability to query the triples with SPARQL, XQuery, or a combination of both. You can also use a REST endpoint to execute SPARQL queries and return RDF data.
If you do not provide a graph for the triple, the triples will be stored in a default graph that uses a MarkLogic Server feature called a collection. MarkLogic Server tracks the default graph with the collection IRI http://marklogic.com/semantics#default-graph.
You can specify a different collection during the load process and load triples into a named graph. For more information about collections, see Collections in the Search Developer's Guide.
If you insert triples into a database without specifying a graph name, the triples will be inserted into the default graph (http://marklogic.com/semantics#default-graph). If you insert triples into a super database and run fn:count(fn:collection()) in the super database, you will get a DUPURI exception for duplicate URIs.
The generated XML documents containing the triple data are loaded into a default directory named /triplestore. Some loading tools let you specify a different directory. For example, when you load triples using mlcp, you can specify the graph and the directory as part of the import options. For more information, see Loading Triples with mlcp.
This section includes the following topics:
- Supported RDF Triple Formats
- Example RDF Formats
- Loading Triples with mlcp
- Loading Triples with XQuery
- Loading Triples with JavaScript
- Loading Triples Using the REST API
- Loading Triples Using the Java API
- Loading Triples Using the Node.js API
Supported RDF Triple Formats
MarkLogic Server supports loading these RDF data formats:
| Format | Description | File Type | MIME Type |
|---|---|---|---|
| RDF/XML | A syntax used to serialize an RDF graph as an XML document. For an example, see RDF/XML. | .rdf | application/rdf+xml |
| Turtle | Terse RDF Triple Language (Turtle) serialization is a simplified subset of Notation 3 (N3), used for expressing data in the lowest common denominator of serialization. For an example, see Turtle. | .ttl | text/turtle |
| RDF/JSON | A syntax used to serialize RDF data as JSON objects. For an example, see RDF/JSON. | .json | application/rdf+json |
| N3 | Notation3 (N3) serialization is a non-XML syntax used to serialize RDF data. For an example, see N3. | .n3 | text/n3 |
| N-Triples | A plain text serialization for RDF graphs. N-Triples is a subset of Turtle and Notation3 (N3). For an example, see N-Triples. | .nt | application/n-triples |
| N-Quads | A superset serialization that extends N-Triples with an optional context value. For an example, see N-Quads. | .nq | application/n-quads |
| TriG | A plain text serialization for RDF-named graphs and RDF datasets. For an example, see TriG. | .trig | application/trig |
Example RDF Formats
This section includes examples for the following RDF formats:
RDF/XML
RDF/XML is the original standard for writing unique RDF syntax as XML. It is used to serialize an RDF graph as an XML document.
This example defines three prefixes: rdf, xsd, and d.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:d="http://example.org/data/" xmlns:xsd="http://www.w3.org/2001/XMLSchema#"> <rdf:Description rdf:about="http://example.org/data#item22"> <d:shipped rdf:datatype="http://www.w3.org/2001/XMLSchema#date"> 2013-05-14</d:shipped> <d:quantity rdf:datatype="http://www.w3.org/2001/XMLSchema#integer"> 27</d:quantity> <d:invoiced rdf:datatype="http://www.w3.org/2001/XMLSchema#boolean"> true</d:invoiced> <d:costPerItem rdf:datatype="http://www.w3.org/2001/XMLSchema#decimal"> 10.50</d:costPerItem> </rdf:Description> </rdf:RDF>
Turtle
Terse RDF Triple Language (or Turtle) serialization expresses data in the RDF data model using a syntax similar to SPARQL. Turtle syntax expresses triples in the RDF data model in groups of three IRIs.
<http://example.org/item/item22> <http://example.org/details/shipped> "2013-05-14"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
This triple states that item 22 was shipped on May 14th, 2013.
Turtle syntax provides a way to abbreviate information for multiple statements using @prefix to factor out the common portions of IRIs. This makes it quicker to write RDF Turtle statements. The syntax resembles RDF/XML, however unlike RDF/XML, it does not rely on XML. Turtle syntax is also valid Notation3 (N3) since Turtle is a subset of N3.
Turtle can only serialize valid RDF graphs.
In this example, four triples describe a transaction. The shipped object is assigned a date datatype, making it a typed literal enclosed in quotes. There are three untyped literals for the quantity, invoiced, and costPerItem objects.
@prefix i: <http://example.org/item> . @prefix dt: <http://example.org/details#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . i:item22 dt:shipped "2013-05-14"^^xsd:date . i:item22 dt:quantity 100 . i:item22 dt:invoiced true . i:item22 dt:costPerItem 10.50 .
RDF/JSON
RDF/JSON is a textual syntax for RDF that allows an RDF graph to be written in a form compatible with JavaScript Object Notation (JSON).
{ "http://example.com/directory#m": { "http://example.com/ns/person#firstName": [ { "value": "Michelle", "type": "literal", "datatype": "http://www.w3.org/2001/XMLSchema#string" } ] } }
N3
Notation3 (N3) is a non-XML syntax used to serialize RDF graphs in a more compact and readable form than XML RDF notation. N3 includes support for RDF-based rules.
When you have several statements about the same subject in N3, you can use a semicolon (;) to introduce another property of the same subject. You can also use a comma to introduce another object with the same predicate and subject.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> . @prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix foafcorp: <http://xmlns.com/foaf/corp/> . @prefix vcard: <http://www.w3.org/2001/vcard-rdf/3.0> . @prefix sec: <http://www.rdfabout.com/rdf/schema/ussec> . @prefix id: <http://www.rdfabout.com/rdf/usgov/sec/id> . id:cik0001265081 sec:hasRelation [ dc:date "2008-06-05"; sec:corporation id:cik0001000045; rdf:type sec:OfficerRelation; sec:officerTitle "Senior Vice President, CFO"] . id:cik0001000180 sec:cik "0001000180"; foaf:name "SANDISK CORP"; sec:tradingSymbol "SNDK"; rdf:type foafcorp:Company. id:cik0001009165 sec:cik "0001009165"; rdf:type foaf:Person; foaf:name "HARARI ELIYAHOU ET AL"; vcard:ADR [ vcard:Street "601 MCCARTHY BLVD.; "; vcard:Locality "MILPITAS, CA"; vcard:Pcode "95035" ] .
N-Triples
N-Triples is a plain text serialization for RDF graphs. It is a subset of Turtle, designed to be simpler to use than Turtle or N3. Each line in N-Triples syntax encodes one RDF triple statement and consists of the following:
- Subject (an IRI or a blank node identifier), followed by one or more characters of whitespace
- Predicate (an IRI), followed by one or more characters of whitespace
- Object (an IRI, blank node identifier, or literal) followed by a period (.) and a new line.
Typed literals may include language tags to indicate the language. In this N-Triples example, @en-US indicates that title of the resource is in US English.
<http://www.w3.org/2001/sw/RDFCore/ntriples> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Document> . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://purl.org/dc/terms/title> "Example Doc"@en-US . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://xmlns.com/foaf/0.1/maker> _:jane . <http://www.w3.org/2001/sw/RDFCore/ntriples/> <http://xmlns.com/foaf/0.1/maker> _:joe . _:jane <http://www.w3.org/1999/02/22-rdf-syntax-ns> <http://xmlns.com/foaf/0.1/Person> . _:jane <http://xmlns.com/foaf/0.1/name> "Jane Doe". _:joe <http://www.w3.org/1999/02/22-rdf-syntax-ns> <http://xmlns.com/foaf/0.1/Person> . _:joe <http://xmlns.com/foaf/0.1/name> "Joe Bloggs".
Each line breaks after the end period. For clarity, additional line breaks have been added.
N-Quads
N-Quads is a line-based, plain text serialization for encoding an RDF dataset. N-Quads syntax is a superset of N-Triples, extending N-Triples with an optional context value. The simplest statement is a sequence of terms (subject, predicate, object) forming an RDF triple, and an optional IRI labeling the graph in a dataset to which the triple belongs. All of these are separated by a whitespace and terminated by a period (.) at the end of each statement.
This example uses the relationship vocabulary. The class or property in the vocabulary has a IRI constructed by appending a term name acquaintanceOf to the vocabulary IRI.
<http://example.org/#Jane> <http://http://purl.org/vocab.org/relationship/#acquaintanceOf> <http://example.org/#Joe> <http://example.org/graphs/directory> .
TriG
TriG is a plain text serialization for serializing RDF graphs. TriG is similar to Turtle, but is extended with curly braces ({) and (}) to group triples into multiple graphs and precede named graphs with their names. An optional equals operator (=) can be used to assign graph names and an optional end period (.) is included for Notation3 compatibility.
Characteristics of TriG serialization include:
- Graph names must be unique within a TriG document, with one unnamed graph per TriG document.
- TriG content is stored in files with an '.trig' suffix. The MIME type of TriG is application/trig and the content encoding is UTF-8.
This example contains a default graph and two named graphs.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> . @prefix dc: <http://purl.org/dc/elements/1.1/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . # default graph is http://marklogic.com/semantics#default-graph { <http://example.org/joe> dc:publisher "Joe" . <http://example.org/jane> dc:publisher "Jane" . } # first named graph <http://example.org/joe> { _:a foaf:name "Joe" . _:a foaf:mbox <mailto:joe@jbloggs.example.org> . } # second named graph <http://example.org/jane> { _:a foaf:name "Jane" . _:a foaf:mbox <mailto:jane@jdoe.example.org> . }
Loading Triples with mlcp
MarkLogic Content Pump (mlcp) is a command line tool for importing into, exporting from, and copying content to MarkLogic from a local file system or Hadoop distributed file system (HDFS).
Using mlcp, you can bulk load billions of triples and quads into a MarkLogic database and specify options for the import. For example, you can specify the directory into which the triples or quads are loaded. It is the recommended tool for bulk loading triples. For more detailed information about mlcp, see Loading Content Using MarkLogic Content Pump in the Loading Content Into MarkLogic Server Guide.
This section discusses loading triples into MarkLogic Server with mlcp and includes the following topics:
Preparation
Use these procedures to load content with mlcp:
- Download and extract the mlcp binary files from developer.marklogic.com. Be sure that you have the latest version of mlcp. For more information about installing and using mlcp and system requirements, see Installation and Configuration in the mlcp User Guide.
Although the extracted mlcp binary files do not need to be on the same MarkLogic host machine, you must have access and permissions for the host machine into which you are loading the triples.
- For these examples we will use the default database (Documents) and forest (Documents). To create your own database see Creating a New Database in the Administrator's Guide.
- Verify that the triple index is enabled by checking the Documents database configuration page of the Admin Interface, or using the Admin API. See Enabling the Triple Index for details.
The collection lexicon index is required for the Graph Store HTTP Protocol used by REST API instances and for use of the GRAPH ?g construct in SPARQL queries. See Configuring the Database to Work with Triples for information on the collection lexicon.
- You can use mlcp with the default server on port 8000, which includes an XDBC server. To create your own XDBC server, see Creating a New XDBC Server in the Administrator's Guide.
- (Optional) Put the mlcp bin directory in your path. For example:
$ export PATH=${PATH}:/space/marklogic/directory-name/bin
where directory-name is derived from the version of mlcp that you downloaded.
- Use a command-line interpreter or interface to enter the import command as a single-line command.
Import Command Syntax
The mlcp import command syntax required for loading triples and quads into MarkLogic is:
mlcp_command import -host hostname -port port number \ -username username -password password -output_graph graphname\ -input_file_path filepath -input_file_type filetype
Long command lines in this section are broken into multiple lines using the line continuation characters \ or ^. Remove the line continuation characters when you use the import command.
The mlcp_command you use depends on your environment. Use the mlcp shell script mclp.sh for UNIX systems and the batch script mlcp.bat for Windows systems. The -host and -port values specify the MarkLogic host machine into which you are loading the triples. Your user credentials, -username and -password are followed by the path to the content , the -input_file_path value. If you use your own database, be sure to add the -database parameter for your database. If no database parameter is specified, the content will be put into the default Documents database.
The -input_file_path may point to a directory, file, or compressed file in .zip or .gzip format. The -input_file_type is the type of content to be loaded. For triples, the -input_file_type must be RDF.
The file extension of the file found in the -input_file_path is used by mlcp to identify the type of content being loaded. The type of RDF serialization is determined by the file extension (.rdf, .ttl, .nt, and so on).
A document with a file extension of .nq or .trig is identified as quad data, all other file extensions are identified as triple data. For more information about file extensions, see Supported RDF Triple Formats.
You must have sufficient MarkLogic privileges to import to the specified host. See Security Considerations in the mlcp User Guide.
Loading Triples and Quads
In addition to the required import options, you can specify several input and output options. See Import Options for more details about these options. For example, you can load triples and quads by specifying RDF as the -input_file_type option:
$ mlcp.sh import -host localhost -port 8000 -username user \ -password passwd -input_file_path /space/tripledata/example.nt \ -output_graph /my/graph -mode local -input_file_type RDF
This example uses the shell script to load triples from a single N-Triples file example.nt, from a local file system directory /space/tripledata into a MarkLogic host on port 8000.
On a Windows environment, the command would look like this:
> mlcp.bat import -host localhost -port 8000 ^ -username admin -password passwd ^ -input_file_path c:\space\tripledata\example.nt -mode local^ -input_file_type RDF -output_graph /my/graph
For clarity, these long command lines are broken into multiple lines using the line continuation characters \ or ^. Remove the line continuation characters when you use the import command.
When you specify RDF as -input_file_type the mlcp RDFReader parses the triples and generates XML documents with sem:triple as the root element of the document.
Import Options
These options can be used with the import command to load triples or quads.
| Options | Description |
|---|---|
-input_file_type string |
Specifies the input file type. Default: document. For triples, use RDF. |
-input_compressed boolean |
When set to true this option enables decompression on import. Default: false |
-fastload boolean |
When set to true this option forces optimal performance with a direct forest update. This may result in duplicate document IRIs. See in the mlcp User Guide. |
-output_directory |
Specifies the destination database directory in which to create the loaded documents. Using this option enables -fastload by default, which can cause duplicate IRIs to be created. See in the mlcp User Guide. Default: /triplestore |
-output_graph |
The graph value to assign to quads with no explicit graph specified in the data. Cannot be used with -output_override_graph. |
-output_override_graph |
The graph value to assign to every quad, whether a quad is specified in the data or not. Cannot be used with -output_graph. |
-output_collections |
Creates a comma-separated list of collections. Default: http://marklogic.com/semantics#default-graph
If -output_collections is used with -output_graph and -output_override_graph, the collections specified will be added to the documents loaded. |
-database string |
(optional) The name of the destination database. Default: The database associated with the destination App Server identified by -host and -port. |
When you load triples using mlcp, the -output_permissions option is ignored - triples (and, under the covers, triples documents) inherit the permissions of the graph that you're loading into.
If -output_collections and -output_override_graph are set at the same time, a graph document will be created for the graph specified by -output_override_graph, and triples documents will be loaded into collections specified by -output_collections and -output_override_graph.
If -output_collections and -output_graph are set at the same time, a graph document will be created for the graph specified by -output_graph (where there is no explicit graph specified in the data). Quads with no explicit graph specified in the data will be loaded into collections specified by -output_collections and the graph specified by -output_graph, while those quads that contain explicit graph data will be loaded into the collections specified by -output_collections and the graph(s) specified.
You can split large triples documents into smaller documents to parallelize loading with mlcp and load all the files in a directory that you specify with -input_file_path.
For more information about import and output options for mlcp, see in the mlcp User Guide.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh import -host localhost -port 8000 -username user \ -password passwd -input_file_path /space/tripledata \ -mode local -input_file_type RDF -output_graph /my/graph
Specifying Collections and a Directory
To load triples into a named graph, specify a collection by using the -output_collections option.
To create a new graph, you need to have the sparql-update-user role. For more information about roles, see Understanding Roles in the Security Guide.
# Windows users, see Modifying the Example Commands for Windows $ mlcp.sh import -host localhost -port 8000 -username user \ -password passwd -input_file_path /space/tripledata \ -mode local -input_file_type RDF -output_graph /my/graph\ -output_collections /my/collection
This command puts all the triples in the tripledata directory into a named graph and overwrites the graph IRI to /my/collection.
Use -output_collections and not -filename_as_collection to overwrite the default graph IRI.
For triples data, the documents go in the default collection (http://marklogic.com/semantics#default-graph) if you do not specify any collections.
For quad data, if you do not specify any collections, the triples are parsed, serialized, and stored in documents with the fourth part of the quad as the collection.
For example with this quad, the fourth part is an IRI that identifies the homepage of the subject.
<http://dbpedia.org/resource/London_Heathrow_Airport> <http://xmlns.com/foaf/0.1/homepage> <http://www.heathrowairport.com/> <http://en.wikipedia.org/wiki/London_Heathrow_Airport?oldid=495283228# absolute-line=26/> .
When the quad is loaded into the database, the collection is generated as a named graph, http://en.wikipedia.org/wiki/London_Heathrow_Airport?oldid=495283228#absolute-line=26.
If the -output_collections import option specifies a named graph, the fourth element of the quad is ignored and the named graph is used.
If you are using a variety of loading methods, consider putting all of the triples documents in a common directory. Since the sem:rdf-insert and sem:rdf-load functions put triples documents in the /triplestore directory, use -output_uri_prefix /triplestore to put mlcp-generated triples documents there as well.
$ mlcp.sh import -host localhost -port 8000 -username user \ -password passwd -input_file_path /space/tripledata/example.zip \ -mode local -input_file_type RDF -input_compressed true -output_collections /my/collection -output_uri_prefix '/triplestore' \ -output_graph /my/graph
When you load triples or quads into a specified named graph from a compressed .zip or .gzip file, mlcp extracts and serializes the content based on the serialization. For example, a compressed file containing Turtle documents (.ttl) will be identified and parsed as triples.
When the content is loaded into MarkLogic with mlcp, the triples are parsed as they are ingested as XML documents with a unique IRI. These unique IRIs are random numbers expressed in hexadecimal. This example shows triples loaded with mlcp from the persondata.ttl file, with the -output_uri_prefix specified as /triplestore:
/triplestore/d2a0b25bda81bb58-0-10024.xml /triplestore/d2a0b25bda81bb58-0-12280.xml /triplestore/d2a0b25bda81bb58-0-13724.xml /triplestore/d2a0b25bda81bb58-0-14456.xml
Carefully consider the method you choose for loading triples. The algorithm for generating the document IRIs with mlcp differs from other loading methods such as loading from a system file directory with sem:rdf-load.
For example, loading the same persondata.ttl file with sem:rdf-load results in IRIs that appear to have no relation to each other:
/triplestore/11b53cf4db02080a.xml /triplestore/19b3a986fcd71a5c.xml /triplestore/215710576ebe4328.xml /triplestore/25ec5ded9bfdb7c2.xml
When you load triples with sem:rdf-load, the triples are bound to the http://marklogic.com/semantics prefix in the resulting documents.
<?xml version="1.0" encoding="UTF-8"?> <sem:triples xmlns:sem="http://marklogic.com/semantics"> <sem:triple> <sem:subject>http://dbpedia.org/resource/Wayne_Stenehjem </sem:subject> <sem:predicate>http://purl.org/dc/elements/1.1/description </sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#string" xml:lang="en">American politician </sem:object> </sem:triple> <sem:triple> <sem:subject>http://dbpedia.org/resource/Wayne_Stenehjem </sem:subject> <sem:predicate>http://dbpedia.org/ontology/birthDate </sem:predicate> <sem:object datatype="http://www.w3.org/2001/XMLSchema#date"> 1953-02-05 </sem:object> </sem:triple> </sem:triples>
You can leave out the sem:triples tag, but you cannot leave out the sem:triple tags.
Loading Triples with XQuery
Triples are typically created outside MarkLogic Server and loaded via Query Console by using the following sem: functions:
The sem:rdf-insert and sem:rdf-loadfunctions are update functions. The sem:rdf-get function is a return function that loads triples in memory. These functions are included in the XQuery Semantics API that is implemented as an XQuery library module.
To use sem: functions in XQuery, import the module with the following XQuery prolog statement in Query Console:
import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy";
If this module is already imported, you will get an error message.
For more details about semantic functions in XQuery, see the Semantics (sem:) documentation in the MarkLogic XQuery and XSLT Function Reference.
sem:rdf-insert
The sem:rdf-insertfunction inserts triples into the database as triples documents. The triple is created in-memory by using the sem:triple and sem:iri constructors. The IRIs of the inserted documents are returned on execution.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:rdf-insert( sem:triple( sem:iri("http://example.org/people#m"), sem:iri("http://example.com/person#firstName"), "Michael"))
This returns the document IRI:
/triplestore/70eb0b7139816fe3.xml
By default, sem:rdf-insert puts the documents into the directory /triplestore/ and assigns the default graph. You can specify a named graph as a collection in the fourth parameter.
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:rdf-insert(sem:triple( sem:iri("http://example.com/ns/directory#jp"), sem:iri("http://example.com/ns/person#firstName"), "John-Paul"), null, null, "mygraph")
When you run this example, the document is inserted into both the default graph and mygraph.

If you insert quads or triples in TriG serialization, the graph name comes from the value in the fourth position in the quads/trig file.
sem:rdf-load
The sem:rdf-loadfunction loads and parses triples from files in a specified location into the database and returns the IRIs of the triples documents. You can specify the serialization of the triples, such as turtle for Turtle files or rdfxml for RDF files.
sem:rdf-load('C:\rdfdata\example.rdf', "rdfxml") => /triplestore/fbd28af1471b39e9.xml
As with sem:rdf-insert, this function also puts the triples documents into the default graph and /triplestore/ directory unless a directory or named graph is specified in the options. This example specifies mynewgraph as a named graph in the parameters:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:rdf-load("C:\turtledata\example.ttl", "turtle", (), (), "mynewgraph")

To use sem:rdf-load you need the xdmp:document-get privilege.
sem:rdf-get
The sem:ref-get function returns triples in triples files from a specified location. The following example retrieves triples serialized in Turtle serialization from the local filesystem:
xquery version "1.0-ml"; import module namespace sem = "http://marklogic.com/semantics" at "/MarkLogic/semantics.xqy"; sem:rdf-get('C:\turtledata\people.ttl', "turtle")
The triples are returned as triples in Turtle serialization with one triple per line. Each triple ends with a period.
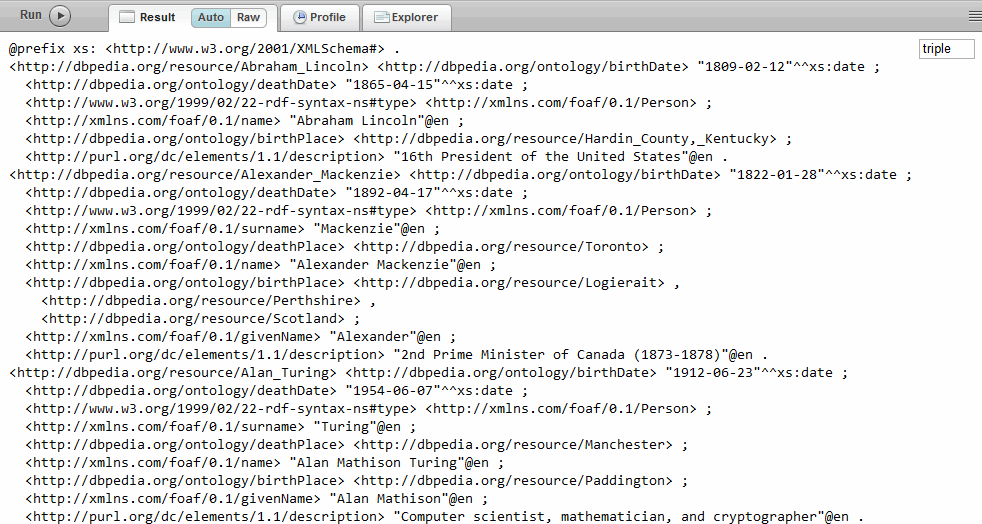
This Query Console display format allows for easy copying from the Result pane.
Loading Triples with JavaScript
Triples can be loaded via Query Console by using the following sem. functions:
The sem.rdfInsert and sem.rdfLoadfunctions are update functions. The sem.rdfGet function is a return function that loads triples in memory. These functions are included in the JavaScript Semantics API.
To use sem. functions in JavaScript, import the module with the following JavaScript statements in Query Console:
declareUpdate(); const sem = require("/MarkLogic/semantics.xqy");
If this module is already imported, you will get an error message.
For more details about semantic functions in JavaScript, see the Semantics (sem.) documentation in the MarkLogic Server-Side JavaScript Function Reference.
sem.rdfInsert
The sem.rdfInsertfunction inserts triples into the database as triples documents. The triple is created in-memory by using the sem.triple and sem.iri constructors. The IRIs of the inserted documents are returned on execution.
declareUpdate(); const sem = require("/MarkLogic/semantics.xqy"); sem.rdfInsert( sem.triple( sem.iri("http://example.com/ns/directory#m"), sem.iri("http://example.com/ns/person#firstName"), "Michael"));
This returns the document IRI:
/triplestore/74521a908ece2074.xml
By default, sem.rdfInsert puts the documents into the directory /triplestore/ and assigns the default graph. You can specify a named graph as a collection in the fourth parameter.
declareUpdate(); const sem = require("/MarkLogic/semantics.xqy"); sem.rdfInsert( sem.triple( sem.iri("http://example.com/ns/directory#m"), sem.iri("http://example.com/ns/person#firstName"), "John-Paul"), (), (), "mygraph");
When you run this example, the document is inserted into both the default graph and mygraph.
If you insert quads or triples in TriG serialization, the graph name comes from the value in the fourth position in the quads/trig file.
sem.rdfLoad
The sem.rdfLoadfunction loads and parses triples from files in a specified location into the database and returns the IRIs of the triples documents. You can specify the serialization of the triples, such as turtle for Turtle files or rdfxml for RDF files.
declareUpdate(); var sem = require("/MarkLogic/semantics.xqy"); sem.rdfLoad('C:/data/example.rdf', "rdfxml") => /triplestore/fbd28af1471b39e9.xml
As with sem.rdf-Insert, this function also puts the triples documents into the default graph and /triplestore/ directory unless a directory or named graph is specified in the options. This example specifies mynewgraph as a named graph in the parameters:
declareUpdate(); var sem = require("/MarkLogic/semantics.xqy"); sem.rdfLoad('C:/turtledata/example.ttl', "turtle", (), (), "mynewgraph")) => /triplestore/fbd28af1471b39e9.xml
To use sem.rdfLoad you need the xdmp.documentGet privilege.
sem.rdfGet
The sem.refGet function returns triples in triples files from a specified location. The following example retrieves triples serialized in Turtle serialization from the local filesystem:
var sem = require("/MarkLogic/semantics.xqy"); sem.rdfGet('C:/turtledata/people.ttl', "turtle");
The triples are returned as triples in Turtle serialization with one triple per line. Each triple ends with a period.
Loading Triples Using the REST API
A REST endpoint is an XQuery module on MarkLogic Server that routes and responds to an HTTP request. An HTTP client invokes endpoints to create, read, update, or delete content in MarkLogic. This section discusses using the REST API to load triples with a REST endpoint. It covers the following topics:
- Preparation
- Addressing the Graph Store
- Specifying Parameters
- Supported Verbs
- Supported Media Formats
- Loading Triples
- Response Errors
Preparation
If you are unfamiliar with the REST API and endpoints, see Introduction to the MarkLogic REST API in the REST Application Developer's Guide.
Use the following procedures to make requests with REST endpoints:
- Install MarkLogic Server version 8.0-4 or later.
- Install
curlor an equivalent command line tool for issuing HTTP requests. - You can use the default database and forest (Documents) on port 8000 or create your own. To create a new database and forest, see Creating a New Database in the Administrator's Guide.
- Verify that the triple index and the collection lexicon are enabled on the Documents database by checking the configuration page of the Admin Interface or by using the Admin API. See Enabling the Triple Index.
The collection lexicon is required for the Graph Store HTTP Protocol of REST API instances.
- You can use the default REST API instance associated with port 8000. If you want to create a new REST API instance, see Creating an Instance in the REST Application Developer's Guide.
Addressing the Graph Store
The graph endpoint is an implementation of the W3C Graph Store HTTP Protocol as specified in the SPARQL 1.1 Graph Store HTTP Protocol:
http://www.w3.org/TR/2013/REC-sparql11-http-rdf-update-20130321/
The base URL for the graph store is:
http://hostname:port/vversion/graphs
Where hostname is the MarkLogic Server host machine, port is the port on which the REST API instance is running, and version is the version number of the API. The Graph Store HTTP Protocol is a mapping from RESTful HTTP requests to the corresponding SPARQL 1.1 Update operations. See Summary of the /graphs Service in the REST Application Developer's Guide.
Specifying Parameters
The graph endpoint accepts an optional parameter for a particular named graph. For example:
http://localhost:8000/v1/graphs?graph=http://named-graph
If omitted, the default graph must be specified as a default parameter with no value.
http://localhost:8000/v1/graphs?default
When a GET request is issued with no parameters, the list of graphs will be given in list format. See GET /v1/graphs for more details.
Supported Verbs
A REST client uses HTTP verbs such as GET and PUT to interact with MarkLogic Server. This table lists the supported verbs and the role required to use each:
| Verb | Description | Role |
|---|---|---|
GET |
Retrieves a named graph. | rest-reader |
POST |
Merges triples into a named graph or adds triples to an empty graph. | rest-writer |
PUT |
Replaces triples in a named graph or adds triples to an empty graph. Functionally equivalent to DELETE followed by POST. For an example, see Loading Triples. |
rest-writer |
DELETE |
Removes triples in a named graph. | rest-writer |
HEAD |
Test for the existence of a graph. Retrieves a named graph, without the body. | rest-reader |
The role you use to make a MarkLogic REST API request must have appropriate privileges for the content accessed by the HTTP call; for example, permission to read or update documents in the target database. For more information about REST API roles and privileges, see Security Requirements in the REST Application Developer's Guide.
This endpoint will only update documents with the element sem:triple as the root.
Supported Media Formats
For a list of supported media formats for the Content-type HTTP header, see Supported RDF Triple Formats.
Loading Triples
To insert triples, make a PUT or POST request to a URL of the form:
http://host:port/v1/graphs?graph=graphname
When constructing the request:
- Specify the graph in which to load the triples.
- Place the content in the request body.
- Specify the MIME type of the content in the
Content-typeHTTP header. See Supported RDF Triple Formats. - Specify the user credentials.
The triples are loaded into the default directory, /triplestore.
This is an example of a curl command for a UNIX or Cygwin command line interpreter. The command sends a PUT HTTP request to insert the contents of the file example.nt into the database as XML documents in the default graph:
# Windows users, see Modifying the Example Commands for Windows $ curl -s -X PUT --data-binary '@example.nt' \ -H "Content-type: application/n-triples" \ --digest --user "admin:password" \ "http://localhost:8000/v1/graphs?default"
When you load triples with the REST endpoint using PUT or POST, you must specify the default graph or a named graph.
These curl command options are used in the preceding example:
| Option | Description |
|---|---|
-s |
Specifies silent mode, so that the curl output does not include the HTTP response headers in the output. The alternative is -i to include the response headers. |
-X http_method |
The type of HTTP request (PUT) that curl will send. Other supported requests are GET, POST and DELETE. See Supported Verbs. |
--data-binary data |
Data to include in the request body. Data may be placed directly on the command line as an argument to --data-binary, or read from a file by using @filename. If you are using Windows, a Windows version of curl that supports the "@" operator is required. |
-H headers |
The HTTP header to include in the request. The examples in this guide use Content-type. |
--digest |
The authentication method specified encrypts the user's password. |
--user user:password |
Username and password used to authenticate the request. Use a MarkLogic Server user that has sufficient privileges to carry out the requested operation. For details, see Security Requirements in the REST Application Developer's Guide. |
For more information about the REST API, see the Semantics documentation in the REST Client API. For more about REST and Semantics see Using Semantics with the REST Client API.
Response Errors
This section covers the error reporting conventions followed by the MarkLogic REST API.
If a request to a MarkLogic REST API Instance fails, an error response code is returned and additional information is detailed in the response body.
These response errors may be returned:
400 Bad Requestreturns forPUTorPOSTrequests that have no parameters at all.400 Bad Requestreturns forPUTorPOSTrequests for payloads that fails to parse.404 Not Foundreturns forGETrequests to a graph that does not exist (the IRI is not present in the collection lexicon).406 Not Acceptablereturns forGETrequests for triples in an unsupported serialization.415 Unsupported Media Typereturns forPOSTorPUTrequest in an unsupported format.The
repairparameter forPOSTandPUTrequests can be set totrueorfalse. By default this isfalse. If set totrue, a payload that does not properly parse will still insert any triples that do parse. If set to false, any payload errors whatsoever will result in a400Bad Requestresponse.
Loading Triples Using the Java API
For an example of loading triples using the MarkLogic Java API, see Example: Loading, Managing, and Querying Triples in the Java Application Developer's Guide.
Loading Triples Using the Node.js API
For an example of loading triples using the MarkLogic Node.js API, see Loading Triples in the Node.js Application Developer's Guide.